このドキュメントでは、オンプレミス ハードウェアから Google Cloud への適切なリソース マッピングを見つける方法について説明します。ベアメタル サーバーで実行されているアプリケーションを Google Cloud に移行する場合は、次の内容を検討してください。
- 物理コア(pCPU)を、Google Cloud 上の仮想 CPU(vCPU)にどのようにマッピングするか。たとえば、ベアメタルの Xeon E5 の 4 つの物理コアを、Google Cloud 上の vCPU にどのようにマッピングしますか。
- さまざまな CPU プラットフォームと、プロセッサの世代のパフォーマンスの違いをどのように捉えるか。たとえば、3.0 GHz の Sandy Bridge は、2.0 GHz の Skylake より 1.5 倍速いでしょうか。
- ワークロードに基づいて、どのようにリソースを適切なサイズに設定するか。たとえば、マルチコア サーバーで実行されているメモリ使用量の多いシングルスレッド アプリケーションを最適化するにはどうすればよいでしょうか。
ソケット、CPU、コア、スレッド
ソケット、CPU、コア、スレッドという用語は、よく同じ意味で使われるため、異なる環境間での移行の際に、混乱の原因になることがあります。
簡単に言うと、サーバーは 1 つ以上のソケットを持つことができます。ソケット(CPU ソケットや CPU スロットとも呼ばれます)は、CPU チップを搭載するマザーボード上のコネクタで、CPU と回路基板の間の物理的な接続を提供します。
CPU とは、実際の集積回路(IC)のことです。CPU の基本的な働きは、格納された一連の命令を実行することです。大まかに言うと、CPU はフェッチ、デコード、実行のステップに従います。これらをまとめて命令サイクルと呼びます。より複雑な CPU では、複数の命令が同時にフェッチ、デコード、実行されます。
各 CPU チップは、1 つ以上のコアを持つことができます。コアは基本的に、命令を受け取り、その命令に基づいてアクションを実行する実行ユニットで構成されます。ハイパースレッド システムでは、物理プロセッサコアは、複数の論理プロセッサとして、リソースを割り当られます。つまり、各物理プロセッサコアは、2 つの仮想(または論理)コアとして、オペレーティング システムに提示されます。
次の図は、ハイパースレッド対応のクアッドコア CPU の概要を示しています。

Google Cloud では、各 vCPU は、利用可能ないずれかの CPU プラットフォーム上に 1 つのハイパースレッドとして実装されます。
システム内の vCPU(論理 CPU)の総数を調べるには、次の式を使用します。
vCPU 数 = 物理コアあたりのスレッド数 × ソケットあたりの物理コア数 × ソケット数
lscpu コマンドは、ソケット、CPU、コア、スレッドの数などの情報を収集します。この情報には、CPU キャッシュとキャッシュ共有、ファミリー、モデル、BogoMips に関する情報も含まれます。一般的な出力は次のとおりです。
... Architecture: x86_64 CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 CPU MHz: 2200.000 BogoMIPS: 4400.00 ...
既存の環境と Google Cloud の間で CPU リソースをマッピングする場合は、サーバーの物理コア数または仮想コア数を確認してください。詳細については、リソースのマッピングのセクションをご覧ください。
CPU クロックレート
プログラムを実行するには、プログラムをプロセッサが理解できる一連の命令に分割する必要があります。次の C プログラムについて考えてみます。この C プログラムは、2 つの数値を足して結果を表示するというものです。
#include <stdio.h>
int main()
{
int a = 11, b = 8;
printf("%d \n", a+b);
}
コンパイル時に、プログラムは次のアセンブリ コードに変換されます。
...
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $11, -8(%rbp)
movl $8, -4(%rbp)
movl -8(%rbp), %edx
movl -4(%rbp), %eax
addl %edx, %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
...
前述の出力の各アセンブリ命令は、1 つのマシン命令に対応しています。たとえば、pushq 命令は、RBP レジスタの内容をプログラム スタックに push する必要があることを示します。各 CPU サイクルの間に、CPU は、命令のフェッチ、レジスタの内容へのアクセス、データの書き込みなど、基本的なオペレーションを実行できます。2 つの数値を加算するサイクルの各段階について詳しくは、こちらの CPU シミュレータをご覧ください。
各 CPU 命令の実行には、複数のクロック サイクルが必要になる場合があります。プログラムの命令ごとに必要な平均クロック サイクル数は、次のように命令あたりのサイクル数(CPI)で定義されます。
命令あたりのサイクル数 = 使用される CPU サイクル数 ÷ 実行される命令数
最近のほとんどの CPU では、命令パイプラインを介してクロック サイクルごとに複数の命令を実行できます。サイクルごとに実行される命令の平均数は、次のようにサイクルあたりの命令数(IPC)で定義されます。
サイクルあたりの命令数 = 実行される命令数 ÷ 使用される CPU サイクル数
CPU クロックレートは、プロセッサが 1 秒あたりに実行できるクロック サイクル数を定義します。たとえば、3.0 GHz のプロセッサは 1 秒あたり 30 億のクロック サイクルを実行できます。つまり、すべてのクロック サイクルが約 0.3 ナノ秒で実行されます。各クロック サイクルの間に、CPU は IPC で定義されるように、1 つ以上の命令を実行できます。
クロックレートは一般的に、プロセッサのパフォーマンスの比較に使用されます。文字通りの定義(1 秒あたりに実行されるサイクル数)で判断すると、クロック サイクル数が高いほど CPU が処理できる作業量が多いため、CPU のパフォーマンスが高いという考え方もあります。同じ世代のプロセッサで CPU を比較するときには、この考え方が当てはまる場合もあります。しかし、異なるプロセッサ ファミリーを比較する場合、パフォーマンスを示す指標としてクロックレートだけを使用するべきではありません。新しい世代の CPU は、以前の世代の CPU より低いクロックレートで実行する場合でも、より良いパフォーマンスを発揮することがあります。
クロックレートとシステム パフォーマンス
プロセッサのパフォーマンスをさらに深く理解するには、クロック サイクル数だけでなく、CPU が 1 サイクルごとに処理できる作業量も確認する必要があります。CPU バウンド プログラムの合計実行時間は、クロックレートだけでなく、実行する命令数、命令あたりのサイクル数、サイクルあたりの命令数、命令セット アーキテクチャ、スケジューリング、ディスパッチ アルゴリズム、使用するプログラミング言語など、他の要因にも依存します。これらの要因は、プロセッサの世代間で大きく異なります。
2 つの異なる実装間で CPU の実行がどのように変わるかを理解するため、簡単な階乗プログラムの例で考えてみます。次のプログラムは、1 つは C で、もう 1 つは Python で記述されています。Perf(Linux 用のプロファイリング ツール)は、CPU とカーネル指標の一部をキャプチャするのに使用されます。
C のプログラム
#include <stdio.h>
int main()
{
int n=7, i;
unsigned int factorial = 1;
for(i=1; i<=n; ++i){
factorial *= i;
}
printf("Factorial of %d = %d", n, factorial);
}
Performance counter stats for './factorial':
...
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
45 page-faults # 0.065 M/sec
1,562,075 cycles # 1.28 GHz
1,764,632 instructions # 1.13 insns per cycle
314,855 branches # 257.907 M/sec
8,144 branch-misses # 2.59% of all branches
...
0.001835982 seconds time elapsed
Python のプログラム
num = 7
factorial = 1
for i in range(1,num + 1):
factorial = factorial*i
print("The factorial of",num,"is",factorial)
Performance counter stats for 'python3 factorial.py':
...
7 context-switches # 0.249 K/sec
0 cpu-migrations # 0.000 K/sec
908 page-faults # 0.032 M/sec
144,404,306 cycles # 2.816 GHz
158,878,795 instructions # 1.10 insns per cycle
38,254,589 branches # 746.125 M/sec
945,615 branch-misses # 2.47% of all branches
...
0.029577164 seconds time elapsed
ハイライト表示された出力は、各プログラムの実行にかかった合計時間を示しています。C で記述されたプログラムは、Python で記述されたプログラムより、約 15 倍の速さで実行されます(C の実行時間 1.8 ミリ秒に対し、Python は 30 ミリ秒)。その他の比較は次のとおりです。
コンテキスト スイッチ。システム スケジューラが別のプログラムを実行する必要がある場合、または割り込みが進行中の実行をトリガーする場合、オペレーティング システムは実行中のプログラムの CPU レジスタの内容を保存し、新しいプログラムを実行するために準備します。C プログラムの実行中にコンテキスト スイッチは発生しませんでしたが、Python プログラムの実行中に 7 回のコンテキスト スイッチが発生しました。
CPU 間の移動。オペレーティング システムは、マルチプロセッサ システムで使用可能な CPU 間のワークロード バランスを維持しようとします。このバランス調整は、定期的および CPU 実行キューが空になるたびに行われます。上記のテストの間には、CPU 間の移動は確認されていません。
命令。C プログラムでは、150 万 CPU サイクルで、170 万の命令が実行されました(IPC = 1.13、CPI = 0.88)が、一方 Python プログラムでは、1 億 4,400 万 CPU サイクルで、1 億 5,800 万の命令が実行されました(IPC = 1.10、CPI = 0.91)。どちらのプログラムでもパイプラインが埋まり、CPU がサイクルごとに複数の命令を実行できるようにしました。Python で生成された命令の数は C の約 90 倍です。
ページ フォールト。各プログラムには、すべての命令とデータを含む仮想メモリのスライスがあります。通常、メインメモリ内のすべての命令を一度にコピーするのは効率的ではありません。ページ フォールトは、プログラムが仮想メモリの内容の一部をメインメモリにコピーする必要が生じるたびに発生します。ページ フォールトは、割り込みを介して CPU から通知されます。
Python のインタプリタ実行可能ファイルは C よりもはるかに大きいため、CPU サイクル(C では 1.5 M、Python では 144 M)とページ フォールト(C では 45、Python では 908)の両方の観点から見ても、追加のオーバーヘッドは明らかです。
分岐と分岐予測ミス。条件付き命令の場合、CPU は分岐する条件を評価する前であっても、実行パスを予測しようとします。このようなステップは、命令パイプラインを埋めるのに役立ちます。このプロセスは投機的実行と呼ばれます。上記のプログラム実行での投機的実行は、きわめて成功しています。分岐予測の失敗は、C のプログラムでたった 2.59%、Python のプログラムで 2.47% でした。
CPU 以外の要素
ここまで、CPU のさまざまな側面とパフォーマンスへの影響について見てきました。しかし、アプリケーションが常に CPU 上で実行されることはまれです。簡単な例として、Linux でユーザーの home ディレクトリからアーカイブを作成する、次の tar コマンドについて考えてみます。
$ time tar cf archive.tar /home/"$(whoami)"
出力は次のようになります。
real 0m35.798s user 0m1.146s sys 0m6.256s
これらの出力値は、次のように定義されます。
- 実時間
- 実時間(
real)は、実行が開始してから完了するまでにかかる時間です。この経過時間には、他のプロセスで使用されるタイムスライスと、プロセスがブロックされた時間(I/O オペレーションの完了を待っている時間など)が含まれます。 - ユーザー時間
- ユーザー時間(
user)は、プロセスでユーザー空間コードの実行に費やされた CPU 時間です。 - システム時間
- システム時間(
sys)は、プロセスでカーネル空間コードの実行に費やされた CPU 時間です。
上記の例では、ユーザー時間が 1.0 秒、システム時間が 6.3 秒です。real 時間と user + sys 時間の差である約 28 秒は、tar コマンドによって費やされた CPU 以外の時間を表します。
実行中に CPU 以外の時間が長い場合は、プロセスが CPU の制約を大きく受けないことを示します。リソースが、期待されるパフォーマンスの達成のボトルネックになっている場合、コンピューティングはなんらかの制約を受けるとされています。移行を計画する際は、アプリケーションの全体像を把握し、パフォーマンスに重要な影響を与える可能性のあるすべての要素を考慮することが重要です。
移行におけるターゲット ワークロードの役割
移行の合理的な出発点を見つけるには、基盤となるリソースのベンチマークを評価することが重要です。パフォーマンスのベンチマーク評価は、さまざまな方法で行うことができます。
実際のターゲット ワークロード: アプリケーションをターゲット環境にデプロイして、主要なパフォーマンス指標(KPI)のパフォーマンスベンチマーク評価を実施します。たとえば、ウェブ アプリケーションの KPI には次のようなものが含まれます。
- アプリケーションの読み込み時間
- エンドツーエンド トランザクションのエンドユーザー レイテンシ
- 接続の切断
- 低トラフィック、平均的なトラフィック、ピーク時のトラフィックで処理するインスタンス数
- インスタンス処理中のリソース(CPU、RAM、ディスク、ネットワーク)の使用率
しかし、ターゲット アプリケーション全体(または一部)のデプロイには、手間と時間がかかることがあります。予備的なベンチマークとして、一般的にはプログラムベースのベンチマークが好まれます。
プログラムベースのベンチマーク: プログラムベースのベンチマークは、エンドツーエンドのアプリケーション フローではなく、アプリケーションの個々のコンポーネントに重点を置いています。これらのベンチマークは、テスト プロファイルを組み合わせて実施します。それぞれのプロファイルは、アプリケーションの 1 つのコンポーネントを対象にしています。たとえば、LAMP スタックのデプロイ用のテスト プロファイルには、Apache Bench(ウェブサーバーのパフォーマンスのベンチマーク評価に使用)と、Sysbench(MySQL のベンチマーク評価に使用)などが考えられます。通常、これらのテストは実際のターゲット ワークロードを設定するよりも簡単で、異なるオペレーティング システムと環境間の移植性が高くなっています。
カーネルまたは合成ベンチマーク: 実際のプログラムから主要な計算能力をテストするには、行列分解や FFT などの合成ベンチマークを使用できます。これらのテストは通常、アプリケーション設計の初期段階で行います。VM とドライブの負荷、I/O 同期、キャッシュ スラッシングなど、マシンの特定の側面のみのベンチマークに最適です。
アプリケーションの理解
多くのアプリケーションは、CPU、メモリ、ディスク I/O、ネットワーク I/O や、これらの要素の組み合わせによる制約を受けます。たとえば、ディスクの競合が原因でアプリケーションの動作速度が低下している場合、サーバーのコアを増やしてもパフォーマンスが向上しない可能性があります。
大規模で複雑な環境で、アプリケーションのオブザーバビリティを維持することは簡単ではありません。分散型システム全体のリソースを追跡できる専門のモニタリング システムがあります。たとえば、Google Cloud では Cloud Monitoring を使用して、コード、アプリケーション、インフラストラクチャ全体を可視化できます。Cloud Monitoring の例についてはこのセクションで後述しますが、まず、スタンドアロン サーバーでの一般的なシステム リソースのモニタリングについて理解することをおすすめします。
top、IOStat、VMStat、iPerf のような多くのユーティリティを使用すると、システムのリソースの概要を大まかに把握できます。たとえば、Linux システム上で top を実行すると、出力は次のようになります。
top - 13:20:42 up 22 days, 5:25, 18 users, load average: 3.93 2.77,3.37 Tasks: 818 total, 1 running, 760 sleeping, 0 stopped, 0 zombie Cpu(s): 88.2%us, 0.0%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 49375504k total, 6675048k used, 42700456k free, 276332k buffers Swap: 68157432k total, 0k used, 68157432k free, 5163564k cached
システムの負荷が高く、待ち時間の割合が大きい場合は、アプリケーションはおそらく I/O バウンドです。ユーザー時間の割合、またはシステム時間の割合のいずれか(もしくは両方)がかなり大きい場合、アプリケーションはおそらく CPU バウンドです。
上記の例では、読み込みの平均(4 vCPU VM の場合)は、最後の 5 分で 3.93、最後の 10 分で 2.77、最後の 15 分で 3.37 です。これらの平均値と、ユーザー時間の割合の大きさ(88.2%)、アイドル時間の短さ(0.3%)、待ち時間がないこと(0.0%)を組み合わせると、システムは CPU バウンドであると考えることができます。
これらのツールは、スタンドアロン システムでは十分機能しますが、通常は大規模な分散型環境をモニタリングするように設計されていません。本番環境システムをモニタリングするには、Cloud Monitoring、Nagios、Prometheus、Sysdig などのツールを使用すると、アプリケーションに対するリソース消費の詳しい分析を得ることができます。
十分な期間をかけてアプリケーションのパフォーマンス モニタリングを実施すると、CPU 使用率、メモリ使用量、ディスク I/O、ネットワーク I/O、ラウンドトリップ タイム、レイテンシ、エラー率、スループットなどの複数の指標にまたがるデータを集めることができます。たとえば、以下の Cloud Monitoring のグラフには、Google Cloud のマネージド インスタンス グループで実行されているすべてのサーバーのメモリとディスクの使用量と合わせて、CPU の負荷と使用率レベルが示されています。この設定の詳細については、Cloud Monitoring エージェントの概要をご覧ください。
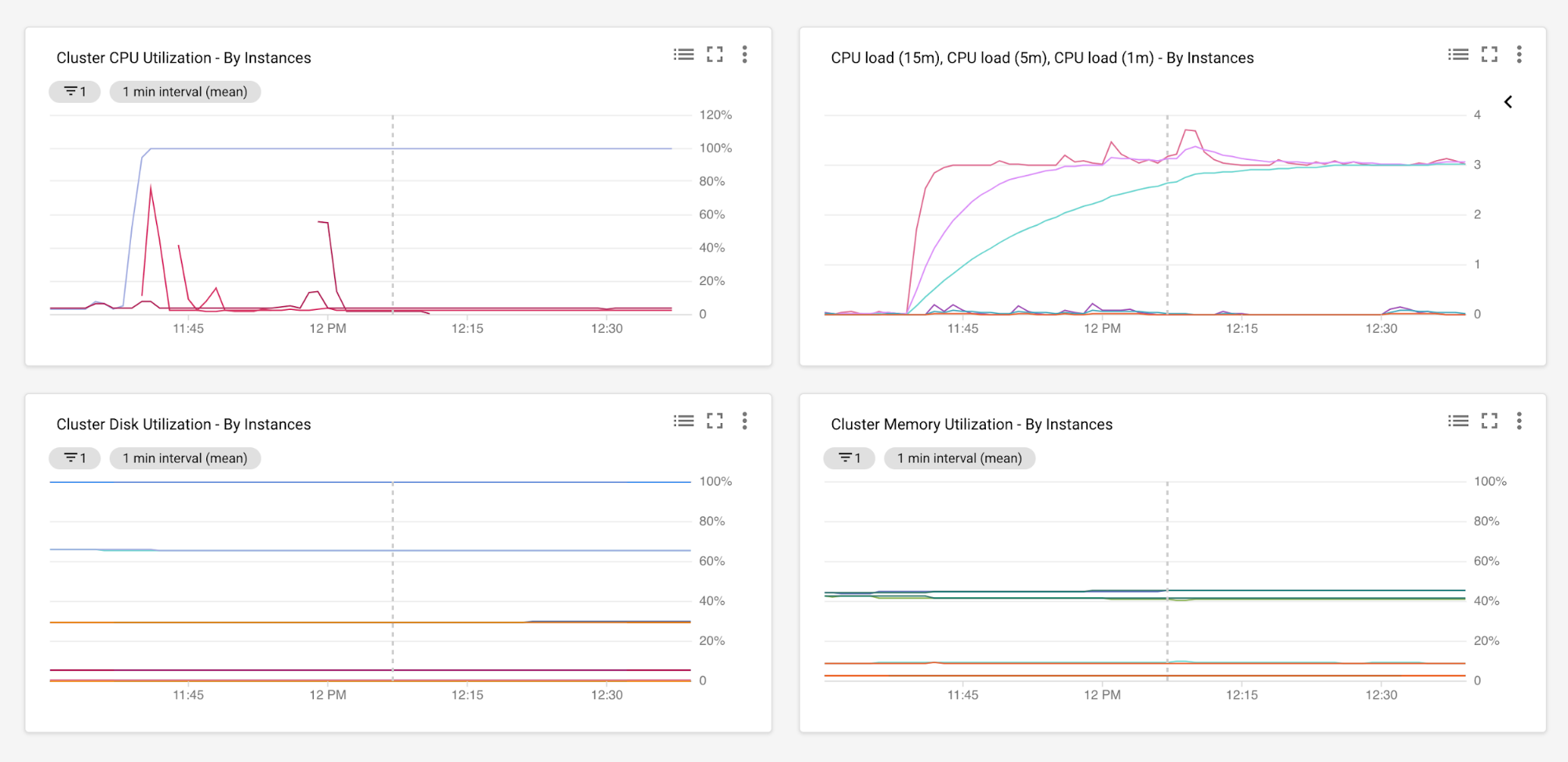
分析目的のデータ収集期間は、リソースの使用率のピークと底を読み取るのに十分な長さにする必要があります。それから、収集したデータを分析して、新しいターゲット環境でのキャパシティ プランニングの出発点を導き出すことができます。
リソースのマッピング
このセクションでは、Google Cloud でのリソースのサイズ設定を確立する方法について説明します。はじめに、既存のリソースの使用率レベルに基づいて、最初のサイズ設定評価を行います。その後、アプリケーション固有のパフォーマンス ベンチマーク テストを実施します。
使用量に基づくサイズ設定
サーバーの既存のコア数を、Google Cloud の vCPU にマッピングする手順は次のとおりです。
現在のコア数を確認する。前のセクションの
lscpuコマンドをご覧ください。サーバーの CPU 使用率を確認する。CPU 使用率は、ユーザーモード(
%us)かカーネルモード(%sy)のときに、CPU が処理にかかる時間を参照してください。nice 処理(%ni)もユーザーモードに属します。一方、ソフトウェア割り込み(%si)とハードウェア割り込み(%hi)は、カーネルモードで扱います。CPU がこれらのいずれの動作もしていない場合は、完了するために、アイドル状態か I/O を待機しているかのいずれかです。プロセスが I/O が完了するのを待機している場合、CPU サイクルに寄与していません。サーバーの現在の CPU 使用率を計算するには、次の
topコマンドを実行します。... Cpu(s): 88.2%us, 0.0%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...CPU の使用率の定義は次のとおりです。
CPU Usage = %us + %sy + %ni + %hi + %siまたは、Cloud Monitoring のような任意のモニタリング ツールを使用して、必要な CPU のインベントリや使用率を収集することもできます。自動スケーリングではないアプリケーションのデプロイ(つまり、1 つ以上の決まった数のサーバーで実行する)の場合、CPU のサイズ設定にはピーク使用率の使用を検討することをおすすめします。こうすることで、ワークロードがピーク使用率に達したときに、アプリケーション リソースの中断を阻止します。自動スケーリングのデプロイ(CPU 使用率に基づく)の場合、サイズ設定のベースラインとして、平均 CPU 使用率を使用することを検討してください。この場合、トラフィックが急増している間は、サーバー数をスケールアウトすることによって、トラフィックの急増を処理します。
トラフィックの急増に対応する十分なバッファを割り当てる。CPU のサイズ設定をする際、予期しないトラフィックの急増の原因となる、スケジュール外の処理に対応するための十分なバッファを含めます。たとえば、予想されるピーク使用量の 10~15% を追加のヘッドルームとして上乗せして、CPU の最大使用率が 70% を超えないように、CPU 容量を計画することもできます。
次の数式を使用して、GCP で予想されるコア数を計算する。
Google Cloud の vCPU = 2 × CEILING [(core-count × utilization%) ÷ (2 × threshold%)]
これらの値の定義は、次のとおりです。
- core-count: 既存のコア数(手順 1 で計算したもの)。
- utilization%: サーバーの CPU 使用率(手順 2 で計算したもの)。
- threshold%: 十分なヘッドルームを考慮した、CPU 最大使用率(手順 3 で計算したもの)。
具体的な例として、オンプレミスで動作するベアメタルの 4 コア Xeon E5640 サーバーのコア数を、Google Cloud の vCPU にマッピングする必要があるシナリオを考えます。Xeon E5640 の仕様は公開されていますが、システムで lscpu などのコマンドを実行して確認することもできます。数値は次のようになります。
- オンプレミスの既存のコア数 = ソケット(1)× コア(4)×コアあたりのスレッド(2)= 8
- ピーク時のトラフィックの間に観測される CPU 使用率(utilization%)が 40% であるとします。
- 30% のバッファを追加でプロビジョニングします。つまり、CPU の最大使用率(threshold%)が 70% を超えないようにします。
- Google Cloud の vCPU = 2 × CEILING [(8 × 0.4)÷(2 × 0.7)] = 6 vCPU
(つまり、2 × CEILING [3.2÷1.4] = 2 × CEILING [2.28] = 2 × 3 = 6)
RAM、ディスク、ネットワーク I/O、その他のシステム リソースについても同様に評価できます。
パフォーマンスベースのサイズ設定
前のセクションでは、現在の CPU 使用率と予想される CPU 使用率に基づいて、pCPU を vCPU にマッピングする方法について詳しく説明しました。このセクションでは、サーバーで実行されているアプリケーションについて考えます。
このセクションでは、パフォーマンスのベンチマーク評価を行うために、標準で正規のテストセット(プログラムベースのベンチマーク)を実施します。具体例のシナリオを続けます。Xeon E5 マシンで MySQL サーバーが動作しているシナリオを考えます。このケースでは、Sysbench OLTP を使用して、データベースのパフォーマンスをベンチマーク評価します。
Sysbench を使用して、MySQL で簡単な読み取りと書き込みテストを行うと、次のような出力が生成されます。
OLTP test statistics:
queries performed:
read: 520982
write: 186058
other: 74424
total: 781464
transactions: 37211 (620.12 per sec.)
deadlocks: 2 (0.03 per sec.)
read/write requests: 707040 (11782.80 per sec.)
other operations: 74424 (1240.27 per sec.)
Test execution summary:
total time: 60.0061s
total number of events: 37211
total time taken by event execution: 359.8158
per-request statistics:
min: 2.77ms
avg: 9.67ms
max: 50.81ms
approx. 95 percentile: 14.63ms
Thread fairness:
events (avg/stddev): 6201.8333/31.78
execution time (avg/stddev): 59.9693/0.00
このベンチマークを実施すると、1 秒あたりのトランザクション数、1 秒あたりの合計読み取り / 書き込み数、現在の環境と Google Cloud 間のエンドツーエンドの実行時間の観点からパフォーマンスを比較できます。外れ値を除外するには、これらのテストを繰り返し実施することをおすすめします。負荷とトラフィックのさまざまなパターンでのパフォーマンスの違いを確認するには、同時実行レベル、テスト期間、シミュレートしたユーザー数、さまざまなハッチ率など、異なったパラメータでテストを繰り返します。
現在の環境と Google Cloud 間のパフォーマンスの数値は、初期の容量評価をより合理的に説明することに役立ちます。Google Cloud 上のベンチマーク テストで、既存の環境と同様、またはより良い結果が出ている場合は、リソースのスケールをさらに調整してパフォーマンスを改善できます。反対に、既存環境のベンチマークの方が Google Cloud 上のベンチマークよりも良い結果の場合は、以下を実施してください。
- 最初の容量評価を見直す。
- システム リソースをモニタリングする。
- 競合の可能性がある領域(CPU と RAM で特定されたボトルネックなど)を探す。
- リソースのサイズを適宜変更する。
以上を行った後、アプリケーション固有のベンチマーク テストを再度実施してください。
エンドツーエンドのパフォーマンス ベンチマーク
ここまでは、オンプレミスと Google Cloud 間の MySQL のパフォーマンスを比較する簡単なシナリオについて説明しました。このセクションでは、次の分散 3 層アプリケーションについて考えます。

図が示すように、現在の環境と Google Cloud の妥当な評価に達するために、おそらく複数のベンチマークを実施してきたでしょう。ただし、アプリケーション パフォーマンスを最も正確に見積もるためのベンチマークのサブセットを確立するのは、難しい場合があります。さらに、依存関係の管理からテストのインストール、実行、結果の集計まで、テストプロセスをさまざまなクラウド環境や非クラウド環境で管理するのは煩雑なタスクです。このようなシナリオでは、PerfKitBenchmarker を使用できます。PerfKit には、複数のクラウドでいろいろなサービスを測定し、比較するためのさまざまなベンチマークが用意されています。また、静的マシンを介して特定のベンチマークをオンプレミスで実施することもできます。
上の図の 3 層アプリケーションで、Google Cloud 上の VM のクラスタの起動時間、CPU、ネットワーク パフォーマンスのベンチマーク テストを実施するとします。PerfKitBenchmarker を使用すると、関連するテスト プロファイルを複数回繰り返し実行できます。結果は次のようになります。
クラスタの起動時間: VM の起動時間を確認できます。これは、アプリケーションに弾性があり、自動スケーリングの一環でインスタンスが追加または削除されることを想定している場合は特に重要です。次のグラフは、
n1-standard-4Compute Engine インスタンスの起動時間が 40~45 秒でほぼ一定(99 パーセンタイルまで)であることを示しています。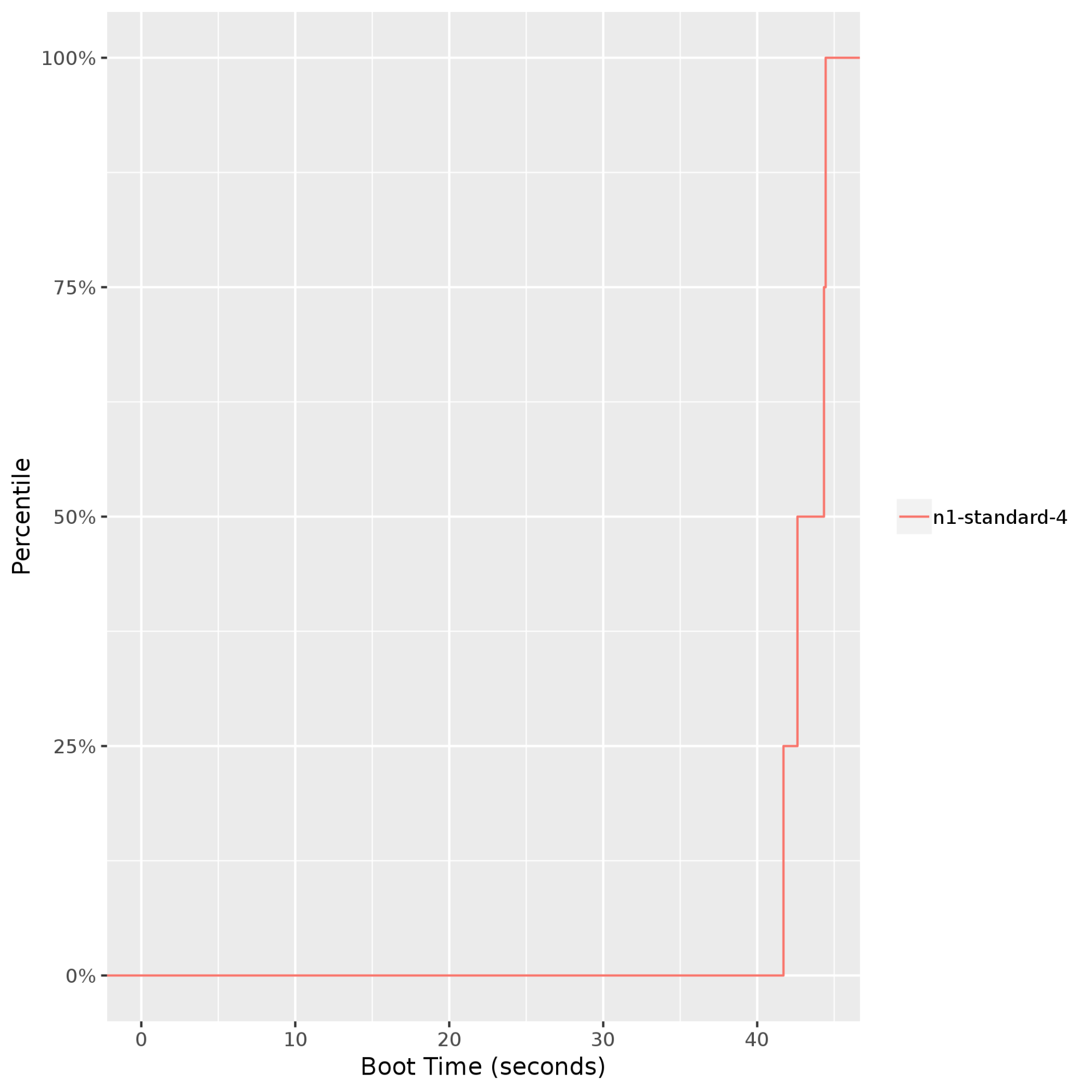
Stress-ng: システムのプロセッサ、メモリ サブシステム、コンパイラに負荷をかけ、多くのコンピューティング処理を必要とするパフォーマンスを測定して、比較します。次の例では、n1-standard-4Compute Engine インスタンス上で、stress-ngがbsearch、malloc、matrix、mergesort、zlibなど、複数のストレステストを実施しています。Stress-ngは、1 秒ごとの偽装の演算(bogo ops)を使用してストレステストのスループットを測定します。さまざまなストレステスト結果にわたって bogo ops を正規化すると、次の出力が得られます。これは、1 秒あたりに実行された演算の幾何平均です。この例では、bogo ops は 50 パーセンタイルで毎秒約 8,000 から 95 パーセンタイルで毎秒約 10,000 までの範囲になります。通常、bogo ops はスタンドアロン CPU のパフォーマンス ベンチマークにのみ使用されます。これらの演算は、アプリケーションを表すものではありません。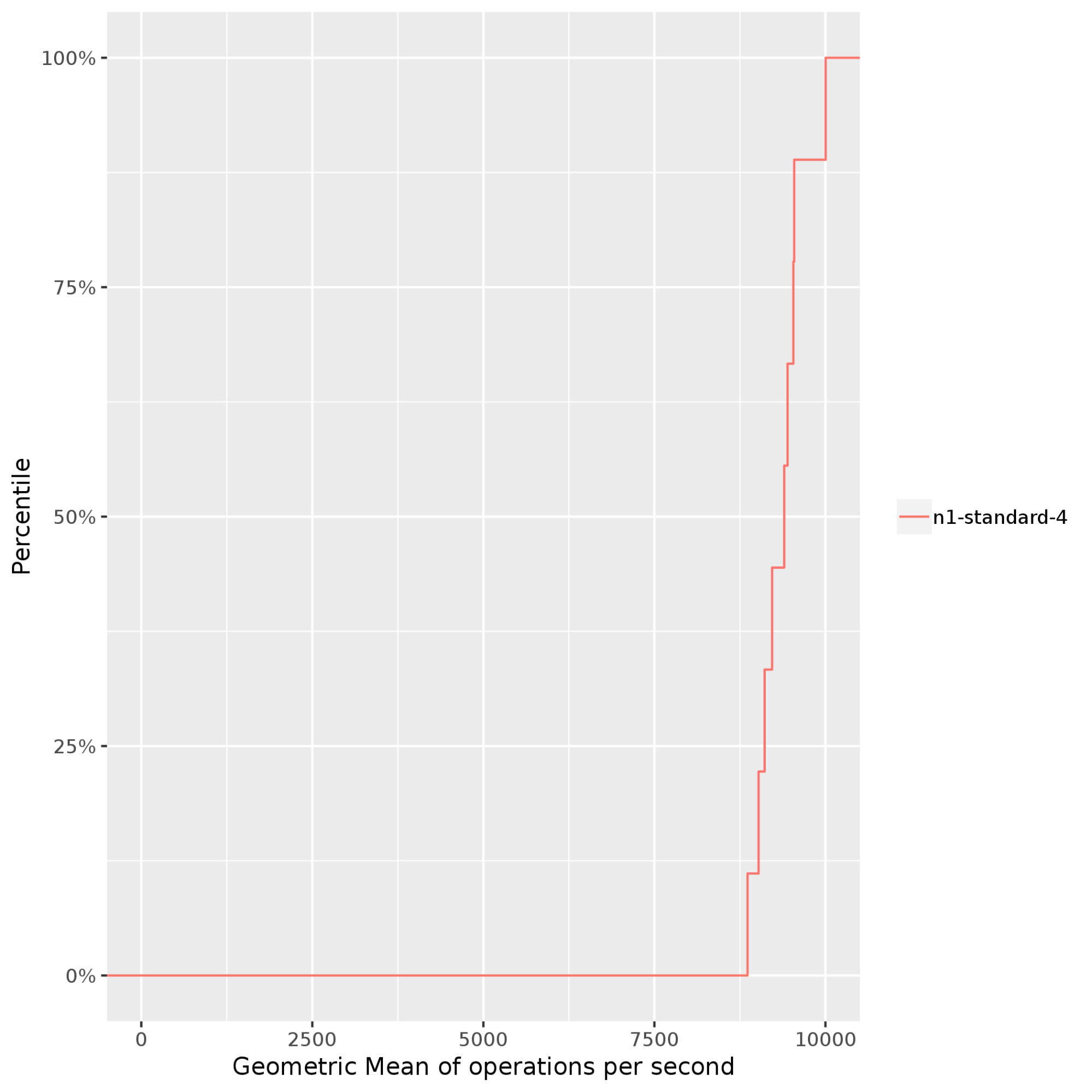
Netperf: リクエスト テストとレスポンス テストでレイテンシを測定します。リクエスト テストとレスポンス テストは、ネットワーク スタックのアプリケーション レイヤで実施されます。レイテンシをテストするこの方法は、スタックのすべてのレイヤに関係し、ping テストよりも VM 間レイテンシを測定する場合に適しています。次のグラフは、同じ Google Cloud ゾーンで実行されているクライアントとサーバー間の TCP リクエストとレスポンス(TCP_RR)のレイテンシを示しています。TCP_RR の値は、50 パーセンタイルで約 70 マイクロ秒から、90 パーセンタイルで約 130 マイクロ秒までの範囲になります。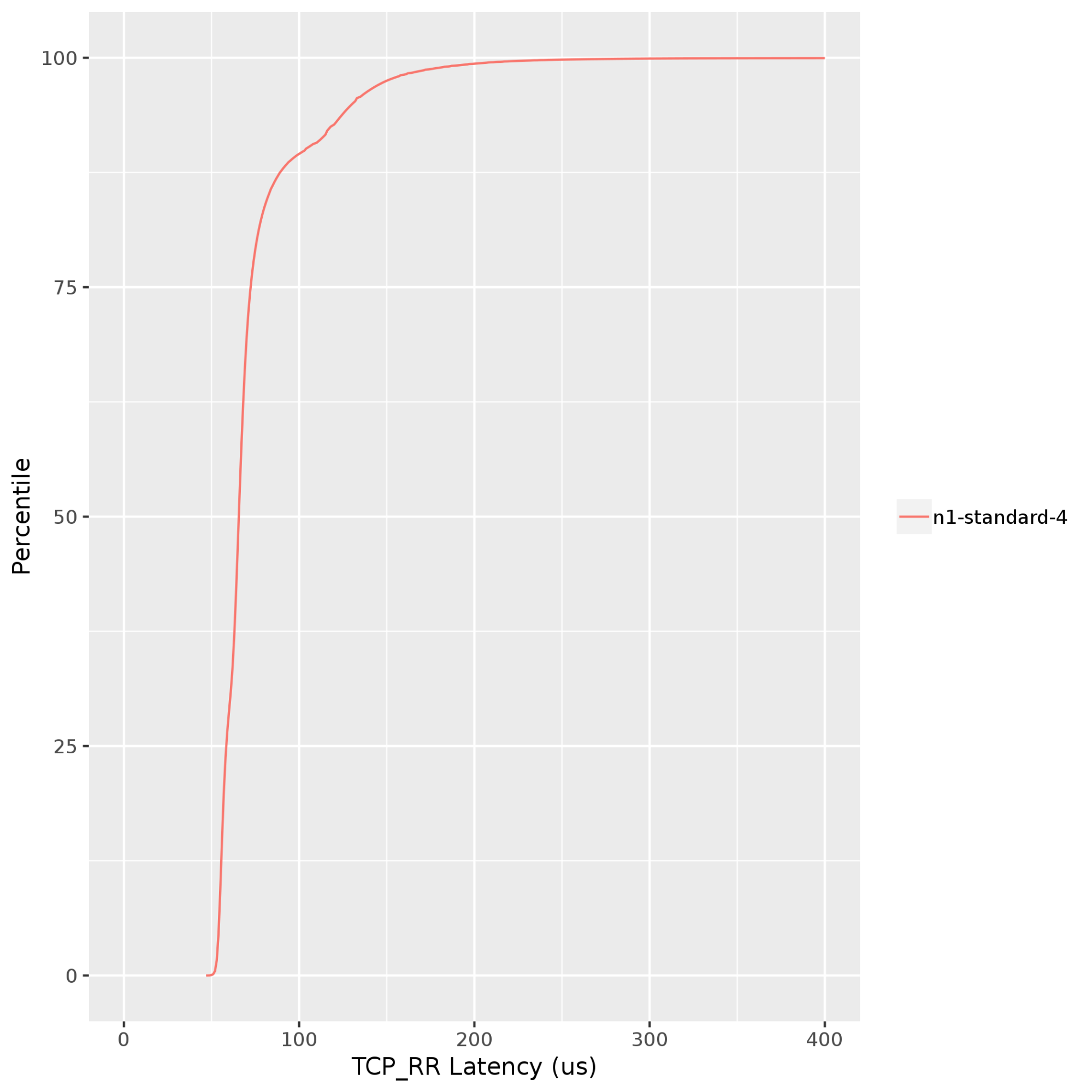
ターゲット ワークロードの性質を考慮して、PerfKit を使用することで他のテスト プロファイルも実行できます。詳しくは、PerfKit でサポートされているベンチマークをご覧ください。
Google Cloud のベスト プラクティス
Google Cloud で移行計画を準備して実施する前に、移行のベスト プラクティスに従うことをおすすめします。これらの方法は出発点にすぎません。依存関係の分離、フォールト トレランスの導入、コンポーネント ワークロードに基づくスケールアップとスケールダウンなど、アプリケーションのさまざまな側面と、各側面を Google Cloud にどのようにマッピングするかを検討する必要があります。
Google Cloud の上限と割り当てを把握する。容量の評価を正式に開始する前に、Google Cloud でのリソース計画に関する重要な考慮事項をいくつかご確認ください。たとえば、次のようなものです。
移行時に必要となる Infrastructure as a Service(IaaS)コンポーネントと Platform as a Service(PaaS)コンポーネントをリストアップし、割り当てと上限、および各サービスで利用可能な微調整をしっかり理解します。
リソースを継続的にモニタリングする。継続的なリソース モニタリングは、システムとアプリケーション パフォーマンスのパターンと傾向を特定するうえで役立ちます。モニタリングは、ベースライン パフォーマンスの確立に役立つだけでなく、時間経過とともにハードウェアのアップグレードやダウングレードの必要性も示します。Google Cloud には、エンドツーエンドのモニタリング ソリューションをデプロイするためのさまざまなオプションが用意されています。
VM のサイズを適切に設定する。VM のプロビジョニングが不足または過剰かどうか特定します。前述のように基本的なモニタリングを設定すると、これらの分析情報を簡単に取得できます。Google Cloud では、インスタンスの過去の使用状況に基づいて、適正サイズの推奨も行います。さらに、ワークロードの特性に基づいて、事前定義されたマシンタイプがニーズを満たさない場合は、カスタムの仮想ハードウェア設定でインスタンスを作成できます。
適切なツールを使用する。大規模な環境では、手動での労力を最小限に抑えるため、次のような自動化ツールをデプロイします。
- StratoZone と CloudPhysics は、アプリケーションの検出と既存のインベントリ データの収集に使用します。
- Migrate to Virtual Machines は、VM を Google Cloud に移行します。また、組み込みテストでクラウド内のパフォーマンス、SLA、コストを検証することもできます。
- Database Migration Service は、データとデータベースを Google Cloud に移行します。
- Cloud Deployment Manager は、クラウドのインフラストラクチャのリソースをコードとして(IaC)プロビジョニングします。
要点
リソースをある環境から別の環境に移行するには、綿密な計画が必要です。ハードウェアのリソースを分離して見るのではなく、アプリケーションをエンドツーエンドで見渡すことが重要です。たとえば、3.0 GHz の Sandy Bridge プロセッサが、1.5 GHz の Skylake プロセッサよりも 2 倍速いかどうかということだけに注目するのではなく、異なるコンピューティング プラットフォームに変えることで、アプリケーションの主要なパフォーマンス指標がどのように変化するかに注目します。
さまざまな環境にわたってリソース マッピングの要件を評価する場合は、次の点を考慮してください。
- アプリケーションが制約を受けるシステム リソース(CPU、メモリ、ディスク、ネットワークなど)。
- 基盤となるインフラストラクチャ(プロセッサの世代、クロック速度、HDD、SSD など)がアプリケーション パフォーマンスに与える影響。
- ソフトウェアやアーキテクチャ設計の選択(シングルまたはマルチスレッド ワークロード、固定デプロイまたは自動スケーリング デプロイなど)がアプリケーション パフォーマンスに与える影響。
- コンピューティング、ストレージ、ネットワーク リソースの現在と予想される使用率レベル。
- アプリケーションを表すのに最も適切なパフォーマンス テスト。
継続的なモニタリングにより、これらの指標に対するデータを収集すると、最初のキャパシティ プランニングの決定に役立ちます。適切なパフォーマンス ベンチマークを続けて実施して、最初のサイズ設定の見積りを微調整できます。
次のステップ
- VM を Google Cloud に移行するためのベスト プラクティスの詳細を確認する。
- Google Cloud の移行センターについて確認する。
- Cloud Foundation Toolkit の詳細について確認する。
- Google Cloud の移行を開始する方法の詳細を確認する。
- Google Cloud と他のクラウド プラットフォームを比較する方法の詳細について確認する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センター をご覧ください。