Cloud TPU マルチスライスの概要
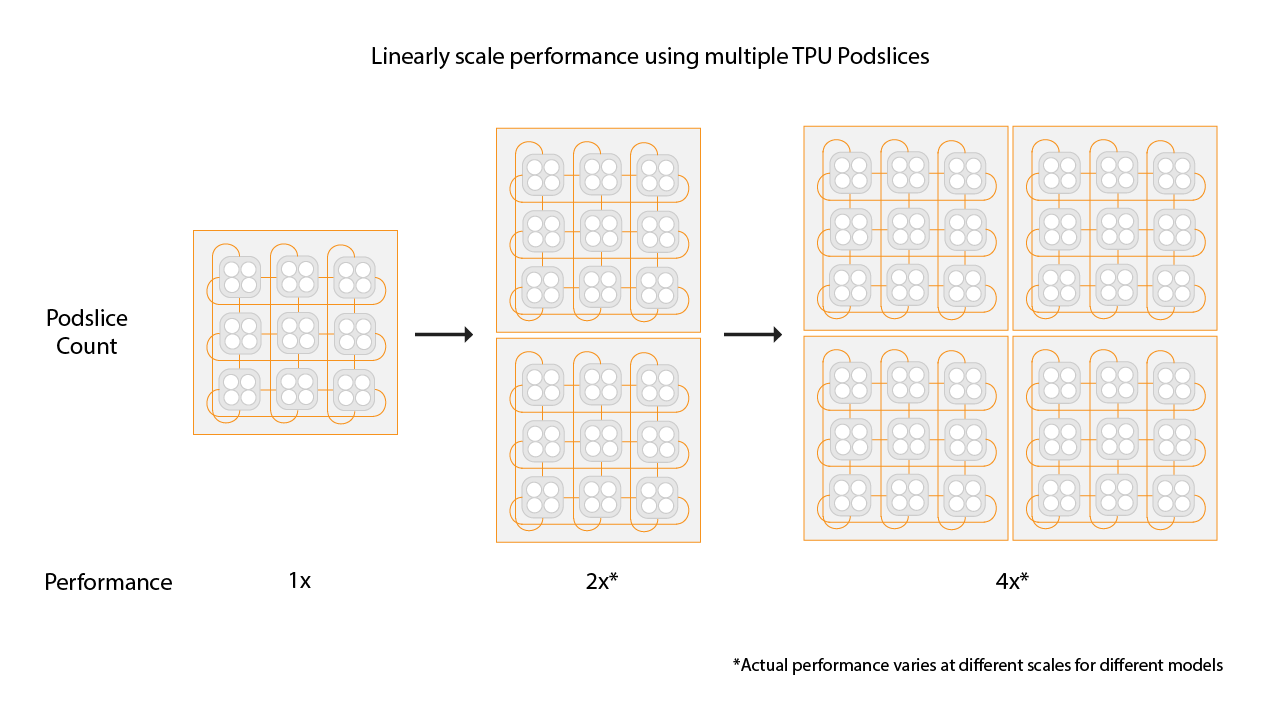
Cloud TPU マルチスライスは、単純なデータ並列処理で、単一の Pod 内、または複数の POD 内のスライスで、トレーニング ジョブが TPU スライスを使用することができるようにする、フルスタック パフォーマンス スケーリング テクノロジーです。TPU v4 チップの場合、トレーニング ジョブは 1 回の実行で 4,096 を超えるチップを使用できます。4, 096 チップ未満を必要とするトレーニング ジョブの場合、単一スライスが最高のパフォーマンスを発揮します。ただし、複数の小さなスライスがより簡単に利用できるため、マルチスライスを小さなスライスで使用する場合、起動時間が短縮されます。
マルチスライス構成にデプロイすると、各スライス内の TPU チップがチップ間相互接続(ICI)を介して通信します。異なるスライスの TPU チップは、CPU(ホスト)にデータを転送することで通信し、CPU(ホスト)からデータセンター ネットワーク(DCN)経由でデータを送信します。
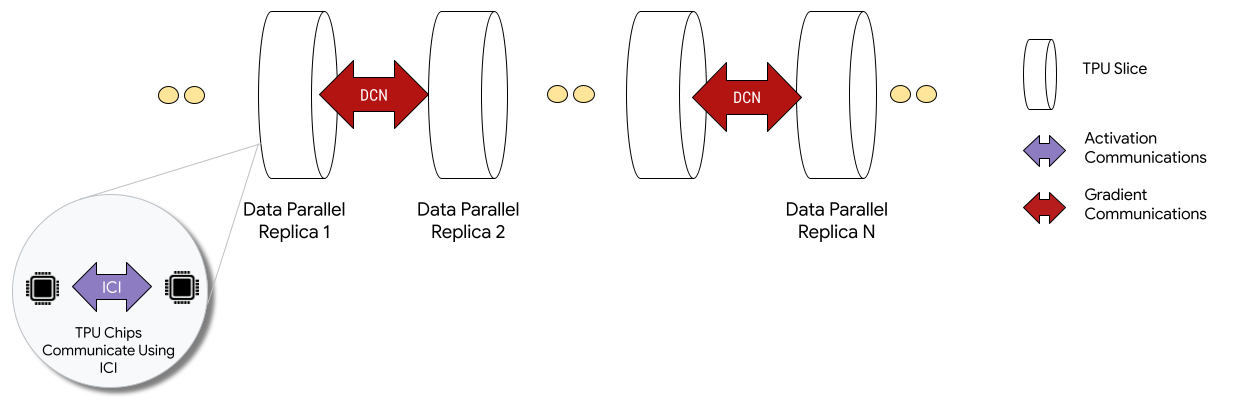
スライス間 DCN 通信を実装するためにデベロッパーがコードを記述することはありません。XLA コンパイラが、そのコードを生成し、最大限のパフォーマンスが発揮できるようにコンピューティングと通信をオーバーラップします。
コンセプト
- アクセラレータ タイプ
- マルチスライスを構成する各 TPU スライスの形状。マルチスライス リクエストの各スライスは同じアクセラレータ タイプです。アクセラレータ タイプは、TPU タイプ(v4 または v5e)とそれに続く TensorCore 数で構成されます。たとえば、
v4-128は、128 個の TensorCore を使用する TPU v4 を指定します。 - 自動修復
- スライスにメンテナンス イベント、プリエンプション、またはハードウェアの障害が発生すると、Cloud TPU が新しいスライスを作成します。まれなケースとして、新しいスライスを作成するための十分なリソースがない場合、ハードウェアが使用可能になるまで作成が完了しません。新しいスライスを作成すると、マルチスライス環境内の他のすべてのスライスが再起動され、トレーニングを続行できます。適切に構成された起動スクリプトを使用すると、ユーザーの介入なしに、トレーニング スクリプトが自動的に再起動され、最新のチェックポイントから読み込みと再開が行われます。
- データセット
- モデルがトレーニングまたは推論に使用するデータ。
- データセンター ネットワーキング(DCN)
- マルチスライス構成で TPU スライスを接続する、高レイテンシ、低スループット(ICI と比較して)ネットワーク。
- ギャング スケジューリング
- すべての TPU スライスを同時にプロビジョニングすると、すべてのスライスが正常にプロビジョニングされるか、まったくプロビジョニングされないことを保証します。
- ホスト
- ホストは、VM を実行する物理コンピュータです。1 つのホストが一度に実行できる VM は 4 つまでです。各 VM には専用の TPU があります。
- 推論
- 事前トレーニング済みの機械学習モデルをホストに読み込み、データを予測します。
- インターチップ相互接続(ICI)
- TPU Pod 内で TPU を接続する高速かつ低レイテンシの内部リンク。
- マルチスライス
- DCN 上で通信できる 2 つ以上の TPU チップ スライス。
- ノード
- マルチスライスのコンテキストでは、ノードは単一の TPU スライスを指します。 マルチスライスの各 TPU スライスにはノード ID が割り当てられます。
- ポッド
- 専用の ICI ネットワーク インターフェースによって接続された TPU チップの集合。Pod を使用すると、処理負荷を複数の TPU に分散できます。
- キューに格納されたリソース(QR)
- シングルスライスまたはマルチスライス TPU 環境に対するリクエストをキューに追加して管理するために使用される TPU リソースの表現。
- 起動スクリプト
- VM が起動または再起動するたびに実行される標準の Compute Engine 起動スクリプト。マルチスライスの場合は、QR 作成リクエストで指定されます。Cloud TPU 起動スクリプトの詳細については、TPU リソースの管理をご覧ください。
- TPU スライス
- TPU チップで構成される TPU Pod の論理項。スライス内のすべてのチップは、ICI ネットワークを使用して相互に通信します。
- TPU VM
- 基盤となる TPU にアクセスできる Linux を実行している仮想マシン。 v4 TPU の場合、各 TPU VM は 4 つのチップに直接アクセスできます。TPU VM は、ワーカーとも呼ばれます。
- Tensor
- 機械学習モデルの多次元データを表すために使用されるデータ構造。
- Tensor processing unit (TPU)
- Google が社内開発した ML アクセラレーション チップ。行列乗算などの主要な機械学習タスクに対して、高速で電力効率の高いコンピューティングを提供するように設計されています。
- Cloud TPU の容量のタイプ
TPU は、さまざまなタイプの容量から作成できます(TPU の料金の仕組みの使用オプションを参照)。
- 予約: 予約済みの割り当てを対象にします。予約済みの割り当てを使用するには、Google と予約契約を結ぶ必要があります。リソースを作成する際は
--reservedフラグを使用します。 - Spot: Spot VM を使用するプリエンプティブルの割り当てを対象にします。優先度の高いジョブに対するリクエストのスペースを確保するために、リソースがプリエンプトされる場合があります。リソースを作成する際は
--spotフラグを使用します。 - オンデマンド: 予約を必要とせずプリエンプトされない、オンデマンド割り当てを対象にします。TPU リクエストは、Cloud TPU が提供するオンデマンド割り当てキューに追加されます。リソースの可用性は保証されません。デフォルトで選択されています。フラグは必要ありません。
- 予約: 予約済みの割り当てを対象にします。予約済みの割り当てを使用するには、Google と予約契約を結ぶ必要があります。リソースを作成する際は
始める
TPU を使用したことがない場合は、まず Google Cloud CLI をインストールし、Cloud TPU 環境を設定します。マルチスライスを使用するには、TPU リソースをキューに格納されたリソースとして管理する必要があります。
既存の TPU v4 ユーザーで、予約がある場合は、予約を新しい予約システムに移行する必要があります。詳しくは、Google Cloud アカウント担当者にお問い合わせください。
入門例
このチュートリアルでは、MaxText GitHub リポジトリのコードを使用します。 MaxText は、Python と Jax で記述された、高性能で任意に拡張可能なオープンソースの十分にテストされた基本 LLM です。MaxText は Cloud TPU で効率的にトレーニングするように設計されています。
shardings.py のコードは、さまざまな並列処理オプションを試すことができるように設計されています。たとえば、データ並列処理、完全にシャーディングされたデータ並列処理(FSDP)、テンソル並列処理などです。コードは、シングルスライスからマルチスライス環境にスケーリングします。
ICI 並列処理
ICI とは、TPU を単一のスライスで接続する高速相互接続のことです。ICI シャーディングは、スライス内のシャーディングに対応します。shardings.py には、3 つの ICI 並列処理パラメータがあります。
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelism
これらのパラメータに指定する値によって、各並列処理メソッドのシャード数が決まります。
これらの入力は、ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism がスライス内のチップ数に等しくなるように制限する必要があります。
次の表では、v4-8 で利用可能な 4 つのチップの ICI 並列処理のユーザー入力の例を示します。
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| 4 方向 FSDP | 1 | 4 | 1 |
| 4 方向 Tensor 並列処理 | 1 | 1 | 4 |
| 双方向 FSDP + 双方向 TensorFlow 並列処理 | 1 | 2 | 2 |
ICI ネットワークは十分高速なため、ほぼ常にデータ並列処理よりも FSDP が優先されることから、ほとんどの場合 ici_data_parallelism を 1 のままにする必要があります。
この例では、JAX を使用して Cloud TPU VM で計算を実行するなど、単一の TPU スライスでコードを実行することに精通していることを前提としています。次の例は、単一のスライスで shardings.py を実行する方法を示しています。
環境を設定します。
$ gcloud auth login $ gcloud config set project your-project-id $ gcloud config set compute/zone your-zone
gcloudの SSH 認証鍵を作成します。パスワードは空白のままにすることをおすすめします(次のコマンドの実行後に 2 回 Enter を押します)。google_compute_engineファイルがすでに存在しているというメッセージが表示された場合は、既存のバージョンを置き換えます。$ ssh-keygen -f ~/.ssh/google_compute_engine次のコマンドを使用して、TPU をプロビジョニングします。
$ gcloud compute tpus queued-resources \ create your-qr-id \ --accelerator-type your-accelerator-type \ --runtime-version tpu-ubuntu2204-base \ --node-id qr-id \ [--reserved |--spot]コマンドフラグの説明
your-qr-id- QR リクエストを識別するユーザー定義の文字列。
accelerator-type- アクセラレータ タイプでは、作成する Cloud TPU のバージョンとサイズを指定します。TPU のバージョンごとにサポートされているアクセラレータ タイプの詳細については、TPU のバージョンをご覧ください。
runtime-version- [Cloud TPU ソフトウェア バージョン](/tpu/docs/supported-tpu-configurations#tpu_software_versions)
node-id- QR リクエストに応じて作成される TPU リソースの ID。
reserved- スライスの作成時に予約割り当てを使用します。
spot- スライスの作成時に Spot VM の割り当てを使用します。
Google Cloud CLI は、タグなどのすべての QR 作成オプションをサポートしているわけではありません。 詳細については、QR を作成するをご覧ください。
QR が
ACTIVE状態になるまで待ちます。これは、ワーカーノードがREADY状態であることを意味します。QR プロビジョニングの開始後、QR のサイズによっては 1 ~ 5 分かかることがあります。 QR リクエストのステータスは、次のコマンドを使用して確認できます。$ gcloud compute tpus queued-resources \ list --filter=your-qr-idv4-8 スライスには、単一の TPU VM があります。SSH を使用して TPU VM に接続します。
$ gcloud compute tpus tpu-vm ssh your-qr-idMaxText(
shardings.pyを含む)のクローンを TPU VM に作成します。MaxText リポジトリ ディレクトリ内で、セットアップ スクリプトを実行して、JAX とその他の依存関係を TPU スライスにインストールします。このスクリプトのセットアップには数分かかります。
$ bash setup.sh次のコマンドを実行して、TPU スライスで
shardings.pyを実行します。$ python3 pedagogical_examples/shardings.py \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048結果はログで確認できます。TPU は約 260 TFLOP/秒、または 90%以上の FLOP 使用率を達成する必要があります。この場合、TPU の高帯域幅メモリ(HBM)に収まるほぼ最大のバッチを選択しています。
ICI では、他のシャーディング戦略を検討してください。たとえば、次の組み合わせを試すことができます。
$ python3 pedagogical_examples/shardings.py \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048完了したら、QR と TPU スライスを削除します。これらのクリーンアップ手順は、スライスを設定した環境から実行する必要があります(最初に
exitを実行して、SSH セッションを終了します)。削除には 2 ~ 5 分かかります。オプションの--asyncフラグを指定してバックグラウンドで実行できます。$ gcloud compute tpus queued-resources delete your-qr-id --force (--async)
DCN 並列処理を使用したマルチスライス シャーディング
shardings.py スクリプトは、データ並列処理の各タイプのシャード数に対応する、DCN 並列処理を指定する 3 つのパラメータを受け入れます。
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
これらのパラメータの値は、dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism がスライスの数と等しくなるように制限する必要があります。
2 つのスライスの例として --dcn_data_parallelism = 2 を使用します。
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | スライス数 | |
| 双方向データ並列処理 | 2 | 1 | 1 | 2 |
DCN はこのようなシャーディングに適していないため、dcn_tensor_parallelism は常に 1 に設定する必要があります。v4 チップの一般的な LLM ワークロードでは、dcn_fsdp_parallelism も 1 に設定する必要があるため、dcn_data_parallelism をスライス数に設定する必要がありますが、これはアプリケーションによって異なります。
スライスの数を増やすと(スライスのサイズとスライスごとのバッチ数が一定に保たれていると想定)、データの並列処理の量が増えます。
マルチスライス環境での shardings.py の実行
マルチスライス環境で shardings.py を実行するには、multihost_runner.py を使用するか、各 TPU VM で shardings.py を実行します。ここでは multihost_runner.py を使用します。
次の手順は、MaxText リポジトリからのはじめに: 複数のスライスでの簡単なテストの手順と似ています。ただしここでは、train.py のより複雑な LLM の代わりに shardings.py を実行します。
multihost_runner.py ツールは簡単なテスト用に最適化されており、同じ TPU を繰り返し再利用します。multihost_runner.py スクリプトは長時間 SSH 接続に依存するため、長時間実行ジョブにはおすすめしません。
これより長いジョブ(数時間や数日など)を実行する場合は、multihost_job.py を使用することをおすすめします。
このチュートリアルでは、multihost_runner.py スクリプトを実行するマシンを示すためにランナーという用語を使用します。スライスを構成する TPU VM を示すためにワーカーという用語を使用します。multihost_runner.py は、ローカルマシン、またはスライスと同じプロジェクト内の任意の Compute Engine VM 上で実行できます。 ワーカーでの multihost_runner.py の実行はサポートされていません。
multihost_runner.py は、SSH を使用して TPU ワーカーに自動的に接続します。
この例では、2 つの v4-16 スライス(合計 4 つの VM と 16 個の TPU チップ)で shardings.py を実行します。サンプルを変更し、より多くの TPU で実行できるようにできます。
環境を設定する
ランナーマシンで MaxText のクローンを作成します。
リポジトリ ディレクトリに移動します。
gcloudの SSH 認証鍵を作成します。空白のパスワードを残すことをおすすめします(次のコマンドの実行後に 2 回 Enter を押します)。google_compute_engineファイルがすでに存在しているというメッセージが表示された場合は、既存のバージョンを保持しないを選択します。$ ssh-keygen -f ~/.ssh/google_compute_engine環境変数を追加して、TPU スライス数を
2に設定します。$ export SLICE_COUNT=2queued-resources createを使用してマルチスライス環境を作成します。次のコマンドは、v4 マルチスライス TPU の作成方法を示しています。v5e を使用するには、v5e の
accelerator-type(例:v5litepod-16)と v5e のruntime-version(v2-alpha-tpuv5-lite)を指定します。$ gcloud compute tpus queued-resources
create your-qr-id
--accelerator-type=your-accelerator-type
--runtime-version=tpu-vm-runtime-version
--node-count=node-count
--node-prefix=your-qr-id
[--reserved|--spot]コマンドフラグの説明
your-qr-id- QR リクエストを識別するユーザー定義の文字列。
accelerator-type- アクセラレータ タイプでは、作成する Cloud TPU のバージョンとサイズを指定します。TPU のバージョンごとにサポートされているアクセラレータ タイプの詳細については、TPU のバージョンをご覧ください。
runtime-version- Cloud TPU ソフトウェアのバージョン。
node-count- 作成するスライスの数。
node-prefix- 各スライスの名前を生成するために使用される接頭辞。各スライスの接頭辞に番号が追加されます。たとえば、
node-prefixをmySliceに設定すると、スライスの名前はmySlice-0、mySlice-1となり、各スライスの数値が続きます。 reserved- スライスの作成時に予約割り当てを使用します。
spot- スライスの作成時に Spot VM の割り当てを使用します。
QR プロビジョニングの開始後、QR のサイズによっては完了に最大 5 分かかることがあります。キューに格納されたリソース(QR)が
ACTIVE状態になるまで待ちます。QR リクエストのステータスは、次のコマンドを使用して確認できます。$ gcloud compute tpus queued-resources list \ --filter=your-qr-idその結果、次のような出力が生成されます。
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v4-16 ACTIVE ...
QR のステータスが 15 分以上
WAITING_FOR_RESOURCESまたはPROVISIONINGの状態になっている場合は、Google Cloud アカウント担当者にお問い合わせください。依存関係をインストールします。
$ python3 multihost_runner.py \ --TPU_PREFIX=your-qr-id \ --COMMAND="bash setup.sh"multihost_runner.pyを使用して、各ワーカーでshardings.pyを実行します。$ python3 multihost_runner.py \ --TPU_PREFIX=your-qr-id \ --COMMAND="python3 pedagogical_examples/shardings.py \ --dcn_data_parallelism $SLICE_COUNT \ --ici_fsdp_parallelism 8 \ --batch_size 131072 \ --embedding_dimension 2048"ログファイルに約 230 TFLOP/秒のパフォーマンスが表示されます。
完了したら TPU と QR をクリーンアップします。削除には 2 ~ 5 分かかります。オプションの
--asyncフラグを指定してバックグラウンドで実行できます。
マルチスライスへのワークロードのスケーリング
マルチスライス環境でモデルを実行する前に、次のコードを変更します。
- メッシュの作成時には、jax.experimental.mesh_utils.create_device_mesh ではなく jax.experimental.mesh_utils.create_hybrid_device_mesh を使用します。
マルチスライスに移行するときに必要なコードの変更は、これだけです。高いパフォーマンスを実現するには、DCN をデータ並列に、完全にシャーディングされたデータ並列軸またはパイプライン並列軸にマッピングする必要があります。パフォーマンスに関する考慮事項とシャーディング戦略の詳細については、最大パフォーマンスのためのマルチスライスを使用したシャーディングをご覧ください。
コードがすべてのデバイスにアクセスできることを確認するには、len(jax.devices()) がマルチスライス環境のチップ数と等しいことを表明します。たとえば、v4-16 の 4 つのスライスを使用している場合、スライスごとに 8 つのチップ × 4 つのスライスがあるため、len(jax.devices()) は 32 を返します。
マルチスライス環境のスライスサイズの選択
線形の速度を上げるには、既存のスライスと同じサイズの新しいスライスを追加します。たとえば、v4-512 スライスを使用する場合、マルチスライスでは、2 番目の v4-512 スライスを追加してグローバル バッチサイズを 2 倍にすることで、約 2 倍のパフォーマンスを実現できます。詳細については、最大パフォーマンスのためのマルチスライスを使用したシャーディングをご覧ください。
複数のスライスでのジョブの実行
マルチスライス環境でカスタム ワークロードを実行するには、次の 3 つの方法があります。
- 試験運用版ランナー スクリプト
multihost_runner.pyを使用 - 本番環境ランナー スクリプト
multihost_job.pyを使用 - 手動アプローチを使用
試験運用版ランナー スクリプト
multihost_runner.py スクリプトは、既存のマルチスライス環境にコードを配布し、各ホストでコマンドを実行して、ログをコピーし、各コマンドのエラー ステータスを追跡します。multihost_runner.py スクリプトについては、MaxText の README をご覧ください。
multihost_runner.py では永続的な SSH 接続が維持されるため、比較的小規模な、比較的短時間で実行されるテストにのみ適しています。multihost_runner.py チュートリアルの手順は、ワークロードとハードウェア構成に適用できます。
本番環境ランナー スクリプト
ハードウェアの障害やその他のプリエンプションに対する復元力が必要な本番環境ジョブの場合は、Create Queued Resource API と直接統合することをおすすめします。実用的な例として、Google は multihost_job.pyを提供しています。これにより、適切な起動スクリプトで Created Queued Resource API 呼び出しをトリガーし、プリエンプション時にトレーニングと再開を行います。multihost_job.py スクリプトについては、MaxText の README をご覧ください。
multihost_job.py は実行ごとにリソースをプロビジョニングする必要があるため、multihost_runner.py のような速い反復サイクルは提供されません。
手動アプローチ
マルチスライス構成でカスタム ワークロードを実行するには、multihost_runner.py または multihost_job.py を使用または調整することをおすすめします。ただし、QR コマンドを直接使用して環境をプロビジョニングして管理する場合は、マルチスライス環境を管理するをご覧ください。
マルチスライス環境を管理する
MaxText リポジトリで提供されるツールを使用せずに、QR を手動でプロビジョニングして管理するには、以下のセクションをご覧ください。
QR を作成する
容量をプロビジョニングする前に、次の環境変数を設定します。
$ export your-qr-id=your-queued-resource-id $ export PROJECT=your-project-name $ export ZONE=us-central2-b $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=tpu-ubuntu2204-base $ export ACCELERATOR_TYPE=v4-16 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT="#!/bin/bash\n ..." $ gcloud config set project project-name $ gcloud config set compute/zone zone
| 入力 | 説明 |
| your-qr-id | ユーザーが割り当てた QR の ID。 |
| プロジェクト | Google Cloud プロジェクト名 |
| ZONE | us-central2-b |
| NETWORK_NAME | VPC ネットワークの名前。 |
| SUBNETWORK_NAME | VPC ネットワーク内のサブネットの名前 |
| RUNTIME_VERSION | tpu-ubuntu2204-base |
| ACCELERATOR_TYPE | v4-16 |
| EXAMPLE_TAG_1, EXAMPLE_TAG_2 … | ネットワーク ファイアウォールの有効なソースやターゲットを識別するために使用されるタグ |
| SLICE_COUNT | スライス数。スライス数の上限は 256 です。 |
| STARTUP_SCRIPT | 作成リクエストに追加された場合、TPU スライスがプロビジョニングまたは再起動された場合は常に、また TPU スライスが修復またはリセットされた場合に、起動スクリプトを実行できます。 |
gcloud を使用して QR リクエストを作成する
$ gcloud compute tpus queued-resources \
create ${your-qr-id} \
--project your-project-id \
--zone your-zone \
--node-count ${SLICE_COUNT} \
--accelerator-type ${ACCELERATOR_TYPE} \
--runtime-version ${RUNTIME_VERSION} \
--network ${NETWORK_NAME} \
--subnetwork ${SUBNETWORK_NAME} \
--tags ${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script='${STARTUP_SCRIPT}'
[--reserved|--spot]
コマンドフラグの説明
your-qr-id- QR リクエストを識別するユーザー定義の文字列。
project- QR リクエストを識別するユーザー定義の文字列。
zone- QR を作成する Google Cloud ゾーン。
node-count- 作成するスライスの数。
accelerator-type- アクセラレータ タイプでは、作成する Cloud TPU のバージョンとサイズを指定します。TPU のバージョンごとにサポートされているアクセラレータ タイプの詳細については、TPU のバージョンをご覧ください。
runtime-version- Cloud TPU ソフトウェアのバージョン。
network- TPU リソースを接続する VPC ネットワークの名前。
subnetwork- TPU リソースを接続する VPC サブネットワークの名前。
reserved- スライスの作成時に予約割り当てを使用します。
spot- スライスの作成時に Spot VM の割り当てを使用します。
--reserved、--spot、またはデフォルトのオンデマンド割り当てを選択する前に、それぞれの割り当てがあることを確認してください。割り当てタイプの詳細については、割り当てポリシーをご覧ください。
curl を使用して QR リクエストを作成する
queued-resource-req.json という名前のファイルを作成して、次の JSON をコピーします。
{
"guaranteed": { "reserved": true },
"tpu": {
"node_spec": [
{
"parent": "projects/your-project-number/locations/your-zone",
"node": {
"accelerator_type": "accelerator-type",
"runtime_version": "tpu-vm-runtime-version",
"network_config": {
"network": "your-network-name",
"subnetwork": "your-subnetwork-name",
"enable_external_ips": true
},
"tags" : ["example-tag-1"]
"metadata": {
"startup-script": "your-startup-script"
}
},
"multi_node_params": {
"node_count": slice-count,
"node_id_prefix": "your-queued-resource-id"
}
}
]
}
}
- your-project-number - Google Cloud プロジェクト番号。
- your-zone - QR を作成するゾーン
- accelerator-type - 単一のスライスのバージョンとサイズ
- tpu-vm-runtime-version - TPU VM ランタイム バージョン
- your-network-name - 省略可。QR が接続されるネットワーク
- your-subnetwork-name - 省略可。QR が接続されるサブネットワーク
- example-tag-1 - 省略可。任意のタグ文字列
- your-startup-script - QR が割り当てられているときに実行される起動スクリプト
- slice-count - マルチスライス環境の TPU スライス数
- your-qr-id - ユーザーが QR に対して指定した ID
詳細については、利用可能なすべてのオプションに関する、REST キューに格納されたリソース API のドキュメントをご覧ください。
Spot の容量を使用するには、次のように置き換えます。
"spot": {}の"guaranteed": { "reserved": true }
行を削除して、デフォルトのオンデマンド容量を使用します。
JSON ペイロードとともに QR 作成リクエストを送信します。
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" -d @queuedresourcereq.json https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-qr-id
- your-project-id - Google Cloud プロジェクト ID。
- your-zone - QR を作成するゾーン
- your-qr-id - ユーザーが QR に対して指定した ID
レスポンスは次のようになります。
{
"name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>",
"metadata": {
"@type": "type.googleapis.com/google.cloud.common.OperationMetadata",
"createTime": "2023-11-01T00:17:05.742546311Z",
"target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>",
"verb": "create",
"cancelRequested": false,
"apiVersion": "v2alpha1"
},
"done": false
}
name 属性の文字列値の末尾にある GUID 値を使用して、QR リクエストに関する情報を取得します。
QR のステータスを取得する
QR リクエストのステータスを取得するには、次のコマンドを使用します。
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/operations/operation-your-qr-guid
- your-project-id - Google Cloud プロジェクト ID。
- your-zone - QR を作成するゾーン
- your-qr-guid - QR 作成リクエストからの出力にある
nameに続く GUID。
このコマンドのレスポンスには、オペレーションのステータスが含まれます。
{
"name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qa-guid>,
"metadata": {...},
"done": true,
"response": {
"@type": "type.googleapis.com/google.cloud.tpu.v2.QueuedResource",
...
"state": {
"state": "WAITING_FOR_RESOURCES"
}
}
}
QR が正常に作成された場合 ("done = true")、response フィールド内の状態は、WAITING_FOR_RESOURCES または FAILED のいずれかになります。QR の状態が WAITING_FOR_RESOURCES の場合、QR はキューに格納され、リソースがあるときにプロビジョニングが開始されます。QR が FAILED 状態の場合、失敗の理由が出力に表示されます。その他の可能性のある状態の詳細については、キューに格納されたリソースのユーザーガイドをご覧ください。
オペレーションが完了したら、describe QR を使用して QR のステージをモニタリングします。
まれに、QR が FAILED 状態である一方、一部のスライスが ACTIVE になる場合があります。その場合は、作成されたリソースを削除してから、数分後にもう一度試すか、Cloud TPU チームに連絡して、問題を解決します。
SSH と依存関係のインストール
TPU Pod スライスで JAX コードを実行するでは、単一スライスで SSH を使用して TPU VM に接続する方法について説明します。SSH 経由でマルチスライス環境内のすべての TPU VM に接続し、依存関係をインストールするには、次の gcloud コマンドを使用します。
$ gcloud compute tpus queued-resources ssh ${your-qr-id} \
--zone your-zone \
--node=all \
--worker=all \
--command="command-to-run"
--batch-size=4
この gcloud コマンドは、SSH を使用して QR 内のすべてのワーカーとノードに指定されたコマンドを送信します。このコマンドは、4 つのグループにバッチ化され、同時に送信されます。現在のバッチの実行が完了すると、コマンドの次のバッチが送信されます。いずれかのコマンドでエラーが発生すると、処理が停止し、以降のバッチは送信されません。詳細については、キューに格納されたリソースの API リファレンスをご覧ください。使用しているスライスの数がローカル コンピュータのスレッド制限(バッチ処理の制限とも呼ばれる)を超えると、デッドロックが発生します。たとえば、ローカルマシンのバッチ処理の上限が 64 であるとします。64 個を超えるスライス(100 など)でトレーニング スクリプトを実行しようとすると、SSH コマンドはスライスをバッチに分割します。64 スライスの最初のバッチでトレーニング スクリプトを実行し、スクリプトが完了するまで待ってから、残りの 36 スライスのバッチでスクリプトを実行します。ただし、64 個のスライスの最初のバッチは、残りの 36 個のスライスがスクリプトの実行を開始するまで完了できず、デッドロックが発生します。
このシナリオを回避するには、--command フラグで指定したスクリプト コマンドにアンパサンド(&)を追加することで、各 VM のバックグラウンドでトレーニング スクリプトを実行します。これを行う場合、スライスの最初のバッチでトレーニング スクリプトを開始すると、制御が直ちに SSH コマンドに戻ります。その後、SSH コマンドは、残りの 36 スライスのバッチに対してトレーニング スクリプトの実行を開始できます。バックグラウンドでコマンドを実行するときに、stdout ストリームと stderr ストリームを適切にパイプする必要があります。同じ QR 内の並列処理を増やすには、--node パラメータを使用して特定のスライスを選択します。
ネットワーク設定
次の手順を実行して、TPU スライスが相互に通信できるようにします。
各スライスに JAX をインストールします。 詳細については、Cloud TPU Pod スライスで JAX コードを実行するをご覧ください。len(jax.devices()) がマルチスライス環境のチップ数と等しいことをアサートします。この操作を行うには、各スライスで次のコマンドを実行します。
$ python3 -c 'import jax; print(jax.devices())'
このコードを v4-16 の 4 つのスライスで実行する場合、スライスごとに 8 つのチップと 4 つのスライスがあり、合計 32 チップ(デバイス)が jax.devices() によって返されます。
QR を一覧表示する
QR の状態を表示するには、queued-resources list コマンドを使用します。
$ gcloud compute tpus queued-resources list
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE
...
que-res-id us-central2-b 4 v4-16 ACTIVE
...
QR を説明する
QR の詳細な構成と状態を表示するには、describe QR API を使用します。この API を呼び出すには、gcloud または curl を使用します。
使用中: gcloud
$ gcloud compute tpus queued-resources describe ${your-qr-id}
...state:
state: ACTIVE
...
使用中: curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${your-qr-id}
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
state は、QR のステータスを表します。QR のステータスの詳細については、キューに格納されたリソースをご覧ください。
プロビジョニングされた環境でジョブを開始する
SSH 経由で各スライス内のすべてのホストに接続し、すべてのホストで次のコマンドを実行して、ワークロードを手動で実行できます。
$ gcloud compute tpus tpu-vm ssh your-qr-id \
--zone=your-zone \
--worker=all \
--node=all \
--command="command-to-run"
QR のリセット
ResetQueuedResource API を使用すると、ACTIVE QR 内のすべての VM をリセットできます。VM をリセットすると、マシンのメモリが強制的に消去され、VM は初期状態にリセットされます。ローカルに格納されているデータはそのまま残り、リセット後に起動スクリプトが呼び出されます。ResetQueuedResource API は、すべての TPU を再起動する場合に役立ちます。たとえば、トレーニングが停止し、すべての VM をリセットするほうが、デバッグするよりも簡単です。
すべての VM のリセットは並行して実行され、ResetQueuedResource オペレーションが完了するまでに 1 ~ 2 分かかります。API を呼び出すには、次のコマンドを使用します。
$ gcloud compute tpus queued-resources reset your-qr-id
QR の削除
トレーニング セッションの最後にリソースを解放するには、--force フラグを指定して、キューに格納されたリソースを削除します。削除が完了するまでに 2 ~ 5 分かかります。オプションの --async フラグを指定してバックグラウンドで実行できます。
$ gcloud compute tpus queued-resources \
delete your-qr-id --force (--async)
障害からの自動回復
停止した場合、マルチスライスでは、影響を受けたスライスを介入なしで修復し、その後、すべてのスライスをリセットできます。影響を受けたスライスが新しいスライスに置き換えられ、残りの正常なスライスがリセットされます。置き換えるスライスを割り当てるための容量がない場合、トレーニングは停止します。
中断後にトレーニングを自動的に再開するには、最後に保存されたチェックポイントを確認して読み込む起動スクリプトを指定する必要があります。起動スクリプトは、スライスが再割り当てされるか、VM がリセットされるたびに自動的に実行されます。create QR request API に送信する JSON ペイロードで起動スクリプトを指定します。
次の起動スクリプト(QR を作成するで使用)を使用すると、MaxText トレーニング中に、障害から自動的に回復し、Cloud Storage バケットに保存されているチェックポイントからトレーニングを再開できます。
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 MaxText/train.py MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
これを試す前に、MaxText リポジトリのクローンを作成してください。
プロファイリングとデバッグ
プロファイリングは、シングル スライス環境とマルチスライス環境で同じです。詳細については、JAX プログラムのプロファイリングをご覧ください。
研修を最適化する
最大パフォーマンスのためのマルチスライスを使用したシャーディング
マルチスライス環境で最大のパフォーマンスを実現するには、複数のスライス間でシャーディングする方法を検討する必要があります。通常は 3 つの選択肢(データ並列処理、完全にシャーディングされたデータ並列処理、パイプライン並列処理)があります。モデル間ディメンション(テンソル並列処理とも呼ばれます)全体で活性化をシャーディングすることはおすすめしません。スライス間帯域幅が大きすぎるためです。 上記のどの戦略でも、過去にうまくいったスライス内で同じシャーディング戦略を使用できます。
純粋なデータ並列処理から始めることをおすすめします。完全にシャーディングされたデータ並列処理を使用すると、メモリ使用量を解放できます。ただし、スライス間の通信で DCN ネットワークを使用するため、ワークロードが遅くなるという欠点があります。パイプラインの並列処理は、バッチサイズに基づいて必要な場合にのみ使用します(以下の分析をご覧ください)。
データ並列処理を使用する場面
純粋なデータ並列処理は、ワークロードが正常に動作しているものの、複数のスライスにわたってスケーリングしてパフォーマンスを向上させる場合に適しています。
複数のスライスで強力なスケーリングを行うには、DCN 全体で all-reduce を実行するために必要な時間が、バックワードパスを実行するために必要な時間よりも短くなければなりません。DCN はスライス間の通信に使用され、ワークロードのスループットを制限する要因です。
各 v4 TPU チップは、ピーク時に 275 x 1012 FLOPS/秒で動作します。
TPU ホストごとに 4 つのチップがあり、各ホストの最大ネットワーク帯域幅は 50 Gbps です。
つまり、算術強度は 4 × 275 × 10 12 FLOPS ÷ 50 Gbps = 22000 FLOPS / ビットです。
モデルでは、ステップごとに各パラメータに 32 ~ 64 ビットの DCN 帯域幅が使用されます。 2 つのスライスを使用する場合、モデルは 32 ビットの DCN 帯域幅を使用します。3 つ以上のスライスを使用する場合、コンパイラによって完全なシャッフル all-reduce オペレーションが実行され、ステップごとに各パラメータに対して最大 64 ビットの DCN 帯域幅が使用されます。各パラメータに必要な FLOPS の量は、モデルによって異なります。具体的には、Transformer ベースの言語モデルの場合、フォワードパスとバックワードパスに必要な FLOPS の数は約 6 x B x P です。ここで、
- B はトークンのバッチサイズ
- P はパラメータの数
パラメータあたりの FLOPS の数は 6 * B で、バックワードパス中のパラメータあたりの FLOPS の数は 4 * B です。
複数のスライス間で強力なスケーリングを行うには、動作の強度が TPU ハードウェアの算術強度を超えることを確認します。動作の強度を計算するには、バックワードパス中のパラメータあたりの FLOPS 数を、1 ステップあたりの各パラメータごとのネットワーク帯域幅(ビット数)で割ります。
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
したがって、Transformer ベースの言語モデルの場合、2 つのスライスを使用する場合は次のようになります。
Operational intensity = 4 * B / 32
3 つ以上のスライスを使用する場合: Operational intensity = 4 * B/64
これにより、Transformer ベースの言語モデルの最小バッチサイズは 176,000 ~ 352,000 になります。DCN ネットワークは一時的にパケットをドロップできるため、Pod あたりのバッチサイズが 350, 000(2 つの Pod)以上で 700, 000(多数の Pod)の場合にのみ、データの並列処理をデプロイしてデータの並列処理を行うことをおすすめします。
他のモデルのアーキテクチャでは、(プロファイラを使用してタイミングを設定するか、FLOPS をカウントして)スライスあたりのバックワードパスのランタイムを推定する必要があります。その後、DCN 全体の短縮を行うため、予想される実行時間と比較して、データ並列処理が有効かどうかを正確に見積もることができます。
完全にシャーディングされたデータ並列処理(FSDP)を使用する場面
完全にシャーディングされたデータ並列処理(FSDP)は、データ並列処理(ノード間でのデータのシャーディング)とノード間の重みのシャーディングを組み合わせたものです。フォワードパスとバックワードパスのオペレーションごとに、すべてのスライスが all-gather され、各スライスに必要な重みが付けられます。all-reduce を使用して勾配を同期させる代わりに、勾配を生成するときに、reduce-scatter が行われます。このようにして、各スライスは担当する重みの勾配のみを取得します。
データ並列処理と同様に、FSDP では、スライス数に比例してグローバル バッチサイズをスケーリングする必要があります。スライスの数を増やすと、FSDP によりメモリの負荷が軽減されます。これは、スライスあたりの重みとオプティマイザーの状態の数が減少しても、ネットワーク トラフィックの増大と、遅延によるブロックの可能性が増大するためです。
実際には、スライスあたりのバッチ数を増やす場合、バックワードパス中の再実体化を最小限に抑えるためにより多くのアクティベーションを保存する場合、またはニューラル ネットワークのパラメータ数を増やす場合に、スライス間の FSDP が最適です。
FSDP の all-gather オペレーションと all-reduce オペレーションが DP のオペレーションと同様に機能するため、前のセクションで説明したのと同じ方法で、FSDP ワークロードが DCN のパフォーマンスによって制限されているかどうかを判断できます。
パイプラインの並列処理を使用する場面
パイプラインの並列処理は、優先される最大バッチサイズよりも大きいグローバル バッチサイズを必要とする別の並列処理戦略で高いパフォーマンスを達成するときに重要になります。パイプラインの並列処理により、パイプラインを構成するスライスがバッチを「共有」できます。ただし、パイプラインの並列処理には 2 つの大きなデメリットがあります。
- チップがデータを待機しているため、アイドル状態になる「パイプライン バブル」が発生します。
- 効果的なバッチサイズ、算術強度を低減し、最終的には FLOP 使用率をモデル化するマイクロバッチ処理を必要とします。
パイプラインの並列処理は、他の並列処理戦略で必要とされるグローバル バッチサイズが大きくなりすぎる場合にのみ使用してください。パイプラインの並列処理を試す前に、高パフォーマンスの FSDP を達成するために必要なバッチサイズでサンプルあたりの収束が低下するかどうかを実験的に確認することをおすすめします。FSDP ではモデルの FLOP 使用率が高くなる傾向がありますが、バッチサイズが大きくなるにつれてサンプルあたりの収束が遅くなる場合は、パイプラインの並列処理が適している可能性があります。ほとんどのワークロードは、パイプラインの並列処理のメリットを享受できないほど大きなバッチサイズを許容できますが、ワークロードによって異なる場合があります。
パイプラインの並列処理が必要な場合は、データ並列処理または FSDP と組み合わせることをおすすめします。これにより、DCN レイテンシがスループットの要因にならない程度まで、パイプラインごとのバッチサイズを増やしながら、パイプラインの深さを最小限に抑えることができます。具体的には、N 個のスライスがある場合は、深さ 2 のパイプラインとデータ並列処理の N/2 のレプリカを検討し、次に深さ 4 のパイプラインとデータ並列処理の N/4 のレプリカを検討するなど、DCN 集合をバックワードパス内の算術の背後に隠すことができるほど、パイプラインあたりのバッチが十分大きくなるまで続けます。これにより、パイプラインの並列処理による速度低下が最小限に抑えられ、グローバル バッチサイズの上限を超えてスケーリングできます。
マルチスライスのベスト プラクティス
データ読み込み
トレーニング中は、データセットからバッチを繰り返し読み込み、モデルにフィードします。作業の TPU が不足しないように、ホスト間でバッチをシャーディングする効率的な非同期データローダーを用意することが重要です。MaxText の現在のデータローダーでは、各ホストがサンプルの同等サブセットを読み込みます。このソリューションはテキストには適していますが、モデル内で再シャーディングが必要です。また、MaxText では、データ イテレータがプリエンプションの前後に同じデータを読み込むことができる決定的スナップショットはまだ提供されていません。
チェックポインティング
Orbax チェックポインティング ライブラリは、JAX PyTrees をローカル ストレージまたは Google Cloud ストレージにチェックポインティングするためのプリミティブを提供します。checkpointing.py では、MaxText への同期チェックポインティングを備えたリファレンスのインテグレーションが提供されます。
サポートされている構成
図形
すべてのスライスが同じ形状(たとえば同じ AcceleratorType)である必要があります。
異種スライス形状はサポートされていません。
オーケストレーション
オーケストレーションは GKE でサポートされています。詳細については、GKE の TPU をご覧ください。
フレームワーク
マルチスライスは、JAX と PyTorch のワークロードのみをサポートしています。
並列処理
データ並列処理でマルチスライスをテストすることをおすすめします。マルチスライスを使用したパイプラインの並列処理の実装の詳細については、Google Cloud のアカウント担当者にお問い合わせください。
サポートとフィードバック
フィードバックをぜひお寄せください。フィードバックを共有したり、サポートをリクエストしたりするには、Cloud TPU サポートまたはフィードバック フォームを使用してご連絡ください。