Guía avanzada de Inception v3
En este documento, se analizan los aspectos del modelo Inception y cómo se relacionan para lograr que este se ejecute de manera eficiente en Cloud TPU. Es una vista avanzada de la guía para ejecutar Inception v3 en Cloud TPU. Los cambios específicos en el modelo que dieron lugar a mejoras significativas se analizan detalladamente. Este documento es un complemento del instructivo de Inception v3.
Las ejecuciones de entrenamiento de la TPU de Inception v3 coinciden con las curvas de exactitud que producen los trabajos de GPU de configuración similar. El modelo se entrenó correctamente con las configuraciones v2-8, v2-128 y v2-512. El modelo alcanzó una exactitud superior al 78.1% en aproximadamente 170 ciclos de entrenamiento.
Los ejemplos de código que se muestran en este documento son ilustrativos, es decir que, representan una imagen de alto nivel de lo que sucede en la implementación real. El código de trabajo se puede encontrar en GitHub.
Introducción
Inception v3 es un modelo de reconocimiento de imágenes que puede alcanzar una exactitud superior al 78.1% en el conjunto de datos de ImageNet. El modelo representa la culminación de muchas ideas que desarrollaron varios investigadores durante años. Se basa en el documento original: Reformulación de la arquitectura de Inception para la visión artificial de Szegedy y otros.
El modelo en sí está compuesto por bloques de compilación simétricos y asimétricos, que incluyen convoluciones, reducción promedio, reducción máxima, concatenaciones, retirados y capas completamente conectadas. La normalización por lotes se usa con frecuencia en todo el modelo y se aplica a las entradas de activación. Las pérdidas se calculan con softmax.
En la siguiente captura de pantalla, se muestra un diagrama de alto nivel del modelo:
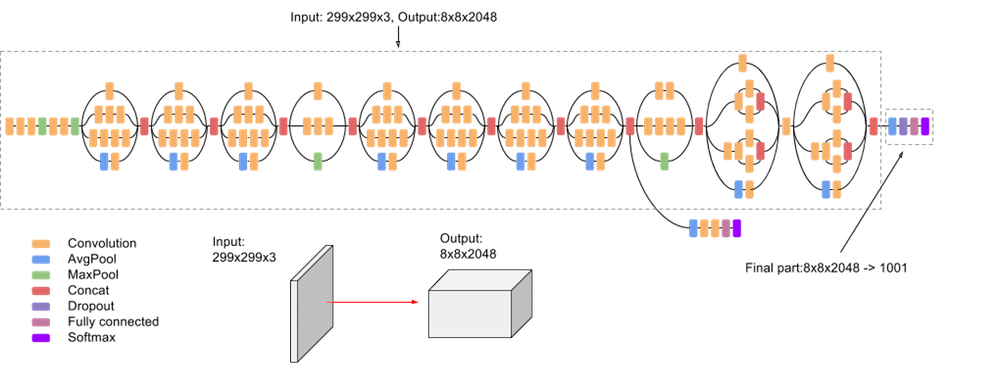
API de Estimator
La versión de la TPU de Inception v3 se escribe con TPUEstimator, una API diseñada para facilitar el desarrollo y ayudarte a que te enfoques en los modelos en lugar de en los detalles del hardware subyacente. La API realiza la mayor parte del trabajo arduo de bajo nivel necesario para ejecutar modelos en las TPU en segundo plano, al tiempo que automatiza funciones comunes, como guardar y restablecer puntos de control.
La API de Estimator aplica la separación del modelo y las partes de entrada del código.
Debes definir las funciones model_fn y input_fn, que corresponden a la definición del modelo y la canalización de entrada. El siguiente código muestra la declaración de estas funciones:
def model_fn(features, labels, mode, params):
…
return tpu_estimator.TPUEstimatorSpec(mode=mode, loss=loss, train_op=train_op)
def input_fn(params):
def parser(serialized_example):
…
return image, label
…
images, labels = dataset.make_one_shot_iterator().get_next()
return images, labels
Dos funciones clave que proporciona la API son train() y evaluate(), que se usan para entrenar y evaluar como se muestra en el siguiente código:
def main(unused_argv):
…
run_config = tpu_config.RunConfig(
master=FLAGS.master,
model_dir=FLAGS.model_dir,
session_config=tf.ConfigProto(
allow_soft_placement=True, log_device_placement=True),
tpu_config=tpu_config.TPUConfig(FLAGS.iterations, FLAGS.num_shards),)
estimator = tpu_estimator.TPUEstimator(
model_fn=model_fn,
use_tpu=FLAGS.use_tpu,
train_batch_size=FLAGS.batch_size,
eval_batch_size=FLAGS.batch_size,
config=run_config)
estimator.train(input_fn=input_fn, max_steps=FLAGS.train_steps)
eval_results = inception_classifier.evaluate(
input_fn=imagenet_eval.input_fn, steps=eval_steps)
Conjunto de datos de ImageNet
Antes de que el modelo se pueda usar para reconocer imágenes, debe entrenarse con un gran conjunto de imágenes etiquetadas. ImageNet es un conjunto de datos común.
ImageNet tiene más de diez millones de URL de imágenes etiquetadas. Un millón de las imágenes también tienen cuadros delimitadores que especifican una ubicación más precisa para los objetos etiquetados.
Con respecto a este modelo, el conjunto de datos de ImageNet está compuesto por 1,331,167 imágenes, las cuales se dividen en conjuntos de datos de entrenamiento y evaluación que contienen 1,281,167 y 50,000 imágenes, respectivamente.
Los conjuntos de datos de entrenamiento y evaluación se mantienen separados intencionalmente. Para entrenar el modelo, solo se utilizan las imágenes del conjunto de datos de entrenamiento, mientras que las imágenes del conjunto de datos de evaluación se utilizan únicamente con el fin de evaluar la exactitud del modelo.
El modelo espera que las imágenes se almacenen como TFRecords. Si deseas obtener más información para convertir imágenes de archivos JPEG sin procesar en TFRecords, consulta download_and_preprocess_imagenet.sh.
Canalización de entrada
Cada dispositivo Cloud TPU tiene 8 núcleos y está conectado a un host (CPU). Las partes de mayor tamaño contienen varios hosts. Otras configuraciones más amplias interactúan con hosts diferentes. Por ejemplo, v2-256 se comunica con 16 hosts.
Los hosts recuperan los datos del sistema de archivos o de la memoria local, llevan a cabo el procesamiento previo necesario de los datos y, luego, transfieren los datos preprocesados a los núcleos de la TPU. Analizamos estas tres fases del control de datos que realiza el host a nivel individual y nos referimos a esas fases de la siguiente manera: 1) Almacenamiento, 2) Procesamiento previo y 3) Transferencia. En la siguiente figura, se muestra una imagen de alto nivel del diagrama:
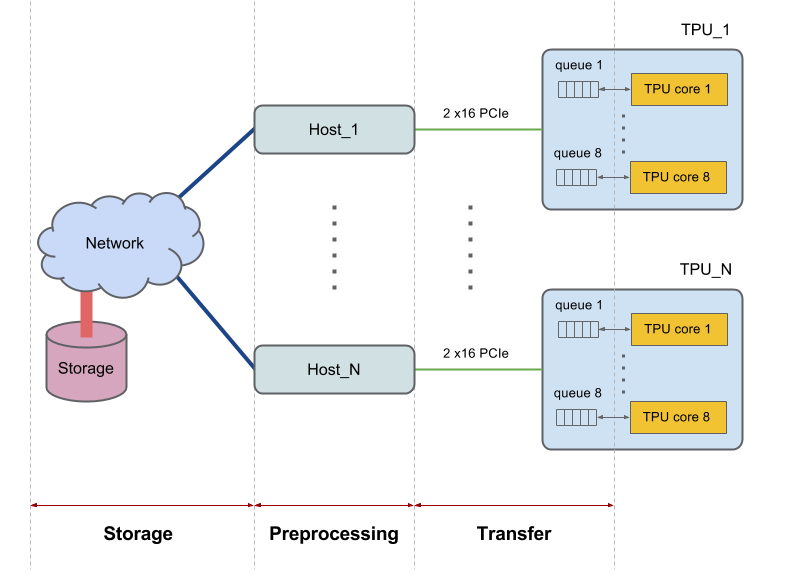
Para obtener un rendimiento adecuado, el sistema debe estar balanceado. Si la CPU del host tarda más que la TPU en completar las tres fases de control de datos, la ejecución estará vinculada al host. Ambos casos se muestran en el siguiente diagrama:
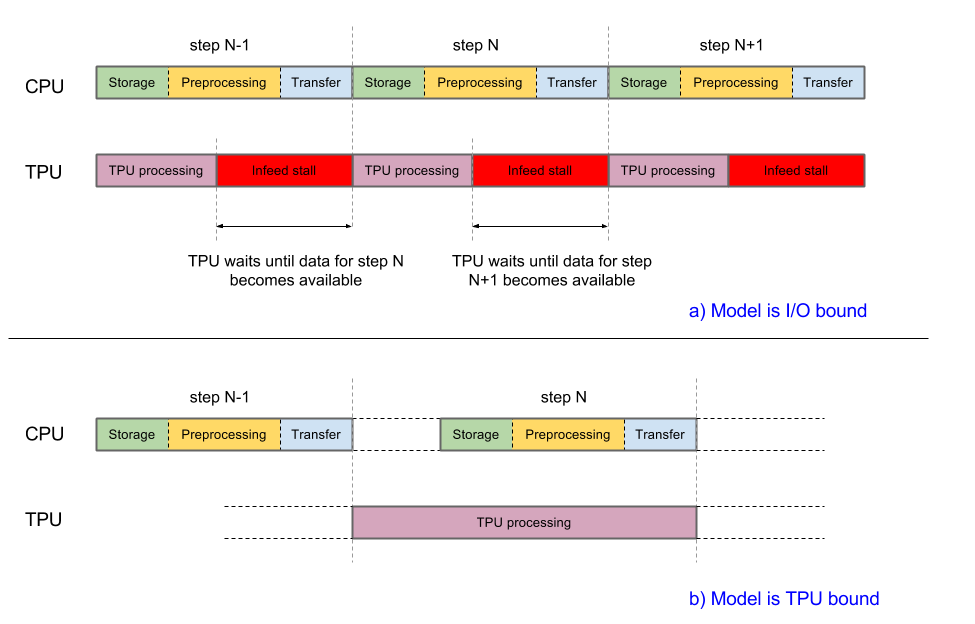
La implementación actual de Inception v3 está a punto de limitarse a la entrada. Las imágenes se recuperan del sistema de archivos, se decodifican y, luego, se procesan previamente. Hay diferentes tipos de etapas de procesamiento previo disponibles, que van desde moderadas hasta complejas. Si usamos las etapas de procesamiento previo más complejas, la canalización de entrenamiento estará vinculada al procesamiento previo. Puedes lograr una exactitud superior al 78.1% con una etapa de procesamiento previo moderadamente compleja que mantiene el modelo vinculado a la TPU.
El modelo usa tf.data.Dataset para controlar el procesamiento de la canalización de entrada. Si deseas obtener más información para optimizar las canalizaciones de entrada, consulta la guía de rendimiento de los conjuntos de datos.
Si bien puedes definir una función y pasarla a la API de Estimator, la clase InputPipeline encapsula todas las funciones requeridas.
La API de Estimator facilita el uso de esta clase. Lo pasas al parámetro input_fn de las funciones train() y evaluate(), como se muestra en el siguiente fragmento de código:
def main(unused_argv):
…
inception_classifier = tpu_estimator.TPUEstimator(
model_fn=inception_model_fn,
use_tpu=FLAGS.use_tpu,
config=run_config,
params=params,
train_batch_size=FLAGS.train_batch_size,
eval_batch_size=eval_batch_size,
batch_axis=(batch_axis, 0))
…
for cycle in range(FLAGS.train_steps // FLAGS.train_steps_per_eval):
tf.logging.info('Starting training cycle %d.' % cycle)
inception_classifier.train(
input_fn=InputPipeline(True), steps=FLAGS.train_steps_per_eval)
tf.logging.info('Starting evaluation cycle %d .' % cycle)
eval_results = inception_classifier.evaluate(
input_fn=InputPipeline(False), steps=eval_steps, hooks=eval_hooks)
tf.logging.info('Evaluation results: %s' % eval_results)
Los elementos principales de InputPipeline se muestran en el siguiente fragmento de código.
class InputPipeline(object):
def __init__(self, is_training):
self.is_training = is_training
def __call__(self, params):
# Storage
file_pattern = os.path.join(
FLAGS.data_dir, 'train-*' if self.is_training else 'validation-*')
dataset = tf.data.Dataset.list_files(file_pattern)
if self.is_training and FLAGS.initial_shuffle_buffer_size > 0:
dataset = dataset.shuffle(
buffer_size=FLAGS.initial_shuffle_buffer_size)
if self.is_training:
dataset = dataset.repeat()
def prefetch_dataset(filename):
dataset = tf.data.TFRecordDataset(
filename, buffer_size=FLAGS.prefetch_dataset_buffer_size)
return dataset
dataset = dataset.apply(
tf.contrib.data.parallel_interleave(
prefetch_dataset,
cycle_length=FLAGS.num_files_infeed,
sloppy=True))
if FLAGS.followup_shuffle_buffer_size > 0:
dataset = dataset.shuffle(
buffer_size=FLAGS.followup_shuffle_buffer_size)
# Preprocessing
dataset = dataset.map(
self.dataset_parser,
num_parallel_calls=FLAGS.num_parallel_calls)
dataset = dataset.prefetch(batch_size)
dataset = dataset.apply(
tf.contrib.data.batch_and_drop_remainder(batch_size))
dataset = dataset.prefetch(2) # Prefetch overlaps in-feed with training
images, labels = dataset.make_one_shot_iterator().get_next()
# Transfer
return images, labels
La sección storage comienza con la creación de un conjunto de datos que incluye la lectura de TFRecords desde el almacenamiento (con tf.data.TFRecordDataset). Las funciones con un propósito especial, repeat() y shuffle(), se usan según sea necesario. La función tf.contrib.data.parallel_interleave() asigna la función prefetch_dataset() a través de su entrada para producir conjuntos de datos anidados y muestra sus elementos intercalados. Obtiene elementos de los conjuntos de datos anidados de cycle_length en paralelo, lo que aumenta la capacidad de procesamiento. El argumento sloppy flexibiliza el requisito de que los resultados se produzcan en un orden determinista y permite que la implementación omita los conjuntos de datos anidados cuyos elementos no estén disponibles cuando se soliciten.
La sección procesamiento previo llama a dataset.map(parser), que a su vez llama a la función del analizador en la que se procesan las imágenes. Los detalles de la etapa de procesamiento previo se analizan en la siguiente sección.
En la sección transferencia (al final de la función), se incluye la línea return images, labels. TPUEstimator toma los valores mostrados y los transfiere automáticamente al dispositivo.
En la siguiente figura, se muestra un ejemplo de seguimiento del rendimiento de Cloud TPU de Inception v3. El tiempo de procesamiento de la TPU, sin tener en cuenta los bloqueos in-feed, es de aproximadamente 815 ms.
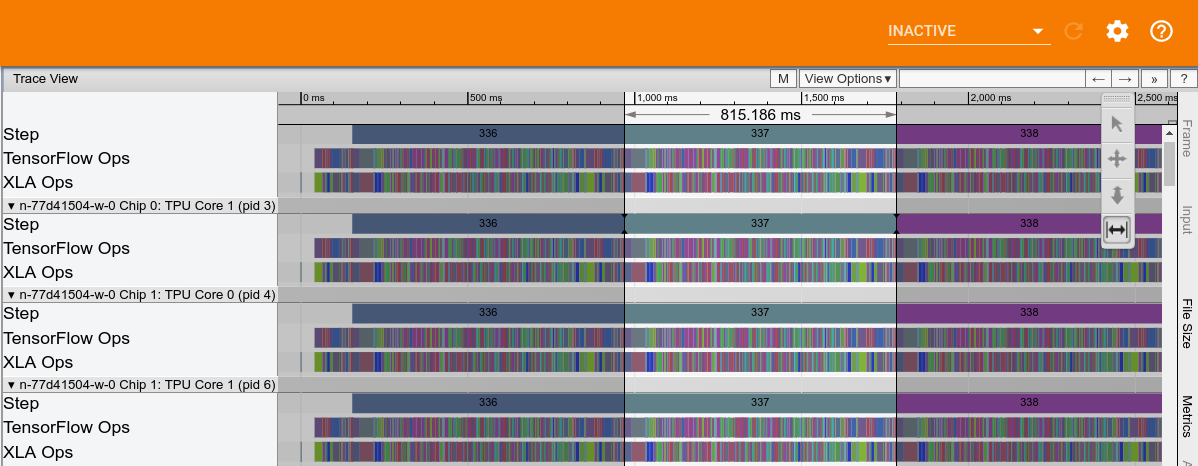
El almacenamiento del host se escribe en el seguimiento y se muestra en la siguiente captura de pantalla:

En la siguiente captura de pantalla, se muestra el procesamiento previo del host, que incluye la decodificación de imágenes y una serie de funciones de distorsión de imagen:

La transferencia de host/TPU se muestra en la siguiente captura de pantalla:

Etapa de procesamiento previo
El procesamiento previo de imágenes es una parte fundamental del sistema y puede influir en la exactitud máxima que el modelo alcanza durante el entrenamiento. Como mínimo, se deben decodificar las imágenes y cambiar el tamaño para adaptarlas al modelo. Para Inception, las imágenes deben ser de 299 x 299 x 3 píxeles.
Sin embargo, la decodificación y el cambio de tamaño no alcanzan para obtener una buena precisión. El conjunto de datos de entrenamiento de ImageNet contiene 1,281,167 imágenes. Un ciclo de entrenamiento se define como un pase a través del conjunto de imágenes de entrenamiento. Durante el entrenamiento, el modelo requiere varios pases a través del conjunto de datos de entrenamiento para mejorar sus capacidades de reconocimiento de imágenes. Para entrenar Inception v3 con una exactitud suficiente, usa entre 140 y 200 ciclos de entrenamiento según el tamaño del lote global.
Resulta útil alterar continuamente las imágenes antes de alimentarlas al modelo, de modo que una imagen en particular sea ligeramente diferente en cada ciclo de entrenamiento. La mejor manera de realizar este procesamiento previo de imágenes es tanto arte como ciencia. Una etapa de procesamiento previo bien diseñada puede aumentar de manera significativa las capacidades de reconocimiento de un modelo. Una etapa de procesamiento previo demasiado simple puede crear un límite artificial en la exactitud que el mismo modelo puede alcanzar durante el entrenamiento.
Inception v3 ofrece opciones para la etapa de procesamiento previo, que varían desde relativamente simples y económicas en términos de procesamiento hasta bastante complejas y costosas desde el punto de vista informático. Se pueden encontrar dos tipos distintos de opciones en los archivos inception_preprocessing.py y vgg_preprocessing.py.
El archivo vgg_preprocessing.py define una etapa de procesamiento previo que se utilizó con éxito para entrenar resnet con una exactitud del 75%, pero genera resultados deficientes cuando se aplica en Inception v3.
El archivo inception_preprocessing.py contiene una etapa de procesamiento previo que se usó para entrenar a Inception v3 con una exactitud de entre el 78.1% y el 78.5% cuando se ejecuta en TPU.
Las variaciones en el procesamiento previo se basan en si el modelo se está entrenando o se está utilizando para realizar una inferencia o evaluación.
En el momento de la evaluación, el procesamiento previo es sencillo: recorta una región central de la imagen y, luego, cambia su tamaño al tamaño predeterminado de 299 x 299. En el siguiente fragmento de código, se muestra una implementación de procesamiento previo:
def preprocess_for_eval(image, height, width, central_fraction=0.875):
with tf.name_scope(scope, 'eval_image', [image, height, width]):
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.image.central_crop(image, central_fraction=central_fraction)
image = tf.expand_dims(image, 0)
image = tf.image.resize_bilinear(image, [height, width], align_corners=False)
image = tf.squeeze(image, [0])
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
image.set_shape([height, width, 3])
return image
Durante el entrenamiento, el recorte es aleatorio: se elige un cuadro de límite de manera aleatoria para seleccionar una región de la imagen a la que, posteriormente, se le cambia el tamaño. La imagen redimensionada se gira opcionalmente y los colores se distorsionan. En el siguiente fragmento de código, se muestra una implementación de estas operaciones:
def preprocess_for_train(image, height, width, bbox, fast_mode=True, scope=None):
with tf.name_scope(scope, 'distort_image', [image, height, width, bbox]):
if bbox is None:
bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4])
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
distorted_image, distorted_bbox = distorted_bounding_box_crop(image, bbox)
distorted_image.set_shape([None, None, 3])
num_resize_cases = 1 if fast_mode else 4
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, method: tf.image.resize_images(x, [height, width], method),
num_cases=num_resize_cases)
distorted_image = tf.image.random_flip_left_right(distorted_image)
if FLAGS.use_fast_color_distort:
distorted_image = distort_color_fast(distorted_image)
else:
num_distort_cases = 1 if fast_mode else 4
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, ordering: distort_color(x, ordering, fast_mode),
num_cases=num_distort_cases)
distorted_image = tf.subtract(distorted_image, 0.5)
distorted_image = tf.multiply(distorted_image, 2.0)
return distorted_image
La función distort_color se encarga de modificar el color. Ofrece una forma rápida en la que solo se modifican el brillo y la saturación. El modo completo modifica el brillo, la saturación y el tono en un orden aleatorio.
def distort_color(image, color_ordering=0, fast_mode=True, scope=None):
with tf.name_scope(scope, 'distort_color', [image]):
if fast_mode:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
else:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
else:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
elif color_ordering == 1:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
elif color_ordering == 2:
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
elif color_ordering == 3:
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
return tf.clip_by_value(image, 0.0, 1.0)
La función distort_color es costosa en términos de procesamiento, en parte debido a las conversiones no lineales de RGB a HSV y de HSV a RGB que se requieren para acceder al tono y la saturación. Tanto el modo rápido como el completo requieren estas conversiones y, aunque el modo rápido es menos costoso desde el punto de vista del procesamiento, expone el modelo a la región vinculada al procesamiento de la CPU, siempre que esté habilitada.
Como alternativa, se agregó una nueva función distort_color_fast a la lista de opciones. Esta función asigna la imagen de RGB a YCrCb con el esquema de conversión de JPEG y altera el brillo y los colores Cr/Cb antes de volver a asignarlo a RGB. En el siguiente fragmento de código, se muestra una implementación de esta función:
def distort_color_fast(image, scope=None):
with tf.name_scope(scope, 'distort_color', [image]):
br_delta = random_ops.random_uniform([], -32./255., 32./255., seed=None)
cb_factor = random_ops.random_uniform(
[], -FLAGS.cb_distortion_range, FLAGS.cb_distortion_range, seed=None)
cr_factor = random_ops.random_uniform(
[], -FLAGS.cr_distortion_range, FLAGS.cr_distortion_range, seed=None)
channels = tf.split(axis=2, num_or_size_splits=3, value=image)
red_offset = 1.402 * cr_factor + br_delta
green_offset = -0.344136 * cb_factor - 0.714136 * cr_factor + br_delta
blue_offset = 1.772 * cb_factor + br_delta
channels[0] += red_offset
channels[1] += green_offset
channels[2] += blue_offset
image = tf.concat(axis=2, values=channels)
image = tf.clip_by_value(image, 0., 1.)
return image
Aquí hay una imagen de muestra después del procesamiento previo. Se seleccionó una región de la imagen elegida al azar y se modificaron los colores con la función distort_color_fast.

La función distort_color_fast es eficiente en términos de procesamiento y, aun así, permite que el entrenamiento esté vinculado al tiempo de ejecución de la TPU. Además, se usó para entrenar el modelo de Inception v3 con una exactitud superior al 78.1% con tamaños de lote del rango de 1,024 a 16,384.
Optimizador
El modelo actual muestra tres tipos de optimizadores: SGD, momentum y RMSProp.
Stochastic gradient descent (SGD) es la actualización más simple: los pesos se desplazan en la dirección del gradiente negativa. A pesar de la simplicidad, es posible obtener resultados positivos en algunos modelos. La dinámica de las actualizaciones se puede escribir de la siguiente manera:
El momento es un optimizador popular que suele conducir a una convergencia más rápida que el SGD. Este optimizador actualiza los pesos como SGD, pero también agrega un componente en la dirección de la actualización anterior. En las siguientes ecuaciones, se describen las actualizaciones que realiza el optimizador de momentum:
que puede escribirse de esta manera:
El último término es el componente de la dirección de la actualización anterior.
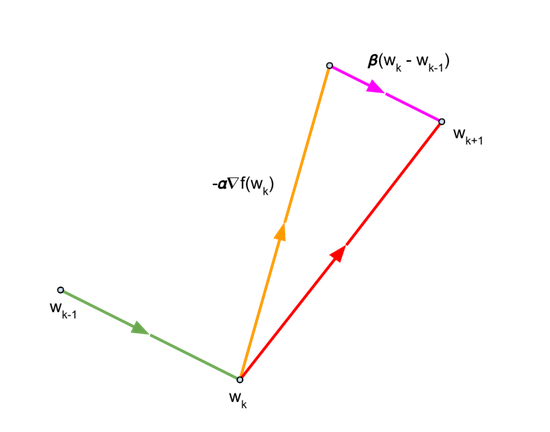
Para el momentum \({\beta}\), usamos el valor de 0.9.
RMSprop es un optimizador popular que propuso por primera vez Geoff Hinton en una de sus clases. En las siguientes ecuaciones, se describe cómo funciona el optimizador:
En el caso de Inception v3, las pruebas muestran que RMSProp ofrece los mejores resultados en términos de máxima exactitud y de tiempo suficiente para lograrla, con un momentum de casi un segundo. Por lo tanto, RMSprop se configura como optimizador predeterminado. Los parámetros utilizados son los siguientes: disminución \({\alpha}\)=0.9, momentum \({\beta}\) 0.9 y ({\epsilon}\)=1.0.
En el siguiente fragmento de código, se muestra cómo configurar estos parámetros:
if FLAGS.optimizer == 'sgd':
tf.logging.info('Using SGD optimizer')
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate)
elif FLAGS.optimizer == 'momentum':
tf.logging.info('Using Momentum optimizer')
optimizer = tf.train.MomentumOptimizer(
learning_rate=learning_rate, momentum=0.9)
elif FLAGS.optimizer == 'RMS':
tf.logging.info('Using RMS optimizer')
optimizer = tf.train.RMSPropOptimizer(
learning_rate,
RMSPROP_DECAY,
momentum=RMSPROP_MOMENTUM,
epsilon=RMSPROP_EPSILON)
else:
tf.logging.fatal('Unknown optimizer:', FLAGS.optimizer)
Cuando se ejecuta en las TPU y se utiliza la API de Estimator, el optimizador debe unirse a una función CrossShardOptimizer para garantizar la sincronización entre las réplicas (junto con cualquier comunicación cruzada que sea necesaria). En el siguiente fragmento de código, se muestra cómo el modelo de Inception v3 une el optimizador:
if FLAGS.use_tpu:
optimizer = tpu_optimizer.CrossShardOptimizer(optimizer)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss, global_step=global_step)
Media móvil exponencial
Durante el entrenamiento, los parámetros entrenables se actualizan durante la propagación inversa según las reglas de actualización del optimizador. Las ecuaciones que describen estas reglas se analizaron en la sección anterior y se repitieron aquí para mayor practicidad:
La promedio móvil exponencial (también conocida como suavizado exponencial) es un paso opcional del procesamiento posterior que se aplica a los pesos actualizados y, a veces, puede generar mejoras notables en el rendimiento. TensorFlow proporciona la función tf.train.ExponentialMovingAverage, que calcula el EMA \({\hat{\theta}}\) de peso \({\theta}\) mediante la fórmula:
según la cual, \({\alpha}\) representa un factor de disminución (cercano a 1.0). En el modelo de Inception v3, \({\alpha}\) se establece en 0.995.
Aunque este cálculo es un filtro de respuesta de impulso infinito (IIR), el factor de disminución establece un período efectivo en el que reside la mayor parte de la energía (o muestras relevantes), como se muestra en el siguiente diagrama:
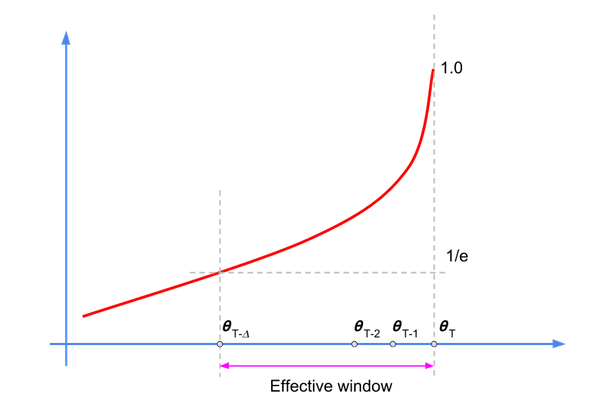
Podemos reescribir la ecuación del filtro de la siguiente manera:
en el mismo espacio en que habíamos utilizado \({\hat\theta_{-1}}=0\).
Los valores de \({\alpha}^k\) disminuyen a medida que aumenta k, por lo que solo un subconjunto de las muestras tendrá una influencia considerable en \(\hat{\theta}_{t+T+1}\). La regla general para el valor del factor de disminución es:\(\frac {1} {1-\alpha}\), que corresponde a \({\alpha}\) = 200 para =0.995.
Primero, obtenemos una colección de variables entrenables y, luego, usamos el método apply() para crear variables sombra para cada variable entrenada.
En el siguiente fragmento de código, se muestra la implementación del modelo de Inception v3:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss, global_step=global_step)
if FLAGS.moving_average:
ema = tf.train.ExponentialMovingAverage(
decay=MOVING_AVERAGE_DECAY, num_updates=global_step)
variables_to_average = (tf.trainable_variables() +
tf.moving_average_variables())
with tf.control_dependencies([train_op]), tf.name_scope('moving_average'):
train_op = ema.apply(variables_to_average)
Nos gustaría usar las variables ema durante la evaluación. Definimos la clase LoadEMAHook que aplica el método variables_to_restore() al archivo del punto de control para evaluar con los nombres de variables de sombra:
class LoadEMAHook(tf.train.SessionRunHook):
def __init__(self, model_dir):
super(LoadEMAHook, self).__init__()
self._model_dir = model_dir
def begin(self):
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY)
variables_to_restore = ema.variables_to_restore()
self._load_ema = tf.contrib.framework.assign_from_checkpoint_fn(
tf.train.latest_checkpoint(self._model_dir), variables_to_restore)
def after_create_session(self, sess, coord):
tf.logging.info('Reloading EMA...')
self._load_ema(sess)
La función hooks se pasa a evaluate(), como se muestra en el siguiente fragmento de código:
if FLAGS.moving_average:
eval_hooks = [LoadEMAHook(FLAGS.model_dir)]
else:
eval_hooks = []
…
eval_results = inception_classifier.evaluate(
input_fn=InputPipeline(False), steps=eval_steps, hooks=eval_hooks)
Normalización por lotes
La normalización por lotes es una técnica muy utilizada para normalizar los atributos de entrada en modelos que pueden ofrecer una reducción sustancial en el tiempo de convergencia. Es una de las mejoras algorítmicas más populares y útiles en el aprendizaje automático durante los últimos años; además, se utiliza en una amplia gama de modelos, incluido Inception v3.
Las entradas de activación se normalizan restando la media y dividiendo por la desviación estándar. Para mantener el sistema balanceado en presencia de la propagación inversa, se ingresan dos parámetros entrenables en cada capa. Las salidas normalizadas \({\hat{x}}\) se someten a una operación posterior \({\gamma\hat{x}}+\beta\), en la que \({\gamma}\) y \({\beta}\) son una especie de desviación estándar y una media que aprendió el modelo en sí.
El conjunto completo de ecuaciones está en el documento y se repite aquí para mayor practicidad:
Entrada: valores de x sobre un minilote: \(\Phi=\) { \({x_{1..m}\\} \) }. Parámetros que hay que aprender: \({\gamma}\), \({\beta}\)
Salida: { \({y_i}=BN_{\gamma,\beta}{(x_i)}\) }
\[{\mu_\phi} \leftarrow {\frac{1}{m}}{\sum_{i=1}^m}x_i \qquad \mathsf(mini-batch\ mean)\]
\[{\sigma_\phi}^2 \leftarrow {\frac{1}{m}}{\sum_{i=1}^m} {(x_i - {\mu_\phi})^2} \qquad \mathbf(mini-batch\ variance)\]
\[{\hat{x_i}} \leftarrow {\frac{x_i-{\mu_\phi}}{\sqrt {\sigma^2_\phi}+{\epsilon}}}\qquad \mathbf(normalize)\]
\[{y_i}\leftarrow {\gamma \hat{x_i}} + \beta \equiv BN_{\gamma,\beta}{(x_i)}\qquad \mathbf(scale \ and \ shift)\]
La normalización ocurre durante el entrenamiento, pero, llegado el momento de la evaluación, nos gustaría que el modelo se comporte de manera determinista: el resultado de la clasificación de una imagen debe depender únicamente de la imagen de entrada y no del conjunto de imágenes que se envían al modelo. Por lo tanto, debemos corregir \({\mu}\) y \({\sigma}^2\) y usar valores que representen las estadísticas de propagación de imágenes.
El modelo calcula los promedios móviles de la media y la varianza sobre los minilotes:
\[{\hat\mu_i} = {\alpha \hat\mu_{t-1}}+{(1-\alpha)\mu_t}\]
\[{\hat\sigma_t}^2 = {\alpha{\hat\sigma^2_{t-1}}} + {(1-\alpha) {\sigma_t}^2}\]
En el caso específico de Inception v3, se obtuvo un factor de disminución razonable (mediante el ajuste de hiperparámetros) para usarlo en GPU. También nos gustaría usar este valor en la TPU; pero para hacer eso, necesitamos hacer algunos ajustes.
La media móvil y la varianza de la normalización por lotes se calculan mediante un filtro de pase de pérdida, como se muestra en la siguiente ecuación (aquí, \({y_t}\) representa la media o la varianza móvil:
\[{y_t}={\alpha y_{t-1}}+{(1-\alpha)}{x_t} \]
(1)
En un trabajo de GPU (síncrono) de 8 x 1, cada réplica lee la media móvil actual y la actualiza. La réplica actual debe escribir la nueva variable móvil antes de que la siguiente réplica pueda leerla.
Cuando hay 8 réplicas, el conjunto de operaciones de una actualización de ensamble es el siguiente:
\[{y_t}={\alpha y_{t-1}}+{(1-\alpha)}{x_t} \]
\[{y_{t+1}}={\alpha y_{t}}+{(1-\alpha)}{x_{t+1}} \]
\[{y_{t+2}}={\alpha y_{t+1}}+{(1-\alpha)}{x_{t+2}} \]
\[{y_{t+3}}={\alpha y_{t+2}}+{(1-\alpha)}{x_{t+3}} \]
\[{y_{t+4}}={\alpha y_{t+3}}+{(1-\alpha)}{x_{t+4}} \]
\[{y_{t+5}}={\alpha y_{t+4}}+{(1-\alpha)}{x_{t+5}} \]
\[{y_{t+6}}={\alpha y_{t+5}}+{(1-\alpha)}{x_{t+6}} \]
\[{y_{t+7}}={\alpha y_{t+6}}+{(1-\alpha)}{x_{t+7}} \]
Este conjunto de 8 actualizaciones secuenciales se puede escribir de la siguiente manera:
\[{y_{t+7}}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{x_{t+k}}\]
(2)
En la implementación actual del cálculo de momento móvil en las TPU, cada fragmento realiza cálculos de forma independiente, y no hay comunicación entre fragmentos cruzados. Los lotes se distribuyen a cada fragmento, y cada uno de ellos procesa 1/8 de la cantidad total de lotes (cuando hay 8 fragmentos).
Aunque cada fragmento calcula los momentos móviles (es decir, la media y la varianza), solo los resultados del fragmento 0 se comunican a la CPU del host. Entonces, en efecto, solo una réplica realiza la actualización móvil de la media/varianza:
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\]
(3)
y esta actualización ocurre a 1/8 de la tasa de su equivalente secuencial. Para comparar las ecuaciones de actualización de la GPU y la TPU, necesitamos alinear las escalas de tiempo respectivas. Específicamente, el conjunto de operaciones que conforman un conjunto de 8 actualizaciones secuenciales en la GPU se debe comparar con una sola actualización en la TPU, como se ilustra en el siguiente diagrama:
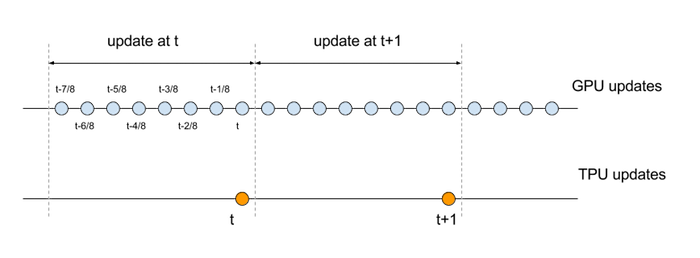
Veamos las ecuaciones con los índices de tiempo modificados:
\[{y_t}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{x_{t-k/8}} \qquad \mathsf(GPU)\]
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\qquad \mathsf(TPU) \]
Si suponemos que 8 minilotes (normalizados en todas las dimensiones relevantes) producen valores similares dentro de la actualización secuencial de minilotes de GPU 8, podemos aproximar estas ecuaciones de la siguiente manera:
\[{y_t}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{\hat{x_t}}={\alpha^8y_{t-1}+(1-\alpha^8){\hat{x_t}}} \qquad \mathsf(GPU)\]
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\qquad \mathsf(TPU) \]
Para hacer coincidir el efecto de un factor de disminución determinado en la GPU, modificamos el factor de disminución en la TPU según corresponda. Específicamente, configuramos \({\beta}\)=\({\alpha}^8\).
Para Inception v3, el valor de disminución utilizado en la GPU es \({\alpha}\)=0.9997, que se traduce en un valor de disminución de la TPU de \({\beta}\)=0.9976.
Adaptación de la tasa de aprendizaje
A medida que aumenta el tamaño de los lotes, el entrenamiento se vuelve más difícil. Se siguen proponiendo diferentes técnicas a fin de lograr un entrenamiento eficiente para los lotes de mayor tamaño (por ejemplo, puedes consultar aquí, aquí y aquí).
Una de estas técnicas consiste en aumentar la tasa de aprendizaje gradualmente (también conocida como adaptación). Se usó el aumento con el objetivo de entrenar el modelo con una exactitud superior al 78.1% para tamaños de lotes de entre 4,096 y 16,384. En el caso de Inception v3, la tasa de aprendizaje se establece primero en alrededor del 10% de lo que normalmente sería la tasa de aprendizaje inicial. La tasa de aprendizaje permanece constante en este valor bajo durante una cantidad específica (pequeña) de "ciclos de entrenamiento fríos" y, luego, comienza un aumento lineal por un número específico de "ciclos de entrenamiento". Al final de los "ciclos de entrenamiento", la tasa de aprendizaje se cruza con el aprendizaje de decaimiento exponencial normal. Esto se ilustra en el siguiente diagrama.
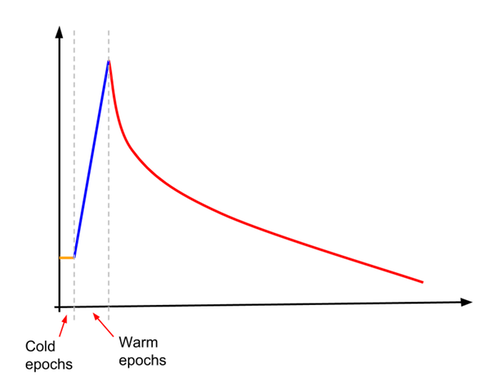
En el siguiente fragmento de código, se muestra cómo hacerlo:
initial_learning_rate = FLAGS.learning_rate * FLAGS.train_batch_size / 256
if FLAGS.use_learning_rate_warmup:
warmup_decay = FLAGS.learning_rate_decay**(
(FLAGS.warmup_epochs + FLAGS.cold_epochs) /
FLAGS.learning_rate_decay_epochs)
adj_initial_learning_rate = initial_learning_rate * warmup_decay
final_learning_rate = 0.0001 * initial_learning_rate
train_op = None
if training_active:
batches_per_epoch = _NUM_TRAIN_IMAGES / FLAGS.train_batch_size
global_step = tf.train.get_or_create_global_step()
current_epoch = tf.cast(
(tf.cast(global_step, tf.float32) / batches_per_epoch), tf.int32)
learning_rate = tf.train.exponential_decay(
learning_rate=initial_learning_rate,
global_step=global_step,
decay_steps=int(FLAGS.learning_rate_decay_epochs * batches_per_epoch),
decay_rate=FLAGS.learning_rate_decay,
staircase=True)
if FLAGS.use_learning_rate_warmup:
wlr = 0.1 * adj_initial_learning_rate
wlr_height = tf.cast(
0.9 * adj_initial_learning_rate /
(FLAGS.warmup_epochs + FLAGS.learning_rate_decay_epochs - 1),
tf.float32)
epoch_offset = tf.cast(FLAGS.cold_epochs - 1, tf.int32)
exp_decay_start = (FLAGS.warmup_epochs + FLAGS.cold_epochs +
FLAGS.learning_rate_decay_epochs)
lin_inc_lr = tf.add(
wlr, tf.multiply(
tf.cast(tf.subtract(current_epoch, epoch_offset), tf.float32),
wlr_height))
learning_rate = tf.where(
tf.greater_equal(current_epoch, FLAGS.cold_epochs),
(tf.where(tf.greater_equal(current_epoch, exp_decay_start),
learning_rate, lin_inc_lr)),
wlr)
# Set a minimum boundary for the learning rate.
learning_rate = tf.maximum(
learning_rate, final_learning_rate, name='learning_rate')