이 가이드에서는 온라인 트랜잭션 처리(OLTP) 관계형 데이터베이스에서 Dataflow를 사용하여 BigQuery로 데이터를 추출, 변환, 로드(ETL) 및 분석하는 방법을 설명합니다.
이 가이드는 BigQuery의 분석 쿼리 기능과 Dataflow의 일괄 처리 기능을 이용하려고 하는 데이터베이스 관리자, 운영 전문가, 클라우드 아키텍트를 대상으로 작성되었습니다.
OLTP 데이터베이스는 전자상거래 사이트, Software as a service(SaaS) 애플리케이션 또는 게임에서 정보를 저장하고 트랜잭션을 처리하는 관계형 데이터베이스인 경우가 많습니다. 또한 대체로 ACID 속성, 즉 개별성, 일관성, 고립성, 지속성을 요구하는 트랜잭션에 최적화되어 정규화된 스키마를 갖는 것이 전형적인 특징입니다. 이와 달리 데이터 웨어하우스는 트랜잭션보다는 데이터 가져오기 및 분석에 최적화되어 일반적으로 정규화되지 않은 스키마가 전형적인 특징입니다. 일반적으로 OLTP 데이터베이스에서 데이터를 정규화하지 않으면 BigQuery에서 분석하는 데 더욱 유용합니다.
목표
본 가이드에서는 정규화된 RDBMS 데이터를 정규화되지 않은 BigQuery 데이터로 추출, 변환, 로드(ETL)하는 두 가지 접근 방식에 대해서 설명합니다.
- BigQuery를 사용해 데이터를 로드하고 변환하는 방식: 분석을 목적으로 소량의 데이터를 BigQuery에 일회성으로 로드할 때 사용합니다. 또한 대규모 또는 여러 데이터 세트를 자동화하기 전에 데이터 세트를 프로토타이핑하는 데 사용되기도 합니다.
- Dataflow를 사용해 데이터를 로드하고, 변환하고, 정리하는 방식: 이 방식은 대용량 데이터를 로드하거나, 여러 데이터 소스에서 데이터를 로드하거나, 데이터를 점진적으로 또는 자동으로 로드하는 데 사용됩니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
API Compute Engine 및 Dataflow 사용 설정
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
API Compute Engine 및 Dataflow 사용 설정
MusicBrainz 데이터 세트 사용:
본 가이드에서는 PostgreSQL을 기반으로 하며 모든 MusicBrainz 음악에 대한 정보가 포함된 MusicBrainz 데이터베이스의 테이블에 대한 JSON 스냅샷을 사용합니다. MusicBrainz 스키마의 일부 요소는 다음과 같습니다.
- 아티스트
- 출시 그룹
- 출시
- 음원
- 작품
- 라벨
- 이러한 항목 간의 많은 관계
MusicBrainz 스키마에는 artist, recording, artist_credit_name이라는 세 가지 관련 테이블이 있습니다. artist_credit은 음원에 대한 아티스트의 크레딧을 나타내며 artist_credit_name 행은 artist_credit 값을 통해 해당 아티스트와 음원을 연결합니다.
이 튜토리얼에서는 이미 줄바꿈으로 구분된 JSON 형식으로 추출되어 공개 Cloud Storage 버킷 gs://solutions-public-assets/bqetl에 저장된 PostgreSQL 테이블을 제공합니다.
이 단계를 직접 수행하려면 MusicBrainz 데이터 세트가 포함된 PostgreSQL 데이터베이스가 있어야 하며 다음 명령어를 사용하여 각 테이블을 내보내야 합니다.
host=POSTGRES_HOST
user=POSTGRES_USER
database=POSTGRES_DATABASE
for table in artist recording artist_credit_name
do
pg_cmd="\\copy (select row_to_json(r) from (select * from ${table}) r ) to exported_${table}.json"
psql -w -h ${host} -U ${user} -d ${db} -c $pg_cmd
# clean up extra '\' characters
sed -i -e 's/\\\\/\\/g' exported_${table}.json
done
접근 방식 1: BigQuery를 사용한 ETL
분석을 목적으로 소량의 데이터를 BigQuery에 일회성으로 로드할 때 사용합니다. 대규모 또는 여러 데이터세트로 자동화를 사용하기 전에 이 접근 방식을 사용하여 데이터세트를 프로토타이핑할 수도 있습니다.
BigQuery 데이터세트 만들기
BigQuery 데이터 세트를 만들려면 MusicBrainz 테이블을 BigQuery에 개별적으로 로드한 다음 로드한 테이블을 조인하여 각 행에 원하는 데이터 연결이 포함되도록 합니다. 새 BigQuery 테이블에 조인 결과를 저장합니다. 그런 다음 로드한 원래 테이블을 삭제할 수 있습니다.
Google Cloud 콘솔에서 BigQuery를 엽니다.
탐색기 패널에서 프로젝트 이름 옆에 있는 메뉴 more_vert를 클릭한 다음 데이터 세트 만들기를 클릭합니다.
데이터 세트 만들기 대화상자에서 다음 단계를 완료합니다.
- 데이터 세트 ID 필드에
musicbrainz를 입력합니다. - 데이터 위치를 us로 설정합니다.
- 데이터 세트 만들기를 클릭합니다.
- 데이터 세트 ID 필드에
MusicBrainz 테이블 가져오기
각 MusicBrainz 테이블마다 다음 단계를 따라 앞에서 만든 데이터 세트에 테이블을 추가합니다.
- Google Cloud 콘솔 BigQuery 탐색기 패널에서 프로젝트 이름이 표시된 행을 펼쳐 새로 만든
musicbrainz데이터 세트를 표시합니다. musicbrainz데이터 세트 옆에 있는 메뉴 more_vert를 클릭한 후 테이블 만들기를 클릭합니다.테이블 만들기 대화상자에서 다음 단계를 완료합니다.
- 다음 항목으로 테이블 만들기 드롭다운 목록에서 Google Cloud Storage를 선택합니다.
GCS 버킷에서 파일 선택 필드에 데이터 파일의 경로를 입력합니다.
solutions-public-assets/bqetl/artist.json파일 형식에서 JSONL(줄바꿈으로 구분된 JSON)을 선택합니다.
프로젝트에 프로젝트 이름이 있는지 확인합니다.
데이터 세트가
musicbrainz인지 확인합니다.테이블에 테이블 이름인
artist를 입력합니다.테이블 유형의 경우 기본 테이블을 선택된 상태로 둡니다.
스키마 섹션 아래에서 텍스트로 수정을 클릭하여 활성화합니다.
artist스키마 파일을 다운로드하고 텍스트 편집기 또는 뷰어에서 엽니다.스키마 섹션의 내용을 다운로드한 스키마 파일의 내용으로 바꿉니다.
테이블 만들기를 클릭합니다.
로드 작업이 완료될 때까지 잠시 기다립니다.
로드가 끝나면 새로운 테이블이 데이터 세트 아래 표시됩니다.
1~5단계를 반복하여 다음과 같이 변경하여
artist_credit_name테이블을 만듭니다.소스 데이터 파일에 다음 경로를 사용합니다.
solutions-public-assets/bqetl/artist_credit_name.json테이블 이름으로
artist_credit_name을 사용합니다.artist_credit_name스키마 파일을 다운로드하고 스키마의 콘텐츠를 사용합니다.
1~5단계를 반복하여 다음과 같이 변경하여
recording테이블을 만듭니다.소스 데이터 파일에 다음 경로를 사용합니다.
solutions-public-assets/bqetl/recording.json테이블 이름으로
recording을 사용합니다.recording스키마 파일을 다운로드하고 스키마의 콘텐츠를 사용합니다.
수동 데이터 비정규화
데이터를 비정규화하려면 분석을 위해 보유하려는 선택한 메타데이터와 함께 각 아티스트의 음원마다 하나의 행이 있는 새로운 BigQuery 테이블에 데이터를 조인합니다.
- Google Cloud 콘솔에서 BigQuery 쿼리 편집기가 열려 있지 않으면 add_box 새 쿼리 작성을 클릭합니다.
다음 쿼리를 복사하여 쿼리 편집기로 붙여넣습니다.
SELECT artist.id, artist.gid AS artist_gid, artist.name AS artist_name, artist.area, recording.name AS recording_name, recording.length, recording.gid AS recording_gid, recording.video FROM `musicbrainz.artist` AS artist INNER JOIN `musicbrainz.artist_credit_name` AS artist_credit_name ON artist.id = artist_credit_name.artist INNER JOIN `musicbrainz.recording` AS recording ON artist_credit_name.artist_credit = recording.artist_creditsettings 더보기 드롭다운 목록을 클릭한 후 쿼리 설정을 선택합니다.
쿼리 설정 대화상자에서 다음 단계를 완료합니다.
- 쿼리 결과의 대상 테이블 설정을 선택합니다.
- 데이터 세트에
musicbrainz를 입력하고 프로젝트의 데이터 세트를 선택합니다. - 테이블 ID에
recordings_by_artists_manual을 입력합니다. - 대상 테이블 쓰기 환경설정에서 테이블 덮어쓰기를 클릭합니다.
- 크기가 큰 결과 허용(크기 제한 없음) 체크박스를 선택합니다.
- 저장을 클릭합니다.
play_circle_filled 실행을 클릭합니다.
쿼리가 완료되면 쿼리 결과의 데이터가 새로 만든 BigQuery 테이블에서 각 아티스트의 노래와 쿼리 결과 창에 표시된 결과의 샘플로 구성됩니다. 예를 들면 다음과 같습니다.
Row id artist_gid artist_name 영역 recording_name 기간 recording_gid 동영상 1 97546 125ec42a... unknown 240 Horo Gun Toireamaid Hùgan Fhathast Air 174106 c8bbe048... FALSE 2 266317 2e7119b5... Capella Istropolitana 189 Concerto Grosso in D minor, op. 2 no. 3: II. Adagio 134000 af0f294d... FALSE 3 628060 34cd3689... Conspirare 5196 Liturgy, op. 42: 9. Praise the Lord from the Heavens 126933 8bab920d... FALSE 4 423877 54401795... Boys Air Choir 1178 Nunc Dimittis 190000 111611eb... FALSE 5 394456 9914f9f9... L’Orchestre de la Suisse Romande 23036 Concert Waltz no. 2, op. 51 509960 b16742d1... FALSE
접근 방식 2: Cloud Dataflow를 사용한 BigQuery로의 ETL
이 가이드 섹션에서는 BigQuery UI가 아닌 Dataflow 파이프라인에서 샘플 프로그램을 사용해 데이터를 BigQuery로 로드합니다. 그런 다음 Beam 프로그래밍 모델을 사용해 데이터를 비정규화하고 정리하여 BigQuery로 로드합니다.
시작하기 전에 먼저 개념과 샘플 코드에 대해서 살펴보겠습니다.
개념 검토
이 가이드의 목표에서 보았듯이 데이터 용량이 작을 경우 BigQuery UI를 사용해 데이터를 빠르게 업로드할 수 있지만 Dataflow를 ETL에 사용하는 방법도 있습니다. 다음과 같은 목표로 대용량 조인, 즉 10TB가 넘는 데이터에서 500~5,000개의 열을 조인할 때는 BigQuery UI가 아닌 Dataflow를 BigQuery ETL에 사용할 수 있습니다.
- 데이터를 저장하여 이후 조인하지 않고 BigQuery에 로드하면서 정리하거나 변환합니다. 결과적으로 이러한 접근 방식은 데이터가 조인 및 변환 상태로만 BigQuery에 저장되기 때문에 저장용량 요건이 비교적 낮습니다.
- 커스텀 데이터 정리를 계획합니다(SQL만으로는 정리할 수 없음).
- 또한 로딩 과정에서 데이터를 로그, 원격 액세스 데이터 등 OLTP 외부 데이터와 결합합니다.
- 지속적 통합 또는 지속적 배포(CI/CD)를 사용해 데이터 로딩 로직에 대한 테스트 및 배포를 자동화합니다.
- 계속해서 ETL 프로세스를 단계적으로 반복하고, 수정하고, 개선합니다.
- 일회성 ETL이 아니라 점진적으로 데이터를 추가할 계획입니다.
다음은 샘플 프로그램에 의해 생성된 데이터 파이프라인 다이어그램입니다.

코드 예시에서 여러 단계의 파이프라인이 편의상 메서드로 그룹화되거나 래핑되며 설명이 포함된 이름이 지정되고 재사용됩니다. 다이어그램에서 재사용된 단계는 점선으로 표시됩니다.
파이프라인 코드 검토
이 코드는 다음 단계를 수행하는 파이프라인을 만듭니다.
조인할 때 포함시킬 테이블을 공개 Cloud Storage 버킷에서 문자열의
PCollection으로 각각 로드합니다. 각 요소는 테이블의 행에 대한 JSON 표현으로 구성됩니다.위의 JSON 문자열을 객체 표현인
MusicBrainzDataObject객체로 변환한 후 객체 표현을 기본 또는 외래 키 같은 열 값 중 하나를 기준으로 구성합니다.공통 아티스트를 기준으로 목록을 조인합니다.
artist_credit_name은 아티스트 크레딧을 음원과 연결하고 아티스트 외래 키를 포함합니다.artist_credit_name테이블은 키 값KV객체 목록으로 로드됩니다.K멤버는 아티스트입니다.MusicBrainzTransforms.innerJoin()메서드를 사용해 목록을 조인합니다.KV객체 컬렉션을 조인할 주요 멤버를 기준으로 그룹화합니다. 결과적으로 긴 키(artist.id열 값)가 포함된KV객체의PCollection과 그 결과인CoGbkResult(Combine Group by Key Result를 의미)가 생성됩니다.CoGbkResult객체는 첫 번째 및 두 번째PCollections에서 공통된 키 값을 가진 객체 목록의 튜플입니다. 이 튜플은group메서드에서CoGroupByKey작업을 실행하기 전에 각PCollection에 공식화된 튜플 태그를 사용하여 처리될 수 있습니다.객체의 각 일치 항목을 조인 결과를 나타내는
MusicBrainzDataObject객체에 병합합니다.컬렉션을
KV객체 목록으로 재구성하여 다음 조인을 시작합니다. 이때K값은 음원 테이블과 조인하는 데 사용되는artist_credit열입니다.그 결과를
artist_credit.id로 구성된 로드된 음원 컬렉션과 조인하여MusicBrainzDataObject객체의 최종 컬렉션을 가져옵니다.이렇게 얻은
MusicBrainzDataObjects객체를TableRows에 매핑합니다.매핑된
TableRows를 BigQuery에 작성합니다.
Beam 파이프라인 프로그래밍의 메커니즘에 대한 자세한 내용은 프로그래밍 모델에 대한 다음 주제를 참조하세요.
코드 실행 단계를 먼저 살펴본 후 파이프라인을 실행합니다.
Cloud Storage 버킷 만들기
파이프라인 코드 실행
Google Cloud Console에서 Cloud Shell을 엽니다.
프로젝트 및 파이프라인 스크립트에 대한 환경 변수 설정
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow export DATASET=musicbrainzPROJECT_ID를 Google Cloud 프로젝트의 프로젝트 ID로 바꿉니다.
gcloud가 이 가이드를 시작할 때 만들었거나 선택한 프로젝트를 사용하고 있는지 확인합니다.gcloud config set project $PROJECT_ID최소 권한의 보안 원칙에 따라 Dataflow 파이프라인의 서비스 계정을 만들고 필요한 권한만 부여합니다(
roles/dataflow.worker,roles/bigquery.jobUser,dataEditormusicbrainz데이터 세트에 대한 역할).gcloud iam service-accounts create musicbrainz-dataflow export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/dataflow.worker gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/bigquery.jobUser bq query --use_legacy_sql=false \ "GRANT \`roles/bigquery.dataEditor\` ON SCHEMA musicbrainz TO 'serviceAccount:${SERVICE_ACCOUNT}'"Dataflow 파이프라인에서 임시 파일에 사용할 버킷을 만들고
musicbrainz-dataflow서비스 계정에Owner권한을 부여합니다.export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} gsutil mb -l us ${DATAFLOW_TEMP_BUCKET} gsutil acl ch -u ${SERVICE_ACCOUNT}:O ${DATAFLOW_TEMP_BUCKET}Dataflow 코드가 포함된 저장소를 클론합니다.
git clone https://github.com/GoogleCloudPlatform/bigquery-etl-dataflow-sample.git디렉터리를 샘플로 변경합니다.
cd bigquery-etl-dataflow-sampleDataflow 작업을 컴파일하고 실행합니다.
./run.sh simple작업을 실행하는 데 약 10분이 소요됩니다.
파이프라인 진행 상황을 보려면 Google Cloud 콘솔에서 Dataflow 페이지로 이동합니다.
작업 상태가 상태 열에 표시됩니다. 성공 상태는 작업이 완료된 것을 의미합니다.
(선택사항) 각 단계에 대한 작업 그래프와 세부정보를 보려면 작업 이름(예:
etl-into-bigquery-bqetlsimple)을 클릭합니다.작업이 완료되면 BigQuery 페이지로 이동합니다.
새로운 테이블에 대해 쿼리를 실행하려면 쿼리 편집기 창에서 다음과 같이 입력합니다.
SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;결과 창에는 다음과 비슷한 결과가 표시됩니다.
Row artist_name artist_gender artist_area recording_name recording_length 1 mirin 2 107 Sylphia 264000 2 mirin 2 107 Dependence 208000 3 Gaudiburschen 1 81 Die Hände zum Himmel 210000 4 Sa4 1 331 Ein Tag aus meiner Sicht 221000 5 Dpat 1 7326 Cutthroat 249000 6 Dpat 1 7326 Deloused 178000 결과가 정렬되지 않으므로 실제 출력은 다를 수 있습니다.
데이터 정리
다음 단계에서는 Dataflow 파이프라인을 약간 변경하여 다음 다이어그램과 같이 참고 테이블을 로드하고 부차 입력으로 처리할 수 있습니다.

그런 다음 BigQuery 테이블에 대해 쿼리할 경우 MusicBrainz 데이터베이스의 area 테이블에서 영역 숫자 ID를 직접 조회하지 않으면 아티스트가 어디에서 시작되었는지 판단하기 어렵습니다. 이렇게 하면 쿼리 결과 분석이 모호해집니다.
이와 마찬가지로 아티스트 성별은 ID로 표시되지만 전체 MusicBrainz 성별 테이블은 행 세 개로만 구성됩니다. 이러한 문제를 해결할 목적으로 Dataflow 파이프라인에 MusicBrainz area 및 gender 테이블을 사용해 ID를 해당 라벨에 매핑하는 단계를 추가할 수 있습니다.
artist_area 테이블과 artist_gender 테이블에는 아티스트 또는 음원 데이터 테이블보다 훨씬 적은 수의 행이 포함되어 있습니다. 아티스트 또는 음원 테이블의 요소 수는 지리적 영역 또는 성별 수에 따라 각각 제약을 받습니다.
따라서 조회 단계에서는 부차 입력이라고 하는 Dataflow 기능이 사용됩니다.
부차 입력은 Musicbrainz 데이터 세트가 포함된 공개 Cloud Storage 버킷의 줄로 구분된 JSON 파일 테이블 내보내기로 로드되며 테이블 데이터를 단일 단계로 비정규화하는 데 사용됩니다.
부차 입력을 파이프라인에 추가하는 코드 검토
파이프라인을 실행하기 전에 먼저 코드를 살펴보며 새로운 단계에 대한 이해의 폭을 넓혀보겠습니다.
이 코드에서는 부차 입력을 사용한 데이터 정리를 보여줍니다. MusicBrainzTransforms 클래스는 부차 입력을 사용하여 외래 키 값을 라벨에 매핑할 수 있는 편리한 추가 기능을 제공합니다. MusicBrainzTransforms 라이브러리는 내부 조회 클래스를 만드는 메서드를 제공합니다. 조회 클래스는 각 참고 테이블을 비롯해 라벨과 가변 길이 인수로 변경되는 필드에 대해서 설명합니다. keyKey는 조회할 키가 포함된 열의 이름이고 valueKey는 해당 라벨이 포함된 열의 이름입니다.
각 부차 입력은 단일 맵 객체로 로드되며 ID에 해당하는 라벨을 조회하는 데 사용됩니다.
먼저 참고 테이블용 JSON은 빈 네임스페이스가 있는 MusicBrainzDataObjects로 로드되고 Key 열 값에서 Value 열 값으로 매핑됩니다.
Map 객체는 각각 destinationKey, 즉 조회 값을 대체하는 키 값으로 Map에 입력됩니다.
그런 다음 아티스트 객체가 JSON에서 변환되는 과정에서 destinationKey 값(숫자로 시작하는 값)이 라벨로 바뀝니다.
artist_area 및 artist_gender 필드의 디코딩을 추가하려면 다음 단계를 완료하세요.
Cloud Shell에서 파이프라인 스크립트에 맞게 환경이 설정되어 있는지 확인합니다.
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_sideinputs export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comPROJECT_ID를 Google Cloud 프로젝트의 프로젝트 ID로 바꿉니다.
파이프라인을 실행하여 디코딩된 영역과 아티스트 성별로 테이블을 만듭니다.
./run.sh simple-with-lookups이전과 마찬가지로 파이프라인 진행 상황을 보려면 Dataflow 페이지로 이동합니다.
파이프라인이 완료되는 데 약 10분이 소요됩니다.
작업이 완료되면 BigQuery 페이지로 이동합니다.
artist_area및artist_gender가 똑같이 포함된 쿼리를 실행합니다.SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow_sideinputs WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;이제
artist_area및artist_gender가 디코딩되어 다음과 같이 출력됩니다.Row artist_name artist_gender artist_area recording_name recording_length 1 mirin Female Japan Sylphia 264000 2 mirin Female Japan Dependence 208000 3 Gaudiburschen Male Germany Die Hände zum Himmel 210000 4 Sa4 Male Hamburg Ein Tag aus meiner Sicht 221000 5 Dpat Male Houston Cutthroat 249000 6 Dpat Male Houston Deloused 178000 결과가 정렬되지 않으므로 실제 출력은 다를 수 있습니다.
BigQuery 스키마 최적화
본 가이드의 마지막 부분에서는 중첩 필드를 사용해 최적의 테이블 스키마를 생성하는 파이프라인을 실행합니다.
잠시 이번 최적화 버전의 테이블을 생성하는 데 사용되는 코드를 살펴보겠습니다.
다음 다이어그램은 아티스트 행을 중복으로 만들지 않고 각 아티스트 행 내에서 아티스트의 음원을 중첩하는 약간 다른 Dataflow 파이프라인을 나타낸 것입니다.

현재 데이터 표현은 매우 평이합니다. 즉, BigQuery 스키마의 모든 아티스트 메타데이터와 모든 음원 및 artist_credit_name 메타데이터가 포함된 크레딧 기록당 하나의 행이 포함됩니다. 이 평이한 표현에는 최소 두 가지 단점이 있습니다.
- 아티스트에 크레딧이 적용되는 모든 음원에 대한
artist메타데이터를 반복하므로 필요한 스토리지가 증가합니다. - JSON으로 데이터를 내보낼 때 중첩된 음원 데이터가 있는 아티스트가 아닌 데이터를 반복하는 배열을 내보냅니다. 이는 의도한 결과일 수도 있습니다.
행당 음원 하나를 저장하는 대신 Dataflow 파이프라인을 변경하여 음원을 각 아티스트 레코드 내에서 반복 필드로 저장할 수 있습니다. 이렇게 하면 성능 저하가 없고 추가 스토리지를 사용하지 않아도 됩니다.
artist_credit_name.artist로 음원과 아티스트 정보를 조인하는 대신 이 대체 파이프라인은 아티스트 객체 내에 음원 중첩 목록을 만듭니다.
BigQuery API의 경우 일괄 삽입 시 100MB의 최대 행 크기 한도(스트리밍 삽입의 경우 10MB)가 있으므로 코드는 이 한도에 도달하지 않도록 지정된 레코드의 중첩된 음원 수를 1000개 요소로 제한합니다. 특정 아티스트에 1,000개가 넘는 음원이 있으면 코드는 artist 메타데이터를 포함하여 행을 복제하고 계속해서 중복 행에 음원 데이터를 중첩합니다.
다음 다이어그램은 파이프라인의 소스, 변환, 싱크를 나타낸 것입니다.
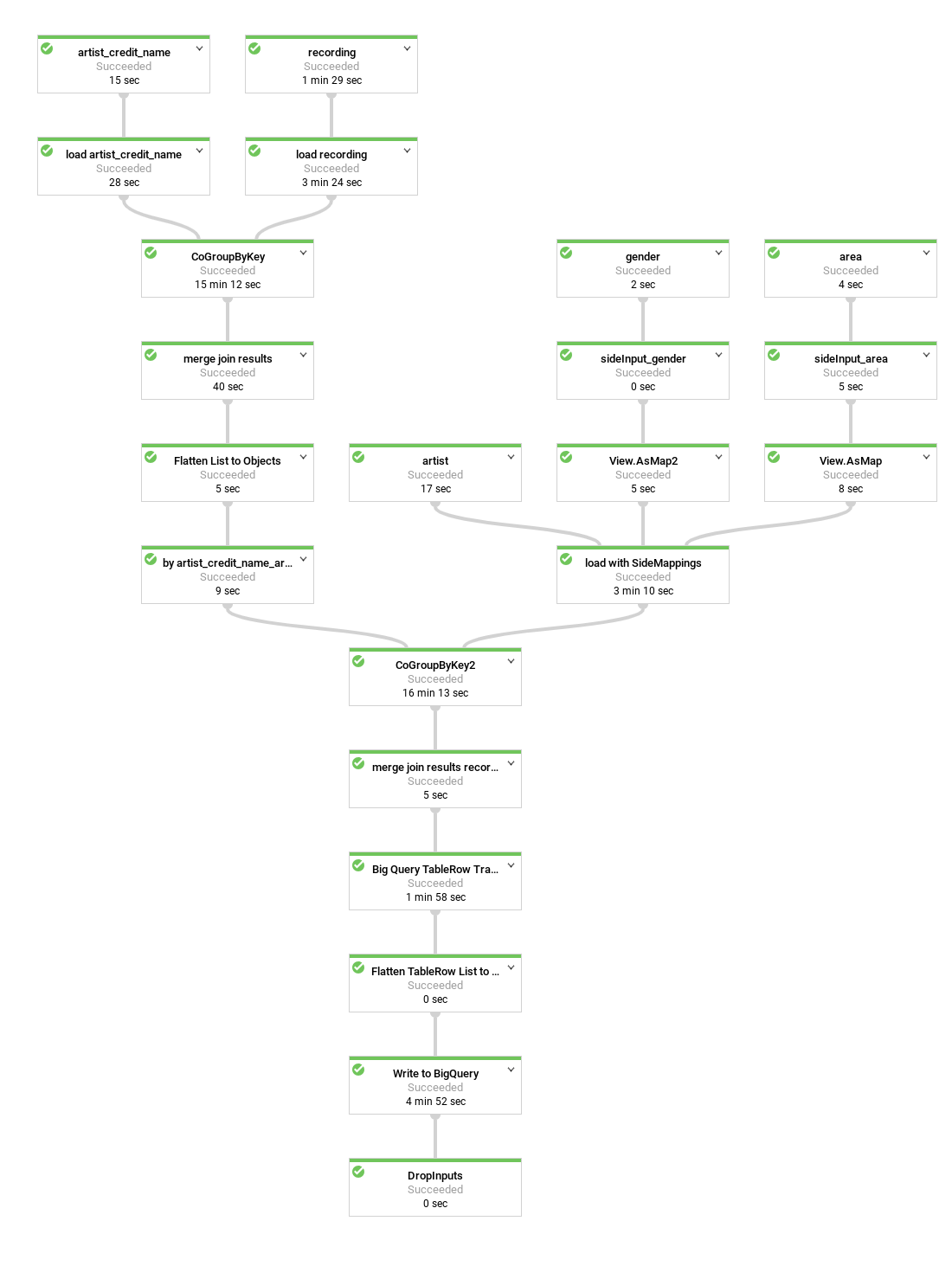
대부분의 경우 단계 이름은 apply 메서드 호출 과정에서 코드로 제공됩니다.
이렇게 최적화된 파이프라인을 만들려면 다음 단계를 완료하세요.
Cloud Shell에서 파이프라인 스크립트에 맞게 환경이 설정되어 있는지 확인합니다.
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_nested export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com파이프라인을 실행하여 아티스트 행에 음원 행을 중첩시킵니다.
./run.sh nested이전과 마찬가지로 파이프라인 진행 상황을 보려면 Dataflow 페이지로 이동합니다.
파이프라인이 완료되는 데 약 10분이 소요됩니다.
작업이 완료되면 BigQuery 페이지로 이동합니다.
BigQuery의 중첩 테이블에서 필드를 쿼리합니다.
SELECT artist_name, artist_gender, artist_area, artist_recordings FROM musicbrainz.recordings_by_artists_dataflow_nested WHERE artist_area IS NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;출력에서
artist_recordings는 확장 가능한 중첩 행으로 표시됩니다.Row artist_name artist_gender artist_area artist_recordings 1 mirin Female Japan (5 rows) 3 Gaudiburschen Male Germany (1 row) 4 Sa4 Male Hamburg (10 rows) 6 Dpat Male Houston (9 rows) 결과가 정렬되지 않으므로 실제 출력은 다를 수 있습니다.
STRUCT에서 값을 추출하는 쿼리를 실행한 후 추출된 값을 사용해 결과를 필터링합니다. 예를 들어 'Justin'이라는 단어가 포함된 음원이 있는 아티스트는 다음과 같습니다.SELECT artist_name, artist_gender, artist_area, ARRAY(SELECT artist_credit_name_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS artist_credit_name_name, ARRAY(SELECT recording_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS recording_name FROM musicbrainz.recordings_by_artists_dataflow_nested, UNNEST(recordings_by_artists_dataflow_nested.artist_recordings) AS artist_recordings_struct WHERE artist_recordings_struct.recording_name LIKE "%Justin%" LIMIT 1000;출력에서
artist_credit_name_name및recording_name는 확장 가능한 중첩 행으로 표시됩니다. 예를 들면 다음과 같습니다.Row artist_name artist_gender artist_area artist_credit_name_name recording_name 1 Damonkenutz null null (1 row) 1 Yellowpants (Justin Martin remix) 3 Fabian Male Germany (10+ rows) 1 Heatwave . 2 Starlight Love . 3 Dreams To Wishes . 4 Last Flight (Justin Faust remix) . ... 4 Digital Punk Boys null null (6 rows) 1 Come True . 2 We Are... (Punkgirlz remix by Justin Famous) . 3 Chaos (short cut) . ... 결과가 정렬되지 않으므로 실제 출력은 다를 수 있습니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
개별 리소스 삭제
전체 프로젝트를 삭제하는 대신 개별 리소스를 삭제하려면 다음 단계를 따르세요.
Cloud Storage 버킷 삭제
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
- 삭제할 버킷의 체크박스를 클릭합니다.
- 버킷을 삭제하려면 삭제를 클릭한 후 안내를 따르세요.
BigQuery 데이터 세트 삭제
BigQuery 웹 UI를 엽니다.
가이드에서 만든 BigQuery 데이터 세트를 선택합니다.
삭제 delete를 클릭합니다.
다음 단계
- BigQuery에서 쿼리를 작성하는 법을 자세히 알아보세요. 데이터 쿼리에서는 동기 및 비동기 쿼리를 실행하거나, 사용자 정의 함수(UDF)를 만드는 방법 등에 대해서 설명합니다.
- BigQuery 구문을 살펴보세요. BigQuery의 SQL 유사 구문은 쿼리 참조(이전 SQL)에 설명되어 있습니다.
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기