This document describes how you query, view, and analyze log entries by using the Google Cloud console. There are two interfaces available to you, the Logs Explorer and Log Analytics. You can query, view, and analyze logs with both interfaces; however, they use different query languages and they have different capabilities. For troubleshooting and exploration of log data, we recommend using the Logs Explorer. To generate insights and trends, we recommend that you use Log Analytics. You can query your logs and save your queries by issuing Logging API commands. You can also query your logs by using Google Cloud CLI.
Logs Explorer
The Logs Explorer is designed to help you troubleshoot and analyze the performance of your services and applications. For example, a histogram displays the rate of errors. If you see a spike in errors or something that is interesting, you can locate and view the corresponding log entries. When a log entry is associated with an error group, the log entry is annotated with a menu of options that let you access more information about the error group.
The same query language is supported by the Cloud Logging API, the Google Cloud CLI, and the Logs Explorer. To simplify query construction when you are using the Logs Explorer, you can build queries by using menus, by entering text, and, in some cases, by using options included with the display of an individual log entry.
The Logs Explorer doesn't support aggregate operations, like counting the number of log entries that contain a specific pattern. To perform aggregate operations, enable analytics on the log bucket and then use Log Analytics.
For details about searching and viewing logs with the Logs Explorer, see View logs by using the Logs Explorer.
Log Analytics
Using Log Analytics, you can run queries that analyze your log data, and then you can view or chart the query results. Charts let you identify patterns and trends in your logs over time. The following screenshot illustrates the charting capabilities in Log Analytics:
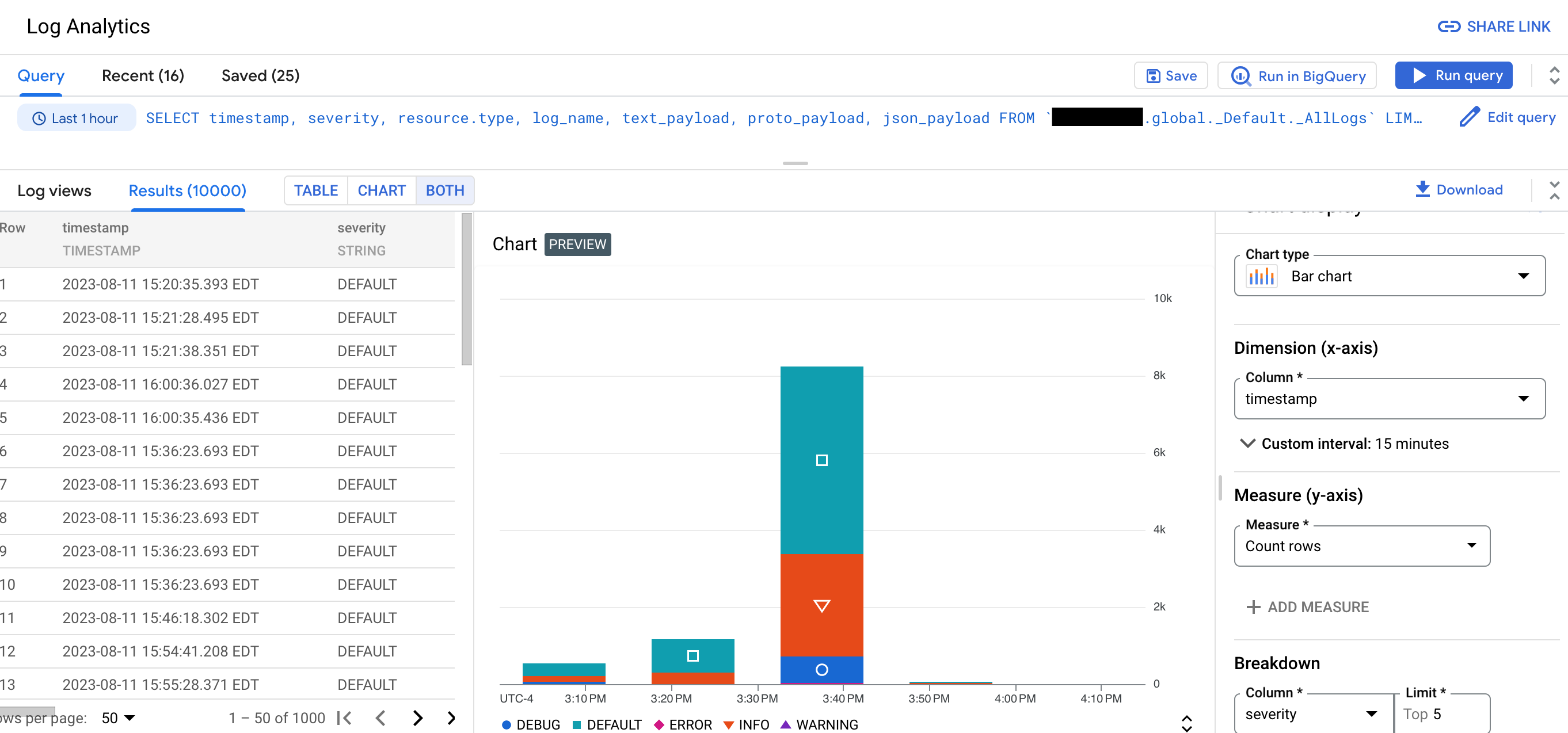
For example, suppose that you are troubleshooting a problem and you want to know the average latency for HTTP requests issued to a specific URL over time. When a log bucket is upgraded to use Log Analytics, you can use SQL queries to query logs stored in your log bucket. By grouping and aggregating your logs, you can gain insights into your log data which can help you reduce time spent troubleshooting.
Log Analytics also let you use BigQuery to query your data. For example, suppose that you want to use BigQuery to compare URLs in your logs with a public dataset of known malicious URLs. To make your log data visible to BigQuery, upgrade your bucket to use Log Analytics and then create a linked dataset.
You can continue to troubleshoot issues and view individual log entries in upgraded log buckets by using the Logs Explorer.
Restrictions
Not all regions are supported for Log Analytics. For more information, see Supported regions.
To upgrade an existing log bucket to use Log Analytics, the following restrictions apply:
- The log bucket is unlocked unless it is the
_Requiredbucket. - There aren't pending updates to the bucket.
- Not all regions are supported for Log Analytics. For more information, see Supported regions.
- The log bucket is unlocked unless it is the
On log buckets that are upgraded to use Log Analytics, you can't do any of the following:
- Remove Log Analytics support.
You can delete the link to a linked BigQuery dataset. Deleting the link doesn't change your ability to query views on the log bucket by using the Log Analytics page.
Only log entries written after the upgrade has completed are available for analytics.
Pricing
Cloud Logging doesn't charge to route logs to a
supported destination; however, the destination might apply charges.
With the exception of the _Required log bucket,
Cloud Logging charges to stream logs into log buckets and
for storage longer than the default retention period of the log bucket.
Cloud Logging doesn't charge for copying logs, or for queries issued through the Logs Explorer page or through the Log Analytics page.
For more information, see the following documents:
- Cloud Logging pricing summary
Destination costs:
- VPC flow log generation charges apply when you send and then exclude your Virtual Private Cloud flow logs from Cloud Logging.
There are no BigQuery ingestion or storage costs when you upgrade a bucket to use Log Analytics and then create a linked dataset. When you create a linked dataset for a log bucket, you don't ingest your log data into BigQuery. Instead, you get read access to the log data stored in your log bucket through the linked dataset.
BigQuery analysis charges apply when you run SQL queries on BigQuery linked datasets, which includes using the BigQuery Studio page, the BigQuery API, and the BigQuery command-line tool.
Blogs
For more information about Log Analytics, see the following blog posts:
- For an overview of Log Analytics, see Log Analytics in Cloud Logging is now GA.
- To learn about creating charts generated by Log Analytics queries and saving those charts to custom dashboards, see Announcing Log Analytics charts and dashboards in Cloud Logging in public preview.
- To learn about analyzing audit logs by using Log Analytics, see Gleaning security insights from audit logs with Log Analytics.
- If you route logs to BigQuery and want to understand the difference between that solution and using Log Analytics, then see Moving to Log Analytics for BigQuery export users.
What's next
- Create a log bucket and upgrade it to use Log Analytics
- Upgrade an existing bucket to use Log Analytics
Build queries:
Sample queries: