En este instructivo, se muestra cómo usar Dataflow para extraer, transformar y cargar (ETL) datos de una base de datos relacional de procesamiento de transacciones en línea (OLTP) en BigQuery para su análisis.
El instructivo está dirigido a administradores de bases de datos, profesionales de operaciones y arquitectos de la nube interesados en aprovechar las capacidades de consulta analítica de BigQuery y las capacidades de procesamiento por lotes de Dataflow.
Las bases de datos OLTP suelen ser bases de datos relacionales que almacenan información y procesan transacciones para sitios de comercio electrónico, aplicaciones de software como servicio (SaaS) o juegos. Por lo general, las bases de datos OLTP están optimizadas para transacciones, que requieren las propiedades ACID (atomicidad, coherencia, aislamiento y durabilidad), y suelen tener esquemas altamente normalizados. En contraposición, los almacenes de datos tienden a estar optimizados para la recuperación y el análisis de datos, en lugar de las transacciones, y normalmente tienen esquemas desnormalizados. Por lo general, el hecho de desnormalizar los datos de una base de datos OLTP hace que esta sea más útil para el análisis en BigQuery.
Objetivos
En el instructivo, se muestran dos enfoques para realizar el procedimiento de ETL de los datos de RDBMS normalizados a fin de obtener datos de BigQuery desnormalizados:
- Usar BigQuery para cargar y transformar los datos: Usa este enfoque a fin de realizar una carga única de una pequeña cantidad de datos en BigQuery para su análisis. También puedes usar este enfoque para el prototipado de tu conjunto de datos antes de la automatización de conjuntos de datos más grandes o múltiples.
- Usar Dataflow para cargar, transformar y limpiar los datos: Usa este enfoque para cargar una cantidad mayor de datos, cargar datos desde varias fuentes o cargarlos de forma progresiva o automática.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Cuando finalices las tareas que se describen en este documento, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Antes de comenzar
Compute Engine y Dataflow- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de .
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de .
Usa el conjunto de datos de MusicBrainz
Este instructivo se basa en instantáneas JSON de tablas de la base de datos de MusicBrainz, que se creó en PostgreSQL y contiene información sobre toda la música de MusicBrainz. El esquema de MusicBrainz incluye, entre otros, los siguientes elementos:
- Artistas
- Lanzamiento de grupos
- Lanzamientos
- Grabaciones
- Trabajos
- Sellos discográficos
- Muchas relaciones entre estas entidades
El esquema de MusicBrainz incluye tres tablas relevantes: artist, recording y artist_credit_name. Un artist_credit representa el crédito otorgado al artista por una grabación, y las filas artist_credit_name vinculan la grabación con su artista correspondiente mediante el valor artist_credit.
En este instructivo, se proporcionan las tablas de PostgreSQL ya extraídas en formato JSON delimitado por saltos de línea y almacenadas en un bucket público de Cloud Storage: gs://solutions-public-assets/bqetl.
Si deseas realizar este paso por tu cuenta, debes tener una base de datos de PostgreSQL que contenga el conjunto de datos de MusicBrainz y usar los siguientes comandos para exportar cada una de las tablas:
host=POSTGRES_HOST
user=POSTGRES_USER
database=POSTGRES_DATABASE
for table in artist recording artist_credit_name
do
pg_cmd="\\copy (select row_to_json(r) from (select * from ${table}) r ) to exported_${table}.json"
psql -w -h ${host} -U ${user} -d ${db} -c $pg_cmd
# clean up extra '\' characters
sed -i -e 's/\\\\/\\/g' exported_${table}.json
done
Enfoque 1: ETL con BigQuery
Usa este enfoque a fin de realizar una carga única de una pequeña cantidad de datos en BigQuery para su análisis. También puedes usar este enfoque para el prototipado de tu conjunto de datos antes de la automatización de conjuntos de datos más grandes o múltiples.
Cree un conjunto de datos de BigQuery
Para crear un conjunto de datos de BigQuery, carga las tablas de MusicBrainz a BigQuery de forma individual. Luego, une las tablas que cargaste para que cada fila contenga la vinculación de datos que desees. Almacena los resultados de la unión en una tabla de BigQuery nueva. A continuación, puedes borrar las tablas originales que cargaste.
En la consola de Google Cloud, abre BigQuery.
En el panel Explorador, haz clic en el menú more_vert junto al nombre de tu proyecto y, luego, haz clic en Crear conjunto de datos.
En el cuadro de diálogo Crear conjunto de datos, sigue estos pasos:
- En el campo ID de conjunto de datos, ingresa
musicbrainz. - Establece la Ubicación de datos en us.
- Haz clic en Crear conjunto de datos.
- En el campo ID de conjunto de datos, ingresa
Importa tablas de MusicBrainz
En cada tabla de MusicBrainz, sigue estos pasos para agregar una tabla al conjunto de datos que creaste:
- En el panel Explorador de BigQuery de la consola de Google Cloud, expande la fila con el nombre de tu proyecto para mostrar el conjunto de datos
musicbrainzrecién creado. - Haz clic en el menú more_vert junto al conjunto de datos
musicbrainzy, luego, en Crear tabla. En el cuadro de diálogo Crear tabla, sigue estos pasos:
- En la lista desplegable Crear tabla desde, selecciona Google Cloud Storage.
En el campo Selecciona un archivo del bucket de GCS, ingresa la ruta de acceso al archivo de datos:
solutions-public-assets/bqetl/artist.jsonEn Formato de archivo, selecciona JSONL (JSON delimitado por saltos de línea).
Asegúrate de que Proyecto contenga el nombre del proyecto.
Asegúrate de que el Conjunto de datos sea
musicbrainz.En Tabla, ingresa el nombre de la tabla,
artist.Para el Table type (Tipo de tabla), deja seleccionada Native table (Tabla nativa).
Debajo de la sección Schema (Esquema), haz clic para activar Edit as Text (Editar como texto).
Descarga el archivo de esquema
artisty ábrelo en un editor de texto o un visualizador.Reemplaza el contenido de la sección Schema (Esquema) por el contenido del archivo de esquema que descargaste.
Haz clic en Crear tabla.
Espera unos momentos a que finalice el trabajo de carga.
Cuando termine la carga, la tabla nueva aparece en el conjunto de datos.
Repite los pasos 1 a 5 para crear la tabla
artist_credit_namecon los siguientes cambios:Usa la siguiente ruta para el archivo de datos de origen:
solutions-public-assets/bqetl/artist_credit_name.jsonUsa
artist_credit_namecomo el nombre de la Tabla.Descarga el archivo de esquema
artist_credit_namey usa el contenido del esquema.
Repite los pasos del 1 al 5 para crear la tabla
recordingcon los siguientes cambios:Usa la siguiente ruta para el archivo de datos de origen:
solutions-public-assets/bqetl/recording.jsonUsa
recordingcomo el nombre de la Tabla.Descarga el archivo del esquema
recordingy usa el contenido del esquema.
Desnormaliza los datos manualmente
A fin de desnormalizar los datos, únelos a una tabla nueva de BigQuery que tenga una fila por cada grabación del artista, junto con los metadatos seleccionados que desees conservar para el análisis.
- Si el editor de consultas de BigQuery no está abierto en la consola de Google Cloud, haz clic en add_box Redactar consulta nueva.
Copia la siguiente consulta y pégala en el Editor de consultas:
SELECT artist.id, artist.gid AS artist_gid, artist.name AS artist_name, artist.area, recording.name AS recording_name, recording.length, recording.gid AS recording_gid, recording.video FROM `musicbrainz.artist` AS artist INNER JOIN `musicbrainz.artist_credit_name` AS artist_credit_name ON artist.id = artist_credit_name.artist INNER JOIN `musicbrainz.recording` AS recording ON artist_credit_name.artist_credit = recording.artist_creditHaz clic en la lista desplegable settings Más y, luego, selecciona Configuración de consulta.
En el cuadro de diálogo Configuración de consulta, completa los siguientes pasos:
- Seleccione Establecer una tabla de destino para los resultados de la consulta (Set a destination table for query results).
- En Conjunto de datos, ingresa
musicbrainzy selecciona el conjunto de datos en tu proyecto. - En ID de tabla, ingresa
recordings_by_artists_manual. - En Destination table write preference (Preferencia de escritura para la tabla de destino), haz clic en Overwrite table (Reemplazar tabla).
- Selecciona la casilla de verificación Permitir resultados grandes (sin límite de tamaño) (Allow Large Results [no size limit]).
- Haz clic en Guardar.
Haz clic en play_circle_filled Ejecutar.
Cuando se completa la consulta, los datos del resultado se organizan en canciones por cada artista de la tabla de BigQuery recién creada y una muestra de los resultados que se muestran en el panel Resultados de la consulta, por ejemplo:
Fila id artist_gid artist_name area recording_name length recording_gid video 1 97546 125ec42a... unknown 240 Horo Gun Toireamaid Hùgan Fhathast Air 174106 c8bbe048... FALSE 2 266317 2e7119b5... Capella Istropolitana 189 Concerto Grosso in D minor, op. 2 no. 3: II. Adagio 134000 af0f294d... FALSE 3 628060 34cd3689... Conspirare 5196 Liturgy, op. 42: 9. Praise the Lord from the Heavens 126933 8bab920d... FALSE 4 423877 54401795... Boys Air Choir 1178 Nunc Dimittis 190000 111611eb... FALSE 5 394456 9914f9f9... L’Orchestre de la Suisse Romande 23036 Concert Waltz no. 2, op. 51 509960 b16742d1... FALSE
Enfoque 2: ETL en BigQuery con Dataflow
En esta sección del instructivo, en lugar de usar la IU de BigQuery, usa un programa de muestra para cargar datos en BigQuery mediante una canalización de Dataflow. Luego, usa el modelo de programación de Beam para desnormalizar y limpiar los datos que se van a cargar en BigQuery.
Antes de comenzar, repasemos algunos conceptos y examinemos el código de muestra.
Revisa los conceptos
Aunque los datos son pequeños y se pueden subir con rapidez mediante la IU de BigQuery, a los fines de este instructivo, también puedes usar Dataflow para ETL. Usa Dataflow para ETL en BigQuery en lugar de la IU de BigQuery cuando realices uniones masivas, es decir, entre 500 y 5,000 columnas de más de 10 TB de datos, con los siguientes objetivos:
- Deseas limpiar o transformar tus datos mientras estos se cargan en BigQuery, en lugar de almacenarlos y unirlos después. Debido a esto, este enfoque también tiene menores requisitos de almacenamiento, ya que los datos solo se almacenan en BigQuery en su estado unido y transformado.
- Planeas realizar una limpieza personalizada de los datos (que no puede lograrse simplemente con SQL).
- Planeas combinar los datos con otros ajenos al OLTP (como registros o datos a los que se accede de forma remota) durante el proceso de carga.
- Planeas automatizar la prueba y la implementación de la lógica de carga de datos mediante la integración o implementación continuas (IC/IC).
- Tienes previsto que el proceso de ETL se itere, aumente y mejore gradualmente con el tiempo.
- Planeas agregar los datos de forma incremental, en lugar de realizar un ETL único.
Este es un diagrama de la canalización de datos que crea el programa de muestra:

En el código de ejemplo, muchos de los pasos de canalización están agrupados o unidos en métodos útiles, reciben nombres descriptivos y se reutilizan. En el diagrama, los pasos que se reutilizan se indican con bordes discontinuos.
Revisa el código de canalización
El código crea una canalización que realiza los siguientes pasos:
Carga cada tabla que desees que forme parte de la unión del bucket público de Cloud Storage en una
PCollectionde strings. Cada elemento comprende la representación JSON de una fila de la tabla.Convierte esas strings JSON en representaciones de objetos, objetos
MusicBrainzDataObject; luego, organiza las representaciones de los objetos por uno de los valores de la columna, como una clave primaria o externa.Une la lista según un artista en común. El
artist_credit_namevincula el crédito de un artista con su grabación y también incluye la clave externa del artista. La tablaartist_credit_namese carga como una lista de objetos de clave-valorKV. El miembroKes el artista.Une la lista mediante el método
MusicBrainzTransforms.innerJoin().- Agrupa las colecciones de objetos
KVpor el miembro clave que deseas usar para la unión. Esto da como resultado unaPCollectionde objetosKVcon una clave larga (el valor de la columnaartist.id) y elCoGbkResultresultante (que significa “grupo de combinación por resultado clave”). El objetoCoGbkResultes una tupla de listas de objetos con la clave-valor en común de la primera y la segundaPCollections. Esta tupla es accesible mediante el uso de la etiqueta de tuplas formulada para cadaPCollectionantes de ejecutar la operaciónCoGroupByKeyen el métodogroup. Fusiona cada combinación de objetos para formar un objeto
MusicBrainzDataObjectque representa un resultado de unión.Reorganiza la colección en una lista de objetos
KVpara comenzar la siguiente unión. Esta vez, el valorKes la columnaartist_credit, que se usa para unirse con la tabla de grabación.Obtiene la colección final resultante de objetos
MusicBrainzDataObjectmediante la unión ese resultado con la colección cargada de grabaciones organizadas porartist_credit.id.Asigna los objetos
MusicBrainzDataObjectsresultantes enTableRows.Escribe el
TableRowsresultante en BigQuery.
- Agrupa las colecciones de objetos
Para obtener más información sobre el funcionamiento de la programación de canalizaciones de Beam, consulta los siguientes temas sobre el modelo de programación:
PCollection- Cómo cargar datos de archivos de texto (incluido Cloud Storage)
- Transformaciones como
ParDoy MapElements` - Unión y
GroupByKey - BigQuery I/O
Después de revisar los pasos que realiza el código, puedes ejecutar la canalización.
Cree un bucket de Cloud Storage
Ejecuta el código de canalización
En la consola de Google Cloud, abre Cloud Shell.
Configura las variables de entorno de tu proyecto y secuencia de comandos de canalización
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow export DATASET=musicbrainzReemplaza PROJECT_ID con el ID de tu proyecto de Google Cloud.
Asegúrate de que
gclouduse el proyecto que creaste o seleccionaste al comienzo del instructivo:gcloud config set project $PROJECT_IDDe acuerdo con el principio de seguridad privilegio mínimo, crea una cuenta de servicio para la canalización de Dataflow y otórgale solo los privilegios necesarios: los roles
roles/dataflow.worker,roles/bigquery.jobUserydataEditoren el conjunto de datosmusicbrainz:gcloud iam service-accounts create musicbrainz-dataflow export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/dataflow.worker gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/bigquery.jobUser bq query --use_legacy_sql=false \ "GRANT \`roles/bigquery.dataEditor\` ON SCHEMA musicbrainz TO 'serviceAccount:${SERVICE_ACCOUNT}'"Crea un bucket para que la canalización de Dataflow lo use en archivos temporales y otórgale privilegios de
Ownera la cuenta de serviciomusicbrainz-dataflow:export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} gsutil mb -l us ${DATAFLOW_TEMP_BUCKET} gsutil acl ch -u ${SERVICE_ACCOUNT}:O ${DATAFLOW_TEMP_BUCKET}Clona el repositorio que contiene el código de Dataflow:
git clone https://github.com/GoogleCloudPlatform/bigquery-etl-dataflow-sample.gitCambia el directorio a la muestra:
cd bigquery-etl-dataflow-sampleCompila y ejecuta el trabajo de Dataflow:
./run.sh simpleEl trabajo toma unos 10 minutos en ejecutarse.
Para ver el progreso de la canalización, ve a la página de Dataflow en la consola de Google Cloud.
El estado de los trabajos se muestra en la columna de estado. Si el estado es Correcto, significa que el trabajo se completó.
Para ver el gráfico del trabajo y los detalles de los pasos, haz clic en el nombre del trabajo, por ejemplo,
etl-into-bigquery-bqetlsimple(opcional).Cuando se complete el trabajo, ve a la página BigQuery.
Para ejecutar una consulta en la tabla nueva, ingresa lo siguiente en el Query Editor (Editor de consultas):
SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;En el panel de resultados, se mostrará un conjunto de resultados similares a los siguientes:
Fila artist_name artist_gender artist_area recording_name recording_length 1 mirin 2 107 Sylphia 264000 2 mirin 2 107 Dependence 208000 3 Gaudiburschen 1 81 Die Hände zum Himmel 210000 4 Sa4 1 331 Ein Tag aus meiner Sicht 221000 5 Dpat 1 7326 Cutthroat 249000 6 Dpat 1 7326 Deloused 178000 El resultado real puede diferir, ya que los resultados no están ordenados.
Limpia los datos
A continuación, realiza un pequeño cambio en la canalización de Dataflow para poder cargar tablas de consulta y procesarlas como entradas complementarias, como se muestra en el siguiente diagrama.

Cuando consultas la tabla de BigQuery resultante, es difícil
suponer desde dónde se origina el artista sin buscar de forma manual el ID numérico de área
de la tabla area en la base de datos de MusicBrainz. Por lo tanto, analizar los resultados de una consulta resulta menos sencillo de lo que podría ser.
De forma similar, los géneros de los artistas se muestran como ID, pero toda la tabla de géneros de MusicBrainz consiste de solo tres filas. Para solucionar este problema, puedes agregar un paso en la canalización de Dataflow a fin de usar las tablas area y gender de MusicBrainz para asignar los ID a las etiquetas correspondientes.
Las tablas artist_area y artist_gender contienen una cantidad de filas significativamente menor que la tabla de datos de grabación o de los artistas. La cantidad de elementos en las tablas posteriores está limitada por la cantidad de áreas geográficas o géneros, respectivamente.
Como resultado, el paso de búsqueda usa la función de Dataflow llamada entrada complementaria.
Las entradas complementarias se cargan como exportaciones de tablas en formato JSON delimitado por saltos de línea en el bucket público de Cloud Storage que contiene el conjunto de datos de musicbrainz, y se usan para desnormalizar los datos de la tabla en un solo paso.
Revisa el código que agrega las entradas complementarias a la canalización
Antes de ejecutar la canalización, revisa el código para comprender mejor los pasos nuevos.
En este código, se muestra la limpieza de datos con entradas complementarias. La clase MusicBrainzTransforms proporciona ventajas adicionales para usar entradas complementarias a fin de asignar clave-valor externa a la etiqueta. La biblioteca MusicBrainzTransforms proporciona un método que crea una clase de búsqueda interna. La clase de búsqueda describe cada tabla de consulta y los campos que se reemplazan por etiquetas y argumentos de longitud variable. keyKey es el nombre de la columna que contiene la clave para la búsqueda y valueKey es el nombre de la columna que contiene la etiqueta correspondiente.
Cada entrada complementaria se carga como un objeto de asignación único, que se usa con el objetivo de buscar la etiqueta que corresponde para un ID.
Primero, el archivo JSON para la tabla de consulta se carga al principio en MusicBrainzDataObjects con un espacio de nombres vacío y se convierte en una asignación del valor de la columna Key al valor de la columna Value.
El valor de destinationKey de los objetos Map coloca un Map en cada uno. Este valor es la clave que se debe reemplazar por los valores buscados.
Luego, mientras se transforman los objetos de artista desde el archivo JSON, el valor de destinationKey (que comienza como un número) se reemplaza por la etiqueta correspondiente.
Para agregar la decodificación de los campos artist_area y artist_gender, completa los siguientes pasos:
En Cloud Shell, asegúrate de que el entorno esté configurado para la secuencia de comandos de la canalización:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_sideinputs export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comReemplaza PROJECT_ID con el ID de tu proyecto de Google Cloud.
Ejecuta la canalización para crear la tabla con el área decodificada y el género del artista:
./run.sh simple-with-lookupsAl igual que antes, para ver el progreso de la canalización, ve a la página Dataflow.
La canalización tardará unos 10 minutos en completarse.
Cuando se complete el trabajo, ve a la página BigQuery.
Realiza la misma consulta que incluye
artist_areayartist_gender:SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow_sideinputs WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;En el resultado,
artist_areayartist_genderahora están decodificados:Fila artist_name artist_gender artist_area recording_name recording_length 1 mirin Female Japan Sylphia 264000 2 mirin Female Japan Dependence 208000 3 Gaudiburschen Male Germany Die Hände zum Himmel 210000 4 Sa4 Male Hamburg Ein Tag aus meiner Sicht 221000 5 Dpat Male Houston Cutthroat 249000 6 Dpat Male Houston Deloused 178000 El resultado real puede variar, ya que los resultados no están ordenados.
Optimiza el esquema de BigQuery
En la parte final de este instructivo, ejecutas una canalización que genera un esquema de tabla óptimo con campos anidados.
Tómate unos minutos para revisar el código con el que se genera esta versión optimizada de la tabla.
En el siguiente diagrama, se muestra una canalización de Dataflow un poco diferente que anida las grabaciones del artista dentro de cada fila de artistas, en lugar de crear filas de artistas duplicadas.

La representación actual de los datos es bastante plana. Es decir, tiene una fila por cada grabación acreditada con todos los metadatos del artista del esquema de BigQuery y todos los metadatos de la grabación y artist_credit_name. Esta representación plana tiene al menos dos desventajas:
- Repite los metadatos de
artistpor cada grabación que se le acredita a un artista, por lo que se requiere más almacenamiento. - Cuando exportas los datos en formato JSON, se exporta un arreglo que repite esos datos, en lugar de un artista con los datos de las grabaciones anidados, que posiblemente es lo que deseas.
Una alternativa que no tiene ninguna desventaja en términos de rendimiento y, además, te permite ahorrar almacenamiento es que, en lugar de almacenar una grabación por fila, almacenes las grabaciones como un campo repetido dentro del registro de cada artista. Para ello, debes hacer algunas modificaciones en la canalización de Dataflow.
En lugar de unir las grabaciones con la información del artista mediante artist_credit_name.artist, esta canalización alternativa crea una lista de grabaciones anidada dentro de un objeto de artista.
La API de BigQuery tiene un límite máximo de tamaño de fila de 100 MB cuando realiza inserciones masivas (10 MB para inserciones de transmisión), por lo que el código limita la cantidad de grabaciones anidadas para un registro determinado a 1,000 elementos para garantizar que no se alcance este límite. Si un artista determinado tiene más de 1,000 grabaciones, el código duplica la fila, junto con los metadatos de artist y continúa anidando los datos de las grabaciones en la fila duplicada.
El diagrama muestra las fuentes, las transformaciones y los receptores de la canalización.
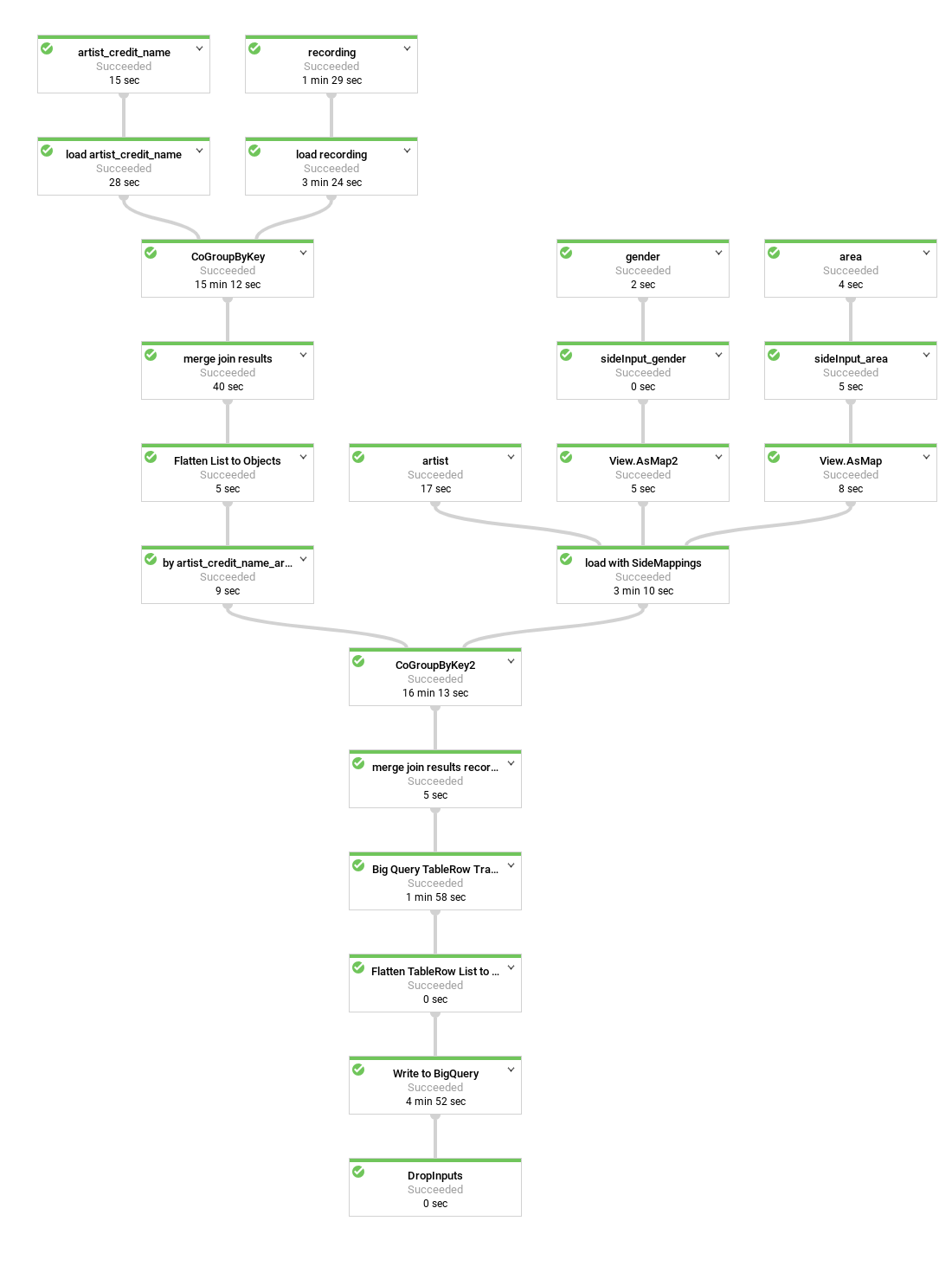
En la mayoría de los casos, los nombres de los pasos se proporcionan en el código como parte de la llamada al método apply.
Para crear esta canalización optimizada, sigue estos pasos:
En Cloud Shell, asegúrate de que el entorno esté configurado para la secuencia de comandos de la canalización:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_nested export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comEjecuta la canalización para anidar las filas de grabaciones en las filas del artista:
./run.sh nestedAl igual que antes, para ver el progreso de la canalización, ve a la página Dataflow.
La canalización tardará unos 10 minutos en completarse.
Cuando se complete el trabajo, ve a la página BigQuery.
Consulta campos de la tabla anidada en BigQuery:
SELECT artist_name, artist_gender, artist_area, artist_recordings FROM musicbrainz.recordings_by_artists_dataflow_nested WHERE artist_area IS NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;En el resultado, el
artist_recordingsse muestra como filas anidadas que se pueden expandir:Fila artist_name artist_gender artist_area artist_recordings 1 mirin Female Japan (5 rows) 3 Gaudiburschen Male Germany (1 row) 4 Sa4 Male Hamburg (10 rows) 6 Dpat Male Houston (9 rows) El resultado real puede diferir, ya que los resultados no están ordenados.
Ejecuta una consulta a fin de extraer valores de
STRUCTy úsalos para filtrar los resultados, por ejemplo, los artistas que tengan grabaciones que contengan la palabra “Justin”:SELECT artist_name, artist_gender, artist_area, ARRAY(SELECT artist_credit_name_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS artist_credit_name_name, ARRAY(SELECT recording_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS recording_name FROM musicbrainz.recordings_by_artists_dataflow_nested, UNNEST(recordings_by_artists_dataflow_nested.artist_recordings) AS artist_recordings_struct WHERE artist_recordings_struct.recording_name LIKE "%Justin%" LIMIT 1000;En el resultado,
artist_credit_name_nameyrecording_namese muestran como filas anidadas que se pueden expandir, por ejemplo:Fila artist_name artist_gender artist_area artist_credit_name_name recording_name 1 Damonkenutz null null (1 row) 1 Yellowpants (Justin Martin remix) 3 Fabian Male Germany (10+ rows) 1 Heatwave . 2 Starlight Love . 3 Dreams To Wishes . 4 Last Flight (Justin Faust remix) . ... 4 Digital Punk Boys null null (6 rows) 1 Come True . 2 We Are... (Punkgirlz remix by Justin Famous) . 3 Chaos (short cut) . ... El resultado real puede diferir, ya que los resultados no están ordenados.
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Borra recursos individuales
Sigue estos pasos para borrar recursos individuales en lugar de borrar todo el proyecto.
Borra el bucket de Cloud Storage
- En la consola de Google Cloud, ve a la página Buckets de Cloud Storage.
- Haz clic en la casilla de verificación del bucket que deseas borrar.
- Para borrar el bucket, haz clic en Borrar y sigue las instrucciones.
Borra los conjuntos de datos de BigQuery
Abre la IU web de BigQuery.
Selecciona los conjuntos de datos de BigQuery que creaste durante el instructivo.
Haz clic en Borrardelete.
¿Qué sigue?
- Obtén más información sobre cómo escribir consultas para BigQuery. En Cómo consultar datos, se explica cómo ejecutar consultas síncronas y asíncronas, crear funciones definidas por el usuario (UDF) y más.
- Explora la sintaxis de BigQuery. BigQuery usa una sintaxis similar a SQL que se describe en la Referencia de consulta (SQL heredado).
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.