借助查询计划可视化工具,您可以快速了解 Spanner 为评估查询而选择的查询计划的结构。本指南介绍了如何使用查询计划来帮助您了解查询的执行情况。
准备工作
如需熟悉本指南中提及的 Google Cloud 控制台界面的各个部分,请阅读以下内容:
在 Google Cloud 控制台中运行查询
- 转到 Google Cloud 控制台中的 Spanner 实例页面。
-
选择包含您要查询的数据库的实例的名称。
Google Cloud 控制台会显示该实例的概览页面。
-
选择要查询的数据库的名称。
Google Cloud 控制台会显示该数据库的概览页面。
-
在侧边菜单中,点击 Spanner Studio。
Google Cloud 控制台会显示数据库的 Spanner Studio 页面。
- 在编辑器窗格中输入 SQL 查询。
-
点击运行。
Spanner 运行查询。
- 点击说明标签页以查看查询计划可视化。
浏览查询编辑器
Spanner Studio 页面提供了一些查询标签页,您可以在其中输入或粘贴 SQL 查询和 DML 语句、对数据库运行这些语句,以及查看其结果和查询执行计划。在下面的屏幕截图中,Spanner Studio 页面的关键组成部分编号如下。
- 标签页栏显示您已打开的查询标签页。如需创建新标签页,请点击新标签页。
标签页栏还提供查询模板您可以粘贴查询,以提供有关数据库查询、事务、读取等方面的数据分析,如内省工具概览。
- 编辑器命令栏提供以下选项:
- 运行命令会执行修改窗格中输入的语句,在结果标签页中生成查询结果,并在说明标签页中生成查询执行计划。使用下拉菜单更改默认行为,以生成仅结果或仅说明。
在编辑器中突出显示某些内容会将运行命令更改为运行选定项,从而允许您仅执行您选择的内容。
- 清除查询命令会删除编辑器中的所有文本,并清除结果和说明子标签页。
- 格式设置查询格式命令会设置编辑器中的语句格式,以使它们更易于阅读。
- 快捷键命令会显示可用于编辑器的键盘快捷键集。
- 点击 SQL 查询帮助链接后,系统会打开一个浏览器标签页,其中提供了有关 SQL 查询语法的文档。
每当编辑器中更新查询时,都会自动对其进行验证。如果语句有效,编辑器命令栏将显示确认对勾标记和有效消息。如果出现任何问题,它会显示包含详细信息的错误消息。
- 运行命令会执行修改窗格中输入的语句,在结果标签页中生成查询结果,并在说明标签页中生成查询执行计划。使用下拉菜单更改默认行为,以生成仅结果或仅说明。
- 您可以在编辑器中输入 SQL 查询和 DML 语句。这些查询会用颜色标记,系统会自动为多行语句添加行号。
在编辑器中输入多个语句时,您必须在最后一个语句之后使用终止分号。
- 查询标签页的底部窗格提供三个子标签页:
- 架构子标签页会显示数据库中的表及其架构。在编辑器中编写语句时,请快速参考。
- 结果子标签页显示在编辑器中运行语句时结果。对于查询,它会显示结果表;对于
INSERT和 >UPDATE等 DML 语句,它会显示有关受影响的行数的消息。 - 说明子标签页会显示您在编辑器中运行语句时创建的查询计划的直观图表。
- 结果和说明子标签都提供了一个语句选择器,可用于选择您要查看的语句结果或查询计划。
查看抽样查询计划
- 转到 Google Cloud 控制台中的 Spanner 实例页面。
-
点击包含您要调查的查询的实例的名称。
Google Cloud 控制台会显示该实例的概览页面。
-
在导航菜单中的“可观测性”标题下,点击查询数据分析。
Google Cloud 控制台会显示该实例的查询数据分析页面。
-
在数据库下拉菜单中,选择要调查的查询所在的数据库。
Google Cloud 控制台会显示该数据库的查询负载信息。“排名前 N 的查询和标记”表格显示按 CPU 利用率排序的热门查询和请求标记列表。
-
找到您要查看抽样查询计划的 CPU 利用率高的查询。点击该查询的 FPRINT 值。
查询详情页面会显示一段时间内的查询的查询计划样本图表。您可以缩小到当前时间之前最多七天。注意:如果查询具有从 SectionQuery API 和分区 DML 查询获取的分区令牌,则不支持查询计划。
-
点击图表中的某个点可查看较旧的查询计划,并直观呈现查询执行期间采取的步骤。您还可以点击任何运算符,以查看关于相应运算符的展开信息。
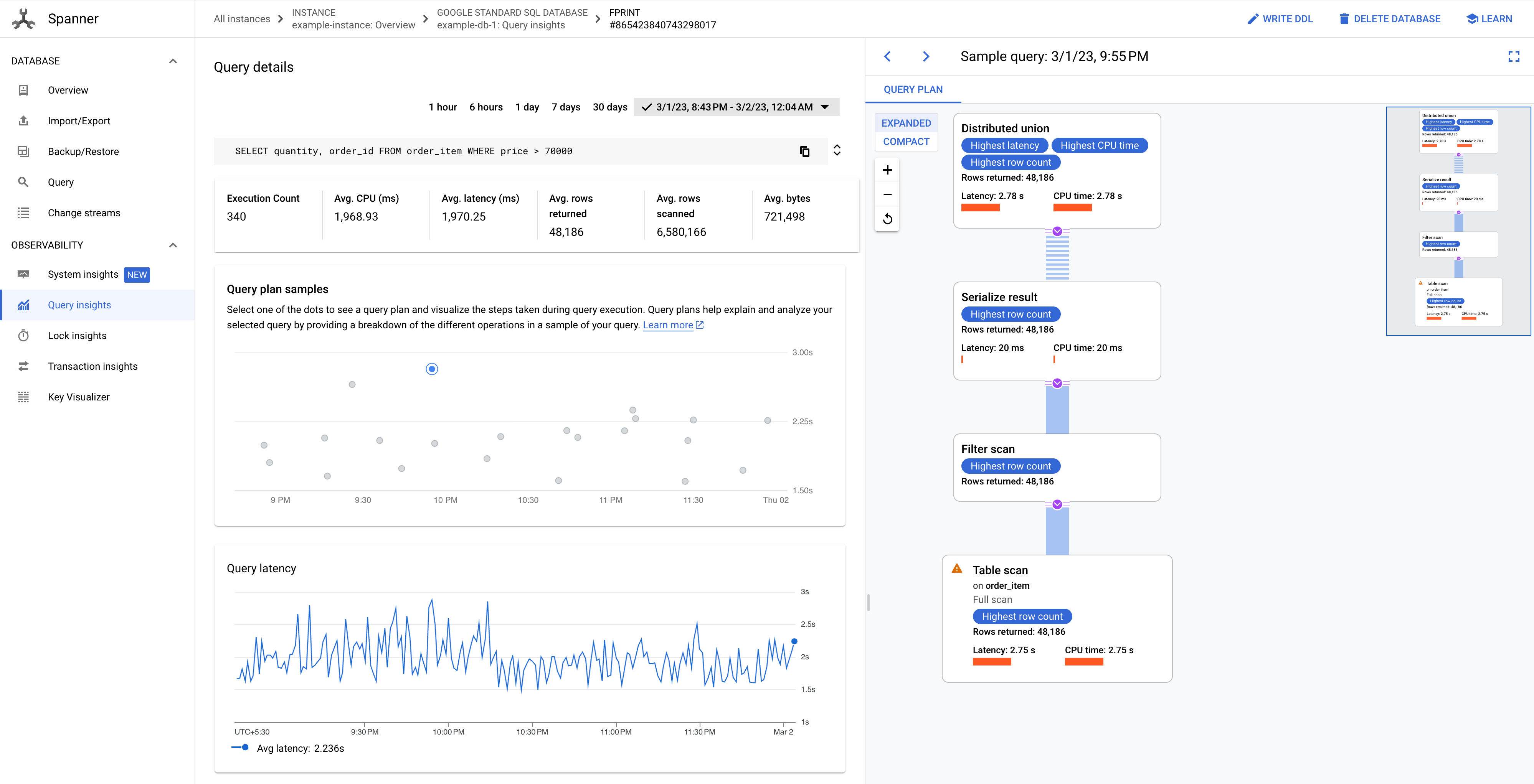
图 8. 查询计划示例图表。
在某些情况下,您可能需要查看抽样查询计划,并比较查询在一段时间内的性能。对于占用较高 CPU 的查询,Spanner 会在 Google Cloud 控制台的查询数据分析页面上保留采样查询计划 30 天。如需查看抽样查询计划,请执行以下操作:
探索查询计划可视化工具
以下屏幕截图中标注了可视化工具的主要组件,并详细地进行了说明。在查询标签页中运行查询后,选择查询编辑器下方的说明标签页,以打开查询执行计划可视化工具。
下图中的数据流是自下而上的,也就是说,所有表和索引都位于图底部,最终输出位于顶部。
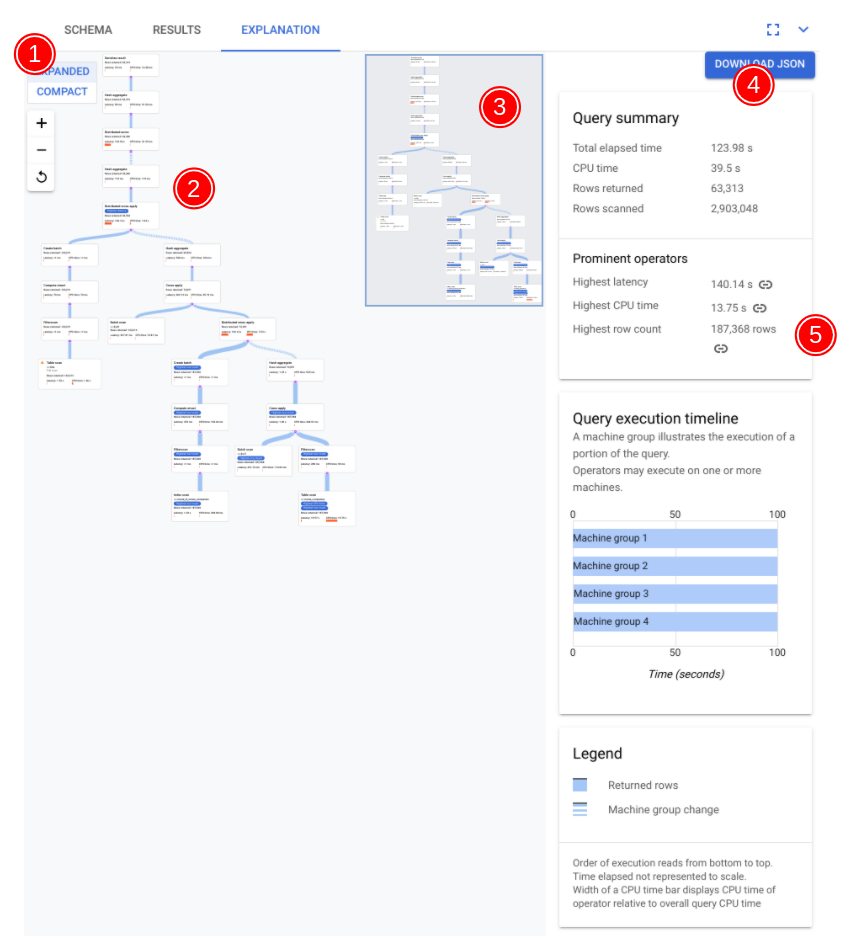
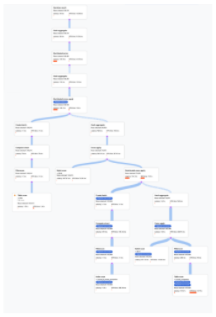
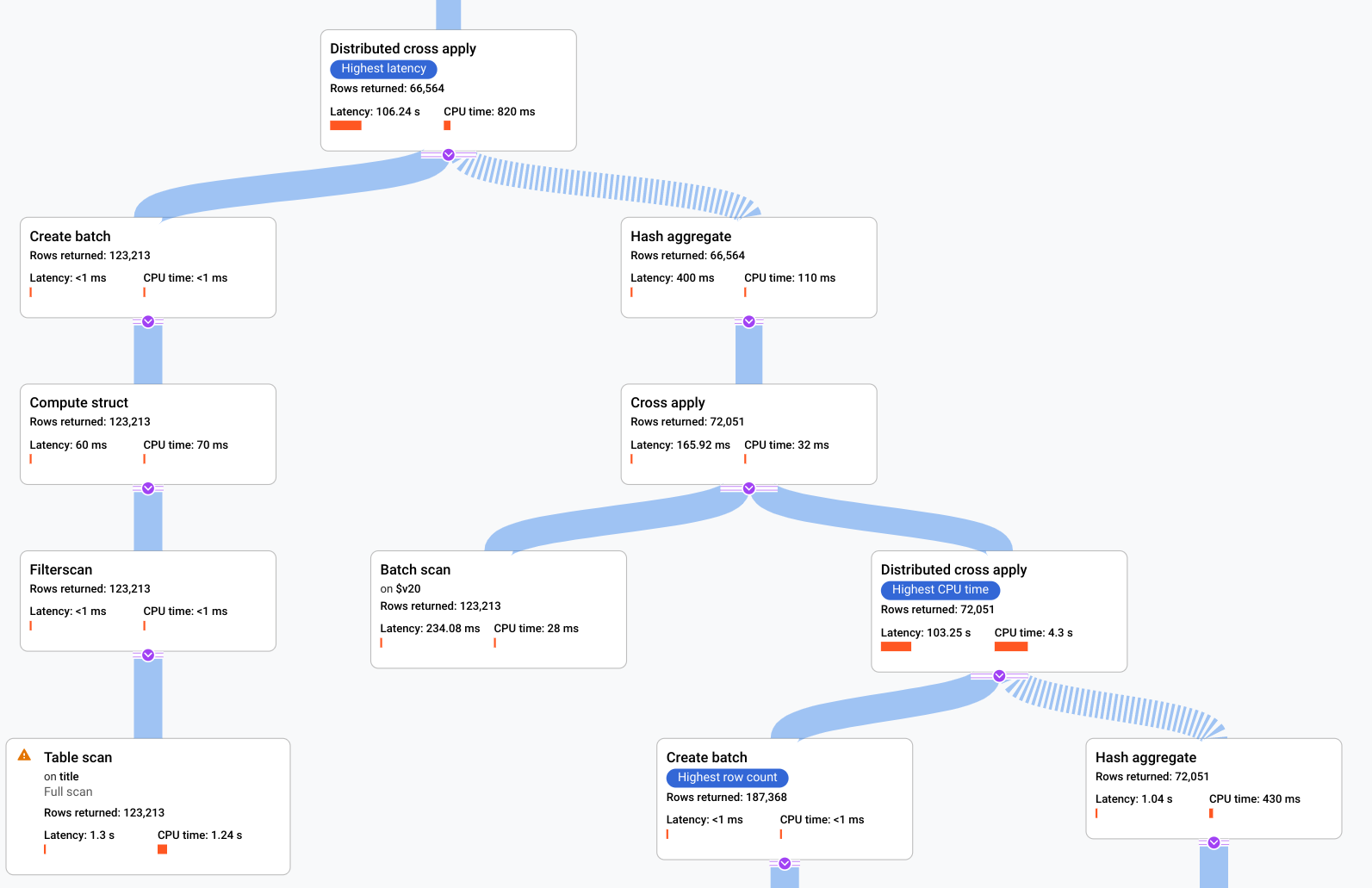
图表上的每个节点(或卡片)表示迭代器并包含以下信息:
- 迭代器名称。迭代器会使用其输入中的行并生成行。
- 运行时统计信息会显示返回的行数、延迟和消耗的 CPU 量。
- 我们提供了以下可视化提示,以帮助您识别查询执行计划中的潜在问题。
- 节点中的红色条表示此迭代器的延迟时间或 CPU 时间占查询总时间的百分比。
- 连接每个节点的线的厚度表示行数。线越粗,传递给下一个节点的行数越大。当您将指针悬停在连接器上时,每张卡片中都会显示实际行数。
- 已执行全表扫描的节点上会显示一个警告三角形。信息面板中的更多详细信息包括为了避免完全扫描提出的建议(例如添加索引,或者以其他方式修改查询或架构)。
- 在方案中选择一张卡片,请查看右侧信息面板 (5) 中的详细信息。
- 迭代器信息可提供您在图表中选择的迭代器卡的详细信息和运行时统计信息。
- 查询摘要详细说明了返回的行数以及运行查询所需的时间。突出的运算符是表现出大量延迟时间、消耗大量 CPU(相对于其他运算符)并返回大量数据行的运算符。
- 查询执行时间轴是基于时间的图表,显示每个机器组运行其查询部分的时长。机器组不一定在查询的整个运行期间始终运行。机器组也有可能会在运行查询期间多次运行,但此处的时间轴仅表示首次运行机器组的开始时间以及最后一次运行机器组的结束时间。
调整表现不佳的查询
想象一下,您的公司运行一个在线电影数据库,其中包含有关电影(如演员表、制片公司、电影详细信息等)的信息。该服务在 Spanner 上运行,但最近遇到了一些性能问题。
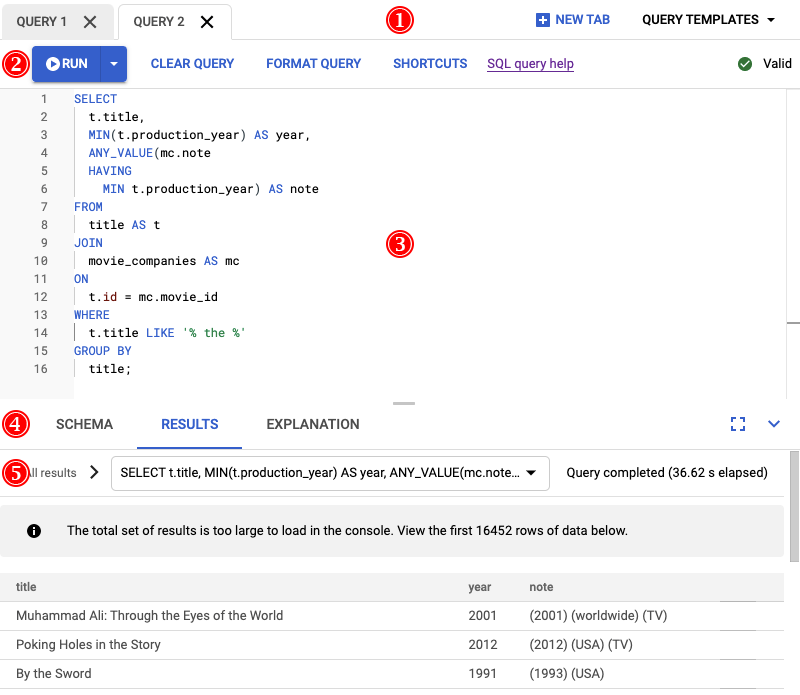
作为该服务的首席开发者,您需要调查这些性能问题,因为这些问题会导致对服务的评分不佳。打开 Google Cloud 控制台,转到您的数据库实例,然后打开查询编辑器。在编辑器中输入以下查询并运行它。
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
运行此查询的结果如以下屏幕截图所示。我们通过选择设置查询格式在编辑器中设置了查询的格式。屏幕右上角还有一个备注,表明查询有效。
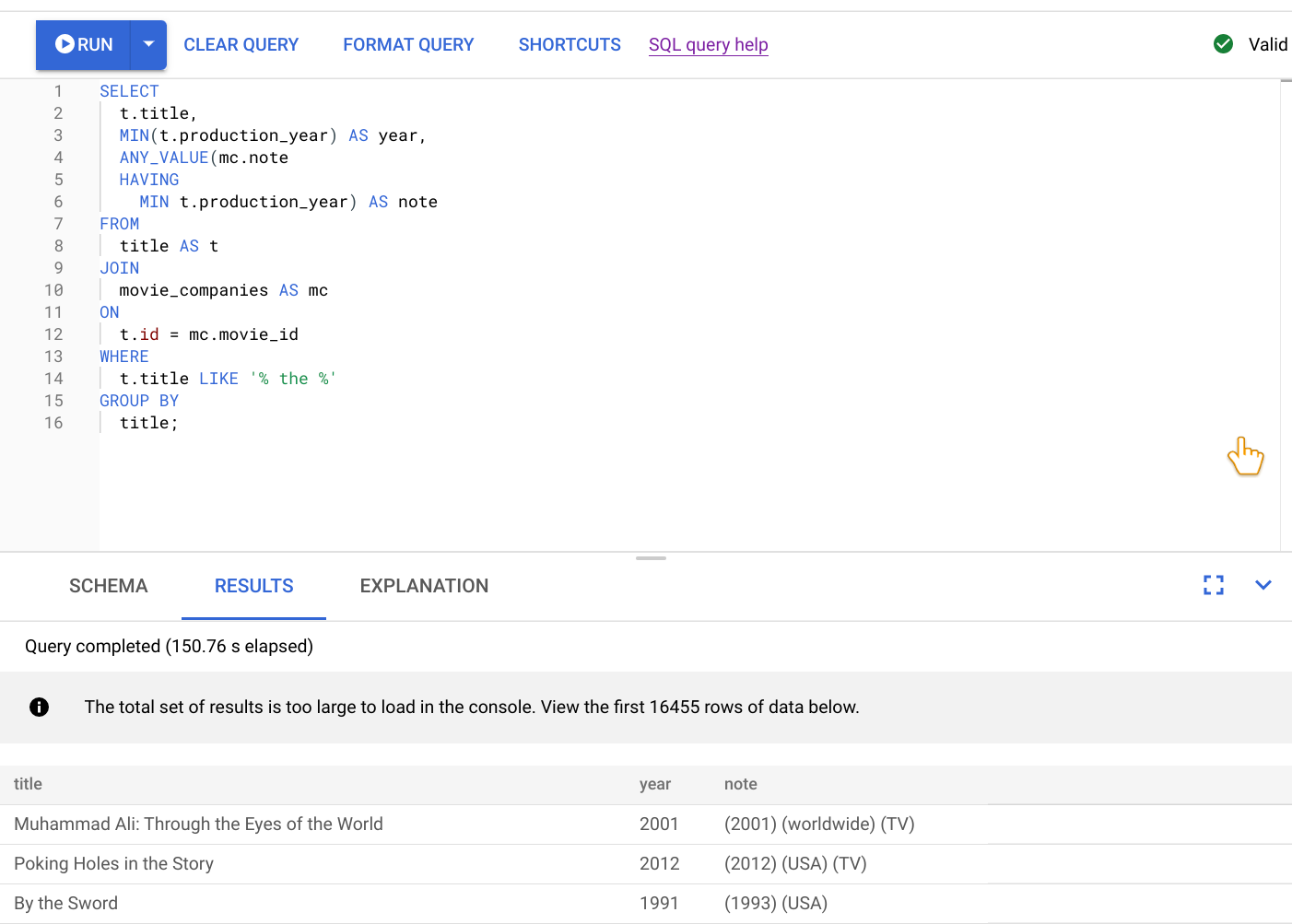
查询编辑器下方的结果标签页显示查询仅在两分钟内完成。您决定进一步查看该查询,确认该查询是否有效。
使用查询计划可视化工具分析慢查询
此时,我们知道上一步中的查询需要花费两分钟以上,但不知道该查询是否尽可能高效,因此不知道此持续时间是否符合预期。
您可以选择查询编辑器正下方的说明标签页,以直观的方式查看 Spanner 为运行查询并返回结果而创建的执行计划。
以下屏幕截图中显示的计划相对较大,但即使在此缩放比例下,您也可以进行以下观察。
根据右侧信息面板中的查询摘要,我们了解到已扫描近 300 万行,最终返回了 6 万 4 千行。
我们还可以从查询执行时间轴面板中看到该查询涉及了 4 个机器组。部分查询由机器组负责执行。运算符可以在一台或多台机器上执行。在时间轴中选择某个机器组会突出显示可视化计划中对该组执行的查询部分。
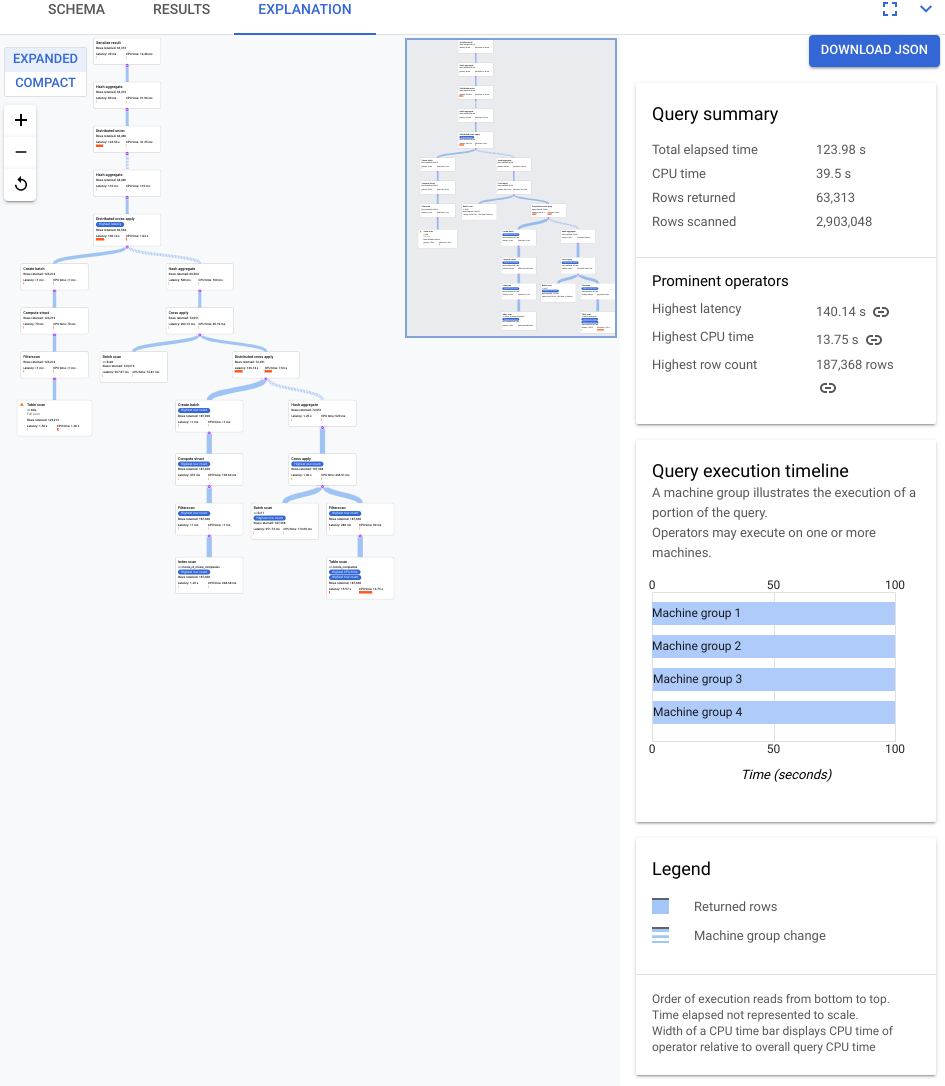
鉴于这些因素,您决定将联接从 Spanner 默认选择的应用联接更改为哈希联接,从而提高性能。
改进查询
要提升查询的性能,可使用联接提示将联接方法更改为哈希联接。此联接实现会执行基于集合的处理。
更新后的查询如下所示:
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
以下屏幕截图展示了更新后的查询。如屏幕截图所示,查询在 5 秒钟内完成,这项更改显著缩短了 120 秒的运行时间。
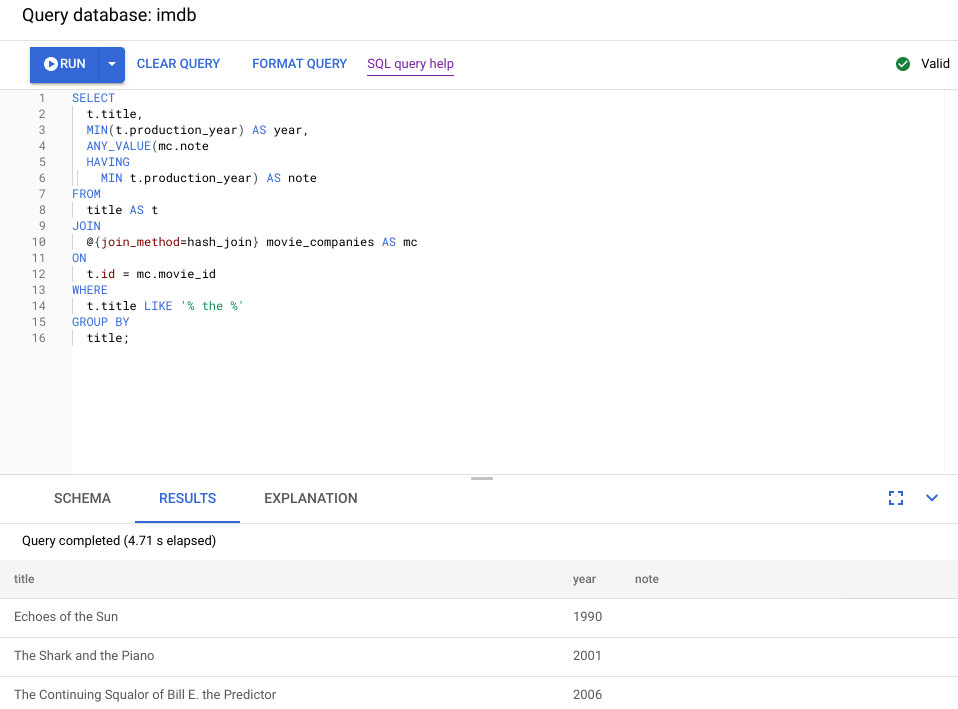
仔细查看下图中所示的新直观计划,了解它传达的信息关于这项改进的信息。
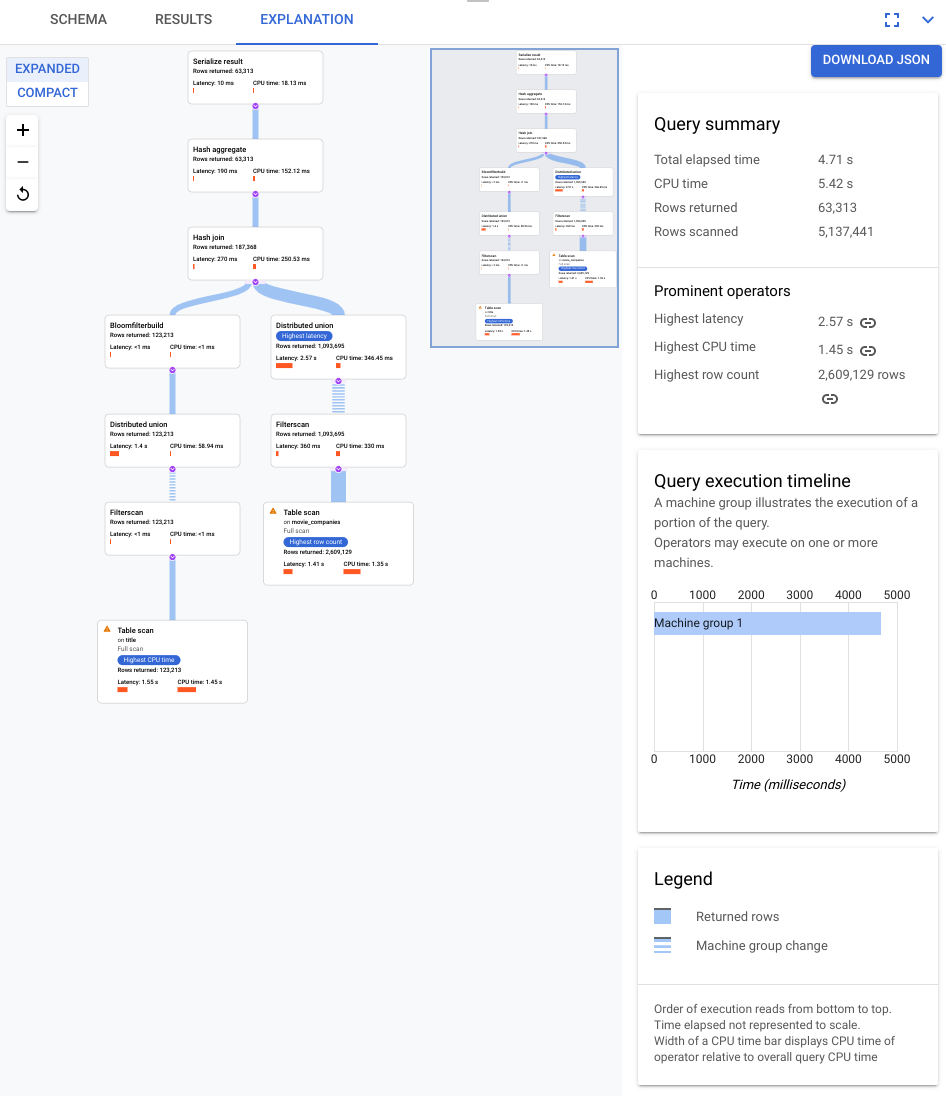
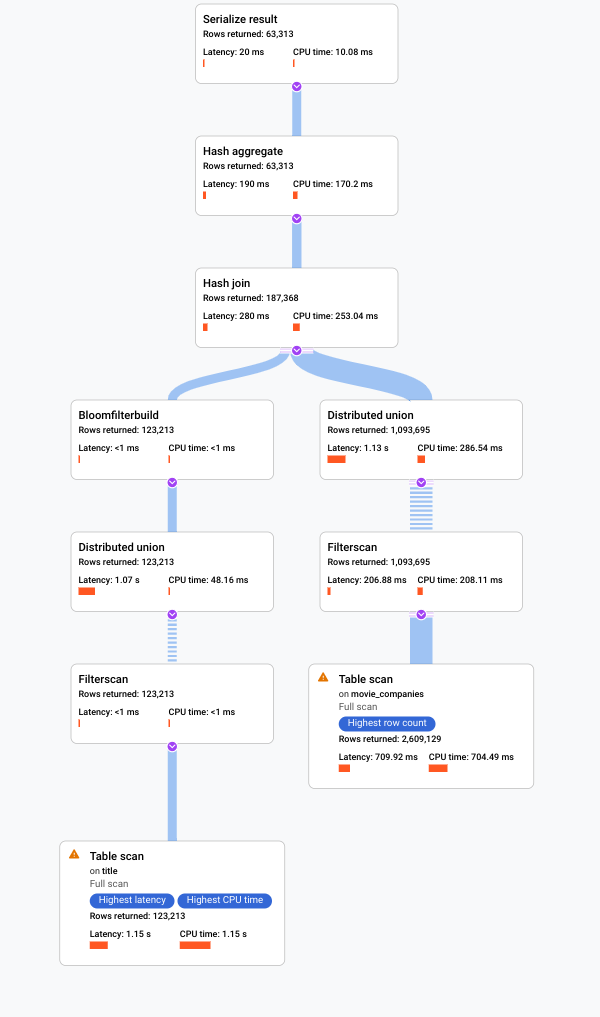
您马上就会注意到一些区别:
此查询执行仅涉及一个机器组。
汇总数量已大幅减少。
总结
在此场景中,我们运行了一个慢查询,并观察其可视化计划以查找低效环节。下面汇总了在进行任何更改前后执行的查询和计划。每个标签页都会显示正在运行的查询和完整查询执行计划可视化的紧凑视图。
早于
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
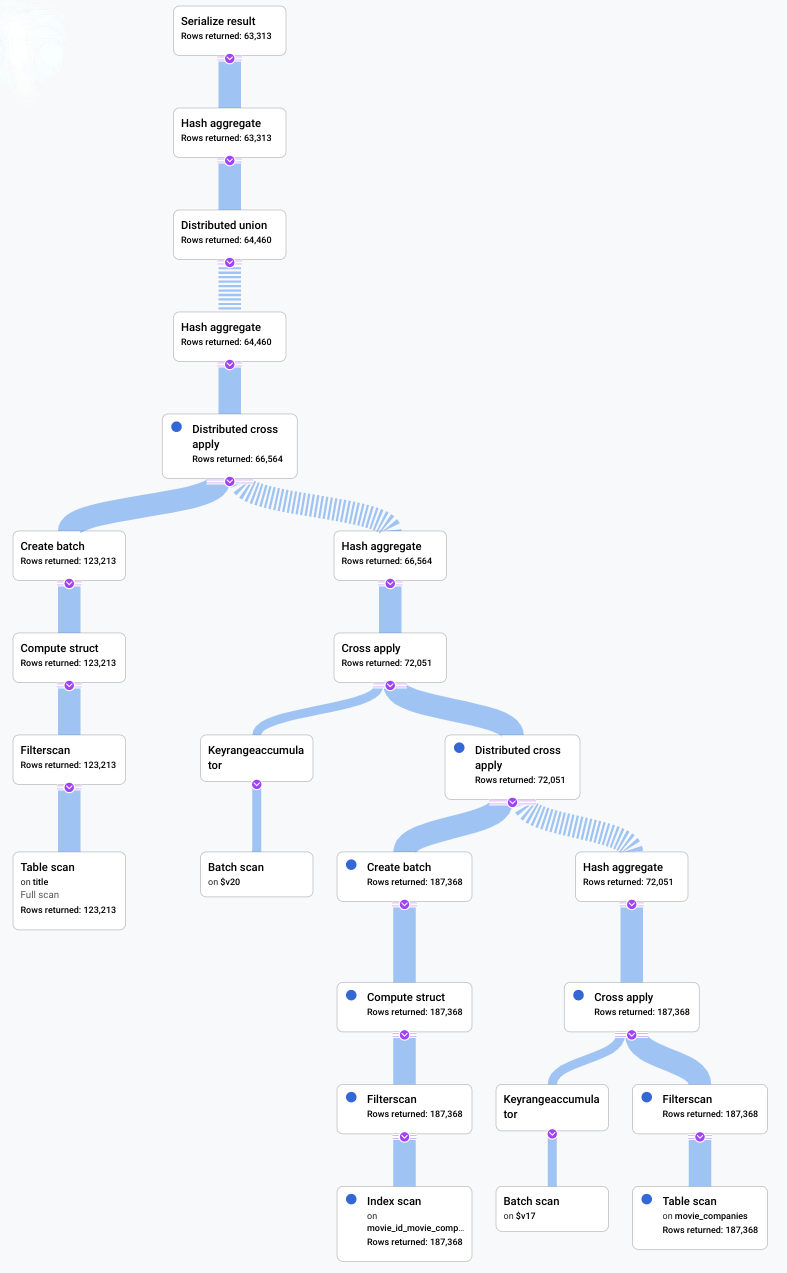
升级后
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
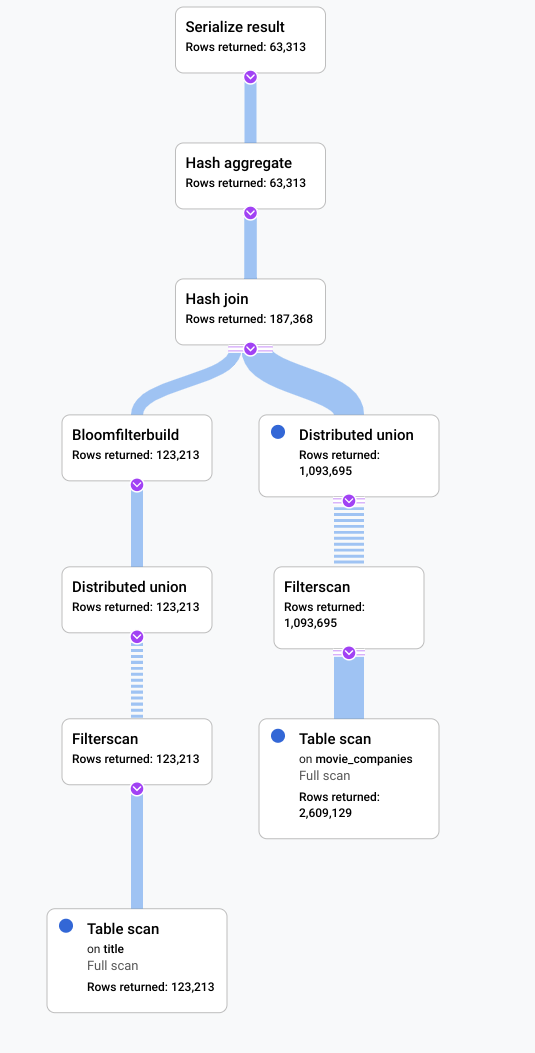
表明此场景中有待改进的指示是表 title 中有很大一部分行符合过滤条件 LIKE
'% the %' 的条件。查找具有这么多行的其他表可能费用非常高。将联接实现更改为哈希联接显著提升了性能。