Halaman ini menjelaskan kuota dan batas produksi untuk Spanner. Kuota dan batas dapat digunakan secara bergantian di Konsol Google Cloud.
Nilai kuota dan batas dapat berubah sewaktu-waktu.
Izin untuk memeriksa dan mengedit kuota
Untuk melihat kuota, Anda harus memiliki izin serviceusage.quotas.get Identity and Access Management (IAM).
Untuk mengubah kuota, Anda harus memiliki izin IAM serviceusage.quotas.update. Izin ini disertakan secara default untuk peran standar berikut: Pemilik, Editor, dan Administrator Kuota.
Izin ini disertakan secara default dalam Pemilik dan Editor peran IAM dasar, serta dalam peran Administrator Kuota yang telah ditentukan.
Memeriksa kuota Anda
Untuk memeriksa kuota resource saat ini di project Anda, gunakan konsol Google Cloud:
Menambah kuota Anda
Seiring bertambahnya penggunaan Spanner dari waktu ke waktu, kuota Anda juga dapat meningkat. Jika Anda memperkirakan akan ada peningkatan penggunaan yang signifikan, Anda harus mengajukan permintaan beberapa hari sebelumnya untuk memastikan kuota Anda berukuran cukup.
Anda mungkin juga perlu meningkatkan penggantian kuota konsumen. Untuk mengetahui informasi selengkapnya, lihat Membuat penggantian kuota konsumen.
Anda dapat meningkatkan batas node konfigurasi instance Spanner saat ini menggunakan Konsol Google Cloud.
Buka halaman Kuota.
Pilih Spanner API di daftar dropdown Service.
Jika Anda tidak melihat Spanner API, berarti Spanner API belum diaktifkan. Untuk mengetahui informasi selengkapnya, lihat Mengaktifkan API.
Pilih kuota yang ingin diubah.
Klik Edit Kuota.
Di panel Perubahan kuota yang muncul, masukkan batas kuota baru.
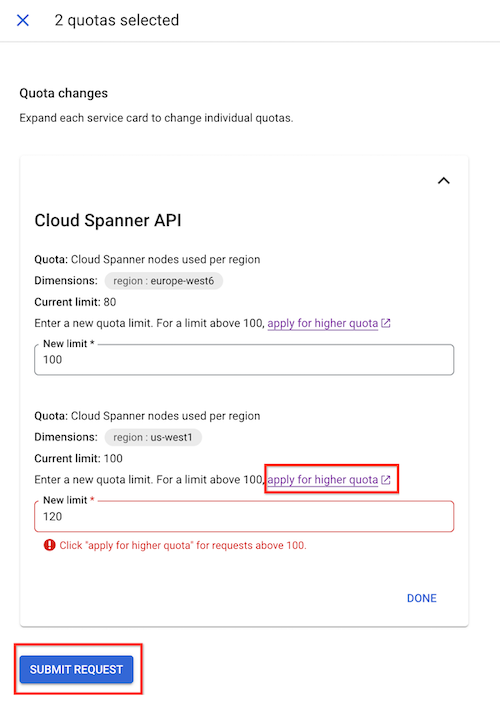
Klik Selesai, lalu Kirim permintaan.
Jika Anda tidak dapat meningkatkan batas node ke batas yang diinginkan secara manual, klik apply for more quota. Isi formulir untuk mengirimkan permintaan ke tim Spanner. Anda akan menerima respons dalam waktu 48 jam sejak permintaan Anda.
Meningkatkan kuota untuk konfigurasi instance kustom
Anda dapat meningkatkan kuota node untuk konfigurasi instance kustom.
Periksa batas node konfigurasi instance kustom dengan memeriksa batas node dari konfigurasi instance dasar.
Gunakan perintah show instance configurations detail jika Anda tidak mengetahui atau mengingat konfigurasi dasar konfigurasi instance kustom Anda.
Jika batas node yang diperlukan untuk konfigurasi instance kustom kurang dari 85, ikuti petunjuk di bagian Meningkatkan kuota sebelumnya. Gunakan Konsol Google Cloud untuk meningkatkan batas node konfigurasi instance dasar yang terkait dengan konfigurasi instance kustom Anda.
Jika batas node yang diperlukan untuk konfigurasi instance kustom lebih dari 85, isi formulir Minta Peningkatan Kuota untuk Node Spanner Anda. Tentukan ID konfigurasi instance kustom Anda dalam formulir.
Batas node
| Nilai | Batas |
|---|---|
| Konfigurasi node per instance |
Batas default bervariasi menurut project dan konfigurasi instance. Untuk mengubah batas kuota project atau meminta peningkatan batas, lihat Meningkatkan kuota. |
Batas instance
| Nilai | Batas |
|---|---|
| Panjang ID instance | 2 hingga 64 karakter |
Batas instance uji coba gratis
Instance uji coba gratis Spanner memiliki batas tambahan berikut. Untuk menaikkan atau menghapus batas ini, upgrade instance uji coba gratis Anda ke instance berbayar.
| Nilai | Batas |
|---|---|
| Kapasitas penyimpanan | 10 GB |
| Batas database | Membuat hingga lima {i>database<i} |
| Fitur yang tidak didukung | Pencadangan dan pemulihan |
| SLA | Tidak ada jaminan SLA |
| Durasi uji coba | Periode uji coba gratis 90 hari |
Batas konfigurasi instance
| Nilai | Batas |
|---|---|
| Konfigurasi instance kustom maksimum per project | 100 |
| Panjang ID konfigurasi instance kustom | 8 hingga 64 karakter ID konfigurasi instance kustom harus diawali dengan |
Batas database
| Nilai | Batas |
|---|---|
| Database per instance |
|
| Peran per database | 100 |
| Panjang ID database | 2 hingga 30 karakter |
| Ukuran penyimpanan1 |
Peningkatan kapasitas penyimpanan sebesar 10 TB per node tersedia dalam konfigurasi instance Spanner regional dan multi-region tertentu. Untuk mengetahui informasi selengkapnya, lihat Peningkatan performa dan penyimpanan. Cadangan disimpan secara terpisah dan tidak diperhitungkan dalam batas ini. Untuk mengetahui informasi selengkapnya, lihat Metrik penggunaan penyimpanan. Perhatikan bahwa Spanner menagih biaya penyimpanan sebenarnya yang digunakan dalam instance, dan bukan total penyimpanan yang tersedia. |
Batas pencadangan dan pemulihan
| Nilai | Batas |
|---|---|
| Jumlah operasi pencadangan yang sedang berjalan per database | 1 |
| Jumlah operasi database pemulihan yang sedang berlangsung per instance (dalam instance database yang dipulihkan, bukan cadangan) | 10 |
| Waktu retensi maksimum cadangan | 1 tahun (termasuk hari tambahan pada tahun kabisat) |
Batas skema
Pernyataan DDL
| Nilai | Batas |
|---|---|
| Ukuran pernyataan DDL untuk perubahan skema tunggal | 10 MB |
Ukuran pernyataan DDL untuk seluruh skema database, seperti yang ditampilkan oleh GetDatabaseDdl |
10 MB |
Tabel
| Nilai | Batas |
|---|---|
| Tabel per database | 5.000 |
| Panjang nama tabel | 1 hingga 128 karakter |
| Kolom per tabel | 1.024 |
| Panjang nama kolom | 1 hingga 128 karakter |
| Ukuran data per sel | 10 MB |
| Jumlah kolom di kunci tabel | 16 Termasuk kolom kunci yang dibagikan ke tabel induk |
| Kedalaman tabel yang memiliki sisipan | 7 Tabel tingkat atas dengan tabel turunan memiliki kedalaman 1. Tabel tingkat atas dengan tabel turunannya lagi memiliki kedalaman 2, dan seterusnya. |
| Total ukuran tabel atau kunci indeks | 8 KB Termasuk ukuran semua kolom yang membentuk kunci |
| Ukuran total kolom non-kunci | 1.600 MB Menyertakan ukuran semua kolom non-kunci untuk tabel |
Indeks
| Nilai | Batas |
|---|---|
| Indeks per database | 10.000 |
| Indeks per tabel | 128 |
| Panjang nama indeks | 1 hingga 128 karakter |
| Jumlah kolom di kunci indeks | 16 Jumlah kolom terindeks (kecuali untuk kolom STORING) ditambah jumlah kolom kunci utama di tabel dasar |
Tabel Virtual
| Nilai | Batas |
|---|---|
| Tampilan per database | 5.000 |
| Panjang nama tampilan | 1 hingga 128 karakter |
| Kedalaman tingkat | 10 Tampilan yang merujuk ke tampilan lain memiliki kedalaman tingkatan 1. Tampilan yang merujuk ke tampilan lain yang merujuk ke tampilan lain memiliki kedalaman tingkatan 2, dan seterusnya. |
Batas kueri
| Nilai | Batas |
|---|---|
Kolom di klausa GROUP BY |
1.000 |
Nilai dalam operator IN |
10.000 |
| Panggilan fungsi | 1.000 |
| Gabungan | 20 |
| Panggilan fungsi bertingkat | 75 |
Klausul GROUP BY bertingkat |
35 |
| Ekspresi subkueri bertingkat | 25 |
| Pernyatan subselect bertingkat | 60 |
| Parameter | 950 |
| Panjang pernyataan kueri | 1 juta karakter |
STRUCT kolom |
1.000 |
| Turunan ekspresi subkueri | 50 |
| Gabungan dalam kueri | 200 |
Batas untuk membuat, membaca, memperbarui, dan menghapus data
| Nilai | Batas |
|---|---|
| Ukuran commit (termasuk indeks dan aliran data perubahan) | 100 MB |
| Baca serentak per sesi | 100 |
| Mutasi per commit (termasuk indeks)2 | 80.000 |
| Pernyataan DML Terpartisi serentak per database | 20.000 |
Batas administratif
| Nilai | Batas |
|---|---|
| Ukuran permintaan tindakan administratif3 | 1 MB |
| Batas kapasitas untuk tindakan administratif4 | 5 per detik per project per pengguna (rata-rata di atas 100 detik) |
Batas permintaan
| Nilai | Batas |
|---|---|
| Ukuran permintaan selain untuk commit5 | 10 MB |
Mengubah batas streaming
| Nilai | Batas |
|---|---|
| Aliran perubahan per database | 10 |
| Mengubah streaming yang menonton kolom non-kunci tertentu6 | 3 |
| Pembaca serentak per partisi data aliran perubahan7 | 5 |
Batas Data Boost
| Nilai | Batas |
|---|---|
| Permintaan Data Boost serentak8 | 200 |
Notes
1. Untuk memberikan ketersediaan tinggi dan latensi rendah dalam mengakses database, Spanner menentukan batas penyimpanan berdasarkan kapasitas komputasi instance:
- Untuk instance yang lebih kecil dari 1 node (1.000 unit pemrosesan), Spanner mengalokasikan 409,6 GB data untuk setiap 100 unit pemrosesan dalam database.
- Untuk instance 1 node dan yang lebih besar, Spanner mengalokasikan 4 TB data untuk setiap node.
Misalnya, untuk membuat instance database berukuran 600 GB, Anda perlu menetapkan kapasitas komputasinya ke 200 unit pemrosesan. Jumlah kapasitas komputasi ini akan membuat instance tetap berada di bawah batas hingga database tumbuh menjadi lebih dari 819,2 GB. Setelah database mencapai ukuran ini, Anda perlu menambahkan 100 unit pemrosesan lagi agar database dapat berkembang. Jika tidak, penulisan ke database dapat ditolak. Untuk mengetahui informasi selengkapnya, lihat Rekomendasi penggunaan penyimpanan database.
Untuk mendapatkan pengalaman pertumbuhan yang lancar, tambahkan kapasitas komputasi sebelum batas database Anda tercapai.
2. Operasi penyisipan dan pembaruan dihitung dengan banyaknya
kolom yang terpengaruh, dan kolom kunci utama selalu terpengaruh. Misalnya,
menyisipkan kumpulan data baru dapat dihitung sebagai lima mutasi, jika nilai disisipkan
ke dalam lima kolom. Memperbarui tiga kolom dalam kumpulan data juga dapat dihitung sebagai lima mutasi jika kumpulan data tersebut memiliki dua kolom kunci utama. Operasi penghapusan dan penghapusan rentang dihitung sebagai satu mutasi, terlepas dari jumlah kolom yang terpengaruh.
Menghapus baris dari tabel induk yang memiliki anotasi
ON DELETE
CASCADE juga dihitung sebagai satu mutasi, terlepas dari
jumlah baris turunan yang disisipkan. Pengecualian untuk hal ini adalah jika ada indeks sekunder yang ditentukan pada baris yang dihapus, perubahan pada indeks sekunder akan dihitung satu per satu. Misalnya, jika sebuah tabel memiliki 2 indeks sekunder, penghapusan rentang baris dalam tabel akan dihitung sebagai 1 mutasi untuk tabel, ditambah 2 mutasi untuk setiap baris yang dihapus karena baris dalam indeks sekunder mungkin tersebar di atas ruang kunci, sehingga tidak mungkin bagi Spanner untuk memanggil operasi rentang penghapusan tunggal pada indeks sekunder. Indeks sekunder meliputi indeks pendukung kunci asing.
Untuk menemukan jumlah mutasi transaksi, lihat Mengambil statistik commit untuk transaksi.
Aliran data perubahan tidak menambahkan mutasi yang diperhitungkan terhadap batas ini.
3. Batas untuk permintaan tindakan administratif tidak termasuk commit, permintaan yang tercantum di catatan 5, dan perubahan skema.
4. Batas kapasitas ini mencakup semua panggilan ke admin API, yang mencakup panggilan untuk melakukan polling operasi yang berjalan lama pada instance, database, atau pencadangan.
5. Batas ini mencakup permintaan untuk membuat database, memperbarui database, membaca, melakukan streaming pembacaan, mengeksekusi kueri SQL, dan mengeksekusi kueri SQL streaming.
6. Aliran data perubahan yang mengawasi seluruh tabel atau database secara implisit mengawasi setiap kolom dalam tabel atau database tersebut, sehingga diperhitungkan terhadap batas ini.
7. Batas ini berlaku untuk pembaca serentak dari partisi aliran perubahan yang sama, baik pembaca adalah pipeline Dataflow maupun kueri API langsung.
8. Batas default bervariasi menurut project dan region. Untuk mengetahui informasi selengkapnya, lihat Memantau dan mengelola penggunaan kuota Data Boost.