개요
Text-to-Speech는 자연스러운 인간 음성에 대한 원시 오디오 데이터를 만듭니다. 즉, 사람이 말하는 것처럼 들리는 오디오를 생성합니다. Text-to-Speech에 합성 요청을 보낼 때는 단어를 '말하는' 음성을 지정해야 합니다.
Text-to-Speech에서는 다양한 음성 중에서 원하는 음성을 선택할 수 있습니다. 음성은 언어, 성별, 억양(일부 언어만 해당)별로 다릅니다. 일부 언어는 여러 음성 중에서 선택할 수 있습니다. 사용 중인 언어로 제공되는 전체 음성 목록은 지원되는 음성 페이지를 참조하세요. API에 요청을 보낼 때 VoiceSelectionParams 필드를 설정하여 Text-to-Speech에서 이 목록의 특정 음성을 사용하도록 지시할 수 있습니다. synthesize 요청을 보내는 방법에 대한 자세한 내용은 Text-to-Speech 빠른 시작을 참조하세요.
Neural2 음성
Text-to-Speech API는 Neural2라는 프리미엄 음성 등급을 제공합니다. Neural2 음성은 Custom Voice를 만드는 데 사용된 것과 동일한 기술을 기반으로 합니다. Neural2는 합성 음성 생성의 최신 버전으로, 누구나 자신의 커스텀 음성을 학습시키지 않고도 Custom Voice 기술을 사용할 수 있게 해줍니다. 전역 및 단일 리전 엔드포인트에서 사용할 수 있습니다.
예시 1. Neural2 음성
Studio 음성(미리보기)
Text-to-Speech API는 Studio 음성을 제공합니다. 이 음성 유형은 나레이션 및 뉴스 읽기와 같은 긴 형식의 텍스트에 사용하도록 특별히 설계되었습니다.
예시 1. en-US-Studio-O 음성 읽기는 Great Gatsby입니다.
표준 음성
Text-to-Speech에서 제공되는 음성은 제작 방법, 음성의 머신 모델을 만드는 데 사용되는 합성 음성 기술에 따라 다릅니다. 일반적인 음성 기술인 파라메트릭 텍스트 음성 변환은 일반적으로 vocoder라고 하는 신호 처리 알고리즘을 통해 출력을 전달하여 오디오 데이터를 생성합니다. Text-to-Speech에서 사용할 수 있는 표준 음성의 대부분은 이러한 종류의 기술을 사용합니다.
WaveNet 음성
또한 Text-to-Speech API는 Google 어시스턴트, Google 검색, Google 번역에 사용되는 음성을 생성하는 데 사용되는 기술과 동일한 WaveNet 모델을 사용하여 생성되는 프리미엄 음성 그룹을 제공합니다. WaveNet 기술은 일련의 합성 음성뿐만 아니라 합성 음성을 생성하는 새로운 방법도 제공합니다.
WaveNet은 다른 TTS(텍스트 음성 변환) 시스템보다 자연스러운 소리를 생성합니다. 음절, 음소, 단어에 인간과 매우 비슷한 강세와 어조를 사용하여 음성을 합성합니다.
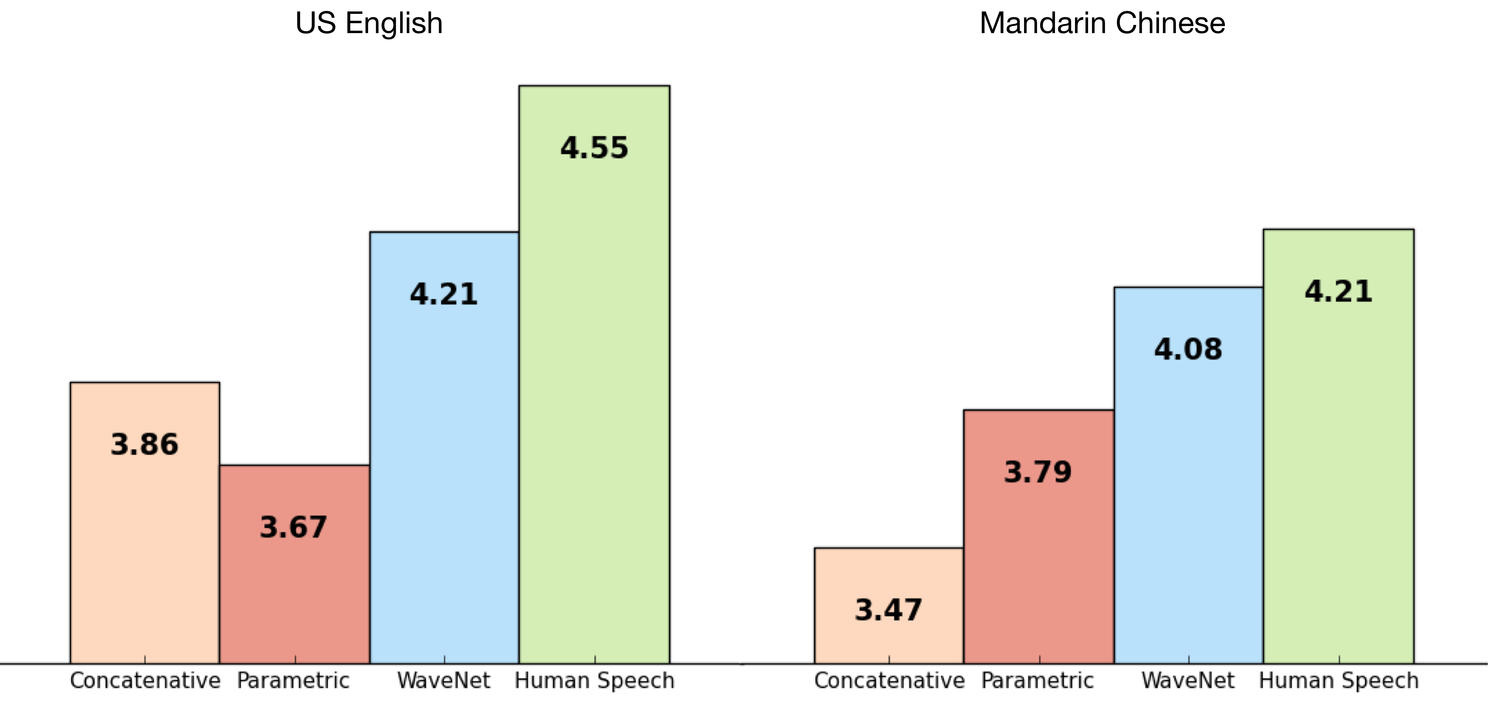 그림 1. WaveNet과 다른 합성 음성, 인간의 음성을 비교한 차트 y축 값은 각 음성의 Mean Opinion Score(MOS)를 나타냅니다.
테스트 항목은 자연스러운 정도에 따라 1~5점 척도로 각 음성의 순위를 매겼습니다. MOS 점수 및 WaveNet 기술에 대한 자세한 내용은 DeepMind WaveNet 페이지를 참조하세요.
그림 1. WaveNet과 다른 합성 음성, 인간의 음성을 비교한 차트 y축 값은 각 음성의 Mean Opinion Score(MOS)를 나타냅니다.
테스트 항목은 자연스러운 정도에 따라 1~5점 척도로 각 음성의 순위를 매겼습니다. MOS 점수 및 WaveNet 기술에 대한 자세한 내용은 DeepMind WaveNet 페이지를 참조하세요.
다른 대부분의 TTS(텍스트 음성 변환) 시스템과 달리 WaveNet 모델은 처음부터 원시 오디오 파형을 만듭니다. 이 모델은 다량의 음성 샘플을 사용하여 학습된 신경망을 사용합니다. 네트워크는 학습 단계에서 서로 이어지는 톤과 현실적인 음성 파형의 모양과 같은 음성의 기본 구조를 추출합니다. 텍스트 입력이 제공되면 학습된 WaveNet 모델이 해당하는 음성 파형을 처음부터 생성할 수 있습니다. 한 번에 하나의 샘플을 초당 최대 24,000개까지 생성하며, 개별 사운드 간에 원활한 전환을 지원합니다.
Wavenet에서 생성된 오디오 클립과 다른 TTS(텍스트 음성 변환) 프로세스에서 생성한 클립이 어떻게 다른지 들어보려면 아래에서 두 오디오 클립을 비교하세요.
예시 1. WaveNet 이외의 고품질 음성
예시 2. WaveNet 음성
직접 사용해 보기
Google Cloud를 처음 사용하는 경우 계정을 만들어 실제 시나리오에서 Text-to-Speech의 성능을 평가합니다. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
무료로 Text-to-Speech 사용해 보기