Quando você usa consultas SQL para pesquisar dados, o Spanner usa automaticamente todos os índices secundários que provavelmente ajudarão a recuperar os dados de maneira mais eficiente. Em alguns casos, no entanto, o Spanner pode escolher um índice que torna as consultas mais lentas. Como resultado, é possível notar que algumas consultas são executadas mais lentamente do que eram executadas no passado.
Esta página explica como detectar alterações na velocidade de execução da consulta. Inspecione o plano de execução da consulta para essas consultas e especifique um índice diferente para consultas futuras, se necessário.
Detecta alterações na velocidade de execução da consulta
É mais provável que você veja uma alteração na velocidade de execução da consulta depois de fazer uma destas alterações:
- Alterar significativamente uma grande quantidade de dados existentes que têm um índice secundário.
- Como adicionar, alterar ou descartar um índice secundário.
É possível usar várias ferramentas diferentes para identificar uma consulta específica que o Spanner está executando mais lentamente que o normal:
- Insights de consulta e Estatísticas de consulta.
Métricas específicas do aplicativo que você captura e analisa com o Cloud Monitoring. Por exemplo, é possível monitorar a métrica Contagem de consultas para determinar o número de consultas em uma instância ao longo do tempo. Descubra qual versão do otimizador de consultas foi usada na execução. uma consulta.
Ferramentas de monitoramento do lado do cliente que medem o desempenho do seu aplicativo.
Uma observação sobre novos bancos de dados
Ao consultar bancos de dados recém-criados com dados recém-inseridos ou importados, o Spanner pode não selecionar os índices mais apropriados, porque o otimizador de consultas leva até três dias para coletar estatísticas do otimizador automaticamente. Para otimizar o uso do índice de um novo banco de dados do Spanner antes disso, é possível criar manualmente um novo pacote de estatísticas.
Analisar o esquema
Depois de localizar a consulta que ficou mais lenta, observe a instrução SQL da consulta e identifique as tabelas usadas pela instrução e as colunas que ela recupera dessas tabelas.
Em seguida, encontre os índices secundários que existem para essas tabelas. Determine se algum dos índices inclui as colunas que você está consultando, o que significa que o Spanner pode usar um dos índices para processar a consulta.
- Se houver índices aplicáveis, a próxima etapa é encontrar o índice que o Spanner usou para a consulta.
Se não houver índices aplicáveis, use o comando
gcloud spanner operations listpara verificar se você descartou recentemente um índice aplicável:gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"Se você descartou um índice aplicável, essa alteração pode ter afetado o desempenho da consulta. Adicione o índice secundário de volta à tabela. Depois que o Spanner adicionar o índice, execute a consulta novamente e analise o desempenho. Se o desempenho não melhorar, a próxima etapa é encontrar o índice que o Spanner usou para a consulta.
Se você não descartou um índice aplicável, a seleção do índice não causou o retorno do desempenho da consulta. Procure outras alterações nos seus dados ou padrões de uso que possam ter afetado o desempenho.
Encontrar o índice usado para uma consulta
Para descobrir qual índice o Spanner está usando para processar uma consulta, consulte o plano de execução da consulta no console do Google Cloud:
Acesse a página Instâncias do Spanner no console do Google Cloud.
Clique no nome da instância que você quer consultar.
No painel esquerdo, clique no banco de dados que você quer consultar e selecione Spanner Studio.
Insira a consulta a ser testada.
Na lista suspensa Executar consulta, selecione Apenas explicação. O Spanner exibe o plano de consulta.
Procure pelo menos um dos seguintes operadores no plano de consulta:
- Verificação de tabela
- Verificação de índice
- Aplicar cruzada ou distribuição distribuída cruzada
As seções a seguir explicam o significado de cada operador.
Operador de verificação da tabela
O operador de verificação de tabela indica que o Spanner não usou um índice secundário:
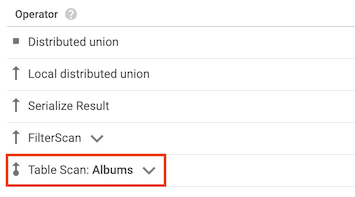
Por exemplo, suponha que a tabela Albums não tenha índices secundários e você execute a seguinte consulta:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
Como não há índices a serem usados, o plano de consulta inclui um operador de verificação de tabela.
Operador de verificação de índice
O operador de verificação de índice indica que o Spanner usou um índice secundário quando processou a consulta:
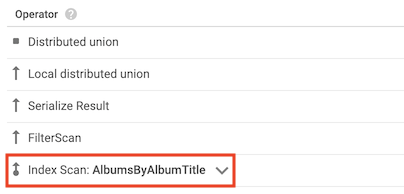
Por exemplo, suponha que você adicione um índice à tabela Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Em seguida, execute a seguinte consulta:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
O índice AlbumsByAlbumTitle contém AlbumTitle, que é a única coluna que a consulta seleciona. Como resultado, o plano de consulta inclui um operador de verificação de índice.
operador cross apply
Em alguns casos, o Spanner usa um índice que contém apenas algumas das colunas selecionadas pela consulta. Como resultado, o Spanner precisa mesclar o índice com a tabela base.
Quando esse tipo de junção ocorre, o plano de consulta inclui um operador de aplicação cruzada ou operação cruzada aplicada que tenha as seguintes entradas:
- Um operador de verificação de índice para o índice de uma tabela
- Um operador de verificação de tabela para a tabela que tem o índice
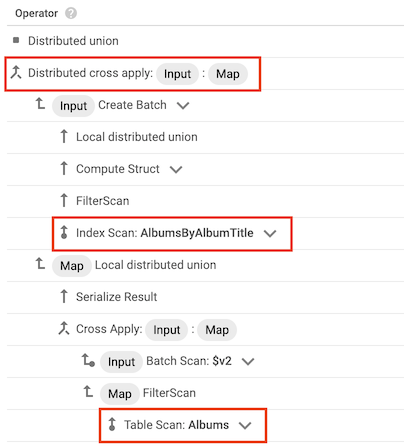
Por exemplo, suponha que você adicione um índice à tabela Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Em seguida, execute a seguinte consulta:
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
O índice AlbumsByAlbumTitle contém AlbumTitle, mas a consulta seleciona todas as colunas na tabela, não apenas AlbumTitle. Como resultado, o plano de consulta inclui um operador de aplicação cruzada distribuída, com uma verificação de índice de AlbumsByAlbumTitle e uma verificação de tabela de Albums como suas entradas.
Escolher um índice diferente
Depois de encontrar o índice que o Spanner usou para sua consulta, tente executar a consulta com um índice diferente ou verificando a tabela base em vez de usar um índice. Para especificar o índice, adicione uma diretiva FORCE_INDEX à consulta.
Se você encontrar uma versão mais rápida da consulta, atualize seu aplicativo para usar a versão mais rápida.
Diretrizes para escolher um índice
Use estas diretrizes para decidir qual índice testar para a consulta:
Se sua consulta atender a algum desses critérios, tente usar a tabela base em vez de um índice secundário:
- A consulta verifica a igualdade com um prefixo da chave primária da tabela base (por exemplo,
SELECT * FROM Albums WHERE SingerId = 1). - Um grande número de linhas satisfaz os predicados de consulta (por exemplo,
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title"). - A consulta usa uma tabela base que contém apenas algumas centenas de linhas.
- A consulta verifica a igualdade com um prefixo da chave primária da tabela base (por exemplo,
Se a consulta contiver um predicado muito seletivo (por exemplo,
REGEXP_CONTAINS,STARTS_WITH,<,<=,>,>=ou!=), tente usando um índice que inclua as mesmas colunas usadas no predicado.
Testar a consulta atualizada
Use o console do Google Cloud para testar a consulta atualizada e descobrir quanto tempo leva para processá-la.
Se sua consulta incluir parâmetros de consulta e um parâmetro de consulta estiver vinculado a alguns valores muito mais frequentemente do que outros, vincule o parâmetro de consulta a um desses valores nos testes. Por exemplo, se a consulta incluir um predicado como WHERE country = @countryId e quase todas as consultas vincular @countryId ao valor US, vincule @countryId a US para seus testes de desempenho. Essa abordagem ajuda você a otimizar para as consultas que são executadas com mais frequência.
Para testar a consulta atualizada no console do Google Cloud, siga estas etapas:
Acesse a página Instâncias do Spanner no console do Google Cloud.
Clique no nome da instância que você quer consultar.
No painel esquerdo, clique no banco de dados que você quer consultar e selecione Spanner Studio.
Insira a consulta a ser testada, incluindo a diretiva
FORCE_INDEXe clique em Executar consulta.O console do Google Cloud abre a guia Resultados e mostra os resultados da consulta, incluindo quanto tempo o serviço do Spanner levou para processá-la.
Essa métrica não inclui outras fontes de latência, como o tempo que o console do Google Cloud levou para interpretar e exibir os resultados da consulta.
Obtenha o perfil detalhado de uma consulta no formato JSON usando a API REST
Por padrão, somente os resultados da instrução são retornados quando você executa uma consulta.
Isso ocorre porque QueryMode está definido como NORMAL.
Para incluir estatísticas detalhadas de execução com os resultados da consulta, defina QueryMode como PROFILE.
Criar uma sessão
Antes de atualizar o modo de consulta, crie uma sessão que represente um canal de comunicação com o serviço de banco de dados do Spanner.
- Clique em
projects.instances.databases.sessions.create. Forneça os códigos projeto, instância e banco de dados no seguinte formato:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]Clique em Executar. A resposta mostra a sessão que você criou neste formulário:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]Você o usará para executar o perfil de consulta na próxima etapa. A sessão criada ficará ativa por no máximo uma hora entre usos consecutivos antes de ser excluída pelo banco de dados.
Definir o perfil da consulta
Habilitar PROFILE para a consulta.
- Clique em
projects.instances.databases.sessions.executeSql. Para sessão, insira o código da sessão criado na etapa anterior:
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]Para o Corpo de solicitação, use o seguinte:
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }Clique em Executar. A resposta retornada incluirá os resultados da consulta, plano de consulta e as estatísticas de execução da consulta.