En esta guía, se proporcionan instrucciones para operar los sistemas SAP HANA implementados en Google Cloud mediante la Guía de implementación de escalamiento vertical de SAP HANA. Ten en cuenta que esta guía no tiene como objetivo reemplazar la documentación estándar de SAP.
Administra un sistema SAP HANA en Google Cloud
En esta sección, se muestra cómo realizar tareas administrativas que, por lo general, se requieren para operar un sistema SAP HANA, incluida la información sobre cómo iniciar, detener y clonar sistemas.
Inicia y detén instancias
Puedes detener uno o varios hosts de SAP HANA en cualquier momento; si se detiene una instancia, esta se cierra. Si se no se cierra por completo en 2 minutos, se produce una interrupción forzosa de la instancia. Como práctica recomendada, debes detener la ejecución de SAP HANA antes de detener la instancia.
Detén una VM
Detener una instancia de máquina virtual (VM) hace que Compute Engine envíe la señal de apagado ACPI a la instancia. No se te factura por la instancia de Compute Engine después de detenerla. Si tienes discos persistentes conectados a la instancia, estos no se borran y se te cobrará por ellos.
Si los datos en el disco persistente son importantes, puedes conservar el disco o crear una instantánea del disco persistente y borrarlo para ahorrar costos. Puedes crear otro disco a partir de la instantánea cuando vuelvas a necesitar los datos.
Para detener una instancia:
En la consola de Google Cloud, ve a la página Instancias de VM.
Selecciona una o más instancias que desees detener.
En la parte superior de la página Instancias de VM, haz clic en stopDETENER.
Para obtener más información, consulta Detén una instancia.
Reinicia una VM
En la consola de Google Cloud, ve a la página Instancias de VM.
Selecciona las instancias que deseas reiniciar.
En la parte superior derecha de la página, haz clic en play_arrowINICIAR para reiniciar las instancias.
Para obtener más información, consulta Reinicia una instancia.
Modifica una VM
Puedes cambiar varios atributos de una VM, incluido su tipo, después de implementarla. Es posible que debas restablecer el sistema SAP de las copias de seguridad para algunos cambios, mientras que para otros solo debes reiniciar la VM.
A fin de obtener más información, consulta Modifica la configuración de las VM para sistemas SAP.
Crea una instantánea de SAP HANA
Para generar una copia de seguridad de un momento determinado del disco persistente, puedes crear una instantánea. Compute Engine almacena de forma redundante varias copias de cada instantánea en varias ubicaciones con sumas de verificación automáticas para garantizar la integridad de los datos.
A fin de crear una instantánea, sigue las instrucciones de Compute Engine para crear instantáneas. Presta especial atención a los pasos de preparación, como vaciar los búferes del disco, para asegurarte de que la instantánea sea coherente.
Las instantáneas son útiles para los siguientes casos prácticos:
| Caso práctico | Detalles |
|---|---|
| Proporcionar una solución de copia de seguridad de datos sencilla, independiente del software y rentable. | Crea copias de seguridad de los datos, los registros, las copias de seguridad y los discos compartidos con instantáneas. Programa una copia de seguridad diaria de estos discos para crear copias de seguridad de un momento determinado de todo el conjunto de datos. Después de la primera instantánea, solo se almacenan los cambios de bloque incrementales en las instantáneas posteriores. Esto ayuda a ahorrar costos. |
| Migrar a un tipo de almacenamiento diferente. | Compute Engine ofrece diferentes tipos de discos persistentes, incluidos los tipos respaldados por el almacenamiento estándar (magnético) y los tipos respaldados por el almacenamiento en unidades de estado sólido (discos persistentes basados en SSD). Cada uno tiene diferentes características de rendimiento y costos. Por ejemplo, usa un tipo estándar para el volumen de copia de seguridad y un tipo basado en SSD para los volúmenes /hana/log y /hana/data, ya que requieren un rendimiento más alto. Para migrar entre tipos de almacenamiento, usa la instantánea de volumen. Luego, crea un volumen nuevo mediante la instantánea y selecciona un tipo de almacenamiento diferente. |
| Migra SAP HANA a otra región o zona. | Usa instantáneas para migrar el sistema SAP HANA de una zona a otra en la misma región, o incluso a otra región. Las instantáneas se pueden usar de forma global en Google Cloud para crear discos en otra zona o región. Para migrar a otra región o zona, debes crear una instantánea de los discos, incluido el disco raíz, y, luego, crear las máquinas virtuales en la zona o región deseadas con los discos creados a partir de esas instantáneas. |
Migra volúmenes de Persistent Disk de SAP HANA existentes a volúmenes de Hyperdisk Extreme
Puedes migrar volúmenes existentes de Persistent Disk a volúmenes de Hyperdisk Extreme para los sistemas SAP HANA que se ejecutan en Google Cloud. Hyperdisk Extreme proporciona un mejor rendimiento para SAP HANA que los tipos de Persistent Disk basados en SSD.
Para migrar los volúmenes de Persistent Disk a volúmenes de Hyperdisk Extreme, usa las instantáneas de discos persistentes y la opción de reinicio rápido de SAP HANA. La opción de reinicio rápido de SAP HANA se usa como auxiliar que reduce el tiempo de inactividad cuando se cambian los tipos de discos, ya que elimina la necesidad de esperar a que se carguen las tablas. Debes tener en cuenta el tiempo necesario para volver a cargar el almacén de filas y los tipos de datos del objeto binario grande (BLOB).
Aunque el proceso de migración requiere un tiempo de inactividad mínimo, la duración real del tiempo de inactividad depende del tiempo que se tarda en completar las siguientes tareas:
- Crear instantáneas. Para reducir el tiempo de inactividad mientras tomas instantáneas, puedes tomar instantáneas de los discos antes de la actividad de migración planificada y, luego, tomar algunas instantáneas adicionales más cerca de la actividad, lo que genera una diferencia menor entre las instantáneas.
- Crear volúmenes de Hyperdisk Extreme mediante las instantáneas de los volúmenes de Persistent Disk.
- Vuelve a cargar las tablas de SAP HANA en la memoria de SAP HANA.
En caso de cualquier problema durante la migración, puedes volver a los discos existentes porque no se ven afectados por este procedimiento y están disponibles hasta que los borres.
Antes de comenzar
Antes de migrar los volúmenes de Persistent Disk de SAP HANA a volúmenes de Hyperdisk Extreme, asegúrate de que se cumplan las siguientes condiciones:
- SAP HANA se ejecuta en un tipo de VM de Compute Engine certificado que admite Hyperdisk Extreme.
- Los datos y registros de SAP HANA usan discos persistentes distintos para los volúmenes
/hana/datay/hana/log. - La administración de volumen lógico de Linux se usa para la persistencia de almacenamiento de SAP HANA.
Si bien se puede usar el almacenamiento directo, se requeriría una reasignación explícita de dispositivo a través de la tabla
/etc/fstab. - El reinicio rápido de SAP HANA está habilitado para tu sistema SAP HANA. Para obtener más información sobre cómo habilitar SAP HANA Fast Restart, consulta Habilita SAP HANA Fast Restart.
- Hay una copia de seguridad válida de la base de datos de SAP HANA disponible. Esta copia de seguridad se puede usar para restablecer la base de datos, si es necesario.
- Si la instancia de VM de destino es parte de un clúster de alta disponibilidad, asegúrate de que el clúster esté en modo de mantenimiento.
- La base de datos de SAP HANA está en funcionamiento.
El sistema de archivos
tmpfsestá cargado por completo con el contenido de los fragmentos de datos deMAIN. Para ver el uso del sistema de archivos, ejecuta el siguiente comando:df -Th.Debería ver un resultado similar al siguiente:
# df -Th Filesystem Type Size Used Avail Use% Mounted on ... /dev/mapper/vg_hana_shared-shared xfs 1.0T 56G 968G 6% /hana/shared /dev/mapper/vg_hana_data-data xfs 14T 5.7T 8.2T 41% /hana/data /dev/mapper/vg_hana_log-log xfs 512G 7.2G 505G 2% /hana/log /dev/mapper/vg_hana_usrsap-usrsap xfs 32G 276M 32G 1% /usr/sap tmpfsDB10 tmpfs 5.7T 800G 4.9T 14% /hana/tmpfs0/DB1 tmpfsDB11 tmpfs 5.7T 796G 4.9T 14% /hana/tmpfs1/DB1 tmpfsDB12 tmpfs 5.7T 783G 4.9T 14% /hana/tmpfs2/DB1 tmpfsDB13 tmpfs 5.7T 780G 4.9T 14% /hana/tmpfs3/DB1 tmpfsDB14 tmpfs 5.7T 816G 4.9T 15% /hana/tmpfs4/DB1 tmpfsDB15 tmpfs 5.7T 780G 4.9T 14% /hana/tmpfs5/DB1 tmpfsDB16 tmpfs 5.7T 816G 4.9T 15% /hana/tmpfs6/DB1 tmpfsDB17 tmpfs 5.7T 780G 4.9T 14% /hana/tmpfs7/DB1
Migra volúmenes de Persistent Disk a volúmenes de Hyperdisk Extreme
En esta sección, se describe cómo migrar el tipo de disco de dos discos persistentes para los volúmenes /hana/data y /hana/log de Persistent Disk (pd-ssd) a Hyperdisk Extreme.
Para ilustrar el proceso de migración, se usa la siguiente configuración de ejemplo:
- Tipo de máquina:
m2-ultramem-416(12 TB de memoria, 416 CPU virtuales) - Sistema de escalamiento vertical de SAP HANA implementado con el documento de Google Cloud Terraform: Guía de implementación de escalamiento vertical de SAP HANA
- SO: SLES para SAP 15 SP1
- SAP HANA: parche 63 de HANA 2 SPS06
- Tipo de disco predeterminado:
pd-ssd - Los volúmenes
/hana/datay/hana/logse activan en discos separados y se compilan mediante LVM y XFS - SAP HANA Fast Restart está habilitado y se cargan alrededor de 6 TB de datos en la base de datos
Para migrar volúmenes de Persistent Disk a volúmenes de Hyperdisk Extreme, sigue estos pasos:
Detén la base de datos de SAP HANA mediante uno de los siguientes comandos:
HDB stopO
sapcontrol -nr INSTANCE_NUMBER -function StopSystem HDBReemplaza
INSTANCE_NUMBERpor el número de instancia de tu sistema SAP HANA.Para obtener más información, consulta el documento de SAP Inicia y detén sistemas de SAP HANA.
Desactiva los sistemas de archivos
/hana/datay/hana/log:umount /hana/data umount /hana/logDetermina los nombres de los datos y registra los discos persistentes mediante uno de los siguientes métodos:
Ejecuta el siguiente comando:
ls -l /dev/disk/by-id/El resultado muestra la asignación de nombres de disco a los dispositivos:
... lrwxrwxrwx 1 root root 9 May 18 20:14 google-hana-vm-data00001 -> ../../sdb lrwxrwxrwx 1 root root 9 May 18 20:14 google-hana-vm-log00001 -> ../../sdc ...Ejecuta el siguiente comando
gcloud compute:gcloud compute instances describe INSTANCE_NAME --zone=ZONEReemplaza lo siguiente:
INSTANCE_NAME: El nombre de la instancia de VMZONE: Es la zona de la instancia de VM.
En el resultado, se muestran los detalles de la instancia de VM, incluida la información del disco asociado:
gcloud compute instances describe hana-vm --zone europe-west4-a ... disks: - autoDelete: false deviceName: hana-vm-shared00001 diskSizeGb: '1024' - autoDelete: false deviceName: hana-vm-usrsap00001 diskSizeGb: '32' - autoDelete: false deviceName: hana-vm-data00001 diskSizeGb: '14093' - autoDelete: false deviceName: hana-vm-log00001 diskSizeGb: '512'En la consola de Google Cloud, ve a la página Instancias de VM de Compute Engine y haz clic en el nombre de la VM. En la sección Almacenamiento, se muestra la información del disco asociado.
Crea instantáneas de los datos y registra los discos persistentes:
gcloud compute snapshots create DATA_DISK-snapshot \ --project=PROJECT_ID \ --source-disk-zone=SOURCE_DISK_ZONE \ --source-disk=DATA_DISK gcloud compute snapshots create LOG_DISK-snapshot \ --project=PROJECT_ID \ --source-disk-zone=SOURCE_DISK_ZONE \ --source-disk=LOG_DISKReemplaza lo siguiente:
DATA_DISK: Es el nombre del disco persistente de datos desde el que necesitas crear una instantánea. Este nombre tiene el prefijo de la instantánea del volumen de datos.LOG_DISK: Es el nombre del disco persistente de registro desde el que necesitas crear una instantánea. Este nombre tiene el prefijo de la instantánea del volumen de registro.PROJECT_ID: el ID del proyecto.SOURCE_DISK_ZONE: La zona del disco persistente desde el que necesitas crear una instantánea.
Para obtener más información sobre cómo crear instantáneas, consulta Crea y administra instantáneas de discos.
Crea nuevos discos Hyperdisk Extreme para los volúmenes
/hana/datay/hana/logsegún las instantáneas:gcloud compute disks create DATA_DISK-hdx \ --project=PROJECT_ID \ --zone=ZONE \ --type=hyperdisk-extreme \ --provisioned-iops=IOPS_DATA_DISK \ --source-snapshot=DATA_DISK-snapshot gcloud compute disks create LOG_DISK-hdx \ --project=PROJECT_ID \ --zone=ZONE \ --type=hyperdisk-extreme \ --provisioned-iops=IOPS_LOG_DISK \ --source-snapshot=LOG_DISK-snapshotReemplaza lo siguiente:
DATA_DISK: el nombre del volumen de datos del disco persistente original que tiene el prefijo del volumen de datos de Hyperdisk Extreme y una instantánea del volumen de datos.LOG_DISK: El nombre del volumen de registro del disco persistente original con el prefijo del volumen de registro de Hyperdisk Extreme y una instantánea del volumen de registro.PROJECT_ID: el ID del proyecto.ZONE: Es la zona en la que necesitas crear discos de Hyperdisk Extreme.IOPS_DATA_DISK: las IOPS aprovisionadas del disco de Hyperdisk Extreme para el volumen de datos. Debes establecer IOPS según tus requisitos de rendimiento.IOPS_LOG_DISK: las IOPS aprovisionadas del disco de Hyperdisk Extreme para el volumen de registro. Debes configurar IOPS según tus requisitos de rendimiento.A fin de obtener información sobre las IOPS mínimas para los volúmenes de Hyperdisk Extreme adjuntos a tu tipo de instancia, consulta Tamaños mínimos para los discos persistentes basados en SSD y los discos persistentes.
Para obtener más información sobre el restablecimiento desde una instantánea, consulta Restablece a partir de una instantánea.
Desconecta los discos persistentes antiguos de SAP HANA:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk=DATA_DISK \ --zone=ZONE gcloud compute instances detach-disk INSTANCE_NAME \ --disk=LOG_DISK \ --zone=ZONEReemplaza lo siguiente:
INSTANCE_NAME: El nombre de la instancia de VMDATA_DISK: Es el nombre del disco persistente de volumen de datos que se desconectará.LOG_DISK: Es el nombre del disco persistente de volumen de registro que se desconectará.ZONE: Es la zona en la que existen los discos persistentes.
Conecta los discos nuevos de Hyperdisk Extreme.
gcloud compute instances attach-disk INSTANCE_NAME \ --disk=DATA_DISK-hdx \ --zone=ZONE gcloud compute instances attach-disk INSTANCE_NAME \ --disk=LOG_DISK-hdx \ --zone=ZONEReemplaza lo siguiente:
INSTANCE_NAME: El nombre de la instancia de VMDATA_DISK: el nombre del Hyperdisk Extreme del volumen de datos que se adjuntará.LOG_DISK: el nombre del Hyperdisk Extreme del volumen de registro que se adjuntará.ZONE: Es la zona en la que existen los discos de Hyperdisk Extreme.
Para activar los volúmenes nuevos, sigue estos pasos como usuario
sudooroot:Quita todas las definiciones de asignación de dispositivos para evitar conflictos de asignación de dispositivos de LVM:
dmsetup remove_allAnaliza todos los discos para detectar grupos de volumen, vuelve a compilar cachés y crea volúmenes faltantes (incluido LVM):
vgscan -v --mknodesDebería ver un resultado similar al siguiente:
Scanning all devices to initialize lvmetad. Reading volume groups from cache. Found volume group "vg_hana_data" using metadata type lvm2 Found volume group "vg_hana_shared" using metadata type lvm2 Found volume group "vg_hana_log" using metadata type lvm2 Found volume group "vg_hana_usrsap" using metadata type lvm2Activa los grupos de volúmenes:
vgchange -ayDebería ver un resultado similar al siguiente:
1 logical volume(s) in volume group "vg_hana_data" now active 1 logical volume(s) in volume group "vg_hana_shared" now active 1 logical volume(s) in volume group "vg_hana_log" now active 1 logical volume(s) in volume group "vg_hana_usrsap" now activeAnaliza volúmenes lógicos:
lvscanDebería ver un resultado similar al siguiente:
ACTIVE '/dev/vg_hana_data/data' [13.76 TiB] inherit ACTIVE '/dev/vg_hana_shared/shared' [1024.00 GiB] inherit ACTIVE '/dev/vg_hana_log/log' [512.00 GiB] inherit ACTIVE '/dev/vg_hana_usrsap/usrsap' [32.00 GiB] inheritActiva los discos:
mount -avDebería ver un resultado similar al siguiente:
/ : ignored /boot/efi : already mounted /hana/shared : already mounted /hana/data : already mounted /hana/log : already mounted /usr/sap : already mounted swap : ignored /hana/tmpfs0/DB1 : already mounted /hana/tmpfs1/DB1 : already mounted /hana/tmpfs2/DB1 : already mounted /hana/tmpfs3/DB1 : already mounted /hana/tmpfs4/DB1 : already mounted /hana/tmpfs5/DB1 : already mounted /hana/tmpfs6/DB1 : already mounted /hana/tmpfs7/DB1 : already mounted
Verifica los volúmenes nuevos:
Verifica el uso de los sistemas de archivos:
df -ThDebería ver un resultado similar al siguiente:
Filesystem Type Size Used Avail Use% Mounted on ... /dev/mapper/vg_hana_shared-shared xfs 1.0T 56G 968G 6% /hana/shared /dev/mapper/vg_hana_usrsap-usrsap xfs 32G 277M 32G 1% /usr/sap tmpfsDB10 tmpfs 5.7T 784G 4.9T 14% /hana/tmpfs0/DB1 tmpfsDB11 tmpfs 5.7T 783G 4.9T 14% /hana/tmpfs1/DB1 tmpfsDB12 tmpfs 5.7T 783G 4.9T 14% /hana/tmpfs2/DB1 tmpfsDB13 tmpfs 5.7T 782G 4.9T 14% /hana/tmpfs3/DB1 tmpfsDB14 tmpfs 5.7T 783G 4.9T 14% /hana/tmpfs4/DB1 tmpfsDB15 tmpfs 5.7T 783G 4.9T 14% /hana/tmpfs5/DB1 tmpfsDB16 tmpfs 5.7T 783G 4.9T 14% /hana/tmpfs6/DB1 tmpfsDB17 tmpfs 5.7T 782G 4.9T 14% /hana/tmpfs7/DB1 /dev/mapper/vg_hana_log-log xfs 512G 7.2G 505G 2% /hana/log /dev/mapper/vg_hana_data-data xfs 14T 5.7T 8.2T 41% /hana/dataVerifica que los dispositivos estén vinculados a los volúmenes nuevos:
lsblkDebería ver un resultado similar al siguiente:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/log
Inicia la instancia de SAP HANA con uno de los siguientes comandos:
HDB startO
sapcontrol -nr INSTANCE_NUMBER -function StartSystem HDBReemplaza
INSTANCE_NUMBERpor el número de instancia para tu sistema SAP HANA.Para obtener más información, consulta Inicia y detén sistemas de SAP HANA.
Resguardo
Si la migración del disco falla, puedes usar los discos originales como opción de resguardo, ya que contienen los datos como existían antes del inicio del procedimiento de migración.
Para restablecer el estado original, realiza los siguientes pasos:
- Detén la instancia de VM.
- Desconecta los volúmenes de Hyperdisk Extreme recién creados.
- Vuelve a conectar los discos originales a la instancia de VM.
- Inicia la instancia de VM.
Cambia la configuración del disco
Puedes cambiar las IOPS o la capacidad de procesamiento aprovisionadas, o aumentar el tamaño de los volúmenes de Hyperdisk
una vez cada 4 horas.
Si intentas volver a modificar el disco antes de que venzan las 4 horas, recibirás
un mensaje de error de tasa limitada, como
Cannot update provisioned throughput due to being rate limited.
Para resolver estos errores, espera 4 horas desde la última modificación antes de
intentar modificar el disco nuevamente.
Usa este procedimiento solo en las emergencias en las que no puedas esperar 4 horas para ajustar el tamaño del disco, las IOPS aprovisionadas o la capacidad de procesamiento de los volúmenes de Hyperdisk.
Para cambiar la configuración del disco, sigue estos pasos:
Detén tu instancia de SAP HANA; para ello, ejecuta uno de los siguientes comandos:
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
Reemplaza
INSTANCE_NUMBERpor el número de instancia de tu sistema SAP HANA.Para obtener más información, consulta Inicia y detén sistemas de SAP HANA.
Crea una instantánea o una imagen de tu disco existente:
Copia de seguridad basada en instantáneas
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONReemplaza lo siguiente:
SNAPSHOT_NAME: el nombre de la instantánea que deseas crear.PROJECT_NAME: El nombre de tu proyecto de Google Cloud.SOURCE_DISK_NAME: el disco de origen que se usa para crear la instantánea.ZONE: la zona del disco de origen en la que se operará.LOCATION: la ubicación de Cloud Storage, ya sea regional o multirregional, en la que se almacenará el contenido de la instantánea.Para obtener más información, consulta Crea y administra instantáneas de discos.
Copia de seguridad basada en imágenes
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONReemplaza lo siguiente:
IMAGE_NAME: el nombre de la imagen de disco que deseas crear.PROJECT_NAME: El nombre de tu proyecto de Google Cloud.SOURCE_DISK_NAME: el disco de origen que se usa para crear la imagen.ZONE: la zona del disco de origen en la que se operará.LOCATION: la ubicación de Cloud Storage, ya sea regional o multirregional, en la que se almacenará el contenido de la imagen.Para obtener más información, consulta Crea imágenes personalizadas.
Crea un disco nuevo a partir de la instantánea o imagen.
Para los volúmenes de Hyperdisk, asegúrate de especificar el tamaño del disco, las IOPS y la capacidad de procesamiento para cumplir con los requisitos de carga de trabajo. Para obtener más información sobre el aprovisionamiento de IOPS y capacidad de procesamiento para Hyperdisk, consulta Información sobre el aprovisionamiento de IOPS y la capacidad de procesamiento para Hyperdisk.
Desde una instantánea
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTReemplaza lo siguiente:
NEW_DISK_NAME: nombre del disco que deseas crear.PROJECT_NAME: El nombre de tu proyecto de Google Cloud.DISK_TYPE: el tipo de disco que se creará.DISK_SIZE: el tamaño del disco.ZONE: la zona de los discos que se crearán.SOURCE_SNAPSHOT: la instantánea de origen que se usa para crear los discos.IOPS: las IOPS aprovisionadas del disco que se creará.THROUGHPUT: la capacidad de procesamiento aprovisionada del disco que se creará.
Desde una imagen
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTReemplaza lo siguiente:
NEW_DISK_NAME: nombre del disco que deseas crear.PROJECT_NAME: El nombre de tu proyecto de Google Cloud.DISK_TYPE: el tipo de disco que se creará.DISK_SIZE: el tamaño del disco.ZONE: la zona de los discos que se crearán.SOURE_IMAGE_NAME: la imagen de origen que se aplicará a los discos que se crean.IMAGE_PROJECT_NAME: el proyecto de Google Cloud en el que se resolverán todas las referencias a imágenes y familias de imágenes.IOPS: las IOPS aprovisionadas del disco que se creará.THROUGHPUT: la capacidad de procesamiento aprovisionada del disco que se creará.
Para obtener más información, consulta
gcloud compute disks create.Desconecta el disco existente del sistema SAP HANA:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEReemplaza lo siguiente:
INSTANCE_NAME: el nombre de la instancia en la que se operará.OLD_DISK_NAME: el disco que se desconectará por su nombre de recurso.ZONE: la zona de la instancia en la que se operará.PROJECT_NAME: El nombre de tu proyecto de Google Cloud.
Para obtener más información, consulta
gcloud compute instances detach-disk.Conecta el disco nuevo al sistema SAP HANA:
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEReemplaza lo siguiente:
INSTANCE_NAME: el nombre de la instancia en la que se operará.NEW_DISK_NAME: el nombre del disco que se conectará a la instancia.ZONE: la zona de la instancia en la que se operará.PROJECT_NAME: El nombre de tu proyecto de Google Cloud.
Para obtener más información, consulta
gcloud compute instances attach-disk.Verifica si los puntos de activación se adjuntan de forma correcta:
lsblkDeberías ver un resultado similar al siguiente:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/logInicia tu instancia de SAP HANA a través de la ejecución de uno de los siguientes comandos:
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
Reemplaza
INSTANCE_NUMBERpor el número de instancia para tu sistema SAP HANA.Para obtener más información, consulta Inicia y detén sistemas de SAP HANA.
Valida el tamaño del disco, las IOPS y la capacidad de procesamiento de tu volumen de Hyperdisk nuevo:
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEReemplaza lo siguiente:
DISK_NAME: el nombre del disco que se describirá.ZONE: la zona del disco que se describirá.PROJECT_NAME: El nombre de tu proyecto de Google Cloud.
Para obtener más información, consulta
gcloud compute disks describe.
Clona tu sistema SAP HANA
Puedes crear instantáneas de un sistema SAP HANA existente en Google Cloud para crear un clon exacto del sistema.
Para clonar un sistema SAP HANA de host único, sigue estos pasos:
Crea una instantánea de los datos y los discos de copia de seguridad.
Crea discos nuevos mediante las instantáneas.
En la consola de Google Cloud, ve a la página Instancias de VM.
Haz clic en la instancia que deseas clonar para abrir la página de detalles de la instancia y, luego, haz clic en Clonar.
Conecta los discos que se crearon a partir de las instantáneas.
Para clonar un sistema SAP HANA de varios hosts, sigue estos pasos:
Aprovisiona un sistema SAP HANA nuevo con la misma configuración que el sistema SAP HANA que deseas clonar.
Realiza una copia de seguridad de los datos del sistema original.
Restablece la copia de seguridad del sistema original en el sistema nuevo.
Instala y actualiza la CLI de gcloud
Después de que se implementa una VM para SAP HANA y se instala el sistema operativo, se requiere que Google Cloud CLI esté actualizado para varios fines, como transferir archivos hacia y desde Cloud Storage, interactuar con los servicios de red, etcétera.
Si sigues las instrucciones de la guía de implementación de SAP HANA, la CLI de gcloud se instalará de forma automática.
Sin embargo, si llevas tu propio sistema operativo a Google Cloud como una imagen personalizada o usas una imagen pública anterior proporcionada por Google Cloud, es posible que debas instalar o actualizar la CLI de gcloud.
Para verificar si la CLI de gcloud está instalada y si hay actualizaciones disponibles, abre una terminal o un símbolo del sistema y, luego, ingresa lo siguiente:
gcloud version
Si no se reconoce el comando, la CLI de gcloud no está instalada.
Para instalar la CLI de gcloud, sigue las instrucciones en Instala la CLI de gcloud.
Para reemplazar la versión 140 o anterior de la CLI de gcloud integrada en SLES, sigue estos pasos:
Accede a la VM mediante
ssh.Cambia al superusuario:
sudo suIngresa los siguientes comandos:
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
Habilita el reinicio rápido de SAP HANA
Google Cloud recomienda enfáticamente habilitar SAP HANA Fast Restart para cada instancia de SAP HANA, en especial para instancias más grandes. SAP HANA Fast Restart reduce los tiempos de reinicio en caso de que SAP HANA finalice, pero el sistema operativo permanezca en ejecución.
Como se establece en las secuencias de comandos de automatización que proporciona Google Cloud, la configuración del kernel y el sistema operativo ya son compatibles con el reinicio rápido de SAP HANA.
Debes definir el sistema de archivos tmpfs y configurar SAP HANA.
Para definir el sistema de archivos tmpfs y configurar SAP HANA, puedes seguir los pasos manuales o usar la secuencia de comandos de automatización que proporciona Google Cloud para habilitar el reinicio rápido de SAP HANA. Para obtener más información, consulta los siguientes vínculos:
- Pasos manuales: Habilita el reinicio rápido de SAP HANA
- Pasos manuales: Habilita el reinicio rápido de SAP HANA
Para obtener instrucciones autorizadas completas sobre Fast Restart SAP HANA, consulta la documentación de la opción Fast Restart SAP HANA.
Pasos manuales
Configura el sistema de archivos tmpfs
Después de que las VM del host y los sistemas base de SAP HANA se implementan de forma correcta, debes crear y activar directorios para los nodos de NUMA en el sistema de archivos tmpfs.
Muestra la topología de NUMA de tu VM
Para poder asignar el sistema de archivos tmpfs requerido, debes saber cuántos nodos de NUMA tiene tu VM. Si deseas mostrar los nodos de NUMA disponibles en una VM de Compute Engine, ingresa el siguiente comando:
lscpu | grep NUMA
Por ejemplo, un tipo de VM m2-ultramem-208 tiene cuatro nodos de NUMA, numerados del 0 al 3, como se muestra en el siguiente ejemplo:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
Crea los directorios de nodos de NUMA
Crea un directorio para cada nodo de NUMA en tu VM y configura los permisos.
Por ejemplo, para cuatro nodos de NUMA que están numerados del 0 al 3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SID
Activa los directorios de nodos de NUMA en tmpfs
Activa los directorios del sistema de archivos tmpfs y especifica una preferencia de nodo de NUMA para cada uno con mpol=prefer:
SID especifica el SID con letras mayúsculas.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
Actualiza /etc/fstab
Para asegurarte de que los puntos de activación estén disponibles después de reiniciar el sistema operativo, agrega entradas a la tabla del sistema de archivos, /etc/fstab:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,relatime,mpol=prefer:3
Opcional: Establece límites para el uso de memoria
El sistema de archivos tmpfs puede aumentar o reducirse de forma dinámica.
A fin de limitar la memoria que usa el sistema de archivos tmpfs, puedes establecer un límite de tamaño para un volumen de nodo NUMA con la opción size.
Por ejemplo:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
También puedes limitar el uso de memoria tmpfs general de todos los nodos de NUMA para una instancia determinada de SAP HANA y un nodo del servidor determinado si configuras el parámetro persistent_memory_global_allocation_limit en la sección [memorymanager] del archivo global.ini.
Configuración de SAP HANA para Fast Restart
A fin de configurar SAP HANA para Fast Restart, actualiza el archivo global.ini y especifica las tablas que se almacenarán en la memoria persistente.
Actualiza la sección [persistence] en el archivo global.ini
Configura la sección [persistence] en el archivo global.ini de SAP HANA para hacer referencia a las ubicaciones de tmpfs. Separa cada ubicación de tmpfs con un punto y coma:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
En el ejemplo anterior, se especifican cuatro volúmenes de memoria para cuatro nodos de NUMA, que corresponden a m2-ultramem-208. Si ejecutas en el m2-ultramem-416, debes configurar ocho volúmenes de memoria (0..7).
Reinicia SAP HANA después de modificar el archivo global.ini.
SAP HANA ahora puede usar la ubicación de tmpfs como espacio de memoria persistente.
Especifica las tablas que se almacenarán en la memoria persistente
Especifica particiones o tablas de columnas específicas para almacenarlas en la memoria persistente.
Por ejemplo, para activar la memoria persistente en una tabla existente, ejecuta la consulta de SQL:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Para cambiar el valor predeterminado de las tablas nuevas, agrega el parámetro table_default en el archivo indexserver.ini. Por ejemplo:
[persistent_memory] table_default = ON
Para obtener más información sobre cómo controlar las columnas, las tablas y qué vistas de supervisión proporcionan información detallada, consulta Memoria persistente de SAP HANA.
Pasos automatizados
La secuencia de comandos de automatización que proporciona Google Cloud para habilitar el reinicio rápido de SAP HANA realiza cambios en los directorios /hana/tmpfs*, el archivo /etc/fstab y la configuración de SAP HANA. Cuando ejecutas la secuencia de comandos, es posible que debas realizar pasos adicionales en función de si esta es la implementación inicial de tu sistema SAP HANA o de cambiar el tamaño de la máquina a un tamaño de NUMA diferente.
Para la implementación inicial de tu sistema SAP HANA o cambio del tamaño de la máquina a fin de aumentar la cantidad de nodos de NUMA, asegúrate de que SAP HANA se ejecute durante la ejecución de la secuencia de comandos de automatización que Google Cloud proporciona para habilitar el reinicio rápido de SAP HANA.
Cuando cambies el tamaño de tu máquina a fin de disminuir la cantidad de nodos de NUMA, asegúrate de que SAP HANA se detenga durante la ejecución de la secuencia de comandos de automatización que proporciona Google Cloud para habilitar el reinicio rápido de SAP HANA. Después de ejecutar la secuencia de comandos, debes actualizar de forma manual la configuración de SAP HANA para completar la configuración de reinicio rápido de SAP HANA. Para obtener más información, consulta Configuración de SAP HANA para un reinicio rápido.
Para habilitar el reinicio rápido de SAP HANA, sigue estos pasos:
Establece una conexión SSH con la VM del host.
Cambiar a la raíz:
sudo su -
Descarga la secuencia de comandos
sap_lib_hdbfr.sh:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Haz que el archivo sea ejecutable:
chmod +x sap_lib_hdbfr.sh
Verifica que la configuración no tenga errores:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Si el comando muestra un error, comunícate con el servicio de Atención al cliente de Cloud. Si deseas obtener más información para comunicarte con el equipo de Atención al cliente de Cloud, consulta Obtén asistencia para SAP en Google Cloud.
Ejecuta la secuencia de comandos después de reemplazar el ID del sistema SAP HANA (SID) y la contraseña para el usuario SYSTEM de la base de datos SAP HANA. Para proporcionar la contraseña de forma segura, te recomendamos que uses un secreto en Secret Manager.
Ejecuta la secuencia de comandos con el nombre de un secreto en Secret Manager. Este secreto debe existir en el proyecto de Google Cloud que contiene tu instancia de VM del host.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Reemplaza lo siguiente:
SID: Especifica el SID con letras mayúsculas. Por ejemplo,AHA.SECRET_NAME: Especifica el nombre del secreto que corresponde a la contraseña del usuario del sistema de la base de datos de SAP HANA. Este secreto debe existir en el proyecto de Google Cloud que contiene tu instancia de VM del host.
Como alternativa, puedes ejecutar la secuencia de comandos con una contraseña de texto sin formato. Después de habilitar el reinicio rápido de SAP HANA, asegúrate de cambiar la contraseña. No se recomienda usar una contraseña con texto sin formato, ya que tu contraseña se registraría en el historial de línea de comandos de tu VM.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Reemplaza lo siguiente:
SID: Especifica el SID con letras mayúsculas. Por ejemplo,AHA.PASSWORD: Especifica la contraseña para el usuario del sistema de la base de datos de SAP HANA.
Para obtener una ejecución inicial exitosa, deberías ver un resultado similar al siguiente:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Configura tu canal de asistencia de SAP con SAProuter
Si necesitas permitir que un ingeniero de asistencia de SAP acceda a los sistemas SAP HANA en Google Cloud, puedes hacerlo mediante SAProuter. Lleva a cabo los pasos siguientes:
Inicia la instancia de VM de Compute Engine en la que se instalará el software SAProuter y asigna una dirección IP externa para que la instancia tenga acceso a Internet.
Crea una dirección IP externa estática nueva y, luego, asigna esta dirección IP a la instancia.
Crea y configura una regla de firewall específica de SAProuter en la red. En esta regla, permite solo el acceso entrante y saliente requerido a la red de asistencia de SAP para la instancia de SAProuter.
Limita el acceso entrante y saliente a una dirección IP específica que SAP te proporciona para conectarte, junto con el puerto TCP
3299. Agrega una etiqueta de destino a la regla de firewall e ingresa el nombre de la instancia. Esto garantiza que la regla de firewall se aplique solo a la instancia nueva. Consulta la documentación de las reglas de firewall para obtener detalles adicionales sobre cómo crear y configurar reglas de firewall.Instala el software SAProuter según SAP Note 1628296 (Nota de SAP 1628296) y crea un archivo
saprouttabque permita el acceso de SAP a los sistemas SAP HANA en Google Cloud.Configura la conexión con SAP. Para la conexión a Internet, usa la comunicación de red segura. Para obtener más información, consulta SAP Remote Support – Help (Asistencia remota de SAP: Ayuda).
Configura tu red
Aprovisionas el sistema SAP HANA mediante el uso de VM con la red virtual de Google Cloud. Google Cloud usa redes definidas por software y tecnologías de sistemas distribuidos de vanguardia para alojar y entregar tus servicios en todo el mundo.
En el caso de SAP HANA, crea una red de subred no predeterminada con rangos de direcciones IP de CIDR no superpuestos para cada subred de la red. Ten en cuenta que cada subred y sus rangos de direcciones IP internas se asignan a una sola región.
Una subred abarca todas las zonas de la región en la que se crea.
Sin embargo, cuando creas una instancia de VM, especificas una zona y una subred para la VM. Por ejemplo, puedes crear un conjunto de instancias en subnetwork1 y en la zone1 de la region1, y otro conjunto de instancias en subnetwork2 y en la zone2 de la region1, según tus necesidades.
Una red nueva no tiene reglas de firewall y, por lo tanto, no tiene acceso a la red. Debes crear reglas de firewall que abran el acceso a las instancias de SAP HANA en función de un modelo de privilegios mínimos. Las reglas de firewall se aplican a toda la red y, también, se pueden configurar para aplicar a instancias de destino específicas mediante el mecanismo de etiquetado.
Las rutas son recursos globales, no regionales, que están conectados a una sola red. Las rutas creadas por el usuario se aplican a todas las instancias de una red. Esto significa que puedes agregar una ruta que reenvíe el tráfico de una instancia a otra en la misma red, incluso entre subredes, sin requerir direcciones IP externas.
En el caso de la instancia de SAP HANA, iníciala sin dirección IP externa y configura otra VM como una puerta de enlace NAT para el acceso externo. Esta configuración requiere que agregues la puerta de enlace NAT como una ruta para la instancia de SAP HANA. Este procedimiento se describe en la guía de implementación.
Seguridad
En las siguientes secciones, se analizan las operaciones de seguridad.
Modelo de privilegio mínimo
La primera línea de defensa es restringir quién puede acceder a la instancia mediante firewalls. Mediante la creación de reglas de firewall, puedes restringir todo el tráfico a una red o puedes orientar máquinas en un conjunto dado de puertos a direcciones IP de origen específicas. Debes seguir el modelo de privilegio mínimo para restringir el acceso a las direcciones IP, los protocolos y los puertos específicos que necesitan acceso. Por ejemplo, siempre debes configurar un host de bastión y permitir el acceso SSH al sistema SAP HANA solo desde ese host.
Cambios de configuración
Debes configurar el sistema SAP HANA y el sistema operativo con la configuración de seguridad recomendada. Por ejemplo, asegúrate de que solo se muestren los puertos de red relevantes para permitir el acceso, fortalecer el sistema operativo en el que ejecutas SAP HANA, etcétera.
Consulta las siguientes notas de SAP (se requiere una cuenta de usuario de SAP):
- 1944799: Guidelines for SLES SAP HANA installation (1944799: Lineamientos para la instalación de SAP HANA en SLES)
- 1730999: Recommended configuration changes (1730999: Cambios de configuración recomendados)
- 1731000: Unrecommended configuration changes (1731000: Cambios de configuración no recomendados)
Inhabilita los servicios de SAP HANA innecesarios
Si no necesitas los servicios de aplicación extendidos de SAP HANA (XS de SAP HANA), inhabilita el servicio. Consulta la SAP note 1697613: Removing the SAP HANA XS Classic Engine service from the topology (Nota de SAP 1697613: Quita el servicio XS de SAP HANA clásico de la topología).
Después de inhabilitar el servicio, quita todos los puertos TCP que se abrieron para el servicio. En Google Cloud, esto significa editar las reglas de firewall de la red para quitar estos puertos de la lista de acceso.
Registros de auditoría
Los registros de auditoría de Cloud constan de dos transmisiones de registros: actividad de administrador y acceso a los datos, que Google Cloud genera automáticamente. Estos pueden ayudarte a responder las preguntas “¿Quién hizo qué, dónde y cuándo?” en el proyecto de Google Cloud.
Los registros de actividad del administrador contienen entradas de registro de las llamadas a la API o las acciones administrativas que modifican la configuración o los metadatos de un servicio o proyecto. Este registro siempre está habilitado y todos los miembros del proyecto pueden verlo.
Los registros de acceso a los datos contienen entradas de registro de las llamadas a la API que crean, modifican o leen los datos proporcionados por el usuario y administrados por un servicio, como los datos almacenados en un servicio de base de datos. Este tipo de registro está habilitado de forma predeterminada en el proyecto y puedes acceder a él a través de Cloud Logging o del feed de actividad.
Protege un bucket de Cloud Storage
Si usas Cloud Storage para alojar copias de seguridad de los datos y los registros, asegúrate de usar TLS (HTTPS) mientras envías datos a Cloud Storage desde las instancias para proteger los datos en tránsito. Cloud Storage encripta los datos en reposo automáticamente. Puedes especificar tus propias claves de encriptación si cuentas con un sistema de administración de claves propio.
Documentos de seguridad relacionados
Consulta los siguientes recursos de seguridad adicionales para el entorno de SAP HANA en Google Cloud:
- Centro de seguridad
- Cumplimiento en Google Cloud
- Informe de seguridad de Google Cloud
- Diseño de seguridad de la infraestructura de Google
Alta disponibilidad para SAP HANA en Google Cloud
Google Cloud proporciona una variedad de opciones a fin de garantizar una alta disponibilidad para el sistema SAP HANA, incluidas las funciones de migración en vivo y el reinicio automático de Compute Engine. Estas funciones, junto con el alto porcentaje de tiempo de actividad mensual de las VM de Compute Engine, podrían hacer que el pago y el mantenimiento de los sistemas en espera sean innecesarios.
Sin embargo, si es necesario, puedes implementar un sistema de escalamiento horizontal de varios hosts que incluya hosts en espera para la conmutación por error automática del host de SAP HANA, o puedes implementar un sistema de escalamiento vertical con una instancia de SAP HANA en espera en un clúster de Linux con alta disponibilidad.
Para obtener más información sobre las opciones de alta disponibilidad de SAP HANA en Google Cloud, consulta la guía de planificación de alta disponibilidad de SAP HANA.
Habilita el hook del proveedor de HA/DR de SAP HANA
Recuperación ante desastres
El sistema SAP HANA proporciona varias funciones de alta disponibilidad para garantizar que la base de datos de SAP HANA resista fallas a nivel de software o infraestructura. Entre estas funciones se encuentran la replicación del sistema SAP HANA y las copias de seguridad de SAP HANA, que son compatibles con Google Cloud.
Para obtener más información sobre las copias de seguridad de SAP HANA, consulta Copia de seguridad y recuperación.
Para obtener más información sobre la replicación del sistema, consulta la guía de planificación de recuperación ante desastres de SAP HANA.
Crear copia de seguridad y de recuperación
Las copias de seguridad son vitales para proteger el sistema de registro (tu base de datos). Debido a que SAP HANA es una base de datos en memoria, crear copias de seguridad con regularidad y, luego, implementar una estrategia de copia de seguridad adecuada te ayuda a recuperar la base de datos de SAP HANA en situaciones como daños o pérdida de datos debido a una interrupción no planificada o falla en tu infraestructura. El sistema SAP HANA proporciona funciones de copia de seguridad y recuperación integradas para ayudarte a hacerlo. Puedes usar los servicios de Google Cloud, como Cloud Storage, como destino de la copia de seguridad de SAP HANA.
También puedes habilitar la función de Backint del agente de Google Cloud para SAP para usar Cloud Storage directamente para copias de seguridad y recuperaciones.
En este documento, se supone que estás familiarizado con la copia de seguridad y la recuperación de SAP HANA, junto con las siguientes notas de servicio de SAP:
- 1642148: FAQ: SAP HANA Database Backup & Recovery (1642148: Preguntas frecuentes: Copia de seguridad y recuperación de la base de datos de SAP HANA)
- 1821207: Determining required recovery files (1821207: Determina los archivos de recuperación necesarios)
- 1869119: Checking backups using
hdbbackupcheck. - 1873247: Checking recoverability with
hdbbackupdiag --check. - 1651055: Programa copias de seguridad de la base de datos de SAP HANA en Linux
Usa volúmenes de discos persistentes de Compute Engine y Cloud Storage para crear copias de seguridad
Si seguiste las instrucciones de implementación basadas en Terraform que proporciona Google Cloud para implementar tu sistema SAP HANA, tienes una instalación de SAP HANA con un directorio /hanabackup alojado en un volumen de disco persistente balanceado.
Para crear las copias de seguridad de la base de datos en línea en el directorio /hanabackup, usas las herramientas estándar de SAP, como SAP HANA Studio, SAP HANA Cockpit, transacción de SAP ABAP DB13 o las instrucciones de SQL de SAP HANA. Por último, guarda la copia de seguridad completa mediante su carga en un bucket de Cloud Storage, desde el que puedes descargar la copia de seguridad, cuando necesites recuperar tu sistema SAP HANA.
Usa Compute Engine para crear instantáneas de disco y copias de seguridad
Puedes usar las copias de seguridad de Compute Engine para SAP HANA y, también, tener la opción de crear una copia de seguridad de todo el disco que aloja tus datos de SAP HANA y volúmenes de registro mediante instantáneas de disco estándar.
Si seguiste las instrucciones de la guía de implementación, tienes una instalación de SAP HANA con un directorio /hanabackup para las copias de seguridad de la base de datos en línea. Puedes usar ese mismo directorio para almacenar instantáneas del volumen /hanabackup y mantener una copia de seguridad de los volúmenes de datos y registros de SAP HANA en un momento determinado.
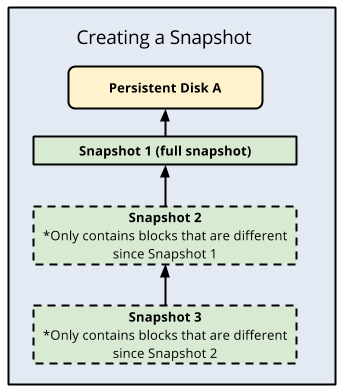
Una ventaja de las instantáneas de disco estándar es que son incrementales, es decir, cada copia de seguridad posterior solo almacena los cambios incrementales en lugar de crear una copia de seguridad nueva. Compute Engine almacena de forma redundante varias copias de cada instantánea en varias ubicaciones con sumas de comprobación automáticas para garantizar la integridad de los datos.
A continuación, se muestra una ilustración de copias de seguridad incrementales:
Cloud Storage como destino de copias de seguridad
Cloud Storage es una buena opción para usar como destino de las copias de seguridad de SAP HANA, ya que proporciona alta durabilidad y disponibilidad de los datos.
Cloud Storage es un almacén de objetos para archivos de cualquier tipo o formato. Tiene almacenamiento casi ilimitado y no tienes que preocuparte por aprovisionarlo o agregarle más capacidad. Un objeto en Cloud Storage consta de datos de archivos y sus metadatos asociados, y puede tener un tamaño de hasta 5 TB. Un bucket de Cloud Storage puede almacenar cualquier cantidad de objetos.
Con Cloud Storage, los datos se almacenan en varias ubicaciones, lo que proporciona alta durabilidad y alta disponibilidad. Cuando subes o copias los datos a Cloud Storage, te informa que la acción tuvo éxito solo si se logra la redundancia del objeto.
En la siguiente tabla, se muestran las opciones de almacenamiento que ofrece Cloud Storage:
| Frecuencia de lectura y escritura de datos | La opción recomendada de Cloud Storage |
|---|---|
| Lecturas o escrituras frecuentes | Elige la clase de almacenamiento estándar para las bases de datos que están en uso, ya que pueden acceder a Cloud Storage con frecuencia para escribir y leer archivos de copia de seguridad. |
| Lecturas o escrituras poco frecuentes | Elige Nearline o Coldline Storage para los datos a los que se accede con poca frecuencia, como las copias de seguridad archivadas que deben mantenerse según la política de retención de tu organización. Nearline es una buena opción para los datos de copia de seguridad a los que planeas acceder una vez al mes, mientras que Coldline es mejor para los datos que tienen una probabilidad muy baja de acceso, como una vez al año como máximo. |
| Datos de archivo | Selecciona Archive Storage para los datos de archivo a largo plazo. Archive es una buena opción para los datos de los que necesitas conservar una copia durante un período prolongado, pero a los que no deseas acceder más de una vez al año. Por ejemplo, usa Archive Storage para las copias de seguridad que necesitas retener a largo plazo para cumplir con los requisitos reglamentarios. Considera reemplazar tu solución de copia de seguridad basada en cinta con Archive. |
Cuando planifiques el uso de estas opciones de almacenamiento, comienza con el nivel de acceso frecuente y mueve los datos de copia de seguridad a los niveles de acceso poco frecuentes. Por lo general, las copias de seguridad se usan con menos frecuencia a medida que se vuelven más antiguas. La probabilidad de necesitar una copia de seguridad que tenga 3 años es muy baja, y puedes agregarla al nivel Archive para ahorrar en costos. Para obtener más información sobre los costos de Cloud Storage, consulta Precios de Cloud Storage.
Cloud Storage en comparación con la copia de seguridad en cinta
El destino local convencional de la copia de seguridad es la cinta. Cloud Storage tiene muchos más beneficios que la cinta, incluida la capacidad de almacenar automáticamente copias de seguridad “fuera del sitio”, ya que los datos en Cloud Storage se replican en varias instalaciones. Esto también significa que las copias de seguridad almacenadas en Cloud Storage tienen alta disponibilidad.
Otra diferencia clave es la velocidad de restablecimiento de las copias de seguridad cuando necesitas usarlas. Si necesitas crear un sistema SAP HANA nuevo o restablecer un sistema existente a partir de una copia de seguridad, Cloud Storage proporciona un acceso más rápido a los datos, lo que te ayuda a compilar el sistema con mayor rapidez.
Función de Backint del agente de Google Cloud para SAP
Puedes usar Cloud Storage directamente para realizar copias de seguridad y recuperaciones de instalaciones locales y en la nube mediante la función de Backint certificada por SAP del agente de Google Cloud para SAP.
Para obtener más información sobre esta función, consulta Copia de seguridad y recuperación basada en Backint para SAP HANA.
Realiza una copia de seguridad y recuperación mediante Backint
En las siguientes secciones, se proporciona información sobre cómo realizar operaciones de copia de seguridad y recuperación mediante la función Backint del agente de Google Cloud para SAP.
- Activa datos y copias de seguridad delta
- Activa copias de seguridad de registros
- Consulta el catálogo de copias de seguridad
- Recupera una base de datos
Activa datos y copias de seguridad delta
Para activar una copia de seguridad del volumen de datos de SAP HANA y enviarla a Cloud Storage mediante la función de Backint del agente de Google Cloud para SAP, puedes usar SAP HANA Studio (SAP HANA Studio), SAP HANA Cockpit, SAP HANA SQL o DBA Cockpit.
Las siguientes son instrucciones de SQL de SAP HANA para activar las copias de seguridad de datos:
Para crear una copia de seguridad completa de la base de datos del sistema, haz lo siguiente:
BACKUP DATA USING BACKINT ('BACKUP_NAME');Reemplaza
BACKUP_NAMEpor el nombre que deseas establecer para la copia de seguridad.Para crear una copia de seguridad completa para una base de datos de usuario:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Reemplaza
TENANT_SIDpor el SID de la base de datos de usuario.Para crear copias de seguridad incrementales y diferenciales, sigue estos pasos:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Reemplaza
BACKUP_TYPEporDIFFERENTIALoINCREMENTAL, según el tipo de copia de seguridad que desees crear.
Existen varias opciones que puedes usar mientras activas las copias de seguridad de datos. Para obtener información sobre estas opciones, consulta la guía de referencia de SQL de SAP HANA Instrucción BACKUP DATA (copia de seguridad y recuperación).
Para obtener más información sobre las copias de seguridad delta y los datos, consulta los documentos de SAP Copias de seguridad de datos y Copias de seguridad delta.
Activa copias de seguridad de registros
Para activar una copia de seguridad del volumen de registro de SAP HANA y enviarla a Cloud Storage con la función de Backint del agente de Google Cloud para SAP, completa los siguientes pasos:
- Crea una copia de seguridad completa de la base de datos. Para obtener instrucciones, consulta la documentación de SAP de tu versión de SAP HANA.
- En el archivo
global.inide SAP HANA, establece el parámetrocatalog_backup_using_backintenyes.
Asegúrate de que el modo de registro de tu sistema SAP HANA sea normal, que es el valor predeterminado. Si el modo de registro está configurado como overwrite, la base de datos de SAP HANA inhabilita la creación de copias de seguridad de registros.
Para obtener más información sobre las copias de seguridad de registros, consulta el documento de SAP Copias de seguridad de registros.
Consulta el catálogo de copia de seguridad
El catálogo de copia de seguridad de SAP HANA es una parte vital de las operaciones de copia de seguridad y recuperación. Contiene información sobre las copias de seguridad creadas para la base de datos de SAP HANA.
Para consultar el catálogo de copia de seguridad con para obtener información sobre las copias de seguridad de una base de datos de usuario, sigue estos pasos:
- Desconecta la base de datos de usuario.
En la base de datos del sistema, ejecuta la siguiente instrucción de SQL:
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
Como alternativa, para consultar un momento específico, ejecuta la siguiente instrucción de SQL:
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
La instrucción crea el archivo
strategyOutput.xmlen el siguiente directorio:/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID.
Para obtener información sobre la instrucción BACKUP LIST DATA, consulta la guía de referencia de SQL de SAP HANA Instrucción BACKUP DATA (copia de seguridad y recuperación).
Para obtener información sobre el catálogo de copias de seguridad, consulta el documento de SAP Catálogo de copia de seguridad.
Recupera una base de datos
Cuando realizas una recuperación mediante una copia de seguridad de datos de varias transmisiones, SAP HANA usa la misma cantidad de canales que se usaron cuando se creó la copia de seguridad. Para obtener más información, consulta el documento de SAP Prerequisites: Recovery Using Multistreamed Backups.
Para restablecer una copia de seguridad de la base de datos de SAP HANA que creaste mediante la función de Backint del agente de Google Cloud para SAP, SAP HANA proporciona las instrucciones de SQL RECOVER DATA y RECOVER DATABASE.
Ambas instrucciones de SQL restablecen las copias de seguridad desde el bucket de Cloud Storage que especificaste para el parámetro bucket en tu archivo PARAMETERS.json, a menos que hayas especificado un bucket para el parámetro recover_bucket:
Las siguientes son instrucciones de SQL de muestra para recuperar una base de datos de SAP HANA mediante una copia de seguridad que creaste mediante la función de Backint del agente de Google Cloud para SAP:
Para recuperar una base de datos de usuario, especifica el nombre del archivo de copia de seguridad:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;Para recuperar una base de datos de usuario mediante la especificación del ID de copia de seguridad, haz lo siguiente:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
Reemplaza
BACKUP_IDpor el ID de la copia de seguridad necesaria.Para recuperar una base de datos de usuario mediante la especificación del ID de copia de seguridad cuando necesitas usar la copia de seguridad del catálogo de copia de seguridad de SAP HANA, que se almacena en tu bucket de Cloud Storage:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
Para recuperar una base de datos de usuario en un momento específico o en una posición de registro específica, haz lo siguiente:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
Para recuperar una base de datos de usuario mediante una copia de seguridad de una base de datos externa, sigue estos pasos:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
Reemplaza lo siguiente:
SOURCE_TENANT_SID: el SID de la base de datos de usuario de origen.SOURCE_SID: el SID del sistema SAP en el que existe la base de datos de usuario de origen
Si necesitas recuperar una base de datos de SAP HANA cuando el catálogo de copia de seguridad de SAP HANA no está disponible en la copia de seguridad almacenada en tu bucket de Cloud Storage, sigue las instrucciones de la nota de SAP 3227931 - Recupera una base de datos de HANA de Backint sin un catálogo de copia de seguridad de HANA.
Administra la identidad y el acceso a las copias de seguridad
Cuando usas Cloud Storage o Compute Engine para crear una copia de seguridad de los datos de SAP HANA, administración de identidades y accesos (IAM) controla el acceso a esas copias de seguridad. Esta característica brinda a los administradores la capacidad de autorizar a los usuarios a realizar acciones en recursos específicos. IAM te proporciona un control centralizado, y visibilidad para administrar todos los recursos de Google Cloud, incluidas las copias de seguridad.
IAM también proporciona un historial completo de registros de auditoría de las autorizaciones, eliminaciones y delegaciones de permisos para los administradores. Esto te permite configurar políticas que supervisan el acceso a los datos en las copias de seguridad, lo que te permite completar el ciclo de control de acceso completo con los datos. IAM proporciona una vista unificada de la política de seguridad en toda la organización, con auditorías integradas para facilitar los procesos de cumplimiento.
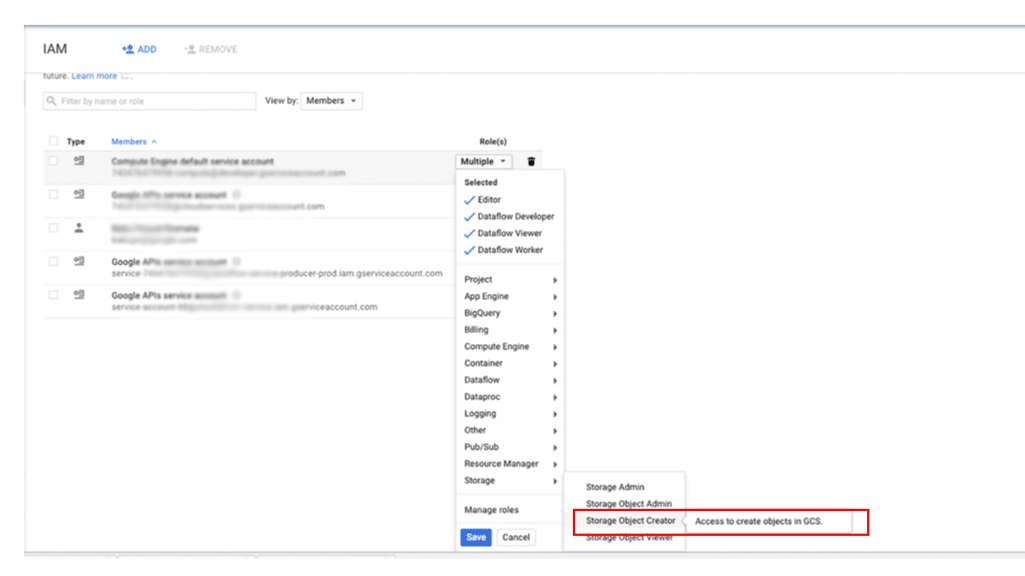
Para otorgar a una principal acceso a tus copias de seguridad en Cloud Storage, sigue estos pasos:
En la consola de Google Cloud, ve a la página IAM y administración.
Especifica el usuario al que deseas otorgar acceso y, luego, asigna el rol Almacenamiento > Creador de objetos de almacenamiento:
Cómo crear copias de seguridad basadas en el sistema de archivos para SAP HANA
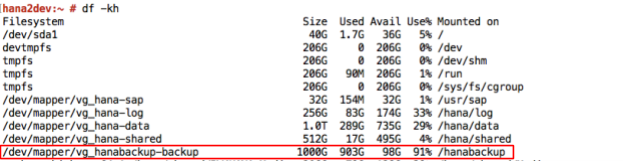
Los sistemas SAP HANA aprovisionados en Google Cloud mediante la guía de implementación se configuran con un conjunto de volúmenes de Persistent Disk o Hyperdisk para usar como destino de copia de seguridad activado por NFS. Las copias de seguridad de SAP HANA se almacenan primero en estos discos locales y, luego, debes copiarlas en Cloud Storage para su almacenamiento a largo plazo. Puedes copiar las copias de seguridad de forma manual en Cloud Storage o programar la copia en Cloud Storage en un crontab.
Si usas la función de Backint del agente de Google Cloud para SAP, entonces crea una copia de seguridad y recupera desde un bucket de Cloud Storage directamente, lo que niega la necesidad de almacenamiento en disco persistente para copias de seguridad.
Para iniciar o programar las copias de seguridad de datos de SAP HANA, puedes usar SAP HANA Studio, los comandos de SQL o Cockpit de DBA. Las copias de seguridad de registros se escriben automáticamente, a menos que estén inhabilitadas. En la siguiente captura de pantalla, se muestra un ejemplo:
Configura global.ini de SAP HANA
Si seguiste las instrucciones de la guía de implementación, el archivo de configuración global.ini de SAP HANA se personaliza con las copias de seguridad de la base de datos almacenadas en /hanabackup/data/ y los archivos de registro automáticos se almacenan en /hanabackup/log/. El siguiente es un ejemplo de cómo se ve global.ini:
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
Para personalizar el archivo de configuración global.ini de la función de Backint del agente de Google Cloud para SAP, consulta Configura SAP HANA para la función de Backint.
Notas para implementaciones de escalamiento horizontal
En una implementación de escalamiento horizontal, una solución de alta disponibilidad que usa la migración en vivo y el reinicio automático funciona de la misma manera que en una configuración de host único. La diferencia principal es que el volumen /hana/shared está activado para NFS en todos los hosts de trabajador y está dominado en la instancia principal de HANA. Hay un período breve de inaccesibilidad en el volumen de NFS en caso de una migración en vivo o un reinicio automático de un host principal. Cuando se reinicia el host principal, el volumen de NFS comienza a funcionar de nuevo en todos los hosts y las operaciones normales se reanudan de forma automática.
El volumen de copia de seguridad de SAP HANA, /hanabackup, debe estar disponible en todos los hosts durante las operaciones de copia de seguridad y recuperación. En caso de falla, debes verificar que /hanabackup esté activado en todos los hosts y volver a activar cualquiera que no lo esté. Cuando elijas copiar el conjunto de copias de seguridad en otro volumen o en Cloud Storage, ejecuta la copia en el host principal para lograr un mejor rendimiento de E/S y reducir el uso de red. A fin de simplificar el proceso de copia de seguridad y recuperación, puedes usar Cloud Storage Fuse para activar el bucket de Cloud Storage en cada host.
El rendimiento del escalamiento horizontal es tan bueno como la distribución de datos. Cuanto mejor se distribuyan los datos, mejor será el rendimiento de tu consulta. Esto requiere que conozcas tus datos, que comprendas cómo se consumen, y que diseñes la distribución y partición de tablas según corresponda. Para obtener más información, consulta la Nota de SAP 2081591 - Preguntas frecuentes: Distribución de tablas de SAP HANA.
Gcloud Python
Gcloud Python es un cliente idiomático de Python que puedes usar para acceder a los servicios de Google Cloud. En esta guía, se usa Gcloud Python a fin de realizar operaciones de copia de seguridad y restablecimiento desde y hacia Cloud Storage para las copias de seguridad de la base de datos de SAP HANA.
Si seguiste las instrucciones de la guía de implementación, las bibliotecas de Gcloud Python ya están disponibles en las instancias de Compute Engine.
Las bibliotecas son de código abierto y te permiten operar en el bucket de Cloud Storage para almacenar y recuperar datos de la copia de seguridad.
Puedes ejecutar el siguiente comando para enumerar objetos en el bucket de Cloud Storage. Puedes usarlo para enumerar las copias de seguridad disponibles:
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Para obtener detalles completos sobre Gcloud Python, consulta la documentación de referencia de la biblioteca cliente de almacenamiento.
Ejemplo de copia de seguridad y restablecimiento
En las siguientes secciones, se ilustra el procedimiento que puedes seguir para una tarea típica de copia de seguridad y restablecimiento con SAP HANA Studio.
Ejemplo de creación de copia de seguridad
En Backup Editor de SAP HANA, selecciona Open Backup Wizard.
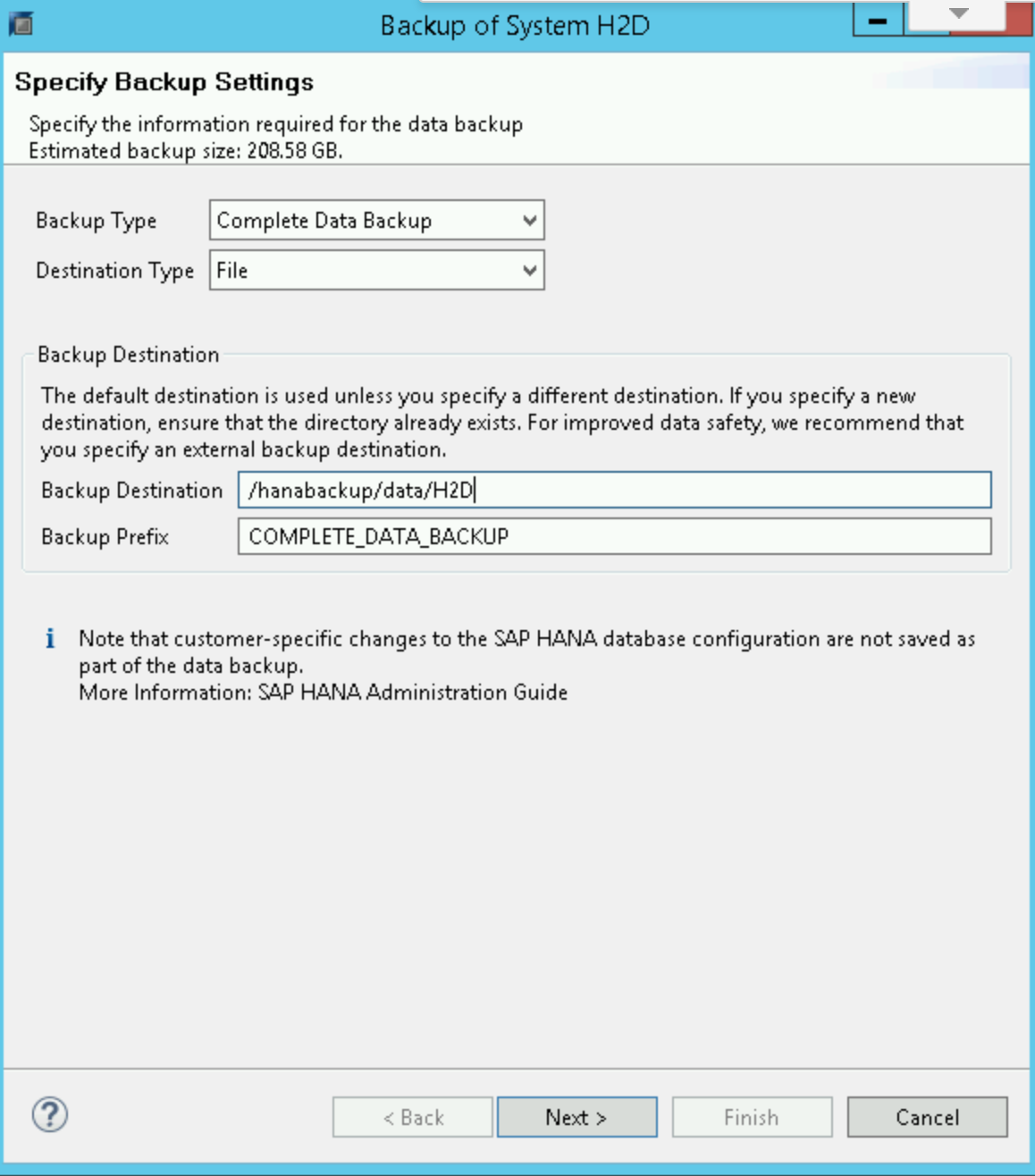
- Selecciona File (Archivo) como el tipo de destino. Esto crea una copia de seguridad de la base de datos en los archivos del sistema de archivos especificado.
- Especifica el destino de la copia de seguridad,
/hanabackup/data/SID, y su prefijo. ReemplazaSIDpor el ID del sistema de tu sistema SAP. - Haz clic en Siguiente.
Haz clic en Finalizar (Finish) en el formulario de confirmación para iniciar la copia de seguridad.
Cuando se inicia la copia de seguridad, aparece una ventana de estado que muestra el progreso de la copia de seguridad. Espera a que se complete la copia de seguridad.
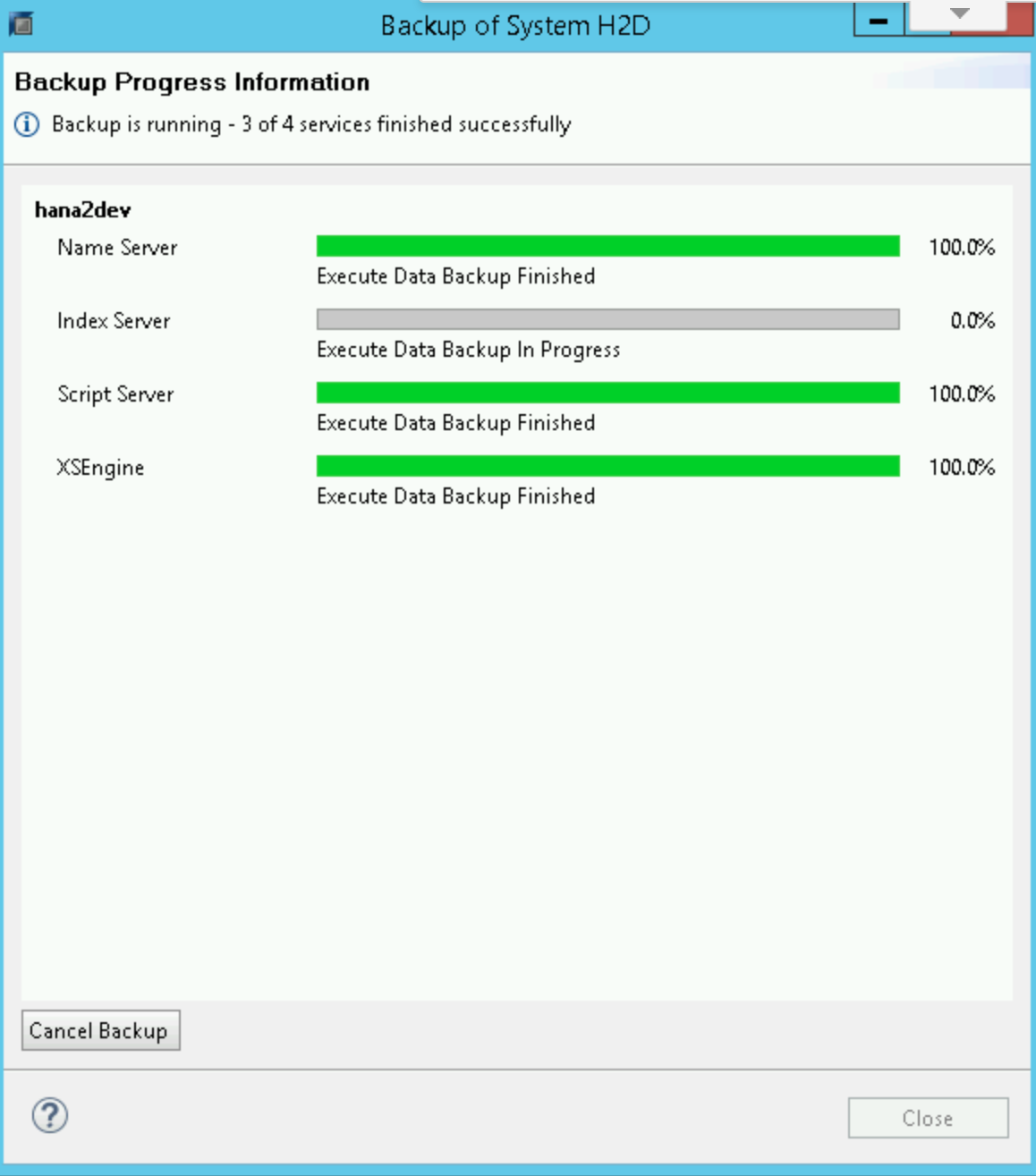
Cuando se completa la copia de seguridad, el resumen de la copia de seguridad muestra un mensaje
Finished.Accede al sistema SAP HANA y verifica que las copias de seguridad estén disponibles en las ubicaciones esperadas en el sistema de archivos. Por ejemplo:
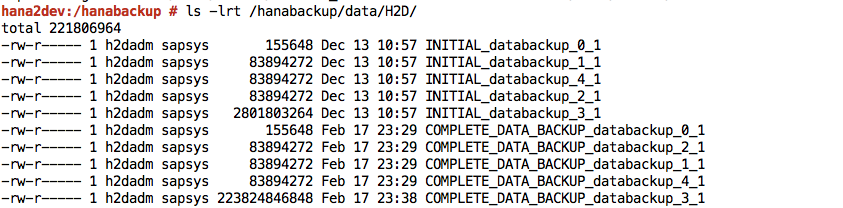

Envía o sincroniza los archivos de copia de seguridad del sistema de archivos
/hanabackupa Cloud Storage. La siguiente secuencia de comandos de Python de muestra envía los datos de/hanabackup/datay/hanabackup/logal bucket que se usa para las copias de seguridad, en el formatoNODE_NAME/DATAoLOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME. Esto te permite identificar los archivos de copia de seguridad según la hora durante la cual se copió la copia de seguridad. Ejecuta esta secuencia de comandosgcloud Pythonen el símbolo bash del sistema operativo:python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFUsa las bibliotecas de Gcloud Python o la consola de Google Cloud para enumerar los datos de la copia de seguridad.
Ejemplo de restablecimiento de una copia de seguridad
Si los archivos de copia de seguridad no están disponibles en el directorio
/hanabackup, pero están disponibles en Cloud Storage, descarga los archivos mediante la ejecución de la siguiente secuencia de comandos desde el símbolo de bash del sistema operativo:python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFPara recuperar la base de datos de SAP HANA, haz clic en Copia de seguridad y recuperación > Recuperar sistema:
Haz clic en Siguiente.
Especifica la ubicación de las copias de seguridad en el sistema de archivos local y haz clic en Agregar.
Haz clic en Siguiente.
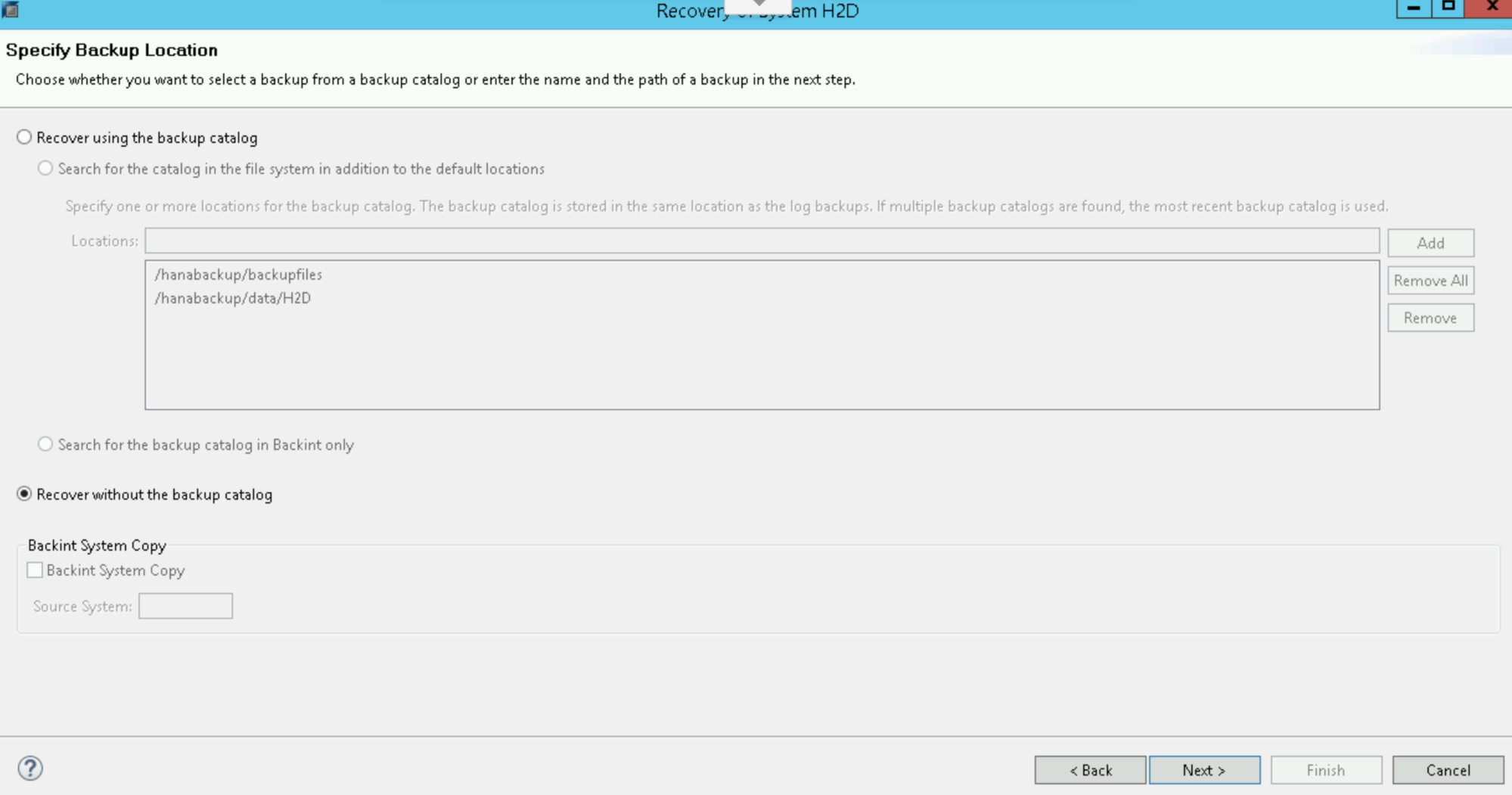
Selecciona Recover without the backup catalog:
Haz clic en Siguiente (Next).
Selecciona Archivo como el tipo de destino y, luego, especifica la ubicación de los archivos de la copia de seguridad y el prefijo correcto para esta. Si seguiste el procedimiento de creación de copia de seguridad de ejemplo, recuerda que
COMPLETE_DATA_BACKUPse estableció como el prefijo.Haz clic en Siguiente (Next) dos veces.
Haz clic en Finalizar (Finish) para iniciar la recuperación.
Cuando se complete la recuperación, reanuda las operaciones normales y quita los archivos de copia de seguridad de los directorios
/hanabackup/data/SID/*.
Próximos pasos
Los siguientes documentos de SAP estándar pueden resultarte útiles:
- SAP HANA Library (Biblioteca de SAP HANA)
- SAP ONE Support Launchpad (Launchpad de asistencia de SAP ONE)
Es posible que también te resulten útiles los siguientes documentos de Google Cloud:
- Oferta gratuita de prueba y funciones en la nube
- Comience a usar Google Cloud
- Compute Engine
- Persistent Disk