Guia avançado do Inception v3
Neste documento, discutimos aspectos do modelo Inception e como eles são combinados para que o modelo seja executado de maneira eficiente no Cloud TPU. Trata-se de uma visualização avançada do guia para executar o Inception v3 no Cloud TPU. Alterações específicas no modelo que levaram a melhorias significativas são discutidas em mais detalhes. Este documento complementa o tutorial do Inception v3.
O treinamento de TPU do Inception v3 executa curvas de precisão de correspondência produzidas por jobs de GPU com configuração semelhante. O modelo foi treinado com êxito nas configurações v2-8, v2-128 e v2-512. O modelo atingiu uma precisão superior a 78,1% em cerca de 170 épocas.
Os exemplos de código contidos neste documento são ilustrativos, uma imagem de alto nível do que acontece em uma implementação real. O código de trabalho pode ser encontrado no GitHub.
Introdução
O Inception v3 é um modelo de reconhecimento de imagem que demonstrou ter mais de 78,1% de precisão no conjunto de dados do ImageNet. Esse modelo é o auge de muitas ideias desenvolvidas por vários pesquisadores ao longo dos anos. Ele é baseado no documento original "Rethinking the Inception Architecture for Computer Vision", de Szegedy e outros autores.
O modelo em si é composto por elementos básicos simétricos e assimétricos, incluindo convoluções, pooling médio, pool máximo, concatenações, dropouts e camadas totalmente conectadas. A normalização em lote é usada extensivamente em todo o modelo e aplicada às entradas de ativação. A perda é calculada usando a função Softmax.
Confira um diagrama detalhado do modelo na captura de tela a seguir:
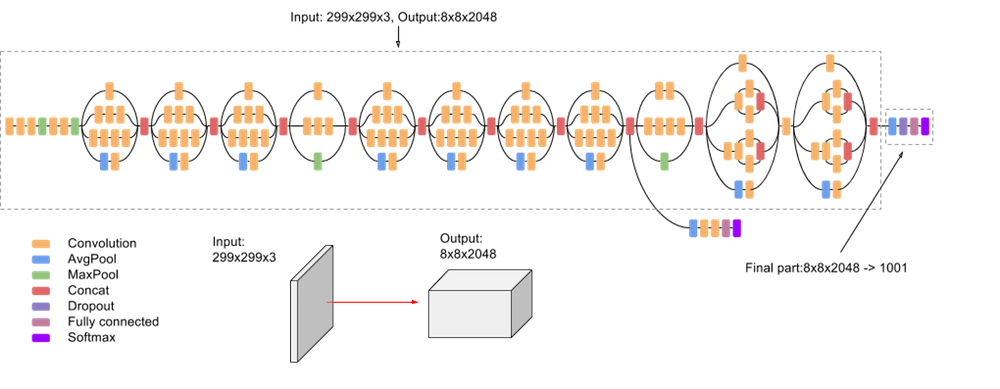
API Estimator
Para gravar a versão de TPU do Inception v3 é necessário usar a TPUEstimator, uma API projetada para facilitar o desenvolvimento, para que você possa se concentrar nos modelos em vez de nos detalhes do hardware subjacente. A API faz a maior parte do trabalho sujo de baixo nível necessário para executar os modelos nas TPUs em segundo plano, ao mesmo tempo em que automatiza funções comuns, como salvar e restaurar os pontos de verificação.
A API Estimator impõe a separação entre o modelo e as partes relativas à entrada no código.
Defina as funções model_fn e input_fn, correspondentes à definição do modelo e ao pipeline de entrada. O código a seguir mostra a declaração dessas
funções:
def model_fn(features, labels, mode, params):
…
return tpu_estimator.TPUEstimatorSpec(mode=mode, loss=loss, train_op=train_op)
def input_fn(params):
def parser(serialized_example):
…
return image, label
…
images, labels = dataset.make_one_shot_iterator().get_next()
return images, labels
Duas funções principais fornecidas pela API são train() e evaluate(), usadas para treinar e avaliar, conforme mostrado no código a seguir:
def main(unused_argv):
…
run_config = tpu_config.RunConfig(
master=FLAGS.master,
model_dir=FLAGS.model_dir,
session_config=tf.ConfigProto(
allow_soft_placement=True, log_device_placement=True),
tpu_config=tpu_config.TPUConfig(FLAGS.iterations, FLAGS.num_shards),)
estimator = tpu_estimator.TPUEstimator(
model_fn=model_fn,
use_tpu=FLAGS.use_tpu,
train_batch_size=FLAGS.batch_size,
eval_batch_size=FLAGS.batch_size,
config=run_config)
estimator.train(input_fn=input_fn, max_steps=FLAGS.train_steps)
eval_results = inception_classifier.evaluate(
input_fn=imagenet_eval.input_fn, steps=eval_steps)
Conjunto de dados ImageNet
Antes que o modelo possa ser usado para reconhecer imagens, ele precisa ser treinado usando um grande conjunto de imagens rotuladas. O ImageNet é um conjunto de dados comum a ser usado.
O ImageNet tem mais de dez milhões de URLs de imagens rotuladas. Um milhão das imagens também tem caixas delimitadoras que especificam um local mais preciso para os objetos rotulados.
Para esse modelo, o conjunto de dados ImageNet é composto de 1.331.167 imagens que são divididas em conjuntos de dados de treinamento e avaliação contendo, respectivamente, 1.281.167 e 50.000 imagens.
Os conjuntos de dados de treinamento e avaliação são intencionalmente mantidos separados. Usamos as imagens do conjunto de dados de treinamento para treinar o modelo e as do conjunto de dados de avaliação para avaliar a precisão dele.
Para o modelo, as imagens devem ser armazenadas como TFRecords. Para mais informações sobre
como converter imagens de arquivos JPEG brutos em TFRecords, consulte download_and_preprocess_imagenet.sh.
Canal de entrada
Cada dispositivo do Cloud TPU tem oito núcleos e está conectado a um host (CPU). As partes maiores têm vários hosts. Outras configurações maiores interagem com vários hosts. Por exemplo, um v2-256 se comunica com 16 hosts.
Os hosts recuperam os dados do sistema de arquivos ou da memória local, fazem operações necessárias de pré-processamento de dados e, por fim, transferem os dados pré-processados para os núcleos da TPU. Essas três fases de gerenciamento de dados realizado pelo host são consideradas individualmente e recebem os nomes de: 1) armazenamento, 2) pré-processamento e 3) transferência. Veja na figura a seguir uma imagem de alto nível do diagrama:
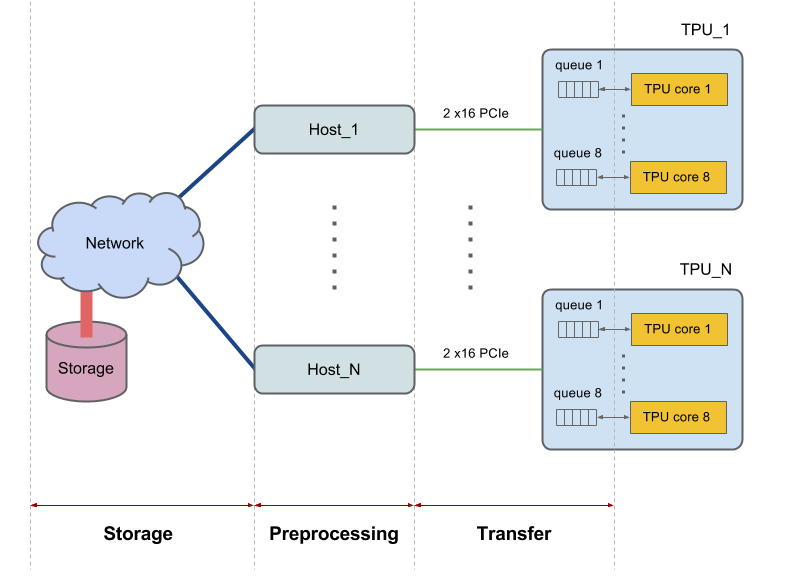
Para que o desempenho seja bom, o sistema deve ser balanceado. Se a CPU host demorar mais que a TPU para concluir as três fases de tratamento de dados, a execução será limitada pelo host. Ambos os casos são mostrados no diagrama a seguir:
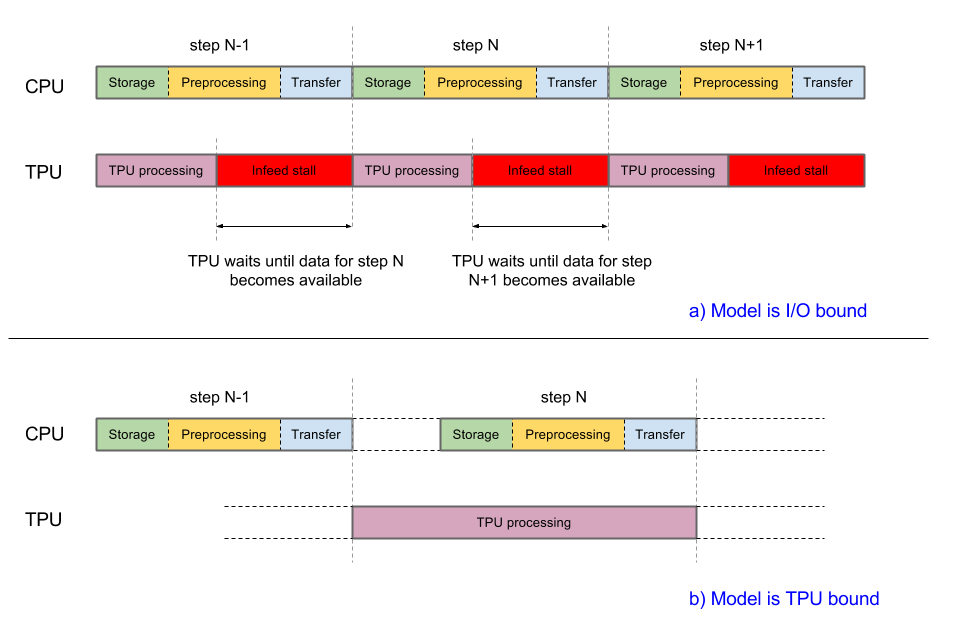
A implementação atual do Inception v3 está prestes a ser limitada pela entrada. As imagens são recuperadas do sistema de arquivos, decodificadas e pré-processadas. Diferentes tipos de estágios de pré-processamento estão disponíveis, de moderado a complexo. Se usarmos o estágio de pré-processamento mais complexo, o pipeline de treinamento será limitado pelo pré-processamento. É possível atingir uma precisão maior que 78,1% usando um estágio de pré-processamento moderadamente complexo que mantém o modelo vinculado à TPU.
O modelo usa tf.data.Dataset para processar o processamento do pipeline de entrada. Para mais informações sobre como otimizar pipelines de entrada, consulte o guia de desempenho de conjuntos de dados.
Embora você possa definir uma função e transmiti-la para a API Estimator, a classe
InputPipeline encapsula todos os recursos necessários.
A API Estimator simplifica o uso dessa classe. Você o transmite para o
parâmetro input_fn das funções train() e evaluate(), conforme mostrado no
snippet de código abaixo:
def main(unused_argv):
…
inception_classifier = tpu_estimator.TPUEstimator(
model_fn=inception_model_fn,
use_tpu=FLAGS.use_tpu,
config=run_config,
params=params,
train_batch_size=FLAGS.train_batch_size,
eval_batch_size=eval_batch_size,
batch_axis=(batch_axis, 0))
…
for cycle in range(FLAGS.train_steps // FLAGS.train_steps_per_eval):
tf.logging.info('Starting training cycle %d.' % cycle)
inception_classifier.train(
input_fn=InputPipeline(True), steps=FLAGS.train_steps_per_eval)
tf.logging.info('Starting evaluation cycle %d .' % cycle)
eval_results = inception_classifier.evaluate(
input_fn=InputPipeline(False), steps=eval_steps, hooks=eval_hooks)
tf.logging.info('Evaluation results: %s' % eval_results)
Os principais elementos do InputPipeline são mostrados no snippet de código abaixo.
class InputPipeline(object):
def __init__(self, is_training):
self.is_training = is_training
def __call__(self, params):
# Storage
file_pattern = os.path.join(
FLAGS.data_dir, 'train-*' if self.is_training else 'validation-*')
dataset = tf.data.Dataset.list_files(file_pattern)
if self.is_training and FLAGS.initial_shuffle_buffer_size > 0:
dataset = dataset.shuffle(
buffer_size=FLAGS.initial_shuffle_buffer_size)
if self.is_training:
dataset = dataset.repeat()
def prefetch_dataset(filename):
dataset = tf.data.TFRecordDataset(
filename, buffer_size=FLAGS.prefetch_dataset_buffer_size)
return dataset
dataset = dataset.apply(
tf.contrib.data.parallel_interleave(
prefetch_dataset,
cycle_length=FLAGS.num_files_infeed,
sloppy=True))
if FLAGS.followup_shuffle_buffer_size > 0:
dataset = dataset.shuffle(
buffer_size=FLAGS.followup_shuffle_buffer_size)
# Preprocessing
dataset = dataset.map(
self.dataset_parser,
num_parallel_calls=FLAGS.num_parallel_calls)
dataset = dataset.prefetch(batch_size)
dataset = dataset.apply(
tf.contrib.data.batch_and_drop_remainder(batch_size))
dataset = dataset.prefetch(2) # Prefetch overlaps in-feed with training
images, labels = dataset.make_one_shot_iterator().get_next()
# Transfer
return images, labels
A seção storage começa com a criação de um conjunto de dados e inclui a leitura de TFRecords do armazenamento (usando tf.data.TFRecordDataset). As funções de finalidade especial repeat() e shuffle() são usadas conforme necessário. A função tf.contrib.data.parallel_interleave() mapeia a função prefetch_dataset() para a entrada dela a fim de produzir conjuntos de dados aninhados e gera os elementos intercalados. Ela recebe elementos dos conjuntos de dados aninhados cycle_length em paralelo, o que aumenta a capacidade. O argumento sloppy flexibiliza o requisito de que as saídas sejam produzidas em uma ordem determinística e permite que a implementação ignore conjuntos de dados aninhados cujos elementos não estejam disponíveis quando solicitados.
A seção preprocessing chama dataset.map(parser), que por sua vez chama a função do analisador em que as imagens são pré-processadas. Discutiremos os detalhes do estágio de pré-processamento na próxima seção.
A seção transfer (no final da função) inclui a linha return images, labels. A TPUEstimator pega os valores retornados e os transfere automaticamente para o dispositivo.
A figura a seguir mostra um exemplo de rastreamento de desempenho do Cloud TPU do Inception v3. O tempo de computação da TPU, ignorando as interrupções de alimentação, é de aproximadamente 815 ms.
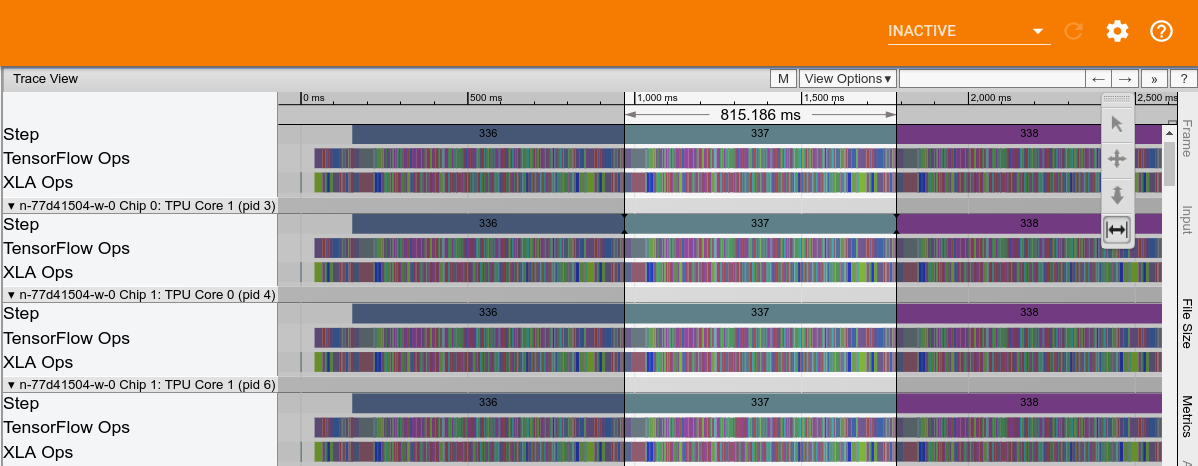
O armazenamento no host é gravado no trace e mostrado na captura de tela a seguir:

O pré-processamento do host, que inclui a decodificação de imagens e uma série de funções de distorção de imagem, é mostrado na captura de tela a seguir:

A transferência entre o host e a TPU é mostrada na seguinte captura de tela:

Estágio de pré-processamento
O pré-processamento de imagem é uma parte crucial do sistema e pode influenciar a acurácia máxima que o modelo alcança durante o treinamento. No mínimo, as imagens precisam ser decodificadas e redimensionadas para se ajustarem ao modelo. No Inception, as imagens precisam ter 299x299x3 pixels.
No entanto, simplesmente decodificar e redimensionar não é suficiente para obter uma boa precisão. O conjunto de dados de treinamento ImageNet contém 1.281.167 imagens. Uma passagem pelo conjunto de imagens de treinamento é chamada de uma época. Durante o treinamento, o modelo exige várias passagens pelo conjunto de dados de treinamento para melhorar os recursos de reconhecimento de imagens. Para treinar o Inception v3 com precisão suficiente, use entre 140 e 200 períodos, dependendo do tamanho global do lote.
É útil alterar continuamente as imagens antes de alimentá-las ao modelo para que uma imagem específica seja ligeiramente diferente em cada época. A melhor maneira de fazer esse pré-processamento de imagens é tanto arte quanto ciência. Um estágio de pré-processamento bem projetado pode aumentar significativamente os recursos de reconhecimento de um modelo. Um estágio de pré-processamento muito simples pode criar um teto artificial na acurácia que o mesmo modelo pode atingir durante o treinamento.
O Inception v3 oferece opções para o estágio de pré-processamento, desde que são relativamente simples e econômicos em termos computacionais até complexos e caros do ponto de vista computacional. Você pode encontrar dois tipos distintos desses estágios nos arquivos vgg_preprocessing.py e inception_preprocessing.py.
O arquivo vgg_preprocessing.py define um estágio de pré-processamento que foi usado para treinar resnet com 75% de acurácia, mas produz resultados abaixo do ideal quando aplicado ao Inception v3.
O arquivo inception_preprocessing.py contém um estágio de pré-processamento que foi usado para treinar o Inception v3 com precisão entre 78,1 e 78,5% quando executado em TPUs.
O pré-processamento varia dependendo se o modelo está em treinamento ou é usado para inferência/avaliação.
No momento da avaliação, o pré-processamento é simples: corte uma região central da imagem e a redimensione para o tamanho padrão de 299 x 299. O snippet de código a seguir mostra uma implementação de pré-processamento:
def preprocess_for_eval(image, height, width, central_fraction=0.875):
with tf.name_scope(scope, 'eval_image', [image, height, width]):
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.image.central_crop(image, central_fraction=central_fraction)
image = tf.expand_dims(image, 0)
image = tf.image.resize_bilinear(image, [height, width], align_corners=False)
image = tf.squeeze(image, [0])
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
image.set_shape([height, width, 3])
return image
Durante o treinamento, o corte é aleatório: uma caixa delimitadora é escolhida aleatoriamente para selecionar uma região da imagem que, em seguida, é redimensionada. Depois, a imagem redimensionada pode opcionalmente ser invertida e ter as cores distorcidas. O snippet de código a seguir mostra uma implementação dessas operações:
def preprocess_for_train(image, height, width, bbox, fast_mode=True, scope=None):
with tf.name_scope(scope, 'distort_image', [image, height, width, bbox]):
if bbox is None:
bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4])
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
distorted_image, distorted_bbox = distorted_bounding_box_crop(image, bbox)
distorted_image.set_shape([None, None, 3])
num_resize_cases = 1 if fast_mode else 4
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, method: tf.image.resize_images(x, [height, width], method),
num_cases=num_resize_cases)
distorted_image = tf.image.random_flip_left_right(distorted_image)
if FLAGS.use_fast_color_distort:
distorted_image = distort_color_fast(distorted_image)
else:
num_distort_cases = 1 if fast_mode else 4
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, ordering: distort_color(x, ordering, fast_mode),
num_cases=num_distort_cases)
distorted_image = tf.subtract(distorted_image, 0.5)
distorted_image = tf.multiply(distorted_image, 2.0)
return distorted_image
A função distort_color é responsável pela alteração de cor. Ela oferece um modo rápido em que apenas o brilho e a saturação são modificados. O modo completo modifica
o brilho, a saturação e a matiz em ordem aleatória.
def distort_color(image, color_ordering=0, fast_mode=True, scope=None):
with tf.name_scope(scope, 'distort_color', [image]):
if fast_mode:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
else:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
else:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
elif color_ordering == 1:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
elif color_ordering == 2:
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
elif color_ordering == 3:
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
return tf.clip_by_value(image, 0.0, 1.0)
A função distort_color é cara em termos de computação, em parte devido às conversões não lineares de RGB em HSV e de HSV em RGB, que são necessárias para acessar o matiz e a saturação. Tanto o modo rápido quanto o completo requerem essas conversões. O modo rápido é mais econômico em termos computacionais, mas mesmo assim ele empurra o modelo para a região limitada por computação da CPU quando ativado.
Como alternativa, uma nova função distort_color_fast foi adicionada à lista de opções. Essa função mapeia a imagem de RGB para YCrCb usando o esquema de conversão de JPEG e altera aleatoriamente o brilho e os cromos de Cr/Cb antes de remapear para RGB. O snippet de código abaixo mostra uma implementação dessa função:
def distort_color_fast(image, scope=None):
with tf.name_scope(scope, 'distort_color', [image]):
br_delta = random_ops.random_uniform([], -32./255., 32./255., seed=None)
cb_factor = random_ops.random_uniform(
[], -FLAGS.cb_distortion_range, FLAGS.cb_distortion_range, seed=None)
cr_factor = random_ops.random_uniform(
[], -FLAGS.cr_distortion_range, FLAGS.cr_distortion_range, seed=None)
channels = tf.split(axis=2, num_or_size_splits=3, value=image)
red_offset = 1.402 * cr_factor + br_delta
green_offset = -0.344136 * cb_factor - 0.714136 * cr_factor + br_delta
blue_offset = 1.772 * cb_factor + br_delta
channels[0] += red_offset
channels[1] += green_offset
channels[2] += blue_offset
image = tf.concat(axis=2, values=channels)
image = tf.clip_by_value(image, 0., 1.)
return image
Abaixo, temos um exemplo de imagem que foi submetida ao pré-processamento. Uma região da imagem escolhida aleatoriamente foi selecionada e as cores alteradas usando a função distort_color_fast.

A função distort_color_fast é eficiente em termos de computação e ainda permite que o treinamento seja limitado ao tempo de execução da TPU. Além disso, ela tem sido usada para treinar o modelo Inception v3 com uma precisão superior a 78,1% usando tamanhos de lote na faixa de 1.024 a 16.384.
Otimizador
O modelo atual apresenta três opções de otimizador: SGD, momentum e RMSProp.
Stochastic gradient descent (SGD) é a atualização mais simples: os pesos são empurrados na direção do gradiente negativo. Ainda que simples, esse tipo consegue bons resultados em alguns modelos. A dinâmica de atualização pode ser escrita como:
O Momentum é um otimizador conhecido que frequentemente leva a uma convergência mais rápida do que o GDE. Esse otimizador atualiza pesos como o SGD, mas também adiciona um componente na direção da atualização anterior. As equações a seguir descrevem as atualizações realizadas pelo otimizador de momentum:
que pode ser escrita como:
O último termo é o componente na direção da atualização anterior.
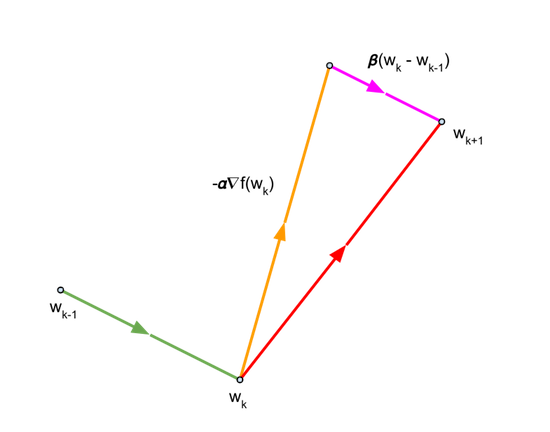
Para o momentum \({\beta}\), usamos o valor de 0,9.
RMSprop é um otimizador muito usado proposto pela primeira vez por Geoff Hinton em uma de suas palestras. As equações a seguir descrevem como o otimizador funciona:
No caso do Inception v3, os testes mostram que o RMSProp gera os melhores resultados em termos de precisão máxima e tempo para atingi-la, com momentum em segundo lugar. Portanto, o RMSprop é configurado como o otimizador padrão. Os parâmetros utilizados são: decay \({\alpha}\) = 0.9, momentum \({\beta}\) = 0.9 e \({\epsilon}\) = 1.0.
O snippet de código a seguir mostra como definir esses parâmetros:
if FLAGS.optimizer == 'sgd':
tf.logging.info('Using SGD optimizer')
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate)
elif FLAGS.optimizer == 'momentum':
tf.logging.info('Using Momentum optimizer')
optimizer = tf.train.MomentumOptimizer(
learning_rate=learning_rate, momentum=0.9)
elif FLAGS.optimizer == 'RMS':
tf.logging.info('Using RMS optimizer')
optimizer = tf.train.RMSPropOptimizer(
learning_rate,
RMSPROP_DECAY,
momentum=RMSPROP_MOMENTUM,
epsilon=RMSPROP_EPSILON)
else:
tf.logging.fatal('Unknown optimizer:', FLAGS.optimizer)
Ao executar em TPUs e usar a API Estimator, o otimizador precisa ser agrupado em uma função CrossShardOptimizer para assegurar a sincronização entre as réplicas (com qualquer comunicação cruzada necessária). O snippet de código a seguir mostra como o modelo Inception v3 une o otimizador:
if FLAGS.use_tpu:
optimizer = tpu_optimizer.CrossShardOptimizer(optimizer)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss, global_step=global_step)
Média móvel exponencial
Durante o treinamento, os parâmetros treináveis são atualizados durante a retropropagação de acordo com as regras de atualização do otimizador. As equações que descrevem essas regras foram discutidas na seção anterior e repetidas aqui por conveniência:
A média móvel exponencial (também conhecida como suavização exponencial) é uma etapa de pós-processamento opcional aplicada aos pesos atualizados e, às vezes, pode levar a melhorias perceptíveis no desempenho. O TensorFlow fornece a função tf.train.ExponentialMovingAverage que calcula a média móvel exponencial \({\ hat {\ theta}} \) de peso \({\ theta} \) usando a fórmula:
em que \({\alpha}\) é um fator de decaimento (próximo a 1,0). No modelo Inception v3, \({\alpha}\) está definido como 0,995.
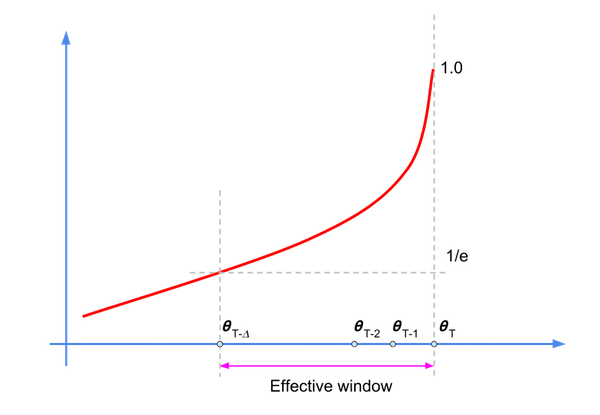
Embora esse cálculo seja um filtro de Resposta ao Impulso Infinita (IIR, na sigla em inglês), o fator de decaimento estabelece uma janela efetiva em que reside a maior parte da energia (ou amostras relevantes), conforme mostrado no diagrama a seguir:
Podemos reescrever a equação do filtro desta forma:
em que usamos\({\hat\theta_{-1}}=0\).
Os valores de \({\alpha}^k\) decaem com o aumento de k. Portanto, apenas um subconjunto das amostras terá uma influência considerável sobre \(\hat{\theta}_{t+T+1}\). A regra geral para o valor do fator de decaimento é: \(\frac {1} {1-\alpha}\), que corresponde a \({\alpha}\) = 200 para =0,995.
Primeiro, recebemos uma coleção de variáveis treináveis e, em seguida, usamos o método apply()
para criar variáveis sombra para cada variável treinada.
O snippet de código a seguir mostra a implementação do modelo Inception v3:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss, global_step=global_step)
if FLAGS.moving_average:
ema = tf.train.ExponentialMovingAverage(
decay=MOVING_AVERAGE_DECAY, num_updates=global_step)
variables_to_average = (tf.trainable_variables() +
tf.moving_average_variables())
with tf.control_dependencies([train_op]), tf.name_scope('moving_average'):
train_op = ema.apply(variables_to_average)
Queremos usar as variáveis de média móvel exponencial durante a avaliação. Definimos
a classe LoadEMAHook que aplica o método variables_to_restore() ao
arquivo de checkpoint a ser avaliado usando os nomes de variáveis sombra:
class LoadEMAHook(tf.train.SessionRunHook):
def __init__(self, model_dir):
super(LoadEMAHook, self).__init__()
self._model_dir = model_dir
def begin(self):
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY)
variables_to_restore = ema.variables_to_restore()
self._load_ema = tf.contrib.framework.assign_from_checkpoint_fn(
tf.train.latest_checkpoint(self._model_dir), variables_to_restore)
def after_create_session(self, sess, coord):
tf.logging.info('Reloading EMA...')
self._load_ema(sess)
A função hooks é transmitida para evaluate(), conforme mostrado no snippet de código a seguir:
if FLAGS.moving_average:
eval_hooks = [LoadEMAHook(FLAGS.model_dir)]
else:
eval_hooks = []
…
eval_results = inception_classifier.evaluate(
input_fn=InputPipeline(False), steps=eval_steps, hooks=eval_hooks)
Normalização em lote
A normalização em lote é uma técnica amplamente usada para normalizar as características de entrada em modelos, podendo resultar na redução substancial do tempo de convergência. Essa é uma das melhorias algorítmicas mais úteis e utilizadas no aprendizado de máquina nos últimos anos. Ela é aplicada a uma ampla gama de modelos, incluindo o Inception v3.
As entradas de ativação são normalizadas subtraindo a média e dividindo pelo desvio padrão. Para manter tudo equilibrado em vista da retropropagação, dois parâmetros treináveis são introduzidos em cada camada. As saídas normalizadas \({\hat{x}}\) passam por uma operação subsequente \({\gamma\hat{x}}+\beta\), em que \({\gamma}\) e \({\beta}\) são um tipo de desvio padrão e média aprendidos pelo próprio modelo.
Você pode ver o conjunto completo de equações neste artigo. Para sua comodidade, também as repetimos aqui:
Entrada: valores de x em um minilote: \(\Phi=\{ {x_{1..m}\} }\) Parâmetros a serem aprendidos: \({\gamma}\),\({\beta}\)
Saída: { \({y_i}=BN_{\gamma,\beta}{(x_i)}\) }
\[{\mu_\phi} \leftarrow {\frac{1}{m}}{\sum_{i=1}^m}x_i \qquad \mathsf(mini-batch\ mean)\]
\[{\sigma_\phi}^2 \leftarrow {\frac{1}{m}}{\sum_{i=1}^m} {(x_i - {\mu_\phi})^2} \qquad \mathbf(mini-batch\ variance)\]
\[{\hat{x_i}} \leftarrow {\frac{x_i-{\mu_\phi}}{\sqrt {\sigma^2_\phi}+{\epsilon}}}\qquad \mathbf(normalize)\]
\[{y_i}\leftarrow {\gamma \hat{x_i}} + \beta \equiv BN_{\gamma,\beta}{(x_i)}\qquad \mathbf(scale \ and \ shift)\]
A normalização ocorre durante o treinamento, mas, no momento da avaliação, queremos que o modelo se comporte de maneira determinista: o resultado da classificação de uma imagem precisa depender apenas da imagem de entrada, e não do conjunto de imagens que estão sendo alimentadas ao modelo. Portanto, precisamos corrigir \({\mu}\) e \({\sigma}^2\) e usar valores que representam as estatísticas de população da imagem.
O modelo calcula as médias móveis da média e a variância dos minilotes:
\[{\hat\mu_i} = {\alpha \hat\mu_{t-1}}+{(1-\alpha)\mu_t}\]
\[{\hat\sigma_t}^2 = {\alpha{\hat\sigma^2_{t-1}}} + {(1-\alpha) {\sigma_t}^2}\]
No caso específico do Inception v3, um fator de decaimento sensível foi obtido (usando o ajuste de hiperparâmetro) para uso em GPUs. Queremos usar esse valor nas TPUs também. Mas para tanto, precisamos fazer alguns ajustes.
A variância e a média móvel da normalização em lote são calculadas usando um filtro de passagem de perda, conforme mostrado na equação a seguir (aqui, \({y_t}\) representa a média móvel ou a variância:
\[{y_t}={\alpha y_{t-1}}+{(1-\alpha)}{x_t} \]
(1)
Em um job de GPU 8x1 (síncrona), cada réplica lê a média móvel atual e a atualiza. A réplica atual precisa gravar a nova variável móvel antes que a próxima réplica possa lê-la.
Quando há oito réplicas, o conjunto de operações para uma atualização combinada é:
\[{y_t}={\alpha y_{t-1}}+{(1-\alpha)}{x_t} \]
\[{y_{t+1}}={\alpha y_{t}}+{(1-\alpha)}{x_{t+1}} \]
\[{y_{t+2}}={\alpha y_{t+1}}+{(1-\alpha)}{x_{t+2}} \]
\[{y_{t+3}}={\alpha y_{t+2}}+{(1-\alpha)}{x_{t+3}} \]
\[{y_{t+4}}={\alpha y_{t+3}}+{(1-\alpha)}{x_{t+4}} \]
\[{y_{t+5}}={\alpha y_{t+4}}+{(1-\alpha)}{x_{t+5}} \]
\[{y_{t+6}}={\alpha y_{t+5}}+{(1-\alpha)}{x_{t+6}} \]
\[{y_{t+7}}={\alpha y_{t+6}}+{(1-\alpha)}{x_{t+7}} \]
Esse conjunto de oito atualizações sequenciais pode ser escrito como:
\[{y_{t+7}}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{x_{t+k}}\]
(2)
Na atual implementação do cálculo do momento móvel em TPUs, cada fragmento executa cálculos de maneira independente, e não há comunicação entre fragmentos. Os lotes são distribuídos para cada fragmento. Cada um deles processa 1/8 do número total de lotes (quando há oito fragmentos).
Embora cada fragmento calcule os momentos móveis (ou seja, média e variância), somente os resultados do fragmento 0 são comunicados de volta à CPU host. Portanto, de fato, apenas uma réplica está fazendo a atualização da média móvel/variância:
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\]
(3)
e essa atualização acontece a 1/8 da taxa da contraparte sequencial. Para comparar as equações de atualização da GPU e da TPU, precisamos alinhar as respectivas escalas de tempo. Especificamente, o conjunto de operações que compõem um conjunto de oito atualizações sequenciais na GPU deve ser comparado com uma única atualização na TPU, conforme ilustrado no diagrama a seguir:
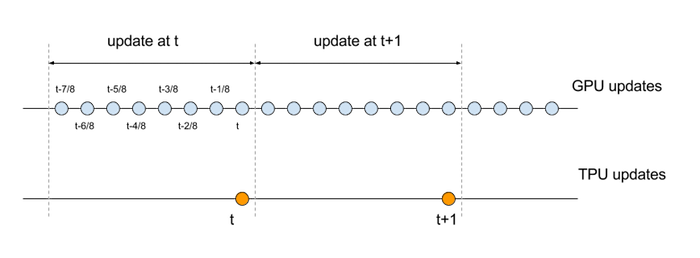
Estas são as equações com os índices de tempo modificados:
\[{y_t}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{x_{t-k/8}} \qquad \mathsf(GPU)\]
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\qquad \mathsf(TPU) \]
Se presumirmos que oito minilotes (normalizados em todas as dimensões relevantes) geram valores semelhantes na atualização sequencial de minilotes da GPU 8, podemos aproximar essas equações da seguinte maneira:
\[{y_t}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{\hat{x_t}}={\alpha^8y_{t-1}+(1-\alpha^8){\hat{x_t}}} \qquad \mathsf(GPU)\]
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\qquad \mathsf(TPU) \]
Para corresponder ao efeito de um determinado fator de decaimento na GPU, modificamos o fator de decaimento na TPU de maneira correspondente. Especificamente, definimos \({\beta}\)=\({\alpha}^8\).
No caso do modelo Inception v3, o valor de decaimento usado na GPU é \({\alpha}\)=0.9997, que se traduz em um valor de decaimento na TPU de \({\beta}\)=0.9976.
Adaptação da taxa de aprendizado
À medida que os tamanhos dos lotes aumentam, o treinamento fica mais difícil. Diferentes técnicas continuam a ser propostas para proporcionar um treinamento eficiente de lotes grandes (consulte aqui, aqui e aqui, por exemplo).
Uma dessas técnicas é o aumento gradual da taxa de aprendizado, também chamado de otimização. A ampliação foi usada para treinar o modelo com acurácia maior que 78,1% em tamanhos de lote que variam de 4.096 a 16.384. No Inception v3, a taxa de aprendizado é definida primeiro como cerca de 10% do que normalmente seria a taxa de aprendizado inicial. A taxa de aprendizado permanece constante nesse valor baixo para um número especificado (pequeno) de "períodos frios" e, em seguida, inicia um aumento linear para um número especificado de "períodos de aquecimento". No final dos "períodos de aquecimento", a taxa de aprendizado cruza com o aprendizado por declínio exponencial normal. Isso é ilustrado no diagrama a seguir.
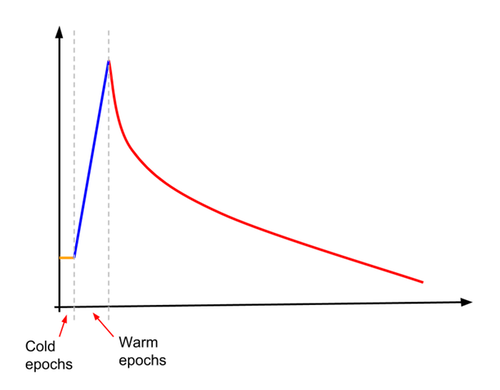
O snippet de código abaixo mostra como fazer isso:
initial_learning_rate = FLAGS.learning_rate * FLAGS.train_batch_size / 256
if FLAGS.use_learning_rate_warmup:
warmup_decay = FLAGS.learning_rate_decay**(
(FLAGS.warmup_epochs + FLAGS.cold_epochs) /
FLAGS.learning_rate_decay_epochs)
adj_initial_learning_rate = initial_learning_rate * warmup_decay
final_learning_rate = 0.0001 * initial_learning_rate
train_op = None
if training_active:
batches_per_epoch = _NUM_TRAIN_IMAGES / FLAGS.train_batch_size
global_step = tf.train.get_or_create_global_step()
current_epoch = tf.cast(
(tf.cast(global_step, tf.float32) / batches_per_epoch), tf.int32)
learning_rate = tf.train.exponential_decay(
learning_rate=initial_learning_rate,
global_step=global_step,
decay_steps=int(FLAGS.learning_rate_decay_epochs * batches_per_epoch),
decay_rate=FLAGS.learning_rate_decay,
staircase=True)
if FLAGS.use_learning_rate_warmup:
wlr = 0.1 * adj_initial_learning_rate
wlr_height = tf.cast(
0.9 * adj_initial_learning_rate /
(FLAGS.warmup_epochs + FLAGS.learning_rate_decay_epochs - 1),
tf.float32)
epoch_offset = tf.cast(FLAGS.cold_epochs - 1, tf.int32)
exp_decay_start = (FLAGS.warmup_epochs + FLAGS.cold_epochs +
FLAGS.learning_rate_decay_epochs)
lin_inc_lr = tf.add(
wlr, tf.multiply(
tf.cast(tf.subtract(current_epoch, epoch_offset), tf.float32),
wlr_height))
learning_rate = tf.where(
tf.greater_equal(current_epoch, FLAGS.cold_epochs),
(tf.where(tf.greater_equal(current_epoch, exp_decay_start),
learning_rate, lin_inc_lr)),
wlr)
# Set a minimum boundary for the learning rate.
learning_rate = tf.maximum(
learning_rate, final_learning_rate, name='learning_rate')