Configurations TPU
Configurations de TPU v5p
Un pod TPU v5p est composé de 8 960 puces interconnectées avec des liaisons à haut débit reconfigurables. La mise en réseau flexible de TPU v5p vous permet de connecter les puces d'une tranche de même taille de plusieurs manières. Lorsque vous créez une tranche TPU à l'aide de la commande gcloud compute tpus tpu-vm create, vous spécifiez son type et sa forme à l'aide des paramètres AcceleratorType ou AcceleratorConfig.
Le tableau suivant présente les formes à tranche unique les plus courantes compatibles avec v5p, ainsi que la plupart (mais pas la totalité) des formes de cube complet supérieures à un cube. La forme v5p maximale est de 16 x 16 x 24 (6 144 chips, 96 cubes).
| Forme des tranches | Taille de la VM | # cœurs | # chips | Nombre de machines | Nombre de cubes | Compatible avec Twisted ? |
| 2x2x1 | Hôte complet | 8 | 4 | 1 | Non disponible | Non disponible |
| 2x2x2 | Hôte complet | 16 | 8 | 2 | Non disponible | Non disponible |
| 2x4x4 | Hôte complet | 64 | 32 | 8 | Non disponible | Non disponible |
| 4x4x4 | Hôte complet | 128 | 64 | 16 | 1 | Non disponible |
| 4x4x8 | Hôte complet | 256 | 128 | 32 | 2 | Oui |
| 4x8x8 | Hôte complet | 512 | 256 | 64 | 4 | Oui |
| 8x8x8 | Hôte complet | 1 024 | 512 | 128 | 8 | Non disponible |
| 8x8x16 | Hôte complet | 2 048 | 1 024 | 256 | 16 | Oui |
| 8x16x16 | Hôte complet | 4 096 | 2 048 | 512 | 32 | Oui |
| 16x16x16 | Hôte complet | 8 192 | 4 096 | 1 024 | 64 | Non disponible |
| 16x16x24 | Hôte complet | 12 288 | 6144 | 1536 | 96 | Non disponible |
L'entraînement sur une seule tranche est compatible avec un maximum de 6 144 chips. Il est extensible jusqu'à 18 432 chips à l'aide de la fonctionnalité Multislice. Pour en savoir plus sur les multitranches, consultez la présentation de Cloud TPU en multitranche.
Utiliser le paramètre AcceleratorType
Lorsque vous allouez des ressources TPU, vous spécifiez le nombre de TensorCore dans une tranche à l'aide de l'argument --accelerator-type. --accelerator-type est une chaîne formatée "v$VERSION_NUMBERp-$CORES_COUNT".
Par exemple, v5p-32 spécifie une tranche TPU v5p comportant 32 TensorCore (16 puces).
Afin de provisionner des TPU pour une tâche d'entraînement v5p, utilisez l'un des types d'accélérateurs suivants dans votre CLI ou votre requête de création d'API TPU:
- V5P-8
- V5P-16
- V5P-32
- V5P-64
- v5p-128 (un cube/rack complet)
- v5p-256 (2 cubes)
- V5P-512
- v5p-1024 ... v5p-12288
Utiliser le paramètre AcceleratorConfig
Pour les versions v5p et ultérieures de Cloud TPU, AcceleratorConfig est utilisé de la même manière qu'avec Cloud TPU v4. La différence est qu'au lieu de spécifier le type de TPU sur --type=v4, vous le spécifiez en tant que version de TPU que vous utilisez (par exemple, --type=v5p pour la version v5p).
Résilience ICI Cloud TPU
La résilience ICI aide à améliorer la tolérance aux pannes des liaisons optiques et des commutateurs de circuit optique (OCS) qui connectent des TPU entre des cubes. (Les connexions ICI à l'intérieur d'un cube utilisent des maillons en cuivre qui ne sont pas affectés.) La résilience ICI permet aux connexions ICI d'être acheminées autour des défaillances OCS et optiques ICI. Par conséquent, il améliore la disponibilité de la planification des tranches de TPU, en contrepartie d'une dégradation temporaire des performances d'ICI.
Comme pour Cloud TPU v4, la résilience ICI est activée par défaut pour les tranches v5p d'un cube ou plus:
- v5p-128 lors de la spécification du type d'accélérateur
- 4 x 4 x 4 lors de la spécification de la configuration de l'accélérateur
Propriétés de VM, d'hôte et de tranche
| Propriété | Valeur dans un TPU |
| Nombre de chips v5p | 4 |
| Nombre de vCPU | 208 (seule la moitié est utilisable si vous utilisez la liaison NUMA pour éviter une pénalité de performances entre NUMA) |
| RAM (Go) | 448 (seule la moitié est utilisable si vous utilisez la liaison NUMA pour éviter une pénalité de performances entre NUMA) |
| Nombre de nœuds NUMA | 2 |
| Débit de la carte d'interface réseau (Gbit/s) | 200 |
Relation entre le nombre de TensorCore, de puces, d'hôtes/VM et de cubes dans un pod:
| Cœurs | Microprocesseurs | Hôtes/VM | Cubes | |
|---|---|---|---|---|
| Organisateur | 8 | 4 | 1 | |
| Cube | 128 | 64 | 16 | 1 |
| Plus grande tranche compatible | 12 288 | 6144 | 1536 | 96 |
| Pod v5p complet | 17920 | 8960 | 2240 | 140 |
Configurations TPU v5e
Cloud TPU v5e est un produit combiné d'entraînement et d'inférence (inférence). Pour faire la différence entre un environnement d'entraînement et d'inférence, utilisez les options AcceleratorType ou AcceleratorConfig avec l'API TPU, ou l'option --machine-type lors de la création d'un pool de nœuds GKE.
Les tâches d'entraînement sont optimisées pour le débit et la disponibilité, tandis que les tâches de diffusion sont optimisées pour la latence. Ainsi, une tâche d'entraînement exécutée sur des TPU provisionnés pour la diffusion peut présenter une disponibilité inférieure et, de même, une tâche de diffusion exécutée sur des TPU provisionnés pour l'entraînement peut présenter une latence plus élevée.
AcceleratorType vous permet de spécifier le nombre de TensorCores que vous souhaitez utiliser.
Vous spécifiez le paramètre AcceleratorType lors de la création d'un TPU à l'aide de gcloud CLI ou de la console Google Cloud. La valeur que vous spécifiez pour AcceleratorType est une chaîne au format suivant : v$VERSION_NUMBER-$CHIP_COUNT.
Vous pouvez également utiliser AcceleratorConfig pour spécifier le nombre de TensorCores que vous souhaitez utiliser. Toutefois, comme il n'existe pas de variantes de topologie 2D personnalisées pour TPU v5e, il n'existe aucune différence entre l'utilisation de AcceleratorConfig et de AcceleratorType.
Pour configurer un TPU v5e à l'aide de AcceleratorConfig, utilisez les options --version et --topology. Définissez --version sur la version de TPU que vous souhaitez utiliser et --topology sur la disposition physique des puces TPU dans la tranche. La valeur que vous spécifiez pour AcceleratorConfig est une chaîne au format AxB, où A et B correspondent au nombre de chips dans chaque direction.
Les formes de tranche 2D suivantes sont compatibles avec la version 5e:
| Topology | Nombre de puces TPU | Nombre d'hôtes |
| 1x1 | 1 | 1/8 |
| 2x2 | 4 | 1/2 |
| 2x4 | 8 | 1 |
| 4x4 | 16 | 2 |
| 4x8 | 32 | 4 |
| 8x8 | 64 | 8 |
| 8x16 | 128 | 16 |
| 16x16 | 256 | 32 |
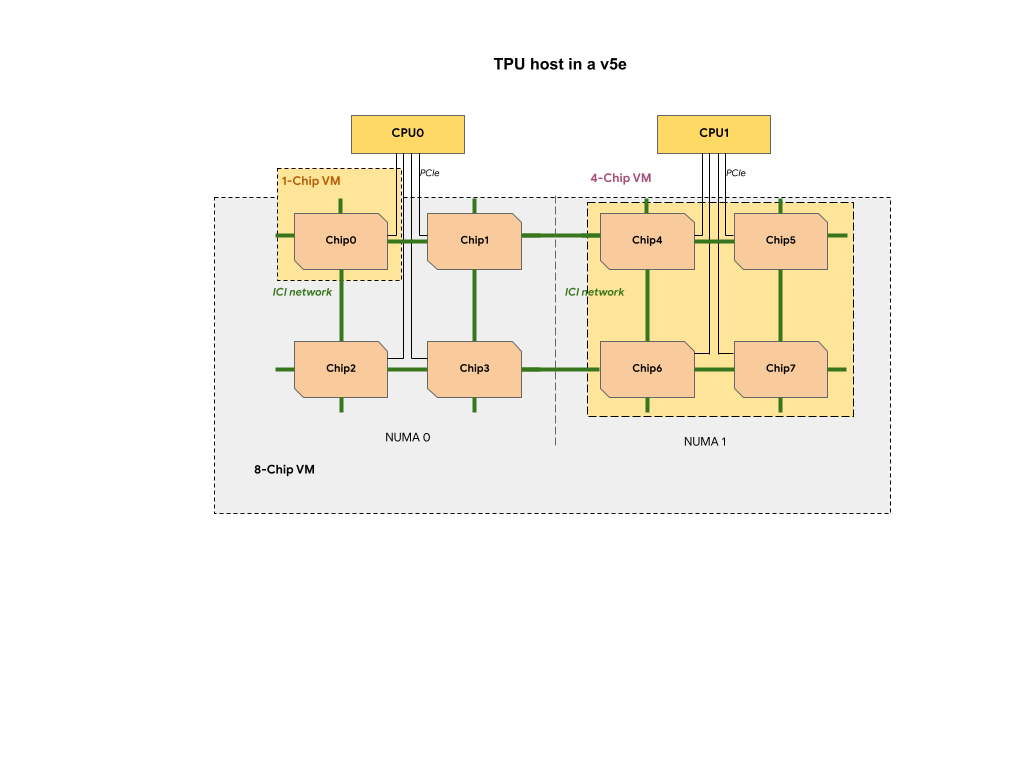
Chaque VM TPU d'une tranche TPU v5e contient une, quatre ou huit puces. Dans des tranches à quatre puces ou plus petites, toutes les puces TPU partagent le même nœud NUMA (Non Uniform Memory Access).
Pour les VM TPU v5e à 8 puces, la communication CPU-TPU est plus efficace au sein des partitions NUMA. Par exemple, dans la figure suivante, la communication avec CPU0-Chip0 est plus rapide que la communication avec CPU0-Chip4.
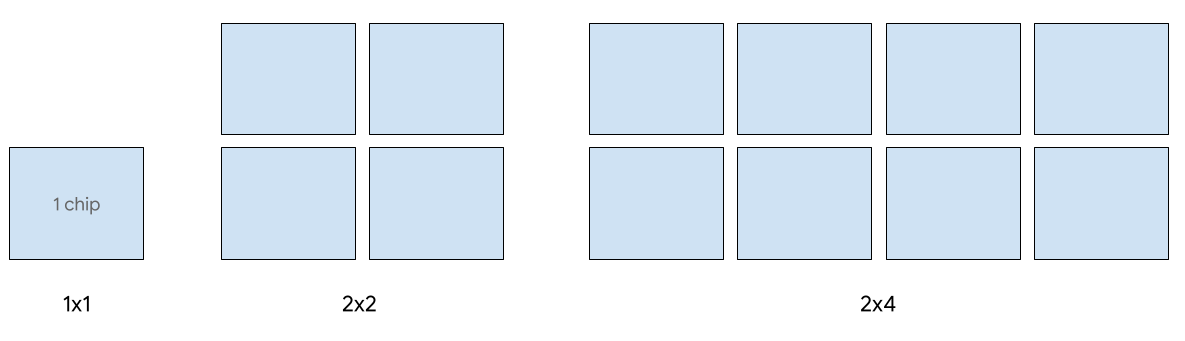
Types Cloud TPU v5e pour la diffusion
La diffusion à hôte unique est compatible avec jusqu'à huit puces v5e. Les configurations suivantes sont compatibles: tranches 1 x 1, 2 x 2 et 2 x 4. Chaque tranche comporte respectivement 1, 4 et 8 chips.
Pour provisionner des TPU pour une tâche de diffusion, utilisez l'un des types d'accélérateurs suivants dans votre requête de création de TPU de CLI ou d'API:
| AcceleratorType (API TPU) | Type de machine (API GKE) |
|---|---|
v5litepod-1 |
ct5lp-hightpu-1t |
v5litepod-4 |
ct5lp-hightpu-4t |
v5litepod-8 |
ct5lp-hightpu-8t |
La diffusion sur plus de huit puces v5e, également appelée diffusion multi-hôte, est compatible avec Sax. Pour en savoir plus, consultez la page Diffusion du grand modèle de langage.
Types Cloud TPU v5e pour l'entraînement
L'entraînement est pris en charge pour un maximum de 256 chips.
Afin de provisionner des TPU pour une tâche d'entraînement v5e, utilisez l'un des types d'accélérateurs suivants dans votre requête de création de TPU de CLI ou d'API:
| AcceleratorType (API TPU) | Type de machine (API GKE) | Topology |
|---|---|---|
v5litepod-16 |
ct5lp-hightpu-4t |
4x4 |
v5litepod-32 |
ct5lp-hightpu-4t |
4x8 |
v5litepod-64 |
ct5lp-hightpu-4t |
8x8 |
v5litepod-128 |
ct5lp-hightpu-4t |
8x16 |
v5litepod-256 |
ct5lp-hightpu-4t |
16x16 |
Comparaison des types de VM TPU v5e:
| Type de VM | n2d-48-24-v5lite-tpu | n2d-192-112-v5lite-tpu | n2d-384-224-v5lite-tpu |
| Nombre de puces v5e | 1 | 4 | 8 |
| Nombre de vCPU | 24 | 112 | 224 |
| RAM (Go) | 48 | 192 | 384 |
| Nombre de nœuds NUMA | 1 | 1 | 2 |
| Applicable à | v5litepod-1 | V5Litepod-4 | V5Litepod-8 |
| Perturbation | Élevée | Moyenne | Faible |
Pour libérer de l'espace pour les charges de travail nécessitant plus de puces, les programmeurs peuvent préempter les VM avec moins de puces. Les VM à huit puces sont donc susceptibles de préempter les VM 1 et 4 puces.
Configurations TPU v4
Un pod TPU v4 est composé de 4 096 puces interconnectées avec des liaisons à haut débit reconfigurables. La mise en réseau flexible de TPU v4 vous permet de connecter les puces d'une tranche de pod de même taille de plusieurs manières. Lorsque vous créez une tranche de pod TPU, vous devez spécifier la version de TPU et le nombre de ressources TPU dont vous avez besoin. Lorsque vous créez une tranche de pod TPU v4, vous pouvez spécifier son type et sa taille de l'une des deux manières suivantes : AcceleratorType et AcceleratorConfig.
Utiliser AcceleratorType
Utilisez AcceleratorType lorsque vous ne spécifiez pas de topologie. Pour configurer des TPU v4 à l'aide de AcceleratorType, utilisez l'option --accelerator-type lors de la création de votre tranche de pod TPU. Définissez --accelerator-type sur une chaîne contenant la version de TPU et le nombre de TensorCores que vous souhaitez utiliser. Par exemple, pour créer une tranche de pod v4 avec 32 TensorCores, vous devez utiliser --accelerator-type=v4-32.
La commande suivante crée une tranche de pod TPU v4 comportant 512 TensorCore à l'aide de l'option --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v4-512
--version=tpu-vm-tf-2.16.1-pod-pjrt
Le numéro situé après la version de TPU (v4) indique le nombre de TensorCores.
Un TPU v4 comporte deux TensorCores. Le nombre de puces TPU serait donc de 512/2 = 256.
Utiliser AcceleratorConfig
Utilisez AcceleratorConfig lorsque vous souhaitez personnaliser la topologie physique de votre tranche TPU. Cela est généralement nécessaire pour le réglage des performances avec des tranches de pod comportant plus de 256 puces.
Pour configurer des TPU v4 à l'aide de AcceleratorConfig, utilisez les options --version et --topology. Définissez --version sur la version de TPU que vous souhaitez utiliser et --topology sur la disposition physique des puces TPU dans la tranche de pod.
Vous spécifiez une topologie de TPU à l'aide d'un 3-tuple, AxBxC, où A<=B<=C et A, B et C sont tous des <= 4, ou tous des multiples d'entiers de 4. Les valeurs A, B et C correspondent
au nombre de chips dans chacune des trois dimensions. Par exemple, pour créer une tranche de pod v4 comportant 16 chips, vous devez définir --version=v4 et --topology=2x2x4.
La commande suivante crée une tranche de pod TPU v4 comportant 128 puces TPU disposées dans un tableau 4x4x8:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--type=v4
--topology=4x4x8
--version=tpu-vm-tf-2.16.1-pod-pjrt
Les topologies où 2A=B=C ou 2A=2B=C présentent également des variantes de topologie optimisées pour la communication de type "tout-en-un" (par exemple, 4 × 4 × 8, 8 × 8 × 16 et 12 × 12 × 24). Elles sont connues sous le nom de topologies toris torsadées.
Les illustrations suivantes illustrent certaines topologies de TPU v4 courantes.
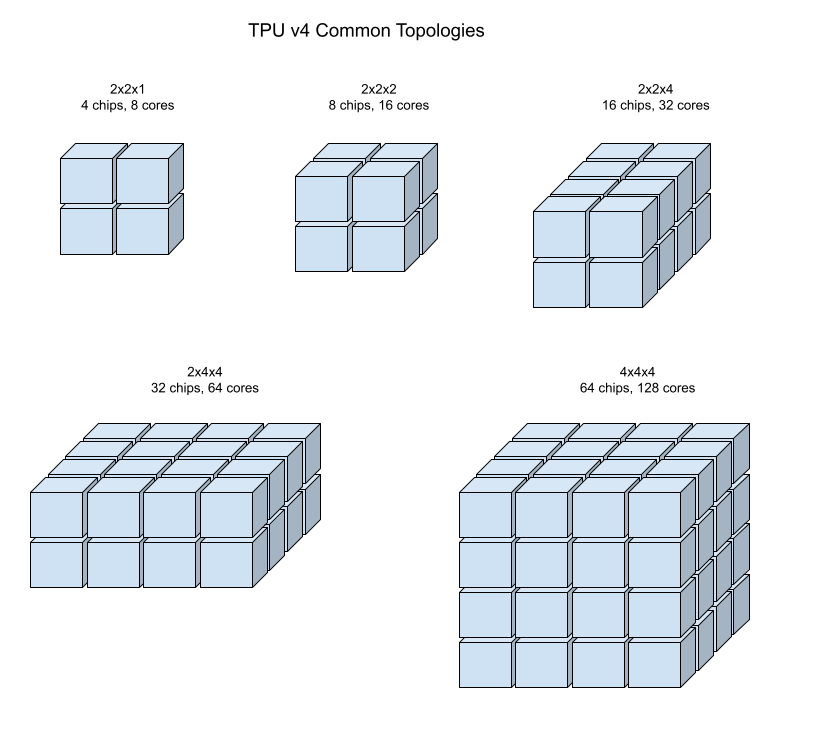
Les tranches de pod plus grandes peuvent être construites à partir d'un ou plusieurs "cubes" de chips de 4 x 4 x 4.
Topologies Tori torsadées
Certaines formes de tranches de tore 3D v4 permettent d'utiliser ce que l'on appelle une topologie de tore torsadé. Par exemple, deux cubes v4 peuvent être disposés en une tranche de 4x4x8 ou en 4x4x8_twisted. Les topologies torsadées offrent une bande passante bissectionnelle nettement plus élevée. L'augmentation de la bande passante bissectionnelle est utile pour les charges de travail qui utilisent des modèles de communication mondiaux. Les topologies torsadées peuvent améliorer les performances de la plupart des modèles, ce qui est le plus bénéfique pour les charges de travail d'intégration TPU volumineuses.
Pour les charges de travail qui utilisent le parallélisme des données comme seule stratégie de parallélisme, les topologies torsadées peuvent être légèrement meilleures. Pour les LLM, les performances avec une topologie torsadée peuvent varier en fonction du type de parallélisme (DP, MP, etc.). Il est recommandé d'entraîner votre LLM avec et sans topologie torsadée afin de déterminer celle qui offre les meilleures performances pour votre modèle. Certaines expériences menées sur le modèle FSDP MaxText ont permis de constater une à deux améliorations de MFU à l'aide d'une topologie torsadée.
Le principal avantage des topologies torsadées est qu'elles transforment une topologie de torus asymétrique (par exemple, 4 × 4 × 8) en une topologie symétrique étroitement liée. La topologie symétrique présente de nombreux avantages:
- Amélioration de l'équilibrage de charge
- Bande passante bissectionnelle plus élevée
- Routes de paquets plus courtes
Ces avantages se traduisent en fin de compte par de meilleures performances pour de nombreux modèles de communication mondiaux.
Le logiciel TPU accepte les tori torsadés sur les tranches où la taille de chaque dimension est égale ou double à celle de la plus petite dimension. Par exemple, 4 x 4 x 8, 4 × 8 × 8 ou 12 x 12 x 24.
Prenons l'exemple de la topologie de torus 4×2 avec des TPU étiquetés avec leurs coordonnées (X,Y) dans la tranche:
Par souci de clarté, les arêtes de ce graphique de topologie sont représentées comme des arêtes non orientées. En pratique, chaque arête est une connexion bidirectionnelle entre les TPU. Les bords entre un côté de cette grille et le côté opposé sont appelés "arêtes enveloppantes", comme indiqué dans le schéma.
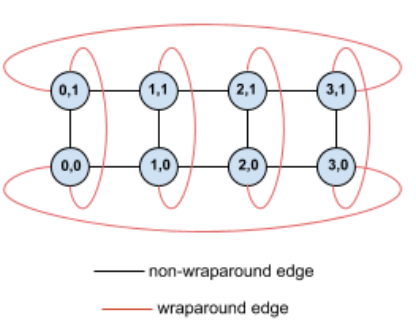
En effectuant une rotation de cette topologie, nous obtenons une topologie de tore torsadée 4×2 complètement symétrique:
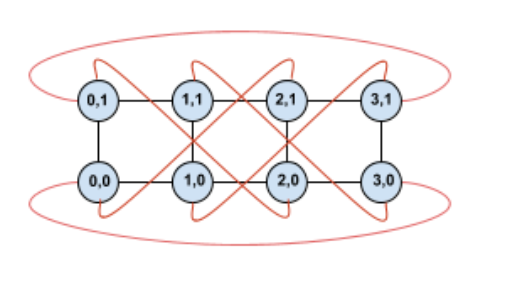
Tout ce qui a changé entre ce schéma et le précédent, ce sont les arêtes enveloppantes en Y. Au lieu d'être connectés à un autre TPU ayant la même coordonnée X, ils ont été décalés pour se connecter au TPU ayant les coordonnées X+2 mod 4.
La même idée se généralise à différentes tailles de dimensions et à différents nombres de dimensions. Le réseau résultant est symétrique, tant que chaque dimension est égale ou double à la taille de la plus petite dimension.
Le tableau suivant présente les topologies torsadées compatibles et une augmentation théorique de la bande passante bissectionnelle par rapport aux topologies non torsadées.
| Topologie torsadée | Augmentation théorique de la bande passante bissectionnelle par rapport à un tore non torsadé |
|---|---|
| 4×4×8_twistés | ~70% |
| 8x8x16_twistés | |
| 12×12×24_twistés | |
| 4×8×8_twistés | ~40% |
| 8×16×16_twisted |
Variantes de topologie TPU v4
Certaines topologies contenant le même nombre de chips peuvent être organisées de différentes manières. Par exemple, une tranche de pod TPU comportant 512 puces (1 024 TensorCore) peut être configurée à l'aide des topologies suivantes: 4x4x32, 4x8x16 ou 8x8x8. Une tranche de pod TPU dotée de 2 048 puces (4 096 TensorCores) offre encore plus d'options de topologie: 4x4x128, 4x8x64, 4x16x32 et 8x16x16. Une tranche de pod TPU dotée de 2 048 puces (4 096 TensorCores) offre encore plus d'options de topologie: 4x4x128, 4x8x64, 4x16x32 et 8x16x16.
La topologie par défaut associée à un nombre de chips donné est celle qui est la plus semblable à un cube (voir la section Topologie v4). Cette forme est probablement le meilleur choix pour l'entraînement ML avec parallélisme des données. D'autres topologies peuvent être utiles pour les charges de travail comportant plusieurs types de parallélisme (par exemple, parallélisme des modèles et des données, ou partitionnement spatial d'une simulation). Ces charges de travail fonctionnent mieux si la topologie correspond au parallélisme utilisé. Par exemple, placer le parallélisme des modèles à quatre voies sur la dimension X et le parallélisme des données à 256 voies sur les dimensions Y et Z correspond à une topologie de 4 x 16 x 16.
Les modèles ayant plusieurs dimensions de parallélisme fonctionnent mieux lorsque leurs dimensions de parallélisme sont mappées aux dimensions de topologie de TPU. Il s'agit généralement de grands modèles de langage (LLM) parallèles données et modèles. Par exemple, pour une tranche de pod TPU v4 avec une topologie de 8 x 16 x 16, les dimensions de topologie de TPU sont 8, 16 et 16. Il est plus efficace d'utiliser le parallélisme des modèles à 8 ou 16 (mappé sur l'une des dimensions de topologie physique de TPU). Un parallélisme de modèle à quatre voies ne serait pas optimal avec cette topologie, car il n'est aligné sur aucune des dimensions de topologie de TPU, mais il serait optimal avec une topologie de 4x16x32 sur le même nombre de puces.
Les configurations TPU v4 se composent de deux groupes : celles dont les topologies sont inférieures à 64 puces (petites topologies) et celles dont les topologies sont supérieures à 64 puces (grandes topologies).
Petites topologies v4
Cloud TPU accepte les tranches de pod TPU v4 suivantes de moins de 64 puces, cubiques de 4 x 4 x 4 : Vous pouvez créer ces petites topologies v4 en utilisant soit leur nom basé sur TensorCore (par exemple, v4-32), soit leur topologie (par exemple, 2x2x4):
| Nom (basé sur le nombre de TensorCore) | Nombre de puces | Topology |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologies v4 volumineuses
Les tranches de pod TPU v4 sont disponibles par incréments de 64 puces, dont les formes sont des multiples de 4 sur les trois dimensions. Les dimensions doivent également être
dans l'ordre croissant. Plusieurs exemples sont présentés dans le tableau suivant. Certaines de ces topologies sont des topologies "personnalisées" qui ne peuvent être créées qu'à l'aide des indicateurs --type et --topology, car il existe plusieurs façons d'organiser les chips.
La commande suivante crée une tranche de pod TPU v4 comportant 512 puces TPU disposées dans un tableau 8x8x8:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--type=v4
--topology=8x8x8
--version=tpu-vm-tf-2.16.1-pod-pjrt
Vous pouvez créer une tranche de pod TPU v4 avec le même nombre de TensorCores à l'aide de --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v4-1024
--version=tpu-vm-tf-2.16.1-pod-pjrt
| Nom (basé sur le nombre de TensorCore) | Nombre de puces | Topology |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
N/A (doit utiliser les options --type et --topology) |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1 024 | 8x8x16 |
N/A (doit utiliser les options --type et --topology) |
1 024 | 4x16x16 |
| v4-4096 | 2 048 | 8x16x16 |
| … | … | … |
Configurations TPU v3
Un pod TPU v3 est composé de 1 024 puces interconnectées avec des liaisons à haut débit. Pour créer un appareil ou une tranche de pod TPU v3, utilisez l'option --accelerator-type de la commande gcloud compute tpus tpu-vm. Spécifiez le type d'accélérateur en indiquant la version de TPU et le nombre de cœurs de TPU. Pour un seul TPU v3, utilisez --accelerator-type=v3-8. Pour une tranche de pod v3 comportant 128 TensorCores, utilisez --accelerator-type=v3-128.
La commande suivante montre comment créer une tranche de pod TPU v3 avec 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v3-128
--version=tpu-vm-tf-2.16.1-pjrt
Le tableau suivant répertorie les types de TPU v3 compatibles:
| Version du TPU | Fin de la compatibilité |
|---|---|
| v3-8 | (Date de fin pas encore fixée) |
| v3-32 | (Date de fin pas encore fixée) |
| v3-128 | (Date de fin pas encore fixée) |
| v3-256 | (Date de fin pas encore fixée) |
| v3-512 | (Date de fin pas encore fixée) |
| v3-1024 | (Date de fin pas encore fixée) |
| v3-2048 | (Date de fin pas encore fixée) |
Pour en savoir plus sur la gestion des TPU, consultez la page Gérer les TPU. Pour en savoir plus sur les différentes versions de Cloud TPU, consultez la page Architecture système.
Configurations TPU v2
Un pod TPU v2 est composé de 512 puces interconnectées avec des liaisons à haut débit reconfigurables. Pour créer une tranche de pod TPU v2, utilisez l'option --accelerator-type de la commande gcloud compute tpus tpu-vm. Spécifiez le type d'accélérateur en indiquant la version de TPU et le nombre de cœurs de TPU. Pour un seul TPU v2, utilisez --accelerator-type=v2-8. Pour une tranche de pod v2 comportant 128 TensorCores, utilisez --accelerator-type=v2-128.
La commande suivante montre comment créer une tranche de pod TPU v2 comportant 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v2-128
--version=tpu-vm-tf-2.16.1-pjrt
Pour en savoir plus sur la gestion des TPU, consultez la page Gérer les TPU. Pour en savoir plus sur les différentes versions de Cloud TPU, consultez la page Architecture système.
Le tableau suivant répertorie les types de TPU v2 compatibles
| Version du TPU | Fin de la compatibilité |
|---|---|
| v2-8 | (Date de fin pas encore fixée) |
| v2-32 | (Date de fin pas encore fixée) |
| v2-128 | (Date de fin pas encore fixée) |
| v2-256 | (Date de fin pas encore fixée) |
| v2-512 | (Date de fin pas encore fixée) |
Compatibilité des types de TPU
Vous pouvez remplacer le type de TPU par un autre type de TPU comportant le même nombre de TensorCore ou de puces (par exemple, v3-128 et v4-128) et exécuter votre script d'entraînement sans modifier le code. Toutefois, si vous passez à un type de TPU comportant un nombre plus ou moins élevé de TensorCores, vous devrez effectuer un réglage et une optimisation significatifs. Pour plus d'informations, consultez la page Entraînement sur pods TPU.
Versions logicielles des VM TPU
Cette section décrit les versions logicielles de TPU que vous devez utiliser pour un TPU avec l'architecture de VM TPU. Pour l'architecture du nœud TPU, consultez la section Versions logicielles du nœud TPU.
Des versions logicielles TPU sont disponibles pour les frameworks TensorFlow, PyTorch et JAX.
TensorFlow
Utilisez la version logicielle de TPU correspondant à la version de TensorFlow avec laquelle votre modèle a été écrit.
À partir de la version 2.15.0 de TensorFlow, vous devez également spécifier l'environnement d'exécution de l'exécuteur de flux (SE) ou PJRT. Par exemple, si vous utilisez TensorFlow 2.16.1 avec l'environnement d'exécution PJRT, utilisez la version logicielle de TPU tpu-vm-tf-2.16.1-pjrt. Les versions antérieures à TensorFlow 2.15.0 ne sont compatibles qu'avec l'exécuteur de flux. Pour en savoir plus sur PJRT, consultez la page Compatibilité avec PJRT TensorFlow.
Les versions logicielles actuellement compatibles avec les VM TPU TensorFlow sont les suivantes:
- tpu-vm-tf-2.16.1-pjrt
- tpu-vm-tf-2.16.1-se
- tpu-vm-tf-2.15.0-pjrt
- tpu-vm-tf-2.15.0-se
- tpu-vm-tf-2.14.1
- tpu-vm-tf-2.14.0
- tpu-vm-tf-2.13.1
- tpu-vm-tf-2.13.0
- tpu-vm-tf-2.12.1
- tpu-vm-tf-2.12.0
- tpu-vm-tf-2.11.1
- tpu-vm-tf-2.11.0
- tpu-vm-tf-2.10.1
- tpu-vm-tf-2.10.0
- tpu-vm-tf-2.9.3
- tpu-vm-tf-2.9.1
- tpu-vm-tf-2.8.4
- tpu-vm-tf-2.8.3
- tpu-vm-tf-2.8.0
- tpu-vm-tf-2.7.4
- tpu-vm-tf-2.7.3
Pour en savoir plus sur les versions de correctif TensorFlow, consultez la page Versions de correctif TensorFlow compatibles.
Compatibilité avec TensorFlow PJRT
À partir de la version 2.15.0 de TensorFlow, vous pouvez utiliser l'interface PJRT pour TensorFlow sur TPU. PJRT propose une défragmentation automatique de la mémoire de l'appareil et simplifie l'intégration du matériel aux frameworks. Pour en savoir plus sur PJRT, consultez l'article PJRT: Simplifiez l'intégration de matériel et de frameworks de ML sur le blog Google Open Source.
Les fonctionnalités des TPU v2, v3 et v4 n'ont pas toutes été migrées vers l'environnement d'exécution PJRT. Le tableau suivant décrit les fonctionnalités compatibles avec PJRT ou l'exécuteur vapeur.
| Accélérateur | Sélection | Compatible avec PJRT | Compatible avec l'exécuteur de flux |
|---|---|---|---|
| TPU v2-v4 | Calcul dense (pas d'API de représentation vectorielle continue de TPU) | Oui | Oui |
| TPU v2-v4 | API de calcul dense + API de représentation vectorielle continue TPU | Non | Oui |
| TPU v2-v4 | tf.summary/tf.print avec positionnement souple de l'appareil |
Non | Oui |
| TPU v5e | Calcul dense (pas d'API de représentation vectorielle continue de TPU) | Oui | Non |
| TPU v5e | API d'intégration de TPU | N/A : TPU v5e n'est pas compatible avec l'API de représentation vectorielle continue de TPU | Non disponible |
| TPU v5p | Calcul dense (pas d'API de représentation vectorielle continue de TPU) | Oui | Non |
| TPU v5p | API d'intégration de TPU | Oui | Non |
TPU v4 avec TensorFlow 2.10.0 et versions antérieures
Si vous entraînez un modèle sur TPU v4 avec TensorFlow, les versions 2.10.0 et antérieures de TensorFlow utilisent les versions spécifiques à v4 indiquées dans le tableau suivant. Si la version de TensorFlow que vous utilisez n'apparaît pas dans le tableau, suivez les instructions de la section TensorFlow.
| Version de TensorFlow | Version logicielle du TPU |
|---|---|
| 2.10.0 | tpu-vm-tf-2.10.0-v4, tpu-vm-tf-2.10.0-pod-v4 |
| 2.9.3 | tpu-vm-tf-2.9.3-v4, tpu-vm-tf-2.9.3-pod-v4 |
| 2.9.2 | tpu-vm-tf-2.9.2-v4, tpu-vm-tf-2.9.2-pod-v4 |
| 2.9.1 | tpu-vm-tf-2.9.1-v4, tpu-vm-tf-2.9.1-pod-v4 |
Versions de Libtpu
Les VM TPU sont créées avec TensorFlow et la bibliothèque Libtpu correspondante préinstallée. Si vous créez votre propre image de VM, spécifiez les versions suivantes du logiciel TensorFlow TPU et les versions correspondantes de libtpu:
| Version de TensorFlow | Version de libtpu.so |
|---|---|
| 2.16.1 | 1.10.1 |
| 2.15.0 | 1.9.0 |
| 2.14.1 | 1.8.1 |
| 2.14.0 | 1.8.0 |
| 2.13.1 | 1.7.1 |
| 2.13.0 | 1.7.0 |
| 2.12.1 | 1.6.1 |
| 2.12.0 | 1.6.0 |
| 2.11.1 | 1.5.1 |
| 2.11.0 | 1.5.0 |
| 2.10.1 | 1.4.1 |
| 2.10.0 | 1.4.0 |
| 2.9.3 | 1.3.2 |
| 2.9.1 | 1.3.0 |
| 2.8.3 | 1.2.3 |
| 2,8*. | 1.2.0 |
| 2.7.3 | 1.1.2 |
PyTorch
Utilisez la version logicielle de TPU correspondant à la version de PyTorch avec laquelle votre modèle a été écrit. Par exemple, si vous utilisez PyTorch 1.13 et TPU v2 ou v3, utilisez la version logicielle de TPU tpu-vm-pt-1.13. Si vous utilisez TPU v4, utilisez la version logicielle du TPU tpu-vm-v4-pt-1.13. La même version logicielle TPU est utilisée pour les pods TPU (par exemple,v2-32, v3-128, v4-32). Les versions logicielles actuelles compatibles sont les suivantes:
TPU v2/v3:
- tpu-vm-pt-2.0 (pytorch-2.0)
- tpu-vm-pt-1.13 (pytorch-1.13)
- tpu-vm-pt-1.12 (pytorch-1.12)
- tpu-vm-pt-1.11 (pytorch-1.11)
- tpu-vm-pt-1.10 (pytorch-1.10)
- v2-alpha (Pytorch-1.8.1)
TPU v4:
- tpu-vm-v4-pt-2.0 (pytorch-2.0)
- tpu-vm-v4-pt-1.13 (pytorch-1.13)
TPU v5 (v5e et v5p):
- v2-alpha-tpuv5 (Pytorch-2.0)
Lorsque vous créez une VM TPU, la dernière version de PyTorch est préinstallée sur la VM TPU. La version correcte de libtpu.so est automatiquement installée lorsque vous installez PyTorch.
Pour modifier la version actuelle du logiciel PyTorch, consultez la page Modifier la version de PyTorch.
JAX
Vous devez installer manuellement JAX sur votre VM TPU. Il n'existe pas de version logicielle (d'exécution) spécifique à JAX pour TPU v2 et v3. Pour les versions ultérieures de TPU, utilisez les versions logicielles suivantes:
- TPU v4: tpu-vm-v4-base
- TPU v5e: v2-alpha-tpuv5
- TPU v5p: v2-alpha-tpuv5
La version correcte de libtpu.so est automatiquement installée lorsque vous installez JAX.
Versions logicielles du nœud TPU
Cette section décrit les versions logicielles de TPU que vous devez utiliser pour un TPU avec l'architecture de nœud TPU. Pour l'architecture des VM TPU, consultez la section Versions logicielles des VM TPU.
Des versions logicielles TPU sont disponibles pour les frameworks TensorFlow, PyTorch et JAX.
TensorFlow
Utilisez la version logicielle de TPU correspondant à la version de TensorFlow avec laquelle votre modèle a été écrit. Par exemple, si vous utilisez TensorFlow 2.12.0, utilisez la version du logiciel TPU 2.12.0. Voici les versions logicielles de TPU spécifiques à TensorFlow:
- 2.12.1
- 2.12.0
- 2.11.1
- 2.11.0
- 2.10.1
- 2.10.0
- 2.9.3
- 2.9.1
- 2.8.4
- 2.8.2
- 2.7.3
Pour en savoir plus sur les versions de correctif TensorFlow, consultez la page Versions de correctif TensorFlow compatibles.
Lorsque vous créez un nœud TPU, la dernière version de TensorFlow est préinstallée sur le nœud TPU.
PyTorch
Utilisez la version logicielle de TPU qui correspond à la version de PyTorch avec laquelle votre modèle a été écrit. Par exemple, si vous utilisez PyTorch 1.9, utilisez la version logicielle pytorch-1.9.
Les versions logicielles de TPU spécifiques à PyTorch sont les suivantes :
- PyTorch-2.0
- PyTorch-1.13
- PyTorch-1.12
- PyTorch-1.11
- PyTorch-1.10
- pytorch-1.9
- pytorch-1.8
- pytorch-1.7
pytorch-1.6
pytorch-nightly
Lorsque vous créez un nœud TPU, la dernière version de PyTorch est préinstallée sur le nœud TPU.
JAX
Vous devez installer JAX manuellement sur votre VM TPU. Par conséquent, aucune version logicielle TPU spécifique à JAX n'est préinstallée. Vous pouvez utiliser n'importe quelle version logicielle listée pour TensorFlow.
Étapes suivantes
- Pour en savoir plus sur l'architecture des TPU, consultez la page Architecture du système.
- Consultez la section Quand utiliser des TPU pour en savoir plus sur les types de modèles adaptés à Cloud TPU.