Visão geral
O Text-to-Speech cria dados de áudio brutos de fala humana natural. Ou seja, ele cria áudio que soa como uma pessoa falando. Quando você envia uma solicitação de síntese para o Text-to-Speech, é necessário especificar uma voz que "fala" as palavras.
Há uma grande variedade de vozes disponíveis para você escolher no Text-to-Speech. As vozes diferem por idioma, gênero e sotaque
(para alguns idiomas). Alguns idiomas têm várias vozes para escolher. Para ver uma lista completa de vozes disponíveis no seu idioma, consulte a página Vozes disponíveis. Você pode instruir o Text-to-Speech a usar uma voz específica dessa lista definindo os campos VoiceSelectionParams quando enviar uma solicitação para a API. Consulte os Guias de início rápido do Text-to-Speech para saber detalhes sobre como enviar uma solicitação synthesize.
Vozes Neural2
A API Text-to-Speech oferece um nível de voz premium chamada Neural2. As vozes Neural2 são baseadas na mesma tecnologia usada para criar uma Voz personalizada. A Neural2 representa a última geração de voz sintética e permite que qualquer pessoa use a tecnologia de voz personalizada sem treinar a própria voz personalizada. Eles estão disponíveis em endpoints globais e de região única.
Exemplo 1. Voz Neural2
Vozes Studio (prévia)
A API Text-to-Speech oferece vozes Studio. Esse tipo de voz foi projetado especificamente para uso em textos longos, como narração e leitura de notícias.
Exemplo 1. A voz de en-US-Studio-O lendo o Great Gatsby.
Vozes padrão
As vozes oferecidas pelo Text-to-Speech diferem na forma como são produzidas: a tecnologia de fala sintética usada para criar o modelo de máquina da voz. Uma tecnologia de fala comum, a conversão paramétrica de texto em voz, normalmente gera dados de áudio pela passagem das saídas por algoritmos de processamento de sinais conhecidos como vocoders. Muitas das vozes padrão disponíveis no Text-to-Speech usam uma variação dessa tecnologia.
Vozes WaveNet
A API Text-to-Speech também oferece um grupo de vozes premium geradas usando um modelo WaveNet, a mesma tecnologia usada para produzir voz para o Google Assistente, a Pesquisa Google e o Google Tradutor. A tecnologia WaveNet fornece mais do que apenas uma série de vozes sintéticas. Ela representa uma nova maneira de criar fala sintética.
O WaveNet gera falas que soam mais naturais do que outros sistemas de conversão de texto em voz. Ele sintetiza a fala com ênfase mais humana e mais inflexão nas sílabas, nos fonemas e nas palavras.
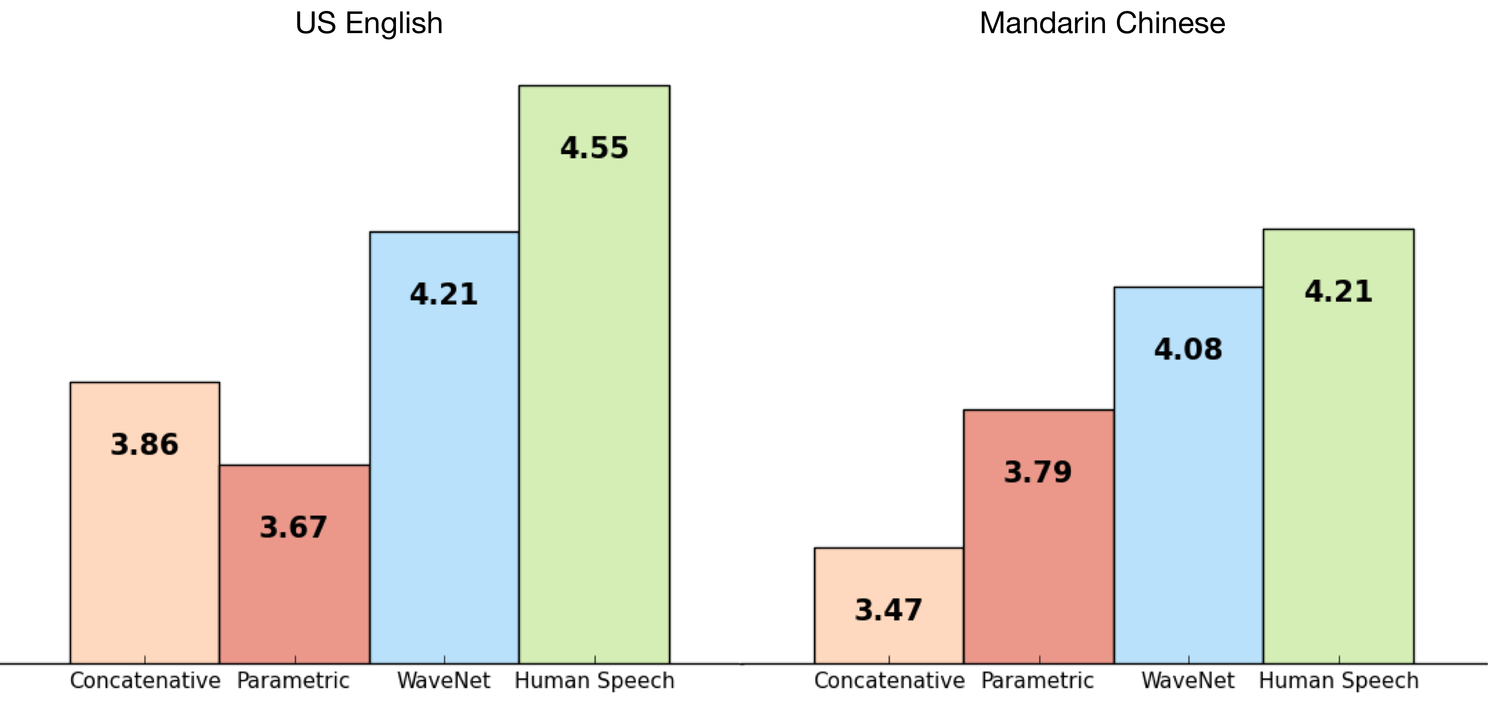 Figura 1. Gráfico que mostra uma comparação do WaveNet com outras vozes sintéticas de fala humana. Os valores do eixo y representam a pontuação média de opinião (MOS, na sigla em inglês) para cada voz.
Os temas de teste classificam cada voz em uma escala de 1 a 5 de acordo com o volume da fala natural. Para mais informações sobre pontuações e MSI da tecnologia WaveNet, consulte a página DeepMind WaveNet (em inglês).
Figura 1. Gráfico que mostra uma comparação do WaveNet com outras vozes sintéticas de fala humana. Os valores do eixo y representam a pontuação média de opinião (MOS, na sigla em inglês) para cada voz.
Os temas de teste classificam cada voz em uma escala de 1 a 5 de acordo com o volume da fala natural. Para mais informações sobre pontuações e MSI da tecnologia WaveNet, consulte a página DeepMind WaveNet (em inglês).
Ao contrário da maioria dos outros sistemas de conversão de texto em voz, um modelo WaveNet cria formas de onda de áudio brutas do zero. O modelo usa uma rede neural que foi treinada com o uso de um grande volume de amostras de fala. Durante o treinamento, a rede extrai a estrutura subjacente da fala, como quais tons se sucedem e a aparência de uma forma de onda de fala realista. Quando recebe uma entrada de texto, o modelo WaveNet treinado pode gerar as formas de onda de fala correspondentes do zero, uma amostra por vez, com até 24.000 amostras por segundo e transições contínuas entre os sons individuais.
Para ouvir a diferença entre um clipe de áudio gerado pelo Wavenet e um clipe gerado por outro processo de conversão de texto em voz, compare os dois clipes de áudio abaixo.
Exemplo 1. Voz de alta qualidade que não é WaveNet
Exemplo 2. Voz do WaveNet
Faça um teste
Se você está começando agora no Google Cloud, crie uma conta para avaliar o desempenho da Text-to-Speech em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
Teste a Text-to-Speech sem custo financeiro