Neste tutorial, demonstramos como usar o Dataflow para extrair, transformar e carregar (ETL) dados de um banco de dados relacional de processamento de transações on-line (OLTP, na sigla em inglês) no BigQuery para análise.
Ele se destina a administradores de bancos de dados, profissionais de operações e arquitetos de nuvem interessados em aproveitar os recursos de consulta analítica do BigQuery e de processamento em lote do Dataflow.
Os bancos de dados OLTP geralmente são relacionais. Eles armazenam informações e processam transações para sites de comércio eletrônico, aplicativos de Software as a Service (SaaS) ou jogos. Normalmente, esses bancos de dados são otimizados para transações que exigem as propriedades ACID: atomicidade, consistência, isolamento e durabilidade. Além disso, eles geralmente têm esquemas altamente normalizados. Por outro lado, os armazenamentos de dados costumam ser otimizados para recuperação e análise de dados em vez de transações, e normalmente têm esquemas desnormalizados. Geralmente, a desnormalização dos dados de um banco OLTP o torna mais útil para a análise no BigQuery.
Objetivos
Neste tutorial, você verá duas abordagens para converter dados de RDBMS normalizados por ETL em dados do BigQuery desnormalizados:
- Usar o BigQuery para carregar e transformar os dados. Use essa abordagem para carregar um pequeno volume de dados uma única vez no BigQuery para análise. Também é possível usar essa abordagem para criar o protótipo do conjunto de dados antes de automatizar conjuntos maiores ou vários conjuntos.
- Usar o Dataflow para carregar, transformar e limpar os dados. Essa abordagem é ideal para carregar um volume maior de dados, dados de várias origens ou carregar dados de maneira incremental ou automática.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Compute Engine e Dataflow.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Compute Engine e Dataflow.
Como usar o conjunto de dados MusicBrainz
Este tutorial baseia-se nos snapshots JSON das tabelas do banco de dados do MusicBrainz. O banco foi criado no PostgreSQL e contém informações sobre todas as músicas do MusicBrainz. Estes são alguns elementos do esquema do MusicBrainz (em inglês):
- Artistas
- Grupos de lançamentos
- Lançamentos
- Gravações
- Obras
- Gravadoras
- Várias relações (em inglês) entre essas entidades
O esquema do MusicBrainz inclui três tabelas relevantes: artist, recording e artist_credit_name. Um artist_credit representa o crédito dado ao artista por uma gravação e as linhas artist_credit_name vinculam a gravação ao artista correspondente pelo valor artist_credit.
Neste tutorial, as tabelas do PostgreSQL já foram extraídas no formato
JSON delimitado por nova linha e armazenadas no bucket
público do Cloud Storage: gs://solutions-public-assets/bqetl.
Se quiser executar essa etapa por conta própria, é necessário ter um banco de dados PostgreSQL com o conjunto de dados MusicBrainz e usar os seguintes comandos para exportar cada uma das tabelas:
host=POSTGRES_HOST
user=POSTGRES_USER
database=POSTGRES_DATABASE
for table in artist recording artist_credit_name
do
pg_cmd="\\copy (select row_to_json(r) from (select * from ${table}) r ) to exported_${table}.json"
psql -w -h ${host} -U ${user} -d ${db} -c $pg_cmd
# clean up extra '\' characters
sed -i -e 's/\\\\/\\/g' exported_${table}.json
done
Abordagem 1: ETL com o BigQuery
Use essa abordagem para carregar um pequeno volume de dados uma única vez no BigQuery para análise. Ela também pode ser usada para criar o protótipo do conjunto de dados antes de usar a automatização em grandes ou vários conjuntos.
Crie um conjunto de dados do BigQuery
Para criar um conjunto de dados do BigQuery, carregue as tabelas do MusicBrainz individualmente e combine-as para que cada linha contenha o vínculo de dados desejado. Armazene os resultados dessa junção em uma nova tabela do BigQuery. Em seguida, exclua as tabelas originais que você carregou.
No console do Google Cloud, abra o BigQuery.
No painel Explorer, clique no menu more_vert ao lado do nome do projeto e, em seguida, clique em Criar conjunto de dados.
Na caixa de diálogo Criar conjunto de dados, siga estas etapas:
- No campo ID do conjunto de dados, digite
musicbrainz. - Defina o Local dos dados como us.
- Clique em Criar conjunto de dados.
- No campo ID do conjunto de dados, digite
Importar tabelas do MusicBrainz
Para cada tabela do MusicBrainz, siga as etapas a seguir para adicionar uma tabela ao conjunto de dados criado:
- No painel Explorer do BigQuery no console do Google Cloud,
abra a linha com o nome do seu projeto para mostrar o conjunto de dados
musicbrainzrecém-criado. - Clique no menu
more_vert
ao lado do conjunto de dados
musicbrainze, em seguida, clique em Criar tabela. Na caixa de diálogo Criar conjunto de dados, siga estas etapas:
- Na lista suspensa Criar tabela na lista suspensa, selecione Google Cloud Storage.
No campo Selecionar arquivo do bucket do GCS, insira o caminho para o arquivo de dados:
solutions-public-assets/bqetl/artist.jsonEm Formato do arquivo, selecione JSONL (JSON delimitado por nova linha).
Verifique se Projeto contém o nome do projeto.
Verifique se Conjunto de dados é
musicbrainz.Em Tabela, insira o nome da tabela,
artist.Em Tipo de tabela, deixe Tabela nativa selecionada.
Abaixo da seção Esquema, clique na opção Editar como texto para ativá-la.
Faça o download do arquivo de esquema
artiste abra em um editor de texto ou visualizador.Substitua o conteúdo da seção Esquema pelo conteúdo do arquivo de esquema baixado.
Clique em Criar tabela:
Aguarde alguns instantes até que o job de carregamento seja concluído.
Após a conclusão, a nova tabela aparecerá no conjunto de dados.
Repita as etapas de 1 a 5 para criar a tabela
artist_credit_namecom as mudanças a seguir:Use o caminho a seguir para o arquivo de dados de origem:
solutions-public-assets/bqetl/artist_credit_name.jsonUse
artist_credit_namecomo o nome da Tabela.Faça o download do arquivo de esquema
artist_credit_namee use o conteúdo do esquema.
Repita as etapas de 1 a 5 para criar a tabela
recordingcom as mudanças a seguir:Use o caminho a seguir para o arquivo de dados de origem:
solutions-public-assets/bqetl/recording.jsonUse
recordingcomo o nome da Tabela.Faça o download do arquivo de esquema
recordinge use o conteúdo do esquema.
Desnormalizar manualmente os dados
Para desnormalizar os dados, mescle-os em um nova tabela do BigQuery que tenha uma linha para cada gravação de artista, junto com os metadados selecionados que você quer reter para análise.
- Se o editor de consultas do BigQuery não estiver aberto no console do Google Cloud, clique em add_box Criar nova consulta.
Copie a consulta a seguir e cole-a no Editor de consultas:
SELECT artist.id, artist.gid AS artist_gid, artist.name AS artist_name, artist.area, recording.name AS recording_name, recording.length, recording.gid AS recording_gid, recording.video FROM `musicbrainz.artist` AS artist INNER JOIN `musicbrainz.artist_credit_name` AS artist_credit_name ON artist.id = artist_credit_name.artist INNER JOIN `musicbrainz.recording` AS recording ON artist_credit_name.artist_credit = recording.artist_creditClique na lista suspensa settings Mais e selecione Configurações de consulta.
Na caixa de diálogo Configurações de consulta, conclua as etapas a seguir:
- Selecione Definir uma tabela de destino para os resultados da consulta.
- Em Conjunto de dados, insira
musicbrainze selecione o conjunto de dados em seu projeto. - Em ID da tabela, insira
recordings_by_artists_manual. - Em Preferência de gravação na tabela de destino, clique em Substituir tabela.
- Marque a caixa de seleção Permitir resultados extensos (sem limite de tamanho).
- Clique em Save.
Clique em play_circle_filled Executar.
Quando a consulta é concluída, os dados do resultado são organizados em músicas para cada artista na tabela do BigQuery recém-criada e uma amostra dos resultados exibidos nos Resultados da consulta. painel, por exemplo:
Linha id artist_gid artist_name area recording_name length recording_gid video 1 97546 125ec42a... unknown 240 Horo Gun Toireamaid Hùgan Fhathast Air 174106 c8bbe048... FALSE 2 266317 2e7119b5... Capella Istropolitana 189 Concerto Grosso in D minor, op. 2 no. 3: II. Adagio 134000 af0f294d... FALSE 3 628060 34cd3689... Conspirare 5196 Liturgy, op. 42: 9. Praise the Lord from the Heavens 126933 8bab920d... FALSE 4 423877 54401795... Boys Air Choir 1178 Nunc Dimittis 190000 111611eb... FALSE 5 394456 9914f9f9... L’Orchestre de la Suisse Romande 23036 Concert Waltz no. 2, op. 51 509960 b16742d1... FALSE
Abordagem 2: ETL no BigQuery com o Dataflow
Nesta seção do tutorial, em vez de usar a IU do BigQuery, você usa um programa de exemplo para carregar dados no BigQuery usando um pipeline do Dataflow. Em seguida, use o modelo de programação do Beam para desnormalizar e limpar dados a serem carregados no BigQuery.
Antes de começar, consulte os conceitos e o código de exemplo.
Consultar os conceitos
Os dados são pequenos e podem ser enviados rapidamente usando a IU do BigQuery, porém, para os fins deste tutorial, também é possível usar o Dataflow para ETL. Use o Dataflow para ETL no BigQuery em vez da IU do BigQuery quando estiver realizando mesclagens em massa, ou seja, de cerca de 500 a 5.000 colunas de mais de 10 TB de dados, com as seguintes metas:
- É recomendável limpar ou transformar os dados conforme eles são carregados no BigQuery, em vez de armazená-los e mesclá-los posteriormente. Essa abordagem tem requisitos de armazenamento mais baixos, porque os dados só são armazenados no BigQuery no estado mesclado e transformado.
- Você planeja fazer uma limpeza de dados personalizada, que não é possível simplesmente com o SQL.
- Você planeja combinar esses dados com outros fora do OLTP, como registros ou dados acessados remotamente, durante o processo de carregamento.
- Você planeja automatizar o teste e a implantação da lógica do carregamento de dados usando integração ou implantação contínuas (CI/CD, na sigla em inglês).
- Você prevê uma iteração gradual, melhorias e aprimoramentos no processo de ETL ao longo do tempo.
- Você planeja adicionar dados incrementalmente, em vez de executar o ETL apenas uma vez.
Veja um diagrama do pipeline de dados criado pelo programa de exemplo:

No código de exemplo, várias etapas do pipeline são agrupadas ou encapsuladas em métodos de conveniência, nomeadas com nomes descritivos e reutilizadas. No diagrama, as etapas reutilizadas estão indicadas pelo contorno tracejado.
Revisar o código do pipeline
O código cria um pipeline que executa as etapas a seguir:
Carrega cada tabela que você quer que faça parte da mesclagem do bucket público do Cloud Storage em uma
PCollectionde strings. Cada elemento compõe a representação JSON de uma linha da tabela.Converte essas strings JSON em representações de objeto, objetos
MusicBrainzDataObjecte, em seguida, organiza as representações de objeto por um dos valores de coluna, como uma chave primária ou externa.A lista é mesclada com base no artista em comum. O
artist_credit_namevincula um crédito de artista à gravação correspondente e inclui a chave estrangeira do artista. A tabelaartist_credit_nameé carregada como uma lista de objetosKVde valor-chave. O membroKé o artista.Mescla a lista usando o método
MusicBrainzTransforms.innerJoin().- Agrupa as coleções de objetos
KVpelo membro chave pelo qual será feita a mesclagem. Isso gera umPCollectionde objetosKVcom uma chave longa (o valor da colunaartist.id) e oCoGbkResultresultante (que significa combinar o grupo por resultado de chave). O objetoCoGbkResulté uma tupla de listas de objetos com o valor de chave em comum no primeiro e no segundoPCollections. Essa tupla pode ser endereçada usando a tag de tupla formulada para cadaPCollectionantes de executar a operaçãoCoGroupByKeyno métodogroup. Mescla cada correspondência de objetos em um objeto
MusicBrainzDataObjectque representa um resultado de mesclagem.A coleção é reorganizada em uma lista de objetos
KVpara iniciar a próxima mesclagem. Desta vez, o valorKé a colunaartist_credit, que é usada na mesclagem com a tabela de gravação.A coleção final de objetos
MusicBrainzDataObjectprovém da mesclagem desse resultado com a coleção de gravações carregada que está organizada porartist_credit.id.Mapeia os objetos
MusicBrainzDataObjectsresultantes emTableRows.Grava o
TableRowsresultante no BigQuery.
- Agrupa as coleções de objetos
Para detalhes sobre a dinâmica da programação de pipeline do Beam, consulte os seguintes tópicos sobre o modelo de programação:
PCollection- Como carregar dados de arquivos de texto (incluindo o Cloud Storage)
- Transformações como
ParDoe MapElements` - Mesclagem e
GroupByKey - E/S do BigQuery
Depois de revisar as etapas que o código executa, execute o pipeline.
Crie um bucket do Google Cloud Storage
Executar o código do pipeline
No Console do Google Cloud, abra o Cloud Shell.
Defina as variáveis de ambiente do projeto e o script do pipeline
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow export DATASET=musicbrainzSubstitua PROJECT_ID pelo ID do projeto do Google Cloud.
Verifique se
gcloudestá usando o projeto que você criou ou selecionou no início do tutorial:gcloud config set project $PROJECT_IDSeguindo o princípio de segurança de privilégio mínimo, crie uma conta de serviço para o pipeline do Dataflow e conceda a ela apenas os privilégios necessários:
roles/dataflow.worker,roles/bigquery.jobUsere odataEditor. papel no conjunto de dadosmusicbrainz:gcloud iam service-accounts create musicbrainz-dataflow export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/dataflow.worker gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/bigquery.jobUser bq query --use_legacy_sql=false \ "GRANT \`roles/bigquery.dataEditor\` ON SCHEMA musicbrainz TO 'serviceAccount:${SERVICE_ACCOUNT}'"Crie um bucket para o pipeline do Dataflow usar para arquivos temporários e conceda a ele os privilégios
Ownerda conta de serviçomusicbrainz-dataflow:export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} gsutil mb -l us ${DATAFLOW_TEMP_BUCKET} gsutil acl ch -u ${SERVICE_ACCOUNT}:O ${DATAFLOW_TEMP_BUCKET}Clone o repositório que contém o código do Dataflow:
git clone https://github.com/GoogleCloudPlatform/bigquery-etl-dataflow-sample.gitMude o diretório para o exemplo:
cd bigquery-etl-dataflow-sampleCompile e execute o job do Dataflow:
./run.sh simpleO job deve levar cerca de 10 minutos para ser executado.
Para ver o progresso do pipeline, no console do Google Cloud, acesse a página do Dataflow.
O status dos jobs é mostrado na coluna de status. O status Concluído indica que o job foi concluído.
(Opcional) Para ver o gráfico do job e os detalhes sobre as etapas, clique no nome do job, por exemplo,
etl-into-bigquery-bqetlsimple.Quando o job for concluído, acesse a página do BigQuery.
Para executar uma consulta na nova tabela, no painel Editor de consultas, insira o seguinte:
SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;O painel de resultados vai mostrar um conjunto de resultados semelhantes aos seguintes:
Linha artist_name artist_gender artist_area recording_name recording_length 1 mirin 2 107 Sylphia 264000 2 mirin 2 107 Dependence 208000 3 Gaudiburschen 1 81 Die Hände zum Himmel 210000 4 Sa4 1 331 Ein Tag aus meiner Sicht 221000 5 Dpat 1 7326 Cutthroat 249000 6 Dpat 1 7326 Deloused 178000 A saída real pode ser diferente porque os resultados não são ordenados.
Limpar os dados
Em seguida, faça uma pequena alteração no pipeline do Dataflow para carregar tabelas de consulta e processá-las como entradas secundárias, conforme mostrado no diagrama a seguir.

Quando você consulta a tabela resultante do BigQuery, é difícil determinar de onde provém o artista sem procurar manualmente o ID numérico da área da tabela area no banco de dados MusicBrainz. Com isso, a análise dos resultados da consulta fica menos direta do que poderia ser.
De modo semelhante, os gêneros dos artistas aparecem como IDs, mas a tabela de gêneros do MusicBrainz só tem três linhas. Para corrigir isso, adicione uma etapa no pipeline do Dataflow que use as tabelas area e gender do MusicBrainz para mapear os IDs para os devidos rótulos.
As tabelas artist_area e artist_gender contêm um número significativamente menor de linhas do que artistas ou tabelas de dados de gravação. O número de elementos nas tabelas posteriores é limitado pelo número de áreas geográficas ou de gêneros, respectivamente.
Consequentemente, a etapa de pesquisa usa o recurso do Dataflow denominado entrada secundária (em inglês).
As entradas secundárias são carregadas como exportações de tabela de arquivos JSON delimitados por linha no bucket público do Cloud Storage que contém o conjunto de dados musicbrainz e são usadas para desnormalizar os dados da tabela em uma única etapa.
Revisar o código que adiciona entradas secundárias ao pipeline
Antes de executar o pipeline, revise o código para entender melhor as novas etapas.
Este código demonstra da limpeza dos dados com entradas secundárias. A classe MusicBrainzTransforms oferece mais conveniência no uso de entradas secundárias para mapear valores de chave estrangeira para rótulos. A biblioteca MusicBrainzTransforms fornece um método que cria uma classe de pesquisa interna. A classe de pesquisa descreve cada tabela de consulta e os campos que são substituídos por rótulos e argumentos de comprimento variável. keyKey é o nome da coluna que contém a chave para a pesquisa e valueKey é o nome da coluna que contém o rótulo correspondente.
Cada entrada secundária é carregada como um único objeto de mapa, que é usado para consultar o rótulo correspondente a um ID.
Primeiro, o JSON da tabela de consulta é carregado em MusicBrainzDataObjects com namespace vazio e transformado em mapa, do valor da coluna Key para o valor da coluna Value.
Cada um desses objetos Map é colocado em um Map pelo valor de destinationKey, que é a chave a ser substituída pelos valores pesquisados.
Em seguida, ao transformar os objetos de artista pelo JSON, o valor de destinationKey (que começa como um número) é substituído pelo rótulo.
Para adicionar a decodificação dos campos artist_area e artist_gender,
siga estas etapas:
No Cloud Shell, verifique se o ambiente está configurado para o script do pipeline:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_sideinputs export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comSubstitua PROJECT_ID pelo ID do projeto do Google Cloud.
Execute o pipeline para criar a tabela com a área decodificada e o gênero do artista:
./run.sh simple-with-lookupsComo antes, para ver o progresso do pipeline, acesse a página Dataflow.
O pipeline vai levar aproximadamente 10 minutos para concluir a operação.
Quando o job for concluído, acesse a página do BigQuery.
Execute a mesma consulta que inclui
artist_areaeartist_gender:SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow_sideinputs WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;Na saída,
artist_areaeartist_genderagora são decodificados:Linha artist_name artist_gender artist_area recording_name recording_length 1 mirin Female Japan Sylphia 264000 2 mirin Female Japan Dependence 208000 3 Gaudiburschen Male Germany Die Hände zum Himmel 210000 4 Sa4 Male Hamburg Ein Tag aus meiner Sicht 221000 5 Dpat Male Houston Cutthroat 249000 6 Dpat Male Houston Deloused 178000 A saída real pode ser diferente porque os resultados não são ordenados.
Otimizar o esquema do BigQuery
Na parte final deste tutorial, você executará um pipeline que gera um esquema de tabela mais otimizado usando campos aninhados.
Revise o código usado para gerar essa versão otimizada da tabela.
No diagrama a seguir, veja um pipeline do Dataflow um pouco diferente. Em vez de linhas duplicadas, você tem as gravações de artistas aninhadas dentro de cada linha de artista.

A representação atual dos dados é bastante simples. Isso significa que ela inclui uma linha por gravação creditada que, por sua vez, inclui todos os metadados do artista do esquema do BigQuery e todas as gravações e metadados de artist_credit_name. Essa representação simples tem pelo menos duas desvantagens:
- Os metadados de
artistsão repetidos para cada gravação creditada a um artista, o que aumenta o armazenamento necessário. - Ao exportar os dados como JSON, você terá uma matriz com dados repetidos, em vez de um artista com os dados de gravação aninhados, o que você provavelmente quer.
Sem prejudicar o desempenho e sem usar armazenamento extra, é possível armazenar as gravações como um campo repetido em cada registro de artista, em vez de armazenar uma gravação por linha. Bastam algumas alterações no pipeline do Dataflow.
Em vez de mesclar as gravações com as informações do artista por artist_credit_name.artist, neste pipeline alternativo, criamos uma lista aninhada de gravações dentro de um objeto de artista.
A API BigQuery tem um limite máximo de tamanho de linha
de 100 MB ao realizar inserções em massa (10 MB para inserções por streaming).
Por isso, o código limita o número de gravações aninhadas para um determinado registro. 1.000 elementos
para garantir que o limite não seja atingido. Se um determinado artista tiver mais de 1.000 gravações, o código duplicará a linha, incluindo os metadados de artist, e continuará aninhando os dados de gravação na linha duplicada.
No diagrama, veja as origens, transformações e coletores do pipeline.
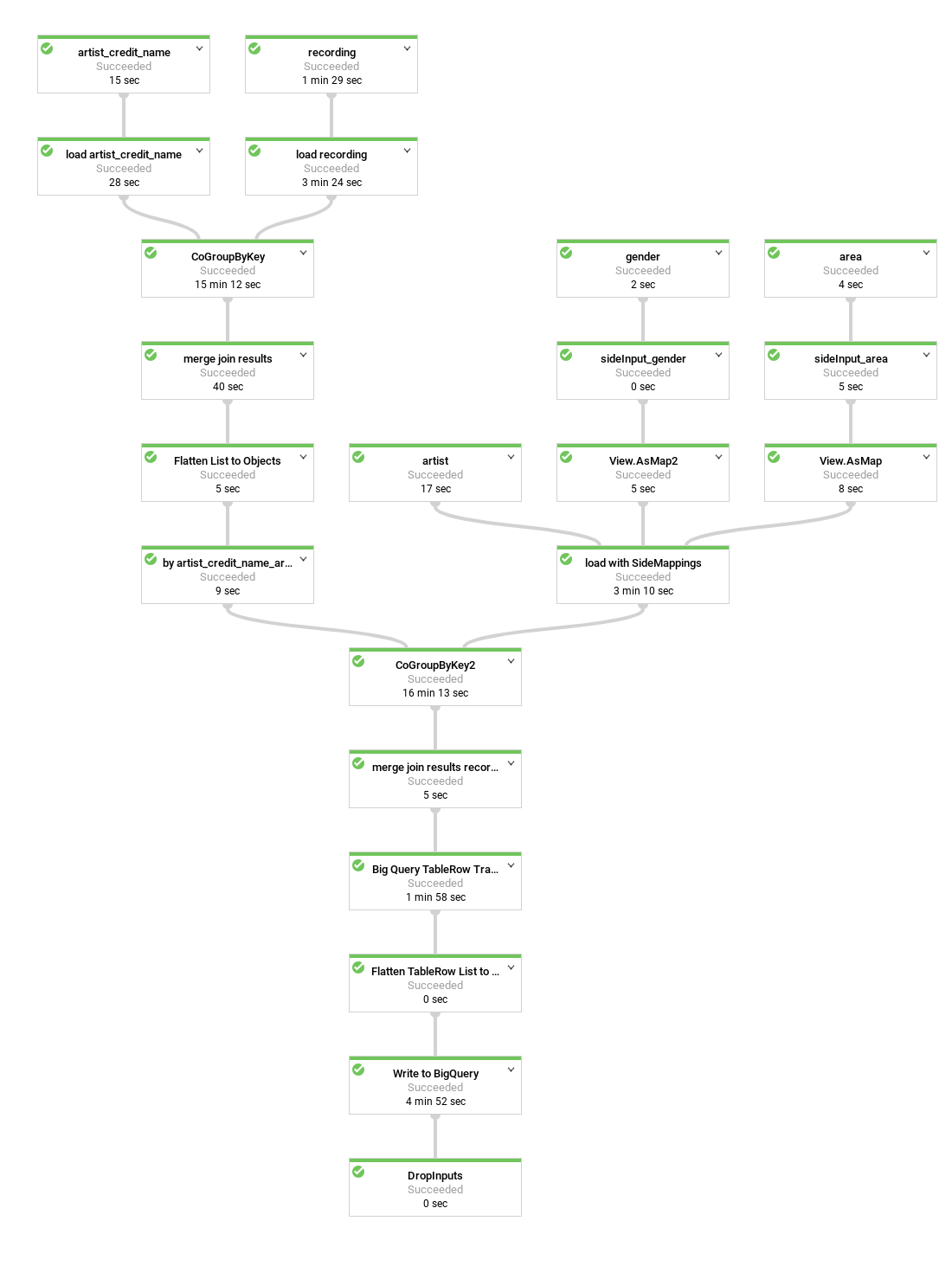
Na maioria dos casos, os nomes das etapas são fornecidos no código como parte da chamada de método apply.
Para criar esse pipeline otimizado, siga estas etapas:
No Cloud Shell, verifique se o ambiente está configurado para o script do pipeline:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_nested export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comExecute o pipeline para aninhar as linhas de gravação dentro das linhas de artista:
./run.sh nestedComo antes, para ver o progresso do pipeline, acesse a página Dataflow.
O pipeline vai levar aproximadamente 10 minutos para concluir a operação.
Quando o job for concluído, acesse a página do BigQuery.
Campos de consulta da tabela aninhada no BigQuery:
SELECT artist_name, artist_gender, artist_area, artist_recordings FROM musicbrainz.recordings_by_artists_dataflow_nested WHERE artist_area IS NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;Na saída, os
artist_recordingssão mostrados como linhas aninhadas que podem ser expandidas:Linha artist_name artist_gender artist_area artist_recordings 1 mirin Female Japan (5 rows) 3 Gaudiburschen Male Germany (1 row) 4 Sa4 Male Hamburg (10 rows) 6 Dpat Male Houston (9 rows) A saída real pode ser diferente porque os resultados não são ordenados.
Execute uma consulta para extrair valores de
STRUCTe usar esses valores para filtrar os resultados. Por exemplo, para artistas que têm gravações contendo a palavra "Justin":SELECT artist_name, artist_gender, artist_area, ARRAY(SELECT artist_credit_name_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS artist_credit_name_name, ARRAY(SELECT recording_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS recording_name FROM musicbrainz.recordings_by_artists_dataflow_nested, UNNEST(recordings_by_artists_dataflow_nested.artist_recordings) AS artist_recordings_struct WHERE artist_recordings_struct.recording_name LIKE "%Justin%" LIMIT 1000;Na saída,
artist_credit_name_nameerecording_namesão mostrados como linhas aninhadas que podem ser expandidas, por exemplo:Linha artist_name artist_gender artist_area artist_credit_name_name recording_name 1 Damonkenutz null null (1 row) 1 Yellowpants (Justin Martin remix) 3 Fabian Male Germany (10+ rows) 1 Heatwave . 2 Starlight Love . 3 Dreams To Wishes . 4 Last Flight (Justin Faust remix) . ... 4 Digital Punk Boys null null (6 rows) 1 Come True . 2 We Are... (Punkgirlz remix by Justin Famous) . 3 Chaos (short cut) . ... A saída real pode ser diferente porque os resultados não são ordenados.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Exclua o projeto
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
Como excluir recursos individuais
Siga estas etapas para remover os recursos individualmente, em vez de excluir o projeto inteiro.
Como excluir o bucket do Cloud Storage
- No Console do Google Cloud, acesse a página Buckets do Cloud Storage.
- Clique na caixa de seleção do bucket que você quer excluir.
- Para excluir o bucket, clique em Excluir e siga as instruções.
Como excluir os conjuntos de dados do BigQuery
Abra a IU da Web do BigQuery.
Selecione os conjuntos de dados do BigQuery criados no tutorial.
Clique em Excluir delete.
A seguir
- Saiba mais sobre como escrever consultas para o BigQuery. Em Como consultar dados, você aprende a executar consultas síncronas e assíncronas, criar funções definidas pelo usuário (UDF, na sigla em inglês) e muito mais.
- Explore a sintaxe do BigQuery. Ela é semelhante à do SQL e está descrita na Referência de consulta (SQL legado).
- Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.