En esta página, se describe la capacidad de procesamiento de Spanner y las dos unidades de medida usadas para cuantificarla: nodos y unidades de procesamiento.
Capacidad de procesamiento
La capacidad de procesamiento define la cantidad de recursos de servidor y almacenamiento que están disponibles para las bases de datos en una instancia. Cuando creas una instancia, especificas su capacidad de procesamiento como una cantidad de unidades de procesamiento o como una cantidad de nodos, con 1,000 unidades de procesamiento iguales a 1 nodo.
La unidad de medida que uses no importa, a menos que crees una instancia cuya capacidad de procesamiento sea menor que 1,000 unidades de procesamiento (1 nodo); en este caso, debes usar unidades de procesamiento para especificar la capacidad de procesamiento de la instancia.
Cuando defines o cambias la capacidad de procesamiento en una instancia, especificas unidades de procesamiento en múltiplos de 100 (100, 200, 300, etc.). Cuando la cantidad de unidades de procesamiento alcanza las 1,000, puedes especificar cantidades más grandes como múltiplos de 1,000 unidades de procesamiento (1,000, 2,000, 3,000, etc.) o como nodos (1, 2, 3 y así sucesivamente).
Las instancias con menos de 1, 000 unidades de procesamiento se compilan para tamaños de datos, consultas y cargas de trabajo más pequeños. Tienen recursos de procesamiento limitados y eso puede generar escalamiento y rendimiento no lineales para algunas cargas de trabajo, y es posible que experimente aumentos intermitentes en las latencias.
Límites de almacenamiento de datos
Como se detalla en Cuotas y límites, a fin de proporcionar alta disponibilidad y baja latencia cuando se accede a una base de datos, Spanner usa la capacidad de procesamiento de una instancia como base para determinar los límites de almacenamiento mediante los siguientes lineamientos:
- Para instancias de menos de 1 nodo (1,000 unidades de procesamiento), Spanner asigna 409.6 GB de datos por cada 100 unidades de procesamiento en la base de datos.
- Para instancias de 1 o más nodos, Spanner asigna 4 TB de datos a cada nodo. Hay disponible una mayor capacidad de almacenamiento (10 TB por nodo) en parámetros de configuración seleccionados de instancias de Spanner regionales y multirregionales. Para obtener más información, consulta Mejoras de rendimiento y almacenamiento.
Por ejemplo, si quieres crear una instancia para una base de datos de 300 GB, puedes configurar su capacidad de procesamiento en 100 unidades de procesamiento. Esta cantidad de capacidad de procesamiento mantiene la instancia por debajo del límite hasta que el tamaño de la base de datos supere los 409.6 GB. Cuando la base de datos alcance este tamaño, deberás agregar otras 100 unidades de procesamiento para permitir que crezca. De lo contrario, Spanner podría rechazar las escrituras en la base de datos. Si deseas obtener más información, consulta Recomendaciones para el uso del almacenamiento de bases de datos.
Spanner factura por el almacenamiento que las instancias realmente usan, no por su asignación de almacenamiento total.
Rendimiento
Los valores máximos de capacidad de procesamiento de lectura y escritura que puede proporcionar una cantidad determinada de capacidad de procesamiento dependen de la configuración de la instancia, el diseño del esquema y las características del conjunto de datos. Consulta las secciones sobre el rendimiento de la configuración regional y el rendimiento de la configuración multirregional para obtener más detalles.
Usas instancias con menos de 1,000 unidades de procesamiento para tamaños de datos, consultas y cargas de trabajo más pequeños. Para cargas de trabajo más grandes, sus recursos de procesamiento limitados pueden generar escalamiento y rendimiento no lineales, con aumentos intermitentes en las latencias.
Capacidad de procesamiento y configuración de instancias
Como se describe en Configuración regional y multirregional, Spanner distribuye una instancia entre zonas de una o más regiones para proporcionar alto rendimiento y alta disponibilidad. En consecuencia, Spanner también distribuye los recursos del servidor que proporciona la capacidad de procesamiento de la instancia.
A continuación, se muestra un diagrama en el que se ilustra la distribución de los recursos del servidor.
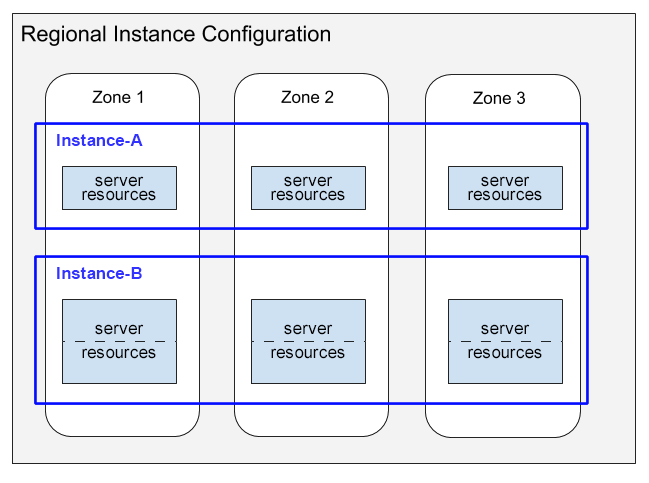
En este diagrama, se muestran dos instancias que tienen configuraciones regionales:
- En Instancia A, se muestra una instancia de 1,000 unidades de procesamiento (1 nodo) con su distribución de la capacidad de procesamiento que consume recursos del servidor en cada una de las tres zonas.
- Instance-B muestra una instancia de 2,000 unidades de procesamiento (2 nodos) con su distribución de la capacidad de procesamiento que consume recursos del servidor en cada una de las tres zonas.
Ten en cuenta lo siguiente en este diagrama:
Para cada instancia, Spanner asigna recursos de servidor en cada zona de la configuración regional. Cada recurso de servidor por zona usa la réplica de datos en su zona. Para obtener información sobre las réplicas de datos en la configuración de instancias, consulta Configuración regional y multirregional. Para obtener información sobre cómo Spanner mantiene sincronizadas estas réplicas de datos, consulta Replicación.
Los recursos del servidor para la Instancia A se muestran en cuadros simples, mientras que los recursos para la Instancia B se muestran en cuadros subdivididos en dos partes. Esta diferencia ilustra que Spanner asigna los recursos del servidor de manera diferente para las instancias de distintos tamaños:
- Para instancias de 1,000 unidades de procesamiento (1 nodo) o menos, Spanner asigna recursos del servidor en una sola tarea del servidor por zona.
- Para instancias de más de 1,000 unidades de procesamiento (1 nodo), Spanner asigna recursos del servidor en varias tareas del servidor por zona, con una tarea por cada 1,000 unidades de procesamiento. El uso de varias tareas del servidor por zona proporciona un mejor rendimiento y permite que Spanner cree divisiones de bases de datos y proporcione un rendimiento aún mejor.
Aumentar y disminuir la capacidad de procesamiento
Después de crear una instancia, puedes aumentar su capacidad de procesamiento más adelante. En la mayoría de los casos, también puedes disminuir la capacidad de procesamiento. Hay algunos casos en los que no puedes disminuir la capacidad de procesamiento:
- Quitar la capacidad de procesamiento requeriría que la instancia almacene más de 4 TB de datos por cada 1,000 unidades de procesamiento (1 nodo).
- En función de tus patrones de uso históricos, Spanner creó una gran cantidad de divisiones para los datos de la instancia y, en algunos casos excepcionales, Spanner no podría administrar las divisiones después de quitar la capacidad de procesamiento.
En el último caso, puedes intentar reducir la capacidad de procesamiento a cantidades cada vez más pequeñas hasta encontrar la capacidad mínima que Spanner necesita para administrar todas las divisiones de la instancia. Si la instancia ya no requiere tantas divisiones debido a un cambio en los patrones de uso, Spanner podría combinar algunas divisiones y permitirte intentar reducir aún más la capacidad de procesamiento de la instancia después de una o dos semanas.
Cuando quites capacidad de procesamiento, supervisa el uso de CPU y las latencias de solicitudes en Cloud Monitoring para asegurarte de que el uso de CPU se mantenga por debajo del 65% en las instancias regionales y del 45% para cada región en las instancias multirregionales. Es posible que experimentes un aumento temporal en la latencia de las solicitudes mientras quitas la capacidad de procesamiento.
Puedes usar la consola de Google Cloud, Google Cloud CLI o las bibliotecas cliente para cambiar la capacidad de procesamiento.
Spanner no tiene un modo de suspensión. La capacidad de procesamiento de Spanner es un recurso dedicado y, incluso cuando no estás ejecutando una carga de trabajo, Spanner realiza con frecuencia trabajo en segundo plano para optimizar y proteger tus datos.
Capacidad de procesamiento en comparación con réplicas
Si necesitas escalar verticalmente los recursos del servidor y de almacenamiento en tu instancia, aumenta la capacidad de procesamiento de la instancia. Ten en cuenta que aumentar la capacidad de procesamiento no aumenta la cantidad de réplicas (que se fijan para una configuración de instancia determinada), sino que aumenta los recursos que cada réplica tiene en la instancia. El aumento de la capacidad de procesamiento le da a cada réplica más CPU y RAM, lo que aumenta la capacidad de procesamiento de la réplica (es decir, pueden producirse más lecturas y escrituras por segundo).
¿Qué sigue?
- Aprende a crear una instancia de Spanner.