本文档介绍如何确定从本地硬件到 Google Cloud 的合适资源映射方式。如果您的应用在裸机服务器上运行,并且您希望将您的应用迁移到 Google Cloud,则可能需要考虑以下问题:
- 物理核心 (pCPU) 如何映射到 Google Cloud 上的虚拟 CPU (vCPU)?例如,如何将裸机 Xeon E5 的 4 个物理核心映射到 Google Cloud 中的 vCPU?
- 如何考虑不同 CPU 平台和处理器世代之间的性能差异?例如,3.0 GHz Sandy Bridge 比 2.0 GHz Skylake 快 1.5 倍吗?
- 如何根据工作负载合理调整资源容量?例如,如何优化在多核服务器上运行的内存密集型单线程应用?
插座 (Socket)、CPU、核心和线程
插座、CPU、核心和线程这四个术语通常可以互换使用,这可能会导致在不同环境之间迁移时出现混淆。
简而言之,一个服务器可以具有一个或多个插座。插座(也称为 CPU 插座或 CPU 插槽 (Slot)) 是主板上装有 CPU 芯片的连接器,提供 CPU 和电路板之间的物理连接。
CPU 指的是实际的集成电路 (IC)。CPU 的基本操作是执行存储的指令序列。概括来讲,CPU 遵循提取、解码和执行步骤,这些步骤统称为指令周期。在更复杂的 CPU 中,可同时提取、解码和执行多个指令。
每个 CPU 芯片可以具有一个或多个核心。核心本质上由执行单元组成,该单元接收指令并根据这些指令执行操作。在超线程系统中,物理处理器核心允许将其资源分配为多个逻辑处理器。换句话说,每个物理处理器核心都作为两个虚拟(即逻辑)核心提供给操作系统。
下图高度概括地展示了一个已启用超线程的四核 CPU。

在 Google Cloud 中,每个 vCPU 实现为某个可用的 CPU 平台上的单个超线程。
要确定系统中的 vCPU(逻辑 CPU)总数,您可以使用以下公式:
vCPU 数 = 每个物理核心的线程数 × 每个套接字的物理核心数 × 套接字数
lscpu 命令用于收集包含插座数、CPU 数、核心数和线程数的信息。此外,它还包含有关 CPU 缓存以及缓存共享、系列、模型和 BogoMips 的信息。以下是一些典型输出:
... Architecture: x86_64 CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 CPU MHz: 2200.000 BogoMIPS: 4400.00 ...
在您的现有环境与 Google Cloud 之间映射 CPU 资源时,请务必了解您的服务器有多少物理核心或虚拟核心。如需了解详情,请参阅映射资源部分。
CPU 时钟频率
要让程序执行,必须将其分解为处理器可以理解的一组指令。请考虑以下 C 程序,该程序会将两个数字相加并显示结果:
#include <stdio.h>
int main()
{
int a = 11, b = 8;
printf("%d \n", a+b);
}
编译时,该程序会转换为以下汇编代码:
...
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $11, -8(%rbp)
movl $8, -4(%rbp)
movl -8(%rbp), %edx
movl -4(%rbp), %eax
addl %edx, %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
...
上文输出中的每个汇编指令都对应单个机器指令。例如,pushq 指令指示应将 RBP 寄存器的内容推送到程序堆栈。在每个 CPU 周期中,CPU 可以执行基本操作,例如提取指令、访问寄存器内容或写入数据。要逐步完成周期中的每个阶段以将两个数值相加,请参阅此 CPU 模拟器。
请注意,每个 CPU 指令可能需要多个时钟周期才能执行。 程序的每个指令所需的平均时钟周期数由每个指令的周期数 (CPI) 定义,如下所示:
每个指令的周期数 = 使用的 CPU 周期数 / 执行的指令数
大多数新型 CPU 都可通过指令流水线操作在每个时钟周期执行多条指令。每个周期执行的平均指令数由每个周期的指令数 (IPC) 定义,如下所示:
每个周期的指令数 = 执行的指令数 / 使用的 CPU 周期数
CPU 时钟频率定义了处理器每秒可以执行的时钟周期数。例如,3.0 GHz 处理器每秒可以执行 30 亿个时钟周期。这意味着每个时钟周期的执行时间约为 0.3 纳秒。在每个时钟周期内,CPU 可以执行由 IPC 定义的一个或多个指令。
时钟频率通常用于比较处理器性能。根据其字面定义(每秒执行的周期数),您可能会得出以下结论:时钟周期数越大,CPU 可以执行的工作就越多,性能也因此越好。在比较相同处理器世代中的 CPU 时,此结论可能是有效的。但是,如果比较不同处理器系列中的 CPU,则不应将时钟频率用作唯一的性能指标。即使新一代 CPU 的运行时钟频率低于上一代 CPU,也可能会提供更好的性能。
时钟频率和系统性能
为了更好地了解处理器的性能,您必须不仅要看时钟周期数,还要看 CPU 在每个周期可以完成的工作量。受 CPU 限制的程序的总执行时间不仅取决于时钟频率,还取决于其他因素,例如要执行的指令数、每个指令的周期数或每个周期的指令数、指令集架构、调度和分派算法以及所用的编程语言。对于不同的处理器世代,这些因素可能也有较大差异。
要了解 CPU 执行情况在两种不同实现之间有何不同,不妨设想一个简单的阶乘程序示例。以下其中一个程序是使用 C 语言编写,而另一个是使用 Python 编写。 Perf(适用于 Linux 的分析工具)用于获取 CPU 和内核的部分指标。
C 程序
#include <stdio.h>
int main()
{
int n=7, i;
unsigned int factorial = 1;
for(i=1; i<=n; ++i){
factorial *= i;
}
printf("Factorial of %d = %d", n, factorial);
}
Performance counter stats for './factorial':
...
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
45 page-faults # 0.065 M/sec
1,562,075 cycles # 1.28 GHz
1,764,632 instructions # 1.13 insns per cycle
314,855 branches # 257.907 M/sec
8,144 branch-misses # 2.59% of all branches
...
0.001835982 seconds time elapsed
Python 程序
num = 7
factorial = 1
for i in range(1,num + 1):
factorial = factorial*i
print("The factorial of",num,"is",factorial)
Performance counter stats for 'python3 factorial.py':
...
7 context-switches # 0.249 K/sec
0 cpu-migrations # 0.000 K/sec
908 page-faults # 0.032 M/sec
144,404,306 cycles # 2.816 GHz
158,878,795 instructions # 1.10 insns per cycle
38,254,589 branches # 746.125 M/sec
945,615 branch-misses # 2.47% of all branches
...
0.029577164 seconds time elapsed
突出显示的输出显示了执行每个程序所用的总时间。用 C 语言编写的程序的执行速度要比用 Python 编写的程序快约 15 倍(1.8 毫秒与 30 毫秒)。以下是一些其他比较:
上下文切换。如果系统调度程序需要运行其他程序或者某一中断触发了正在进行的执行时,操作系统会保存正在运行的程序的 CPU 寄存器内容,并为新程序执行设置这些内容。在 C 程序执行期间没有发生任何上下文切换,但在 Python 程序执行期间发生了 7 次上下文切换。
CPU 迁移。操作系统会尝试在多处理器系统的可用 CPU 之间保持工作负载平衡。系统会定期完成此平衡,而且只要 CPU 运行队列为空时,也会完成此平衡。在测试期间,未观察到 CPU 迁移。
指令。C 程序生成的 170 万条指令会在 150 万个 CPU 周期内执行(IPC = 1.13,CPI = 0.88),而 Python 程序生成的 1.58 亿条指令会在 1.44 亿个周期内执行(IPC = 1.10,CPI = 0.91)。两个程序都填满了流水线,允许 CPU 在每个周期运行多个指令。但为 Python 生成的指令数大约是 C 的 90 倍。
页面错误。每个程序都有一个虚拟内存片,其中包含其所有指令和数据。通常,将所有这些指令都复制到主内存效率并不高。每当程序需要将其在虚拟内存中的部分内容复制到主内存时,就会发生页面错误。CPU 通过中断发出页面错误通知。
由于 Python 的解释器可执行文件比 C 要大得多,因此就 CPU 周期(C 为 150 万个,Python 为 1.44 亿个)和页面错误(C 为 45 个,Python 为 908 个)而言,Python 的额外开销很明显。
分支和分支未命中。对于条件指令,CPU 甚至会在评估分支条件之前尝试预测执行路径。此类步骤有助于保持指令流水线处于已填满状态。 此过程称为推测执行。推测执行在前面的执行中非常成功:分支预测器在 C 程序中只有 2.59% 的时间是错误的,而在 Python 程序中只有 2.47% 的时间是错误的。
CPU 之外的其他因素
到目前为止,您已经了解了 CPU 的各个方面及其对性能的影响。但是,一个应用持续占用 100% 的 CPU 执行时间很少见。举个简单的例子,设想在 Linux 中使用以下 tar 命令从用户的 home 目录创建归档文件:
$ time tar cf archive.tar /home/"$(whoami)"
输出如下所示:
real 0m35.798s user 0m1.146s sys 0m6.256s
这些输出值的定义如下:
- 实际时间
- 实际时间 (
real) 是从头到尾执行的时间。此已用时间包括其他进程使用的时间片以及进程被阻止的时间,例如等待 I/O 操作完成的时间。 - 用户时间
- 用户时间 (
user) 是进程中执行用户空间代码所花费的 CPU 时间。 - 系统时间
- 系统时间 (
sys) 是进程中执行内核空间代码所花费的 CPU 时间。
在上述示例中,用户时间为 1.0 秒,而系统时间为 6.3 秒。real 时间与 user + sys 时间之和相差约 28 秒,表示 tar 命令所花费的 CPU 等待时间。
如果某次执行的 CPU 等待时间较长,则表明进程不受 CPU 限制。如果资源成为实现预期性能的瓶颈,我们可以说计算受该资源限制。在规划迁移时,请务必全面了解应用,并考虑可能会对性能产生有意义影响的所有因素。
目标工作负载在迁移中的角色
为了找到合理的迁移起点,请务必对底层资源进行基准测试。您可以通过各种方式进行性能基准测试:
实际目标工作负载:在目标环境中部署应用,并对关键性能指标 (KPI) 进行性能基准测试。例如,Web 应用的 KPI 可以包含以下内容:
- 应用加载时间
- 端到端事务的最终用户延迟时间
- 舍弃连接数
- 低流量、平均流量和峰值流量的服务实例数
- 服务实例的资源(CPU、RAM、磁盘、网络)利用率
但是,部署完整(或部分)目标应用可能很复杂,而且非常耗时。对于初步基准测试,通常首选基于程序的基准测试。
基于程序的基准测试:基于程序的基准测试侧重于应用的各个组件,而不是端到端应用流。这些基准测试运行各种测试配置文件,其中每个配置文件都针对应用的一个组件。例如,LAMP 堆栈部署的测试配置文件可包括用于对 Web 服务器性能进行基准测试的 Apache Bench 以及用于对 MySQL 进行基准测试的 Sysbench。这些测试通常比实际目标工作负载更容易设置,而且在不同的操作系统和环境中具有高度可移植性。
内核或合成基准测试:要测试来自实际程序的关键计算密集型方面,您可以使用矩阵分解或 FFT 等合成基准。您通常在早期应用设计阶段运行这些测试。 它们最适合仅对机器的某些方面(例如虚拟机和驱动压力、I/O 同步以及缓存抖动)进行基准测试。
了解您的应用
许多应用受 CPU、内存、磁盘 I/O 和网络 I/O 限制或者同时受这些因素中的几个因素限制。例如,如果应用因磁盘争用而运行缓慢,则为服务器提供更多核心可能不会改善性能。
请注意,在复杂的大型环境中保持应用的可监测性可能非常重要。有专门的监控系统可以跟踪系统范围内的所有分布式资源。例如,在 Google Cloud 上,您可以使用 Cloud Monitoring 全面深入了解您的代码、应用和基础架构。本部分稍后将讨论 Cloud Monitoring 示例,但首先应了解如何监控独立服务器上的典型系统资源。
许多实用程序(如 top、IOStat、VMStat 和 iPerf)都能让您高度概括地了解系统资源。例如,在 Linux 系统上运行 top 会生成如下输出:
top - 13:20:42 up 22 days, 5:25, 18 users, load average: 3.93 2.77,3.37 Tasks: 818 total, 1 running, 760 sleeping, 0 stopped, 0 zombie Cpu(s): 88.2%us, 0.0%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 49375504k total, 6675048k used, 42700456k free, 276332k buffers Swap: 68157432k total, 0k used, 68157432k free, 5163564k cached
如果系统具有高负载且等待时间百分比较高,则表示您可能拥有受 I/O 限制的应用。如果用户百分比时间或系统百分比时间中的一个或两个非常高,则表示您可能拥有受 CPU 限制的应用。
在前面的示例中,最后 5 分钟、10 分钟和 15 分钟的负载平均值(对于一台配备了 4 个 vCPU 的虚拟机)分别为 3.93、2.77 和 3.37。如果将这些平均值与较高的用户时间百分比 (88.2%)、较低的闲置时间 (0.3%) 和无等待时间 (0.0%) 相结合,则可以得出系统受 CPU 限制这一结论。
虽然这些工具对于独立系统很实用,但通常不适合监控大型分布式环境。为了监控生产系统,Cloud Monitoring、Nagios、Prometheus 和 Sysdig 等工具可以针对您的应用提供深入的资源消耗分析。
通过在足够长的时间段内对您的应用进行性能监控,您可以跨多个指标(如 CPU 利用率、内存用量、磁盘 I/O、网络 I/O、往返时间、延迟时间、错误率和吞吐量)收集数据。例如,以下 Cloud Monitoring 图显示了Google Cloud 托管实例组中运行的所有服务器的 CPU 负载和利用率水平以及内存用量和磁盘使用率。如需详细了解此设置,请参阅 Cloud Monitoring 代理概览。
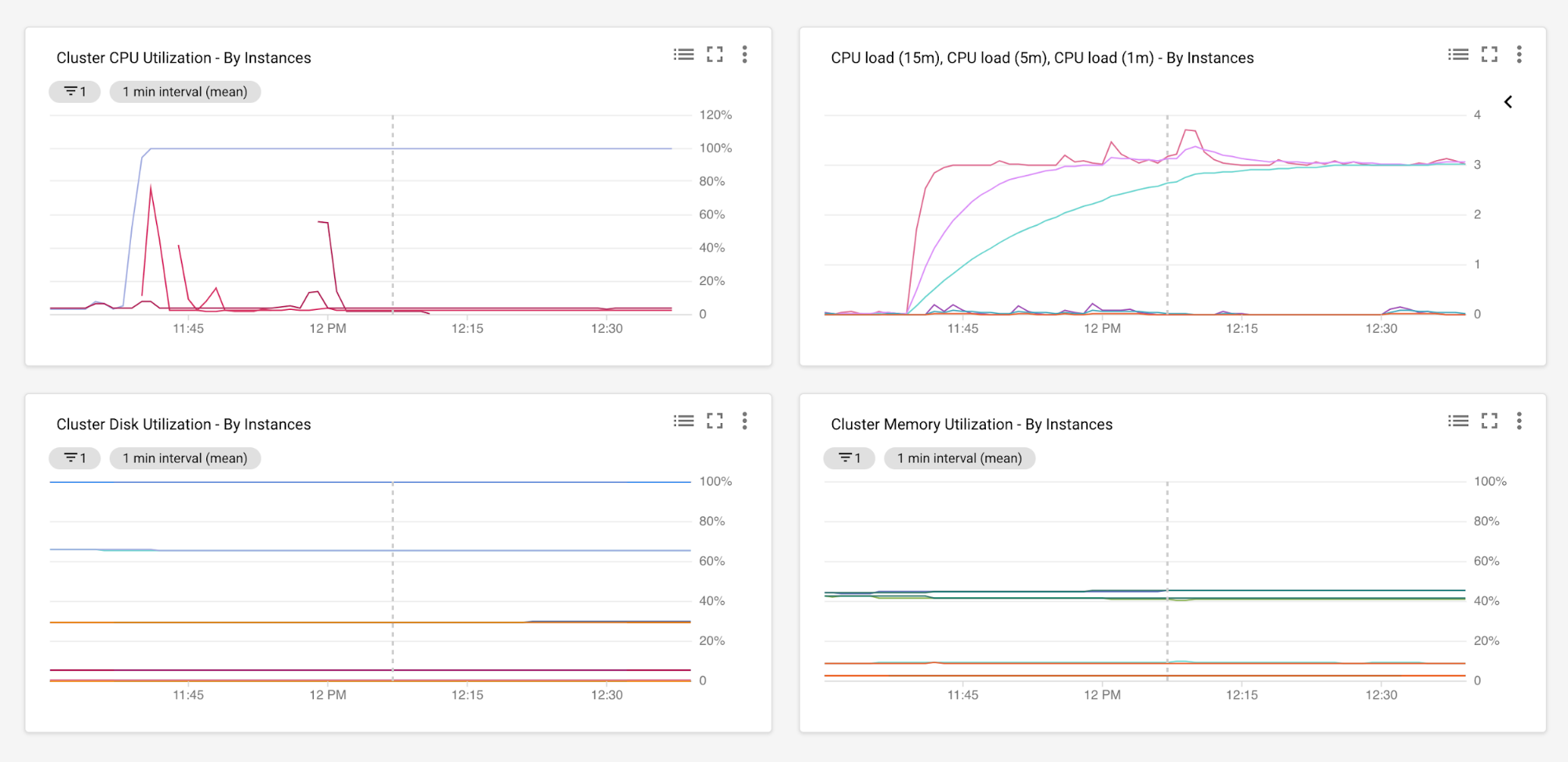
为了进行分析,数据收集时间段应足够长,以显示资源的峰值和低谷利用率。然后,您可以分析收集的数据,为新目标环境中的容量规划提供起点。
映射资源
本部分介绍如何在 Google Cloud 上确定资源容量。首先,您需要根据现有资源利用率水平进行初始容量评估。然后,您可以运行特定于应用的性能基准测试。
基于使用情况的容量调整
按照以下步骤将服务器的现有核心数映射到 Google Cloud 中的 vCPU。
确定当前核心数。请参阅前面部分中的
lscpu命令确定服务器的 CPU 利用率。CPU 使用率是指 CPU 在用户模式 (
%us) 或内核模式 (%sy) 下花费的时间。Nice 进程 (%ni) 也属于用户模式,而软件中断 (%si) 和硬件中断 (%hi) 是在内核模式下加以处理。如果 CPU 未执行上述任何操作,则表示 CPU 空闲或等待 I/O 完成。进程等待 I/O 完成时,不计入 CPU 周期。要计算服务器的当前 CPU 使用率,请运行以下
top命令:... Cpu(s): 88.2%us, 0.0%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...CPU 使用率的定义如下:
CPU Usage = %us + %sy + %ni + %hi + %si或者,您也可以使用 Cloud Monitoring 等任何可以收集所需 CPU 库存和利用率的监控工具。对于非自动扩缩的应用部署(即,使用一个或多个固定数量的服务器运行),我们建议您考虑将峰值利用率用于调整 CPU 容量。这种方法可在工作负载处于峰值使用率的情况下保护应用资源免受干扰。对于自动扩缩部署(基于 CPU 使用率),平均 CPU 利用率是确定容量的安全基准。在这种情况下,您可以通过在高峰期间横向扩容服务器数量来处理流量高峰。
分配足够的缓冲区以应对任何高峰。调整 CPU 容量时,请包括足够的缓冲区,以应对可能导致意外高峰的计划外处理。例如,您可以规划 CPU 容量,以留下超出预期峰值使用率达 10-15% 的额外余量,且总体 CPU 利用率上限不超过 70%。
使用以下公式计算 GCP 上的预期核心数:
Google Cloud 上的 vCPU 数 = 2 × CEILING[(core-count × utilization%) / (2 × threshold%)]
这些值的定义如下:
- core-count:现有核心数(在步骤 1 中计算得出)。
- utilization%:服务器的 CPU 利用率(在步骤 2 中计算得出)。
- threshold%:考虑到充足余量(在步骤 3 中计算得出)后,服务器上允许的 CPU 使用率上限。
如需了解具体示例,不妨设想以下场景:您必须将在本地运行的裸机 4 核 Xeon E5640 服务器的核心数映射到 Google Cloud 中的 vCPU。Xeon E5640 规范是公开可用的,但您也可以通过在系统上运行类似 lscpu 的命令来确认这一点。这些数字如下所示:
- 本地现有核心数 = 插座数 (1) × 核心数 (4) × 每个核心的线程数 (2) = 8。
- 假设在峰值流量期间观察到的 CPU 利用率 (utilization%) 为 40%。
- 预配 30% 的额外缓冲区;也就是说,CPU 利用率上限 (threshold%) 不应超过 70%。
- Google Cloud 上的 vCPU 数 = 2 × CEILING[(8 × 0.4)/(2 × 0.7)] = 6 个 vCPU
(即,2 × CEILING[3.2/1.4] = 2 × CEILING[2.28] = 2 × 3 = 6)
您可以对 RAM、磁盘、网络 I/O 和其他系统资源执行类似的评估。
基于性能的容量调整
上一部分根据当前和预期 CPU 使用水平详细介绍了 pCPU 到 vCPU 的映射。本部分会考虑正在服务器上运行的应用。
在本部分中,您将运行一组标准的规范测试(基于程序的基准测试),以进行性能基准测试。继续该示例场景,设想您在 Xeon E5 机器上运行 MySQL 服务器。在这种情况下,您可以使用 Sysbench OLTP 对数据库性能进行基准测试。
使用 Sysbench 对 MySQL 进行简单的读写测试可产生以下输出:
OLTP test statistics:
queries performed:
read: 520982
write: 186058
other: 74424
total: 781464
transactions: 37211 (620.12 per sec.)
deadlocks: 2 (0.03 per sec.)
read/write requests: 707040 (11782.80 per sec.)
other operations: 74424 (1240.27 per sec.)
Test execution summary:
total time: 60.0061s
total number of events: 37211
total time taken by event execution: 359.8158
per-request statistics:
min: 2.77ms
avg: 9.67ms
max: 50.81ms
approx. 95 percentile: 14.63ms
Thread fairness:
events (avg/stddev): 6201.8333/31.78
execution time (avg/stddev): 59.9693/0.00
若运行此基准测试,您可以就每秒事务数、总读取/写入次数以及端到端执行时间,对当前环境与 Google Cloud 的性能进行比较。我们建议您多次迭代运行这些测试,以排除任何离群值。若要观察不同负载和流量模式下的性能差异,您还可以使用不同的参数(例如并发级别、测试时长、模拟用户数量或不同的填充率)重复运行这些测试。
当前环境与 Google Cloud 之间的性能数据有助于初始容量评估的进一步合理化。如果 Google Cloud 上的基准测试获得的结果与现有环境类似或更好,您可以根据性能提升进一步调整资源规模。另一方面,如果现有环境上的基准比 Google Cloud 更好,您应该执行以下操作:
- 重新审视初始容量评估。
- 监控系统资源。
- 查找可能的争用区域(例如,在 CPU 和 RAM 上发现的瓶颈)。
- 相应地调整资源容量。
完成后,请重新运行特定于应用的基准测试。
端到端性能基准测试
到目前为止,您已经了解了一个简单的场景,该场景只是对本地和 Google Cloud 之间的 MySQL 性能进行了比较。在本部分中,设想以下分布式 3 层应用。

如上图所示,您可能已经运行了多个基准测试,以取得对当前环境和 Google Cloud 的合理评估。不过,确定哪部分基准可以最准确地估算应用性能可能会非常困难。此外,管理测试过程(从依赖项管理,到跨不同云环境或非云环境测试安装、执行以及聚合结果)也是一项单调乏味的任务。对于此类场景,您可以使用 PerfKitBenchmarker。PerfKit 包含的各组基准可用来衡量和比较多个云中的不同产品。PerfKit 还可以通过静态机器在本地运行某些基准测试。
假设对于上述图表中的 3 层应用,您希望运行测试,以便对 Google Cloud 上虚拟机的集群启动时间、CPU 和网络性能进行基准测试。使用 PerfKitBenchmarker,您可以多次迭代运行相关测试配置文件,从而产生以下结果:
集群启动时间:提供虚拟机启动时间的视图。如果应用具有弹性并期望在自动扩缩过程中添加或移除实例,这一点尤为重要。下图显示了
n1-standard-4Compute Engine 实例的启动时间在 40-45 秒内,保持相当稳定(高达第 99 百分位)。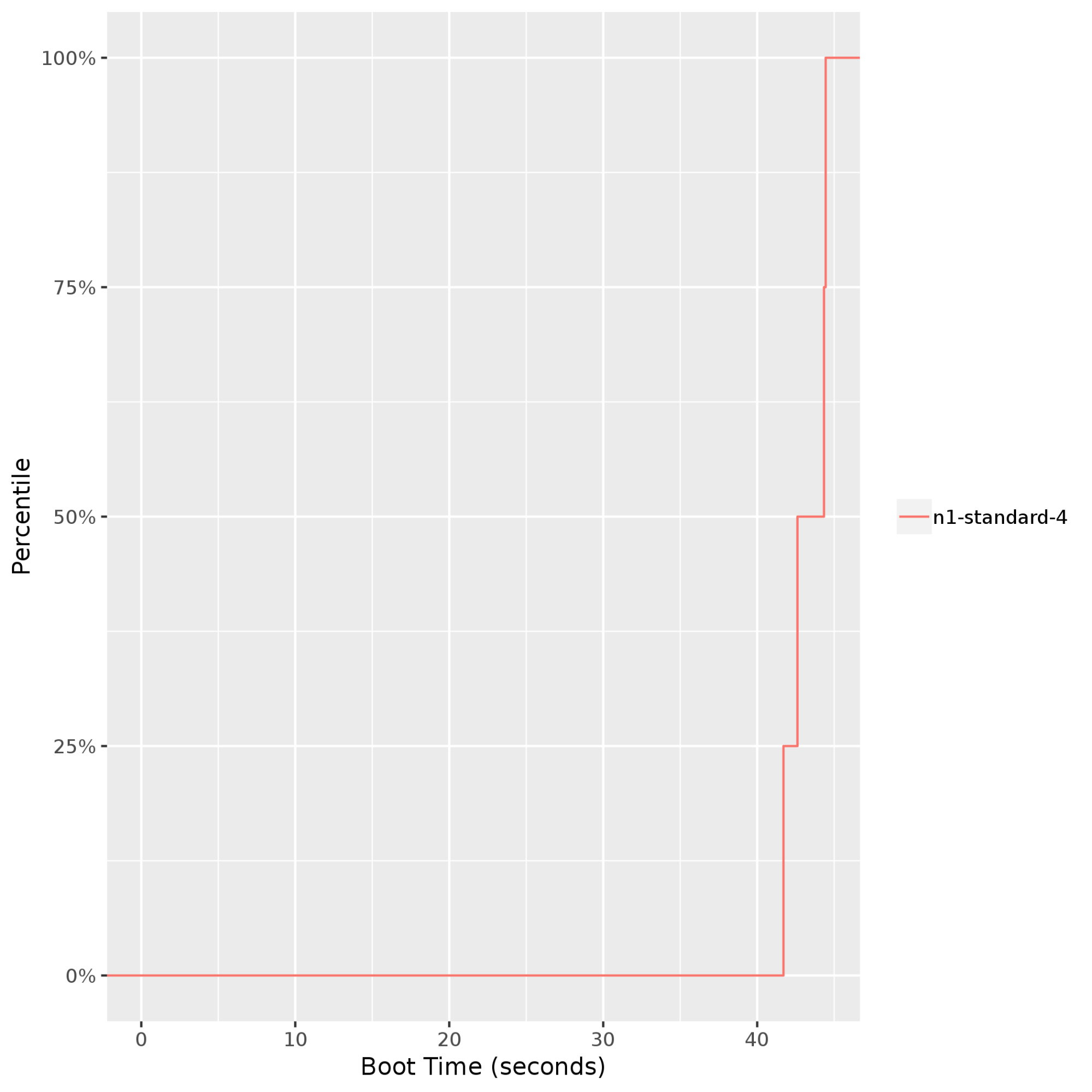
Stress-ng:通过对系统的处理器、内存子系统和编译器施加压力来衡量和比较计算密集型性能。在以下示例中,stress-ng会针对n1-standard-4Compute Engine 实例运行多项压力测试,例如bsearch、malloc、matrix、mergesort和zlib。Stress-ng使用每秒的 Bogus 操作数(Bogo 操作数)来衡量压力测试吞吐量。如果跨不同的压力测试结果,对 Bogo 操作数进行标准化,则会得到以下输出,其中显示了每秒执行的操作数的几何均值。在此示例中,Bogo 操作数的范围为每秒约 8000 次(第 50 百分位)到每秒约 10000 次(第 95 百分位)。请注意,Bogo 操作数通常仅用于对独立 CPU 性能进行基准测试。这些操作可能无法代表您的应用。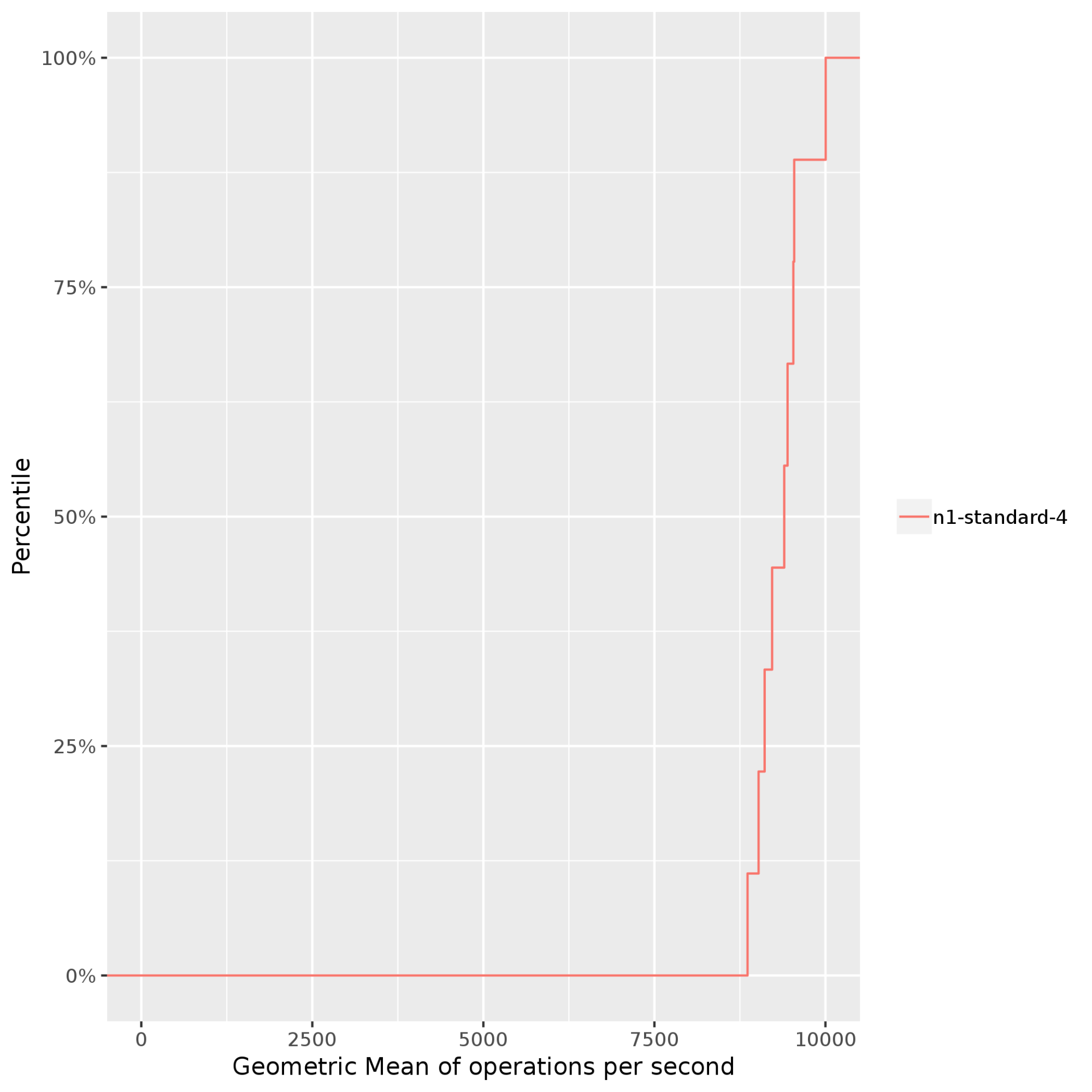
Netperf:通过请求和响应测试来测量延迟时间。请求和响应测试在网络堆栈的应用层运行。这种延迟时间测试方法涉及堆栈的所有层,在测量虚拟机到虚拟机的延迟时间方面优于 Ping 测试。下图显示了在同一 Google Cloud 地区中运行的客户端和服务器之间的 TCP 请求和响应 (TCP_RR) 延迟时间。TCP_RR 值范围为约 70 微秒(第 50 百分位)到约 130 微秒(第 90 百分位)。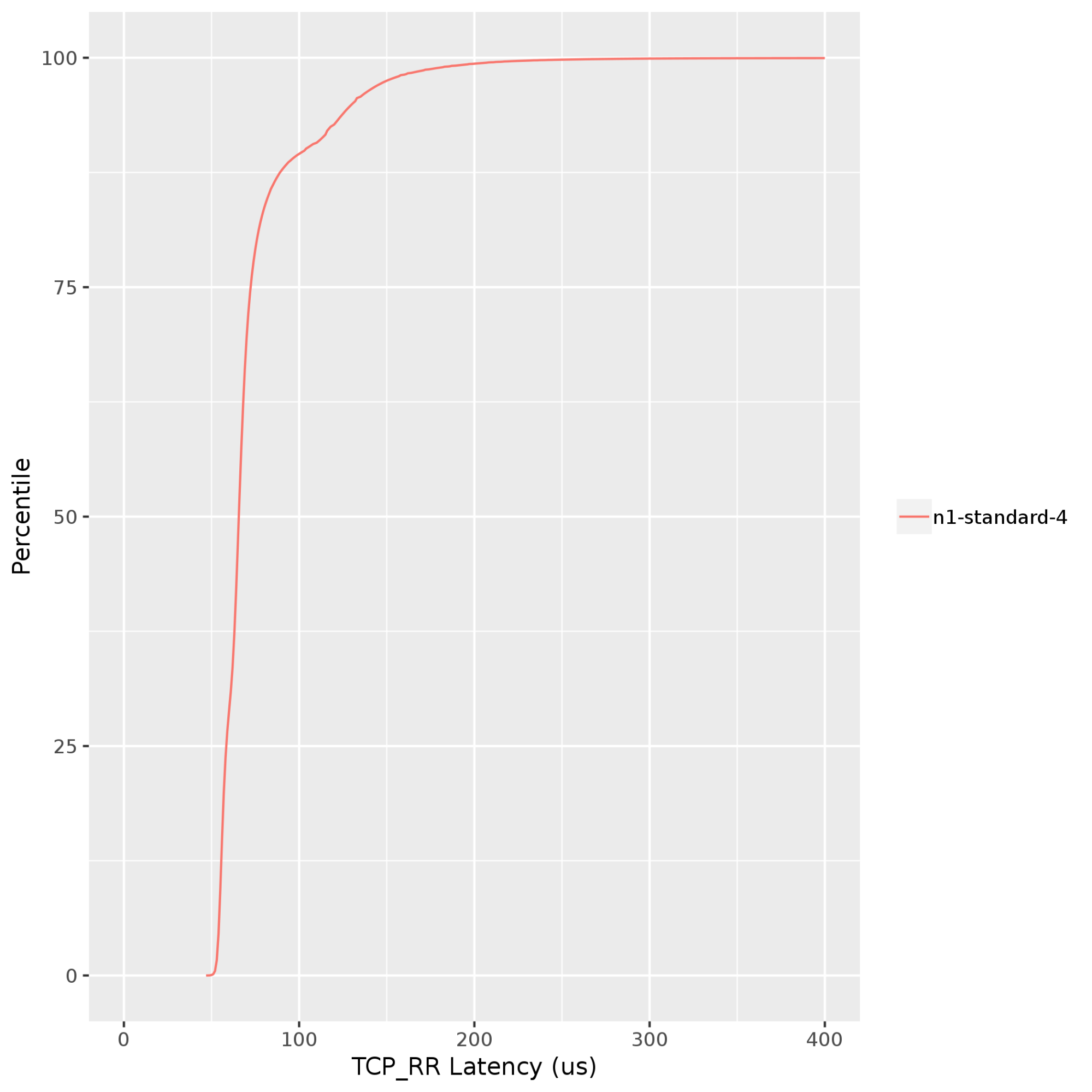
鉴于目标工作负载的性质,您可以使用 PerfKit 运行其他测试配置文件。如需了解详情,请参阅 PerfKit 中支持的基准。
关于 Google Cloud 的最佳做法
在 Google Cloud 上设置和执行迁移计划之前,我们建议您遵循迁移最佳做法。这些做法只是一个起点。您可能需要考虑应用的其他许多方面(例如分离依赖项、引入容错能力以及确保根据组件工作负载进行扩缩),以及每个方面如何映射到 Google Cloud。
了解 Google Cloud 的限制和配额。在正式开始容量评估之前,请先了解 Google Cloud 资源规划的一些重要注意事项,例如:
列出迁移期间将需要的基础架构即服务 (IaaS) 和平台即服务 (PaaS) 组件,并清楚地了解每个服务具有的任何配额和限制以及所进行的任何微调。
持续监控资源。持续的资源监控可帮助您识别系统和应用性能的模式和趋势。监控不仅有助于确定基准性能,还能证明随时间进行硬件升级和降级的必要性。Google Cloud 为部署端到端监控解决方案提供了各种选择:
调整虚拟机容量。确定虚拟机何时预配不足或预配过度。如前所述,设置基本监控应该可以轻松提供这些数据分析。Google Cloud 还会根据实例的历史使用情况推荐合理容量。此外,根据工作负载的性质,如果预定义机器类型无法满足您的需求,您可以使用自定义虚拟化硬件设置创建实例。
使用正确的工具。对于大规模环境,部署自动化工具以最大程度地减少手动操作,例如:
- StratoZone 和 CloudPhysics,用于应用发现和现有库存数据收集。
- Migrate to Virtual Machines,用于将虚拟机迁移到 Google Cloud,并用于内置测试来验证云端内性能、服务等级协议 (SLA) 和费用。
- Database Migration Service,用于将数据和数据库迁移到 Google Cloud。
- Cloud Deployment Manager,用于预配云基础架构资源即代码 (IaC)。
掌握要点
将资源从一个环境迁移到另一个环境需要仔细规划。请务必不仅单独查看硬件资源,还要您端到端地全面了解您的应用。例如,您不能只关注 3.0 GHz Sandy Bridge 处理器的速度是否为 1.5 GHz Skylake 处理器的两倍,而是应关注应用的关键性能指标在不同计算平台之间的变化。
评估不同环境中的资源映射要求时,请考虑以下事项:
- 对您的应用有限制的系统资源(例如 CPU、内存、磁盘或网络)。
- 底层基础架构(例如处理器世代、时钟速度、硬盘 (HDD) 或固态硬盘 (SSD))对应用性能的影响。
- 软件和架构设计选择(例如单线程或多线程工作负载、固定部署或自动扩缩部署)对应用性能的影响。
- 计算、存储和网络资源的当前和预期利用率水平。
- 可代表您的应用的最合适性能测试。
通过持续监控来收集这些指标的数据,有助于您确定初始容量方案。进一步的操作是通过执行合适的性能基准测试来微调初始容量估计值。
后续步骤
- 详细了解有关将虚拟机迁移到 Google Cloud 的最佳做法。
- 了解 Google Cloud 的迁移中心。
- 详细了解 Cloud Foundation Toolkit。
- 详细了解如何开始进行 Google Cloud 迁移。
- 详细了解 Google Cloud 与其他云平台的对比情况。
- 探索有关 Google Cloud 的参考架构、图表和最佳实践。查看我们的 Cloud Architecture Center。