Google Cloud Managed Service for Prometheus 是针对 Prometheus 指标的 Google Cloud 全代管式多云跨项目解决方案。您可以使用 Prometheus 全局监控工作负载并发出提醒,而无需大规模手动管理和操作 Prometheus。
Managed Service for Prometheus 会从 Prometheus 导出器中收集指标,并支持使用 PromQL 全局查询数据,这意味着您可以继续使用任何现有的 Grafana 信息中心、基于 PromQL 的提醒和工作流。它与混合云和多云兼容,可以监控 Kubernetes、虚拟机和 Cloud Run 上的无服务器工作负载,将数据保留 24 个月,并与上游 Prometheus 保持兼容以维持可移植性。您还可以使用 PromQL 在 Cloud Monitoring 中查询超过 6,500 个免费指标(包括免费的 GKE 系统指标),作为 Prometheus 监控的补充。
本文档简要介绍代管式服务,此外还有其他文档介绍如何设置和运行该服务。如需定期接收新功能和版本的最新动态,请提交可选的注册表单。
了解家得宝公司如何使用 Managed Service for Prometheus 在运行 Kubernetes 本地集群的 2,200 家门店中统一可观测性:
系统概览
Google Cloud Managed Service for Prometheus 可让您熟悉 Prometheus,后者由 Cloud Monitoring 的全球多云跨项目基础架构提供支持。
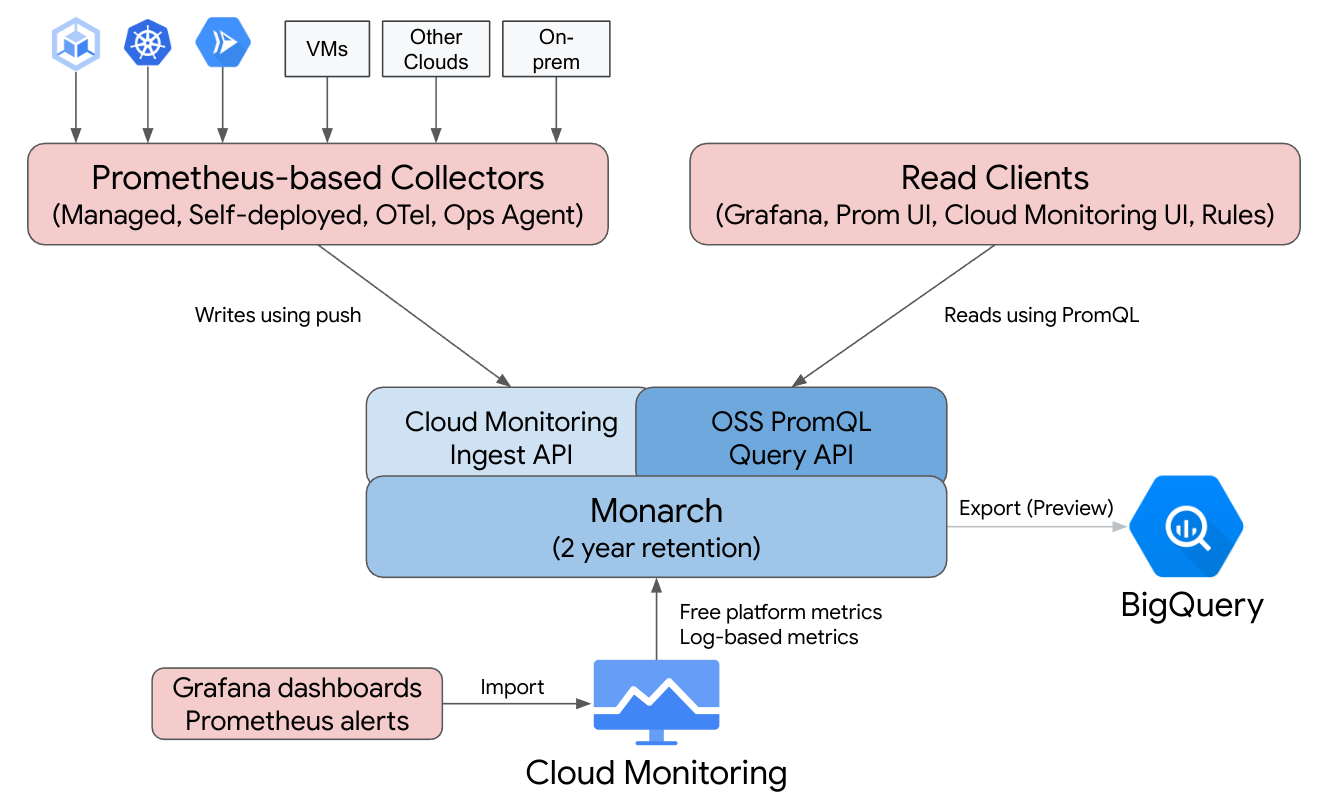
Managed Service for Prometheus 基于 Monarch 构建。Monarch 是可全局扩缩的数据存储区,Google 将其用于自己的监控服务。由于 Managed Service for Prometheus 使用与 Cloud Monitoring 相同的后端和 API,因此 Cloud Monitoring 指标和 Managed Service for Prometheus 注入的指标都可以使用 Cloud Monitoring 中的 PromQL、Grafana 或任何能够读取 Prometheus API 的其他工具进行查询。
在标准 Prometheus 部署中,数据收集、查询评估、规则和提醒评估,以及数据存储都在单个 Prometheus 服务器中处理。Managed Service for Prometheus 将这些功能的责任拆分为多个组件:
- 数据收集由代管式收集器、自行部署的收集器、OpenTelemetry 收集器或 Ops Agent 处理,这些收集器或代理会爬取本地导出器,并将收集到的数据转发到 Monarch。这些收集器可用于 Kubernetes、无服务器和传统虚拟机工作负载,并且可以在任何地方运行,包括其他云和本地部署。
- 查询评估由 Monarch 处理,它会在所有 Google Cloud 区域和多达 1,000 个 Google Cloud 项目中执行查询并联合结果。
- 规则和提醒评估的处理方式如下:编写 Cloud Monitoring 中的 PromQL 提醒,这些提醒完全在云端执行;或者,使用本地运行和本地配置的规则评估器组件,这些组件针对全局 Monarch 数据存储区执行规则和提醒,并将所有触发的提醒转发到 Prometheus AlertManager。
- 数据存储由 Monarch 处理,它会将所有 Prometheus 数据存储 24 个月,不产生额外费用。
Grafana 连接到全局 Monarch 数据存储区,而不是连接到各个 Prometheus 服务器。如果您在所有部署中配置了 Managed Service for Prometheus 收集器,则此单个 Grafana 实例可让您集中查看所有云中的所有指标。
数据收集
您可以通过以下四种模式之一使用 Managed Service for Prometheus:使用代管式数据收集、自部署数据收集、OpenTelemetry 收集器或 Ops Agent。
Managed Service for Prometheus 为 Kubernetes 环境中的代管式数据收集提供 operator。我们建议您使用代管式收集;使用它可使您免于部署、扩缩、分片、配置和维护 Prometheus 服务器。GKE 和非 GKE Kubernetes 环境均支持代管式收集。
借助自部署数据收集,您可以像往常一样管理 Prometheus 安装。它与上游 Prometheus 的唯一区别在于,您运行Managed Service for Prometheus 直接替换二进制文件,而不是上游 Prometheus 二进制文件。
OpenTelemetry 收集器可用于爬取 Prometheus 导出器,并将数据发送到 Managed Service for Prometheus。OpenTelemetry 支持为所有信号使用单代理策略,通过该策略,一个收集器可用于任何环境中的指标(包括 Prometheus 指标)、日志和跟踪记录。
您可以在任何 Compute Engine 实例上配置 Ops Agent,以爬取 Prometheus 指标并将其发送到全局数据存储区。使用代理可以极大地简化虚拟机发现,并且无需在虚拟机环境中安装、部署或配置 Prometheus。
如果您有一项可写入 Prometheus 指标或 OTLP 指标的 Cloud Run 服务,那么您可以使用 Sidecar 和 Managed Service for Prometheus 将指标发送到 Cloud Monitoring。
- 如需从 Cloud Run 收集 Prometheus 指标,请使用 Prometheus Sidecar。
- 如需从 Cloud Run 收集 OTLP 指标,请使用 OpenTelemetry Sidecar。
您可以在本地部署和任何云中运行托管式收集器、自部署收集器和 OpenTelemetry 收集器。在 Google Cloud 外部运行的收集器会将数据发送到 Monarch,以进行长期存储和全局查询。
在选择收集选项时,请考虑以下事项:
代管式收集:
- Google 推荐在所有 Kubernetes 环境中使用的方法。
- 使用 GKE 界面、gcloud CLI、
kubectlCLI 或 Terraform 进行部署。 - Prometheus 的操作(生成抓取配置、扩缩注入、将规则的范围限定到正确的数据等等)完全由 Kubernetes operator 处理。
- 使用轻量级自定义资源 (CR) 配置抓取和规则。
- 适合希望享受自动化程度更高的全代管式体验的用户。
- 通过 prometheus-operator 配置进行直观迁移。
- 支持最新的 Prometheus 使用场景。
- Google Cloud 技术支持提供完整支持。
自部署收集:
- 可以直接替代上游 Prometheus 二进制文件。
- 您可以使用自己偏好的部署机制,例如 prometheus-operator 或手动部署。
- 使用偏好的方法(如注解或 prometheus-operator)配置抓取。
- 扩缩和功能分片是手动完成的。
- 适合快速集成到更复杂的现有设置中。您可以重复使用现有配置,并行运行上游 Prometheus 和 Managed Service for Prometheus。
- 规则和提醒通常在单独的 Prometheus 服务器中运行,可能更适合边缘部署,因为本地规则评估不会产生任何网络流量。
- 可能支持代管式收集尚不支持的长尾用例,例如用于减少基数的局部聚合。
- Google Cloud 技术支持提供有限帮助。
OpenTelemetry 收集器:
- 一个可以从任何环境中收集指标(包括 Prometheus 指标)并将其发送到任何兼容的后端的收集器。 也可用于收集日志和跟踪记录,并将其发送到任何兼容的后端,包括 Cloud Logging 和 Cloud Trace。
- 手动或使用 Terraform 部署在任何计算或 Kubernetes 环境中。可用于从无状态环境(如 Cloud Run)发送指标。
- 爬取使用该收集器的 Prometheus 接收器中类似 Prometheus 的配置进行配置。
- 支持基于推送的指标收集模式。
- 元数据是使用资源检测器处理器从任何云注入的。
- 您可以使用 Cloud Monitoring 提醒政策或独立规则评估器执行规则和提醒。
- 能够为跨信号的工作流和功能(例如范例)提供有力支持。
- Google Cloud 技术支持提供有限帮助。
Ops Agent:
- 收集和发送源自 Compute Engine 环境(包括 Linux 和 Windows 发行版)的 Prometheus 指标数据的最简单方法。
- 使用 gcloud CLI、Compute Engine 界面或 Terraform 部署。
- 爬取在代理的 Prometheus 接收器中使用类似 Prometheus 的配置进行配置,由 OpenTelemetry 提供支持。
- 您可以使用 Cloud Monitoring 或独立规则评估器执行规则和提醒。
- 附带可选的 Logging 代理和进程指标。
- Google Cloud 技术支持提供完整支持。如需开始使用,请参阅代管式收集使用入门、自部署收集使用入门、OpenTelemetry 收集器使用入门或 Ops Agent 使用入门。
如果您在 Google Kubernetes Engine 或 Google Cloud 外部使用代管式服务,则可能需要进行一些其他配置;请参阅在 Google Cloud 外部运行代管式收集、在 Google Cloud 外部运行自部署收集或添加 OpenTelemetry 处理器。
查询评估
Managed Service for Prometheus 支持可调用 Prometheus 查询 API 的任何查询界面,包括 Grafana 和 Cloud Monitoring 界面。从本地 Prometheus 切换到 Managed Service for Prometheus 时,现有 Grafana 信息中心会继续运行;您可以继续使用热门开源代码库和社区论坛中的 PromQL。
您可以使用 PromQL 在 Cloud Monitoring 中查询超过 6,500 个免费指标,甚至无需将数据发送到 Managed Service for Prometheus。您还可以使用 PromQL 查询免费的 Kubernetes 指标、自定义指标和基于日志的指标。
如需了解如何配置 Grafana 以查询 Managed Service for Prometheus 数据,请参阅使用 Grafana 进行查询。
如需了解如何使用 PromQL 查询 Cloud Monitoring 指标,请参阅 Cloud Monitoring 中的 PromQL。
规则和提醒评估
Managed Service for Prometheus 提供完全基于云的提醒流水线和独立的规则评估器,这两者都针对指标范围中可访问的所有 Monarch 数据评估规则。如果针对多项目指标范围评估规则,您就无需将感兴趣的所有数据共同存储在单个 Prometheus 服务器或单个 Google Cloud 项目中,而且还可以在群组或者项目上设置 IAM 权限。
由于所有规则评估选项都接受标准 Prometheus rule_files 格式,因此您可以通过复制粘贴现有规则或复制粘贴常见开源库中的规则,轻松迁移到 Managed Service for Prometheus 代码库。如果使用自部署收集器,您可以继续在收集器中本地评估记录规则。记录和提醒规则的结果存储在 Monarch 中,就像直接收集的指标数据一样。 您还可以将 Prometheus 提醒规则迁移到 Cloud Monitoring 中基于 PromQL 的提醒政策。
如需使用 Cloud Monitoring 进行提醒评估,请参阅 Cloud Monitoring 中的 PromQL 提醒。
如需了解如何使用代管式收集进行规则评估,请参阅代管式规则评估和提醒。
如需了解如何使用自部署收集、OpenTelemetry 收集器和 Ops Agent 进行规则评估,请参阅自部署规则评估和提醒。
如需了解如何使用自部署收集器的记录规则来减少基数,请参阅费用控制和归因。
数据存储
所有 Managed Service for Prometheus 数据都会存储 24 个月,且无额外费用。
Managed Service for Prometheus 支持最短 5 秒的抓取间隔。数据会以完整的粒度保存 1 周,然后降采样为 1 分钟时间点并保存 5 周,然后降采样为 10 分钟时间点并保存剩余的保留期限。
Managed Service for Prometheus 对活跃时序数或时序总数没有限制。
如需了解详情,请参阅 Cloud Monitoring 文档中的配额和限制。
结算和配额
Managed Service for Prometheus 是一款 Google Cloud 产品,具有结算和用量配额。
结算
该服务的结算主要取决于提取到存储空间中的指标样本数量。读取 API 调用还存在名义费用。Managed Service for Prometheus 不收取指标数据的存储或保留费用。
- 如需了解当前价格,请参阅 Google Cloud Managed Service for Prometheus 价格摘要。
- 如需根据预期时序数或预期的每秒样本数估算账单费用,请参阅 Google Cloud 价格计算器中的“Cloud Operations”标签页。
- 如需了解如何降低费用或确定高费用来源,请参阅费用控制和归因。
- 如需了解价格模式,请参阅可控制性和可预测性的价格。
- 如需查看价格示例,请参阅基于注入的样本数量的价格示例。
配额
Managed Service for Prometheus 与 Cloud Monitoring 共享注入和读取配额。默认注入配额为每个项目 500 QPS,一次调用最多可以包含 200 个样本,相当于每秒 10 万个样本。默认读取配额为每个指标范围 100 QPS。
您可以增加这些配额以支持您的指标和查询量。如需了解如何管理配额及申请增加配额,请参阅使用配额。
服务条款与合规性
Managed Service for Prometheus 是 Cloud Monitoring 的一部分,因此继承了 Cloud Monitoring 的某些协议和认证,包括但不限于:
后续步骤
- 代管式收集使用入门。
- 自部署收集使用入门。
- OpenTelemetry 收集器使用入门。
- Ops Agent 使用入门。
- 使用 Cloud Monitoring 中的 PromQL 查询 Prometheus 指标。
- 使用 Grafana 查询 Prometheus 指标。
- 使用 PromQL 查询 Cloud Monitoring 指标。
- 阅读最佳实践和查看架构图。