O Dataproc e o Google Cloud contêm vários atributos que podem ajudar a proteger seus dados. Neste guia, você verá como a segurança do Hadoop funciona e como ela afeta o Google Cloud, fornecendo orientações sobre a arquitetura da segurança ao realizar a implantação no Google Cloud.
Visão geral
O mecanismo e o modelo de segurança típicos para uma implantação local do Hadoop são diferentes dos fornecidos pela nuvem. Entender a segurança no Hadoop pode ajudar a arquitetar melhor a segurança ao realizar a implantação no Google Cloud.
Há duas maneiras de implantar o Hadoop no Google Cloud: como clusters gerenciados pelo Google (Dataproc) ou como clusters gerenciados pelo usuário (Hadoop no Compute Engine). A maior parte do conteúdo e da orientação técnica neste guia se aplica às duas maneiras de implantação. Aqui, o termo Dataproc/Hadoop é usado ao se referir a conceitos ou procedimentos que se aplicam a qualquer tipo de implantação. No guia, são apontados os poucos casos em que a implantação no Dataproc difere da implantação no Hadoop no Compute Engine.
Segurança típica do Hadoop no local
O diagrama a seguir mostra uma infraestrutura típica do Hadoop local e como ela é protegida. Observe como os componentes básicos do Hadoop interagem entre si e com os sistemas de gerenciamento de usuários.
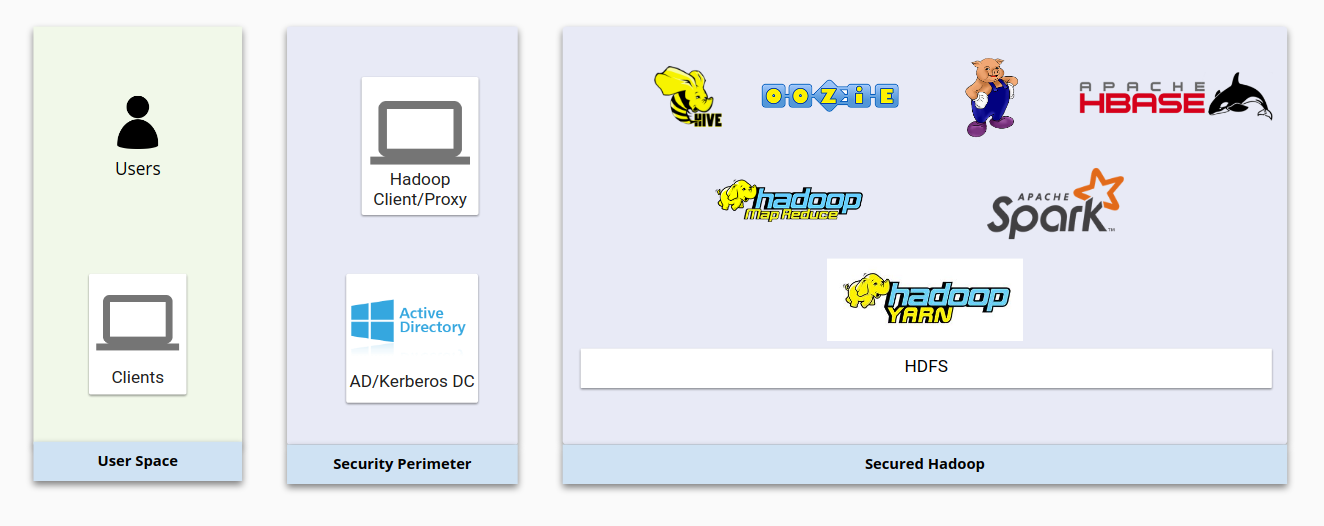
No geral, a segurança do Hadoop é baseada nestes quatro pilares:
- a autenticação é fornecida por meio do Kerberos integrado ao LDAP ou ao Active Directory;
- a autorização é fornecida por meio do HDFS e de produtos de segurança, como o Apache Sentry ou o Apache Ranger, que garantem que os usuários tenham acesso adequado aos recursos do Hadoop;
- a criptografia é fornecida por meio de criptografia de rede e criptografia HDFS, que juntas protegem os dados em trânsito e em repouso;
- a auditoria é fornecida por produtos de um fornecedor, como o Cloudera Navigator.
Da perspectiva da conta do usuário, o Hadoop tem uma estrutura de usuário e um grupo próprios para gerenciar identidades e executar daemons. Os daemons Hadoop HDFS e YARN, por exemplo, são executados como usuários hdfs e yarn do Unix, conforme explicado em Hadoop no modo seguro (em inglês).
Os usuários do Hadoop geralmente são mapeados de usuários do sistema Linux ou usuários do Active Directory/LDAP. Usuários e grupos do Active Directory são sincronizados por ferramentas como Centrify ou RedHat SSSD.
Autenticação do Hadoop no local
Um sistema seguro requer que usuários e serviços provem para o sistema que são eles mesmos. O modo seguro do Hadoop usa o Kerberos para autenticação. A maioria dos componentes do Hadoop é projetada para usar o Kerberos para autenticação. O Kerberos geralmente é implementado em sistemas de autenticação empresarial, como o Active Directory ou sistemas compatíveis com LDAP.
Principais do Kerberos
Um usuário no Kerberos é chamado de principal. Em uma implantação do Hadoop, há principais de usuários e principais de serviços. Os principais de usuários geralmente são sincronizados entre o Active Directory ou outros sistemas de gerenciamento de usuários e um centro de distribuição de chaves (KDC, na sigla em inglês). Um principal de usuário representa um usuário humano. Um principal de serviço é exclusivo de um serviço por servidor, portanto, cada serviço em cada servidor tem um único principal para representá-lo.
Arquivos keytab
Um arquivo keytab contém os principais do Kerberos e as chaves deles. Usuários e serviços podem usar keytabs para autenticar os serviços do Hadoop sem usar ferramentas interativas e inserir senhas. O Hadoop cria os principais de cada serviço em cada nó. Esses principais são armazenados em arquivos keytab nos nós do Hadoop.
SPNEGO
Se você estiver acessando um cluster do Kerberos usando um navegador da Web, o navegador precisa saber como transmitir as chaves do Kerberos. É aí que entra o Mecanismo de negociação GSS-API simples e protegido (SPNEGO, na sigla em inglês) [página em inglês], que fornece uma maneira de usar o Kerberos em aplicativos da Web.
Integração
O Hadoop se integra ao Kerberos não apenas para autenticação do usuário, mas também para autenticação de serviços. Qualquer serviço do Hadoop em qualquer nó terá um principal próprio do Kerberos, que ele usa para se autenticar. Os serviços geralmente têm arquivos keytab armazenados no servidor que contém uma senha aleatória.
Para interagir com os serviços, os usuários humanos precisam conseguir o tíquete Kerberos por meio do comando kinit, do Centrify ou do SSSD.
Autorização do Hadoop no local
Depois que uma identidade é validada, o sistema de autorização verifica o tipo de acesso que o usuário ou serviço tem. No Hadoop, alguns projetos de código aberto, como o Apache Sentry e o Apache Ranger, são usados para fornecer autorização.
Apache Sentry e Apache Ranger
O Apache Sentry e o Apache Ranger são mecanismos comuns de autorização usados em clusters do Hadoop. Componentes no Hadoop implementam os próprios plug-ins no Sentry ou no Ranger para especificar como se comportar quando essas ferramentas confirmam ou negam acesso a uma identidade. O Sentry e o Ranger dependem de sistemas de autenticação como o Kerberos, o LDAP ou o AD. O mecanismo de mapeamento de grupo do Hadoop garante que o Sentry ou o Ranger vejam o mesmo mapeamento de grupo que os outros componentes do ecossistema do Hadoop.
ACL e permissões do HDFS
O HDFS usa um sistema de permissões do tipo POSIX com uma lista de controle de acesso (ACL) para determinar se os usuários têm acesso aos arquivos. Cada arquivo e diretório está associado a um proprietário e um grupo. A estrutura tem uma pasta raiz que pertence a um superusuário. Diferentes níveis da estrutura podem ter criptografias distintas e diferentes propriedades, permissões e ACL estendida (facl).
Conforme mostrado no diagrama a seguir, as permissões geralmente são concedidas no nível do diretório para grupos específicos com base nas necessidades de acesso. Os padrões de acesso são identificados como papéis diferentes e são associados a grupos do Active Directory. Em geral, os objetos pertencentes a um único conjunto de dados residem na camada que tem permissões para um grupo específico, com diretórios diferentes para diferentes categorias de dados.
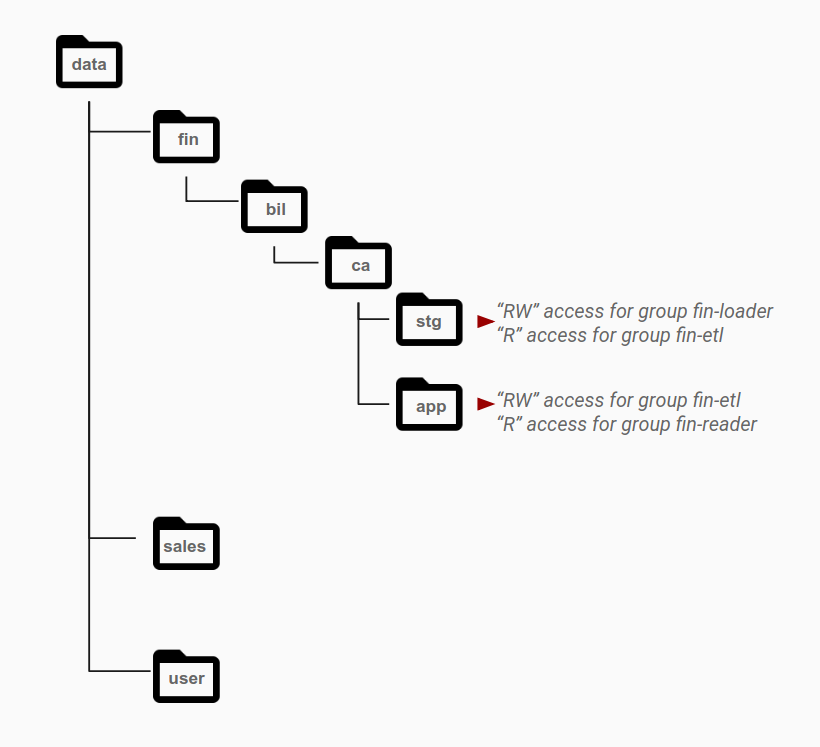
Por exemplo, o diretório stg é a área de preparo para dados financeiros. A pasta stg tem permissões de leitura e gravação para o grupo fin-loader. A partir dessa área preparo, outro grupo de contas do aplicativo, fin-etl, que representa pipelines de ETL, tem acesso somente leitura a esse diretório. Pipelines de ETL processam dados e os salvam no diretório app a ser exibido. Para ativar esse padrão de acesso, o diretório app tem acesso de leitura/gravação para o grupo fin-etl (que é a identidade usada para gravar os dados de ETL) e acesso somente leitura para o grupo fin-reader (que consome os dados resultantes).
Criptografia do Hadoop no local
O Hadoop fornece maneiras de criptografar dados em repouso e em trânsito. Para criptografar dados em repouso, você pode criptografar o HDFS usando criptografia de chaves baseada em Java ou soluções de criptografia de um fornecedor. O HDFS é compatível com zonas de criptografia para fornecer a capacidade de criptografar arquivos diferentes usando chaves diferentes. Cada zona de criptografia é associada a uma única chave que é especificada quando a zona é criada.
Cada arquivo dentro de uma zona de criptografia tem uma chave de criptografia de dados (DEK, na sigla em inglês) exclusiva. As DEKs nunca são tratadas diretamente pelo HDFS. Em vez disso, o HDFS manipula somente uma chave de criptografia de dados criptografada (EDEK, na sigla em inglês). Os clientes descriptografam uma EDEK e, em seguida, usam a DEK subsequente para ler e gravar dados. Os nós de dados do HDFS simplesmente veem um fluxo de bytes criptografados.
O trânsito de dados entre os nós do Hadoop pode ser criptografado usando o protocolo TLS (Transport Layer Security). O TLS fornece criptografia e autenticação para a comunicação entre dois componentes do Hadoop. Normalmente, o Hadoop usaria certificados internos assinados pela CA para o TLS entre os componentes.
Auditoria do Hadoop no local
Uma parte importante da segurança é a auditoria. Ela ajuda a encontrar atividades suspeitas e fornece um registro de quem teve acesso aos recursos. O Cloudera Navigator e outras ferramentas de terceiros geralmente são usadas para gerenciamento de dados, como o acompanhamento de auditoria no Hadoop. Essas ferramentas fornecem visibilidade e controle sobre os dados armazenados no Hadoop e sobre a computação realizada nesses dados. A auditoria de dados pode capturar um registro completo e imutável de toda a atividade dentro de um sistema.
Hadoop no Google Cloud
Em um ambiente tradicional do Hadoop no local, os quatro pilares da segurança do Hadoop (autenticação, autorização, criptografia e auditoria) são integrados e gerenciados por componentes diferentes. No Google Cloud, eles são gerenciados por diferentes componentes do Google Cloud externos ao Dataproc e ao Hadoop no Compute Engine.
É possível gerenciar recursos do Google Cloud usando o Console do Google Cloud, que é uma interface baseada na Web. Também é possível usar a Google Cloud CLI, que pode ser mais rápida e prática se você não tiver problemas em trabalhar com a linha de comando. Você pode executar comandos da gcloud se instalar o CLI gcloud no seu computador local ou com uma instância do Cloud Shell.
Autenticação do Google Cloud no Hadoop
Há dois tipos de identidades do Google no Google Cloud: contas de serviço e contas de usuário. A maioria das APIs do Google exige autenticação com uma identidade do Google. Um número limitado de APIs do Google Cloud funcionará sem autenticação (como usar chaves de API), mas recomenda-se o uso de todas as APIs com autenticação de conta de serviço.
Contas de serviço usam chaves privadas para estabelecer a identidade. As contas de usuários usam o protocolo OAUTH 2.0 para autenticar usuários finais. Para mais informações, consulte a Visão geral da autenticação.
Autorização do Google Cloud no Hadoop
O Google Cloud oferece várias maneiras de especificar as permissões que uma identidade autenticada tem para um conjunto de recursos.
IAM
O Google Cloud oferece gerenciamento de identidade e acesso (IAM, na sigla em inglês), que permite gerenciar o controle de acesso definindo quais usuários (participantes) têm que tipo de acesso (papel) a que recurso.
Com o IAM, é possível conceder acesso aos recursos do Google Cloud e impedir o acesso indesejado a outros recursos. Com o IAM, você pode implementar o princípio de segurança do menor privilégio, concedendo apenas o acesso mínimo necessário aos recursos.
Contas de serviço
Conta de serviço é um tipo especial de Conta do Google que pertence ao seu aplicativo ou a uma máquina virtual (VM, na sigla em inglês) e não a um usuário final individual. Os aplicativos podem usar as credenciais da conta de serviço para se autenticarem com outras APIs do Cloud. Além disso, é possível criar regras de firewall que permitam ou neguem o tráfego de e para instâncias com base na conta de serviço atribuída a cada uma dessas instâncias.
Os clusters do Dataproc são criados com base nas VMs do Compute Engine. Se a atribuição de uma conta de serviço personalizada ocorrer durante a criação de um cluster do Dataproc, ela será aplicada a todas as VMs no cluster. Isso dá ao cluster acesso detalhado e controle dos recursos do Google Cloud. Se você não especificar uma conta de serviço, as VMs do Dataproc usarão a conta de serviço padrão do Compute Engine gerenciada pelo Google. Por padrão, essa conta tem o papel de editor de projeto amplo, que oferece uma ampla gama de permissões. Não é recomendado usar a conta de serviço padrão para criar um cluster do Dataproc em um ambiente de produção.
Permissões de conta de serviço
Ao atribuir uma conta de serviço personalizada a um cluster do Dataproc/Hadoop, o nível de acesso dessa conta é determinado pela combinação de escopos de acesso concedidos às instâncias de VM do cluster e dos papéis do IAM concedidos à conta de serviço. Para configurar uma instância usando sua conta de serviço personalizada, é necessário configurar os escopos de acesso e os papéis do IAM. Essencialmente, esses mecanismos interagem desta maneira:
- os escopos de acesso autorizam o acesso de uma instância;
- o IAM restringe esse acesso aos papéis concedidos à conta de serviço que a instância usa;
- As permissões na interseção dos escopos de acesso e dos papéis do IAM são as permissões finais que a instância tem.
Ao criar um cluster do Dataproc ou uma instância do Compute Engine no Console do Google Cloud, selecione o escopo de acesso da instância:
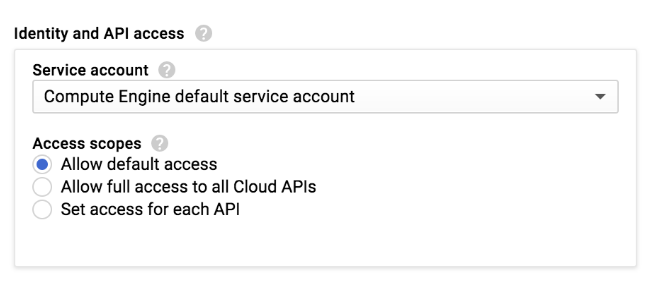
Um cluster do Dataproc ou uma instância do Compute Engine tem um conjunto de escopos de acesso definidos para uso com a configuração Permitir acesso padrão:
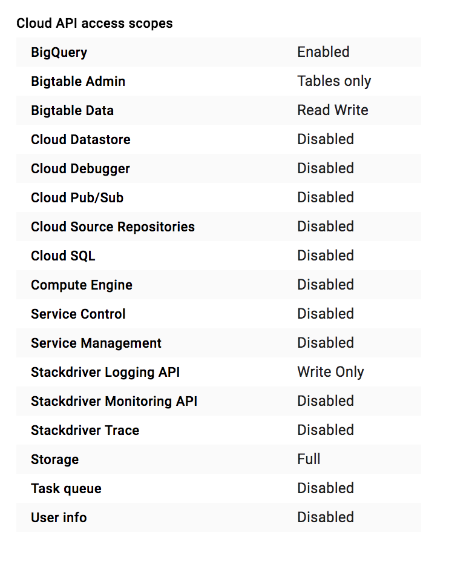
Existem muitos escopos de acesso que você pode escolher. Recomendamos que, ao criar um novo cluster ou instância de
VM, você defina Permitir acesso completo a todas as APIs do Cloud (no Console) ou
o escopo de acesso https://www.googleapis.com/auth/cloud-platform (se você usar a
Google Cloud CLI). Esses escopos autorizam o acesso a todos os serviços do Google Cloud. Depois de definir o escopo, recomendamos que você limite esse acesso atribuindo os papéis de IAM à conta de serviço do cluster.
Essa conta não pode executar ações fora desses papéis, mesmo com o escopo de acesso do Google Cloud. Para mais detalhes, consulte a documentação de permissões da conta de serviço.
Comparação entre o IAM, o Apache Sentry e o Apache Ranger
O IAM desempenha um papel semelhante aos do Apache Sentry e do Apache Ranger. O IAM define o acesso por meio de papéis. O acesso a outros componentes do Google Cloud é definido nesses papéis e associado a contas de serviço. Isso significa que todas as instâncias que usam a mesma conta de serviço têm o mesmo acesso a outros recursos do Google Cloud. Quem tiver acesso a essas instâncias terá o mesmo acesso aos recursos do Google Cloud que a conta de serviço.
Clusters do Dataproc e instâncias do Compute Engine não têm um mecanismo para mapear usuários e grupos do Google para usuários e grupos do Linux. No entanto, é possível criar usuários e grupos do Linux. No cluster do Dataproc ou nas VMs do Compute Engine, as permissões do HDFS e o mapeamento de usuários e grupos do Hadoop ainda funcionam. Esse mapeamento pode ser usado para restringir o acesso ao HDFS ou para impor a alocação de recursos usando uma fila YARN.
Quando os aplicativos em um cluster do Dataproc ou em uma VM do Compute Engine precisam acessar recursos externos, como o Cloud Storage ou o BigQuery, eles são autenticados como a identidade da conta de serviço atribuída às VMs no cluster. Depois, use o IAM para conceder à conta de serviço personalizada do cluster o nível mínimo de acesso necessário ao aplicativo.
Permissões do Cloud Storage
O Dataproc usa o Cloud Storage como sistema de armazenamento. Além disso, ele fornece um sistema HDFS local, que não estará disponível se o cluster do Dataproc for excluído. Se o aplicativo não depende estritamente do HDFS, é melhor usar o Cloud Storage para aproveitar totalmente o Google Cloud.
O Cloud Storage não tem hierarquias de armazenamento. A estrutura de diretórios simula a estrutura de um sistema de arquivos. Ele também não tem permissões semelhantes a POSIX. O controle de acesso por contas de usuário e contas de serviço do IAM pode ser definido no nível do bucket. Ele não impõe permissões com base em usuários do Linux.
Criptografia do Google Cloud no Hadoop
Com algumas poucas exceções, os serviços do Google Cloud criptografam o conteúdo do cliente em repouso e em trânsito usando vários métodos de criptografia. O processo de criptografia é automático. O cliente não precisa realizar nenhuma ação.
Por exemplo, todo novo armazenamento em discos permanentes é criptografado de acordo com o Padrão avançado de criptografia de 256 bits (AES-256), e cada chave de criptografia também é criptografada com um conjunto de chaves raiz (mestre) com rotação regular. O Google Cloud utiliza as mesmas políticas de gerenciamento de criptografia e de chave, bibliotecas criptográficas e raiz de confiança usados para muitos serviços de produção do Google, inclusive o Gmail e os dados corporativos do próprio Google.
Como a criptografia é um atributo padrão do Google Cloud (ao contrário da maioria das implementações do Hadoop local), não é preciso se preocupar com a implementação dela, a menos que queira usar sua própria chave de criptografia. O Google Cloud também oferece uma solução de chaves de criptografia gerenciada pelo cliente e uma solução de chaves de criptografia fornecida pelo cliente. É possível que você gerencie as chaves de criptografia ou as armazene no local.
Para mais detalhes, consulte criptografia em repouso e criptografia em trânsito.
Auditoria do Google Cloud no Hadoop
Os registros de auditoria do Cloud podem manter alguns tipos de registros para cada projeto e organização. Os serviços do Google Cloud gravam entradas de registro de auditoria nesses registros para ajudar a responder às perguntas sobre quem fez o quê, onde e quando nos projetos do Google Cloud.
Para mais informações sobre registros de auditoria e serviços que gravam registros de auditoria, consulte a documentação do Cloud Audit Logging.
Processo de migração
Para ajudar a executar uma operação segura e eficiente do Hadoop no Google Cloud, siga o processo descrito nesta seção.
Nesta seção, presume-se que o ambiente do Google Cloud esteja configurado. Isso inclui a criação de usuários e grupos no Google Workspace. Eles são gerenciados manualmente ou sincronizados com o Active Directory, e tudo foi configurado para que o Google Cloud funcione totalmente em termos de autenticação de usuários.
Determine quem gerenciará as identidades
A maioria dos clientes do Google usa o Cloud Identity para gerenciar identidades. Porém, alguns gerenciam identidades corporativas independentemente das identidades do Google Cloud. Nesse caso, as permissões POSIX e SSH determinam o acesso do usuário final aos recursos da nuvem.
Se você tiver um sistema de identidade independente, comece criando chaves de conta de serviço do Google Cloud e fazendo o download delas. Em seguida, vincule o modelo de segurança POSIX e SSH local ao modelo do Google Cloud. Para isso, basta conceder permissões de acesso no formato POSIX aos arquivos da chave de conta de serviço salva. Permita ou negue o acesso de identidades locais a esses arquivos.
Se você seguir esse caminho, a capacidade de realizar auditorias estará nas mãos dos seus próprios sistemas de gerenciamento de identidades. Para fornecer uma trilha de auditoria, é possível usar os registros SSH (que armazenam os arquivos-chave da conta de serviço) dos logins de usuários nos nós de borda ou optar por um mecanismo de keystore mais sólido e explícito para buscar credenciais de conta de serviço dos usuários. Nesse caso, a "representação da conta de serviço" é registrada em auditoria na camada de keystore.
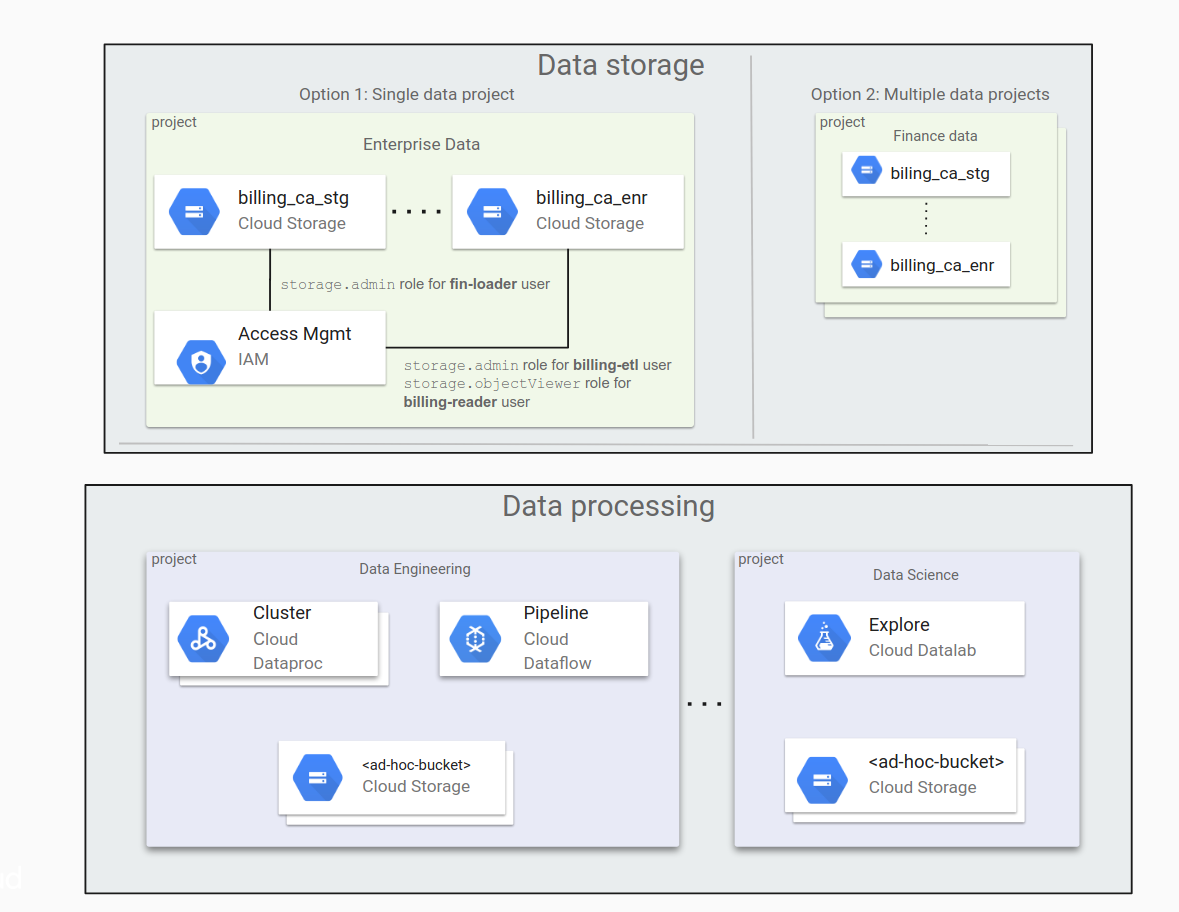
Determine se é melhor usar um único projeto de dados ou vários projetos de dados
Se sua organização tiver muitos dados, isso significa que é preciso dividir os dados em diferentes buckets do Cloud Storage. Também é necessário pensar em como distribuir esses buckets de dados entre os projetos. Talvez você queira migrar uma pequena quantidade de dados ao começar a usar o Google Cloud, transferindo mais e mais dados com o passar do tempo conforme as cargas de trabalho e os aplicativos são transferidos.
Pode parecer conveniente deixar todos os seus buckets de dados em um projeto, mas essa geralmente não é uma boa abordagem. Para gerenciar o acesso aos dados, você usa uma estrutura de diretório simplificada com papéis do IAM para os buckets. Isso pode ser difícil de administrar à medida que o número de buckets aumenta.
Uma alternativa é armazenar dados em vários projetos dedicados a diferentes organizações: um projeto para o departamento financeiro, outro para o grupo jurídico e assim por diante. Nesse caso, cada grupo gerencia as próprias permissões de maneira independente.
Durante o processamento de dados, pode ser necessário acessar ou criar buckets ad hoc. O processamento pode ser dividido entre limites de confiança, como cientistas de dados acessando dados que são produzidos por um processo que eles não possuem.
O diagrama a seguir mostra uma organização típica de dados no Cloud Storage em um único projeto de dados e em vários projetos de dados.
Veja os principais pontos a considerar ao decidir qual abordagem é melhor para sua organização.
Com um único projeto de dados:
- é fácil gerenciar todos os buckets, desde que o número de buckets seja pequeno;
- a concessão de permissão é feita principalmente por membros do grupo de administradores.
Com vários projetos de dados:
- é mais fácil delegar responsabilidades de gerenciamento aos proprietários do projeto;
- essa abordagem é útil para organizações que têm diferentes processos de concessão de permissão. Por exemplo, o processo de concessão de permissão em projetos do departamento de marketing pode ser diferente daquele do departamento jurídico.
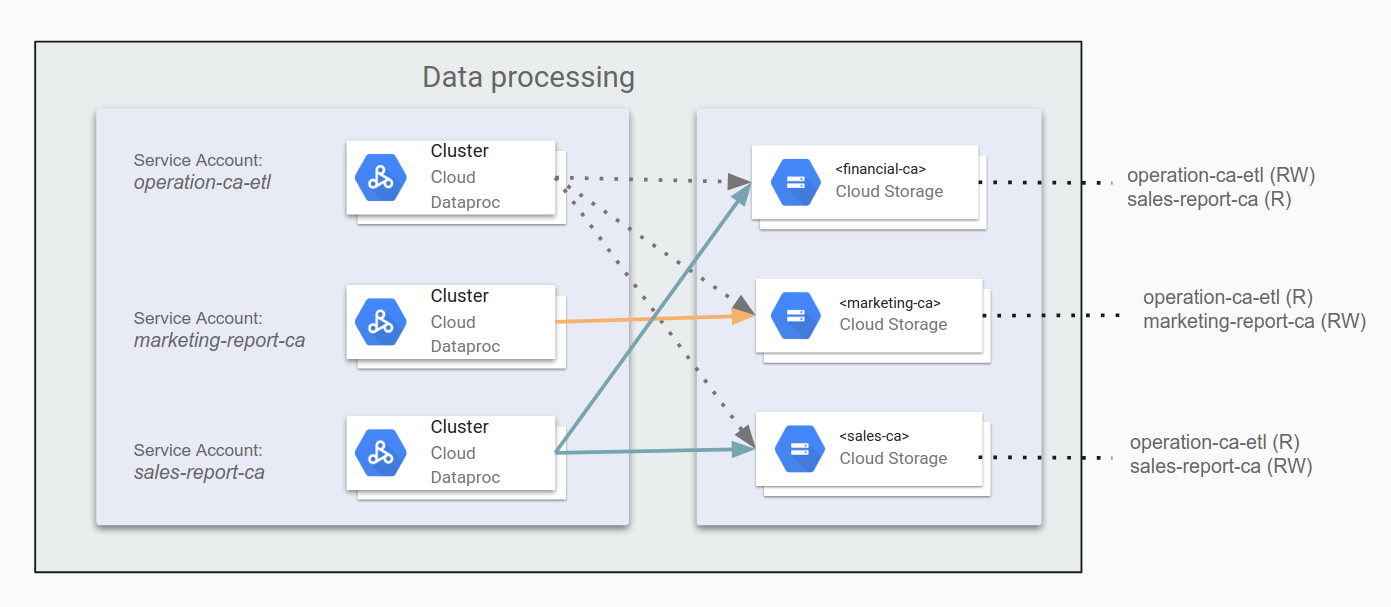
Identifique aplicativos e crie contas de serviço
Quando os clusters do Dataproc/Hadoop interagem com outros recursos do Google Cloud, como o Cloud Storage, é preciso identificar todos os aplicativos que serão executados no Dataproc/Hadoop e o acesso de que precisarão. Por exemplo, imagine que há um job de ETL que preenche dados financeiros referentes à Califórnia no bucket financial-ca. Ele precisará de acesso de leitura e gravação ao bucket. Depois de identificar os aplicativos que usarão o Hadoop, será possível criar contas de serviço para cada um deles.
Lembre-se de que esse acesso não afeta os usuários do Linux dentro do cluster do Dataproc ou no Hadoop no Compute Engine.
Para mais informações sobre contas de serviço, consulte Como criar e gerenciar contas de serviço.
Conceda permissões para contas de serviço
Quando você sabe qual acesso cada aplicativo precisa ter para diferentes buckets do Cloud Storage, é possível definir essas permissões nas contas de serviço de aplicativos relevantes. Se os aplicativos também precisarem acessar outros componentes do Google Cloud, como o BigQuery ou o Bigtable, será possível conceder permissões a esses componentes usando contas de serviço.
Por exemplo, é possível especificar operation-ca-etl como um aplicativo de ETL para gerar relatórios de operação reunindo dados de marketing e de vendas da Califórnia, concedendo permissão para gravar relatórios no bucket de dados do departamento financeiro. Em seguida, é possível configurar os aplicativos marketing-report-ca e sales-report-ca para que cada um tenha acesso de leitura e gravação aos respectivos departamentos. O diagrama a seguir ilustra essa configuração.
Siga o princípio do privilégio mínimo. Ele especifica que você concede a cada usuário ou conta de serviço apenas as permissões mínimas necessárias para executar as tarefas. As permissões padrão no Google Cloud são otimizadas para facilitar o uso e reduzir o tempo de configuração. Para criar infraestruturas do Hadoop que provavelmente serão aprovadas em análises de segurança e conformidade, crie permissões mais restritivas. Investir esforços desde o início e documentar essas estratégias não só ajuda a fornecer um canal seguro e compatível, como também ajuda na hora de analisar a arquitetura com equipes de segurança e conformidade.
Crie clusters
Depois de planejar e configurar o acesso, é possível criar clusters do Dataproc ou o Hadoop no Compute Engine com as contas de serviço criadas. Cada cluster terá acesso a outros componentes do Google Cloud com base nas permissões concedidas a essa conta de serviço. Forneça o escopo ou escopos de acesso ao Google Cloud e ajuste-os com o acesso da conta de serviço. Se ocorrer algum problema de acesso, especialmente para o Hadoop no Compute Engine, verifique essas permissões.
Para criar um cluster do Dataproc com uma conta de serviço específica, use este comando gcloud:
gcloud dataproc clusters create [CLUSTER_NAME] \
--service-account=[SERVICE_ACCOUNT_NAME]@[PROJECT+_ID].iam.gserviceaccount.comn \
--scopes=scope[, ...]
É melhor evitar o uso da conta de serviço padrão do Compute Engine pelos seguintes motivos:
- Se vários clusters e VMs do Compute Engine usarem a conta de serviço padrão do Compute Engine, a auditoria será difícil.
- A configuração do projeto para a conta de serviço padrão do Compute Engine pode variar, o que significa que ela pode ter mais privilégios do que o cluster precisa.
- As alterações na conta de serviço padrão do Compute Engine podem afetar ou até mesmo causar interrupções não intencionais nos seus clusters e nos aplicativos executados neles.
Avalie definir as permissões de IAM para cada cluster
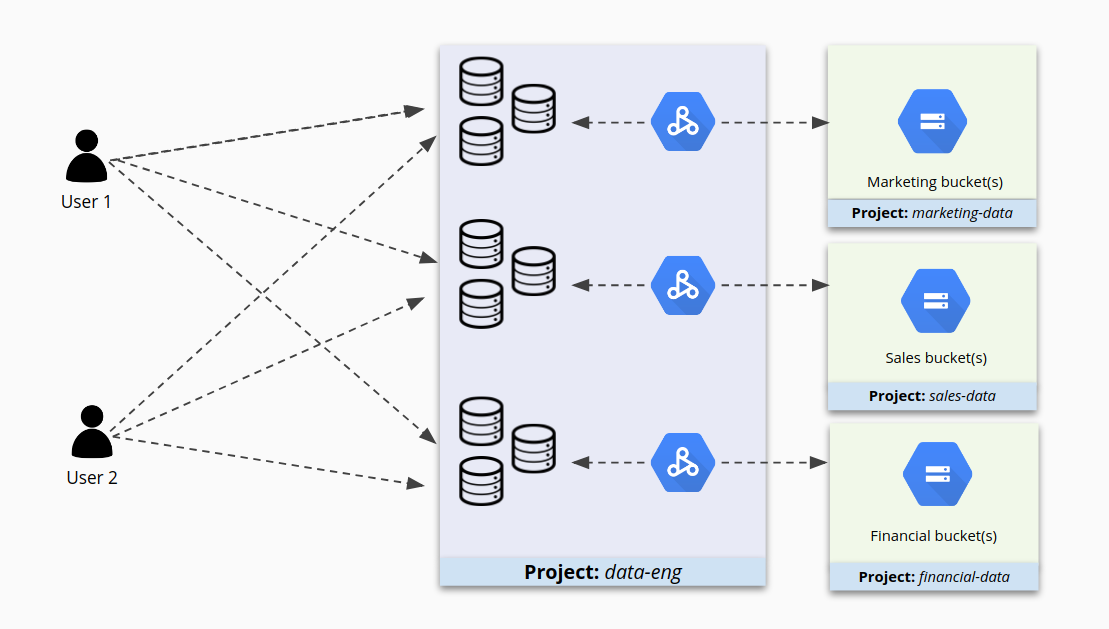
Colocar muitos clusters em um projeto pode tornar o gerenciamento desses clusters conveniente, mas pode não ser a melhor maneira de proteger o acesso a eles. Por exemplo, considerando os clusters 1 e 2 no projeto A, alguns usuários podem ter os privilégios certos para trabalhar no cluster 1, mas também podem ter permissões demais para o cluster 2. Ou, pior ainda, eles podem ter acesso ao cluster 2 simplesmente porque ele está no mesmo projeto, quando não deveriam ter acesso.
Quando os projetos contêm muitos clusters, o acesso a eles pode se tornar complicado, conforme mostrado na figura a seguir.
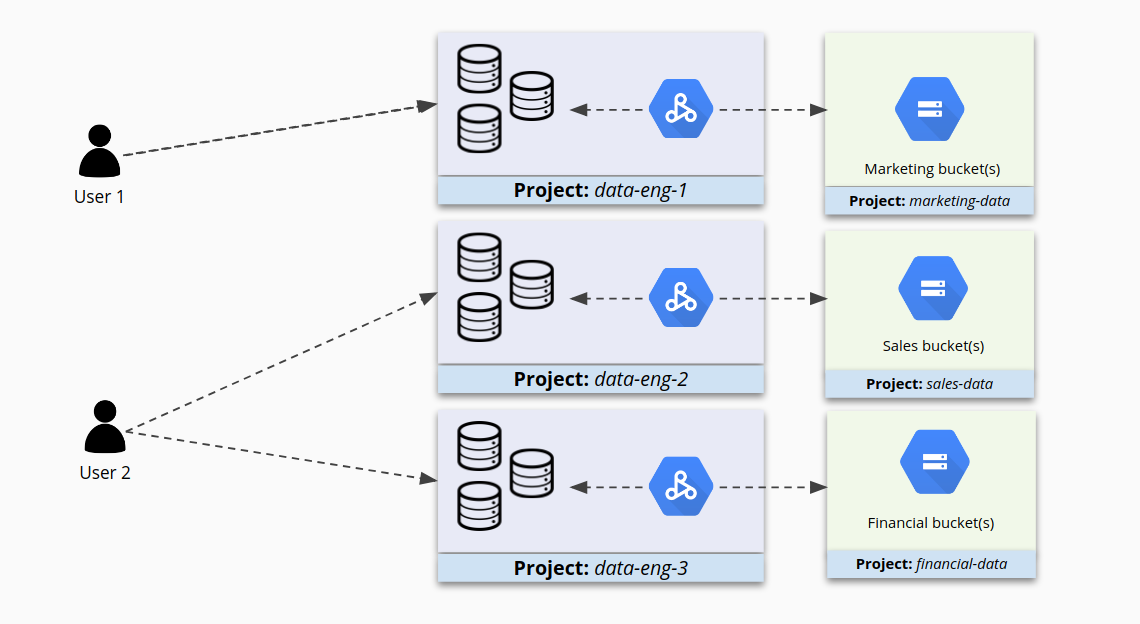
Se, em vez disso, você agrupar clusters semelhantes em projetos menores e configurar o IAM separadamente para cada cluster, terá um maior grau de controle sobre o acesso. Agora os usuários têm acesso aos clusters destinados a eles e estão impedidos de acessar outros.
Restrinja o acesso a clusters
Definir o acesso usando contas de serviço protege as interações entre o Dataproc/Hadoop e outros componentes do Google Cloud. No entanto, isso não controla totalmente quem pode acessar o Dataproc/Hadoop. Por exemplo, um usuário do cluster que tem o endereço IP dos nós do cluster do Dataproc/Hadoop ainda pode usar o SSH para se conectar a ele (em alguns casos) ou enviar jobs para ele. No ambiente local, o administrador do sistema geralmente tem sub-redes, regras de firewall, autenticação do Linux e outras estratégias para restringir o acesso a clusters do Hadoop.
Há várias maneiras de restringir o acesso no nível de autenticação do Google Workspace ou do Google Cloud ao usar o Dataproc/Hadoop no Compute Engine. Porém, neste guia o foco é o acesso no nível dos componentes do Google Cloud.
Como restringir o login do SSH usando o login do SO
No ambiente local, para impedir que os usuários se conectem a um nó do Hadoop, é necessário configurar o controle de acesso do perímetro, o acesso SSH no nível do Linux e os arquivos sudoer.
No Google Cloud, é possível configurar restrições SSH no nível do usuário para se conectar a instâncias do Compute Engine. Para isso, basta usar o seguinte processo:
- Ative o atributo de login do SO no projeto ou em instâncias individuais.
- Conceda os papéis do IAM necessários para você mesmo e outros participantes.
- Se quiser, adicione chaves SSH personalizadas a contas de usuário para você e para outros participantes. Se preferir, o Compute Engine poderá gerar essas chaves automaticamente, quando você se conectar às instâncias.
Depois que você ativar o Login do SO em uma ou mais instâncias no projeto, elas aceitarão conexões apenas de contas de usuário com os papéis necessários do IAM no projeto ou na organização.
Por exemplo, você pode conceder acesso à instância para seus usuários com o seguinte processo:
Conceda os papéis de acesso à instância necessários ao usuário. Os usuários precisam ter os papéis a seguir:
- Papel
iam.serviceAccountUser Um dos seguintes papéis de login:
- Papel
compute.osLogin, que não concede permissões de administrador. - Papel
compute.osAdminLogin, que concede permissões de administrador.
- Papel
- Papel
Se você for um administrador da organização e quiser permitir que identidades do Google fora da organização acessem suas instâncias, conceda a essas identidades externas o papel
compute.osLoginExternalUserno nível da organização. Também é preciso conceder a elas os papéiscompute.osLoginoucompute.osAdminLoginpara envolvidos no projeto ou no nível da organização.
Depois de configurar os papéis necessários, conecte-se a uma instância usando as ferramentas do Compute Engine. O Compute Engine gera automaticamente chaves SSH e as associa à sua conta de usuário.
Para mais informações sobre o recurso de login do sistema operacional, consulte Como gerenciar o acesso à instância usando o login do sistema operacional.
Como restringir o acesso a uma rede usando regras de firewall
No Google Cloud, também é possível criar regras de firewall que usam contas de serviço para filtrar o tráfego de entrada ou saída. Essa abordagem pode funcionar particularmente bem nestas circunstâncias:
- Você tem vários usuários ou aplicativos que precisam de acesso ao Hadoop, o que significa que criar regras com base no IP é um desafio.
- Você está executando clusters temporários do Hadoop ou VMs de cliente, para que os endereços IP sejam alterados com frequência.
Usando regras de firewall em conjunto com contas de serviço, é possível definir o acesso a um determinado cluster do Dataproc/Hadoop para permitir apenas uma conta de serviço específica. Dessa maneira, somente as VMs em execução como essa conta de serviço terão acesso ao cluster no nível especificado.
O diagrama a seguir ilustra o processo de uso de contas de serviço para restringir o acesso. dataproc-app-1, dataproc-1, dataproc-2 e app-1-client são todos contas de serviço. As regras de firewall permitem que dataproc-app-1 acesse dataproc-1 e dataproc-2 e que os clientes usando app-1-client acessem dataproc-1. No lado do armazenamento, o acesso e as permissões do Cloud Storage são restringidos pelas permissões do Cloud Storage a contas de serviço em vez de regras de firewall.
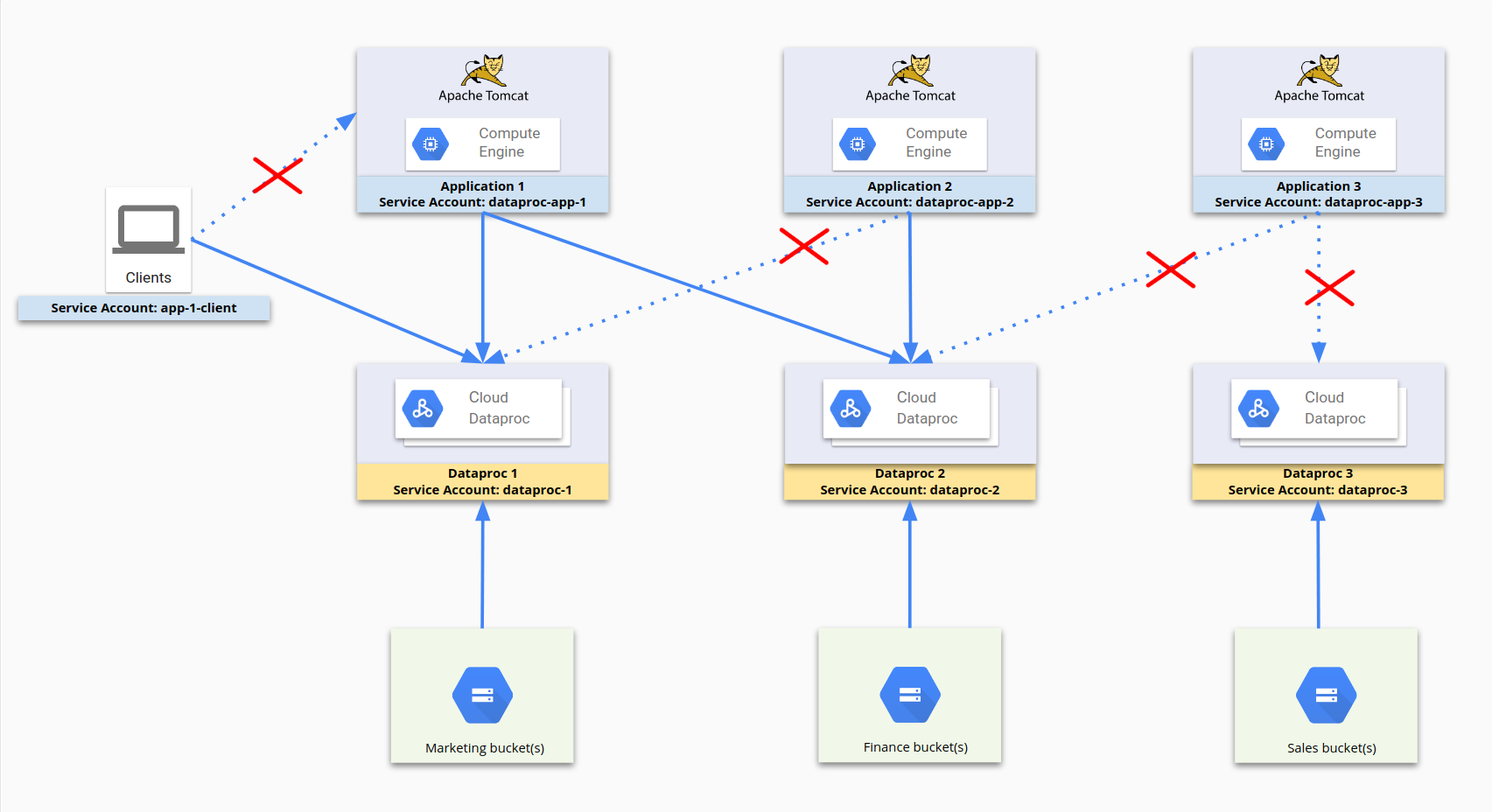
Para essa configuração, as seguintes regras de firewall foram estabelecidas:
| Nome da regra | Configurações |
|---|---|
dp1 |
Objetivo: dataproc-1Fonte: [Intervalo de IP] Fonte SA: dataproc-app-1Permitir [portas] |
dp2 |
Objetivo: dataproc-2Fonte: [Intervalo de IP] Fonte SA: dataproc-app-2Permitir [portas] |
dp2-2 |
Objetivo: dataproc-2Fonte: [Intervalo de IP] Fonte SA: dataproc-app-1Permitir [portas] |
app-1-client |
Objetivo: dataproc-1Fonte: [Intervalo de IP] Fonte SA: app-1-clientPermitir [portas] |
Para mais informações sobre o uso de regras de firewall com contas de serviço, consulte Filtragem de origem e de destino por conta de serviço.
Verificar se há portas de firewall abertas inadvertidamente
Ter regras de firewall apropriadas no local também é importante para expor as interfaces de usuário baseadas na Web que são executadas no cluster. Verifique se você não tem portas de firewall abertas da Internet que se conectam a essas interfaces. Portas abertas e regras de firewall configuradas incorretamente podem permitir que usuários não autorizados executem código arbitrário.
Por exemplo, o Apache Hadoop YARN fornece APIs REST que compartilham as mesmas portas que as interfaces da Web do YARN. Por padrão, os usuários que podem acessar a interface da Web do YARN podem criar aplicativos, enviar jobs e executar operações do Cloud Storage.
Analise as Configurações de rede do Dataproc e Criar um túnel SSH para estabelecer uma conexão segura com o controlador do cluster. Para mais informações sobre o uso de regras de firewall com contas de serviço, consulte Filtragem de origem e de destino por conta de serviço.
E quanto aos clusters multilocatários?
Em geral, é uma prática recomendada executar clusters do Dataproc/Hadoop separados para aplicativos diferentes. No entanto, se você precisar usar um cluster multilocatário e não quiser violar os requisitos de segurança, crie usuários e grupos do Linux dentro dos clusters do Dataproc/Hadoop para fornecer alocação de recursos e autorização por meio de uma fila YARN. A autenticação precisa ser implementada por você, porque não há mapeamento direto entre usuários do Google e do Linux. A ativação do Kerberos no cluster pode fortalecer o nível de autenticação no escopo do cluster.
Às vezes, usuários humanos, como um grupo de cientistas de dados, usam um cluster do Hadoop para descobrir dados e criar modelos. Em uma situação como essa, agrupar usuários que compartilham o mesmo acesso aos dados e criar um cluster dedicado do Dataproc/Hadoop seria uma boa escolha. Dessa maneira, é possível adicionar usuários ao grupo que tem permissão para acessar os dados. Os recursos de cluster também podem ser alocados com base em usuários do Linux.