Descripción general: Migra almacenes de datos a BigQuery
En este documento, se analizan los conceptos generales que se aplican a cualquier tecnología de almacenamiento de datos y se describe un framework que puedes usar para organizar y estructurar tu migración a BigQuery.
Terminología
Usamos la siguiente terminología cuando analizamos la migración de almacenes de datos:
- Caso de uso
- Un caso práctico consta de todos los conjuntos de datos, el procesamiento de datos y las interacciones del sistema y el usuario que se requieren para lograr el valor empresarial, como el seguimiento de los volúmenes de ventas a lo largo del tiempo. En el almacenamiento de datos, el caso práctico a menudo consta de lo siguiente:
- Las canalizaciones de datos que transfieren datos sin procesar de varias fuentes de datos, como las bases de datos de administración de relaciones con clientes (CRM)
- Los datos almacenados en el almacén de datos
- Las secuencias de comandos y procedimientos para manipular, procesar y analizar los datos en mayor medida
- Una aplicación empresarial que lee los datos o interactúa con ellos
- Carga de trabajo
- Un conjunto de casos prácticos que están conectados y tienen dependencias compartidas. Por ejemplo, un caso de uso puede tener las siguientes relaciones y dependencias:
- Los informes de compra pueden ser independientes y son útiles para comprender los gastos y solicitar descuentos.
- Los informes de ventas pueden ser independientes y son útiles para planificar campañas de marketing.
- Sin embargo, los informes de ganancias y pérdidas dependen de las compras y las ventas, y son útiles para determinar el valor de la empresa.
- Aplicación empresarial
- Un sistema con el que los usuarios finales interactúan, por ejemplo, un informe visual o un panel. Una aplicación empresarial también puede adoptar la forma de una canalización de datos operativos o un ciclo de comentarios. Por ejemplo, después de calcular o predecir los cambios en el precio del producto, una canalización de datos operativos puede actualizar los precios del producto nuevo en una base de datos transaccional.
- Proceso ascendente
- Los sistemas de origen y las canalizaciones de datos que cargan datos en el almacén de datos.
- Proceso descendente
- Las secuencias de comandos, los procedimientos y las aplicaciones empresariales que se usan para procesar, consultar y visualizar los datos en el almacén de datos.
- Migración de descarga
- Una estrategia de migración que tiene como objetivo lograr que el caso práctico funcione para el usuario final en el entorno nuevo lo más rápido posible o aprovechar la capacidad adicional disponible en el entorno nuevo. Los casos prácticos se descargan de la siguiente manera:
- Se copian y, luego, se sincronizan el esquema y los datos del almacén de datos heredado
- Se migran las secuencias de comandos descendentes, los procedimientos y las aplicaciones empresariales
La descarga de la migración puede aumentar la complejidad y el trabajo involucrados en la migración de canalizaciones de datos.
- Migración completa
- Un enfoque de migración, como una migración de descarga, pero en lugar de copiar y sincronizar el esquema y los datos, debes configurar la migración para transferir datos de forma directa al nuevo almacén de datos en la nube desde los sistemas de origen ascendentes. En otras palabras, también se migrarán las canalizaciones de datos requeridas para el caso práctico.
- Almacén de datos empresarial (EDW)
- Un almacén de datos que consta de una base de datos analítica y de varios componentes y procedimientos analíticos vitales. Estos incluyen canalizaciones de datos, consultas y aplicaciones empresariales que se necesitan para entregar las cargas de trabajo de la organización.
- Almacén de datos en la nube (CDW)
- Un almacén de datos que tiene las mismas características que un EDW, pero se ejecuta en un servicio por completo administrado en la nube, en este caso, BigQuery.
- Canalización de datos
- Un proceso que conecta sistemas de datos a través de una serie de funciones y tareas que realizan varios tipos de transformaciones de datos. Para obtener más información, consulta ¿Qué es una canalización de datos? en esta serie.
Razones para migrar a BigQuery
En las últimas décadas, las organizaciones perfeccionaron la ciencia del almacenamiento de datos. Cada vez más, aplican estadísticas descriptivas a grandes cantidades de datos almacenados, lo que les permite obtener estadísticas sobre sus operaciones empresariales principales. La inteligencia empresarial (BI) convencional, que se enfoca en las consultas, los informes y el procesamiento analítico en línea, fue un factor diferenciador en el pasado que definía el destino de una empresa, pero ya no es suficiente.
Ahora, las organizaciones necesitan comprender eventos pasados con estadísticas descriptivas y, también, necesitan estadísticas predictivas, que a menudo usan aprendizaje automático (AA) para extraer patrones de datos y realizar predicciones probabilísticas. El objetivo fundamental es desarrollar estadísticas prescriptivas que combinen lecciones del pasado con predicciones sobre el futuro para guiar las acciones en tiempo real automáticamente.
Las prácticas tradicionales de almacenamiento de datos capturan datos sin procesar de varias fuentes, que suelen ser sistemas de procesamiento transaccional en línea (OLTP). Luego, se extrae un subconjunto de datos por lotes, se lo transforma en función de un esquema definido y se lo carga en el almacén de datos. Debido a que los almacenes de datos tradicionales capturan un subconjunto de datos por lotes y almacenan datos según esquemas rígidos, no son adecuados para manejar el análisis en tiempo real ni responder a consultas espontáneas. Google diseñó BigQuery en parte como respuesta a estas limitaciones inherentes.
Las ideas innovadoras suelen retrasarse debido al tamaño y la complejidad de la organización de TI que implementa y mantiene estos almacenes de datos tradicionales. La creación de una arquitectura de almacén de datos escalable, con alta disponibilidad y segura puede demorar años y requerir una inversión considerable. BigQuery ofrece una sofisticada tecnología de software como servicio (SaaS) que se puede usar para operaciones de almacenamiento de datos sin servidores. Esto te permite enfocarte en hacer avanzar tu empresa principal mientras delegas el mantenimiento de la infraestructura y el desarrollo de la plataforma a Google Cloud.
BigQuery ofrece acceso a almacenamiento de datos estructurados, procesamiento y estadísticas de forma escalable, flexible y rentable. Estas características son esenciales cuando tus volúmenes de datos crecen de forma exponencial para que los recursos de almacenamiento y procesamiento estén disponibles según sea necesario, además de poder obtener valor de esos datos. Además, para las organizaciones que recién comienzan en el análisis de macrodatos y el aprendizaje automático, y que desean evitar las complejidades potenciales de los sistemas de macrodatos locales, BigQuery ofrece un plan de pago por uso para experimentar con servicios administrados.
Con BigQuery, puedes encontrar respuestas a problemas que antes no se podían resolver, aplicar el aprendizaje automático para descubrir patrones emergentes de datos y probar nuevas hipótesis. Como resultado, obtienes estadísticas oportunas sobre el rendimiento de tu empresa, lo que te permite modificar los procesos para obtener mejores resultados. Además, la experiencia del usuario final a menudo se enriquece con estadísticas relevantes obtenidas del análisis de macrodatos, como se explica más adelante en esta serie.
Qué migrar y cómo hacerlo: el marco de trabajo de migración
Realizar una migración puede ser una tarea compleja y prolongada. Por lo tanto, recomendamos que te adhieras a un marco de trabajo para organizar y estructurar el trabajo de migración en fases:
- Prepárate y descubre: prepárate para la migración con el descubrimiento de cargas de trabajo y casos prácticos.
- Planifica: Prioriza los caso de uso, define las medidas de éxito y planifica tu migración.
- Ejecuta: Itera los pasos para la migración, desde la evaluación hasta la validación.
Prepárate y descubre
En la fase inicial, el enfoque está en la preparación y el descubrimiento. Se trata de brindarte a ti y a tus partes interesadas una oportunidad temprana para descubrir los casos prácticos existentes y plantear inquietudes iniciales. Es importante que también realices un análisis inicial sobre los beneficios esperados. Estos incluyen ganancias de rendimiento (por ejemplo, simultaneidad mejorada) y reducciones en el costo total de propiedad (TCO). Esta fase es crucial para ayudarte a establecer el valor de la migración.
Por lo general, un almacén de datos admite una amplia gama de casos prácticos y tiene una gran cantidad de partes interesadas, desde analistas de datos hasta ejecutivos empresariales. Recomendamos que involucres a representantes de estos grupos para comprender qué casos prácticos existen, si estos tienen un buen rendimiento y si los interesados planifican casos prácticos nuevos.
El proceso de la fase de descubrimiento consta de las siguientes tareas:
- Examinar la propuesta de valor de BigQuery y compararla con la de tu almacén de datos heredado
- Realizar un análisis inicial de TCO
- Establecer qué casos prácticos se ven afectados por la migración
- Modelar las características de las canalizaciones de datos y los conjuntos de datos subyacentes que deseas migrar para identificar dependencias
Para obtener información sobre los casos prácticos, puedes desarrollar un cuestionario para recolectar información de tus expertos en la materia (SME), usuarios finales y partes interesadas. El cuestionario debe recolectar la siguiente información:
- ¿Cuál es el objetivo del caso práctico? ¿Cuál es el valor empresarial?
- ¿Cuáles son los requisitos no funcionales? Actualidad de los datos, uso simultáneo, etcétera.
- ¿El caso práctico forma parte de una carga de trabajo más grande? ¿Depende de otros casos prácticos?
- ¿Qué conjuntos de datos, tablas y esquemas respaldan el caso práctico?
- ¿Qué sabes sobre las canalizaciones de datos que alimentan esos conjuntos de datos?
- ¿Qué herramientas de BI, informes y paneles se usan en la actualidad?
- ¿Cuáles son los requisitos técnicos actuales en torno a las necesidades operativas, el rendimiento, la autenticación y el ancho de banda de la red?
En el siguiente diagrama, se muestra una arquitectura heredada de alto nivel antes de la migración. Se ilustra el catálogo de fuentes de datos disponibles, canalizaciones de datos heredadas, canalizaciones operativas heredadas y bucles de comentarios, además de los informes de BI y paneles heredados a los que acceden los usuarios finales.

Planificación
La fase de planificación consiste en tomar la entrada de la fase de preparación y descubrimiento, evaluarla y, luego, usarla para planificar la migración. Esta fase se puede dividir en las siguientes tareas:
Cataloga y prioriza casos prácticos
Recomendamos que dividas el proceso de migración en iteraciones. Puedes catalogar casos prácticos existentes y nuevos, y asignarles una prioridad. Para obtener más detalles, consulta las secciones sobre cómo migrar con un enfoque iterativo y cómo priorizar casos de uso de este documento.
Define medidas de éxito
Es útil definir medidas claras de éxito, como los indicadores clave de rendimiento (KPI), antes de la migración. Tus medidas te permitirán evaluar el éxito de la migración en cada iteración. A la vez, esto te permite realizar mejoras en el proceso de migración en iteraciones posteriores.
Crea una definición de “finalizado”
Con las migraciones complejas, no siempre es evidente cuándo se terminó de migrar un caso práctico determinado. Por lo tanto, debes describir una definición formal de tu estado final previsto. Esta definición debe ser lo bastante genérica para que pueda aplicarse a todos los casos prácticos que desees migrar. La definición debe actuar como un conjunto de criterios mínimos para que el caso práctico se considere migrado por completo. Por lo general, esta definición incluye puntos de control para asegurarte de que el caso práctico se integró, se probó y se documentó.
Diseña y propone una prueba de concepto (POC), un estado a corto plazo y un estado final ideal
Después de priorizar tus casos prácticos, puedes comenzar a pensar en su estado durante todo el período de la migración. Considera la primera migración de casos prácticos como una prueba de concepto (PoC) para validar el enfoque de migración inicial. Considera lo que se puede lograr en las primeras semanas o meses como el estado a corto plazo. ¿Cómo afectarán tus planes de migración a tus usuarios? ¿Tendrán una solución híbrida o se puede migrar primero una carga de trabajo completa para un subconjunto de usuarios?
Crea estimaciones de tiempo y costos
Para garantizar un proyecto de migración exitoso, es importante generar estimaciones de tiempo realistas. Para lograrlo, interactúa con todas las partes interesadas relevantes para analizar su disponibilidad y acordar su nivel de participación durante el proyecto. Esto te ayudará a estimar los costos laborales con mayor precisión. Para estimar los costos relacionados con el consumo proyectado de recursos de nube, visita Estima los costos de almacenamiento y consultas y la Introducción al control de costos de BigQuery en la documentación de BigQuery.
Identifica a un socio de migración y, luego, interactúa con él
En la documentación de BigQuery, se describen muchas herramientas y recursos que puedes usar para realizar la migración. Sin embargo, puede ser difícil realizar una migración grande y compleja por tu cuenta si no tienes experiencia previa o no tienes toda la experiencia técnica requerida dentro de tu organización. Por lo tanto, te recomendamos que, desde el principio, identifiques y, luego, interactúes con un socio de migración. Para obtener más información, consulta nuestros programas globales de socios y de servicios de consultoría.
Migra con un enfoque iterativo
Cuando se migra una gran operación de almacenamiento de datos a la nube, es una buena idea adoptar un enfoque iterativo. Por lo tanto, te recomendamos que realices la transición a BigQuery a través de iteraciones. Dividir el esfuerzo de migración en iteraciones facilita el proceso general, reduce el riesgo y brinda oportunidades para aprender y mejorar después de cada iteración.
Una iteración consiste en todo el trabajo necesario para descargar o migrar por completo uno o más casos de uso relacionados dentro de un período determinado. Puedes pensar en una iteración como un ciclo de sprint en la metodología ágil, que consta de una o más historias de usuario.
Para facilitar el seguimiento, se recomienda que asocies un caso práctico individual con una o más historias de usuario. Por ejemplo, considera la siguiente historia de usuario: “Como analista de precios, quiero analizar los cambios en los precios de los productos durante el último año para poder calcular los precios futuros”.
El caso práctico correspondiente podría ser el siguiente:
- Transferir datos desde una base de datos transaccional que almacena productos y precios.
- Transformar los datos en una sola serie temporal para cada producto y, también, implementar cualquier valor faltante
- Almacenar los resultados en una o más tablas en el almacén de datos.
- Hacer que los resultados estén disponibles a través de un notebook de Python (la aplicación empresarial)
El valor empresarial de este caso práctico es apoyar el análisis de precios.
Es posible que este caso práctico, al igual que la mayoría, admita múltiples historias de usuarios.
Es probable que un caso práctico descargado esté seguido de una iteración posterior para migrarlo por completo. De lo contrario, es posible que aún dependas del almacén de datos heredado existente, ya que los datos se copian desde allí. La migración completa posterior es el delta entre la descarga y una migración completa sin descarga previa; en otras palabras, la migración de las canalizaciones de datos para extraer, transformar y cargar los datos en el almacén de datos.
Prioriza los casos de uso
Dónde comienzas y finalizas la migración depende de las necesidades de tu empresa. Decidir el orden en el que se migran los casos prácticos es importante porque tener éxito rápido durante una migración es crucial para continuar en la ruta de adopción de la nube. Experimentar errores en una etapa inicial puede convertirse en un obstáculo grave para el esfuerzo general de migración. Es posible que estés interesado en los beneficios de Google Cloud y BigQuery, pero puede ser complicado y tedioso procesar todas las canalizaciones y conjuntos de datos creados o administrados en tu almacén de datos heredado para casos prácticos diferentes.
Aunque no existe una respuesta única para todos los casos, hay prácticas recomendadas que puedes aplicar mientras evalúas tus aplicaciones empresariales y casos prácticos locales. Este tipo de planificación inicial puede facilitar el proceso de migración y la transición completa a BigQuery.
En las siguientes secciones, se exploran posibles enfoques para priorizar casos prácticos.
Enfoque: aprovechar las oportunidades actuales
Observa las oportunidades actuales que podrían ayudarte a maximizar el retorno de la inversión de un caso práctico específico. Este enfoque es útil en especial si tienes que justificar el valor empresarial de migrar a la nube. También brinda la oportunidad de recolectar puntos de datos adicionales para ayudar a evaluar el costo total de la migración.
A continuación, presentamos algunas preguntas de ejemplo para ayudarte a identificar qué casos prácticos priorizar:
- ¿El caso práctico consta de canalizaciones y conjuntos de datos limitados por el almacén de datos empresarial heredado?
- ¿Tu almacén de datos empresarial actual requiere una actualización de hardware? ¿Se prevé la necesidad de expandir el hardware? Si es así, puede ser útil descargar los casos prácticos a BigQuery lo antes posible.
Identificar oportunidades de migración puede generar algunas ganancias rápidas que generen beneficios inmediatos y tangibles para los usuarios y la empresa.
Enfoque: migrar primero las cargas de trabajo analíticas
Migra las cargas de trabajo de procesamiento analítico en línea (OLAP) antes que las de procesamiento de transacciones en línea (OLTP). Un almacén de datos es a menudo el único lugar en la organización en el que tienes todos los datos para crear una vista única y global de las operaciones de la organización. Por lo tanto, es común que las organizaciones tengan canalizaciones de datos que retroalimenten los sistemas transaccionales para actualizar el estado o activar procesos; por ejemplo, comprar mayor cantidad de un producto cuando su inventario es bajo. Las cargas de trabajo de OLTP tienden a ser más complejas y tener requisitos operativos y Acuerdos de Nivel de Servicio (ANS) más estrictos que las de OLAP, por lo que también suele ser más fácil migrar antes estas últimas.
Enfoque: centrarse en la experiencia del usuario
Identifica oportunidades para mejorar la experiencia del usuario a través de la migración de conjuntos de datos específicos y la habilitación de nuevos tipos de estadísticas avanzadas. Por ejemplo, una forma de mejorar la experiencia del usuario es usar estadísticas en tiempo real. Puedes compilar experiencias del usuario sofisticadas en torno a una transmisión de datos en tiempo real cuando se fusiona con datos históricos. Por ejemplo:
- Un empleado de oficina administrativa que recibió una alerta de inventario casi agotado en su app para dispositivos móviles
- Un cliente en línea que podría beneficiarse si sabe que gastar otro dólar le daría acceso al siguiente nivel de recompensas
- Un miembro del personal de enfermería que recibe alertas sobre los signos vitales de un paciente en su reloj inteligente, lo que le permite tomar la mejor decisión luego de revisar el historial de tratamiento del paciente en su tablet
También puedes mejorar la experiencia del usuario con estadísticas predictivas y prescriptivas. Para ello, puedes usar BigQuery ML, Vertex AI AutoML Tabular o los modelos entrenados con anterioridad de Google para análisis de imágenes, análisis de videos, reconocimiento de voz, lenguaje natural y traducción. También puedes entregar tu modelo personalizado con Vertex AI para casos de uso adaptados a las necesidades de tu empresa. Esto podría involucrar las siguientes tareas:
- Recomendar un producto según las tendencias del mercado y el comportamiento de compra del usuario
- Predecir una demora en un vuelo
- Detectar actividades fraudulentas
- Marcar contenido inapropiado.
- Otras ideas innovadoras que podrían diferenciar tu app de la competencia
Enfoque: priorizar los casos prácticos con menos riesgos
Hay varias preguntas que TI puedes hacer para ayudar a evaluar qué casos prácticos son los que presentan menos riesgos durante la migración, lo que los hace mejores candidatos para las primeras fases. Por ejemplo:
- ¿Cuál es la importancia empresarial de este caso práctico?
- ¿Hay un gran número de empleados o clientes que dependen del caso práctico?
- ¿Cuál es el entorno de destino (por ejemplo, desarrollo o producción) para el caso práctico?
- ¿Qué entiende nuestro equipo de TI del caso práctico?
- ¿Cuántas integraciones y dependencias tiene el caso práctico?
- Nuestro equipo de TI ¿tiene documentación adecuada, actualizada y completa sobre el caso práctico?
- ¿Cuáles son los requisitos operativos (ANS) del caso práctico?
- ¿Cuáles son los requisitos de cumplimiento legales o gubernamentales para el caso práctico?
- ¿Cuáles son las sensibilidades de tiempo de inactividad y latencia para acceder al conjunto de datos subyacente?
- ¿Hay propietarios de línea de negocios entusiasmados y dispuestos a migrar su caso práctico con anticipación?
Revisar esta lista de preguntas puede ayudarte a clasificar las canalizaciones y conjuntos de datos de menor a mayor riesgo. Los elementos de bajo riesgo se deben migrar primero y los de mayor riesgo, después.
Ejecuta
Una vez que reúnas información sobre tus sistemas heredados y crees una reserva prioritaria de casos prácticos, puedes agruparlos en cargas de trabajo y continuar con la migración en iteraciones.
Una iteración puede constar de un solo caso práctico, unos pocos casos prácticos individuales o varios relacionados con una sola carga de trabajo. La opción que elijas para la iteración depende de la interconectividad de los casos prácticos, las dependencias compartidas y los recursos que tienes disponibles para realizar el trabajo.
Por lo general, una migración consta de los siguientes pasos:
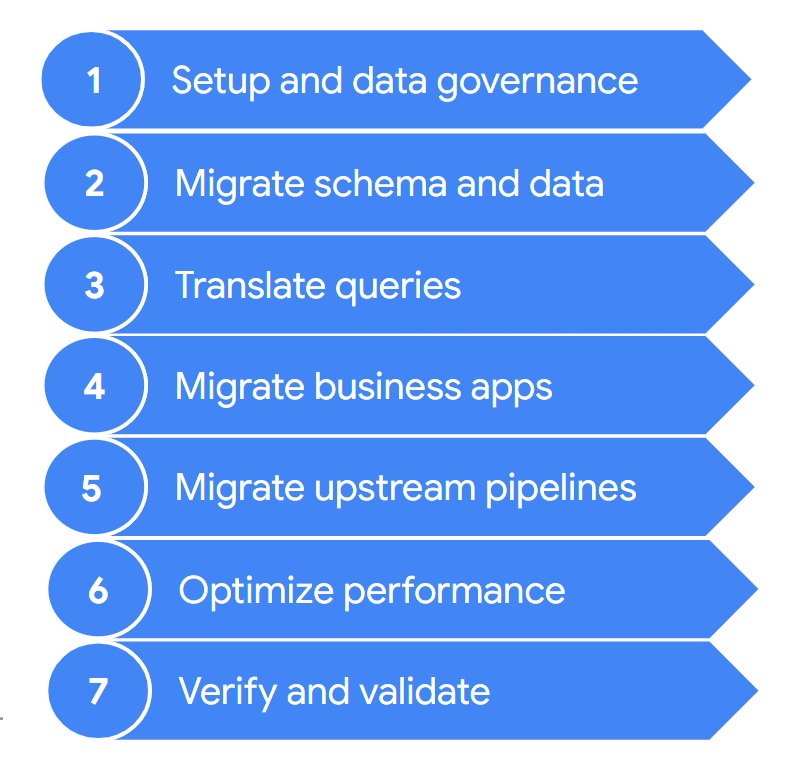
Estos pasos se describen con más detalle en las siguientes secciones. Es posible que no debas realizar todos estos pasos en cada iteración. Por ejemplo, en una iteración, puedes decidir enfocarte en copiar algunos datos de tu almacén de datos heredado a BigQuery. En cambio, en una iteración posterior, puedes enfocarte en modificar la canalización de transferencia de una fuente de datos original directamente a BigQuery.
1. Configuración y administración de datos
La configuración es el trabajo fundamental que se requiere para permitir que los casos prácticos se ejecuten en Google Cloud. Esto puede incluir la configuración de tus proyectos de Google Cloud, red, nube privada virtual (VPC) y administración de datos. También incluye desarrollar una buena comprensión el estado actual: qué funciona y qué no. Esto te ayudará a entender los requisitos para tu iniciativa de migración. Puedes usar la función de evaluación de migración de BigQuery para ayudarte con este paso.
La administración de datos es un enfoque basado en principios para administrar los datos durante su ciclo de vida, desde la adquisición hasta el uso y la eliminación. En tu programa de administración de datos, se describen con claridad las políticas, procedimientos, responsabilidades y controles relacionados con las actividades de datos. Este programa ayuda a garantizar que la información se recopile, mantenga, use y difunda de una forma que satisfaga la integridad de los datos y las necesidades de seguridad de tu organización. También ayuda a que tus empleados puedan descubrir y usar todo el potencial de los datos.
Con el documento de administración de datos, comprenderás la administración de datos y los controles necesarios para migrar el almacenamiento de datos local a BigQuery.
2. Migra el esquema y los datos
El esquema del almacén de datos define cómo están estructurados tus datos y define las relaciones entre tus entidades de datos. El esquema es el centro del diseño de datos y también influye en muchos procesos ascendentes y descendentes.
En el documento sobre la transferencia de datos y esquemas, se proporciona información detallada sobre la transferencia de datos a BigQuery y recomendaciones para actualizar el esquema para aprovechar al máximo las funciones de BigQuery.
3. Traduce consultas
Usa la traducción de SQL por lotes para migrar tu código de SQL de forma masiva o la traducción de SQL interactiva para traducir consultas ad hoc.
Algunos almacenes de datos heredados incluyen extensiones de SQL estándar para habilitar la funcionalidad de su producto. BigQuery no es compatible con estas extensiones de propietario; en su lugar, cumple con el estándar ANSI/ISO SQL:2011. Esto significa que algunas de tus consultas aún pueden necesitar una refactorización manual si los traductores de SQL no pueden interpretarlas.
4. Migra aplicaciones empresariales
Las aplicaciones empresariales pueden tener muchas formas, desde paneles hasta aplicaciones personalizadas y canalizaciones de datos operacionales que proporcionan bucles de comentarios a los sistemas transaccionales.
Para obtener más información sobre las opciones de análisis cuando trabajas con BigQuery, consulta Descripción general del análisis de BigQuery. En este tema, se proporciona una descripción general de las herramientas de informes y análisis que puedes usar para obtener estadísticas útiles a partir de tus datos.
En la sección sobre ciclos de comentarios del documento de canalización de datos, se describe cómo puedes usar una canalización de datos para crear un ciclo de comentarios para aprovisionar sistemas ascendentes.
5. Migra canalizaciones de datos
En el documento sobre canalizaciones de datos, se presentan procedimientos, patrones y tecnologías para migrar las canalizaciones de datos heredadas a Google Cloud. Con ese documento, podrás comprender qué es una canalización de datos, qué procedimientos y patrones puedes emplear, y qué opciones y tecnologías de migración están disponibles en relación con la migración mayor del almacenamiento de datos.
6. Optimiza el rendimiento
BigQuery procesa datos de manera eficiente para conjuntos de datos pequeños y a escala de petabytes. Con la ayuda de BigQuery, tus trabajos de análisis de datos deberían funcionar bien sin modificaciones en tu almacén de datos recién migrado. Si observas que, en determinadas circunstancias, el rendimiento de las consultas no satisface tus expectativas, consulta Introducción a la optimización del rendimiento de las consultas para obtener asesoramiento.
7. Verifica y valida
Al final de cada iteración, debes validar el éxito de la migración de casos prácticos, para ello, debes verificar lo siguiente:
- Los datos y el esquema se migraron por completo.
- Las prioridades de administración de datos se cumplieron y probaron.
- Se establecieron la automatización y los procedimientos de mantenimiento y supervisión.
- Las consultas se tradujeron de forma correcta.
- Las canalizaciones de datos migradas funcionan como se esperaba.
- Las aplicaciones empresariales están configuradas de forma correcta para acceder a los datos y consultas que se migraron.
Puedes comenzar con la Herramienta de validación de datos, una herramienta de CLI de código abierto de Python que compara los datos de los entornos de origen y destino para asegurarte de que coincidan. Es compatible con varios tipos de conexiones junto con la funcionalidad de validación de varios niveles.
También es una buena idea medir el impacto de la migración de casos prácticos, por ejemplo, en términos de mejorar el rendimiento, reducir los costos o habilitar nuevas oportunidades técnicas o empresariales. Luego, puedes cuantificar con mayor precisión el valor del retorno de la inversión y compararlo con tus criterios de éxito para la iteración.
Después de validar la iteración, puedes liberar el caso práctico migrado en la producción y dar a tus usuarios acceso a las aplicaciones empresariales y conjuntos de datos que se migraron.
Por último, toma notas y documenta las lecciones aprendidas en esta iteración para que puedas aplicarlas en la siguiente y acelerar la migración.
Resumen del esfuerzo de migración
Durante la migración, debes ejecutar tu almacén de datos heredado y BigQuery, como se detalla en este documento. En la arquitectura de referencia del siguiente diagrama, se resalta que ambos almacenes de datos ofrecen una funcionalidad y rutas similares: ambos pueden realizar transferencias desde los sistemas de origen, integrarse en las aplicaciones empresariales y proporcionar el acceso de usuario requerido. Es importante destacar que, en el diagrama, también se señala que los datos se sincronizan de tu almacén de datos a BigQuery. Esto permite que los casos prácticos se descarguen durante toda la duración del esfuerzo de migración.

Si suponemos que deseas realizar una migración completa de tu almacén de datos a BigQuery, el estado final de la migración será similar al siguiente:

¿Qué sigue?
Obtén más información sobre los siguientes pasos en la migración de almacenes de datos:
- Evaluación de la migración
- Descripción general de transferencia de datos y esquemas
- Canalizaciones de datos
- Traducción de SQL por lotes
- Traducción de SQL interactiva
- Seguridad y administración de los datos
- Herramienta de validación de datos
También puedes obtener información sobre cómo pasar de tecnologías de almacenamiento de datos específicas a BigQuery:
- Migrar desde Netezza
- Migra desde Oracle
- Migra desde Amazon Redshift
- Migra desde Teradata
- Migrar desde Snowflake