Overview
Text-to-Speech generates audio data of natural, human-like speech. That is, it creates audio that sounds like a person talking. When you send a synthesis request to Text-to-Speech, you must specify a voice.
There are a wide selection of voices available for you to pick from in
Text-to-Speech. The voices differ by language, gender, and accent
(for some languages). Some languages have multiple voices to choose from. See
the Supported Voices page for a complete list
of voices available in your language. You can tell Text-to-Speech to
use a specific voice from this list by setting the
VoiceSelectionParams
fields when you send a request to the API. See the Text-to-Speech
Quickstarts for details on how to send a
synthesize request.
Journey voices
Journey voices (experimental) are backed by advancements in large language modeling, which improves the prosodic richness. Journey voices can manage a broader range of pitch, volume, timbre, and length. They also have enhanced speech mechanics, making them better at handling disfluencies and interrupts compared to our other voice options. We recommend experimenting with these voices for conversational speech use cases.
Example 1. The en-US-Journey-D voice
Casual voices (Preview)
Casual voices were designed to manage a conversational, imperfect dialogue for naturalness and comfort with human users. They support disfluencies (oh, uh, um, mhm) and have a more natural cadence and tone.
Studio voices
The Text-to-Speech API provides a premium voice tier called Studio. This voice type is designed specifically for use with long-form texts such as narration and news reading.
Example 1. The en-US-Studio-O voice reading the Great Gatsby.
Neural2 voices
The Text-to-Speech API provides a voice tier called Neural2. Neural2 voices are based on the same technology used to create a Custom Voice. Neural2 allows anyone to use Custom Voice technology without training their own custom voice. They're available in global and single region endpoints.
Example 1. Neural2 voice
WaveNet voices
The Text-to-Speech API also offers a group of premium voices generated using a WaveNet model, the same technology used to produce speech for Google Assistant, Google Search, and Google Translate. WaveNet technology provides more than just a series of synthetic voices: it represents a new way of creating synthetic speech.
A WaveNet generates speech that sounds more natural than other text-to-speech systems. It synthesizes speech with more human-like emphasis and inflection on syllables, phonemes, and words.
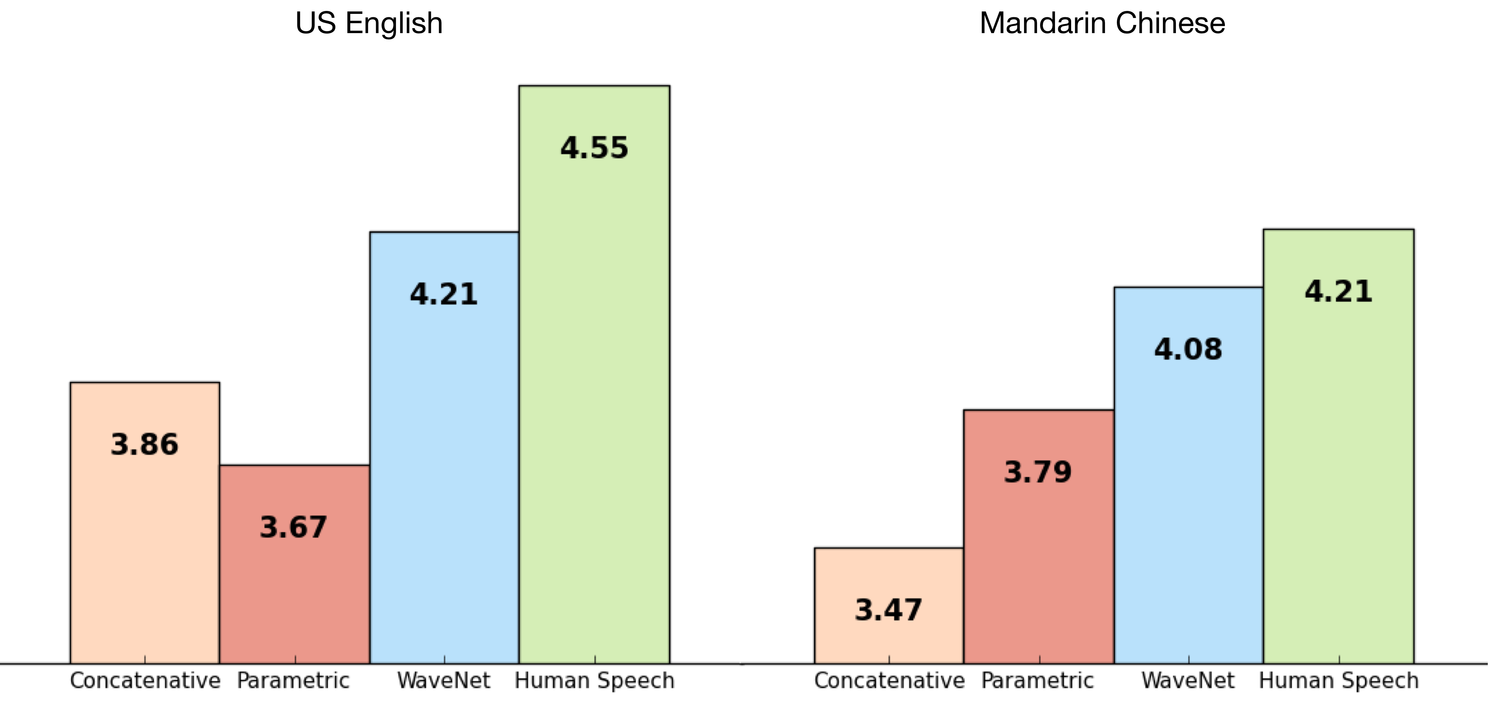 Figure 1. Chart showing comparison of WaveNet to other synthetic voices, human
speech. The y-axis values represent the Mean Opinion Score (MOS) for each voice.
Test subjects ranked each voice on a scale of 1-5 according to how much it
sounded like natural speech. For more information on MOS scores and WaveNet
technology, see the DeepMind WaveNet
page.
Figure 1. Chart showing comparison of WaveNet to other synthetic voices, human
speech. The y-axis values represent the Mean Opinion Score (MOS) for each voice.
Test subjects ranked each voice on a scale of 1-5 according to how much it
sounded like natural speech. For more information on MOS scores and WaveNet
technology, see the DeepMind WaveNet
page.
Unlike most other text-to-speech systems, a WaveNet model creates raw audio waveforms from scratch. The model uses a neural network that has been trained using a large volume of speech samples. During training, the network extracts the underlying structure of the speech, such as which tones follow each other and what a realistic speech waveform looks like. When given a text input, the trained WaveNet model can generate the corresponding speech waveforms from scratch, one sample at a time, with up to 24,000 samples per second and seamless transitions between the individual sounds.
To hear the difference between a WaveNet-generated audio clip and a clip generated by another text-to-speech process, compare the two audio clips below.
Example 1. High quality, non-WaveNet voice
Example 2. WaveNet voice
Standard voices
The voices offered by Text-to-Speech differ in how they are produced, the synthetic speech technology used to create the machine model of the voice. One common speech technology, parametric text-to-speech, typically generates audio data by passing outputs through signal processing algorithms known as vocoders. Many of the standard voices available in Text-to-Speech use a variation of this technology.
Try it for yourself
If you're new to Google Cloud, create an account to evaluate how Text-to-Speech performs in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
Try Text-to-Speech free