En este documento, se describe cómo mover trabajos de Apache Spark a Dataproc. El documento está dirigido a ingenieros y arquitectos de macrodatos. Se cubren temas como consideraciones para la migración, preparación, migración de trabajo y administración.
Descripción general
Cuando quieras mover tus cargas de trabajo de Apache Spark de un entorno local a Google Cloud, te recomendamos usar Dataproc para ejecutar clústeres de Apache Spark o Apache Hadoop. Dataproc es un servicio completamente administrado y admitido que ofrece Google Cloud. Te permite separar almacenamiento y procesamiento, lo que te ayuda a administrar tus costos y ser más flexible en el escalamiento de tus cargas de trabajo.
Si un entorno administrado de Hadoop no cumple con tus necesidades, también puedes usar una configuración diferente, como ejecutar Spark en Google Kubernetes Engine (GKE), o alquilar máquinas virtuales en Compute Engine y configurar un clúster de Hadoop o Spark tú mismo. Sin embargo, ten en cuenta que, si eliges una opción diferente a usar Dataproc, tú mismo debes administrarla y solo cuenta con asistencia de la comunidad.
Planifica la migración
Existen muchas diferencias entre ejecutar trabajos de Spark locales y ejecutarlos en los clústeres de Dataproc o Hadoop en Compute Engine. Es importante prestar atención a tu carga de trabajo y prepararte para la migración. En esta sección, describimos las consideraciones que hay que tener en cuenta y los preparativos necesarios antes de migrar los trabajos de Spark.
Identifica los tipos de trabajo y planifica los clústeres
Existen tres tipos de cargas de trabajo de Spark, como se describe en esta sección.
Trabajos por lotes programados con regularidad
Los trabajos por lotes programados con regularidad incluyen casos prácticos como ETL diarios o por hora, o canalizaciones para el entrenamiento de modelos de aprendizaje automático con Spark ML. En estos casos, te recomendamos que crees un clúster por cada lote de carga de trabajo y, luego, borres el clúster una vez que finalice el trabajo. Cuentas con la flexibilidad de configurar tu clúster porque puedes adaptar la configuración para cada carga de trabajo por separado. Los clústeres de Dataproc se facturan en incrementos por bloques de un segundo después del primer minuto. Por lo tanto, este método también es rentable, ya que permite etiquetar tus clústeres. Para obtener más información, consulta la página sobre precios de Dataproc.
Puedes implementar trabajos por lotes con plantillas de flujo de trabajo o seguir estos pasos:
Crea un clúster y espera hasta que se complete su creación. (Puedes supervisar si se creó el clúster con una llamada a la API o con un comando de gcloud). Si ejecutas tu trabajo en un clúster de Dataproc dedicado, puede que sea útil apagar la asignación dinámica y el servicio Shuffle externo. El siguiente comando de
gcloudmuestra las propiedades de configuración de Spark que se proporcionan cuando creas el clúster de Dataproc:dataproc clusters create ... \ --properties 'spark:spark.dynamicAllocation.enabled=false,spark:spark.shuffle.service.enabled=false,spark.executor.instances=10000'Envía tu trabajo al clúster. (Puedes supervisar el estado de tu trabajo mediante una llamada a la API o un comando de gcloud). Por ejemplo:
jobId=$(gcloud --quiet dataproc jobs submit pyspark \ --async \ --format='value(reference.jobId)' \ --cluster $clusterName \ --region global \ gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py) gcloud dataproc jobs describe $jobId \ --region=global \ --format='value(status.state)'Borra el clúster después de que se ejecute el trabajo con una llamada a la API o un comando de gcloud.
Trabajos de transmisión
Para los trabajos de transmisión, tienes que crear un clúster de Dataproc de larga duración y configurarlo para que se ejecute en modo de alta disponibilidad. No recomendamos usar VM interrumpibles en este caso.
Cargas de trabajo ad hoc o interactivas que envían los usuarios
Los ejemplos de cargas de trabajo ad hoc incluyen a los usuarios que escriben consultas o ejecutan trabajos de estadísticas durante el día.
Para estos casos, debes decidir si necesitas que el clúster se ejecute en modo de alta disponibilidad, si quieres usar VM interrumpibles y cómo administrarás el acceso al clúster. Puedes programar la creación del clúster y su finalización (por ejemplo, si no lo necesitas nunca durante la noche o los fines de semana), y puedes implementar un escalamiento ascendente o descendente de acuerdo con la programación.
Identifica las fuentes de datos y dependencias
Cada trabajo tiene sus propias dependencias (por ejemplo, las fuentes de datos que necesita). Además, otros equipos de tu empresa podrían depender del resultado de tus trabajos. Por lo tanto, debes identificar todas las dependencias y, luego, crear un plan de migración que incluya procedimientos para los siguientes casos:
La migración paso a paso de todas tus fuentes de datos a Google Cloud. Al principio, es útil duplicar la fuente de datos en Google Cloud para que la tengas en dos lugares
La migración trabajo por trabajo de tus cargas de trabajo de Spark a Google Cloud apenas migraron las fuentes de datos correspondientes. Como con los datos, en algún punto, tal vez tengas dos cargas de trabajo en ejecución en paralelo en tu entorno antiguo y en Google Cloud
La migración de otras cargas de trabajo que dependen de los resultados de tus cargas de trabajo de Spark. Otra posibilidad es replicar los resultados en el entorno inicial
El cierre de los trabajos de Spark en el entorno anterior después de que todos los equipos dependientes confirmen que ya no necesitan los trabajos.
Elige opciones de almacenamiento
Hay dos opciones de almacenamiento para usar con tus clústeres de Dataproc: puedes almacenar todos los datos en Cloud Storage o puedes usar discos locales o discos persistentes con los trabajadores del clúster. La opción correcta varía según el carácter de tus trabajos.
Compara Cloud Storage y HDFS
Cada nodo de un clúster de Dataproc cuenta con un conector de Cloud Storage instalado. De forma predeterminada, el conector se instala en /usr/lib/hadoop/lib. El conector implementa la interfaz del sistema de archivos de Hadoop y hace que Cloud Storage sea compatible con HDFS.
Debido a que Cloud Storage es un sistema de almacenamiento de objeto binario grande (BLOB), el conector emula a los directorios según el nombre del objeto. Puedes acceder a tus datos con el prefijo gs://, en lugar del prefijo hdfs://.
El conector de Cloud Storage, por lo general, no necesita ninguna personalización. Sin embargo, si necesitas realizar cambios, puedes seguir las instrucciones para configurar el conector. También hay una lista completa de claves de configuración disponible.
Cloud Storage es una buena opción cuando:
- Un clúster o distintos trabajos utilizarán tus datos en ORC, Parquet, Avro o cualquier otro formato y necesitas persistencia de datos si el clúster termina.
- Necesitas una capacidad de procesamiento alta y tus datos están almacenados en archivos más grandes que 128 MB.
- Necesitas durabilidad entre varias zonas para tus datos.
- Necesitas que los datos tengan alta disponibilidad, por ejemplo, cuando quieres borrar el Nombre del nodo de HDFS como un único punto de error.
El almacenamiento HDFS local es una buena opción cuando:
- Tus trabajos requieren muchas operaciones de metadatos, por ejemplo, si tienes miles de particiones y directorios, y el tamaño de cada archivo es relativamente pequeño.
- Modificas los datos HDFS con frecuencia o renombras directorios. (Los objetos de Cloud Storage son inmutables, por lo que renombrar un directorio es una operación costosa porque consiste en copiar todos los objetos a una clave nueva y, luego, borrarlos).
- Usas mucho la operación append en archivos HDFS.
Tienes cargas de trabajo que involucran una gran cantidad de E/S. Por ejemplo, tienen muchas escrituras particionadas, como en el siguiente ejemplo:
spark.read().write.partitionBy(...).parquet("gs://")Tienes cargas de trabajo de E/S que son muy sensibles a la latencia. Por ejemplo, necesitas una latencia en milisegundos de un solo dígito por operación de almacenamiento.
En general, recomendamos usar Cloud Storage como fuente de datos de inicio y final en una canalización de macrodatos. Por ejemplo, si un flujo de trabajo contiene cinco trabajos de Spark en serie, el primero recupera los datos iniciales desde Cloud Storage y, luego, escribe datos aleatorios y un resultado del trabajo intermedio en HDFS. El trabajo de Spark final escribe sus resultados en Cloud Storage.
Ajusta el tamaño de almacenamiento
El uso de Dataproc con Cloud Storage te permite reducir los requisitos del disco y ahorrar costos, ya que colocas los datos allí y no en el HDFS. Cuando almacenas tus datos en Cloud Storage, en lugar de en el HDFS local, puedes usar discos más pequeños para tu clúster. Si haces que tu clúster sea a pedido, como se mencionó antes, podrás separar almacenamiento y procesamiento, y así reducir costos de forma significativa.
Incluso si almacenas todos tus datos en Cloud Storage, tu clúster de Dataproc necesita HDFS para algunas operaciones como el control de almacenamiento y la recuperación de archivos, o la agregación de registros. También necesita espacio en el disco local que no sea de HDFS para la redistribución. Puedes reducir el tamaño del disco por trabajador si no usas demasiado el HDFS local.
A continuación, se describen algunas opciones para ajustar el tamaño del HDFS local:
- Disminuye el tamaño total del disco HDFS local mediante la disminución del tamaño del disco persistente principal para la instancia principal y los trabajadores. El disco persistente principal también contiene el volumen de inicio y las bibliotecas de sistema, por lo tanto, asigna al menos 100 GB.
- Aumenta el tamaño total del HDFS local con el aumento del tamaño del disco persistente principal para los trabajadores. Analiza esta opción en detalle: no es común tener cargas de trabajo que mejoren su rendimiento mediante el uso de HDFS con discos persistentes estándar, en comparación con el uso de Cloud Storage o HDFS local con SSD.
- Adjunta hasta ocho SSD (375 GB cada uno) a cada trabajador y usa estos discos para el HDFS. Esta es una buena opción si necesitas usar HDFS con cargas de trabajo de E/S intensivas y necesitas una latencia en milisegundos de un solo dígito. Asegúrate de usar un tipo de máquina que tenga suficientes CPU y memoria destinada al trabajador para admitir estos discos.
- Usa discos persistentes SSD (PD-SSD) para tu instancia principal o trabajadores como disco principal.
Accede a Dataproc
Acceder a Dataproc o Hadoop en Compute Engine no es como acceder a un clúster local. Tienes que determinar la configuración de seguridad y las opciones de acceso a la red.
Redes
Todas las instancias de VM de un clúster de Dataproc tienen que conectarse entre ellas a través de herramientas de redes internas y necesitan puertos UDP, ICMP y TCP abiertos. Puedes otorgar acceso a tu clúster de Dataproc desde direcciones IP externas mediante la configuración de red predeterminada o con una red de VPC. Tu clúster de Dataproc tendrá acceso a través de herramientas de redes a todos los servicios de Google Cloud (depósitos de Cloud Storage, API y demás) en cualquier opción de red que uses. Para permitir el acceso a través de herramientas de redes hacia recursos locales, o desde ellos, elige una configuración de red de VPC y establece las reglas de firewall adecuadas. Para obtener más detalles, consulta la guía Configuración de la red de un clúster de Dataproc y la sección Accede a YARN que se muestra más adelante.
Administración de identidades y accesos
Además de acceder a redes, tu clúster de Dataproc necesita permisos para acceder a los recursos. Por ejemplo, para escribir datos en un bucket de Cloud Storage, tu clúster de Dataproc debe tener acceso de escritura en el bucket. El acceso se establece con el uso de funciones. Analiza tu código de Spark y busca todos los recursos que no sean de Dataproc que el código necesita. Luego, concede las funciones correctas a la cuenta de servicio del clúster. Además, asegúrate de que los usuarios que crearán los clústeres, trabajos, operaciones y plantillas de flujo de trabajo tengan los permisos correctos.
Para obtener más detalles y prácticas recomendadas, consulta la documentación de IAM.
Verifica Spark y otras dependencias de la biblioteca
Compara tu versión de Spark y las versiones de otras bibliotecas con la lista de versiones oficial de Dataproc y busca si hay alguna biblioteca que aún no está disponible. Te recomendamos usar versiones de Spark que sean oficialmente compatibles con Dataproc.
Si necesitas agregar bibliotecas, puedes seguir estos pasos:
- Crea una imagen personalizada de un clúster de Dataproc.
- Crea secuencias de comandos de inicialización en Cloud Storage para tu clúster. Puedes usar secuencias de comandos de inicialización para instalar más dependencias, copiar objetos binarios, etcétera.
- Recompila tu código de Java o Scala y crea un paquete con todas las dependencias adicionales que no sean parte de la distribución de base como un “fat jar” con Gradle, Maven, Sbt o demás herramientas.
Ajusta el tamaño del clúster de Dataproc
En cualquier configuración del clúster, ya sea local o en la nube, el tamaño del clúster es decisivo para el rendimiento del trabajo de Spark. Un trabajo de Spark sin los recursos suficientes será lento o tendrá errores, en particular si no tiene suficiente memoria del ejecutor. Si quieres obtener consejos sobre lo que debes tener en cuenta a la hora de ajustar el tamaño del clúster de Hadoop, consulta la sección ajustar el tamaño de tu clúster de la guía de migración de Hadoop.
En las secciones siguientes, se describen algunas opciones sobre cómo ajustar el tamaño de tu clúster.
Obtén la configuración de tus trabajos actuales de Spark
Observa cómo se configuran tus trabajos de Spark actuales y asegúrate de que el clúster de Dataproc tenga el tamaño suficiente. Si pasas de un clúster compartido a varios clústeres de Dataproc (uno por cada lote de carga de trabajo), busca la configuración de YARN para cada aplicación, a modo de comprender cuántos ejecutores necesitas, la cantidad de CPU por ejecutor y la memoria total del ejecutor. Si tu clúster local tiene configuración de colas de YARN, observa qué trabajos comparten los recursos de cada cola y, luego, identifica los cuellos de botella. Esta migración es una oportunidad de quitar cualquier restricción de recursos que tengas en tu clúster local.
Elige tipos de máquinas y opciones de disco
Elige la cantidad y el tipo de VM que se adapten a las necesidades de tu carga de trabajo. Si decidiste usar HDFS local para almacenamiento, asegúrate de que las VM tengan el tipo de disco y el tamaño correctos. No olvides incluir las necesidades de recursos de los programas controladores en tus cálculos.
Cada VM tiene un límite de salida de herramientas de redes de 2 Gbps por CPU virtual. Escribir en los discos persistentes o en SSD persistentes cuenta para este límite. Por lo tanto, una VM con una cantidad muy baja de CPU virtuales podría verse regulada por este límite cuando escribe en estos discos. Es probable que esto suceda en la fase de redistribución, cuando Spark escribe datos aleatorios en el disco y mueve los datos aleatorios por la red entre los ejecutores. Los discos persistentes necesitan al menos 2 CPU virtuales para alcanzar el rendimiento máximo de escritura, y los SSD persistentes necesitan 4 CPU virtuales. Ten en cuenta que estos valores mínimos no consideran el tráfico, como la comunicación entre las VM. Además, el tamaño de cada disco afecta su pico de rendimiento.
La configuración que elijas impactará en el costo de tu clúster de Dataproc. El precio de Dataproc se suma al precio por instancia de cada VM de Compute Engine y otros recursos de Google Cloud. Si quieres obtener más información y usar la calculadora de precios de Google Cloud para obtener un cálculo estimativo de tus costos, consulta la página de precios de Dataproc.
Comparativa de rendimiento y optimización
Cuando terminas la fase de migración del trabajo, pero antes de dejas de ejecutar las cargas de trabajo de Spark en tu clúster local, compara tus trabajos de Spark y ten en cuenta algunas optimizaciones. Recuerda que puedes cambiar el tamaño de tu clúster si tu configuración no es óptima.
Dataproc Serverless para el ajuste de escala automático de Spark
Usa Dataproc Serverless para ejecutar cargas de trabajo de Spark sin aprovisionar ni administrar tu propio clúster. Especifica los parámetros de la carga de trabajo y, luego, envía la carga de trabajo al servicio de Dataproc Serverless. El servicio ejecutará la carga de trabajo en una infraestructura de procesamiento administrada y ajustará los recursos de forma automática según sea necesario. Los cargos de Dataproc Serverless se aplican solo al momento en que se ejecuta la carga de trabajo.
Realiza la migración
En esta sección, se describe cómo migrar los datos, cambiar el código del trabajo y cómo se ejecutan los trabajos.
Migrar datos
Antes de ejecutar cualquier trabajo de Spark en tu clúster de Dataproc, debes migrar tus datos a Google Cloud. Para obtener más información, consulta la Guía de migración de datos.
Migra el código de Spark
Una vez planificada tu migración a Dataproc y movidas las fuentes de datos requeridas, podrás migrar el código de trabajo. Si no hay diferencias en las versiones de Spark entre los dos clúster, y si deseas almacenar datos en Cloud Storage en lugar del HDFS local, solo necesitas cambiar el prefijo de todas las rutas de acceso de tus archivos HDFS de hdfs:// a gs://.
Si usas versiones de Spark distintas, consulta las notas de la versión de Spark, compara las dos versiones y adapta tu código de Spark en consecuencia.
Puedes copiar los archivos jar para tus aplicaciones de Spark en el bucket de Cloud Storage que está vinculado a tu clúster de Dataproc o a una carpeta de HDFS. En la siguiente sección, se explican las opciones disponibles para ejecutar trabajos de Spark.
Si decides usar plantillas de flujo de trabajo, te recomendamos que pruebes por separado cada trabajo de Spark que planeas agregar. Luego, puedes ejecutar una prueba final de la plantilla para asegurarte de que el flujo de trabajo de la plantilla sea correcto (revisa que no falten trabajos anteriores, que los resultados se almacenen en las ubicaciones correctas, etcétera).
Ejecuta los trabajos
Puedes ejecutar los trabajos de Spark de las siguientes formas:
Mediante el siguiente comando de
gcloud:gcloud dataproc jobs submit [COMMAND]
en el que:
[COMMAND]esspark,pysparkospark-sqlPuedes establecer las propiedades de Spark con la opción
--properties. Si quieres obtener más información, consulta la documentación para este comandoCon el mismo proceso que usaste antes de migrar el trabajo a Dataproc. El clúster de Dataproc debe ser accesible desde las instalaciones locales y debes usar la misma configuración
Mediante Cloud Composer. Puedes crear un entorno (un servidor Apache Airflow administrado), definir varios trabajos de Spark como un flujo de trabajo de DAG y, luego, ejecutar el flujo de trabajo completo
Para obtener más detalles, consulta la guía Enviar un trabajo.
Administra los trabajos después de la migración
Después de mover los trabajos de Spark a Google Cloud, es importante administrarlos con las herramientas y mecanismos que proporciona Google Cloud. En esta sección, se analizan los registros, la supervisión, el acceso a los clústeres, el escalamiento de los clústeres y la optimización de trabajos.
Usa la supervisión de registro y rendimiento
En Google Cloud, puedes usar Cloud Logging y Cloud Monitoring para ver y personalizar registros, y supervisar trabajos y recursos.
La mejor forma de encontrar qué causó la falla de un trabajo de Spark es mirar el resultado del controlador y los registros que generan los ejecutores de Spark.
Puedes recuperar el resultado del programa del controlador con la consola de Google Cloud o con un comando de gcloud. El resultado también se almacena en el bucket de Cloud Storage del clúster de Dataproc. Para obtener más detalles, consulta la sección sobre el resultado del controlador de trabajo en la documentación de Dataproc.
Todos los otros registros se ubican en archivos diferentes dentro de las máquinas del clúster. Es posible ver los registros de cada contenedor desde la IU web de la app de Spark (o desde el servidor de historial después de que termina el programa) en la pestaña de ejecutores. Necesitas navegar por cada contenedor de Spark para poder ver cada registro. Si escribes registros o imprimes en stdout o stderr en el código de tu aplicación, los registros se guardan con el redireccionamiento de stdout o stderr.
En un clúster de Dataproc, YARN está configurado para recopilar todos estos registros de forma predeterminada y están disponibles en Cloud Logging. Cloud Logging proporciona una vista consolidada y concisa de todos los registros, de modo que no necesitas pasar tiempo navegando entre los registros del contenedor para encontrar errores.
En la siguiente imagen, se muestra la página de Cloud Logging en la consola de Google Cloud. Puedes ver todos los registros desde tu clúster de Dataproc si seleccionas el nombre del clúster en el menú del selector. No olvide ampliar la duración en el selector de rango de tiempo.
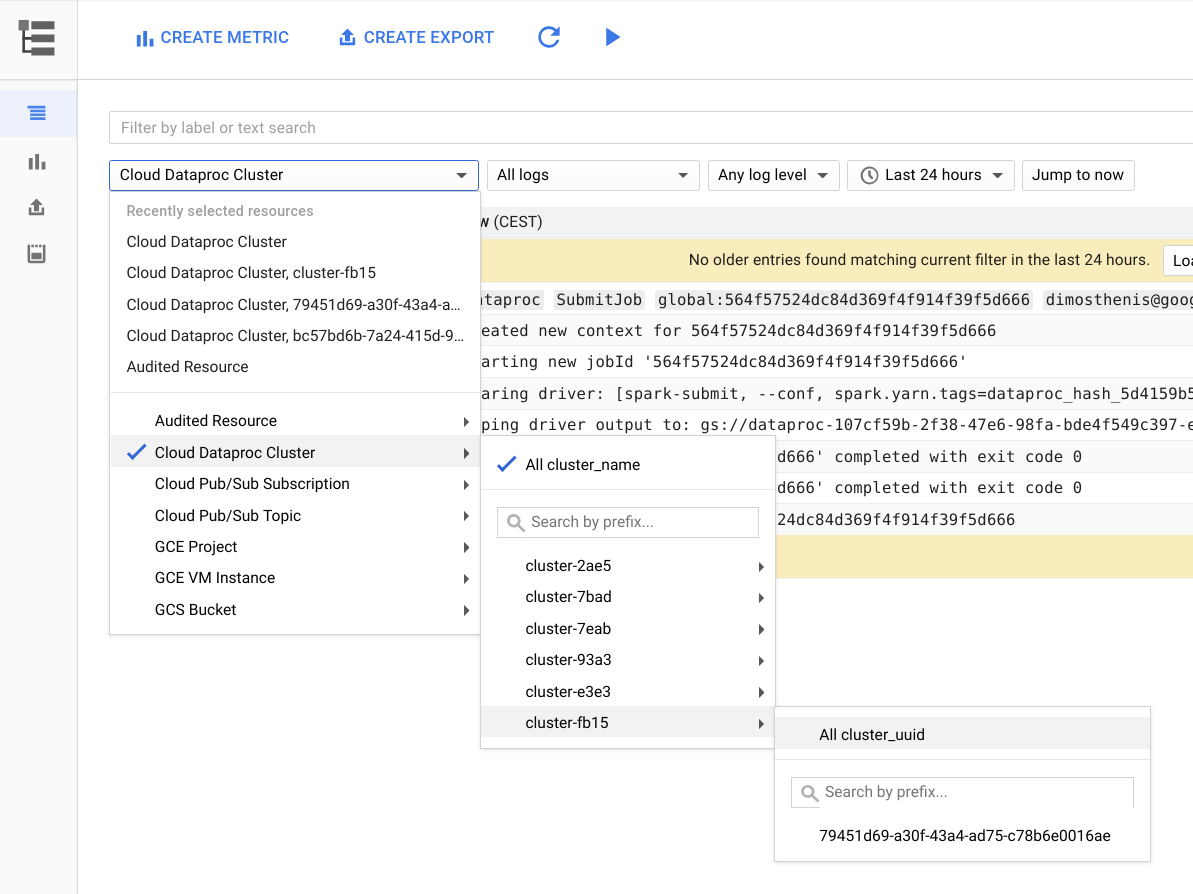
Puedes obtener registros desde una aplicación de Spark si filtras por su ID. Puedes obtener el ID de aplicación desde el resultado del controlador.
Crea y usa etiquetas
A fin de encontrar los registros más rápido, puedes crear y usar tus propias etiquetas para cada clúster o por cada trabajo de Dataproc. Por ejemplo, puedes crear una etiqueta con la clave env y el valor exploration, y usarla para tu trabajo de exploración de datos. Luego, puedes obtener registros para todas las creaciones de trabajos de exploración si filtras con label:env:exploration en Cloud Logging.
Ten en cuenta que este filtro no mostrará todos los registros para este trabajo, sino, solo los registros de creación de recursos.
Establece el nivel de registro
Puedes establecer el nivel de registro del controlador con el siguiente comando de gcloud:
gcloud dataproc jobs submit hadoop --driver-log-levels
Establece el nivel de registro para el resto de la aplicación desde el contexto de Spark. Por ejemplo:
spark.sparkContext.setLogLevel("DEBUG")
Supervisa trabajos
Cloud Monitoring puede supervisar la CPU, el disco, el uso de red y los recursos de YARN del clúster. Puedes crear un panel personalizado a fin de obtener gráficos actualizados para estas y otras métricas. Dataproc se ejecuta por encima de Compute Engine. Si quieres visualizar el uso de CPU, E/S del disco o las métricas de las herramientas de redes en un gráfico, tienes que seleccionar una instancia de VM de Compute Engine como el tipo de recurso y, luego, filtrar por el nombre del clúster. En el siguiente diagrama, se muestra un ejemplo del resultado.
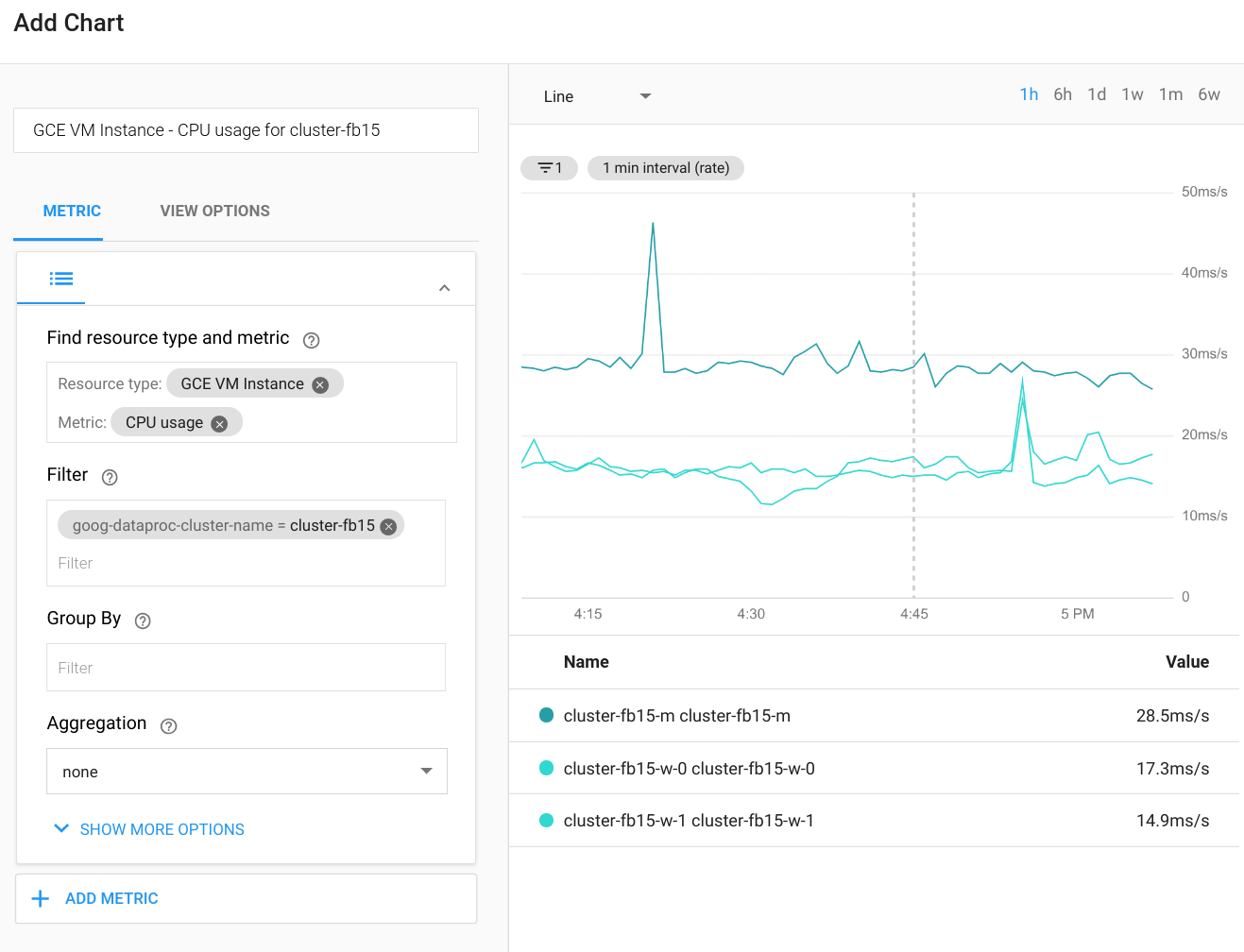
Para ver las métricas de las consultas, trabajos, etapas o tareas de Spark, conéctate a la IU web de la aplicación de Spark. En la próxima sección, se explica cómo hacerlo. Para obtener detalles sobre cómo crear métricas personalizadas, consulta la guía Métricas personalizadas del agente.
Accede a YARN
Puedes acceder a la interfaz web de administrador de recursos de YARN por fuera del clúster de Dataproc mediante la configuración de un túnel SSH. Es preferible usar el proxy SOCKS ligero en vez de la redirección de puertos local porque así se facilita la navegación por la interfaz web.
Las siguientes URL son útiles para acceder a YARN:
Administrador de recursos de YARN:
http://[MASTER_HOST_NAME]:8088Servidor de historial de Spark:
http://[MASTER_HOST_NAME]:18080
Si el clúster de Dataproc solo tiene direcciones IP internas, te puedes conectar a través de una conexión de VPN o a través de un Host de bastión. Para obtener más información, consulta Elige una opción de conexión para las VMs solo para uso interno.
Escala y cambia el tamaño de los clústeres de Dataproc
El clúster de Dataproc se puede escalar si se aumenta o disminuye la cantidad de trabajadores principales o secundarios (interrumpibles). Dataproc también admite el retiro de servicio ordenado.
Varios factores afectan al escalamiento descendente en Spark. Ten en cuenta las siguientes cuestiones:
Usar
ExternalShuffleServiceno es recomendable, en particular, si realizas un escalamiento descendente del clúster de forma periódica. La redistribución usa los resultados que se escribieron en el disco local del trabajador después de que se ejecutó la fase de procesamiento. Por lo tanto, el nodo no se puede quitar, incluso si los recursos de procesamiento ya no se consumen.Spark almacena en caché datos en memoria (tanto los RDD como los conjuntos de datos) y los ejecutores que se usan para almacenar en caché nunca salen. Como resultado, si se usa un trabajador para almacenar en caché, nunca se retirará de servicio ordenado. Si se quitan los trabajadores a la fuerza, esto influiría en el rendimiento general, ya que los datos almacenados en caché se perderían.
La transmisión de Spark tiene la asignación dinámica inhabilitada de modo predeterminado, y la clave de configuración que establece este comportamiento no está documentada. (Puedes seguir el debate sobre el comportamiento de la asignación dinámica en una conversación sobre problemas de Spark). Si usas la transmisión o la transmisión estructurada de Spark, también debes inhabilitar la asignación dinámica de forma explícita, como se comentó antes en Identifica los tipos de trabajo y planifica los clústeres.
En general, recomendamos que evites el escalamiento descendente de un clúster de Dataproc si ejecutas cargas de trabajo por lotes o transmisión.
Optimiza el rendimiento
En esta sección, se analizan los métodos para obtener un mejor rendimiento y reducir costos mientras se ejecutan trabajos de Spark.
Administra los tamaños de archivos de Cloud Storage
Para obtener un rendimiento óptimo, divide tus datos en Cloud Storage en archivos con tamaños de 128 MB a 1 GB. El uso de muchos archivos pequeños puede crear un cuello de botella. Si tienes muchos archivos pequeños, considera copiar los archivos para procesarlos en el HDFS local y, luego, volver a copiar los resultados.
Cambia a discos SSD
Si realizas muchas operaciones de redistribución o escrituras particionadas, cambia a SSD para aumentar el rendimiento.
Coloca las VM en la misma zona
A modo de reducir los costos de herramientas de redes y aumentar el rendimiento, usa la misma ubicación regional para tus depósitos de Cloud Storage y tus clústeres de Dataproc.
De forma predeterminada, cuando usas extremos de Dataproc globales o regionales, las VM de tu clúster se ubicarán en la misma zona (o en otra zona que tenga la capacidad suficiente en la misma región) cuando se crea el clúster. También puedes especificar la zona cuando se crea el clúster.
Usa VM interrumpibles
El clúster de Dataproc puede usar instancias de VM interrumpibles como trabajadores. Esto da como resultado menores costos de procesamiento por hora para tus cargas de trabajo no críticas, comparado con el uso de instancias normales. Sin embargo, hay algunos factores a tener en cuenta cuando usas VM interrumpibles:
- Las VM interrumpibles no se pueden usar para almacenamiento de HDFS.
- De forma predeterminada, las VM interrumpibles se crean con un disco de arranque más pequeño y es posible que desees anular esta configuración si ejecutas cargas de trabajo pesadas y aleatorias. Para obtener más detalles, consulta la página sobre VM interrumpibles en la documentación de Dataproc.
- No recomendamos hacer que más de la mitad del total de tus trabajadores sean interrumpibles.
Cuando usas VM interrumpibles, recomendamos que ajustes la configuración de tu clúster para que sea más tolerante a los errores de las tareas, porque las VM pueden tener menor disponibilidad. Por ejemplo, establece una configuración como la siguiente en YARN:
yarn.resourcemanager.am.max-attempts mapreduce.map.maxattempts mapreduce.reduce.maxattempts spark.task.maxFailures spark.stage.maxConsecutiveAttempts
Puedes agregar o quitar VM interrumpibles con facilidad desde tu clúster. Para obtener más detalles, consulta VM interrumpibles.
¿Qué sigue?
- Consulta la guía sobre cómo migrar la infraestructura de Hadoop local a Google Cloud.
- Consulta nuestra descripción de vida de un trabajo de Dataproc.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.