Google Cloud Managed Service para Prometheus es la solución de múltiples nubes entre proyectos y completamente administrada de Google Cloud para las métricas de Prometheus. Te permite supervisar y generar alertas sobre tus cargas de trabajo de forma global mediante Prometheus, sin tener que administrar ni operar Prometheus de forma manual a gran escala.
El servicio administrado para Prometheus recopila métricas de los exportadores de Prometheus y te permite consultar los datos de forma global mediante PromQL, lo que significa que puedes seguir usando los paneles de Grafana existentes, las alertas basadas en PromQL y los flujos de trabajo. Es compatible con nubes híbridas y múltiples, puede supervisar cargas de trabajo de Kubernetes, de VMs y sin servidores en Cloud Run, conserva los datos durante 24 meses y mantiene la portabilidad, gracias a la compatibilidad con Prometheus ascendente. También puedes complementar la supervisión de Prometheus si consultas más de 6,500 métricas gratuitas en Cloud Monitoring, incluidas las métricas del sistema de GKE gratuitas, mediante PromQL.
En este documento, se ofrece una descripción general del servicio administrado y, en otros documentos, se describe cómo configurar y ejecutar el servicio. Para recibir actualizaciones periódicas sobre características y versiones nuevas, envía el formulario de registro opcional.
Descubre cómo The Home Depot usa el servicio administrado para Prometheus a fin de obtener una observabilidad unificada en 2,200 tiendas que ejecutan clústeres de Kubernetes locales:
Descripción general del sistema
Google Cloud Managed Service para Prometheus te familiariza con Prometheus respaldado por la infraestructura global de múltiples nubes y entre proyectos de Cloud Monitoring.
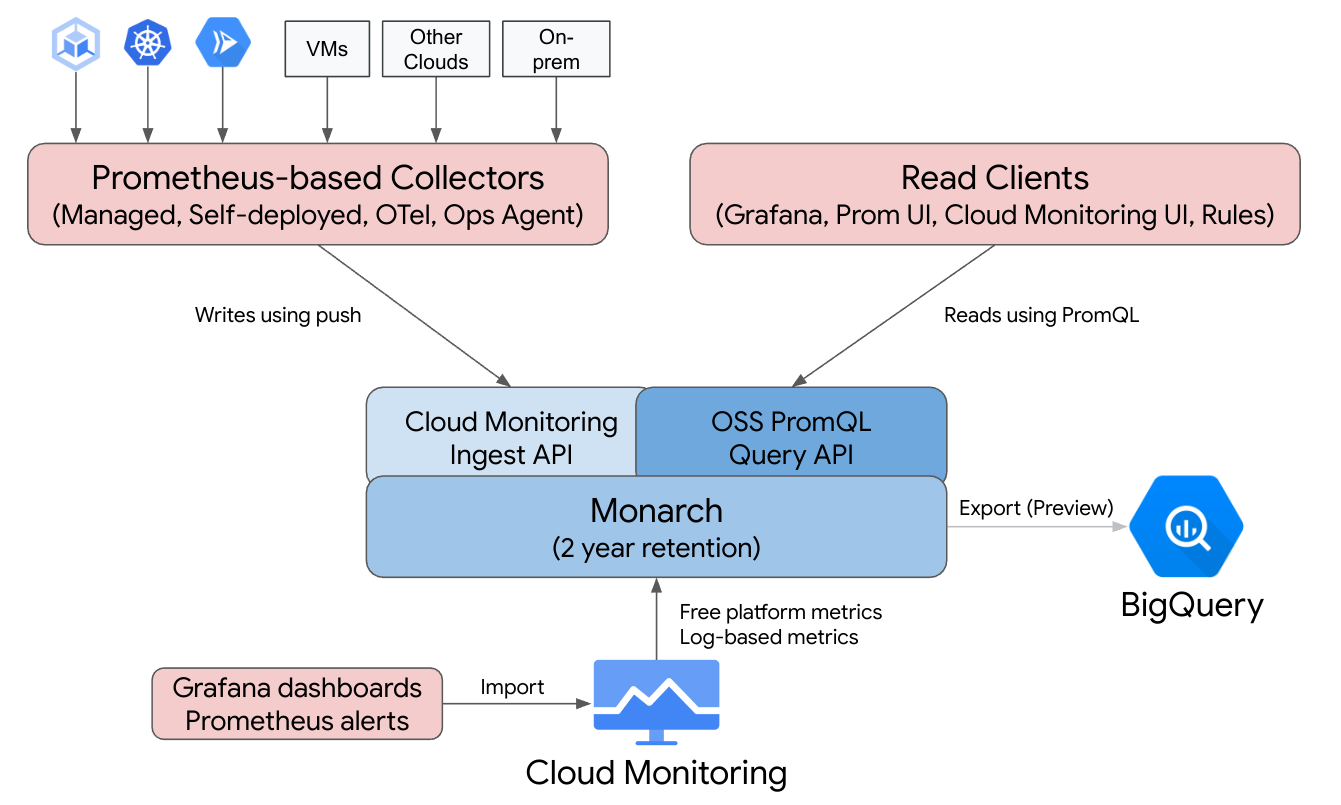
Managed Service para Prometheus se basa en Monarch, el mismo almacén de datos escalable de forma global que se usa para la supervisión de Google. Debido a que el servicio administrado para Prometheus usa el mismo backend y las mismas API que Cloud Monitoring, tanto las métricas de Cloud Monitoring como las que transfiere el servicio administrado para Prometheus se pueden consultar mediante PromQL en Cloud Monitoring, Grafana o cualquier otra herramienta que pueda leer la API de Prometheus.
En una implementación estándar de Prometheus, la recopilación de datos, la evaluación de consultas, la evaluación de reglas y alertas, y el almacenamiento de datos se manejan dentro de un único servidor de Prometheus. El servicio administrado para Prometheus divide las responsabilidades de estas funciones en varios componentes:
- La recopilación de datos se controla mediante recopiladores administrados, recopiladores autoimplementados, el recopilador de OpenTelemetry o el agente de operaciones, que realizan scraping de exportadores locales y reenvía los datos recopilados a Monarch. Estos recopiladores se pueden usar para cargas de trabajo de VM tradicionales, sin servidores y de Kubernetes y se pueden ejecutar en todas partes, incluidas implementaciones locales y otras nubes.
- Monarch realiza la evaluación de consultas, que ejecuta resultados de consultas y uniones en todas las regiones de Google Cloud y en hasta 1,000 proyectos de Google Cloud.
- La evaluación de reglas y alertas se controla mediante la escritura de alertas de PromQL en Cloud Monitoring que se ejecutan por completo en la nube, o mediante componentes del evaluador de reglas configurados y ejecutados de forma local que ejecutan reglas y alertas en el almacén de datos global de Monarch y reenvían las alertas activadas a Prometheus AlertManager.
- Monarc controla el almacenamiento de datos, que almacena todos los datos de Prometheus por 24 meses sin costo adicional.
Grafana se conecta al almacén de datos global de Monarch en lugar de conectarse a servidores de Prometheus individuales. Si tienes un servicio administrado para recopiladores de Prometheus configurado en todas las implementaciones, esta única instancia de Grafana te brinda una vista unificada de todas las métricas en todas las nubes.
Recopilación de datos
Puedes usar Managed Service para Prometheus de cuatro modos: con recopilación de datos administrados, con implementación de datos autoimplementada, con el recopilador de OpenTelemetry o con el agente de operaciones.
Managed Service para Prometheus ofrece un operador de recopilación de datos administrados en entornos de Kubernetes. Te recomendamos que uses la colección administrada; su uso elimina la complejidad de implementar, escalar, fragmentar, configurar y mantener servidores de Prometheus. La recopilación administrada es compatible con entornos de Kubernetes que no son de GKE o de GKE.
Con la recopilación de datos implementada de forma automática, administras tu instalación de Prometheus como siempre. La única diferencia con Prometheus es que ejecutas el servicio administrado para el objeto binario de reemplazo directo de Managed Service para Prometheus en lugar del objeto binario ascendente de Prometheus.
El recopilador de OpenTelemetry se puede usar para recopilar exportadores de Prometheus y enviar datos al servicio administrado para Prometheus. OpenTelemetry admite una estrategia de agente único para todas las señales, en la que se puede usar un colector para las métricas (incluidas las métricas de Prometheus), los registros y los seguimientos en cualquier entorno.
Puedes configurar el agente de operaciones en cualquier instancia de Compute Engine para recopilar y enviar métricas de Prometheus al almacén de datos global. Usar un agente simplifica mucho el descubrimiento de VMs y elimina la necesidad de instalar, implementar o configurar Prometheus en entornos de VM.
Si tienes un servicio de Cloud Run que escribe Métricas de Prometheus o Métricas de OTLP, puedes usar un archivo adicional y un servicio administrado para Prometheus a fin de enviar las métricas a Cloud Monitoring.
- Para recopilar las métricas de Prometheus de Cloud Run, usa el sidecar de Prometheus.
- Para recopilar métricas de OTLP de Cloud Run, usa el sidecar de OpenTelemetry.
Puedes ejecutar recopiladores administrados, autoimplementados y de OpenTelemetry en implementaciones locales y en cualquier nube. Los recopiladores que se ejecutan fuera de Google Cloud envían datos a Monarch para el almacenamiento a largo plazo y las consultas globales.
Cuando elijas entre las opciones de recopilación, ten en cuenta lo siguiente:
Recopilación administrada:
- El enfoque que Google recomienda para todos los entornos de Kubernetes.
- Se implementa con la IU de GKE, la CLI de gcloud, la CLI de
kubectlo Terraform. - El operador de Kubernetes se encarga por completo de la operación de Prometheus (generar opciones de configuración de recopilación, escalamiento de transferencia, reglas de permisos para los datos correctos), etcétera.
- La recopilación y las reglas se configuran mediante recursos personalizados ligeros (CR).
- Ideal para quienes desean tener una experiencia práctica completamente administrada.
- Migración intuitiva de las opciones de configuración prometheus-operator.
- Es compatible con la mayoría de los casos de uso actuales de Prometheus.
- Asistencia completa por parte de la asistencia técnica de Google Cloud.
Recopilación de implementación automática:
- Un reemplazo directo para el objeto binario de Prometheus ascendente.
- Puedes usar tu mecanismo de implementación preferido, como el operador Prometheus o la implementación manual.
- El scraping se configura mediante tus métodos preferidos, como las anotaciones o el operador de Prometheus.
- El escalamiento y la fragmentación funcional se realizan de forma manual.
- Ideal para una integración rápida en opciones de configuración más complejas. Puedes reutilizar tu configuración existentes y ejecutar Prometheus y Managed Service for Prometheus lado a lado.
- Por lo general, las reglas y las alertas se ejecutan dentro de servidores individuales de Prometheus, lo que puede ser preferible para las implementaciones perimetrales, ya que la evaluación de reglas locales no genera tráfico de red.
- Es posible que admita casos de uso de cola larga que aún no son compatibles con la recopilación administrada, como las agregaciones locales para reducir la cardinalidad.
- Asistencia limitada por parte de la asistencia técnica de Google Cloud.
El recopilador de OpenTelemetry:
- Un solo colector que puede recopilar métricas (incluidas las métricas de Prometheus) de cualquier entorno y enviarlas a cualquier backend compatible. También se puede usar para recopilar registros y seguimientos, y enviarlos a cualquier backend compatible, incluidos Cloud Logging y Cloud Trace.
- Se implementa en cualquier entorno de procesamiento o de Kubernetes de forma manual o mediante Terraform. Se puede usar para enviar métricas desde entornos sin estado, como Cloud Run.
- El scraping se configura con archivos de configuración similares a Prometheus en el receptor de Prometheus del colector.
- Admite patrones de recopilación de métricas basadas en envíos.
- Los metadatos se insertan desde cualquier nube mediante procesadores de detectores de recursos.
- Las reglas y las alertas se pueden ejecutar con una política de alertas de Cloud Monitoring o el evaluador de reglas independiente.
- Es compatible con flujos de trabajo de indicadores múltiples y funciones como ejemplos.
- Asistencia limitada por parte de la asistencia técnica de Google Cloud.
El Agente de operaciones:
- La forma más fácil de recopilar y enviar datos de métricas de Prometheus que se originan en los entornos de Compute Engine, incluidos los distribuciones de Linux y Windows.
- Se implementa con la CLI de gcloud, la IU de Compute Engine o Terraform.
- El scraping se configura mediante archivos de configuración similares a Prometheus en el receptor de Prometheus del Agente, con la tecnología de OpenTelemetry.
- Las reglas y alertas se pueden ejecutar con Cloud Monitoring o el evaluador de reglas independientes.
- Viene con agentes de Logging opcionales y métricas de proceso.
- Asistencia completa por parte de la asistencia técnica de Google Cloud. Para comenzar, consulta Comienza a usar la recopilación administrada, Comienza con la recopilación autoimplementada, Comienza a usar el recopilador de OpenTelemetry o Comienza a usar el agente de operaciones.
Si usas el servicio administrado fuera de Google Kubernetes Engine o Google Cloud, es posible que se necesite alguna configuración adicional. Consulta Ejecuta una colección administrada fuera de Google Cloud, Ejecuta la colección con implementación automática fuera de Google Cloud o Agrega procesadores de OpenTelemetry.
Evaluación de consultas
Managed Service para Prometheus admite cualquier IU de consulta que pueda llamar a la API de consulta de Prometheus, incluidos Grafana y la IU de Cloud Monitoring. Los paneles de Grafana existentes continúan funcionando cuando se cambia de Prometheus local a Managed Service para Prometheus, y puedes continuar usando PromQL que se encuentra en repositorios populares de código abierto y en foros de la comunidad.
Puedes usar PromQL para consultar más de 6,500 métricas gratuitas en Cloud Monitoring, incluso sin enviar datos al servicio administrado para Prometheus. También puedes usar PromQL para consultar métricas gratuitas de Kubernetes, métricas personalizadas y métricas basadas en registros.
Si deseas obtener información sobre cómo configurar Grafana para consultar datos del Servicio administrado para Prometheus, revisa Consulta con Grafana.
Para obtener información sobre cómo consultar las métricas de Cloud Monitoring con PromQL, consulta PromQL en Cloud Monitoring.
Evaluación de reglas y alertas
El servicio administrado para Prometheus proporciona una canalización de alertas completamente basada en la nube y un evaluador de reglas independiente, que evalúan las reglas con todos los datos de Monarch a los que se puede acceder en un permiso de métricas. La evaluación de las reglas en un alcance de métricas de varios proyectos elimina la necesidad de ubicar todos los datos de interés en un solo servidor de Prometheus o en un solo proyecto de Google Cloud, y te permite configurar permisos de IAM en grupos de proyectos.
Debido a que todas las opciones de evaluación de reglas aceptan el formato estándar de Prometheus rule_files, puedes migrar con facilidad al servicio administrado para Prometheus si copias y pegas reglas existentes o reglas que se encuentran en el código abierto popular. repositorios. Para los que usan recopiladores autoimplementados, puedes continuar con la evaluación de las reglas de grabación de manera local en tus recopiladores. Los resultados de las reglas de grabación y alertas se almacenan en Monarch, al igual que los datos de métricas recopilados directamente. También puedes migrar tus reglas de alertas de Prometheus a las políticas de alertas basadas en PromQL en Cloud Monitoring.
Para la evaluación de alertas con Cloud Monitoring, consulta Alertas de PromQL en Cloud Monitoring.
Para la evaluación de reglas con recopilación administrada, consulta Evaluación y alertas de reglas administradas.
Para la evaluación de reglas con recopilación autoimplementada, el colector de OpenTelemetry y el agente de operaciones, consulta Evaluación y alertas de reglas autoimplementadas.
Para obtener información sobre la reducción de la cardinalidad mediante reglas de grabación en recopiladores autoimplementados, consulta Control de costos y atribución.
Almacenamiento de datos
Todos los datos de Managed Service para Prometheus se almacenan durante 24 meses sin costo adicional.
Managed Service para Prometheus admite un intervalo de recopilación mínimo de 5 segundos. Los datos se almacenan con un nivel de detalle completo durante 1 semana, luego se reduce el muestreo a puntos de 1 minuto para las siguientes 5 semanas, luego se reduce el muestreo a puntos de 10 minutos y se almacenan por el resto del período de retención. .
Managed Service para Prometheus no tiene un límite en la cantidad de series temporales activas o totales.
Para obtener más información, consulta Cuotas y límites en la documentación de Cloud Monitoring.
Facturación y cuotas
Managed Service para Prometheus es un producto de Google Cloud, y se aplican cuotas de facturación y de uso.
Facturación
La facturación del servicio se basa principalmente en la cantidad de muestras de métricas transferidas al almacenamiento. También hay un cargo nominal para las llamadas a la API de lectura. Managed Service para Prometheus no cobra por el almacenamiento ni la retención de los datos de métricas.
- Para conocer los precios actuales, consulta Resumen de precios de Google Cloud Managed Service para Prometheus.
- Para estimar tu factura en función de la cantidad de series temporales esperadas o las muestras esperadas por segundo, consulta la pestaña Cloud Operations dentro de la Calculadora de precios de Google Cloud Marketing Platform.
- Para obtener sugerencias sobre cómo reducir tu factura o determinar los orígenes de los costos elevados, consulta Control de costos y atribución.
- Para obtener más información sobre la lógica del modelo de precios, consulta Precios de la capacidad de control y la previsibilidad.
- Para ver ejemplos de precios, consulta Ejemplo de precios basado en muestras transferidas.
Cuotas
Managed Service para Prometheus comparte las cuotas de transferencia y lectura con Cloud Monitoring. La cuota de transferencia predeterminada es de 500 QPS por proyecto con hasta 200 muestras en una sola llamada, lo que equivale a 100,000 muestras por segundo. La cuota de lectura predeterminada es de 100 QPS por permiso de métricas.
Puedes aumentar estas cuotas para admitir tus volúmenes de métricas y consultas. Si quieres obtener más información para administrar cuotas y solicitar aumentos de cuota, consulta Trabaja con cuotas.
Condiciones del Servicio y cumplimiento
El servicio administrado para Prometheus es parte de Cloud Monitoring y, por lo tanto, hereda ciertos acuerdos y certificaciones de Cloud Monitoring, incluidos (sin limitaciones):
- Las Condiciones del Servicio de Google Cloud
- El Acuerdo de Nivel de Servicio (ANS) de operaciones
- Niveles de cumplimiento de US DISA y FedRAMP
- Compatibilidad con VPC-SC (Controles del servicio de VPC)
¿Qué sigue?
- Comienza a usar la colección administrada.
- Comienza con la colección de implementación automática.
- Comienza a usar el recopilador de OpenTelemetry
- Comienza a usar el Agente de operaciones.
- Usa PromQL en Cloud Monitoring para consultar las métricas de Prometheus.
- Usa Grafana para consultar métricas de Prometheus.
- Consulta las métricas de Cloud Monitoring mediante PromQL.
- Lee las prácticas recomendadas y visualiza los diagramas de arquitectura.