Guide avancé d'Inception v3
Ce document présente divers aspects du modèle Inception et la manière dont ils s'agencent pour que le modèle s'exécute efficacement sur Cloud TPU. Il s'agit d'une version avancée du guide d'utilisation d'Inception v3 sur Cloud TPU. Les modifications particulières du modèle qui ont abouti à des améliorations significatives sont abordées plus en détail. Ce document complète le Tutoriel Inception v3.
L'entraînement TPU Inception v3 donne des résultats comparables aux courbes de précision générées par des tâches GPU de configuration similaire. Le modèle a été entraîné avec succès sur les configurations v2-8, v2-128 et v2-512. Le modèle a atteint une justesse supérieure à 78,1% sur environ 170 époques.
Les exemples de code présentés dans ce document visent à illustrer et donner une vue d'ensemble de ce qui se passe lors de la mise en œuvre réelle. Le code fonctionnel est disponible sur GitHub.
Introduction
Inception v3 est un modèle de reconnaissance d'image dont la précision est supérieure à 78,1% sur l'ensemble de données ImageNet. Ce modèle est l'aboutissement de nombreuses idées développées par plusieurs chercheurs au fil des ans. Il est basé sur l'article originel Rethinking the Inception Architecture for Computer Vision (Repenser l'architecture Inception pour la vision par ordinateur) de Szegedy, et. al.
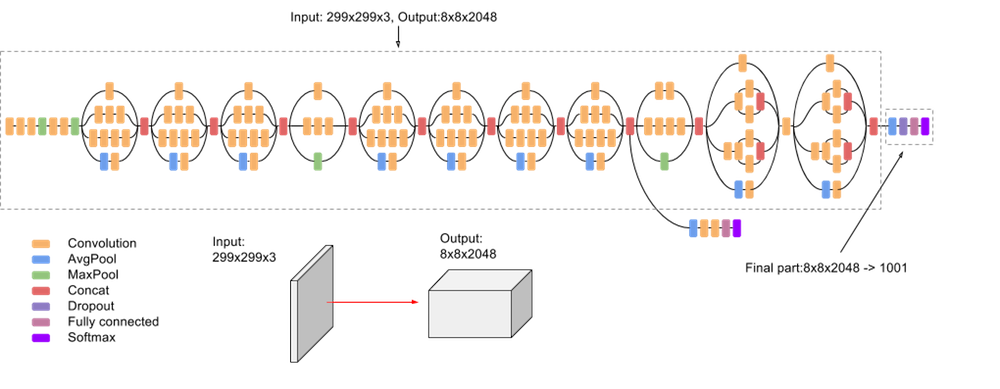
Le modèle lui-même est constitué de composants symétriques et asymétriques, y compris des convolutions, le pooling moyen, le pooling maximal, des concaténations, des abandons et des couches entièrement connectées. La normalisation des lots est largement utilisée dans le modèle et appliquée aux entrées d'activation. La perte est calculée à l'aide de Softmax.
La capture d'écran suivante illustre un schéma simplifié du modèle:
API Estimator
La version TPU de Inception v3 est codée à l'aide de TPUEstimator, une API conçue pour faciliter le développement et faire en sorte que vous puissiez vous concentrer sur les modèles eux-mêmes plutôt que sur les détails du matériel sous-jacent. L'API effectue en arrière-plan l'essentiel du travail de bas niveau nécessaire à l'exécution de modèles sur les TPU, tout en automatisant des fonctions courantes telles que l'enregistrement et la restauration des points de contrôle.
L'API Estimator fait respecter la séparation des sections de code relatives au modèle et aux données.
Vous définissez les fonctions model_fn et input_fn, correspondant à la définition du modèle et au pipeline d'entrée. Le code suivant montre la déclaration de ces fonctions:
def model_fn(features, labels, mode, params):
…
return tpu_estimator.TPUEstimatorSpec(mode=mode, loss=loss, train_op=train_op)
def input_fn(params):
def parser(serialized_example):
…
return image, label
…
images, labels = dataset.make_one_shot_iterator().get_next()
return images, labels
Les deux fonctions clés fournies par l'API sont train() et evaluate(). Elles permettent d'entraîner et d'évaluer les résultats, comme indiqué dans le code suivant:
def main(unused_argv):
…
run_config = tpu_config.RunConfig(
master=FLAGS.master,
model_dir=FLAGS.model_dir,
session_config=tf.ConfigProto(
allow_soft_placement=True, log_device_placement=True),
tpu_config=tpu_config.TPUConfig(FLAGS.iterations, FLAGS.num_shards),)
estimator = tpu_estimator.TPUEstimator(
model_fn=model_fn,
use_tpu=FLAGS.use_tpu,
train_batch_size=FLAGS.batch_size,
eval_batch_size=FLAGS.batch_size,
config=run_config)
estimator.train(input_fn=input_fn, max_steps=FLAGS.train_steps)
eval_results = inception_classifier.evaluate(
input_fn=imagenet_eval.input_fn, steps=eval_steps)
Ensemble de données ImageNet
Avant de pouvoir être utilisé pour reconnaître des images, le modèle doit être entraîné à l'aide d'un grand ensemble d'images étiquetées. ImageNet est un ensemble de données communément utilisé.
ImageNet contient plus de dix millions d'URL d'images avec libellés. Un million d'images comportent également des cadres de délimitation spécifiant un emplacement plus précis pour les objets étiquetés.
Pour ce modèle, l'ensemble de données ImageNet est composé de 1 331 167 images partagées en deux ensembles de données d'entraînement et d'évaluation, contenant respectivement 1 281 167 et 50 000 images.
La séparation entre ensembles de données d'entraînement et d’évaluation est intentionnelle. Seules les images de l'ensemble de données d'entraînement sont utilisées pour entraîner le modèle, et seules les images de l'ensemble de données d'évaluation sont utilisées pour évaluer la justesse du modèle.
Le modèle s'attend à ce que les images soient enregistrées sous forme de fichiers TFRecords. Pour en savoir plus sur la conversion d'images de fichiers JPEG bruts au format TFRecords, consultez download_and_preprocess_imagenet.sh.
Pipeline d'entrée
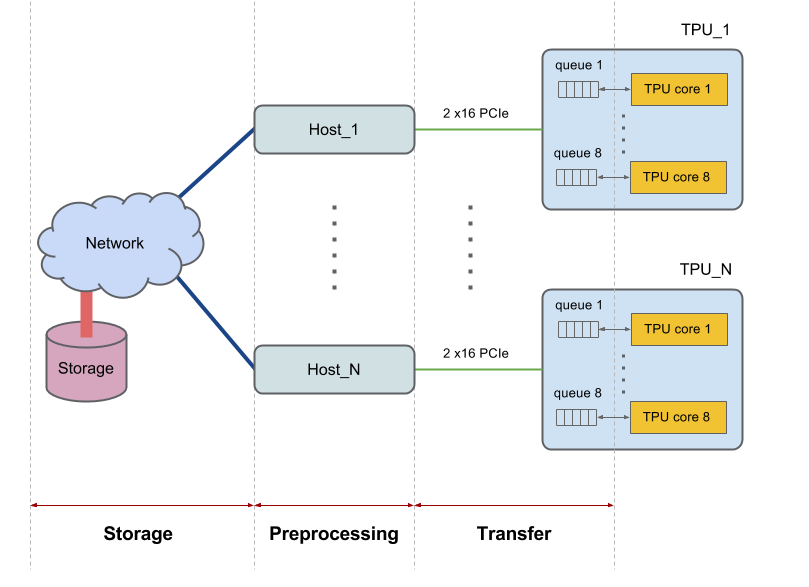
Chaque appareil Cloud TPU possède huit cœurs et est connecté à un hôte (processeur). Les tranches plus conséquentes possèdent plusieurs hôtes. D'autres configurations plus conséquentes interagissent avec plusieurs hôtes. Par exemple, une version 2-256 communique avec 16 hôtes.
Les hôtes récupèrent les données depuis le système de fichiers ou la mémoire locale, effectuent tout prétraitement requis sur les données, puis transfèrent les données prétraitées vers les cœurs de TPU. Nous considérons individuellement chacune de ces trois phases de traitement des données effectuées par l'hôte et nous les désignons par les termes : 1) stockage, 2) prétraitement, 3) transfert. La figure suivante illustre une vue d'ensemble du schéma:
Pour optimiser les performances, le système doit être équilibré. Si le processeur hôte prend plus de temps que le TPU pour terminer les trois phases de traitement des données, l'exécution est limitée par l'hôte. Les deux cas sont illustrés dans le schéma suivant:
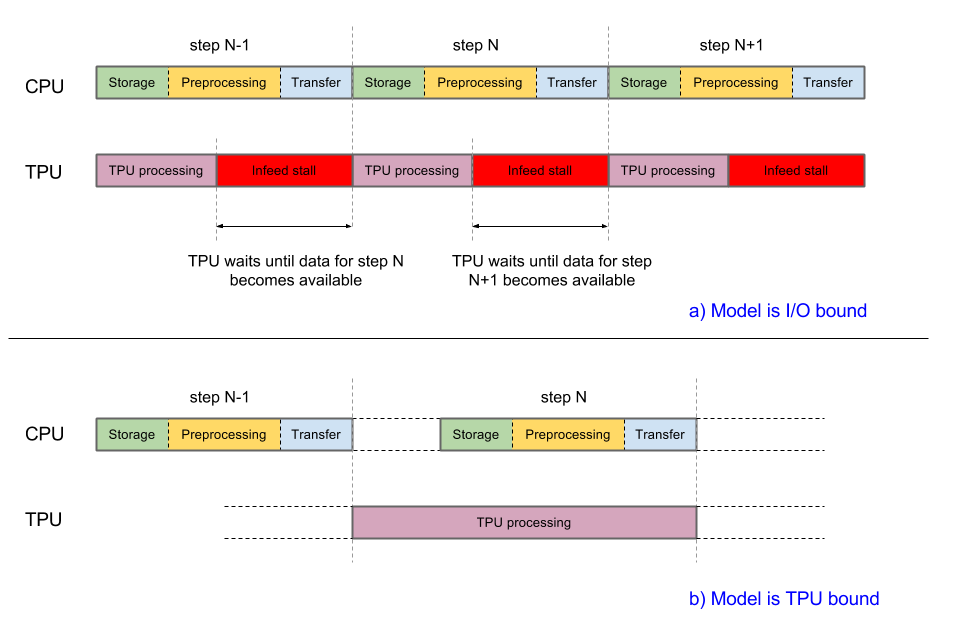
L'implémentation actuelle d'Inception v3 est sur le point d'être subordonnée aux entrées. Les images sont extraites du système de fichiers, décodées, puis prétraitées. Différents types d'étapes de prétraitement sont disponibles, allant de modérées à complexes. Si nous utilisons les étapes de prétraitement les plus complexes, le pipeline d'entraînement sera lié au prétraitement. Vous pouvez atteindre une justesse supérieure à 78,1% en utilisant une étape de prétraitement modérément complexe qui maintient le modèle lié au TPU.
Le modèle utilise tf.data.Dataset pour gérer le traitement du pipeline d'entrée. Pour en savoir plus sur l'optimisation des pipelines d'entrée, consultez le guide sur les performances des ensembles de données.
Bien que vous puissiez définir une fonction et la transmettre à l'API Estimator, la classe InputPipeline encapsule toutes les fonctionnalités requises.
L'API Estimator facilite l'utilisation de cette classe. Transmettez-le au paramètre input_fn des fonctions train() et evaluate(), comme indiqué dans l'extrait de code suivant:
def main(unused_argv):
…
inception_classifier = tpu_estimator.TPUEstimator(
model_fn=inception_model_fn,
use_tpu=FLAGS.use_tpu,
config=run_config,
params=params,
train_batch_size=FLAGS.train_batch_size,
eval_batch_size=eval_batch_size,
batch_axis=(batch_axis, 0))
…
for cycle in range(FLAGS.train_steps // FLAGS.train_steps_per_eval):
tf.logging.info('Starting training cycle %d.' % cycle)
inception_classifier.train(
input_fn=InputPipeline(True), steps=FLAGS.train_steps_per_eval)
tf.logging.info('Starting evaluation cycle %d .' % cycle)
eval_results = inception_classifier.evaluate(
input_fn=InputPipeline(False), steps=eval_steps, hooks=eval_hooks)
tf.logging.info('Evaluation results: %s' % eval_results)
Les principaux éléments de InputPipeline sont présentés dans l'extrait de code suivant.
class InputPipeline(object):
def __init__(self, is_training):
self.is_training = is_training
def __call__(self, params):
# Storage
file_pattern = os.path.join(
FLAGS.data_dir, 'train-*' if self.is_training else 'validation-*')
dataset = tf.data.Dataset.list_files(file_pattern)
if self.is_training and FLAGS.initial_shuffle_buffer_size > 0:
dataset = dataset.shuffle(
buffer_size=FLAGS.initial_shuffle_buffer_size)
if self.is_training:
dataset = dataset.repeat()
def prefetch_dataset(filename):
dataset = tf.data.TFRecordDataset(
filename, buffer_size=FLAGS.prefetch_dataset_buffer_size)
return dataset
dataset = dataset.apply(
tf.contrib.data.parallel_interleave(
prefetch_dataset,
cycle_length=FLAGS.num_files_infeed,
sloppy=True))
if FLAGS.followup_shuffle_buffer_size > 0:
dataset = dataset.shuffle(
buffer_size=FLAGS.followup_shuffle_buffer_size)
# Preprocessing
dataset = dataset.map(
self.dataset_parser,
num_parallel_calls=FLAGS.num_parallel_calls)
dataset = dataset.prefetch(batch_size)
dataset = dataset.apply(
tf.contrib.data.batch_and_drop_remainder(batch_size))
dataset = dataset.prefetch(2) # Prefetch overlaps in-feed with training
images, labels = dataset.make_one_shot_iterator().get_next()
# Transfer
return images, labels
La section concernant le stockage commence par la création d'un ensemble de données et comprend la lecture des fichiers TFRecord à partir de l'espace de stockage (à l'aide de tf.data.TFRecordDataset). Les fonctions spéciales repeat() et shuffle() sont utilisées si nécessaire. La fonction tf.contrib.data.parallel_interleave() mappe la fonction prefetch_dataset() sur son entrée pour produire des ensembles de données imbriqués et renvoie leurs éléments entrelacés. Elle récupère les éléments des ensembles de données imbriqués cycle_length en parallèle, ce qui augmente le débit. L'argument sloppy assouplit la contrainte exigeant que les sorties soient produites dans un ordre déterministe et permet à la mise en œuvre de sauter les ensembles de données imbriqués dont les éléments ne sont pas immédiatement disponibles sur demande.
La section concernant le prétraitement appelle dataset.map(parser), qui à son tour appelle la fonction d'analyseur dans laquelle les images sont prétraitées. Les détails de la phase de prétraitement sont abordés à la section suivante.
La section concernant le transfert (à la fin de la fonction) comporte la ligne return images, labels. TPUEstimator prend les valeurs renvoyées et les transmet automatiquement à l'appareil.
La figure suivante montre un exemple de trace des performances Cloud TPU d'Inception v3. Le temps de calcul TPU, sans tenir compte des blocages d'alimentation, est d'environ 815 ms.
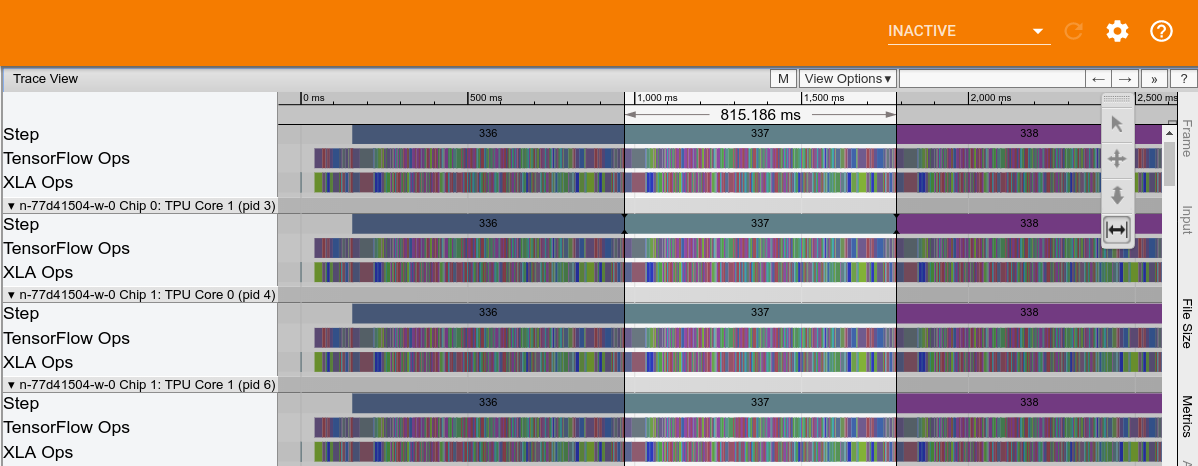
Le stockage hôte est écrit dans la trace et illustré dans la capture d'écran suivante:

La capture d'écran suivante montre le prétraitement hôte, qui comprend le décodage des images et une série de fonctions de distorsion d'image:

La capture d'écran suivante montre le transfert hôte/TPU:

Étape de prétraitement
Le prétraitement des images est un élément crucial du système. Il peut influencer la justesse maximale atteinte par le modèle pendant l'entraînement. Les images doivent être au moins décodées et redimensionnées pour s'adapter au modèle. Pour Inception, la taille des images doit être de 299 x 299 x 3 pixels.
Toutefois, un simple décodage et redimensionnement ne suffisent pas pour obtenir une bonne précision. L'ensemble de données d'entraînement ImageNet contient 1 281 167 images. Une passe effectuée sur l'ensemble des images d'apprentissage correspond à une époque. Pendant l'entraînement, le modèle nécessite plusieurs passes dans l'ensemble de données d'entraînement pour améliorer ses capacités de reconnaissance d'images. Pour entraîner Inception v3 avec une précision suffisante, utilisez entre 140 et 200 époques en fonction de la taille de lot globale.
Il est utile de modifier les images en continu avant de les alimenter avec le modèle, afin qu'une image particulière soit légèrement différente à chaque époque. La meilleure façon de réaliser ce prétraitement des images relève autant de l'art que de la science. Une étape de prétraitement bien conçue peut améliorer considérablement les capacités de reconnaissance d'un modèle. Une étape de prétraitement trop simple peut créer un plafond artificiel sur la justesse que le même modèle peut atteindre pendant l'entraînement.
Inception v3 offre des options pour la phase de prétraitement, allant d'une complexité relativement faible et peu coûteuse en calcul à assez complexe et coûteuse en calcul. Les fichiers vgg_preprocessing.py et inception_preprocessing.py illustrent deux scénarios de prétraitement distincts.
Le fichier vgg_preprocessing.py définit une étape de prétraitement qui a été utilisée avec succès pour entraîner resnet avec une justesse de 75 %, mais qui produit des résultats sous-optimaux lorsqu'elle est appliquée à Inception v3.
Le fichier inception_preprocessing.py contient une étape de prétraitement qui a été utilisée pour entraîner Inception v3 avec une précision comprise entre 78,1 et 78,5% en cas d'exécution sur des TPU.
Le prétraitement diffère selon que le modèle est en cours d'entraînement ou utilisé pour l'inférence ou l'évaluation.
Au moment de l'évaluation, le prétraitement est simple: recadrez une zone centrale de l'image, puis redimensionnez-la à la taille par défaut de 299 x 299. L'extrait de code suivant illustre une mise en œuvre du prétraitement:
def preprocess_for_eval(image, height, width, central_fraction=0.875):
with tf.name_scope(scope, 'eval_image', [image, height, width]):
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.image.central_crop(image, central_fraction=central_fraction)
image = tf.expand_dims(image, 0)
image = tf.image.resize_bilinear(image, [height, width], align_corners=False)
image = tf.squeeze(image, [0])
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
image.set_shape([height, width, 3])
return image
Pendant l'entraînement, le recadrage est aléatoire : un cadre englobant est choisi de manière aléatoire pour sélectionner une région de l'image qui est ensuite redimensionnée. L'image redimensionnée est ensuite éventuellement retournée et ses couleurs sont soumises à une distorsion. L'extrait de code suivant montre la mise en œuvre de ces opérations:
def preprocess_for_train(image, height, width, bbox, fast_mode=True, scope=None):
with tf.name_scope(scope, 'distort_image', [image, height, width, bbox]):
if bbox is None:
bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4])
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
distorted_image, distorted_bbox = distorted_bounding_box_crop(image, bbox)
distorted_image.set_shape([None, None, 3])
num_resize_cases = 1 if fast_mode else 4
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, method: tf.image.resize_images(x, [height, width], method),
num_cases=num_resize_cases)
distorted_image = tf.image.random_flip_left_right(distorted_image)
if FLAGS.use_fast_color_distort:
distorted_image = distort_color_fast(distorted_image)
else:
num_distort_cases = 1 if fast_mode else 4
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, ordering: distort_color(x, ordering, fast_mode),
num_cases=num_distort_cases)
distorted_image = tf.subtract(distorted_image, 0.5)
distorted_image = tf.multiply(distorted_image, 2.0)
return distorted_image
La fonction distort_color est chargée d'altérer les couleurs. Elle propose un mode rapide modifiant seulement la luminosité et la saturation. Le mode complet modifie la luminosité, la saturation et la teinte, dans un ordre aléatoire.
def distort_color(image, color_ordering=0, fast_mode=True, scope=None):
with tf.name_scope(scope, 'distort_color', [image]):
if fast_mode:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
else:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
else:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
elif color_ordering == 1:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
elif color_ordering == 2:
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
elif color_ordering == 3:
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
return tf.clip_by_value(image, 0.0, 1.0)
La fonction distort_color est coûteuse en termes de calculs, en partie en raison des conversions non linéaires de RVB vers HSV et de HSV vers RVB. Celles-ci sont nécessaires pour accéder à la teinte et à la saturation. Les modes rapide et complet ont tous les deux besoin de ces conversions et bien que le mode rapide soit moins coûteux en calcul, lorsqu'il est activé, il pousse toujours le modèle vers la région subordonnée aux calculs processeur.
Une nouvelle fonction alternative distort_color_fast a également été ajoutée à la liste des options. Cette fonction mappe l'image RVB en YCrCb en utilisant le schéma de conversion JPEG, et modifie de manière aléatoire la luminosité et les chromas Cr/Cb avant de revenir en RVB. L'extrait de code suivant montre une implémentation de cette fonction:
def distort_color_fast(image, scope=None):
with tf.name_scope(scope, 'distort_color', [image]):
br_delta = random_ops.random_uniform([], -32./255., 32./255., seed=None)
cb_factor = random_ops.random_uniform(
[], -FLAGS.cb_distortion_range, FLAGS.cb_distortion_range, seed=None)
cr_factor = random_ops.random_uniform(
[], -FLAGS.cr_distortion_range, FLAGS.cr_distortion_range, seed=None)
channels = tf.split(axis=2, num_or_size_splits=3, value=image)
red_offset = 1.402 * cr_factor + br_delta
green_offset = -0.344136 * cb_factor - 0.714136 * cr_factor + br_delta
blue_offset = 1.772 * cb_factor + br_delta
channels[0] += red_offset
channels[1] += green_offset
channels[2] += blue_offset
image = tf.concat(axis=2, values=channels)
image = tf.clip_by_value(image, 0., 1.)
return image
Voici un exemple d'image ayant subi un prétraitement. Une région de l'image a été sélectionnée au hasard et ses couleurs ont été modifiées à l'aide de la fonction distort_color_fast.

La fonction distort_color_fast est efficace en termes de calcul et permet de garder l'entraînement subordonné au temps d’exécution du TPU. De plus, il a été utilisé pour entraîner le modèle Inception v3 avec une justesse supérieure à 78,1% en utilisant des tailles de lot comprises entre 1 024 et 16 384.
Optimiseur
Le modèle actuel présente trois types d'optimiseurs : SGD (méthode du gradient stochastique), Momentum (moment) et RMSProp.
Stochastic gradient descent (SGD) est la mise à jour la plus simple: les pondérations sont déplacées dans la direction du gradient négatif. Malgré sa simplicité, il permet d'obtenir de bons résultats sur certains modèles. La dynamique des mises à jour peut être décrite comme suit :
Momentum est un optimiseur populaire qui permet fréquemment d'obtenir une convergence plus rapide que SGD. Il met à jour les pondérations de façon très semblable à SGD, mais ajoute également un composant suivant la direction de la mise à jour précédente. Les équations suivantes décrivent les mises à jour effectuées par l'optimiseur de momentum:
que l'on peut écrire comme suit :
Le dernier terme est le composant suivant la direction de la mise à jour précédente.
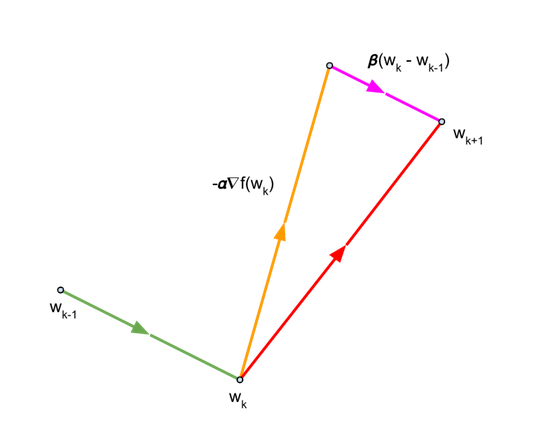
Pour le moment \({\beta}\), nous utilisons la valeur de 0,9.
RMSprop est un optimiseur populaire initialement proposé par Geoff Hinton durant l'une de ses conférences. Les équations suivantes décrivent le fonctionnement de l'optimiseur:
Pour Inception v3, les tests montrent que RMSProp donne les meilleurs résultats en termes de justesse maximale et de temps requis pour l'atteindre, suivi de près par Momentum. Ainsi, RMSprop est défini comme l'optimiseur par défaut. Les paramètres utilisés sont : decay \({\alpha}\) = 0,9, momentum \({\beta}\) = 0,9 et \({\epsilon}\) = 1,0.
L'extrait de code suivant montre comment définir ces paramètres:
if FLAGS.optimizer == 'sgd':
tf.logging.info('Using SGD optimizer')
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate)
elif FLAGS.optimizer == 'momentum':
tf.logging.info('Using Momentum optimizer')
optimizer = tf.train.MomentumOptimizer(
learning_rate=learning_rate, momentum=0.9)
elif FLAGS.optimizer == 'RMS':
tf.logging.info('Using RMS optimizer')
optimizer = tf.train.RMSPropOptimizer(
learning_rate,
RMSPROP_DECAY,
momentum=RMSPROP_MOMENTUM,
epsilon=RMSPROP_EPSILON)
else:
tf.logging.fatal('Unknown optimizer:', FLAGS.optimizer)
Lorsqu'il s'exécute sur des TPU et à l'aide de l'API Estimator, l'optimiseur doit être encapsulé dans une fonction CrossShardOptimizer afin d'assurer la synchronisation entre les instances dupliquées (ainsi que toute communication nécessaire entre les instances). L'extrait de code suivant montre comment le modèle Inception v3 encapsule l'optimiseur:
if FLAGS.use_tpu:
optimizer = tpu_optimizer.CrossShardOptimizer(optimizer)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss, global_step=global_step)
Moyenne mobile exponentielle
Lors de l'entraînement, les paramètres pouvant être entraînés sont mis à jour lors de la rétropropagation conformément aux règles de mise à jour de l'optimiseur. Les équations décrivant ces règles ont été abordées dans la section précédente et sont répétées ici pour plus de commodité:
La moyenne glissante exponentielle (également appelée "lissage exponentiel") est une étape de post-traitement facultative appliquée aux pondérations mises à jour et peut parfois entraîner des améliorations notables des performances. TensorFlow fournit la fonction tf.train.ExponentialMovingAverage qui calcule la moyenne mobile exponentielle \({\hat{\theta}}\) de la pondération \({\theta}\) à l'aide de la formule suivante :
où \({\alpha}\) est un facteur de décroissance (proche de 1,0). Dans le modèle Inception v3,\({\alpha}\) est défini sur 0,995.
Même si ce calcul est un filtre à réponse impulsive infinie (IIR), le facteur de décroissance établit une fenêtre effective dans laquelle réside la plupart de l'énergie (ou des échantillons pertinents), comme illustré dans le schéma suivant:
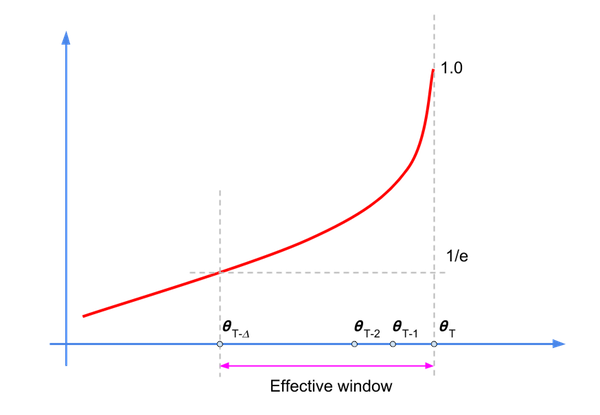
Nous pouvons réécrire l'équation du filtre comme suit:
où nous avons utilisé \({\hat\theta_{-1}}=0\).
Les valeurs \({\alpha}^k\) décroissent à mesure que k augmente. Par conséquent, seul un sous-ensemble des échantillons aura une influence notable sur \(\hat{\theta}_{t+T+1}\). La règle de base pour la valeur du facteur de dépréciation est la suivante : \(\frac {1} {1-\alpha}\), ce qui correspond à \({\alpha}\) = 200 pour =0,995.
Nous obtenons d'abord une collection de variables pouvant être entraînées, puis utilisons la méthode apply() pour créer des variables fictives pour chaque variable entraînée.
L'extrait de code suivant illustre l'implémentation du modèle Inception v3:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss, global_step=global_step)
if FLAGS.moving_average:
ema = tf.train.ExponentialMovingAverage(
decay=MOVING_AVERAGE_DECAY, num_updates=global_step)
variables_to_average = (tf.trainable_variables() +
tf.moving_average_variables())
with tf.control_dependencies([train_op]), tf.name_scope('moving_average'):
train_op = ema.apply(variables_to_average)
Nous aimerions utiliser les variables de moyenne mobile exponentielle lors de l'évaluation. Nous définissons la classe LoadEMAHook qui applique la méthode variables_to_restore() au fichier de point de contrôle à évaluer à l'aide des noms de variables fictives:
class LoadEMAHook(tf.train.SessionRunHook):
def __init__(self, model_dir):
super(LoadEMAHook, self).__init__()
self._model_dir = model_dir
def begin(self):
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY)
variables_to_restore = ema.variables_to_restore()
self._load_ema = tf.contrib.framework.assign_from_checkpoint_fn(
tf.train.latest_checkpoint(self._model_dir), variables_to_restore)
def after_create_session(self, sess, coord):
tf.logging.info('Reloading EMA...')
self._load_ema(sess)
La fonction hooks est transmise à evaluate(), comme indiqué dans l'extrait de code suivant:
if FLAGS.moving_average:
eval_hooks = [LoadEMAHook(FLAGS.model_dir)]
else:
eval_hooks = []
…
eval_results = inception_classifier.evaluate(
input_fn=InputPipeline(False), steps=eval_steps, hooks=eval_hooks)
Normalisation par lots
La normalisation par lots est une technique couramment utilisée pour normaliser les caractéristiques en entrée des modèles, ce qui peut réduire considérablement le temps de convergence. Il s’agit de l’une des améliorations algorithmiques les plus populaires et les plus utiles en matière de machine learning de ces dernières années. Elle est utilisée dans un large éventail de modèles, tels qu'Inception v3.
Les entrées d'activation sont normalisées en soustrayant la moyenne et en divisant par l'écart type. Pour préserver l'équilibre lorsqu'il y a rétropropagation, deux paramètres pouvant être entraînés sont introduits au niveau de chaque couche. Les sorties normalisées \({\hat{x}}\) subissent une opération ultérieure \({\gamma\hat{x}}+\beta\), où \({\gamma}\) et \({\beta}\) sont une sorte d'écart-type et de moyenne apprise par le modèle lui-même.
L'ensemble complet des équations est disponible dans l'article et nous le reproduisons ici pour plus de commodité :
Entrée : Valeurs de x sur un mini-lot : \(\Phi=\) { \({x_{1..m}\\} \) } Paramètres à apprendre : \({\gamma}\),\({\beta}\)
Sortie : { \({y_i}=BN_{\gamma,\beta}{(x_i)}\) }
\[{\mu_\phi} \leftarrow {\frac{1}{m}}{\sum_{i=1}^m}x_i \qquad \mathsf(mini-batch\ mean)\]
\[{\sigma_\phi}^2 \leftarrow {\frac{1}{m}}{\sum_{i=1}^m} {(x_i - {\mu_\phi})^2} \qquad \mathbf(mini-batch\ variance)\]
\[{\hat{x_i}} \leftarrow {\frac{x_i-{\mu_\phi}}{\sqrt {\sigma^2_\phi}+{\epsilon}}}\qquad \mathbf(normalize)\]
\[{y_i}\leftarrow {\gamma \hat{x_i}} + \beta \equiv BN_{\gamma,\beta}{(x_i)}\qquad \mathbf(scale \ and \ shift)\]
La normalisation a lieu pendant l'entraînement, mais au moment de l'évaluation, nous souhaitons que le modèle se comporte de manière déterministe: le résultat de la classification d'une image doit dépendre uniquement de l'image d'entrée et non de l'ensemble des images qui lui sont fournies. Nous devons donc corriger \({\mu}\) et \({\sigma}^2\), puis utiliser des valeurs qui représentent les statistiques relatives au remplissage de l'image.
Le modèle calcule des moyennes mobiles de la moyenne et de la variance sur les mini-lots:
\[{\hat\mu_i} = {\alpha \hat\mu_{t-1}}+{(1-\alpha)\mu_t}\]
\[{\hat\sigma_t}^2 = {\alpha{\hat\sigma^2_{t-1}}} + {(1-\alpha) {\sigma_t}^2}\]
Dans le cas spécifique d'Inception v3, nous avons obtenu un facteur de décroissance raisonnable (en utilisant les réglages d'hyperparamètres) à utiliser dans les GPU. Nous aimerions utiliser cette valeur également sur TPU, mais pour cela, nous devons procéder à des ajustements.
La moyenne mobile et la variance de la normalisation par lot sont toutes deux calculées à l'aide d'un filtre passe à perte, comme indiqué dans l'équation suivante (ici, \({y_t}\) représente la moyenne ou la variance mobile):
\[{y_t}={\alpha y_{t-1}}+{(1-\alpha)}{x_t} \]
(1)
Dans une tâche GPU 8x1 (synchrone), chaque instance répliquée lit la moyenne mobile actuelle et la met à jour. L'instance répliquée actuelle doit écrire la nouvelle variable mobile avant que l'instance répliquée suivante puisse la lire.
Lorsqu'il y a huit instances dupliquées, le jeu d'opérations requis pour une mise à jour d'ensemble est le suivant :
\[{y_t}={\alpha y_{t-1}}+{(1-\alpha)}{x_t} \]
\[{y_{t+1}}={\alpha y_{t}}+{(1-\alpha)}{x_{t+1}} \]
\[{y_{t+2}}={\alpha y_{t+1}}+{(1-\alpha)}{x_{t+2}} \]
\[{y_{t+3}}={\alpha y_{t+2}}+{(1-\alpha)}{x_{t+3}} \]
\[{y_{t+4}}={\alpha y_{t+3}}+{(1-\alpha)}{x_{t+4}} \]
\[{y_{t+5}}={\alpha y_{t+4}}+{(1-\alpha)}{x_{t+5}} \]
\[{y_{t+6}}={\alpha y_{t+5}}+{(1-\alpha)}{x_{t+6}} \]
\[{y_{t+7}}={\alpha y_{t+6}}+{(1-\alpha)}{x_{t+7}} \]
Cet ensemble de huit mises à jour séquentielles peut être écrit synthétiquement sous la forme :
\[{y_{t+7}}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{x_{t+k}}\]
(2)
Dans la mise en œuvre actuelle du calcul du moment mobile sur les TPU, chaque segment effectue les calculs de manière indépendante, et il n'y a pas de communication entre partitions. Les lots sont distribués à chaque partition et chacune traite 1/8e du nombre total de lots (lorsqu'il y a huit partitions).
Bien que chaque segment calcule les moments mobiles (c'est-à-dire la moyenne et la variance), seuls les résultats de la partition 0 sont communiqués au processeur hôte. Ainsi, une seule instance répliquée effectue la mise à jour de la moyenne/variance mobile:
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\]
(3)
et cette mise à jour se fait 1/8e du taux de son équivalent séquentiel. Pour comparer les équations de mise à jour GPU et TPU, nous devons aligner les échelles de temps respectives. Plus précisément, l'ensemble des opérations qui constituent un ensemble de huit mises à jour séquentielles sur le GPU doit être comparé à une seule mise à jour sur le TPU, comme illustré dans le schéma suivant:
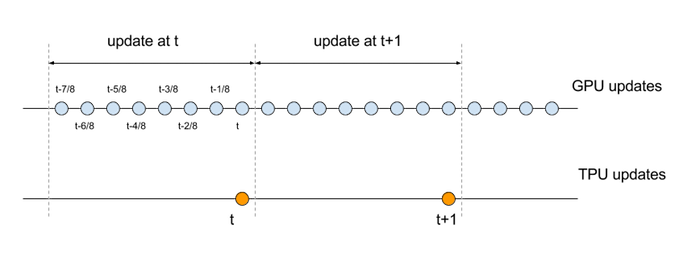
Voyons les équations avec les index temporels modifiés :
\[{y_t}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{x_{t-k/8}} \qquad \mathsf(GPU)\]
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\qquad \mathsf(TPU) \]
Si nous partons du principe que huit mini-lots (normalisés pour toutes les dimensions pertinentes) génèrent des valeurs similaires dans la mise à jour séquentielle du GPU 8 mini-lots, nous pouvons estimer ces équations comme suit:
\[{y_t}={\alpha^8y_{t-1}}+(1-\alpha){\sum_{k=0}^7} {\alpha^{7-k}}{\hat{x_t}}={\alpha^8y_{t-1}+(1-\alpha^8){\hat{x_t}}} \qquad \mathsf(GPU)\]
\[{z_t}={\beta {z_{t-1}}}+{(1-\beta)u_t}\qquad \mathsf(TPU) \]
Pour correspondre à l'effet d'un facteur de décroissance donné sur le GPU, nous modifions en conséquence le facteur de dépréciation sur le TPU. Plus précisément, nous définissons \({\beta}\)=\({\alpha}^8\).
Pour Inception v3, la valeur de décroissance utilisée sur GPU est de \({\alpha}\)=0,9997, ce qui se traduit par une valeur de décroissance sur TPU de \({\beta}\)=0,9976.
Adaptation du taux d'apprentissage
À mesure que la taille des lots augmente, l'entraînement devient plus difficile. Différentes techniques continuent d'être proposées pour permettre un entraînement efficace pour les lots de grande taille (consultez les exemples ici, ici et ici).
L'une de ces techniques consiste à augmenter progressivement le taux d'apprentissage (on parle également de montée en puissance). L'activation progressive a permis d'entraîner le modèle avec une justesse supérieure à 78,1% pour des tailles de lot allant de 4 096 à 16 384. Pour Inception v3, le taux d'apprentissage est d'abord défini sur environ 10% du taux d'apprentissage de départ normal. Le taux d'apprentissage reste constant à cette valeur faible pour un (petit) nombre spécifié d'"époques à froid", puis commence une augmentation linéaire pour un nombre spécifié d'époques de préchauffage. À la fin des "époques d'échauffement", le taux d'apprentissage recoupe l'apprentissage par décroissance exponentiel normal. Ceci est illustré dans le schéma suivant.
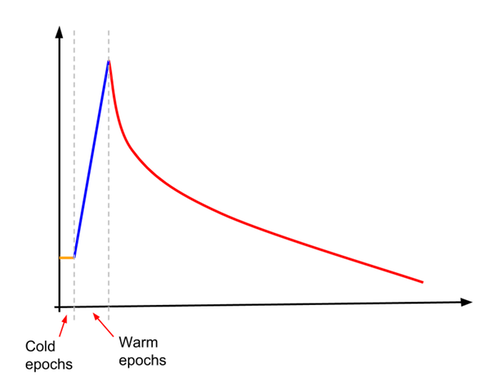
L'extrait de code suivant montre comment procéder:
initial_learning_rate = FLAGS.learning_rate * FLAGS.train_batch_size / 256
if FLAGS.use_learning_rate_warmup:
warmup_decay = FLAGS.learning_rate_decay**(
(FLAGS.warmup_epochs + FLAGS.cold_epochs) /
FLAGS.learning_rate_decay_epochs)
adj_initial_learning_rate = initial_learning_rate * warmup_decay
final_learning_rate = 0.0001 * initial_learning_rate
train_op = None
if training_active:
batches_per_epoch = _NUM_TRAIN_IMAGES / FLAGS.train_batch_size
global_step = tf.train.get_or_create_global_step()
current_epoch = tf.cast(
(tf.cast(global_step, tf.float32) / batches_per_epoch), tf.int32)
learning_rate = tf.train.exponential_decay(
learning_rate=initial_learning_rate,
global_step=global_step,
decay_steps=int(FLAGS.learning_rate_decay_epochs * batches_per_epoch),
decay_rate=FLAGS.learning_rate_decay,
staircase=True)
if FLAGS.use_learning_rate_warmup:
wlr = 0.1 * adj_initial_learning_rate
wlr_height = tf.cast(
0.9 * adj_initial_learning_rate /
(FLAGS.warmup_epochs + FLAGS.learning_rate_decay_epochs - 1),
tf.float32)
epoch_offset = tf.cast(FLAGS.cold_epochs - 1, tf.int32)
exp_decay_start = (FLAGS.warmup_epochs + FLAGS.cold_epochs +
FLAGS.learning_rate_decay_epochs)
lin_inc_lr = tf.add(
wlr, tf.multiply(
tf.cast(tf.subtract(current_epoch, epoch_offset), tf.float32),
wlr_height))
learning_rate = tf.where(
tf.greater_equal(current_epoch, FLAGS.cold_epochs),
(tf.where(tf.greater_equal(current_epoch, exp_decay_start),
learning_rate, lin_inc_lr)),
wlr)
# Set a minimum boundary for the learning rate.
learning_rate = tf.maximum(
learning_rate, final_learning_rate, name='learning_rate')