O Spanner é um banco de dados altamente consistente, distribuído e escalável construído pelos engenheiros do Google para ser compatível com alguns dos aplicativos mais importantes da empresa. Ele usa ideias essenciais das comunidades de sistemas distribuídos e de bancos de dados e as expande de novas maneiras. O Spanner expõe esse serviço interno como um serviço disponível publicamente no Google Cloud Platform.
Como o Spanner precisa lidar com os exigentes requisitos de escalonamento e tempo de atividade impostos pelos aplicativos comerciais críticos do Google, nós o criamos desde o início para ser um banco de dados amplamente distribuído. O serviço pode abranger várias máquinas e vários data centers e regiões. Aproveitamos essa distribuição para lidar com grandes conjuntos de dados e cargas de trabalho, mantendo uma disponibilidade muito alta. Também procuramos fazer com que o Spanner ofereça as mesmas garantias de consistência rigorosas fornecidas por outros bancos de dados de nível empresarial, porque queremos criar uma ótima experiência para os desenvolvedores. É muito mais fácil raciocinar sobre um software e desenvolvê-lo para um banco de dados compatível com uma consistência forte do que para um banco de dados compatível apenas com consistência no nível de linha, consistência no nível de entidade ou sem garantia de consistência alguma.
Neste documento, descrevemos em detalhes como as gravações e leituras funcionam no Spanner e como ele garante uma consistência forte.
Pontos de partida
Alguns conjuntos de dados são grandes demais para caber em uma única máquina. Há também cenários em que o conjunto de dados é pequeno, mas a carga de trabalho é muito pesada para uma única máquina lidar. Isso significa que precisamos encontrar uma maneira de dividir nossos dados em peças separadas que possam ser armazenadas em várias máquinas. Nossa ideia é particionar tabelas de banco de dados em intervalos de chaves contíguas chamados de divisões. Uma única máquina pode atender várias divisões, e há um serviço de pesquisa rápida para determinar as máquinas que atendem um determinado intervalo de chaves. Os detalhes de como os dados são divididos e as máquinas em que residem são transparentes para os usuários do Spanner. O resultado é um sistema que pode fornecer latências baixas para leitura e gravação, mesmo sob cargas de trabalho pesadas em grande escala.
Também queremos garantir que os dados estejam acessíveis, mesmo com falhas. Para isso, replicamos cada divisão em várias máquinas em domínios de falha diferentes. A replicação consistente das diferentes cópias da divisão é gerenciada pelo algoritmo Paxos. No Paxos, enquanto a maioria das réplicas de votação da divisão estiver ativa, uma delas pode ser escolhida como a líder para processar gravações e permitir que outras réplicas atendam leituras.
O Spanner oferece transações somente leitura e transações de leitura e gravação. O primeiro tipo é o preferencial para operações (incluindo instruções SQL SELECT) que não alteram os dados. As transações somente leitura ainda fornecem consistência forte e operam, por padrão, na cópia mais recente dos dados. Mas, com elas, é possível realizar a execução sem a necessidade de qualquer forma de bloqueio interno, o que as torna mais rápidas e escaláveis. As transações de leitura e gravação são usadas para transações que inserem, atualizam ou excluem dados. Isso inclui transações que realizam leituras seguidas de uma gravação. Elas ainda são altamente escaláveis, mas as transações de leitura e gravação introduzem bloqueio e precisam ser articuladas por líderes do Paxos. Observe que o bloqueio é transparente para os clientes do Spanner.
Muitos sistemas anteriores de bancos de dados distribuídos optaram por não oferecer garantias de consistência forte devido à comunicação entre máquinas que geralmente é exigida e é muito cara. O Spanner consegue fornecer instantâneos de consistência forte em todo o banco de dados com o uso de uma tecnologia desenvolvida pelo Google chamada TrueTime. Assim como o capacitor de fluxo de uma máquina do tempo de 1985, o TrueTime é o que torna o Spanner possível. Ele é uma API que permite que qualquer máquina nos datacenters do Google saiba o tempo global exato com um alto grau de precisão, ou seja: em alguns milissegundos. Isso permite que diferentes máquinas do Spanner processem a ordenação das operações transacionais (e correspondam essa ordenação ao que o cliente observou), muitas vezes sem qualquer comunicação. O Google teve que preparar seus data centers com hardware especial (relógios atômicos) para fazer o TrueTime funcionar. A exatidão e a precisão de tempo resultantes são muito maiores do que pode ser alcançado por outros protocolos (como o NTP). Em particular, o Spanner atribui um carimbo de data/hora a todas as leituras e gravações. Uma transação no carimbo de data/hora T1 garante a reflexão dos resultados de todas as gravações que aconteceram antes de T1. Se uma máquina quiser cumprir uma leitura em T2, será necessário garantir que a visualização dos dados esteja atualizada pelo menos em T2. Por causa do TrueTime, essa determinação geralmente é muito barata. Os protocolos para garantir a consistência dos dados são complicados, mas estão detalhados no whitepaper original do Spanner e neste whitepaper sobre consistência no Spanner.
Exemplo prático
É hora de conferir alguns exemplos práticos para ver como tudo funciona:
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
Neste exemplo, temos uma tabela com uma chave primária de número inteiro simples.
| Divisão | KeyRange |
|---|---|
| 0 | [-∞, 3) |
| 1 | [3,224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
Dado o esquema para ExampleTable acima, o espaço da chave primária é particionado em divisões. Por exemplo: se houver uma linha em ExampleTable com um Id de 3700, ela ficará na Divisão 8. Conforme detalhado acima, a própria Divisão 8 é replicada em várias máquinas.
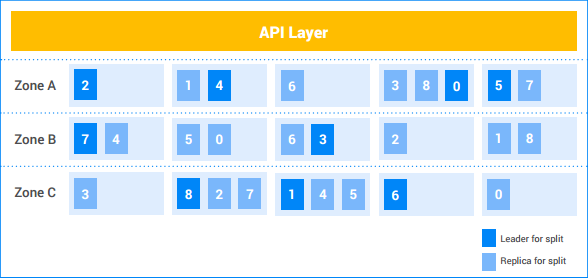
Nesta instância de exemplo do Spanner, o cliente tem cinco nodes e a instância é replicada em três zonas. As nove divisões estão numeradas de 0 a 8, com os líderes do Paxos para cada divisão com sombreamento escuro. As divisões também têm réplicas em cada zona, com sombreamento claro. A distribuição de divisões entre os nodes pode ser diferente em cada zona, e os líderes do Paxos não residem todos na mesma zona. Com essa flexibilidade, o Spanner fica mais robusto em certos tipos de perfis de carga e modos de falha.
Gravação com divisão única
Digamos que o cliente queira inserir uma nova linha (7, "Seven") em ExampleTable.
- A API Layer pesquisa a divisão que tem o intervalo de chave que contém
7. Ele está na Divisão 1. - A API Layer envia a solicitação de gravação para o líder da Divisão 1.
- O líder inicia uma transação.
- O líder tenta conseguir um bloqueio de gravação na linha
Id=7. Essa é uma operação local. Se outra transação simultânea de leitura e gravação estiver lendo essa linha atualmente, ela terá um bloqueio de leitura e a transação atual será bloqueada até que possa adquirir o bloqueio de gravação.- É possível que a transação A esteja aguardando um bloqueio mantido pela transação B e a transação B aguarde um bloqueio mantido pela transação A. Uma vez que nenhuma das operações libera qualquer bloqueio até que adquira todos os bloqueios, isso pode levar a um impasse. O Spanner usa um algoritmo padrão de prevenção de impasse de "wound-wait" para garantir que as transações progridam. Em particular, uma transação "mais nova" aguardará um bloqueio mantido por uma "mais antiga", mas a "antiga" vai "ferir" (cancelar) uma mais nova que contenha um bloqueio solicitado pela mais antiga. Portanto, nunca haverá ciclos de impasse para espera de bloqueio.
- Uma vez que o bloqueio é adquirido, o líder atribui um carimbo de data/hora à transação com base no TrueTime.
- Esse carimbo de data/hora é, com certeza, maior que o de qualquer transação confirmada previamente que tenha usado os dados. É isso que garante que a ordem das transações (conforme percebida pelo cliente) corresponda à ordem das mudanças nos dados.
- O líder comunica as réplicas da Divisão 1 sobre a transação e o carimbo de data/hora dela. Depois que a maioria dessas réplicas tiver armazenado a mutação da transação em um armazenamento estável (no sistema de arquivos distribuído), a transação é confirmada. Isso garante que a transação seja recuperável, mesmo que haja uma falha em uma minoria de máquinas. As réplicas ainda não aplicam as mutações à cópia dos dados delas.
O líder aguarda até ter certeza de que o carimbo de data/hora da transação passou em tempo real, o que normalmente requer alguns milissegundos para que possamos aguardar qualquer incerteza no carimbo de data/hora do TrueTime. Isso é o que garante uma consistência forte. Uma vez que um cliente tenha conhecimento do resultado de uma transação, é garantido que todos os outros leitores verão os efeitos da transação. Essa "espera de confirmação" normalmente se sobrepõe à comunicação de réplica na etapa acima, de modo que o custo de latência real é mínimo. Veja mais detalhes neste artigo.
O líder responde ao cliente para comunicar que a transação foi confirmada, informando opcionalmente o carimbo de data/hora de confirmação da transação.
Paralelamente à resposta ao cliente, as mutações da transação são aplicadas aos dados.
- O líder aplica as mutações à cópia dos dados dele e, em seguida, libera os bloqueios de transação.
- O líder também informa as outras réplicas da Divisão 1 para que a mutação seja aplicada às cópias dos dados delas.
- Em qualquer transação de leitura e gravação ou somente leitura em que seja necessário ver os efeitos das mutações, há uma espera pela aplicação dessas mutações antes da leitura dos dados. Para transações de leitura e gravação, isso é aplicado porque a transação precisa ter um bloqueio de leitura. Para transações somente leitura, isso é aplicado pela comparação do carimbo de data/hora da leitura com o dos últimos dados aplicados.
Normalmente, tudo isso acontece em alguns milissegundos. Esse é o tipo mais barato de gravação feito pelo Spanner, já que somente uma divisão está envolvida.
Gravação com várias divisões
Se houver várias divisões envolvidas, será necessária uma camada extra de coordenação (usando o algoritmo de confirmação padrão em duas fases).
Digamos que a tabela contenha 4.000 linhas:
| 1 | "uma" |
| 2 | "two" |
| ... | ... |
| 4.000 | "quatro mil" |
E digamos que o cliente queira ler o valor da linha 1000 e gravar um valor nas linhas 2000, 3000 e 4000 dentro de uma transação. Isso será executado dentro de uma transação de leitura e gravação da seguinte maneira:
- O cliente começa uma transação de leitura e gravação, t.
- O cliente emite uma solicitação de leitura para a linha 1.000 à API Layer e a marca como parte de t.
- A API Layer pesquisa a divisão que tem a chave
1000. Ela fica na Divisão 4. A API Layer envia uma solicitação de leitura ao líder da Divisão 4 e a marca como parte de t.
O líder da Divisão 4 tenta conseguir um bloqueio de leitura na linha
Id=1000. Essa é uma operação local. Se outra transação simultânea tiver um bloqueio de gravação nessa linha, a transação atual será bloqueada até que ela possa conseguir o bloqueio. No entanto, esse bloqueio de leitura não impede que outras transações consigam bloqueios de leitura.- Como no caso de divisão única, o impasse é impedido por "wound-wait".
O líder procura o valor de
Id1000("Mil") e retorna o resultado da leitura para o cliente.
Mais tarde…O cliente emite uma solicitação de confirmação para a transação t. Essa solicitação de confirmação contém três mutações: (
[2000, "Dos Mil"],[3000, "Tres Mil"]e[4000, "Quatro Mil"]).- Todas as divisões envolvidas em uma transação se tornam participantes da transação. Nesse caso, a Divisão 4 (que atendia a leitura para a chave
1000), a Divisão 7 (que manipulará a mutação para a chave2000) e a Divisão 8 (que manipulará as mutações para as chaves3000e4000) são participantes.
- Todas as divisões envolvidas em uma transação se tornam participantes da transação. Nesse caso, a Divisão 4 (que atendia a leitura para a chave
Um participante se torna o coordenador. Nesse caso, talvez seja o líder da Divisão 7. O trabalho dele é garantir que a transação seja confirmada ou cancelada atomicamente em todos os participantes. Ou seja, ele não vai realizar a confirmação em um participante e o cancelamento em outro.
- O trabalho realizado pelos participantes e coordenadores é feito na verdade pelas máquinas líderes dessas divisões.
Os participantes adquirem bloqueios. Esta é a primeira fase da confirmação de duas fases.
- A Divisão 7 adquire um bloqueio de gravação na chave
2000. - A Divisão 8 adquire um bloqueio de gravação nas chaves
3000e4000. - A Divisão 4 verifica se ainda há um bloqueio de leitura na chave
1000, ou seja, se o bloqueio não foi perdido devido a uma falha da máquina ou ao algoritmo de wound-wait. - Cada divisão do participante grava o respectivo conjunto de bloqueios replicando-os para (pelo menos) a maioria das réplicas de divisão. Isso garante que os bloqueios possam permanecer mantidos mesmo em falhas do servidor.
- Se todos os participantes notificarem com êxito o coordenador de que os bloqueios deles foram mantidos, a transação global poderá ser confirmada. Isso garante que haja um ponto no tempo em que todos os bloqueios necessários para a transação são mantidos. Esse ponto se torna o ponto de confirmação da transação, garantindo que possamos ordenar corretamente os efeitos dessa transação diante de outras transações que vieram antes ou depois.
- É possível que os bloqueios não possam ser adquiridos (por exemplo, se descobrirmos que pode haver um impasse com o algoritmo de wound-wait). Se algum participante disser que não é possível confirmar a transação, toda a transação será cancelada.
- A Divisão 7 adquire um bloqueio de gravação na chave
Se todos os participantes e o coordenador adquirem bloqueios com êxito, o coordenador (Divisão 7) decide confirmar a transação. Ele atribui um carimbo de data/hora à transação com base no TrueTime.
- Essa decisão de confirmação, bem como as mutações para a chave
2000, é replicada aos membros da Divisão 7. Depois que a maioria das réplicas da Divisão 7 registra a decisão de confirmação para um armazenamento estável, a transação é confirmada.
- Essa decisão de confirmação, bem como as mutações para a chave
O coordenador comunica o resultado da transação a todos os participantes. Esta é a segunda fase da confirmação de duas fases.
- Cada líder participante replica a decisão de confirmação às réplicas da divisão do participante.
Se a transação for confirmada, o coordenador e todos os participantes aplicarão as mutações aos dados.
- Como no caso de divisão única, os leitores subsequentes de dados no coordenador ou nos participantes precisam esperar até que os dados sejam aplicados.
O líder do coordenador responde ao cliente para dizer que a transação foi confirmada, opcionalmente retornando o carimbo de data/hora de confirmação da transação.
- Como no caso de divisão única, o resultado é comunicado ao cliente após uma espera de confirmação, para garantir consistência forte.
Normalmente, tudo isso acontece em alguns milissegundos, embora normalmente um pouco a mais do que no caso de divisão única devido à coordenação extra de divisão cruzada.
Leitura forte (várias divisões)
Digamos que o cliente queira ler todas as linhas em que Id >= 0 e Id < 700 como parte de uma transação somente leitura.
- A API Layer pesquisa as divisões que têm qualquer chave no intervalo
[0, 700). Essas linhas são de propriedade das Divisões 0, 1 e 2. - Como essa é uma leitura forte em várias máquinas, a API Layer escolhe o
carimbo de data/hora de leitura usando o TrueTime atual. Isso garante que ambas as leituras retornem dados do mesmo instantâneo do banco de dados.
- Outros tipos de leituras, como leituras desatualizadas, também escolhem um carimbo de data/hora para ler (mas ele pode estar no passado).
- A API Layer envia a solicitação de leitura a algumas réplicas das Divisões 0, 1 e 2. Ela também inclui o carimbo de data/hora de leitura selecionado na etapa acima.
Para leituras fortes, a réplica de exibição normalmente faz uma RPC ao líder para solicitar o carimbo de data/hora da última transação que precisa ser aplicada e a leitura poderá continuar depois que a transação for aplicada. Se a réplica for a líder ou se ela determinar que foi capturada o suficiente para atender à solicitação do estado interno e do TrueTime, ela atenderá diretamente a leitura.
Os resultados das réplicas são combinados e retornados ao cliente (por meio da API Layer).
Observe que as leituras não adquirem bloqueios em transações somente leitura. E, como as leituras podem ser atendidas por qualquer réplica atualizada de uma determinada divisão, o potencial de capacidade de leitura do sistema é muito alto. Se o cliente é capaz de tolerar leituras que estejam pelo menos 10 segundos desatualizadas, a capacidade de leitura pode ser ainda maior. Como o líder normalmente atualiza as réplicas com o carimbo de data/hora seguro mais recente a cada 10 segundos, as leituras em um carimbo de data/hora desatualizado podem evitar um RPC extra ao líder.
Conclusão
Tradicionalmente, designers de sistemas de banco de dados distribuídos descobriram que garantias transacionais fortes são caras, devido a toda a comunicação necessária entre as máquinas. Com o Spanner, nos concentramos em reduzir o custo das transações para torná-las viáveis em escala e independentemente da distribuição. Uma das principais razões para isso é o TrueTime, que reduz a comunicação entre máquinas a muitos tipos de coordenação. Além disso, uma engenharia cuidadosa e o ajuste de desempenho resultaram em um sistema de alta performance mesmo quando oferece garantias fortes. No Google, descobrimos que isso facilitou de maneira significativa o desenvolvimento de aplicativos no Spanner em comparação a outros sistemas de banco de dados com garantias mais fracas. Quando os desenvolvedores de aplicativos não precisam se preocupar com disputas ou inconsistências nos dados, eles podem se concentrar no que importa de verdade: a criação e a entrega de aplicativos excelentes.