O Google Cloud Managed Service para Prometheus é a solução totalmente gerenciada, de várias nuvens e entre projetos do Google Cloud para métricas do Prometheus. Ele permite monitorar e receber alertas globalmente sobre as cargas de trabalho usando o Prometheus, sem precisar gerenciar e operar manualmente o Prometheus em grande escala.
O Serviço gerenciado para Prometheus coleta métricas dos exportadores do Prometheus e permite que você consulte os dados globalmente usando o PromQL, o que significa que é possível continuar usando todos os painéis existentes do Grafana, alertas baseados em PromQL e fluxos de trabalho. Ele é compatível com nuvem híbrida e multicloud, pode monitorar o Kubernetes, VMs e cargas de trabalho sem servidor no Cloud Run, retém os dados por 24 meses e mantém a portabilidade ao se manter compatível com o Prometheus upstream. Também é possível complementar o monitoramento do Prometheus consultando mais de 6.500 métricas gratuitas no Cloud Monitoring, incluindo métricas gratuitas do sistema do GKE, usando PromQL.
Neste documento, apresentamos uma visão geral do serviço gerenciado. Outros documentos descrevem como configurar e executar o serviço. Para receber atualizações regulares sobre novos recursos e versões, envie o formulário de inscrição opcional.
Saiba como a The Home Depot usa o serviço gerenciado do Prometheus para garantir a observabilidade unificada em 2.200 lojas que executam clusters locais do Kubernetes:
Visão geral do sistema
O Google Cloud Managed Service para Prometheus oferece a familiaridade do Prometheus com suporte da infraestrutura global, de várias nuvens e entre projetos do Cloud Monitoring.
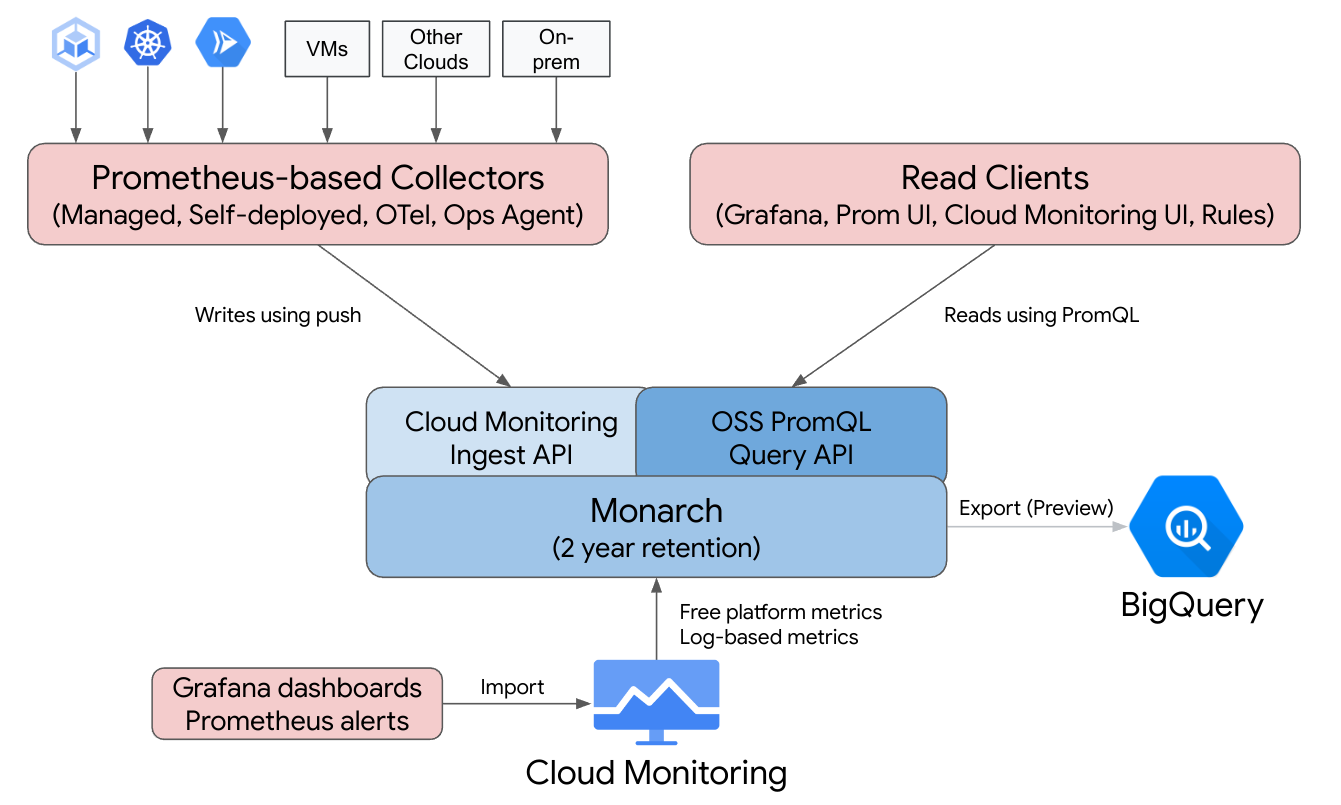
O Managed Service para Prometheus é criado com base no Monarch, o mesmo repositório de dados globalmente escalonável usado para monitoramento pelo Google. Como o Managed Service para Prometheus usa o mesmo back-end e APIs que o Cloud Monitoring, as métricas e métricas do Cloud Monitoring ingeridas pelo Managed Service para Prometheus podem ser consultadas usando PromQL no Cloud Monitoring, Grafana ou qualquer outra ferramenta que possa ler a API Prometheus.
Em uma implantação padrão do Prometheus, a coleta de dados, a avaliação de consultas, a avaliação de regras e alertas e o repositório de dados são processados em um único servidor do Prometheus. O Managed Service para Prometheus divide as responsabilidades dessas funções em vários componentes:
- A coleta de dados é processada por coletores gerenciados, coletores autoimplantados, o OpenTelemetry Collector ou o agente de operações, que copiam os exportadores locais e encaminham os dados coletados para o Monarch. Esses coletores podem ser usados para cargas de trabalho de VMs tradicionais, sem servidor e do Kubernetes. Eles podem ser executados em qualquer lugar, incluindo outras nuvens e implantações no local.
- A avaliação de consultas é processada pelo Monarch, que executa resultados de consultas e uniões em todas as regiões do Google Cloud e em até 1.000 projetos do Google Cloud.
- A avaliação de regras e alertas é processada com a gravação de alertas PromQL no Cloud Monitoring, que são totalmente executados na nuvem, ou com o uso de Componentes de avaliação de regras executados e configurados localmente que executam regras e alertas em relação ao armazenamento de dados global do Monarch e encaminham os alertas disparados para o Prometheus AlertManager.
- O repositório de dados é processado pelo Monarch, que armazena todos os dados do Prometheus por 24 meses sem custos extras.
O Grafana se conecta ao armazenamento de dados global do Monarch, em vez de se conectar a servidores individuais do Prometheus. Se você tiver configurado os coletores do Managed Service para Prometheus em todas as implantações, essa única instância do Grafana terá uma visualização unificada de todas as métricas em todas as nuvens.
Coleta de dados
É possível usar o Managed Service para Prometheus em um dos quatro modos: com a coleta de dados gerenciada, com a coleta de dados autoimplantada, com o OpenTelemetry Collector ou com o agente de operações.
O Managed Service para Prometheus oferece um operador para coleta de dados gerenciada em ambientes do Kubernetes. Recomendamos que você use a coleta gerenciada. O uso dela elimina a complexidade de implantar, escalonar, fragmentar, configurar e manter servidores do Prometheus. A coleta gerenciada é compatível com ambientes do GKE e ambientes do Kubernetes que não são do GKE.
Com a coleta de dados autoimplantada, você gerencia a instalação do Prometheus como sempre fez. A única diferença do Prometheus upstream é que você executa o binário substituto do Managed Service para Prometheus em vez do binário upstream do Prometheus.
O coletor do OpenTelemetry pode ser usado para copiar os exportadores do Prometheus e enviar dados para o Managed Service para Prometheus. O OpenTelemetry é compatível com uma estratégia de agente único para todos os sinais, em que um coletor pode ser usado para métricas (incluindo métricas do Prometheus), registros e traces em qualquer ambiente.
É possível configurar o Agente de operações em qualquer instância do Compute Engine para coletar e enviar métricas do Prometheus para o armazenamento de dados global. O uso de um agente simplifica muito a descoberta de VMs e elimina a necessidade de instalar, implantar ou configurar o Prometheus em ambientes de VM.
Se você tiver um serviço do Cloud Run que grava métricas do Prometheus ou do OTLP, use um arquivo secundário e o Managed Service para Prometheus para enviar as métricas para o Cloud Monitoring.
- Para coletar métricas do Prometheus no Cloud Run, use o arquivo secundário do Prometheus.
- Para coletar métricas OTLP do Cloud Run, use o arquivo secundário do OpenTelemetry.
É possível executar coletores gerenciados, autoimplantados e do OpenTelemetry em implantações no local e em qualquer nuvem. Os coletores executados fora do Google Cloud enviam dados ao Monarch para armazenamento de longo prazo e consulta global.
Ao escolher uma das opções de coleta, considere o seguinte:
Coleta gerenciada:
- A abordagem recomendada pelo Google para todos os ambientes do Kubernetes.
- Implantado usando a IU do GKE, a CLI gcloud,
a CLI
kubectlou o Terraform. - A operação do Prometheus, como geração de configurações de raspagem de dados, escalonamento de ingestão, regras de escopo para os dados certos e assim por diante, é totalmente processada pelo operador do Kubernetes.
- A coleta e as regras são configuradas usando recursos personalizados leves (CRs, na sigla em inglês).
- Bom para quem quer uma experiência mais prática e totalmente gerenciada.
- Migração intuitiva de configs prometheus-operator.
- É compatível com a maioria dos casos de uso atuais do Prometheus.
- Assistência total com o suporte técnico do Google Cloud.
Coleção autoimplantada:
- Uma substituição simples para o binário upstream do Prometheus.
- É possível usar seu mecanismo de implantação preferido, como o prometheus-operator ou o implantação manual.
- A raspagem de dados é configurada usando seus métodos preferidos, como anotações ou prometheus-operator.
- O escalonamento e a fragmentação funcional são feitos manualmente.
- Ideal para uma integração rápida com configurações existentes mais complexas. É possível reutilizar os configs atuais e executar o Prometheus e o Managed Service para Prometheus para upstream lado a lado.
- Regras e alertas normalmente são executados em servidores individuais do Prometheus, o que pode ser melhor para implantações na borda, já que a avaliação de regras locais não gera tráfego de rede.
- Pode ser compatível com casos de uso de cauda longa que ainda não são compatíveis com a coleta gerenciada, como agregações locais, para reduzir a cardinalidade.
- Assistência limitada com o suporte técnico do Google Cloud.
O coletor da OpenTelemetry:
- Um único coletor que pode coletar métricas (incluindo métricas do Prometheus) de qualquer ambiente e enviá-las para qualquer back-end compatível. Também pode ser usado para coletar registros e traces e enviá-los para qualquer back-end compatível, incluindo o Cloud Logging e o Cloud Trace.
- Implantado em qualquer ambiente de computação ou do Kubernetes manualmente ou usando o Terraform. Pode ser usado para enviar métricas de ambientes sem estado, como o Cloud Run.
- A coleta é feita usando configurações semelhantes ao Prometheus no receptor do Prometheus do coletor.
- Compatível com padrões de coleta de métricas baseadas em push.
- Os metadados são injetados de qualquer nuvem usando processadores de detectores de recursos.
- As regras e alertas podem ser executados usando uma política de alertas do Cloud Monitoring ou o avaliador de regras autônomo.
- Compatível com fluxos de trabalho de vários sinais e recursos como exemplos.
- Assistência limitada com o suporte técnico do Google Cloud.
O agente de operações:
- A maneira mais fácil de coletar e enviar dados de métricas do Prometheus provenientes de ambientes do Compute Engine, incluindo distribuições do Linux e Windows.
- Implantado usando a CLI gcloud, a IU do Compute Engine ou o Terraform.
- A cópia é configurada usando configurações semelhantes ao Prometheus no receptor Prometheus do Agente, com tecnologia do OpenTelemetry.
- As regras e alertas podem ser executados usando o Cloud Monitoring ou o avaliador de regras autônomo.
- Vem com agentes e métricas de processo opcionais do Logging.
- Assistência total com o suporte técnico do Google Cloud. Para começar, consulte Primeiros passos da coleção gerenciada, Primeiros passos com a coleção autoimplantada, Primeiros passos com o coletor do OpenTelemetry ou Primeiros passos com o agente de operações.
Se você usa o serviço gerenciado fora do Google Kubernetes Engine ou do Google Cloud, algumas configurações extras podem ser necessárias. verExecutar a coleção gerenciada fora do Google Cloud ,Execute a coleção autoimplantada fora do Google Cloud ouAdicionar processadores OpenTelemetry do Google Analytics.
Avaliação da consulta
O Managed Service para Prometheus é compatível com qualquer IU de consulta que possa chamar a API de consulta do Prometheus, incluindo o Grafana e a IU do Cloud Monitoring. Os painéis atuais do Grafana continuam funcionando ao mudar do Prometheus local para o Managed Service para Prometheus, e é possível continuar usando o PromQL encontrado em repositórios de código aberto e fóruns de comunidades.
É possível usar o PromQL para consultar mais de 6.500 métricas gratuitas no Cloud Monitoring, mesmo sem enviar dados ao Managed Service para Prometheus. Também é possível usar o PromQL para consultar métricas sem custos do Kubernetes, métricas personalizadas e métricas com base em registros.
Para informações sobre como configurar o Grafana para consultar dados do Managed Service para Prometheus, consulte Consultar usando o Grafana.
Para informações sobre como consultar métricas do Cloud Monitoring usando PromQL, consulte PromQL no Cloud Monitoring.
Avaliação de regras e alertas
O Managed Service para Prometheus fornece um pipeline de alertas totalmente baseado em nuvem e um avaliador de regras autônomo, que avaliam regras em relação a todos os dados acessíveis do Monarch em um escopo de métricas. A avaliação de regras em relação a um escopo de métricas de vários projetos elimina a necessidade de colocalizar todos os dados de interesse em um único servidor do Prometheus ou em um único projeto do Google Cloud e permite definir permissões do IAM em grupos de projetos.
Como todas as opções de avaliação de regras aceitam o formato rule_files
padrão do Prometheus, é possível migrar facilmente para o Managed Service para Prometheus copiando e colando
as regras atuais ou colando as regras coladas encontradas em repositórios
de código aberto conhecidos. No caso em que coletores autoimplantados são usados, é possível continuar
avaliando as regras de gravação localmente nos coletores. Os resultados das regras de gravação
e de alerta são armazenados no Monarch, assim como os
dados de métricas coletados diretamente. Também é possível migrar as regras de alertas do Prometheus para
políticas de alertas baseadas em PromQL no Cloud Monitoring.
Para avaliação de alertas com o Cloud Monitoring, consulte Alertas do PromQL no Cloud Monitoring.
Para avaliação de regras com coleta gerenciada, consulte Avaliação e alertas de regras gerenciadas.
Para avaliação de regras com coleta autoimplantada, o coletor do OpenTelemetry e o agente de operações, consulte Avaliação e alertas de regras autoimplantadas.
Para informações sobre como reduzir a cardinalidade usando regras de registro em coletores autoimplantados, consulte Controles de custo e atribuição.
Armazenamento de dados
Todos os dados do Managed Service para Prometheus são armazenados por 24 meses sem custo adicional.
O Managed Service para Prometheus é compatível com um intervalo mínimo de raspagem de dados de 5 segundos. Os dados são armazenados com granularidade total por uma semana, depois são reduzidos para 1 minuto nas próximas cinco semanas e, em seguida, diminuídos para 10 minutos e armazenados pelo restante do período de armazenamento.
O Managed Service para Prometheus não tem limite para o número de séries temporais ativas ou totais.
Para mais informações, consulte Cotas e limites na documentação do Cloud Monitoring.
Faturamento e cotas
O Managed Service para Prometheus é um produto do Google Cloud, e as cotas de faturamento e uso se aplicam.
Faturamento
O faturamento do serviço se baseia principalmente no número de amostras de métricas ingeridas no armazenamento. Também há uma cobrança nominal para chamadas de API de leitura. O Managed Service para Prometheus não cobra pelo armazenamento nem pela retenção de dados de métricas.
- Para preços atuais, consulte Resumo de preços do Google Cloud Managed Service para Prometheus.
- Para estimar sua fatura com base no número esperado de séries temporais ou nas amostras esperadas por segundo, consulte a guia "Operações do Cloud" na calculadora de preços do Google Cloud.
- Para dicas sobre como reduzir a fatura ou determinar as fontes de custos altos, consulte Controles de custo e atribuição.
- Para informações sobre a lógica do modelo de preços, consulte Preços para controle e previsibilidade.
- Para exemplos de preços, consulte Exemplo de preços com base em amostras de ingestão.
Cotas
O Managed Service para Prometheus compartilha cotas de ingestão e leitura com o Cloud Monitoring. A cota de ingestão padrão é de 500 QPS por projeto, com até 200 amostras em uma única chamada, o que equivale a 100.000 amostras por segundo. A cota de leitura padrão é de 100 QPS por escopo de métricas.
É possível aumentar essas cotas para oferecer suporte aos volumes de métrica e consulta. Para informações sobre como gerenciar cotas e solicitar aumentos de cotas, consulte Como trabalhar com cotas.
Termos de Serviço e conformidade
O Managed Service para Prometheus faz parte do Cloud Monitoring e, portanto, herda determinados contratos e certificações do Cloud Monitoring, incluindo, entre outros:
- Termos de Serviço do Google Cloud
- Contrato de nível de serviço (SLA) de operações
- Níveis de conformidade USA DISA e FedRAMP
- Suporte para VPC-SC (VPC Service Controls)
A seguir
- Comece a usar a coleção gerenciada.
- Primeiros passos com a coleção autoimplantada (em inglês).
- Primeiros passos com o OpenTelemetry Collector
- Começar a usar o Agente de operações.
- Use o PromQL no Cloud Monitoring para consultar as métricas do Prometheus.
- Use o Grafana para consultar as métricas do Prometheus.
- Métricas de consulta do Cloud Monitoring usando o PromQL.
- Leia as práticas recomendadas e diagramas de arquitetura de visualização.