ここでは、SAP Data Services(DS)を使用して、SAP アプリケーションまたはその基盤となるデータベースから BigQuery にデータをエクスポートする方法について説明します。
データベースは、SAP HANA データベースなど、SAP でサポートされているデータベースです。
このガイドの例では、SQL Anywhere データベースのテーブルをエクスポートしますが、このテーブルを使用して、SAP アプリケーションとデータベースの両方のレイヤから BigQuery への他の種類のオブジェクトのエクスポートを設定できます。
データ エクスポートを使用して、SAP データをバックアップしたり、SAP システムのデータを BigQuery の他のシステムの消費者データと統合して機械学習から分析情報を導き出したりするなど、ペタバイト規模のデータ分析を行うことができます。
これらの手順は、SAP Basis、SAP DS、Google Cloud の構成に関する基本的な経験がある SAP システム管理者を対象としています。
アーキテクチャ

SAP Data Services は、SAP アプリケーションまたは基盤となるデータベースからデータを取得して BigQuery 形式との互換性を保持するようデータを変換し、BigQuery にデータを移動する読み込みジョブを開始します。読み込みジョブが完了すると、BigQuery でデータを分析できるようになります。
エクスポートは、エクスポート時のソースシステム内のデータのスナップショットです。SAP Data Services がいつエクスポートを開始するかは、ユーザーが制御します。ターゲット BigQuery テーブルの既存のデータは、エクスポートされたデータによって上書きされます。エクスポートが完了すると、BigQuery のデータはソースシステムのデータと同期されなくなります。
このシナリオでは、SAP ソースシステム、SAP Data Services は、Google Cloud 内または外で実行していると想定できます。
コア ソリューション コンポーネント
SAP Data Services を使用して SAP アプリケーションまたはデータベースから BigQuery にデータをエクスポートするには、次のコンポーネントが必要です。
| コンポーネント | 必要なバージョン | 注 |
|---|---|---|
| SAP アプリケーション サーバー スタック | R/3 4.6C 以降の ABAP ベースの SAP システム | このガイドでは、アプリケーション サーバーとデータベース サーバーを別々のマシンで実行している場合でも、ソースシステムと総称されます。 適切な権限で RFC ユーザーを定義する 省略可: ロギング テーブル用に個別のテーブル スペースを定義する |
| Database(DB)システム | SAP Product Availability Matrix(PAM)でサポート対象として表示されている DB バージョン。PAM に表示されている SAP NetWeaver スタックの制限が適用されます。 | |
| SAP Data Services | SAP Data Services 4.2 SP1 以降 | |
| BigQuery | なし |
料金
BigQuery は、Google Cloud の課金対象のコンポーネントです。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを出すことができます。
前提条件
次の手順は、SAP アプリケーション システム、データベース サーバー、SAP Data Services がインストール済みで、通常の操作が行えるよう構成されていることを前提としています。
計画された構成が SAP ライセンス要件を遵守していることを SAP に確認してください。SAP アプリケーション システムからエクスポートするか、基盤となるデータベースからエクスポートするかによって要件が異なる場合があります。
Google Cloud で Google Cloud プロジェクトを設定する
BigQuery を使用するには、Google Cloud プロジェクトが必要です。
Google Cloud プロジェクトを作成する
Google Cloud コンソールに移動し、設定ウィザードの指示に従って登録します。
左上隅にある Google Cloud ロゴの横のプルダウンをクリックして、[新しいプロジェクト] を選択します。
プロジェクトに名前を付けて、[作成] をクリックします。
プロジェクトが作成されたら(右上に通知が表示されます)、ページを更新します。
API の有効化
BigQuery API を有効にします。
サービス アカウントを作成する
サービス アカウント(特にそのキーファイル)は、SAP DS を BigQuery に対して認証するために使用されます。キーファイルは、後でターゲット データストアを作成するときに使用します。
Google Cloud コンソールで、[サービス アカウント] ページに移動します。
Google Cloud プロジェクトを選択します。
[サービス アカウントを作成] をクリックします。
サービス アカウント名を入力します。
[作成して続行] をクリックします。
[ロールを選択] リストで、[BigQuery] > [BigQuery データ編集者] の順に選択します。
[別のロールを追加] をクリックします。
[ロールを選択] リストで、[BigQuery] > [BigQuery ジョブユーザー] の順に選択します。
[続行] をクリックします。
必要に応じて、他のユーザーにサービス アカウントへのアクセス権を付与します。
[完了] をクリックします。
Google Cloud コンソールの [サービス アカウント] ページで、作成したサービス アカウントのメールアドレスをクリックします。
サービス アカウント名で [キー] タブをクリックします。
[鍵を追加] プルダウン メニューをクリックして、[新しい鍵を作成] を選択します。
キーのタイプとして [JSON] を指定します。
[作成] をクリックします。
自動的にダウンロードされたキーファイルを安全な場所に保存します。
SAP システムから BigQuery へのエクスポートの構成
このソリューションの構成には、大きく分けて次の手順が含まれます。
- SAP Data Services の構成
- SAP Data Services と BigQuery 間のデータフローの作成
SAP Data Services の構成
データサービス プロジェクトを作成する
- SAP Data Services Designer アプリケーションを開きます。
- [Project] > [New] > [Project] の順に移動します。
- [Project name] フィールドに名前を指定します。
- [Create] をクリックします。左側の Project Explorer にプロジェクトが表示されます。
ソース データストアを作成する
SAP Data Services のソース データストアとして、SAP アプリケーション システムまたはその基盤となるデータベースを使用できます。エクスポートできるデータ オブジェクトのタイプは、データストアとして SAP アプリケーション システムとデータベースのどちらを使用するかに依存します。
SAP アプリケーション システムをデータストアとして使用する場合は、以下のオブジェクトをエクスポートできます。
- テーブル
- ビュー
- 階層
- ODP
- BAPI(関数)
- IDoc

基盤となるデータベースをデータストア接続として使用する場合は、以下のようなオブジェクトをエクスポートできます。
- テーブル
- ビュー
- ストアド プロシージャ
- その他のデータ オブジェクト

SAP アプリケーション システムとデータベースのデータストア構成については、以下のセクションで説明します。データストア接続やデータ オブジェクトのタイプに関係なく、SAP Data Services データフローでオブジェクトをインポートして使用する手順はほぼ同じです。
SAP アプリケーション レイヤへの接続の構成
次の手順では、SAP アプリケーションへの接続を作成し、Designer オブジェクト ライブラリの該当するデータストア ノードにデータ オブジェクトを追加します。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services プロジェクトを開きます。
- [Project] > [New] > [Datastore] の順に移動します。
- [Datastore Name] に入力します。たとえば、「ECC_DS」と入力します。
- [Datastore type] フィールドで、[SAP Applications] を選択します。
- [Application server name] フィールドに、SAP アプリケーション サーバーのインスタンス名を入力します。
- SAP アプリケーション サーバーのアクセス認証情報を指定します。
- [OK] をクリックします。
SAP データベース レイヤへの接続の構成
SAP HANA
次の手順では、SAP HANA データベースへの接続を作成し、Designer オブジェクト ライブラリの該当するデータストア ノードにデータテーブルを追加します。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services プロジェクトを開きます。
- [Project] > [New] > [Datastore] の順に移動します。
- [Datastore Name] に入力します。たとえば、「HANA_DS」と入力します。
- [Datastore type] フィールドで、[Database] オプションを選択します。
- [Database type] フィールドで、[SAP HANA] オプションを選択します。
- [Database version] フィールドで、データベースのバージョンを選択します。
- データベース サーバーの名前、ポート番号、アクセス認証情報を入力します。
- [OK] をクリックします。
サポートされている他のデータベース
次の手順では、SQL Anywhere への接続を作成し、Designer オブジェクト ライブラリの該当するデータストア ノードにデータテーブルを追加します。
他のサポートされているデータベースへの接続を作成する手順は、これとほとんど同じです。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services プロジェクトを開きます。
- [Project] > [New] > [Datastore] の順に移動します。
- 名前を入力します。たとえば、「SQL_ANYWHERE_DS」と入力します。
- [Datastore type] フィールドで、[Database] オプションを選択します。
- [Database type] フィールドで、[SQL Anywhere] オプションを選択します。
- [Database version] フィールドで、データベースのバージョンを選択します。
- データベース サーバーの名前、データベース名、アクセス認証情報を入力します。
- [OK] をクリックします。
新しいデータストアが、Designer のローカル オブジェクト ライブラリの [Datastore] タブに表示されます。
ターゲット データストアを作成する
次の手順により、サービス アカウントの作成セクションで以前に作成したサービス アカウントを使用する BigQuery データストアを作成します。サービス アカウントにより、SAP Data Services は BigQuery に安全にアクセスできるようになります。
詳細については、SAP Data Services ドキュメントの Obtain your Google service account email および Obtain a Google service account private key file をご覧ください。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services プロジェクトを開きます。
- [Project] > [New] > [Datastore] の順に移動します。
- [Name] フィールドに入力します。たとえば、「BQ_DS」と入力します。
- [Datastore type] フィールドで、[Google BigQuery] を選択します。
- [Web Service URL] オプションが表示されます。ソフトウェアは、デフォルトの BigQuery ウェブサービス URL を使用してオプションを自動的に補完します。
- [Advanced] を選択します。
- SAP Data Services ドキュメントにある BigQuery の Datastore option descriptions に基づいて、詳細オプションを完了します。
- [OK] をクリックします。
新しいデータストアが、Designer のローカル オブジェクト ライブラリの [Datastore] タブに表示されます。
SAP Data Services と BigQuery 間のデータフローを設定する
データフローを設定するには、バッチジョブを作成し、BigQuery ローダーのデータフローを作成して、外部メタデータとしてソーステーブルと BigQuery テーブルを SAP Data Services にインポートする必要があります。
バッチジョブを作成する
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer で SAP Data Services プロジェクトを開きます。
- [Project] > [New] > [Batch Job] の順に移動します。
- [Name] フィールドに入力します。たとえば、「JOB_SQL_ANYWHERE_BQ」と入力します。
- [OK] をクリックします。
データフロー ロジックを作成する
ソーステーブルをインポートする
次の手順により、ソース データストアからデータベース テーブルをインポートし、SAP Data Services で使用できるようにします。
- SAP Data Services Designer アプリケーションを開きます。
- Project Explorer でソース データストアを展開します。
- 右パネルの上にある [External Metadata] オプションを選択します。使用可能なテーブルなど、オブジェクトを含むノードのリストが表示されます。
- インポートするテーブルをリストから選択します。
- 右クリックして、[Import] オプションを選択します。
- これで、インポートされたテーブルがソース データストア ノードのオブジェクト ライブラリで使用できるようになります。
データフローを作成する
- Project Explorer でバッチジョブを選択します。
- 右側のパネルで空のワークスペースを右クリックし、[Add New] > [Dataflow] オプションを選択します。
- [dataflow] アイコンを右クリックして、[Rename] を選択します。
- 名前を「DF_SQL_ANYWHERE_BQ」に変更します。
[dataflow] アイコンをダブルクリックして、データフロー ワークスペースを開きます。
![[dataflow] アイコンの画面キャプチャ。](https://cloud.google.com/static/solutions/sap/docs/images/bigquery/bq-export-dataflow-icon.png?hl=ja)
データフローをインポートして、ソース データストア オブジェクトに接続する
- Project Explorer でソース データストアを展開します。
- データストアから、ソーステーブルをデータフロー ワークスペースにドラッグ&ドロップします(テーブルをワークスペースにドラッグするときに [Make Source] オプションを選択します)。この手順では、データストアの名前は「SQL_ANYWHERE_DS」です。データストアの名前は異なる場合があります。
- オブジェクト ライブラリの [Transforms] タブの [Platform] ノードから Query トランスフォームをデータフローにドラッグします。
- ワークスペース内のソーステーブルを Query トランスフォームに接続します。
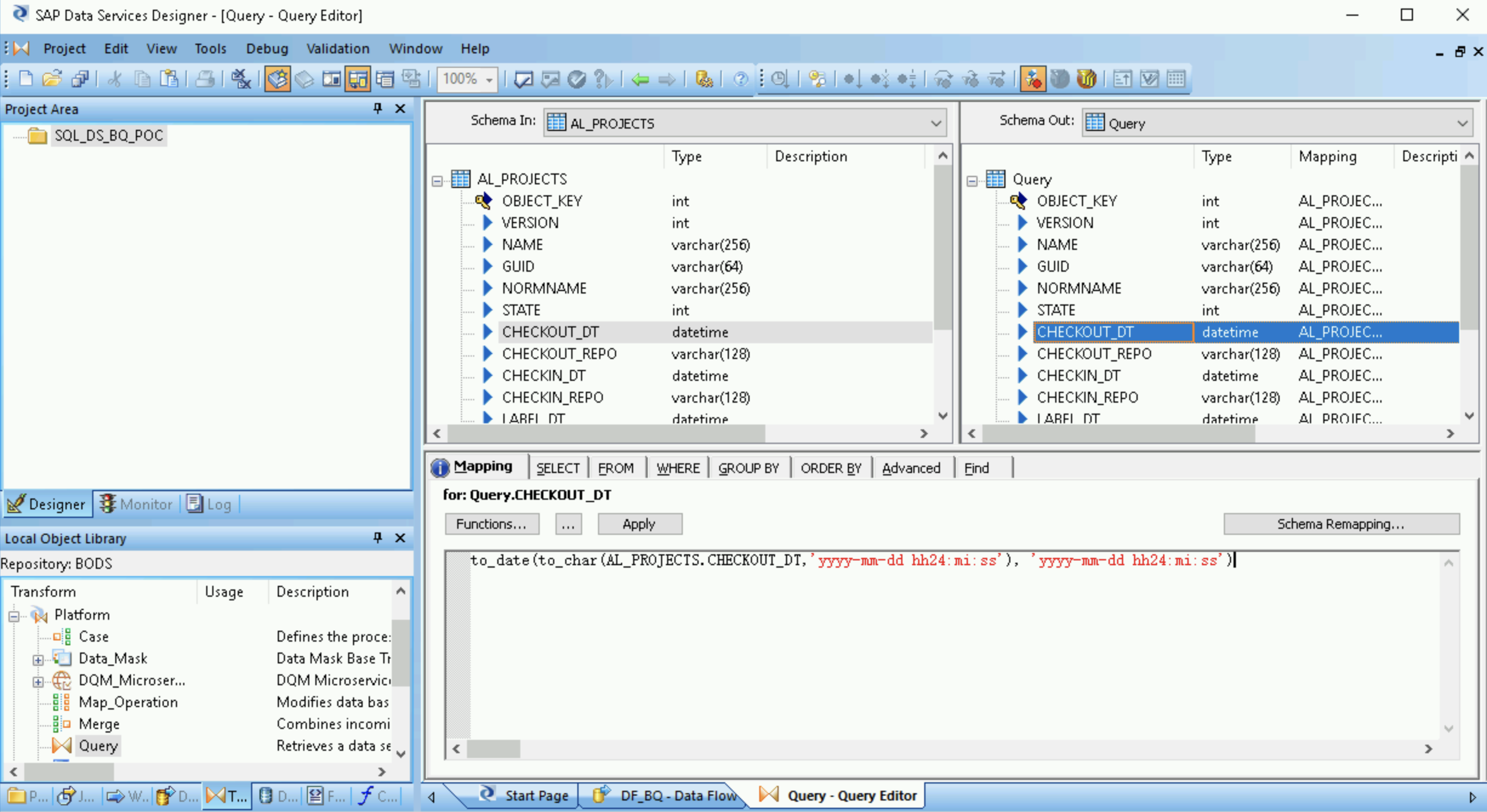
- Query トランスフォームをダブルクリックします。
左側の [Schema In] の下にあるすべてのテーブル フィールドを選択し、右側の [Schema Out] にドラッグします。
- 右の [Schema Out] リストで [datetime] フィールドを選択します。
- スキーマリストの下の [Mapping] タブを選択します。
フィールド名を次の関数に置き換えます。
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
ここで、「FIELDNAME」は、選択したフィールドの名前です。
アプリケーション ツールバーにある [Back] アイコンをクリックして、Dataflow Editor に戻ります。
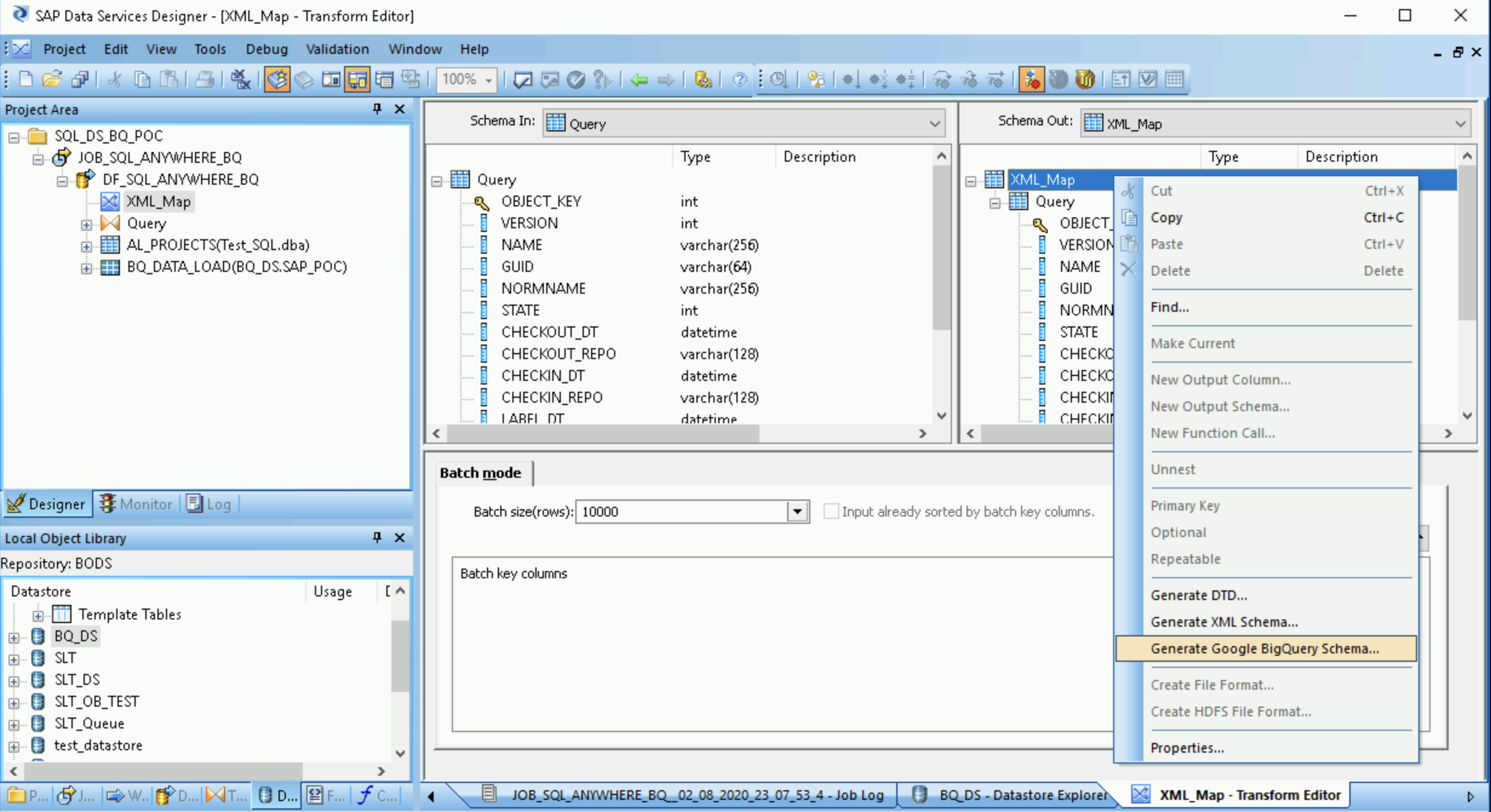
オブジェクト ライブラリの [Transforms] タブの [Platform] ノードから XML_Map トランスフォームをデータフローにドラッグします。
ダイアログで [Batch mode] を選択します。
Query トランスフォームを XML_Map トランスフォームに接続します。
Query トランスフォーム > XML map のフローを表すアイコンの画面キャプチャ。" class="l10n-absolute-url-src screenshot" l10n-attrs-original-order="src,alt,class" src="https://cloud.google.com/static/solutions/sap/docs/images/bigquery/bq-export-dataflow-to-xml-map.png" />
スキーマ ファイルを作成する
次の手順により、ソーステーブルの構造を反映するスキーマ ファイルが生成されます。その後、スキーマ ファイルを使用して BigQuery テーブルを作成します。
このスキーマにより、BigQuery ローダーのデータフローが新しい BigQuery テーブルに入力されます。
- XML_Map トランスフォームを開き、BigQuery テーブルに含まれているデータに基づいて入力スキーマと出力スキーマのセクションを完成させます。
- [Schema Out] 列の [XML_Map] ノードを右クリックし、プルダウン メニューから [Generate Google BigQuery Schema] を選択します。
- スキーマの名前と場所を入力します。
- [Save] をクリックします。
SAP Data Services は、.json ファイル拡張子を持つスキーマ ファイルを生成します。
BigQuery テーブルを作成する
データ読み込み用に、Google Cloud 上の BigQuery データセットにテーブルを作成する必要があります。SAP Data Services で作成したスキーマを使用して、テーブルを作成します。
テーブルは、前の手順で生成したスキーマに基づいています。
- Google Cloud コンソールで、Google Cloud プロジェクトにアクセスします。
- [BigQuery] を選択します。
- 該当するデータセットをクリックします。
- [テーブルを作成] をクリックします。
- テーブルの名前を入力します。例:
BQ_DATA_LOAD。 - [スキーマ] で設定を切り替え、[テキストとして編集] モードを有効にします。
- スキーマ ファイルを作成するで作成したスキーマ ファイルの内容をコピーして貼り付けることにより、BigQuery で新しいテーブルのスキーマを設定します。
- [テーブルを作成] をクリックします。
BigQuery テーブルをインポートする
次の手順により、前の手順で作成した BigQuery テーブルをインポートし、SAP Data Services で使用できるようにします。
- SAP Data Services Designer オブジェクト ライブラリで、BigQuery データストアを右クリックし、[Refresh Object Library] オプションを選択します。これにより、データフローで使用できるデータソース テーブルのリストが更新されます。
- BigQuery データストアを開きます。
- 右パネルの上にある、[External Metadata] を選択します。作成した BigQuery テーブルが表示されます。
- 該当する BigQuery のテーブル名を右クリックして、[Import] を選択します。
- 選択したテーブルの SAP Data Services へのインポートが開始されます。これで、テーブルがターゲット データストア ノードのオブジェクト ライブラリで使用できるようになります。
データフローをインポートして、ターゲット データストア オブジェクトに接続する
- オブジェクト ライブラリのデータストアから、インポートした BigQuery テーブルをデータフローにドラッグします。この手順では、データストアの名前は
BQ_DSです。データストアの名前は異なる場合があります。 XML_Map トランスフォームをインポートされた BigQuery テーブルに接続します。
Query トランスフォーム > XML map > BigQuery テーブルのフローを表すアイコンの画面キャプチャ。" class="l10n-absolute-url-src screenshot" l10n-attrs-original-order="src,alt,class" src="https://cloud.google.com/static/solutions/sap/docs/images/bigquery/bq-export-dataflow-complete.png" />
XML_Map トランスフォームを開き、BigQuery テーブルに含まれているデータに基づいて入力スキーマと出力スキーマのセクションを完成させます。
ワークスペースで BigQuery テーブルをダブルクリックして開き、次の表に示すように [Target] タブのオプションを完了します。
オプション 説明 ポートの作成 [No] を指定します。これはデフォルトです。
[Yes] を指定すると、ソースファイルまたはターゲット ファイルが埋め込みデータフロー ポートになります。モード 初期ロードに [Truncate] を指定します。これにより、BigQuery テーブル内の既存のレコードが SAP Data Services によってロードされたデータに置き換えられます。デフォルトは [Truncate] です。 ローダー数 正の整数を指定して、処理に使用するローダー(スレッド)の数を設定します。デフォルトは 4 です。
各ローダーは、BigQuery で再開可能な読み込みジョブを 1 つ開始します。任意のローダー数を指定できます。
適切なローダー数を判断するには、以下を含む SAP のドキュメントをご覧ください。
1 回のローダーで失敗できる記録の最大数 0 または正の整数を指定して、BigQuery が記録の読み込みを停止するまでに、1 回の読み込みジョブで失敗できる記録の最大数を設定します。デフォルトはゼロ(0)です。 上のツールバーにある [Validate] アイコンをクリックします。
アプリケーション ツールバーにある [Back] アイコンをクリックして、Dataflow Editor を終了します。
BigQuery へのデータの読み込み
次の手順により、レプリケーション ジョブを開始し、SAP Data Services でデータフローを実行してソースシステムから BigQuery にデータをロードします。
ロードを実行すると、ソース データセット内のすべてのデータが、ロード データフローに接続されているターゲット BigQuery テーブルに複製されます。ターゲット テーブルのデータはすべて上書きされます。
- SAP Data Services Designer で、Project Explorer を開きます。
- レプリケーション ジョブ名を右クリックして、[Execute] を選択します。
- [OK] をクリックします。
- 読み込みプロセスが開始し、SAP Data Services ログにデバッグ メッセージが表示され始めます。データは、初期ロードのために BigQuery で作成したテーブルに読み込まれます。この手順では、ロードテーブルの名前は
BQ_DATA_LOADです。テーブルの名前は異なる場合があります。 - 読み込みが完了したかどうかを確認するには、Google Cloud コンソールに移動して、テーブルを含む BigQuery データセットを開きます。データがまだ読み込み中の場合、テーブル名の横に「読み込み中」と表示されます。
読み込み後、データは BigQuery で処理できる状態になります。
負荷のスケジューリング
SAP Data Services Management Console を使用して、読み込みジョブを定期的に実行するようにスケジュールできます。
- SAP Data Services Management Console アプリケーションを開きます。
- [Administrator] をクリックします。
- 左側のメニューツリーで [Batch] ノードを展開します。
- SAP Data Services リポジトリの名前をクリックします。
- [Batch Job Configuration] タブをクリックします。
- [Add Schedule] をクリックします。
- [Schedule name] に入力します。
- [Active] にチェックを入れます。
- [Select scheduled time for executing the jobs] セクションで、デルタロードの実行頻度を指定します。
- 重要: Google Cloud では、1 日に実行できる BigQuery 読み込みジョブの数に上限があります。スケジュールが上限を超えないようにしてください。上限を引き上げることはできません。BigQuery の読み込みジョブ制限の詳細については、BigQuery ドキュメントの割り当てと上限をご覧ください。
[Apply] をクリックします。
![SAP Data Services Management Console の [Schedule Batch Job] タブの画面キャプチャ。](https://cloud.google.com/static/solutions/sap/docs/images/bigquery/bq-export-sap-ds-data-mgmt-console.png?hl=ja)
次のステップ
BigQuery で複製されたデータをクエリおよび分析します。クエリの詳細については、以下をご覧ください。
- BigQuery ドキュメントの BigQuery データのクエリの概要。
SAP Landscape Transformation Replication Server と SAP Data Services を使用して SAP アプリケーションから BigQuery にデータをほぼリアルタイムで複製するソリューションを設定する方法の詳細については、以下をご覧ください。
Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。