Configuraciones de TPU
Parámetros de configuración de TPU v5p
Un pod de TPU v5p está compuesto por 8,960 chips interconectados con vínculos de alta velocidad reconfigurables. Las redes flexibles de TPU v5p te permiten conectar los chips en una porción del mismo tamaño de varias maneras. Cuando creas una porción de TPU con el comando gcloud compute tpus tpu-vm create, debes especificar su tipo y forma con los parámetros AcceleratorType o AcceleratorConfig.
En la siguiente tabla, se muestran las formas de una sola porción más comunes admitidas con v5p, además de la mayoría de las formas de cubo completas (pero no todas) mayores que 1 cubo. La forma máxima de v5p es de 16 × 16 × 24 (6,144 chips, 96 cubos).
| Forma de la porción | Tamaño de la VM | Cantidad de núcleos | # chips | Cantidad de máquinas | Cantidad de cubos | ¿Compatible con Twisted? |
| 2x2x1 | Host completo | 8 | 4 | 1 | N/A | N/A |
| 2x2x2 | Host completo | 16 | 8 | 2 | N/A | N/A |
| 2x4x4 | Host completo | 64 | 32 | 8 | N/A | N/A |
| 4 × 4 × 4 | Host completo | 128 | 64 | 16 | 1 | N/A |
| 4 × 4 × 8 | Host completo | 256 | 128 | 32 | 2 | Sí |
| 4 × 8 × 8 | Host completo | 512 | 256 | 64 | 4 | Sí |
| 8 × 8 × 8 | Host completo | 1024 | 512 | 128 | 8 | N/A |
| 8 × 8 × 16 | Host completo | 2,048 | 1024 | 256 | 16 | Sí |
| 8 × 16 × 16 | Host completo | 4,096 | 2,048 | 512 | 32 | Sí |
| 16 × 16 × 16 | Host completo | 8192 | 4,096 | 1024 | 64 | N/A |
| 16 × 16 × 24 | Host completo | 12288 | 6144 | 1,536 | 96 | N/A |
El entrenamiento de una sola porción es compatible con hasta 6,144 chips. Es extensible a 18,432 chips con Multislice. Consulta la Descripción general de Multislice de Cloud TPU para obtener detalles sobre Multislice.
Cómo usar el parámetro AcceleratorType
Cuando asignas recursos TPU, usas el argumento --accelerator-type para especificar la cantidad de TensorCores en una porción. --accelerator-type es una cadena con formato "v$VERSION_NUMBERp-$CORES_COUNT".
Por ejemplo, v5p-32 especifica una porción de TPU v5p con 32 TensorCores (16 chips).
Si deseas aprovisionar TPU para un trabajo de entrenamiento v5p, usa uno de los siguientes tipos de aceleradores en tu solicitud de creación de la CLI o API de TPU:
- v5p-8
- v5p-16
- v5p-32
- v5p-64
- v5p-128 (un cubo completo/bastidor)
- v5p-256 (2 cubos)
- v5p-512
- v5p-1024 ... v5p-12288
Usa el parámetro AcceleratorConfig
En las versiones de Cloud TPU v5p y posteriores, AcceleratorConfig se usa de la misma manera que con Cloud TPU v4. La diferencia es que, en lugar de especificar el tipo de TPU como --type=v4, debes especificarlo como la versión de TPU que estás usando (por ejemplo, --type=v5p para la versión v5p).
Resiliencia de ICI de Cloud TPU
La resiliencia a los ICI ayuda a mejorar la tolerancia a errores de los vínculos ópticos y los interruptores de circuitos ópticos (OCS) que conectan las TPU entre cubos. (Las conexiones de ICI dentro de un cubo usan eslabones de cobre que no se ven afectados). La resiliencia de ICI permite que las conexiones ICI se enruten en torno a los errores de OCS y de ICI ópticos. Como resultado, mejora la disponibilidad de programación de porciones de TPU, con la compensación de una degradación temporal en el rendimiento de ICI.
Al igual que Cloud TPU v4, la resiliencia de ICI se habilita de forma predeterminada para las porciones v5p que tienen un cubo o más:
- v5p-128 cuando se especifica el tipo de acelerador
- 4×4×4 cuando se especifica la configuración del acelerador
Propiedades de VM, host y porción
| Propiedad | Valor en una TPU |
| Cantidad de chips v5p | 4 |
| Cantidad de CPU virtuales | 208 (solo la mitad se puede usar si se usa la vinculación de NUMA para evitar la penalización de rendimiento entre NUMA) |
| RAM (GB) | 448 (solo la mitad se puede usar si se usa la vinculación de NUMA para evitar la penalización de rendimiento entre NUMA) |
| Cant. de nodos de NUMA | 2 |
| Capacidad de procesamiento de NIC (Gbps) | 200 |
Relación entre la cantidad de TensorCores, chips, hosts/VM y cubos en un Pod:
| Núcleos | Papas fritas | Hosts/VMs | Cubos | |
|---|---|---|---|---|
| Presentador | 8 | 4 | 1 | |
| Cube (también conocido como rack) | 128 | 64 | 16 | 1 |
| Porción admitida más grande | 12288 | 6144 | 1,536 | 96 |
| Pod completo de v5p | 17920 | 8960 | 2240 | 140 |
Parámetros de configuración de TPU v5e
Cloud TPU v5e es un producto combinado de entrenamiento e inferencia (entrega). Para diferenciar entre un entorno de entrenamiento y un entorno de inferencia, usa las marcas AcceleratorType o AcceleratorConfig con la API de TPU o la marca --machine-type cuando crees un grupo de nodos de GKE.
Los trabajos de entrenamiento están optimizados para la capacidad de procesamiento y la disponibilidad, mientras que los trabajos de entrega están optimizados para la latencia. Por lo tanto, un trabajo de entrenamiento en TPU aprovisionadas para la entrega podría tener una disponibilidad menor y, de manera similar, un trabajo de entrega ejecutado en TPU aprovisionadas para el entrenamiento podría tener una latencia más alta.
Usa AcceleratorType para especificar la cantidad de TensorCores que deseas usar.
Cuando crees una TPU, debes especificar el AcceleratorType con
gcloud CLI o la consola de Google Cloud. El valor que especificas para AcceleratorType es una string con el formato: v$VERSION_NUMBER-$CHIP_COUNT.
También puedes usar AcceleratorConfig para especificar la cantidad de TensorCores que deseas usar. Sin embargo, debido a que no hay variantes de topología 2D personalizadas para TPU v5e, no hay diferencia entre el uso de AcceleratorConfig y AcceleratorType.
Para configurar una TPU v5e con AcceleratorConfig, usa las marcas --version y --topology. Establece --version en la versión de TPU que deseas usar y --topology en la disposición física de los chips TPU en la porción. El valor que especificas para AcceleratorConfig es una string con el formato AxB, en el que A y B son los recuentos de chips en cada dirección.
Las siguientes formas de porciones 2D son compatibles con v5e:
| Topología | Cantidad de chips TPU | Cantidad de organizadores |
| 1x1 | 1 | 1/8 |
| 2x2 | 4 | 1/2 |
| 2x4 | 8 | 1 |
| 4x4 | 16 | 2 |
| 4x8 | 32 | 4 |
| 8x8 | 64 | 8 |
| 8x16 | 128 | 16 |
| 16x16 | 256 | 32 |
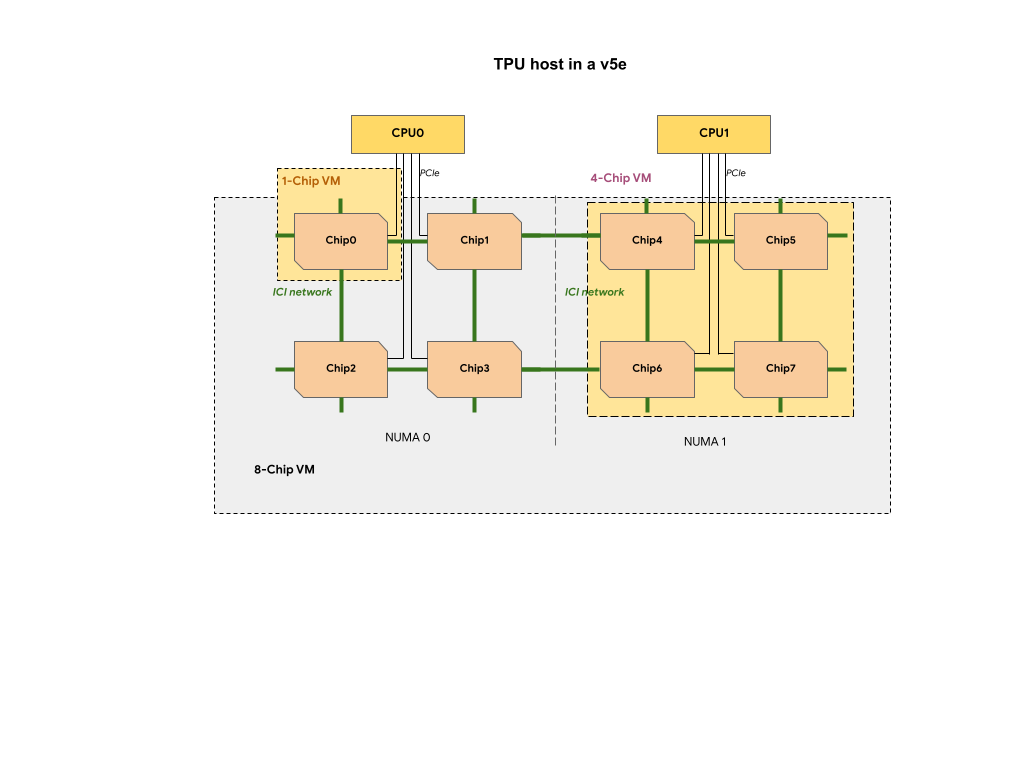
Cada VM de TPU en una porción de TPU v5e contiene 1, 4 u 8 chips. En porciones de 4 chips y más pequeñas, todos los chips TPU comparten el mismo nodo de Acceso a la memoria no uniforme (NUMA).
Para las VMs TPU v5e de 8 chips, la comunicación entre CPU y TPU será más eficiente dentro de las particiones
NUMA. Por ejemplo, en la siguiente figura, la comunicación de CPU0-Chip0 será más rápida que la comunicación de CPU0-Chip4.
Tipos de Cloud TPU v5e para entregar
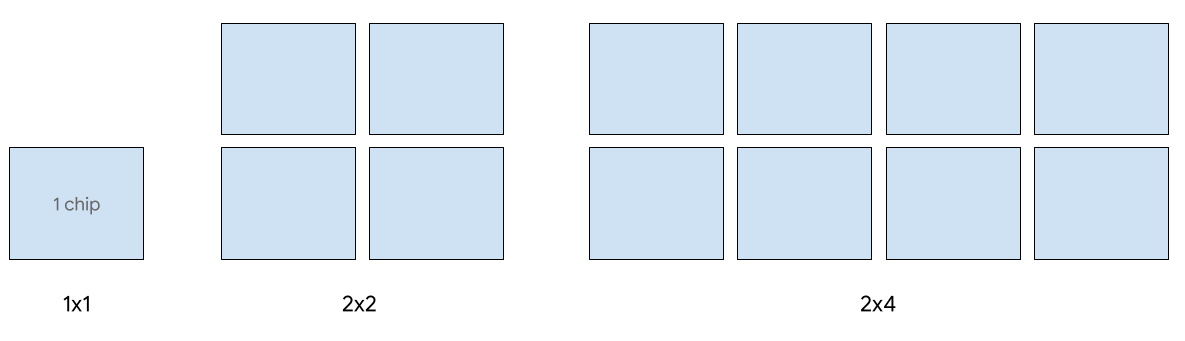
La entrega de un solo host es compatible con hasta 8 chips v5e. Se admiten las siguientes configuraciones: porciones de 1 x 1, 2 x 2 y 2 x 4. Cada porción tiene 1, 4 y 8 chips, respectivamente.
Si deseas aprovisionar TPU para un trabajo de entrega, usa uno de los siguientes tipos de aceleradores en la solicitud de creación de TPU de la CLI o API:
| AcceleratorType (API de TPU) | Tipo de máquina (API de GKE) |
|---|---|
v5litepod-1 |
ct5lp-hightpu-1t |
v5litepod-4 |
ct5lp-hightpu-4t |
v5litepod-8 |
ct5lp-hightpu-8t |
La entrega en más de 8 chips v5e, también llamada entrega de varios hosts, es compatible con Sax. Para obtener más información, consulta Entrega de modelos grandes de lenguaje.
Tipos de Cloud TPU v5e para el entrenamiento
El entrenamiento es compatible con un máximo de 256 chips.
Si deseas aprovisionar TPU para un trabajo de entrenamiento v5e, usa uno de los siguientes tipos de aceleradores en tu solicitud de creación de TPU de la CLI o API:
| AcceleratorType (API de TPU) | Tipo de máquina (API de GKE) | Topología |
|---|---|---|
v5litepod-16 |
ct5lp-hightpu-4t |
4x4 |
v5litepod-32 |
ct5lp-hightpu-4t |
4x8 |
v5litepod-64 |
ct5lp-hightpu-4t |
8x8 |
v5litepod-128 |
ct5lp-hightpu-4t |
8x16 |
v5litepod-256 |
ct5lp-hightpu-4t |
16x16 |
Comparación de tipos de VM de TPU v5e:
| Tipo de VM | n2d-48-24-v5lite-tpu | n2d-192-112-v5lite-tpu | n2d-384-224-v5lite-tpu |
| Cantidad de chips v5e | 1 | 4 | 8 |
| Cantidad de CPU virtuales | 24 | 112 | 224 |
| RAM (GB) | 48 | 192 | 384 |
| Cant. de nodos de NUMA | 1 | 1 | 2 |
| Se aplica a | v5litepod-1 | v5litepod-4 | V5litepod-8 |
| Interrupción | Alta | Media | Baja |
A fin de liberar espacio para las cargas de trabajo que requieren más chips, los programadores pueden interrumpir las VM con menos chips. Por lo tanto, es probable que las VMs de 8 chips interrumpan a las VMs de 1 y 4 chips.
Parámetros de configuración de TPU v4
Un pod de TPU v4 consta de 4,096 chips interconectados con vínculos de alta velocidad reconfigurables. Las redes flexibles de TPU v4 te permiten conectar los chips en una porción de Pod del mismo tamaño de varias maneras. Cuando creas una porción de pod de TPU, debes especificar la versión de TPU y la cantidad de recursos de TPU que necesitas. Cuando creas una porción de pod de TPU v4, puedes especificar su tipo y tamaño de una de estas dos maneras: AcceleratorType y AcceleratorConfig.
Usa AcceleratorType
Usa AcceleratorType cuando no especifiques una topología. Para configurar las TPU v4 con AcceleratorType, usa la marca --accelerator-type cuando crees tu porción de pod de TPU. Configura --accelerator-type en una string que contenga la versión de TPU y la cantidad de TensorCores que deseas usar. Por ejemplo, para crear una porción de pod v4 con 32 TensorCores, usarías --accelerator-type=v4-32.
Con el siguiente comando, se crea una porción de pod de TPU v4 con 512 TensorCores mediante la marca --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v4-512
--version=tpu-vm-tf-2.16.1-pod-pjrt
El número después de la versión de TPU (v4) especifica la cantidad de TensorCores.
Hay dos TensorCores en una TPU v4, por lo que la cantidad de chips TPU sería 512/2 = 256.
Usa AcceleratorConfig
Usa AcceleratorConfig cuando desees personalizar la topología física de la porción de TPU. Por lo general, esto es necesario para el ajuste de rendimiento con porciones de pod de más de 256 chips.
Para configurar las TPU v4 con AcceleratorConfig, usa las marcas --version y --topology. Establece --version en la versión de TPU que deseas usar y --topology en la disposición física de los chips TPU en la porción de Pod.
Debes especificar una topología de TPU con una tupla de 3, AxBxC, en la que A<=B<=C y A, B, C son todos <= 4 o todos son múltiplos enteros de 4. Los valores A, B y C son los recuentos de chips en cada una de las tres dimensiones. Por ejemplo, para crear una porción de Pod v4 con 16 chips, debes configurar --version=v4 y --topology=2x2x4.
El siguiente comando crea una porción de pod de TPU v4 con 128 chips TPU organizados en un arreglo de 4 x 4 x 8:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--type=v4
--topology=4x4x8
--version=tpu-vm-tf-2.16.1-pod-pjrt
Topologías en las que 2A=B=C o 2A=2B=C también tienen variantes de topología optimizadas para la comunicación de todo a todos, por ejemplo, 4 × 4 × 8, 8 × 8 × 16 y 12 × 12 × 24. Estas topologías se conocen como topologías torilas retorcidas.
En las siguientes ilustraciones, se muestran algunas topologías comunes de TPU v4.
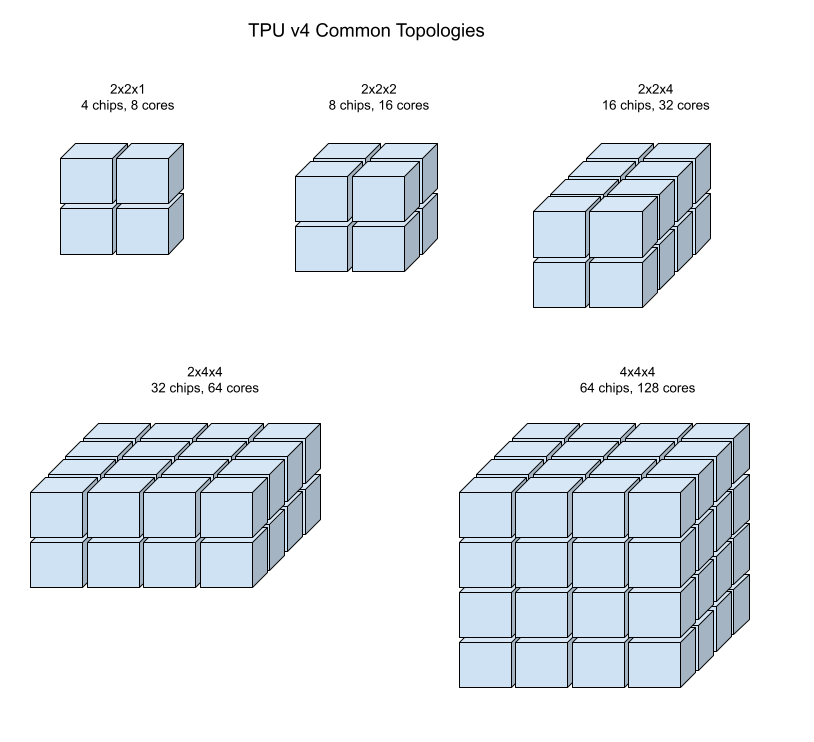
Las porciones de Pod más grandes se pueden compilar a partir de uno o más “cubos” de 4×4×4 de chips.
Topologías de Tori trenzado
Algunas formas de porciones de torus 3D v4 tienen la opción de usar lo que se conoce como una topología de torus trenzado. Por ejemplo, se pueden organizar dos cubos v4 como una porción de 4x4x8 o 4x4x8_twisted. Las topologías trenzadas ofrecen un ancho de banda de bisección significativamente mayor. Un mayor ancho de banda de bisección es útil para cargas de trabajo que usan patrones de comunicación globales. Las topologías retorcidas pueden mejorar el rendimiento para la mayoría de los modelos, y las grandes cargas de trabajo de incorporación de TPU son las que más se benefician.
En el caso de las cargas de trabajo que usan el paralelismo de datos como la única estrategia de paralelismo, las topologías retorcidas pueden tener un rendimiento un poco mejor. Para los LLM, el rendimiento con una topología retorcida puede variar según el tipo de paralelismo (DP, MP, etcétera). La práctica recomendada es entrenar tu LLM con y sin una topología retorcida para determinar cuál le proporciona el mejor rendimiento a tu modelo. Algunos experimentos en el modelo MaxText para FSDP experimentaron 1 o 2 mejoras de MFU mediante una topología retorcida.
El beneficio principal de las topologías trenzadas es que transforman una topología de torus asimétrica (por ejemplo, 4 × 4 × 8) en una topología simétrica estrechamente relacionada. La topología simétrica tiene muchos beneficios:
- Balanceo de cargas mejorado
- Mayor ancho de banda de bisección
- Rutas de paquetes más cortas
En última instancia, estos beneficios se traducen en un mejor rendimiento para muchos patrones de comunicación globales.
El software de la TPU admite tori trenzado en porciones en las que el tamaño de cada dimensión es igual o dos veces el tamaño de la dimensión más pequeña. Por ejemplo, 4 × 4 × 8, 4 × 8 × 8 o 12 × 12 × 24.
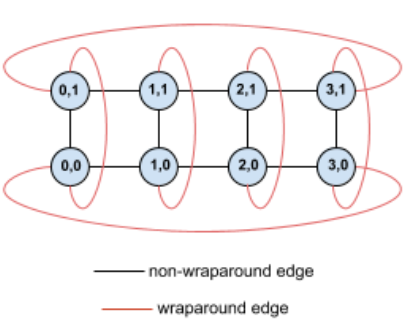
Como ejemplo, considera esta topología de torus de 4 × 2 con TPU etiquetadas con sus coordenadas (X,Y) en la porción:
Para mayor claridad, los bordes de este gráfico de topología se muestran como bordes no dirigidos. En la práctica, cada perímetro es una conexión bidireccional entre las TPU. Nos referimos a los bordes entre un lado de esta cuadrícula y el lado opuesto como bordes envolventes, como se indica en el diagrama.
Cuando se torce esta topología, obtenemos una topología de torus trenzado de 4 × 2 completamente simétrica:
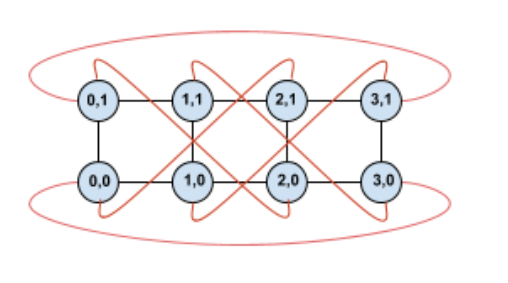
Todo lo que cambió entre este diagrama y el anterior son los bordes envolventes Y. En lugar de conectarse a otra TPU con la misma coordenada X, se cambiaron para conectarse a la TPU con la coordenada X+2 mod 4.
La misma idea se generaliza a diferentes tamaños de dimensión y diferentes cantidades de dimensiones. La red resultante será simétrica, siempre que cada dimensión sea igual o dos veces el tamaño de la dimensión más pequeña.
En la siguiente tabla, se muestran las topologías trenzadas admitidas y un aumento teórico en el ancho de banda de bisección con ellas en comparación con las topologías no retorcidas.
| Topología trenzada | Aumento teórico del ancho de banda de bisección en comparación con un torus no trenzado |
|---|---|
| 4×4×8_twisted | Aprox. un 70% |
| 8 x 8 x 16_trezado | |
| 12×12×24_twisted | |
| 4×8×8_twisted | Aprox. un 40% |
| 8 × 16 × 16_twist |
Variantes de topología de TPU v4
Algunas topologías que contienen la misma cantidad de chips se pueden organizar de diferentes maneras. Por ejemplo, una porción de pod de TPU con 512 chips (1, 024 TensorCores) se puede configurar mediante las siguientes topologías: 4 × 4 × 32, 4 × 8 × 16 y 8 × 8 × 8. Una porción de pod de TPU con 2,048 chips (4,096 TensorCores) ofrece aún más opciones de topología: 4 × 4 × 128, 4 × 8 × 64, 4 × 16 × 32 y 8 × 16 × 16. Una porción de pod de TPU con 2,048 chips (4,096 TensorCores) ofrece aún más opciones de topología: 4 × 4 × 128, 4 × 8 × 64, 4 × 16 × 32 y 8 × 16 × 16.
La topología predeterminada asociada con un recuento de chips determinado es la más similar a un cubo (consulta Topología de la versión 4). Es probable que esta forma sea la mejor opción para el entrenamiento del AA con datos paralelos. Otras topologías pueden ser útiles para cargas de trabajo con varios tipos de paralelismo (por ejemplo, paralelismo de modelos y datos o partición espacial de una simulación). Estas cargas de trabajo tienen un mejor rendimiento si la topología coincide con el paralelismo utilizado. Por ejemplo, ubicar el paralelismo de modelos de 4 vías en la dimensión X y el paralelismo de datos de 256 vías en las dimensiones Y y Z coincide con una topología de 4 × 16 × 16.
Los modelos con varias dimensiones de paralelismo tienen un mejor rendimiento cuando las dimensiones de paralelismo se asignan a las dimensiones de topología de TPU. Por lo general, son modelos grandes de lenguaje (LLM) paralelos de datos y modelos. Por ejemplo, para una porción de pod de TPU v4 con una topología de 8 × 16 × 16, las dimensiones de topología de TPU son 8, 16 y 16. Es más eficaz usar paralelismo de modelos de 8 o 16 vías (asignado a una de las dimensiones de la topología de TPU física). Un paralelismo de modelos de 4 vías sería subóptimo con esta topología, ya que no está alineada con ninguna de las dimensiones de topología de TPU, pero sería óptimo con una topología de 4 × 16 × 32 en la misma cantidad de chips.
Las configuraciones de TPU v4 constan de dos grupos: los que tienen topologías de menos de 64 chips (topologías pequeñas) y los que tienen más de 64 chips (topologías grandes).
Topologías v4 pequeñas
Cloud TPU es compatible con las siguientes porciones de pod de TPU v4 más pequeñas que 64 chips, un cubo 4x4x4. Puedes crear estas topologías v4 pequeñas con su nombre basado en TensorCore (por ejemplo, v4-32) o su topología (por ejemplo, 2x2x4):
| Nombre (según la cantidad de TensorCore) | Cantidad de chips | Topología |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologías v4 grandes
Las porciones de pod de TPU v4 están disponibles en incrementos de 64 chips, con formas que son múltiplos de 4 en las tres dimensiones. Las dimensiones también deben estar en orden creciente. En la siguiente tabla, se muestran varios ejemplos. Algunas de estas topologías son topologías “personalizadas” que solo se pueden crear con las marcas --type y --topology porque hay más de una manera de organizar los chips.
El siguiente comando crea una porción de pod de TPU v4 con 512 chips TPU organizados en un arreglo de 8 x 8 x 8:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--type=v4
--topology=8x8x8
--version=tpu-vm-tf-2.16.1-pod-pjrt
Puedes crear una porción de pod de TPU v4 con la misma cantidad de TensorCores mediante --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v4-1024
--version=tpu-vm-tf-2.16.1-pod-pjrt
| Nombre (según la cantidad de TensorCore) | Cantidad de chips | Topología |
| v4-128 | 64 | 4 × 4 × 4 |
| v4-256 | 128 | 4 × 4 × 8 |
| v4-512 | 256 | 4 × 8 × 8 |
N/A: Debes usar las marcas --type y --topology. |
256 | 4 × 4 × 16 |
| v4-1024 | 512 | 8 × 8 × 8 |
| v4-1536 | 768 | 8 × 8 × 12 |
| v4-2048 | 1024 | 8 × 8 × 16 |
N/A: Debes usar las marcas --type y --topology |
1024 | 4x16x16 |
| v4-4096 | 2,048 | 8 × 16 × 16 |
| … | … | … |
Parámetros de configuración de TPU v3
Un pod de TPU v3 consta de 1,024 chips interconectados con vínculos de alta velocidad. Si quieres crear un dispositivo de TPU v3 o una porción de pod, usa la marca --accelerator-type para el comando gcloud compute tpus tpu-vm. Para especificar el tipo de acelerador, especifica la versión de TPU y la cantidad de núcleos de TPU. Para una sola TPU v3, usa --accelerator-type=v3-8. Para una porción de pod v3 con 128 TensorCores, usa --accelerator-type=v3-128.
En el siguiente comando, se muestra cómo crear una porción de pod de TPU v3 con 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v3-128
--version=tpu-vm-tf-2.16.1-pjrt
En la siguiente tabla, se enumeran los tipos de TPU v3 compatibles:
| Versión de TPU | Finalización de compatibilidad |
|---|---|
| v3-8 | (Fecha de finalización aún no establecida) |
| v3-32 | (Fecha de finalización aún no establecida) |
| v3-128 | (Fecha de finalización aún no establecida) |
| v3-256 | (Fecha de finalización aún no establecida) |
| v3-512 | (Fecha de finalización aún no establecida) |
| v3-1024 | (Fecha de finalización aún no establecida) |
| v3-2048 | (Fecha de finalización aún no establecida) |
Para obtener más información sobre cómo administrar las TPU, consulta Administra las TPU. Para obtener más información sobre las diferentes versiones de Cloud TPU, consulta Arquitectura del sistema.
Parámetros de configuración de TPU v2
Un pod de TPU v2 está compuesto por 512 chips interconectados con vínculos de alta velocidad reconfigurables. Si quieres crear una porción de pod de TPU v2, usa la marca --accelerator-type para el comando gcloud compute tpus tpu-vm. Para especificar el tipo de acelerador, especifica la versión de TPU y la cantidad de núcleos de TPU. Para una sola TPU v2, usa --accelerator-type=v2-8. Para una porción de pod v2 con 128 TensorCores, usa --accelerator-type=v2-128.
En el siguiente comando, se muestra cómo crear una porción de pod de TPU v2 con 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v2-128
--version=tpu-vm-tf-2.16.1-pjrt
Para obtener más información sobre cómo administrar las TPU, consulta Administra las TPU. Para obtener más información sobre las diferentes versiones de Cloud TPU, consulta Arquitectura del sistema.
En la siguiente tabla, se enumeran los tipos de TPU v2 compatibles
| Versión de TPU | Finalización de compatibilidad |
|---|---|
| v2-8 | (Fecha de finalización aún no establecida) |
| v2-32 | (Fecha de finalización aún no establecida) |
| v2-128 | (Fecha de finalización aún no establecida) |
| v2-256 | (Fecha de finalización aún no establecida) |
| v2-512 | (Fecha de finalización aún no establecida) |
Compatibilidad con tipos de TPU
Puedes cambiar el tipo de TPU a otro tipo de TPU que tenga la misma cantidad de TensorCores o chips (por ejemplo, v3-128 y v4-128) y ejecutar la secuencia de comandos de entrenamiento sin cambios en el código. Sin embargo, si cambias a un tipo de TPU con un número de TensorCores mayor o menor, deberás realizar un ajuste y optimización significativos. Para obtener más información, consulta Entrenamiento en pods de TPU.
Versiones de software de VM de TPU
En esta sección, se describen las versiones de software de TPU que debes usar para una TPU con la arquitectura de VM de TPU. Para conocer la arquitectura del nodo TPU, consulta Versiones de software del nodo TPU.
Las versiones de software de TPU están disponibles para los frameworks de TensorFlow, PyTorch y JAX.
TensorFlow
Usa la versión de software de TPU que coincida con la versión de TensorFlow con la que se escribió tu modelo.
A partir de TensorFlow 2.15.0, también debes especificar el entorno de ejecución del ejecutor de transmisión (SE) o el de PJRT. Por ejemplo, si usas TensorFlow 2.16.1 con el entorno de ejecución de PJRT, usa la versión de software de la TPU tpu-vm-tf-2.16.1-pjrt. Las versiones anteriores a TensorFlow 2.15.0 solo admiten el ejecutor de transmisión. Para obtener más información sobre PJRT, consulta Compatibilidad con PJRT de TensorFlow.
Estas son las versiones de software de VM de TPU de TensorFlow compatibles actuales:
- tpu-vm-tf-2.16.1-pjrt
- tpu-vm-tf-2.16.1-se
- tpu-vm-tf-2.15.0-pjrt
- tpu-vm-tf-2.15.0-se
- tpu-vm-tf-2.14.1
- tpu-vm-tf-2.14.0
- tpu-vm-tf-2.13.1
- tpu-vm-tf-2.13.0
- tpu-vm-tf-2.12.1
- tpu-vm-tf-2.12.0
- tpu-vm-tf-2.11.1
- tpu-vm-tf-2.11.0
- tpu-vm-tf-2.10.1
- tpu-vm-tf-2.10.0
- tpu-vm-tf-2.9.3
- tpu-vm-tf-2.9.1
- tpu-vm-tf-2.8.4
- tpu-vm-tf-2.8.3
- tpu-vm-tf-2.8.0
- tpu-vm-tf-2.7.4
- tpu-vm-tf-2.7.3
Para obtener más información sobre las versiones de parche de TensorFlow, consulta Versiones de parche de TensorFlow compatibles.
Compatibilidad con TensorFlow PJRT
A partir de TensorFlow 2.15.0, puedes usar la interfaz PJRT para TensorFlow en TPU. PJRT incluye desfragmentación automática de la memoria del dispositivo y simplifica la integración del hardware con frameworks. Si deseas obtener más información sobre PJRT, consulta PJRT: Simplificación de la integración del hardware y el framework del AA en el blog de código abierto de Google.
No todas las funciones de TPU v2, v3 y v4 se migraron al entorno de ejecución de PJRT. En la siguiente tabla, se describe qué funciones son compatibles con PJRT o el ejecutor de vapor.
| Acelerador | Atributo | Compatible con PJRT | Ejecutor de transmisión compatible |
|---|---|---|---|
| TPU v2-v4 | Procesamiento denso (sin API de incorporación de TPU) | Sí | Sí |
| TPU v2-v4 | API de procesamiento densa + API de incorporación de TPU | No. | Sí |
| TPU v2-v4 | tf.summary/tf.print con la colocación de dispositivos blandos |
No. | Sí |
| TPU v5e | Procesamiento denso (sin API de incorporación de TPU) | Sí | No. |
| TPU v5e | API de incorporación de TPU | N/A: TPU v5e no es compatible con la API de incorporación de TPU | N/A |
| TPU v5p | Procesamiento denso (sin API de incorporación de TPU) | Sí | No. |
| TPU v5p | API de incorporación de TPU | Sí | No. |
TPU v4 con TensorFlow 2.10.0 y versiones anteriores
Si entrenas un modelo en TPU v4 con TensorFlow, las versiones de TensorFlow 2.10.0 y anteriores usan versiones específicas de v4 que se muestran en la siguiente tabla. Si la versión de TensorFlow que estás usando no aparece en la tabla, sigue las instrucciones en la sección de TensorFlow.
| Versión de TensorFlow | Versión de software de TPU |
|---|---|
| 2.10.0 | tpu-vm-tf-2.10.0-v4, tpu-vm-tf-2.10.0-pod-v4 |
| 2.9.3 | tpu-vm-tf-2.9.3-v4, tpu-vm-tf-2.9.3-pod-v4 |
| 2.9.2 | tpu-vm-tf-2.9.2-v4, tpu-vm-tf-2.9.2-pod-v4 |
| 2.9.1 | tpu-vm-tf-2.9.1-v4, tpu-vm-tf-2.9.1-pod-v4 |
Versiones de Libtpu
Las VM de TPU se crean con TensorFlow y la biblioteca Libtpu correspondiente preinstalada. Si creas tu propia imagen de VM, especifica las siguientes versiones de software de TPU de TensorFlow y las versiones de libtpu correspondientes:
| Versión de TensorFlow | Versión de libtpu.so |
|---|---|
| 2.16.1 | 1.10.1 |
| 2.15.0 | 1.9.0 |
| 2.14.1 | 1.8.1 |
| 2.14.0 | 1.8.0 |
| 2.13.1 | 1.7.1 |
| 2.13.0 | 1.7.0 |
| 2.12.1 | 1.6.1 |
| 2.12.0 | 1.6.0 |
| 2.11.1 | 1.5.1 |
| 2.11.0 | 1.5.0 |
| 2.10.1 | 1.4.1 |
| 2.10.0 | 1.4.0 |
| 2.9.3 | 1.3.2 |
| 2.9.1 | 1.3.0 |
| 2.8.3 | 1.2.3 |
| 2.8.* | 1.2.0 |
| 2.7.3 | 1.1.2 |
PyTorch
Usa la versión de software de TPU que coincida con la versión de PyTorch con la que se escribió el modelo. Por ejemplo, si usas PyTorch 1.13 y TPU v2 o v3, usa la versión de software de TPU tpu-vm-pt-1.13. Si usas TPU v4, usa la versión de software de TPU tpu-vm-v4-pt-1.13. Se usa la misma versión de software de TPU para los pods de TPU (por ejemplo, v2-32, v3-128 y v4-32). Las versiones actuales del software de TPU compatibles son las siguientes:
TPU v2 y v3:
- tpu-vm-pt-2.0 (pytorch-2.0)
- tpu-vm-pt-1.13 (pytorch-1.13)
- tpu-vm-pt-1.12 (pytorch-1.12)
- tpu-vm-pt-1.11 (pytorch-1.11)
- tpu-vm-pt-1.10 (pytorch-1.10)
- v2-alpha (pytorch-1.8.1)
TPU v4:
- tpu-vm-v4-pt-2.0 (pytorch-2.0)
- tpu-vm-v4-pt-1.13 (pytorch-1.13)
TPU v5 (v5e y v5p):
- v2-alpha-tpuv5 (pytorch-2.0)
Cuando creas una VM de TPU, la versión más reciente de PyTorch está preinstalada en la VM de TPU. La versión correcta de libtpu.so se instala automáticamente cuando instalas PyTorch.
Para cambiar la versión actual del software de PyTorch, consulta Cambia la versión de PyTorch.
JAX
Debes instalar JAX de forma manual en tu VM de TPU. No existe una versión de software (entorno de ejecución) de TPU específica de JAX para TPU v2 y v3. Para las versiones posteriores de TPU, usa las siguientes versiones de software:
- TPU v4: tpu-vm-v4-base
- TPU v5e: v2-alpha-tpuv5
- TPU v5p: v2-alpha-tpuv5
La versión correcta de libtpu.so se instala automáticamente cuando instalas JAX.
Versiones de software del nodo TPU
En esta sección, se describen las versiones de software de TPU que debes usar para una TPU con la arquitectura de nodo TPU. Para la arquitectura de la VM de TPU, consulta Versiones de software de VM de TPU.
Las versiones de software de TPU están disponibles para los frameworks de TensorFlow, PyTorch y JAX.
TensorFlow
Usa la versión de software de TPU que coincida con la versión de TensorFlow con la que se escribió tu modelo. Por ejemplo, si usas TensorFlow 2.12.0, usa la versión de software de TPU 2.12.0. Estas son las versiones de software de TPU específicas de TensorFlow:
- 2.12.1
- 2.12.0
- 2.11.1
- 2.11.0
- 2.10.1
- 2.10.0
- 2.9.3
- 2.9.1
- 2.8.4
- 2.8.2
- 2.7.3
Para obtener más información sobre las versiones de parche de TensorFlow, consulta Versiones de parche de TensorFlow compatibles.
Cuando creas un nodo TPU, la versión más reciente de TensorFlow está preinstalada en el nodo TPU.
PyTorch
Usa la versión de software de TPU que coincida con la versión de PyTorch con la que se escribió el modelo. Por ejemplo, si usas PyTorch 1.9, utiliza la versión de software pytorch-1.9.
Las versiones de software de TPU específicas de PyTorch son las siguientes:
- pytorch-2.0
- pytorch-1.13
- pytorch-1.12
- pytorch-1.11
- pytorch-1.10
- pytorch-1.9
- pytorch-1.8
- pytorch-1.7
pytorch-1.6
pytorch-nightly
Cuando creas un nodo TPU, la versión más reciente de PyTorch está preinstalada en el nodo TPU.
JAX
Debes instalar JAX de forma manual en la VM de TPU, por lo que no hay una versión de software de TPU específica de JAX preinstalada. Puedes usar cualquiera de las versiones de software que se mencionan para TensorFlow.
¿Qué sigue?
- Obtén más información sobre la arquitectura de TPU en la página Arquitectura del sistema.
- Consulta Cuándo usar las TPU para obtener información sobre los tipos de modelos que funcionan con Cloud TPU.