この記事は、Google Cloud の障害復旧(DR)について説明するシリーズの 3 番目のパートです。このパートでは、データのバックアップと復元のシナリオについて説明します。
シリーズは次のパートで構成されています。
- 障害復旧計画ガイド
- 障害復旧の構成要素
- データの障害復旧シナリオ(この記事)
- アプリケーションの障害復旧シナリオ
- 地域制限があるワークロードの障害復旧の設計
- 障害復旧のユースケース: 地域制限のあるデータ分析アプリケーション
- クラウド インフラストラクチャの停止に対する障害復旧の設計
はじめに
障害復旧計画では、障害の発生時にデータを失わないようにする方法を指定しなければなりません。ここでの「データ」という語は、2 つのシナリオに対応しています。データベース、ログデータ、および他のデータタイプをバックアップして復元することは、次のいずれかのシナリオに該当します。
- データのバックアップ。データのバックアップだけであれば、個別の量のデータをある場所から別の場所にコピーする作業になります。バックアップは、データの破損から復旧して、良好な状態が既知であるディレクトリを本番環境に復元するため、または本番環境がダウンしている場合は DR 環境にデータを復元するため、復旧計画の一環として行われます。通常、データ バックアップの RTO は小~中程度であり、RPO は小さくなります。
- データベースのバックアップ。データベースのバックアップは通常、その時点までのデータの復旧を伴うため、やや複雑になります。そのため、データベース バックアップをバックアップして復元する方法を検討し、リカバリ データベース システムが本番環境構成(同一バージョン、ミラーリングしたディスク構成)を反映していることを確認するのに加えて、トランザクション ログをバックアップする方法も検討する必要があります。復旧の際は、データベース機能を復元した後、最新のデータベース バックアップを適用してから、前回のバックアップ後にバックアップされた復元済みのトランザクション ログを適用する必要があります。データベース システムに固有の複雑な要因(本番環境システムとリカバリ システムのバージョンを一致させる必要があるなど)のため、高可用性優先アプローチを採用して、データベース サーバーが使用不能になる可能性のある状況からの復旧時間を最小限に抑えることで、RTO と RPO の値を小さくできます。
この記事の残りの部分では、RTO と RPO の目標値を達成するためのデータとデータベース シナリオの設計方法の例について説明します。
本番環境がオンプレミスの場合
このシナリオでは、本番環境はオンプレミスであり、障害復旧計画では Google Cloud を復旧サイトとして使用します。
データのバックアップとリカバリ
データをオンプレミスから Google Cloud に定期的にバックアップするプロセスを実装するには、さまざまな戦略を利用できます。このセクションでは、最も一般的なソリューションのうち 2 つを検討していきます。このセクションでは、最も一般的なソリューションのうち 2 つを検討していきます。
ソリューション 1: スケジュールされたタスクを利用して Cloud Storage にバックアップする
DR 構成要素:
- Cloud Storage
データをバックアップするための方法の 1 つは、Cloud Storage にデータを転送するスクリプトまたはアプリケーションを実行するタスクをスケジュールすることです。Cloud Storage へのバックアップ プロセスは、gsutil コマンドライン ツールを使用するか、Cloud Storage クライアント ライブラリのいずれかを利用して自動化できます。たとえば次の gsutil コマンドは、ソース ディレクトリにあるすべてのファイルを、指定されたバケットにコピーします。
gsutil -m cp -r [SOURCE_DIRECTORY] gs://[BUCKET_NAME]
次の手順は、gsutil ツールを利用してバックアップと復元のプロセスを実装する方法を示したものです。
- データファイルのアップロード元のオンプレミス マシンに
gsutilをインストールします。 - データのバックアップ先としてバケットを作成します。
- JSON 形式で、専用サービス アカウントのサービス アカウント キーを生成します。このファイルは、自動スクリプトの一部として
gsutilに認証情報を渡すために使用されます。 バックアップのアップロードに使用するスクリプトを実行するオンプレミス マシンにサービス アカウント キーをコピーします。
IAM ポリシーを作成して、バケットとそのオブジェクトにアクセスできるユーザーを制限します(この目的専用に作成されたサービス アカウントと、オンプレミス オペレータのアカウントを含めます)。Cloud Storage へのアクセス権の詳細については、
gsutilコマンドの IAM 権限をご覧ください。ターゲット バケットでファイルのアップロードとダウンロードをテストします。
データ転送タスクのスクリプト作成のガイダンスに従って、スケジュール設定済みのスクリプトを設定します。
gsutilを利用して Google Cloud の復旧 DR 環境にデータを復元する、復元プロセスを構成します。
gsutil rsync コマンドを使用して、データと Cloud Storage バケット間のリアルタイムの増分同期を実行することもできます。
たとえば、次の gsutil rsync コマンドは、不足しているファイルやオブジェクト、またはデータが変更されているファイルをコピーすることで、Cloud Storage バケット内のコンテンツをソース ディレクトリのコンテンツと同じにします。連続するバックアップ セッション間で変更されたデータの量がソースデータ全体量と比較して小さい場合、gsutil rsync の使用は gsutil cp の使用よりも効率的です。これにより、バックアップ スケジュールの頻度が高くなり、RPO 値を小さくすることができます。
gsutil -m rsync -r [SOURCE_DIRECTORY] gs://[BUCKET_NAME]
詳細については、コロケーションまたはオンプレミスのストレージから転送(転送プロセスを最適化する方法を含む)をご覧ください。
ソリューション 2: Transfer Service for On Premises Data を使用して Cloud Storage にバックアップする
DR 構成要素:
- Cloud Storage
- Transfer Service for On Premises Data
ネットワーク全体で大量のデータを転送すると、多くの場合、慎重な計画と堅牢な実行戦略が必要になります。スケーラブルで信頼性の高い、保守しやすいカスタム スクリプトを開発することは簡単ではありません。多くの場合、カスタム スクリプトによって RPO 値が小さくなり、データ損失のリスクが増します。
大規模なデータ転送を実装する 1 つの方法は、Transfer Service for On Premises Data を使用することです。このサービスは、スケーラブルで、信頼性が高く、管理されたマネージド サービスで、エンジニアリング チームに投資したり転送ソリューションを購入したりしなくても、大量のデータをデータセンターから Cloud Storage バケットに転送できます。
ソリューション 3: パートナーのゲートウェイ ソリューションを使用して Cloud Storage にバックアップする
DR 構成要素:
- Cloud Interconnect
- Cloud Storage の階層型ストレージ
オンプレミスのアプリケーションは、データのバックアップおよび復元の戦略の一環として利用できるサードパーティのソリューションと統合されることがよくあります。こうしたソリューションでは、最新のバックアップをより高速なストレージに保存し、古いバックアップをより低価格な(低速)ストレージにゆっくり移行するという、階層型ストレージのパターンがよく使用されます。Google Cloud をターゲットとして使用する場合は、低速の階層に相当するものとして利用可能な複数のストレージ クラス オプションがあります。
このパターンを実装する 1 つの方法は、オンプレミス ストレージと Google Cloud の間でパートナーのゲートウェイを利用して、この Cloud Storage へのデータ転送を円滑化することです。次の図では、オンプレミスの NAS アプライアンスまたは SAN からの転送を管理するパートナー ソリューションを使ってこの手法を示しています。

障害が発生した場合は、バックアップ対象のデータを DR 環境に復元する必要があります。環境を本番環境に戻すことができるまで、DR 環境を使用して本番環境トラフィックが提供されます。これを達成する方法は、アプリケーションやパートナーソリューションとそのアーキテクチャによって異なります(一部のエンドツーエンドのシナリオは、DR アプリケーションのドキュメントで説明されています)。
オンプレミスから Google Cloud にデータを転送する方法については、ビッグデータ セットの Google Cloud への転送をご覧ください。
パートナー ソリューションの詳細については、Google Cloud ウェブサイトのパートナーのページをご覧ください。
データベースのバックアップと復元
データベース システムをオンプレミスから Google Cloud に復元するプロセスを実装するには、さまざまな戦略を採用できます。このセクションでは、最も一般的なソリューションのうち 2 つを検討していきます。
この記事では、サードパーティのデータベースに組み込まれているさまざまなビルトインのバックアップおよび復元のメカニズムについては、詳しく説明しません。このセクションでは、ここで説明したソリューションで実装されている一般的なガイダンスを示します。
ソリューション 1: Google Cloud のリカバリ サーバーを使用したバックアップと復元
- データベース管理システムに組み込みのバックアップ メカニズムを利用して、データベースのバックアップを作成します。
- オンプレミス ネットワークと Google Cloud ネットワークを接続します。
- データのバックアップ先として、Cloud Storage バケットを作成します。
gsutilかパートナーのゲートウェイ ソリューションを利用して、バックアップ ファイルを Cloud Storage にコピーします(データのバックアップと復元のセクションで説明した手順をご覧ください)。詳しくは、ビッグデータ セットを Google Cloud に転送するをご覧ください。- トランザクション ログを Google Cloud のリカバリサイトにコピーします。トランザクション ログのバックアップを取ると、RPO 値を小さく保つことが可能です。
このバックアップ トポロジを設定したら、Google Cloud 上のシステムに確実に復旧できるようにする必要があります。この手順では通常、バックアップ ファイルをターゲット データベースに復元するだけでなく、トランザクション ログを再生して最小の RTO 値を得るようにします。典型的な復旧シーケンスは次のようになります。
- Google Cloud 上のデータベース サーバーのカスタム イメージを作成します。イメージ上のデータベース サーバーの構成は、オンプレミスのデータベース サーバーと同じにする必要があります。
- オンプレミスのバックアップ ファイルとトランザクション ログファイルを Cloud Storage にコピーするプロセスを実装します。実装例については、ソリューション 1 をご覧ください。
- 最小サイズのインスタンスをカスタム イメージから起動し、必要な永続ディスクをアタッチします。
- 永続ディスクの自動削除フラグを false に設定します。
- バックアップ ファイルの復元に関するデータベース システムの指示に従って、あらかじめ Cloud Storage にコピーされた最新のバックアップ ファイルを適用します。
- Cloud Storage にコピーした最新のトランザクション ログファイルを適用します。
- 最小限のインスタンスをより大きなインスタンスに置き換えます。置き換え後のインスタンスは本番環境トラフィックを受け入れられる大きさでなければなりません。
- Google Cloud の復元されたデータベースを指すようにクライアントを切り替えます。
本番環境が実行され、本番稼働ワークロードへの対応が可能になったら、Google Cloud 復旧環境へのフェイルオーバーの際に行った手順を逆に行います。本番環境に戻すための一般的なシーケンスは次のようになります。
- Google Cloud 上で実行されているデータベースのバックアップをとります。
- バックアップ ファイルを本番環境にコピーします。
- 本番環境データベース システムにバックアップ ファイルを適用します。
- クライアントが Google Cloud のデータベース システムに接続できないようにします。たとえば、データベース システム サービスを停止します。 この時点から本番環境の復旧が完了するまで、アプリケーションは使用できなくなります。
- すべてのトランザクション ログファイルを本番環境にコピーして適用します。
- クライアント接続を本番環境にリダイレクトします。
ソリューション 2: Google Cloud 上のスタンバイ サーバーへのレプリケーション
RTO と RPO の値を非常に小さくするための 1 つの方法は、データを(バックアップするだけでなく)レプリケートし、場合によってはデータベース状態もリアルタイムでデータベース サーバーのホット スタンバイに複製することです。
- オンプレミス ネットワークと Google Cloud ネットワークを接続します。
- Google Cloud 上のデータベース サーバーのカスタム イメージを作成します。イメージ上のデータベース サーバーの構成は、オンプレミスのデータベース サーバーと同じにする必要があります。
- カスタム イメージからインスタンスを起動し、必要な永続ディスクをアタッチします。
- 永続ディスクの自動削除フラグを false に設定します。
- 各データベース ソフトウェアの手順に従って、オンプレミスのデータベース サーバーと Google Cloud のターゲット データベース サーバー間のレプリケーションを構成します。
- クライアントは、通常のオペレーションで、オンプレミスのデータベース サーバーを指すように構成されます。
このレプリケーション トポロジを構成したら、Google Cloud ネットワークで実行されているスタンバイ サーバーを参照するようにクライアントを切り替えます。
本番環境がバックアップされて本番環境ワークロードをサポートできるようになったら、本番環境データベース サーバーを Google Cloud データベース サーバーと再同期してから、クライアントを切り替えて本番環境に戻す必要があります。
本番環境が Google Cloud の場合
このシナリオでは、本番環境と障害復旧環境の両方が Google Cloud 上で実行されます。
データのバックアップとリカバリ
データ バックアップの一般的なパターンは、階層型のストレージ パターンを使用することです。本番環境ワークロードが Google Cloud 上にある場合、階層型ストレージ システムは次の図のようになります。バックアップされたデータにアクセスする必要性が低いため、データはストレージ コストがより安い階層に移行します。
DR 構成要素:
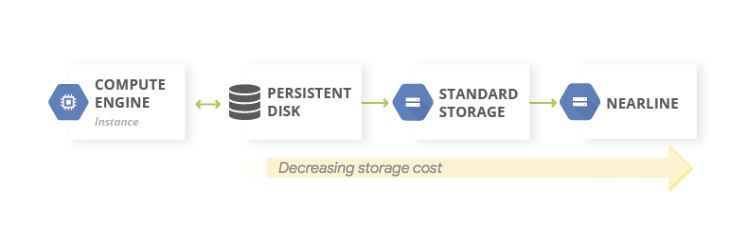
Nearline、Coldline、Archive のストレージ クラスは、アクセス頻度の低いデータを格納するためのストレージですので、これらのクラスに格納されるデータやメタデータの取得に関連する追加コスト、および請求対象となる最小保存期間があります。
データベースのバックアップと復元
セルフマネージド データベースを使用する場合は(たとえば MySQL、PostgreSQL、または SQL Server を Compute Engine のインスタンスにインストールした場合)、本番環境データベースをオンプレミスで管理する場合と同じ運用上の懸念事項がありますが、基盤となるインフラストラクチャを管理する必要はなくなります。
適切な DR 構成要素機能を利用して HA 構成を設定すれば、RTO を小さく保つことができます。データベース構成は、障害発生前にできるだけ近い状態に復旧しやすいように設計すると、RPO 値を小さく保つのに役立ちます。Google Cloud にはこのシナリオに対応するさまざまなオプションが用意されています。
このセクションでは、Google Cloud 上のセルフマネージド データベースのデータベース復旧アーキテクチャを設計する際の、一般的な 2 つのアプローチについて説明します。
状態を同期せずにデータベース サーバーを復旧させる
一般的なパターンは、システム状態をホット スタンバイと同期せずにデータベース サーバーを復旧できるようにすることです。
DR 構成要素:
- Compute Engine
- マネージド インスタンス グループ
- Cloud Load Balancing(内部負荷分散)
次の図は、このシナリオに対処したアーキテクチャの例を示しています。このアーキテクチャを実装することで、手動復旧を要することなく自動的に障害に対応する DR 計画を作成できます。

このシナリオを構成する方法を次のステップで概説します。
- VPC ネットワークを作成します。
次の手順に従って、データベース サーバーで構成されたカスタム イメージを作成します。
- 接続された標準永続ディスクにデータベース ファイルとログファイルが書き込まれるように、サーバーを構成します。
- 接続された永続ディスクからスナップショットを作成します。
- スナップショットから永続ディスクを作成してディスクをマウントするように、起動スクリプトを構成します。
- ブートディスクのカスタム イメージを作成します。
このイメージを使用するインスタンス テンプレートを作成します。
インスタンス テンプレートを使用して、ターゲット サイズが 1 のマネージド インスタンス グループを構成します。
Cloud Monitoring の指標を使用してヘルスチェックを構成します。
マネージド インスタンス グループを使用して、内部ロード バランシングを構成します。
永続ディスクのスナップショットを定期的に作成するスケジュール設定されたタスクを構成します。
置換用のデータベース インスタンスが必要な場合、この構成では自動的に次の処理が行われます。
- 同じゾーンにある正しいバージョンの別のデータベース サーバーが起動されます。
- 最新のバックアップとトランザクション ログファイルを含む永続ディスクが、新しく作成されたデータベース サーバー インスタンスにアタッチされます。
- イベントに応じてデータベース サーバーと通信するクライアントを再構成する必要性が最小限に抑えられます。
- 本番環境データベース サーバーに適用される Google Cloud セキュリティ コントロール(IAM ポリシー、ファイアウォール設定)が、復旧したデータベース サーバーに確実に適用されます。
置換インスタンスはインスタンス テンプレートから作成されるため、元のインスタンスに適用されたコントロールは置換インスタンスにも適用されます。
このシナリオでは、Google Cloud で利用可能な HA 機能のいくつかを利用します。フェイルオーバーの手順は、災害発生時に自動的に行われるため手動で開始する必要はありません。内部ロードバランサにより、置換インスタンスが必要な場合でも、データベース サーバーには確実に同じ IP アドレスが使用されます。インスタンス テンプレートとカスタム イメージによって、置換インスタンスは必ず置換前のインスタンスと同一の構成になります。永続ディスクの定期的なスナップショットを作成することで、スナップショットからディスクを再作成して置換インスタンスに接続する際、置換インスタンスでは RPO 値に従って復元されたデータが使用されます。この値は、スナップショットの頻度に応じて異なります。このアーキテクチャでは、永続ディスクに書き込まれた最新のトランザクション ログファイルも自動的に復元されます。
マネージド インスタンス グループは、厚みのある HA を提供します。アプリケーションまたはインスタンスのレベルでの障害に対応するメカニズムが提供されるため、これらのシナリオが発生した場合、手動で介入する必要はありません。ターゲット サイズを 1 に設定すると、マネージド インスタンス グループで実行され、トラフィックを処理するアクティブなインスタンスが 1 つだけ存在するようになります。
標準永続ディスクはゾーン単位なので、ゾーン単位での障害が発生した場合、ディスクを再作成するにはスナップショットが必要になります。スナップショットはリージョン間でも使用できるため、ディスクは同じリージョンに復元するのと同じくらい簡単に別のリージョンにも復元できます。
この構成のバリエーションは、標準永続ディスクの代わりにリージョンの永続ディスクを使用することです。この場合、復旧手順の一環としてスナップショットを復元する必要はありません。
どのバリエーションを選択するかは、予算および RTO と RPO の値によって決まります。
Google Cloud での HA シナリオおよび DR シナリオ用に設計されたデータベース構成の詳細については、以下をご覧ください。
- Cassandra 障害復旧での Cloud Storage の使用では、Compute Engine 上で稼働する Cassandra 環境のバックアップと復旧プロセスを実装する方法が説明されています。この記事は、データベース スナップショットのローカル ディスクへのバックアップと増分バックアップを実装し、Cloud Storage にコピーするプロセスを説明しています。
- Compute Engine への MongoDB のデプロイでは、レプリカセットを第 2 のリージョンにデプロイした MongoDb の HA アーキテクチャについて説明しています。
非常に大規模なデータベースの部分的な破損からの復旧
ペタバイト単位のデータを格納できるデータベースを使用している場合は、一部のデータに影響を与えるがすべてのデータには影響しない障害が発生する可能性があります。その場合、復元すべきデータの量を最小限に抑える必要があります。一部のデータを復元するために、データベース全体を復元する必要はありません。
採用できる緩和策はいくつかあります。
- 特定の期間ごとに、データを異なるテーブルに格納します。この方法では、データセット全体ではなく、データのサブセットのみを新しいテーブルに復元する必要があります。
元のデータを Cloud Storage に保存します。これにより、新しいテーブルを作成して、破損していないデータを再読み込みできます。そこから、新しいテーブルを指すようにアプリケーションを調整できます。
さらに、RTO に応じて可能であれば、破損していないデータを新しいテーブルに復元するまでアプリケーションをオフラインにしておくことで、データが破損しているテーブルへのアクセスを防止できます。
Google Cloud のマネージド データベース サービス
このセクションでは、Google Cloud 上のマネージド データベース サービスに適切なバックアップと回復のメカニズムを実装するための方法をいくつか説明します。
マネージド データベースはスケールを考慮して設計されているため、従来の RDMBS で行われている従来のバックアップおよび復元メカニズムは通常利用できません。セルフマネージド データベースの場合と同様、ペタバイト単位のデータを格納できるデータベースを使用している場合は、DR シナリオにおいて復元するべきデータの量を最小限に抑える必要があります。この目標を達成するには、マネージド データベースごとにさまざまな戦略を採用できます。
Bigtable は Bigtable レプリケーションを提供します。レプリケートされた Bigtable データベースは、ゾーンやリージョンの障害に直面した際も、単一クラスタより高い可用性、読み取りスループットの向上、より高い耐久性と復元性を実現できます。
Bigtable のバックアップはフルマネージド サービスであり、テーブルのスキーマとデータのコピーを保存しておき、後でバックアップから新しいテーブルに復元できます。
また、Bigtable のテーブルを一連の Hadoop シーケンス ファイルとしてエクスポートすることもできます。これらのファイルは Cloud Storage に保存するか、Bigtable の別のインスタンスにデータを再インポートするために利用できます。Bigtable のデータセットは、Google Cloud リージョン内のゾーン間で非同期にレプリケートできます。
BigQuery: データをアーカイブする場合は、BigQuery の長期保存を活用できます。連続する 90 日間にわたってテーブルが編集されていない場合、そのテーブルのストレージ料金は自動的に 50% 値引きされます。テーブルを長期にわたって保存していても、パフォーマンス、耐久性、可用性などの各種機能性が損なわれることはありません。ただしそのテーブルを編集すると、価格は通常のストレージ価格に戻り、90 日間のカウントダウンが再び開始されます。
BigQuery は、単一リージョンの 2 つのゾーンに複製されますが、テーブルの破損への対処には役立ちません。そのため、そのようなシナリオから復旧できる計画が必要です。たとえば、次の操作が可能です。
- 破損の検出が 7 日以内の場合、過去の時点のテーブルに対してクエリを行い、スナップショット デコレータを利用して、破損する前のテーブルを復元します。
- BigQuery からデータをエクスポートし、エクスポートしたデータを含む(ただし破損したデータは含まない)新しいテーブルを作成します。
- 特定の期間ごとに、データを異なるテーブルに格納します。この方法では、データセット全体ではなく、データの一部のみを新しいテーブルに復元するだけで済みます。
- 特定の期間にデータセットのコピーを作成します。データ破損のイベントが、ポイントインタイム クエリでキャプチャできる期間(7 日以上前など)を超えた場合に、そのコピーを使用できます。また、データセットをあるリージョンから別のリージョンへコピーして、リージョンのエラーの際にデータの可用性を確保することもできます。
- 元のデータを Cloud Storage に保存します。これにより、新しいテーブルを作成して、破損していないデータを再読み込みできます。そこから、新しいテーブルを指すようにアプリケーションを調整できます。
Firestore: マネージド エクスポートおよびインポート サービスを使用すると、Cloud Storage バケットを使用して Firestore エンティティをインポートおよびエクスポートできます。これにより、偶発的なデータの削除から復旧するためのプロセスを実装できます。
Cloud SQL: フルマネージドの Google Cloud MySQL データベースである Cloud SQL を使用する場合は、Cloud SQL インスタンスの自動的なバックアップとバイナリログを有効にする必要があります。これにより、ポイントインタイム リカバリを実行して、データベースをバックアップから復旧し、新しい Cloud SQL インスタンスに復元することができます。詳細は、Cloud SQL のバックアップと復旧をご覧ください。
また、Cloud SQL を HA 構成とクロスリージョン レプリカで構成し、ゾーンやリージョンのエラーが発生した際に稼働時間を最大化できます。
Spanner: Dataflow テンプレートを利用して、Cloud Storage バケット内の一連の Avro ファイルにデータベースを完全にエクスポートし、さらに別のテンプレートを利用してそのエクスポート ファイルを新しい Spanner データベースに再インポートできます。
より制御されたバックアップを行うには、Cloud Dataflow コネクタを使用すると、Cloud Dataflow パイプラインで Spanner にデータを読み書きするためのコードを記述できます。たとえば、このコネクタを利用して Spanner からバックアップ ターゲットの Cloud Storage にデータをコピーできます。Spanner からデータを読み取る(または書き戻す)速度は、構成されたノードの数によって異なります。これは RTO 値に直接影響を与えます。
Spanner の commit タイムスタンプ機能は、前回のフル バックアップ以降に追加または変更された行のみを選択できるため、増分バックアップに役立ちます。
マネージド バックアップでは、Spanner のバックアップと復元を使用すると、最長 1 年間保持できる整合性のあるバックアップを作成できます。RTO の値は export より低くなります。これは、復元オペレーションでは、データをコピーすることなくバックアップが直接マウントされるためです。
RTO 値を小さくするには、ストレージおよび読み取り / 書き込みスループットの要件を満たすために必要な最小限のノード数で構成された、ウォーム スタンバイの Spanner インスタンスを設定します。
Spanner のポイントインタイム リカバリ(PITR)を使用すると、過去の特定の時点のデータを復元できます。たとえば、オペレーターがデータを誤って書き込みした場合や、アプリケーション ロールアウトによってデータベースが破損した場合に PTR を使用すると、最長で過去 7 日前までのデータを復元できます。
Cloud Composer: Cloud Composer(Apache Airflow の管理対象バージョン)を利用すると、複数の Google Cloud データベースの定期的なバックアップをスケジュール設定できます。有向非巡回グラフ(DAG)をスケジュールに従って(たとえば毎日)実行して、データを別のプロジェクト、データセット、またはテーブルに(使用するソリューションに応じて)コピーするか、データを Cloud Storage にエクスポートすることができます。
データのエクスポートまたはコピーは、さまざまな Cloud Platform 演算子を使用して行うことができます。
たとえば、DAG を作成すると次のようなことが可能になります。
- BigQueryToCloudStorageOperator を使用して、BigQuery テーブルを Cloud Storage にエクスポートする。
- DatastoreExportOperator を使用して、Datastore モードの Firestore を Cloud Storage にエクスポートする。
- MySqlToGoogleCloudStorageOperator を使用して、MySQL テーブルを Cloud Storage にエクスポートする。
- PostgresToGoogleCloudStorageOperator を使用して、Postgres テーブルを Cloud Storage にエクスポートする。
本番環境が別のクラウドの場合
このシナリオでは、本番環境で別のクラウド プロバイダを利用しており、障害復旧計画では Google Cloud を復旧サイトとして使用します。
データのバックアップとリカバリ
オブジェクト ストア間でデータを転送することは、DR シナリオの一般的なユースケースです。Storage Transfer Service は Amazon S3 と互換性があるため、Amazon S3 から Cloud Storage にオブジェクトを転送する際に推奨される方法になります。
ファイル作成日、ファイル名フィルタ、データを転送する時刻に基づいた高度なフィルタを使用して、データソースからデータシンクへの定期的な同期をスケジュールする転送ジョブを構成できます。必要な RPO を達成するには、次の要素を考慮する必要があります。
変化率: 一定期間内に生成または更新されるデータ量。変化率が高いほど、転送の各期間に変更を宛先に転送する際に、より多くのリソースが必要になります。
転送のパフォーマンス: ファイルの転送にかかる時間。大きなファイルを転送する場合、通常これは送信元と宛先の使用可能な帯域幅によって決定されます。ただし、転送ジョブが小さいファイルで構成されている場合、QPS が制限要因になる可能性があります。その場合、十分な帯域幅が確保されていることを条件に、複数の同時実行ジョブのスケジュールを設定してパフォーマンスをスケーリングできます。実際のデータの代表サブセットを使用して、転送のパフォーマンスを測定することをおすすめします。
頻度: バックアップ ジョブの間隔。宛先でのデータの鮮度は、転送ジョブが最後にスケジュールされたときの最新のデータになります。したがって、連続転送ジョブの間隔は RPO の目標より長くならないようにすることが重要です。たとえば、RPO 目標が 1 日の場合、転送ジョブは少なくとも 1 日に 1 回スケジュールする必要があります。
モニタリングとアラート: Storage Transfer Service は、さまざまなイベントで Pub/Sub 通知を提供します。予期しない障害やジョブの完了時間の変更に対処するため、これらの通知に登録することをおすすめします。
AWS から Google Cloud にデータを移動するもう 1 つの方法は、Amazon S3 および Cloud Storage と互換性のある Python ツール boto を使用することです。これは gsutil コマンドライン ツールのプラグインとしてインストールできます。
データベースのバックアップと復元
この記事では、サードパーティのデータベースに組み込まれているさまざまなビルトインのバックアップおよび復旧メカニズムや、他のクラウド プロバイダで利用されているバックアップや復旧の手法については、詳しく説明しません。非マネージド データベースをコンピューティング サービス上で運用している場合は、本番環境クラウド プロバイダが提供している HA 設備を活用できます。それらを拡張して HA デプロイを Google Cloud に組み込んだり、データベース バックアップ ファイルのコールド ストレージの最終的な宛先として Cloud Storage を使用したりすることも可能です。
次のステップ
- Google Cloud の地域とリージョンを読む。
この DR シリーズの他の記事を読む:
Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センター をご覧ください。