La réplication est la possibilité de créer des copies d'une instance Cloud SQL ou d'une base de données sur site, et de décharger les tâches vers les copies.
Introduction
La principale raison de l'utilisation de la réplication est de procéder au scaling de l'utilisation des données dans une base de données sans dégrader les performances.
Autres raisons possibles :
- Migrer des données entre régions
- Migrer des données entre différentes plates-formes
- Migrer des données depuis une base de données sur site vers Cloud SQL
En outre, une instance dupliquée peut être promue si l'instance d'origine est corrompue.
Lorsque vous faites référence à une instance Cloud SQL, l'instance répliquée est appelée instance principale et les copies sont appelées instances dupliquées avec accès en lecture. L'instance principale et les instances dupliquées avec accès en lecture résident dans Cloud SQL.
Lorsque vous faites référence à une base de données sur site, le scénario de réplication est appelé réplication depuis un serveur externe. Dans ce scénario, la base de données répliquée est le serveur de base de données source. Les copies qui résident dans Cloud SQL sont appelées instances dupliquées Cloud SQL. Il existe également une instance qui représente le serveur de base de données source dans Cloud SQL appelé instance de représentation source.
Dans un scénario de reprise après sinistre, vous pouvez promouvoir une instance répliquée afin de la convertir en instance principale. Vous pouvez ainsi l'utiliser à la place d'une instance située dans une région subissant une interruption de service. Vous pouvez également promouvoir une instance répliquée en vue de remplacer une instance corrompue.
Cloud SQL est compatible avec les types d'instances dupliquées suivants :
- Instances dupliquées avec accès en lecture
- Instances dupliquées interrégionales avec accès en lecture
- Instances répliquées en cascade avec accès en lecture
- Instances dupliquées externes avec accès en lecture
- Instances répliquées Cloud SQL, lors d'une réplication à partir d'un serveur externe
Cloud SQL n'est pas compatible avec la réplication entre deux serveurs externes. Cependant, Cloud SQL est compatible avec la réplication basée sur l'identifiant de transaction global (GTID). Les GTID identifient de manière unique chaque transaction sur le serveur et dans une configuration de réplication. Étant donné que chaque transaction possède un identifiant unique, le serveur MySQL peut effectuer le suivi des transactions qu'il a exécutées. Un GTID utilise des coordonnées absolues pour que l'instance répliquée d'une instance Cloud SQL puisse pointer vers son instance principale. Vous n'avez pas besoin de spécifier un nom de fichier pour le journal binaire ou une position dans l'instruction CHANGE MASTER. Il y a moins d'erreurs avec les instances répliquées et la récupération à un moment précis. Compte tenu de ces avantages, vous ne pouvez pas désactiver la réplication basée sur GTID dans Cloud SQL.
Instances dupliquées avec accès en lecture
Vous utilisez une instance dupliquée avec accès en lecture pour décharger les tâches d'une instance Cloud SQL. L'instance dupliquée avec accès en lecture est une copie exacte de l'instance principale. Les données et autres modifications de l'instance principale sont mises à jour quasiment en temps réel sur l'instance dupliquée avec accès en lecture.
Les instances dupliquées avec accès en lecture sont accessibles en lecture seule et il est impossible d'y effectuer des opérations d'écriture. L'instance dupliquée avec accès en lecture traite les requêtes, les requêtes de lecture et le trafic d'analyse, réduisant ainsi la charge sur l'instance principale.
Vous vous connectez à une instance dupliquée directement à l'aide de son nom de connexion et de son adresse IP. Si vous vous connectez à une instance dupliquée à l'aide d'une adresse IP privée, vous n'avez pas besoin de créer une connexion VPC privée supplémentaire pour l'instance dupliquée, car la connexion est héritée de l'instance principale.
Pour savoir comment créer ce type d'instance, consultez la page Créer des instances dupliquées avec accès en lecture. Pour en savoir plus sur la gestion des instances dupliquées avec accès en lecture, consultez la page Gérer les instances dupliquées avec accès en lecture.
Il est recommandé de placer les instances dupliquées avec accès en lecture dans une zone différente de celle de l'instance principale lorsque vous utilisez la haute disponibilité sur votre instance principale. Cette pratique garantit que les instances dupliquées avec accès en lecture continuent de fonctionner lorsque la zone qui contient l'instance principale subit une panne. Pour plus d'informations, consultez la page Présentation de la haute disponibilité.
Sélectionner un type de machine approprié
Les instances dupliquées avec accès en lecture peuvent avoir un type de machine différent de celui de l'instance principale. Vous devez surveiller les métriques de votre instance, telles que l'utilisation du processeur et de la mémoire, pour vous assurer que l'instance dupliquée est dimensionnée correctement pour sa charge de travail, en particulier si elle est plus petite que l'instance principale. Une instance dupliquée sous-dimensionnée est plus susceptible d'offrir des performances médiocres, par exemple avec des événements de mémoire insuffisante.
Instances dupliquées interrégionales avec accès en lecture
La réplication interrégionale vous permet de créer une instance dupliquée avec accès en lecture dans une région différente de celle de l'instance primaire. Vous créez une instance dupliquée interrégionale avec accès en lecture de la même manière que vous créez une instance dupliquée régionale.
Les instances dupliquées interrégionales :
- améliorent les performances de lecture en rapprochant les instances dupliquées de la région de votre application ;
- fournissent une fonctionnalité de reprise après sinistre supplémentaire afin de se protéger contre une défaillance régionale ;
- vous permettent de migrer des données d'une région à une autre ;
Pour en savoir plus sur les instances dupliquées interrégionales, consultez la page Promouvoir des instances dupliquées pour la migration régionale ou la reprise après sinistre.
Instances répliquées en cascade avec accès en lecture
La réplication en cascade vous permet de créer une instance répliquée avec accès en lecture qui soit hiérarchiquement intégrée à une autre instance répliquée avec accès en lecture, dans la même région ou dans une région différente. Voici quelques cas d'utilisation des instances répliquées en cascade :
- Reprise après sinistre : vous pouvez utiliser une hiérarchie en cascade d'instances répliquées avec accès en lecture pour simuler la topologie correspondant à votre instance principale et à ses instances répliquées avec accès en lecture. Lors d'une panne, l'instance répliquée avec accès en lecture que vous avez sélectionnée est promue en instance principale et les instances répliquées avec accès en lecture placées sous la nouvelle instance principale continuent d'être répliquées et sont prêtes à être utilisées.
- Amélioration des performances : réduisez la charge sur l'instance principale en déchargeant le travail de réplication sur plusieurs instances répliquées avec accès en lecture.
- Scaling des lectures : vous pouvez disposer d'un plus grand nombre d'instances répliquées pour partager la charge de lecture.
- Réduction des coûts : vous pouvez réduire les coûts de mise en réseau en utilisant une seule instance répliquée en cascade, associée à une réplication interrégionale dans d'autres régions.
Terminologie
- Instance répliquée en cascade : instance répliquée avec accès en lecture qui possède sa propre instance répliquée.
- Niveaux : vous pouvez créer des niveaux d'instances répliquées dans une hiérarchie d'instances répliquées en cascade. Par exemple, si vous ajoutez quatre instances répliquées à une instance, ces quatre instances répliquées se trouvent au même niveau.
- Instances sœurs : plusieurs instances répliquées qui sont répliquées à partir de la même instance principale. Ces instances sœurs sont au même niveau dans la hiérarchie des instances répliquées. Une instance répliquée peut officiellement comporter jusqu'à neuf instances sœurs.
- Instance répliquée terminale : instance répliquée avec accès en lecture qui ne comporte aucune instance répliquée d'elle-même. Dans une hiérarchie de réplication à plusieurs niveaux, l'instance répliquée terminale constitue le dernier niveau.
- Promouvoir : action qui convertit une instance répliquée, à n'importe quel niveau de la hiérarchie, en instance principale. Une fois la promotion effectuée, la hiérarchie d'instances répliquées en cascade au sein de l'instance répliquée est conservée.
Configurer des instances répliquées en cascade
Les instances répliquées en cascade vous permettent d'ajouter des instances répliquées avec accès en lecture à n'importe quelle instance répliquée existante. Vous pouvez ajouter jusqu'à quatre niveaux d'instances répliquées, y compris l'instance principale. Lorsque vous promouvez l'instance répliquée en haut d'une hiérarchie d'instances répliquées en cascade, celle-ci devient une instance principale et la réplication en cascade des instances qui lui sont hiérarchiquement inférieures est conservée.
Pour planifier votre configuration, vous devez définir la fonction ciblée pour les instances répliquées avec accès en lecture. Les deux sections suivantes décrivent des configurations de reprise après sinistre et de réplication multirégionale.
Reprise après sinistre
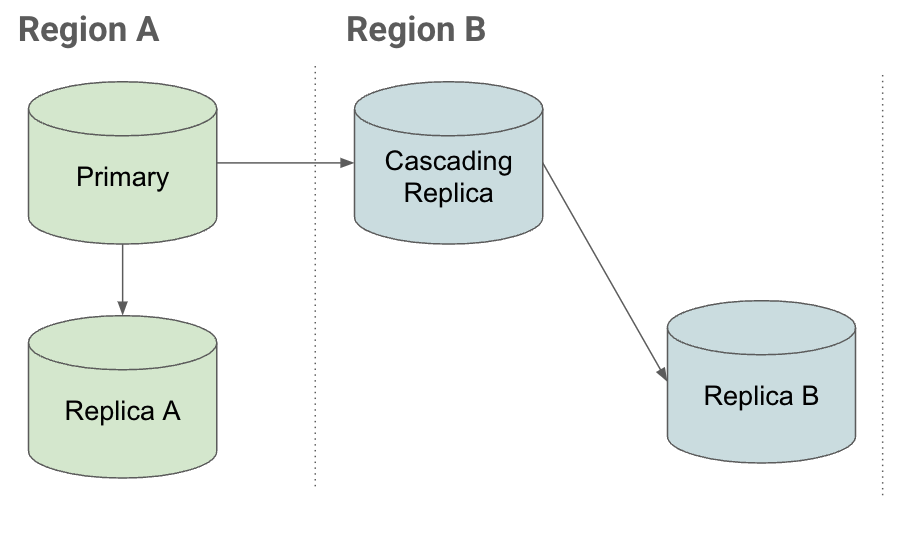
Pour comprendre comment les instances répliquées en cascade peuvent vous aider à rétablir rapidement un système en cas de panne, considérons le scénario de réplication suivant :
Configuration
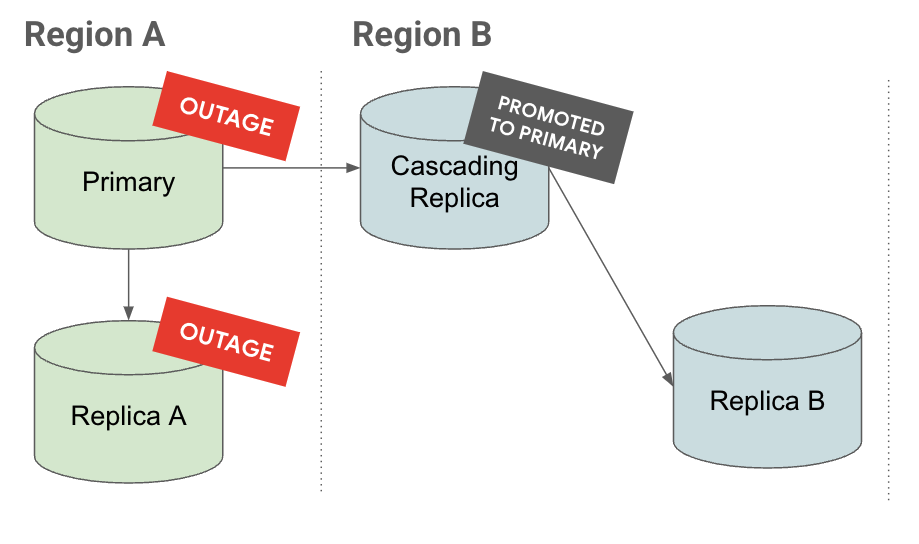
Indisponibilité
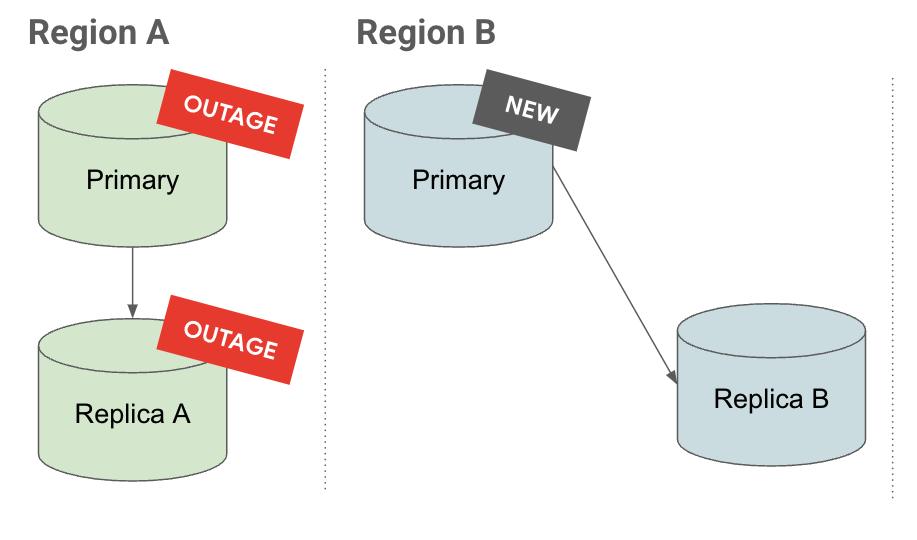
Promotion
Si vous souhaitez utiliser une instance de la région B dans une configuration de reprise après sinistre et si vous disposez :
- d'instances répliquées associées à l'instance principale (instance répliquée A), et situées dans la même région que celle-ci ;
- d'instances répliquées associées à l'instance principale, et situées dans d'autres régions (instances répliquées en cascade) ;
alors vous pouvez créer des instances répliquées avec accès en lecture sous l'instance répliquée en cascade dans la région B.
Dans l'onglet Panne, en cas de panne dans la région A, l'instance répliquée en cascade est promue en instance principale. Elle contient déjà des instances répliquées avec accès en lecture, ce qui réduit l'objectif de temps de récupération (RTO).
Dans l'onglet Promotion, vous constatez que lorsqu'une instance répliquée en cascade est promue, ses instances répliquées sont également promues et continuent de se répliquer dans les niveaux hiérarchiquement inférieurs.
Réplication multirégionale
Un autre cas d'utilisation des instances répliquées en cascade consiste à répartir la capacité de lecture dans une deuxième région, en ciblant une efficience économique maximale. Des instances répliquées en cascade C et D peuvent être créées à partir de l'instance répliquée B. Les clients peuvent répartir les requêtes de lecture sur les instances répliquées B, C et D afin de réduire la charge sur chaque instance répliquée. Le coût du trafic réseau interrégional n'est facturé qu'une seule fois, lors du passage de l'instance principale à l'instance répliquée B. La réplication de B à C et de B à D s'effectue via un transfert réseau intrarégional, qui est gratuit.
Vous pouvez créer une hiérarchie comportant jusqu'à quatre instances à l'aide d'instances répliquées en cascade pour la réplication multirégionale :
Instance principale A → Instance répliquée B → Instance répliquée C et instance répliquée D
Restrictions
- Vous ne pouvez pas supprimer une instance répliquée qui contient des instances répliquées. Pour supprimer l'instance répliquée, vous devez commencer par les instances répliquées terminales qu'elle contient et remonter ainsi dans la hiérarchie.
- La dépendance circulaire au sein d'une région n'est pas acceptée. Pour que l'instance répliquée d'une instance répliquée en cascade se trouve dans la même région que l'instance principale, l'instance répliquée en cascade doit également se trouver dans la même région.
Instances dupliquées externes avec accès en lecture
Les instances dupliquées externes avec accès en lecture sont des instances MySQL externes qui sont dupliquées à partir d'une instance principale Cloud SQL. Par exemple, une instance MySQL qui s'exécute sur Compute Engine est considérée comme une instance externe.
Les instances dupliquées externes avec accès en lecture sont soumises aux restrictions suivantes :
- La réplication sur une instance MySQL hébergée par une autre plate-forme cloud n'est pas toujours possible. Consultez la documentation du fournisseur concerné. Par exemple, la définition du champ de configuration
replicate-ignore-dbest obligatoire et les fournisseurs de cloud qui n'autorisent pas cela ne sont pas acceptés. Pour connaître les autres champs de configuration requis, consultez la section Configurer des instances dupliquées externes. - Si la réplication est interrompue pendant quelques heures (en cas de panne liée au réseau ou au serveur, par exemple), l'instance dupliquée prend du retard par rapport à l'instance principale. L'instance dupliquée rattrape ce retard dès qu'elle se reconnecte à l'instance principale et qu'elle recommence à répliquer des données. Toutefois, si la réplication est interrompue pendant une durée supérieure à la durée de conservation des journaux de réplication Cloud SQL (7 sauvegardes), vous devez supprimer l'instance dupliquée et la recréer.
- Les données qui circulent de l'instance principale vers l'instance répliquée externe sont facturées en tant que transfert de données sortantes. Consultez la page Tarifs pour connaître la tarification du transfert de données selon votre type d'instance Cloud SQL.
Cas d'utilisation de la réplication
Les cas d'utilisation suivants s'appliquent à chaque type de réplication.
| Nom | Instance principale | Instance dupliquée | Avantages et cas d'utilisation | Informations supplémentaires | |
|---|---|---|---|---|---|
| Instance dupliquée avec accès en lecture | Instance Cloud SQL | Instance Cloud SQL |
|
||
| Instance dupliquée interrégionale avec accès en lecture | Instance Cloud SQL | Instance Cloud SQL |
|
||
| Instance dupliquée externe avec accès en lecture | Instance Cloud SQL | Instance MySQL externe à Cloud SQL |
|
||
| Réplication à partir d'un serveur externe | Instance MySQL externe à Cloud SQL | Instance Cloud SQL pour MySQL |
|
Conditions préalables à la création d'une instance dupliquée avec accès en lecture
Pour que vous puissiez créer une instance dupliquée avec accès en lecture pour une instance Cloud SQL principale, celle-ci doit répondre aux exigences suivantes :
- Les sauvegardes automatiques doivent être activées.
- La journalisation binaire doit être activée, ce qui nécessite l'activation de la récupération à un moment précis. En savoir plus sur l'impact de ces journaux.
- Au moins une sauvegarde doit avoir été créée depuis que la journalisation binaire a été activée.
Exigences supplémentaires pour l'instance dupliquée externe :
- La version MySQL de l'instance dupliquée doit être identique ou ultérieure à celle de l'instance principale. En savoir plus
- Vous devez configurer SSL/TLS sur votre instance principale pour renforcer la sécurité. En savoir plus
Impact de l'activation de la journalisation binaire
Vous devez activer la récupération à un moment précis pour activer la journalisation binaire sur l'instance principale et accepter les instances dupliquées avec accès en lecture. Cette action entraîne les conséquences suivantes :
- Impact sur les performances
Cloud SQL utilise une réplication basée sur les lignes, qui exploite les options MySQL
sync_binlog=1etinnodb_support_xa=true. Un disque fsync supplémentaire est donc requis pour chaque opération d'écriture, ce qui entraîne une réduction des performances. - Impact sur le stockage
Le stockage des journaux binaires est facturé au même tarif que le stockage des données ordinaires. Les journaux binaires sont automatiquement tronqués à l'âge de la plus ancienne sauvegarde automatique. Cloud SQL conserve actuellement les sept dernières sauvegardes automatisées ainsi que toutes les sauvegardes à la demande. La taille des journaux binaires (et donc le montant facturé) dépend de la charge de travail. Par exemple, une charge de travail lourde en écriture utilise plus d'espace de journaux binaires qu'une charge de travail lourde en lecture.
Vous pouvez afficher la taille des journaux binaires à l'aide de la commande MySQL SHOW BINARY LOGS.
Lors des opérations de sauvegarde, les journaux sont enregistrés dans la sauvegarde avec les données.
Journalisation binaire sur les instances dupliquées avec accès en lecture
- La journalisation binaire est compatible avec les instances dupliquées avec accès en lecture (MySQL 5.7 et 8.0 uniquement). Vous activez la journalisation binaire sur une instance dupliquée avec les mêmes commandes d'API que sur l'instance principale, mais en utilisant le nom de l'instance dupliquée plutôt que le nom de l'instance principale. Notez que les termes
enable binary loggingetenable point-in-time recoverysont interchangeables.La durabilité de la journalisation binaire sur l'instance dupliquée (mais pas sur l'instance principale) peut être définie avec l'option
sync_binlogqui contrôle la fréquence à laquelle le serveur MySQL synchronise le journal binaire sur le disque.La journalisation binaire peut être activée sur une instance dupliquée même si la sauvegarde est désactivée sur l'instance principale.
Si une instance dupliquée qui possède cette valeur est promue sur un serveur autonome, le paramètre est réinitialisé sur la valeur sécurisée
1sur le serveur autonome.
Facturation
- Une instance dupliquée avec accès en lecture est facturée au même tarif qu'une instance Cloud SQL standard. La réplication des données est gratuite.
- Pour les instances répliquées externes, les données qui circulent de l'instance principale vers l'instance répliquée externe sont facturées en tant que transfert de données. Consultez la page Tarifs pour connaître la tarification du transfert de données selon votre type d'instance Cloud SQL.
- La tarification d'une instance dupliquée interrégionale avec accès en lecture est la même que pour créer une instance Cloud SQL dans la région. Reportez-vous à la section Tarifs de l'instance Cloud SQL et sélectionnez la région appropriée. En plus du coût standard associé à l'instance, une instance répliquée interrégionale génère des frais de transfert de données inter-régions pour les journaux de réplication envoyés depuis l'instance principale vers l'instance répliquée, comme décrit dans la section Tarifs de sortie du réseau.
Guide de référence pour les instances dupliquées avec accès en lecture de Cloud SQL
| Sujet | Discussion |
|---|---|
| Sauvegardes | Vous ne pouvez pas configurer de sauvegarde sur une instance dupliquée. |
| Cœurs et mémoire | Les instances dupliquées avec accès en lecture peuvent utiliser un nombre de cœurs et une quantité de mémoire différents de ceux de l'instance principale. |
| Supprimer l'instance principale | Pour pouvoir supprimer une instance principale, vous devez supprimer toutes les instances dupliquées avec accès en lecture qui lui sont associées ou les promouvoir en instances autonomes. |
| Supprimer l'instance dupliquée | La suppression d'une instance dupliquée n'a aucune incidence sur l'état de l'instance principale. |
| Désactiver la journalisation binaire | Pour pouvoir désactiver les journaux binaires sur une instance principale, vous devez supprimer toutes les instances dupliquées avec accès en lecture qui lui sont associées ou les promouvoir en instances autonomes. |
| Basculer | Une instance principale ne peut pas basculer vers une instance dupliquée avec accès en lecture, et les instances dupliquées avec accès en lecture ne peuvent en aucun cas basculer en cas de panne. |
| Haute disponibilité | Les instances répliquées avec accès en lecture vous permettent d'activer la haute disponibilité sur les instances répliquées. |
| Équilibrage de charge | Cloud SQL n'assure pas l'équilibrage de charge entre les instances dupliquées. Vous pouvez choisir de mettre en œuvre l'équilibrage de charge pour votre instance Cloud SQL. Vous pouvez également utiliser le regroupement de connexions pour répartir les requêtes sur les instances dupliquées avec votre configuration d'équilibrage de charge afin d'améliorer les performances. |
| Intervalles de maintenance | Il n'est pas possible de définir des intervalles de maintenance sur des instances dupliquées avec accès en lecture. Par ailleurs, les instances dupliquées avec accès en lecture ne partagent pas d'intervalles de maintenance avec l'instance principale. Les opérations de maintenance sont susceptibles de se produire à tout moment sur l'instance dupliquée avec accès en lecture. La maintenance des instances dupliquées avec accès en lecture intervient à un autre moment que sur l'instance principale. |
| Instances dupliquées avec accès en lecture multiples | Cloud SQL est compatible avec les instances répliquées en cascade. Par conséquent, vous pouvez créer jusqu'à 10 instances répliquées par instance principale. Elles peuvent être associées à quatre niveaux au maximum, y compris au principal. |
| Réplication parallèle | Pour plus d'informations sur l'utilisation de la réplication parallèle pour améliorer les performances, consultez la page Configurer la réplication parallèle. |
| Adresse IP privée | Si vous vous connectez à une instance dupliquée à l'aide d'une adresse IP privée, vous n'avez pas besoin de créer une connexion VPC privée supplémentaire pour l'instance dupliquée, car elle est héritée de l'instance principale. |
| Restauration de l'instance principale | Vous ne pouvez pas restaurer l'instance principale d'une instance répliquée tant que celle-ci existe. Avant de restaurer une instance à partir d'une sauvegarde ou d'effectuer une récupération à un moment précis, vous devez promouvoir ou supprimer toutes les instances dupliquées qui lui sont associées. |
| Paramètres | Les paramètres MySQL de l'instance principale, tels que le mot de passe racine et les modifications apportées à la table utilisateur, sont transmis aux instances dupliquées. Les modifications apportées aux processeurs et à la mémoire ne sont pas transmises aux instances dupliquées. |
| Arrêt d'une instance dupliquée | Vous ne pouvez pas utiliser la commande stop sur une instance dupliquée. Vous pouvez utiliser la commande restart, delete ou disable replication, mais vous ne pouvez pas l'arrêter comme vous le feriez avec une instance principale. |
| Mettre à jour une instance dupliquée | Les instances dupliquées avec accès en lecture peuvent à tout moment faire l'objet d'une mise à jour perturbatrice. |
| Tables utilisateur | Vous ne pouvez pas apporter de modifications à l'instance dupliquée. Toutes les modifications apportées aux utilisateurs doivent être effectuées sur l'instance principale. |
Étape suivante
- Apprenez à créer une instance dupliquée avec accès en lecture.
- Apprenez à configurer une image dupliquée externe.
- Apprenez à répliquer des données à partir d'un serveur externe.
- Découvrez comment configurer une configuration de serveur externe.
- Apprenez à répliquer dans MySQL.
- Apprenez à configurer la haute disponibilité d'une instance.