In dieser Anleitung wird beschrieben, wie Sie mit NVIDIA TensorRT5-GPUs in Compute Engine Deep-Learning-Inferenzen für umfangreiche Arbeitslasten ausführen.
Einige Grundlagen vorab:
- Die Deep-Learning-Inferenz ist die Phase im maschinellen Lernprozess, in der ein trainiertes Modell zur Erkennung, Verarbeitung und Klassifizierung von Ergebnissen verwendet wird.
- NVIDIA TensorRT ist eine für die Ausführung von Deep-Learning-Arbeitslasten optimierte Plattform.
- GPUs dienen zum Beschleunigen datenintensiver Arbeitslasten wie maschinelles Lernen und Datenverarbeitung. In Compute Engine sind verschiedene NVIDIA-GPUs verfügbar. In dieser Anleitung werden T4-GPUs verwendet, da diese speziell für Arbeitslasten mit Deep-Learning-Inferenzen konzipiert wurden.
Zielsetzungen
In dieser Anleitung werden die folgenden Verfahren behandelt:
- Vorbereiten eines Modells mit einer vorab trainierten Grafik
- Testen der Inferenzgeschwindigkeit für ein Modell mit unterschiedlichen Optimierungsmodi
- Konvertieren eines benutzerdefinierten Modells nach TensorRT
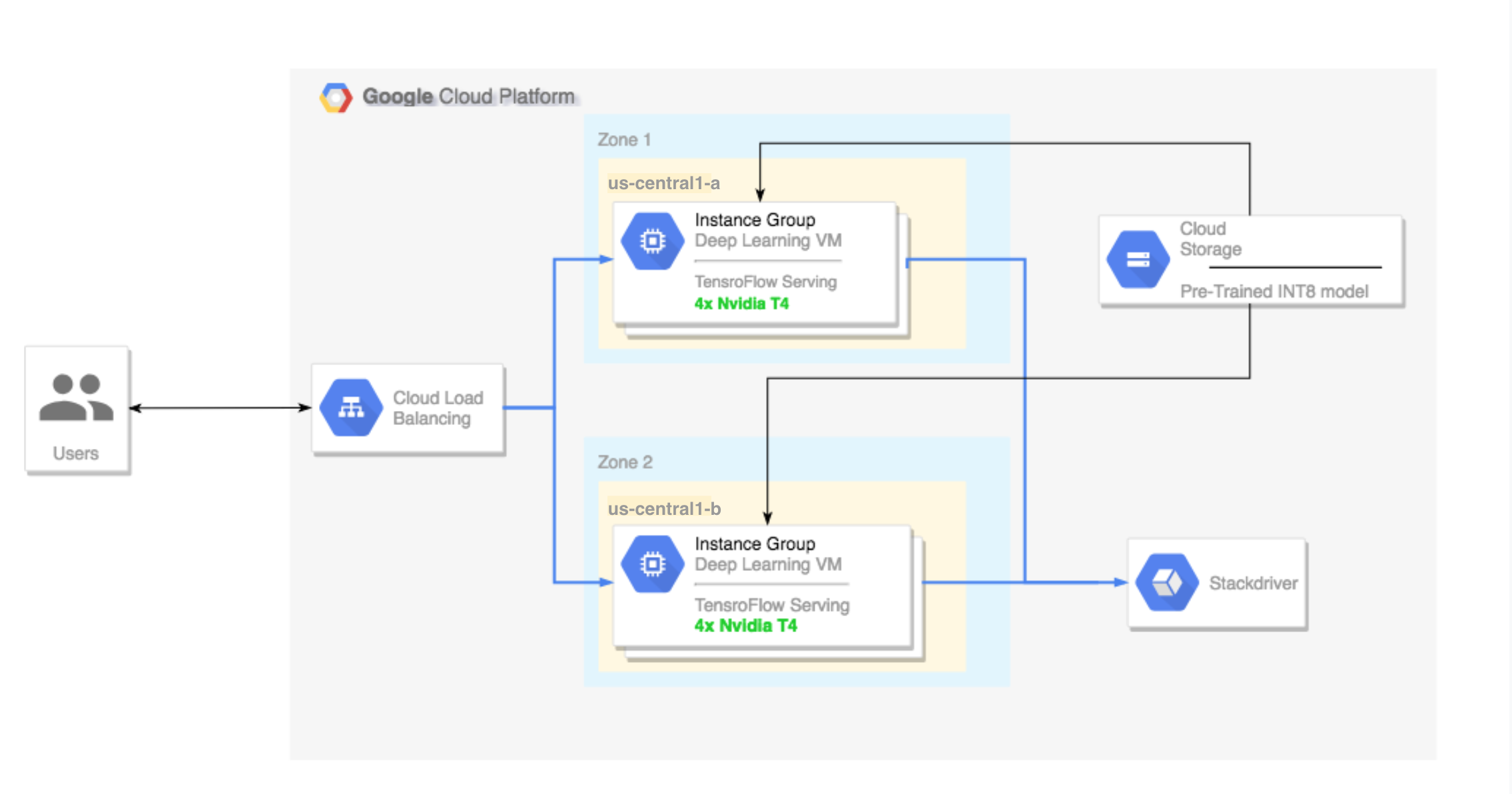
- Einrichten eines Clusters mit mehreren Zonen. Dieser Mehrzonencluster ist so konfiguriert:
- Grundlage sind Deep Learning-VM-Images. Auf diesen Images sind TensorFlow, TensorFlow Serving und TensorRT5 vorinstalliert.
- Autoscaling ist aktiviert. Das Autoscaling in dieser Anleitung basiert auf der GPU-Nutzung.
- Load-Balancing ist aktiviert.
- Firewall ist aktiviert.
- Ausführen einer Inferenzarbeitslast im Mehrzonencluster
Kosten
Die Kosten für die Ausführung dieser Anleitung variieren je nach Abschnitt.
Sie können die Kosten mit dem Preisrechner berechnen.
Verwenden Sie die folgenden Spezifikationen, um die Kosten für die Vorbereitung Ihres Modells zu schätzen und die Inferenzgeschwindigkeiten bei verschiedenen Optimierungsgeschwindigkeiten zu testen:
- 1 VM-Instanz:
n1-standard-8(8 vCPUs, 30 GB RAM) - 1 NVIDIA T4-GPU
Verwenden Sie die folgenden Spezifikationen, um die Kosten für die Einrichtung des Mehrzonenclusters zu schätzen:
- 2 VM-Instanzen:
n1-standard-16(16 vCPUs, 60 GB RAM) - 4 NVIDIA T4-GPUs für jede VM-Instanz
- 100 GB SSD für jede VM-Instanz
- 1 Weiterleitungsregel
Hinweis
Projekteinrichtung
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Compute Engine and Cloud Machine Learning APIs aktivieren.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Compute Engine and Cloud Machine Learning APIs aktivieren.
Tools einrichten
So verwenden Sie Google Cloud CLI in dieser Anleitung:
- Installieren Sie die Google Cloud CLI oder aktualisieren Sie sie auf die neueste Version.
- (Optional) Legen Sie eine Standardregion und -zone fest.
Modell vorbereiten
In diesem Abschnitt wird die Erstellung einer VM-Instanz beschrieben, die zur Ausführung des Modells verwendet wird. In diesem Abschnitt wird auch beschrieben, wie Sie ein Modell aus dem offiziellen TensorFlow-Modellkatalog herunterladen.
Erstellen Sie die VM-Instanz: Diese Anleitung wird mit
tf-ent-2-10-cu113erstellt. Informationen zu den neuesten Image-Versionen finden Sie in der Dokumentation zu Deep Learning-VM-Images unter Betriebssystem auswählen.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
Wählen Sie ein Modell aus. In dieser Anleitung kommt das ResNet-Modell zum Einsatz. Dieses ResNet-Modell wurde mit dem ImageNet-Dataset in TensorFlow trainiert.
Führen Sie den folgenden Befehl aus, um das ResNet-Modell in die VM-Instanz herunterzuladen:
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
Halten Sie den Speicherort des ResNet-Modells in der Variablen
$WORKDIRfest. Ersetzen SieMODEL_LOCATIONdurch das Arbeitsverzeichnis, das das heruntergeladene Modell enthält.export WORKDIR=MODEL_LOCATION
Inferenzgeschwindigkeitstest ausführen
Dieser Abschnitt behandelt die folgenden Verfahren:
- Einrichten des ResNet-Modells
- Ausführen von Inferenztests mit verschiedenen Optimierungsmodi
- Überprüfen der Ergebnisse der Inferenztests
Der Testvorgang im Überblick
TensorRT kann zwar die Geschwindigkeit von Inferenzarbeitslasten erhöhen, die bedeutendste Verbesserung folgt jedoch aus dem Quantisierungsprozess.
Die Modellquantisierung ist der Prozess, durch den Sie die Genauigkeit von Gewichtungen bei einem Modell reduzieren. Wenn zum Beispiel die Anfangsgewichtung eines Modells FP32 ist, können Sie die Genauigkeit auf FP16, INT8 oder sogar INT4 reduzieren. Es ist wichtig, den richtigen Kompromiss zwischen Geschwindigkeit (Genauigkeit der Gewichtungen) und Treffsicherheit eines Modells auszuwählen. Glücklicherweise verfügt TensorFlow über Funktionen, die genau dies tun. Sie messen die Treffsicherheit und stellen sie der Geschwindigkeit oder anderen Messwerten wie Durchsatz, Latenz, Conversion-Raten und Gesamttrainingszeit gegenüber.
Vorgehensweise
Richten Sie das ResNet-Modell ein. Führen Sie die folgenden Befehle aus, um das Modell einzurichten:
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
Führen Sie den Test aus. Die Ausführung dieses Befehls dauert einige Zeit.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
Dabei gilt:
$WORKDIRist das Verzeichnis, in das Sie das ResNet-Modell heruntergeladen haben.- Die
--native-Argumente sind die verschiedenen zu testenden Quantisierungsmodi.
Überprüfen Sie die Ergebnisse. Nach Abschluss des Tests können Sie die Inferenzergebnisse für jeden Optimierungsmodus vergleichen.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
Führen Sie den folgenden Befehl aus, um die vollständigen Ergebnisse zu sehen:
cat $WORKDIR/log.txt
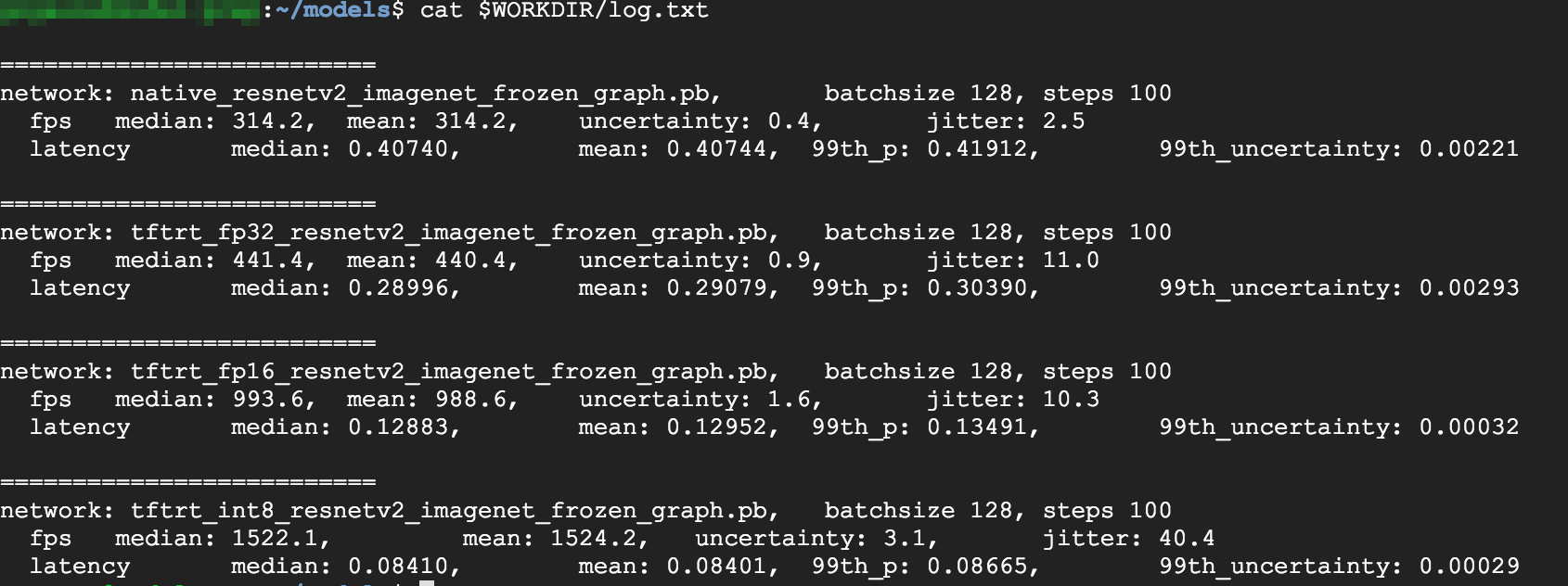
Wie Sie sehen, sind die Ergebnisse für FP32 und FP16 identisch. Wenn Sie also mit TensorRT arbeiten möchten, können Sie auf jeden Fall sofort mit FP16 beginnen. INT8 liefert etwas schlechtere Ergebnisse.
Außerdem sehen Sie, dass die Ausführung des Modells mit TensorRT5 die folgenden Ergebnisse liefert:
- Durch die FP32-Optimierung wird der Durchsatz von 314 fps um 40 % auf 440 fps verbessert. Gleichzeitig nimmt die Latenz um etwa 30 % ab und beträgt 0,28 ms statt 0,40 ms.
- Durch die FP16-Optimierung anstelle der nativen TensorFlow-Grafik wird die Geschwindigkeit von 314 fps um 214 % auf 988 fps erhöht. Gleichzeitig nimmt die Latenz um 0,12 ms ab und beträgt im Vergleich ca. nur ein Drittel.
- Mit INT8 können Sie eine Beschleunigung von 385 % von 314 fps auf 1.524 fps beobachten, wobei die Latenz auf 0,08 ms sinkt.
Benutzerdefiniertes Modell in TensorRT konvertieren
Für diese Konvertierung können Sie ein INT8-Modell verwenden.
Laden Sie das Modell herunter. Zum Konvertieren eines benutzerdefinierten Modells in eine TensorRT-Grafik benötigen Sie ein gespeichertes Modell. Führen Sie den folgenden Befehl aus, um ein gespeichertes INT8-ResNet-Modell abzurufen:
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
Konvertieren Sie das Modell mithilfe von TFTools in die TensorRT-Grafik. Führen Sie den folgenden Befehl aus, um das Modell mithilfe von TFTools zu konvertieren:
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
Sie haben nun ein INT8-Modell im Verzeichnis
$WORKDIR/resnet_v2_int8_NCHW/00001.Versuchen Sie, einen Inferenztest auszuführen, um zu bestätigen, dass alles ordnungsgemäß eingerichtet ist.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
Laden Sie das Modell in Cloud Storage hoch. Dieser Schritt ist erforderlich, damit das Modell über den Mehrzonencluster verwendet werden kann, der im nächsten Abschnitt eingerichtet wird. Führen Sie die folgenden Schritte aus, um das Modell hochzuladen:
Archivieren Sie das Modell.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
Laden Sie das Archiv hoch. Ersetzen Sie
GCS_PATHdurch den Pfad zu Ihrem Cloud Storage-Bucket.export GCS_PATH=GCS_PATH gsutil cp model.tar.gz $GCS_PATH
Bei Bedarf können Sie unter folgender URL eine fixierte INT8-Grafik aus Cloud Storage abrufen:
gs://cloud-samples-data/dlvm/t4/model.tar.gz
Mehrzonencluster einrichten
Cluster erstellen
Nachdem Sie ein Modell auf der Cloud Storage-Plattform erstellt haben, können Sie einen Cluster erstellen.
Erstellen Sie eine Instanzvorlage. Eine Instanzvorlage ist eine nützliche Ressource zum Erstellen neuer Instanzen. Siehe Instanzvorlagen. Ersetzen Sie
YOUR_PROJECT_NAMEdurch Ihre Projekt-ID.export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- Diese Instanzvorlage enthält ein Startskript, das durch den Metadatenparameter angegeben wird.
- Führen Sie dieses Startskript während der Instanzerstellung in jeder Instanz aus, die diese Vorlage verwendet.
- Dieses Startskript führt die folgenden Schritte aus:
- Monitoring-Agent herunterladen, der die GPU-Auslastung in der Instanz überwacht
- Modell herunterladen
- Inferenzdienst starten
- Im Startskript enthält
tf_serve.pydie Inferenzlogik. Dieses Beispiel enthält eine sehr kleine Python-Datei, die auf dem TFServe-Paket basiert. - Sie können sich das Startskript unter startup_inf_script.sh ansehen.
- Diese Instanzvorlage enthält ein Startskript, das durch den Metadatenparameter angegeben wird.
Erstellen Sie eine verwaltete Instanzgruppe (Managed Instance Group, MIG). Diese verwaltete Instanzgruppe wird benötigt, um mehrere ausgeführte Instanzen in bestimmten Zonen einzurichten. Die Instanzen werden auf der Grundlage der im vorherigen Schritt erstellten Instanzvorlage erstellt.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
- Sie können diese Instanz in jeder verfügbaren Zone erstellen, die T4-GPUs unterstützt. Dafür benötigen Sie jedoch GPU-Kontingente in der Zone.
Das Erstellen der Instanz dauert einige Zeit. Mit den folgenden Befehlen können Sie den Fortschritt beobachten:
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

Nachdem die verwaltete Instanzgruppe erstellt wurde, sollten Sie eine Ausgabe wie diese sehen:

Prüfen Sie, ob auf der Cloud Monitoring-Seite von Google Cloud Messwerte verfügbar sind.
Rufen Sie in der Google Cloud Console die Seite Monitoring auf.
Wenn im Navigationsbereich der Metrics Explorer angezeigt wird, klicken Sie auf Metrics Explorer. Wählen Sie andernfalls Ressourcen und dann Metrics Explorer aus.
Suchen Sie nach
gpu_utilization.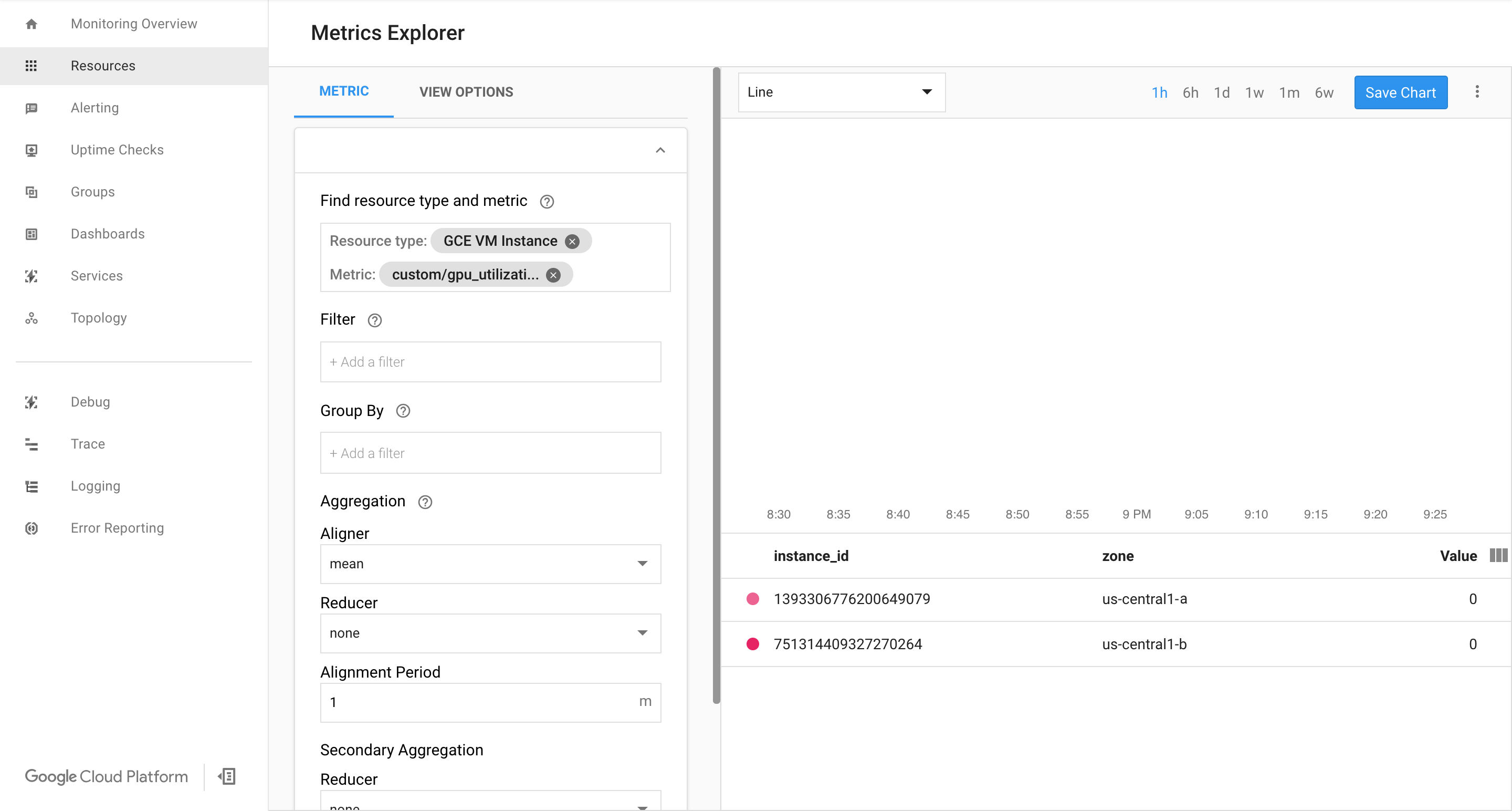
Wenn Daten eingehen, sollten Sie etwa Folgendes sehen:
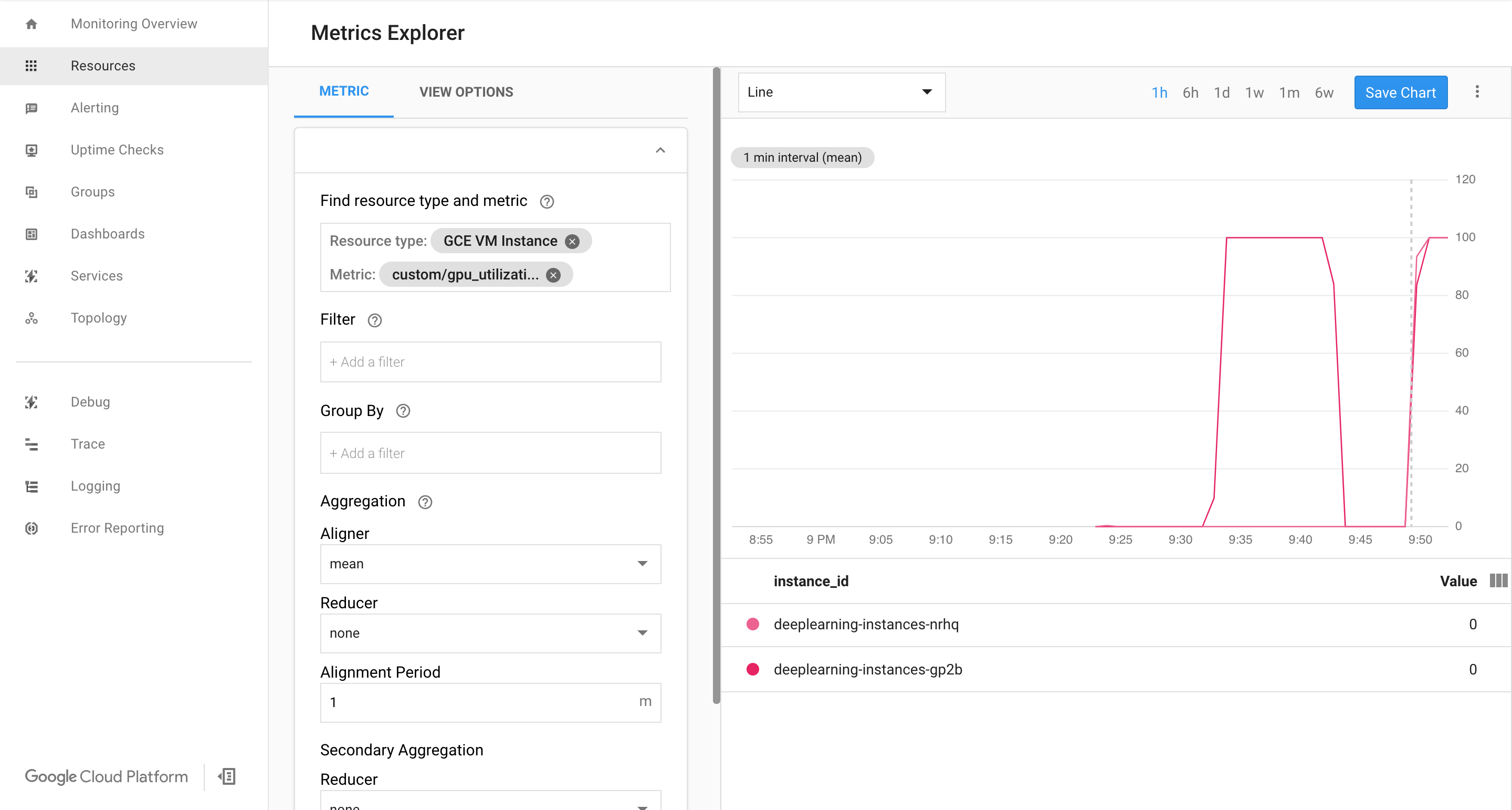
Autoscaling aktivieren
Aktivieren Sie das Autoscaling für die verwaltete Instanzgruppe.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationist der vollständige Pfad zu unserem Messwert. Im Beispiel ist eine Auslastung von 85 angegeben. Das bedeutet, dass die Plattform immer dann eine neue Instanz in der Gruppe erzeugt, wenn die GPU-Auslastung 85 % erreicht.Testen Sie das Autoscaling. Führen Sie die folgenden Schritte aus, um das Autoscaling zu testen:
- Stellen Sie eine SSH-Verbindung zur Instanz her. Siehe Verbindung mit einer Instanz herstellen.
Verwenden Sie das Tool
gpu-burn, um Ihre GPU für 600 Sekunden auf 100 % Auslastung zu laden:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Rufen Sie die Cloud Monitoring-Seite auf. Beobachten Sie das Autoscaling. Der Cluster wird durch Hinzufügen einer weiteren Instanz vergrößert.
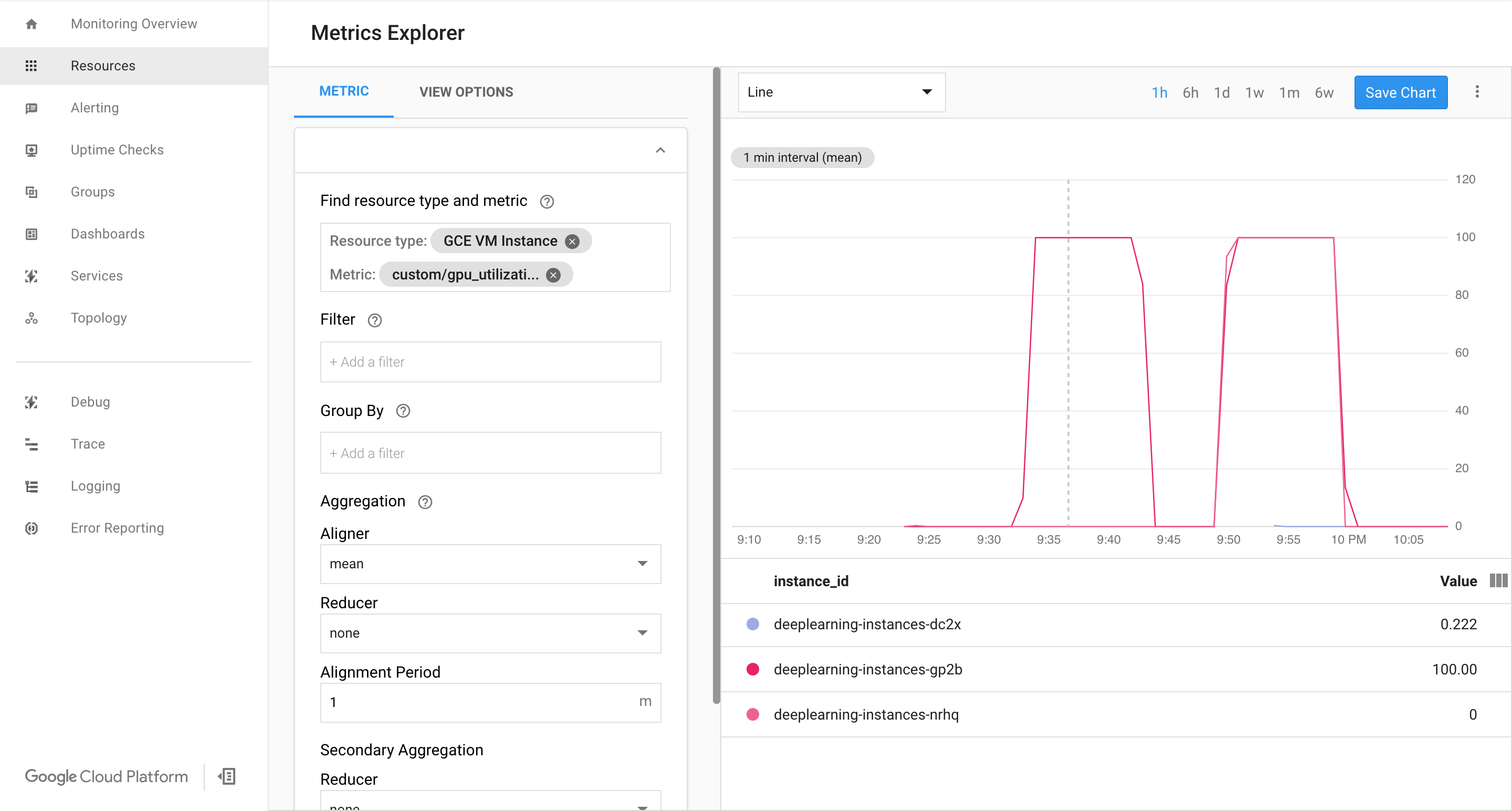
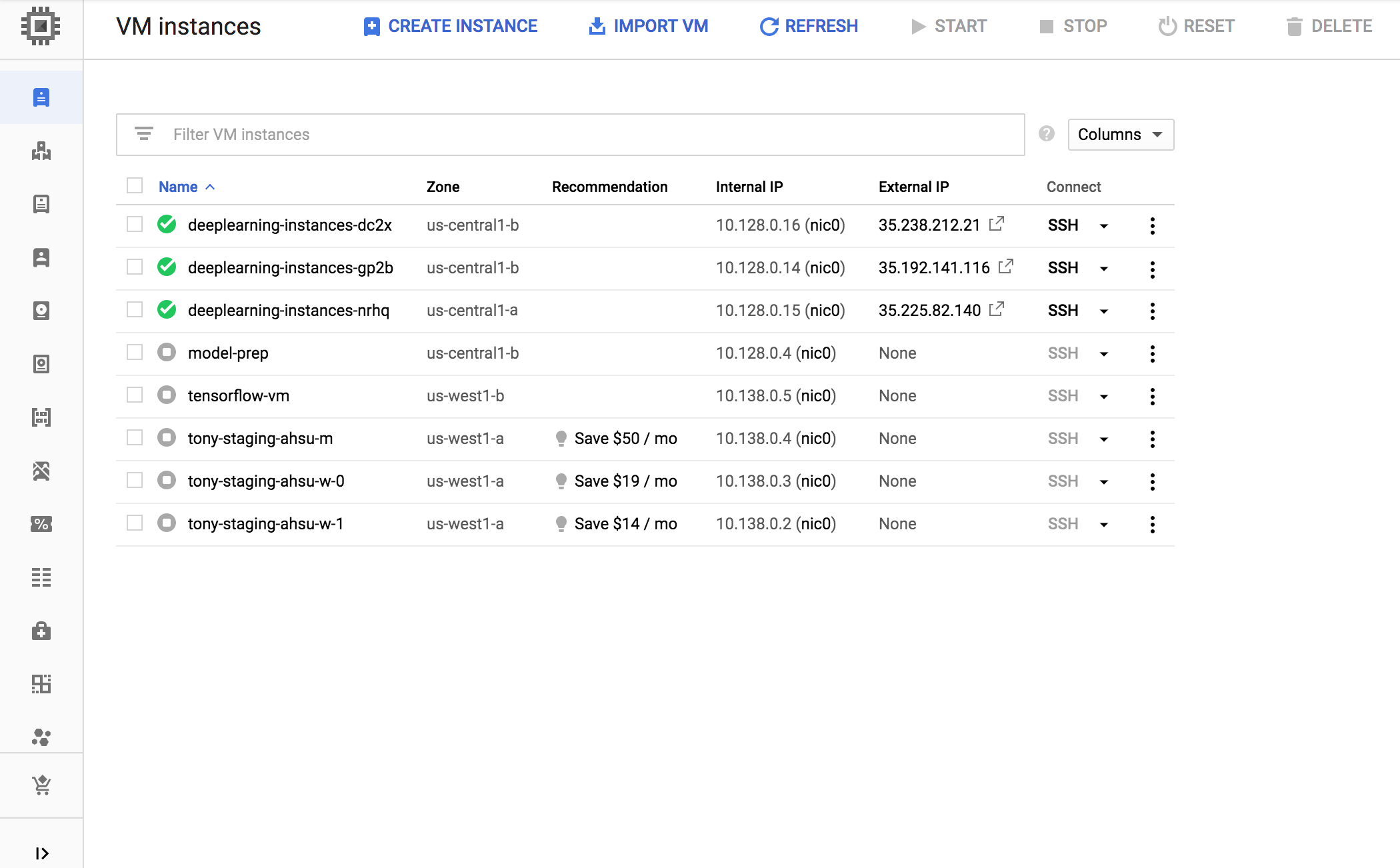
Rufen Sie in der Google Cloud Console die Seite Instanzgruppen auf.
Klicken Sie auf die verwaltete Instanzgruppe
deeplearning-instance-group.Klicken Sie auf den Tab Monitoring.
Jetzt sollte Ihre Autoscaling-Logik erfolglos versuchen, so viele Instanzen wie möglich einzurichten, um die Last zu reduzieren:
Nun können Sie das Einrichten von Instanzen anhalten und beobachten, wie das System verkleinert wird.
Load-Balancer einrichten
Sehen wir uns nun an, was bereits vorhanden ist:
- Ein trainiertes, mit TensorRT5 (INT8) optimiertes Modell
- Eine verwaltete Instanzgruppe. Für diese Instanzen ist das Autoscaling basierend auf der GPU-Auslastung aktiviert
Jetzt können Sie vor den Instanzen einen Load-Balancer erstellen.
Erstellen Sie Systemdiagnosen. Anhand der Systemdiagnosen lässt sich feststellen, ob ein bestimmter Host im Back-End den Traffic bereitstellen kann.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
Erstellen Sie einen Backend-Dienst, der eine Instanzgruppe und eine Systemdiagnose enthält.
Erstellen Sie die Systemdiagnose.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
Erweitern Sie den neuen Back-End-Dienst um die Instanzgruppe.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
Richten Sie die Weiterleitungs-URL ein. Der Load-Balancer muss wissen, welche URL an die Back-End-Dienste weitergeleitet werden kann.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
Erstellen Sie den Load-Balancer.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
Weisen Sie dem Load-Balancer eine externe IP-Adresse zu.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
Ermitteln Sie die zugewiesene IP-Adresse.
gcloud compute addresses list
Richten Sie die Weiterleitungsregel ein, die Google Cloud anweist, alle Anfragen von der öffentlichen IP-Adresse an den Load-Balancer weiterzuleiten.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80Nachdem die globalen Weiterleitungsregeln erstellt wurden, kann es mehrere Minuten dauern, bis die Konfiguration aktiv ist.
Firewall aktivieren
Überprüfen Sie, ob Firewallregeln vorhanden sind, die Verbindungen von externen Quellen zu Ihren VM-Instanzen zulassen.
gcloud compute firewall-rules list
Wenn Sie keine Firewallregeln haben, die diese Verbindungen zulassen, müssen Sie diese erstellen. Führen Sie die folgenden Befehle aus, um Firewallregeln zu erstellen:
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
Inferenz ausführen
Mit dem folgenden Python-Skript können Sie Bilder in ein Format konvertieren, das auf den Server hochgeladen werden kann.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))Führen Sie die Inferenz aus.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Löschen Sie die Weiterleitungsregeln.
gcloud compute forwarding-rules delete $FORWARDING_RULE --global
Löschen Sie die IPV4-Adresse.
gcloud compute addresses delete $IP4_NAME --global
Löschen Sie den Load-Balancer.
gcloud compute target-http-proxies delete $LB_NAME
Löschen Sie die Weiterleitungs-URL.
gcloud compute url-maps delete $WEB_MAP_NAME
Löschen Sie den Backend-Dienst.
gcloud compute backend-services delete $WEB_BACKED_SERVICE_NAME --global
Löschen Sie die Systemdiagnosen.
gcloud compute health-checks delete $HEALTH_CHECK_NAME
Löschen Sie die verwaltete Instanzgruppe.
gcloud compute instance-groups managed delete $INSTANCE_GROUP_NAME --region us-central1
Löschen Sie die Instanzvorlage.
gcloud beta compute --project=$PROJECT_NAME instance-templates delete $INSTANCE_TEMPLATE_NAME
Löschen Sie die Firewallregeln.
gcloud compute firewall-rules delete www-firewall-80
gcloud compute firewall-rules delete www-firewall-8888