概览
Text-to-Speech 生成自然人类语音的原始音频数据。也就是说,它生成的音频听上去像人在说话。当您向 Text-to-Speech 发送合成请求时,您必须指定“说出”字词的语音。
您可以从 Text-to-Speech 中选择多种语音。语音因语言、性别和口音(适用于某些语言)而异。有些语言有多种语音可供选择。请参见支持的语音页面,查看适用于您所用语言的完整语音列表。在向 API 发送请求时,您可以设置 VoiceSelectionParams 字段,以指示 Text-to-Speech 使用此列表的特定语音。如需详细了解如何发送 synthesize 请求,请参阅 Text-to-Speech 快速入门。
Neural2 语音
Text-to-Speech API 提供了一种名为 Neural2 的优质语音层级。Neural2 语音基于用于创建自定义语音的相同技术。Neural2 代表合成语音生成的最新功能,并允许任何人使用 Custom Voice 技术,而无需训练自己的自定义语音。在全球和单区域端点中提供。
示例 1:Neural2 语音
Studio 语音(预览版)
Text-to-Speech API 提供 Studio 语音。这种语音类型专门设计用于诸如叙述和新闻阅读等长篇文字。
示例 1:朗读《了不起的盖茨比》(Great Gatsby) 的 en-US-Studio-O 语音。
标准语音
Text-to-Speech 提供的语音在制作方式和用于创建语音机器模型的合成语音技术方面也有所不同。“参数式文字转语音”是一种场景语音技术,通常通过称为声码器 的信号处理算法传递输出来生成音频数据。Text-to-Speech 中提供的许多标准语音都使用了这种技术的变体。
WaveNet 语音
Text-to-Speech 还提供一组使用 WaveNet 模型生成的优质语音,Google 助理、Google 搜索以及 Google 翻译也使用该技术生成语音。WaveNet 技术提供的不仅仅是一系列合成语音:它代表了一种生成合成语音的全新方式。
与其他文本转语音系统相比,WaveNet 生成的语音听起来更为自然。它合成的语音在音节、音位和字词的重音与音调方面更像人类语音。
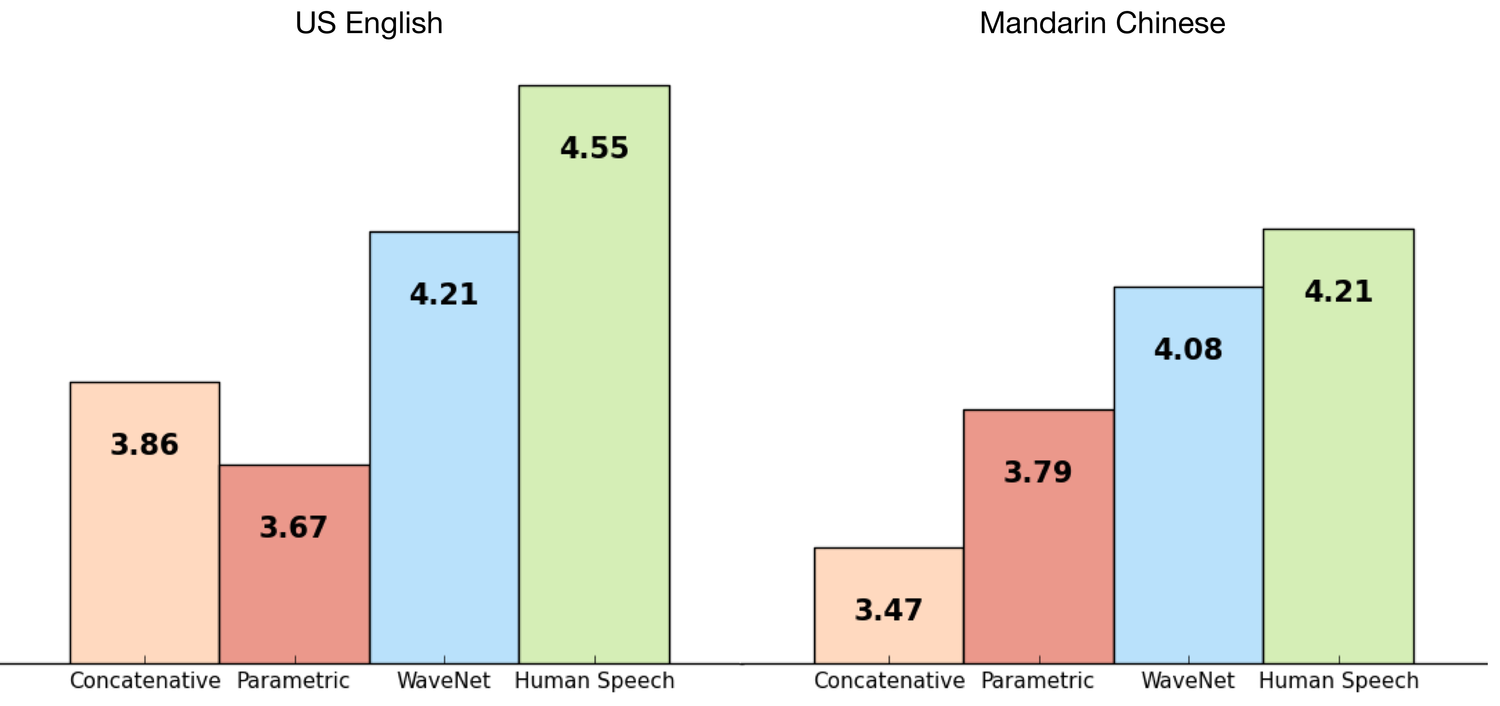 图 1:WaveNet 与其他合成语音以及人类语音的比较图表。 y 轴值表示每个语音的平均意见分数 (MOS)。测试对象会根据每声音与自然语音的相似程度,以 1 到 5 的等级对声音进行排名。如需详细了解 MOS 分数和 WaveNet 技术,请参阅 DeepMind WaveNet页面。
图 1:WaveNet 与其他合成语音以及人类语音的比较图表。 y 轴值表示每个语音的平均意见分数 (MOS)。测试对象会根据每声音与自然语音的相似程度,以 1 到 5 的等级对声音进行排名。如需详细了解 MOS 分数和 WaveNet 技术,请参阅 DeepMind WaveNet页面。
与大多数其他文本转语音系统不同,WaveNet 模型从头开始生成原始音频波形。该模型使用一个经过大量语音样本进行训练的神经网络。在训练期间,该网络提取语音的基础结构,例如哪些音调彼此跟随以及真实的语音波形是什么样子。当给定文本输入时,经过训练的 WaveNet 模型可以从头开始生成相应的语音波形,每次一个样本,每秒最多生成 24,000 个样本并在各个声音之间无缝过渡。
如果您想听听 Wavenet 生成的音频剪辑与其他文本转语音系统生成的剪辑有何不同,请比较下面的两个剪辑。
示例 1:高品质、非 WaveNet 语音
示例 2:WaveNet 语音
自行试用
如果您是 Google Cloud 新手,请创建一个账号来评估 Text-to-Speech 在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
免费试用 Text-to-Speech