Client
Spanner est compatible avec les requêtes SQL. Voici un exemple de requête :
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
La construction @firstName fait référence à un paramètre de requête. Vous pouvez utiliser un paramètre de requête partout où une valeur littérale peut être utilisée. Il est fortement recommandé d'utiliser des paramètres dans les API de programmation. Ces paramètres de requête permettent d'éviter les attaques par injection SQL et les requêtes qui en résultent sont plus susceptibles de béneficier de diverses mises en cache côté serveur. Reportez-vous à la section Mise en cache ci-dessous.
Les paramètres de requête doivent être liés à une valeur lors de l'exécution de la requête. Exemple :
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Une fois que Spanner reçoit un appel d'API, il analyse la requête et les paramètres liés pour déterminer quel nœud de serveur Spanner doit traiter la requête. Le serveur renvoie un flux de lignes de résultats utilisées par les appels de l'API ResultSet.next().
Exécution de la requête
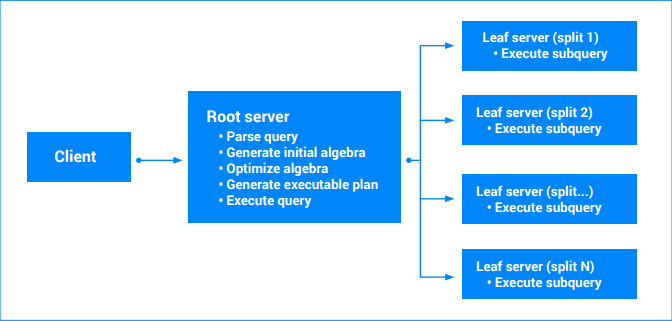
L'exécution d'une requête commence par l'arrivée d'une requête "exécuter une requête" sur un serveur Spanner. Le serveur effectue les étapes suivantes :
- Valider la demande
- Analyser le texte de la requête
- Générer une algèbre de requête initiale
- Générer une algèbre de requête optimisée
- Générer un plan de requête exécutable
- Exécuter le plan (vérifier les autorisations, lire les données, encoder les résultats, etc.)
Analyse
L'analyseur SQL analyse le texte de la requête et le convertit en un arbre syntaxique abstrait. Il extrait la structure de requête de base (SELECT …
FROM … WHERE …) et effectue des vérifications syntaxiques.
Algèbre
Le système de types de Spanner peut représenter des scalaires, des tableaux, des structures, etc. L'algèbre de requête définit des opérateurs pour l'analyse de tables, le filtrage, le tri/regroupement, toutes sortes de jointures, l'agrégation, etc. L'algèbre de requête initiale est construite à partir du résultat de l'analyseur. Les références de nom de champ dans l'arbre d'analyse sont résolues à l'aide du schéma de base de données. Ce code vérifie également les erreurs sémantiques (par exemple, un nombre incorrect de paramètres, une incohérence dans les types, etc.).
L'étape suivante ("optimisation de la requête") permet de générer une algèbre optimale à partir de l'algèbre initiale. Cette algèbre peut être plus simple, plus efficace ou tout simplement plus adaptée aux capacités du moteur d'exécution. Par exemple, l'algèbre optimale peut spécifier une "jointure de hachage" là où une algèbre initiale n'aurait spécifié qu'une simple "jointure".
Exécution
Le plan de requête exécutable final est construit à partir de l'algèbre réécrite. Le plan exécutable est un graphe acyclique dirigé par des "itérateurs". Chaque itérateur expose une séquence de valeurs. Les itérateurs peuvent consommer des entrées pour produire des sorties (par exemple, les itérateurs de tri). Les requêtes impliquant une seule division peuvent être exécutées par un seul serveur (celui qui contient les données). Le serveur analyse les plages de différentes tables, exécute les jointures, réalise l'agrégation ainsi que toutes les autres opérations définies par l'algèbre de requête.
Les requêtes impliquant plusieurs partitions sont prises en compte dans plusieurs parties. Une partie de la requête continue à être exécutée sur le serveur principal (racine). D'autres parties de la requête sont transmises aux nœuds feuilles (les nœuds qui possèdent les partitions en cours de lecture). Ce transfert peut être appliqué de manière récursive pour les requêtes complexes, ce qui génère une arborescence d'exécutions de serveur. Tous les serveurs s'accordent sur un horodatage pour que les résultats de la requête constituent un instantané cohérent des données. Chaque serveur de cette arborescence renvoie un flux de résultats partiels. Pour les requêtes impliquant une agrégation, il peut s'agir de résultats partiellement agrégés. Le serveur de requête racine traite les résultats des serveurs de l'arborescence et exécute le reste du plan de requête. Pour en savoir plus, consultez la section Plans d'exécution de requêtes.
Lorsqu'une requête implique plusieurs divisions, Spanner peut l'exécuter en parallèle sur l'ensemble des divisions. Le degré de parallélisme dépend de la plage de données analysée par la requête, du plan d'exécution de la requête et de la distribution des données entre les divisions. Spanner définit automatiquement le degré maximal de parallélisme d'une requête en fonction de la taille de son instance et de la configuration de l'instance (régionale ou multirégionale) afin d'optimiser les performances des requêtes et d'éviter de surcharger le processeur.
Mise en cache
La plupart des artefacts du traitement des requêtes sont automatiquement mis en cache et réutilisés pour les requêtes suivantes. Cela inclut entre autres les algèbres de requête et les plans de requête exécutables. La mise en cache est basée sur le texte de la requête, les noms et les types de paramètres liés, et d'autres informations. C'est pourquoi l'utilisation de paramètres de liaison (tels que @firstName dans l'exemple ci-dessus) est préférable à l'utilisation de valeurs littérales dans le texte de la requête. Le premier peut être mis en cache une fois et réutilisé quelle que soit la valeur liée réelle. Pour en savoir plus, consultez la page Optimiser les performances de requête Spanner.
Gestion des exceptions
Le flux de lignes de résultats provenant de la méthode executeQuery peut être interrompu pour plusieurs raisons: erreurs réseau temporaires, transfert d'une partition d'un serveur à un autre (par exemple, équilibrage de charge), redémarrage du serveur (par exemple, mise à niveau vers une nouvelle version), etc. Afin de faciliter la récupération de ces erreurs, Spanner envoie des "jetons de reprise" opaques avec des lots de données de résultats partielles. Ces jetons de reprise peuvent être utilisés lors d'une nouvelle tentative de requête afin de poursuivre là où la requête interrompue s'est arrêtée. Si vous utilisez les bibliothèques clientes Spanner, cette opération s'effectue automatiquement. Ainsi, les utilisateurs de la bibliothèque cliente n'ont pas à se soucier de ce type d'échec temporaire.