Dataproc und Google Cloud bieten verschiedene Features zum Schutz Ihrer Daten. In diesem Leitfaden wird beschrieben, wie Sicherheit in Hadoop funktioniert und in Google Cloud umgesetzt wird. Außerdem erhalten Sie Hinweise zum Aufbauen einer Sicherheitsarchitektur für die Bereitstellung in Google Cloud.
Übersicht
Bei einer lokalen Hadoop-Bereitstellung sind Sicherheitsmodell und Sicherheitsmechanismus normalerweise anders gestaltet als in der Cloud. Wenn Sie wissen, wie Sicherheit in Hadoop funktioniert, können Sie die Sicherheitsarchitektur für die Bereitstellung in Google Cloud besser planen.
Sie können Hadoop in Google Cloud auf zwei Arten bereitstellen: als von Google verwaltete Cluster (Dataproc) oder als nutzerverwaltete Cluster (Hadoop in Compute Engine). Die Inhalte und technischen Anleitungen in diesem Leitfaden gelten größtenteils für beide Bereitstellungsformen. In diesem Leitfaden wird der Begriff Dataproc/Hadoop verwendet, um Konzepte oder Verfahren zu beschreiben, die sich auf beide Bereitstellungsformen beziehen. In einigen Details unterscheidet sich die Bereitstellung in Dataproc jedoch von der Bereitstellung in Hadoop auf Compute Engine. Auf solche Fälle weisen wir im Leitfaden gesondert hin.
Gängige Sicherheitsverfahren bei einer lokalen Hadoop-Bereitstellung
Im folgenden Diagramm wird eine typische lokale Hadoop-Infrastruktur mit den entsprechenden Sicherheitsmaßnahmen dargestellt. Es zeigt, wie die grundlegenden Hadoop-Komponenten untereinander und mit Nutzerverwaltungssystemen interagieren.
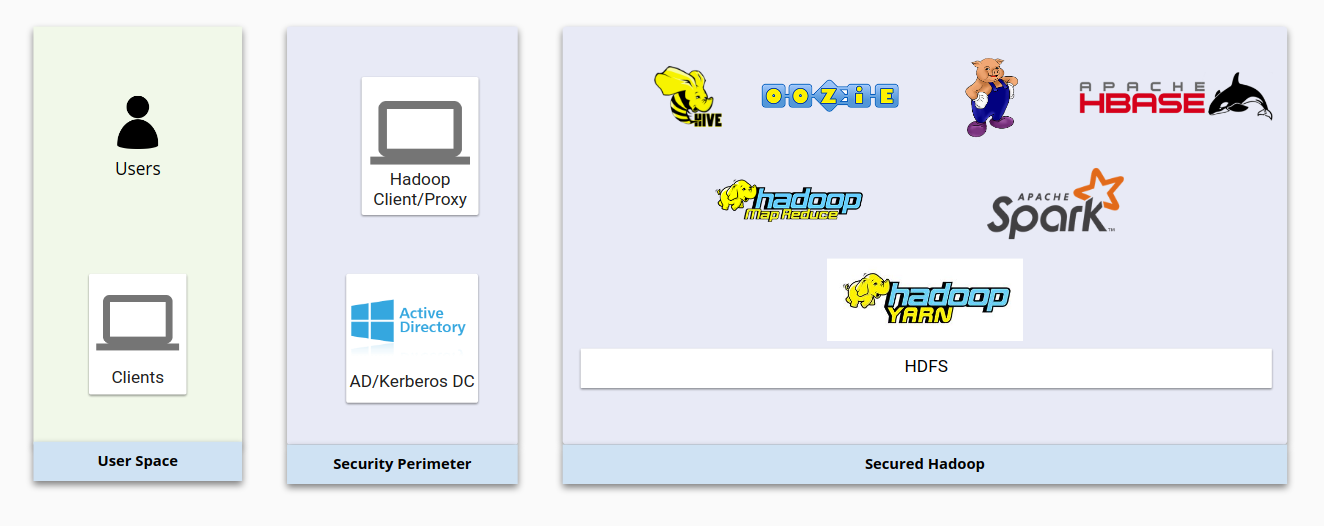
Diese vier Punkte bilden die Sicherheitsgrundlage von Hadoop:
- Die Authentifizierung erfolgt über Kerberos, eingebunden in LDAP oder Active Directory.
- Die Autorisierung erfolgt über HDFS und Sicherheitsprodukte wie Apache Sentry oder Apache Ranger. Dadurch wird gewährleistet, dass die Nutzer die richtigen Zugriffsberechtigungen auf Hadoop-Ressourcen haben.
- Die Verschlüsselung erfolgt über die Netzwerkverschlüsselung und die HDFS-Verschlüsselung. Damit sind die Daten sowohl bei der Übertragung als auch im inaktiven Zustand geschützt.
- Das Auditing erfolgt durch Produkte wie Cloudera Navigator, die der Anbieter liefert.
Aus Sicht des Nutzerkontos hat Hadoop eine eigene Nutzer- und Gruppenstruktur, mit der Identitäten verwaltet und Daemons ausgeführt werden können. Die HDFS- und YARN-Daemons in Hadoop werden beispielsweise als Unix-Nutzer hdfs und yarn ausgeführt. Weitere Informationen finden Sie unter Hadoop im sicheren Modus.
Hadoop-Nutzer entsprechen normalerweise Linux-Systemnutzern bzw. Nutzern in Active Directory/LDAP. Active Directory-Nutzer und -Gruppen werden mithilfe von Tools wie Centrify oder RedHat SSSD synchronisiert.
Authentifizierung bei einer lokalen Hadoop-Bereitstellung
In einem sicheren System müssen Nutzer und Dienste ihre Identität nachweisen. Im sicheren Modus von Hadoop wird Kerberos zur Authentifizierung eingesetzt. Die meisten Hadoop-Komponenten sind auf Kerberos als Authentifizierungskomponente ausgelegt. Kerberos wird normalerweise in Enterprise-Authentifizierungssystemen wie Active Directory oder LDAP-kompatiblen Systemen implementiert.
Kerberos-Principals
Ein Nutzer wird in Kerberos als Principal bezeichnet. In einer Hadoop-Bereitstellung gibt es Nutzer-Principals und Dienst-Principals. Nutzer-Principals werden normalerweise von Active Directory oder anderen Nutzerverwaltungssystemen über ein Schlüsselverteilungszentrum (Key Distribution Center, KDC) synchronisiert. Ein Nutzer-Principal repräsentiert einen menschlichen Nutzer. Ein Dienst-Principal verweist auf einem Server genau auf einen Dienst, sodass jeder Dienst auf jedem Server einen eindeutigen Principal hat.
Keytab-Dateien
Eine Keytab-Datei enthält Kerberos-Principals und die dazugehörigen Schlüssel. Nutzer und Dienste können sich mithilfe von Keytabs gegenüber Hadoop-Diensten authentifizieren, ohne interaktive Tools zu verwenden und Kennwörter einzugeben. Hadoop erstellt Dienst-Principals für jeden Dienst auf jedem Knoten. Diese Principals werden auf Hadoop-Knoten in Keytab-Dateien gespeichert.
SPNEGO
Wenn Sie mit einem Webbrowser auf einen Cluster zugreifen, der mit Kerberos gesichert ist, muss der Browser in der Lage sein, Kerberos-Schlüssel zu übergeben. Dies geschieht über den Simple and Protected GSS-API Negotiation Mechanism (SPNEGO). Über diesen Mechanismus kann Kerberos in Webanwendungen verwendet werden.
Integration
Hadoop setzt Kerberos nicht nur zur Authentifizierung von Nutzern, sondern auch von Diensten ein. Jeder Hadoop-Dienst auf einem beliebigen Knoten hat einen eigenen Kerberos-Principal für die Authentifizierung. Für Dienste wird normalerweise eine Keytab-Datei mit einem zufälligen Kennwort auf dem Server gespeichert.
Um mit Diensten interagieren zu können, müssen Nutzer normalerweise ihr Kerberos-Ticket über den Befehl kinit oder Centrify oder SSSD anfordern.
Autorisierung bei lokalen Hadoop-Bereitstellungen
Nach der Feststellung der Identität prüft das Autorisierungssystem, welche Art von Zugriff der Nutzer oder Dienst hat. Bei Hadoop werden Open-Source-Projekte wie Apache Sentry und Apache Ranger zur Autorisierung verwendet.
Apache Sentry und Apache Ranger
Apache Sentry und Apache Ranger sind gängige Autorisierungsmechanismen bei Hadoop-Clustern. Für Komponenten, die auf Hadoop ausgeführt werden, sind eigene Plug-ins für Sentry oder Ranger implementiert, die das Verhalten steuern, wenn Sentry oder Ranger den Zugriff für eine Identität bestätigt oder verweigert. Sentry und Ranger stützen sich auf Authentifizierungssysteme wie Kerberos, LDAP oder AD. Durch den Mechanismus der Gruppenzuordnung in Hadoop ist gewährleistet, dass Sentry oder Ranger die gleiche Gruppenzuordnung sehen wie die anderen Komponenten der Hadoop-Umgebung.
HDFS-Berechtigungen und ACL
In HDFS wird mithilfe eines POSIX-ähnlichen Berechtigungssystems mit einer Zugriffssteuerungsliste (Access Control List, ACL) festgestellt, ob Nutzer Zugriff auf Dateien haben. Alle Dateien und Verzeichnisse werden jeweils einem Inhaber und einer Gruppe zugeordnet. Die Struktur hat einen Stammordner, der einem Superuser gehört. Auf den verschiedenen Ebenen der Struktur kann es unterschiedliche Verschlüsselungen, Inhaber und Berechtigungen sowie erweiterte ACLs (facl) geben.
Den jeweiligen Gruppen werden normalerweise je nach ihren Zugriffserfordernissen Berechtigungen auf Verzeichnisebene erteilt. Dies ist im Diagramm unten dargestellt. Zugriffsmuster werden zu unterschiedlichen Rollen zusammengefasst und Active Directory-Gruppen zugeordnet. Objekte, die zu einem einzelnen Dataset gehören, befinden sich normalerweise auf der Ebene, für die eine bestimmte Gruppe Berechtigungen hat. Für die verschiedenen Datenkategorien gibt es dabei unterschiedliche Verzeichnisse.
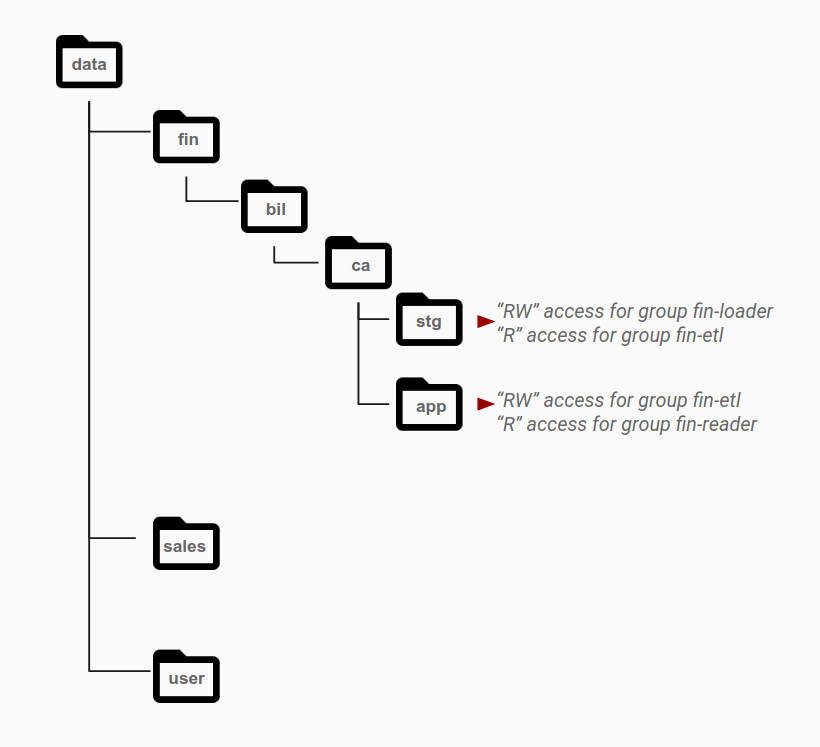
Das Verzeichnis stg ist beispielsweise der Staging-Bereich für Finanzdaten. Für den Ordner stg hat die Gruppe fin-loader Lese- und Schreibberechtigungen. Innerhalb dieses Staging-Bereichs hat eine andere Anwendungskontengruppe namens fin-etl, die ETL-Pipelines repräsentiert, Lesezugriff auf dieses Verzeichnis. ETL-Pipelines verarbeiten Daten und speichern sie im Verzeichnis app, wo sie bereitgestellt werden. Zum Aktivieren dieses Zugriffsmusters erhält die Gruppe fin-etl Lese-/Schreibzugriff auf das Verzeichnis app. Diese Gruppe ist die Identität, mit der die ETL-Daten geschrieben werden. Die Gruppe fin-reader, die die Ergebnisdaten auswertet, erhält Lesezugriff auf dieses Verzeichnis.
Verschlüsselung bei lokalen Hadoop-Bereitstellungen
Hadoop bietet Möglichkeiten zum Verschlüsseln von inaktiven Daten und zum Verschlüsseln von Daten während der Übertragung. Zum Verschlüsseln inaktiver Daten kann man HDFS verschlüsseln. Dazu können Schlüssel in Java verschlüsselt oder eigene Verschlüsselungslösungen von entsprechenden Anbietern genutzt werden. HDFS unterstützt Verschlüsselungszonen, man kann also verschiedene Dateien mit unterschiedlichen Schlüsseln verschlüsseln. Beim Erstellen einer Verschlüsselungszone wird ihr ein solcher Schlüssel zugewiesen.
Innerhalb einer Verschlüsselungszone hat jede Datei einen eindeutigen Datenverschlüsselungsschlüssel (Data Encryption Key, DEK). DEKs werden niemals direkt von HDFS verarbeitet. Stattdessen arbeitet HDFS nur mit einem verschlüsselten Datenverschlüsselungsschlüssel (Encrypted Data Encryption Key, EDEK). Die Clients entschlüsseln den EDEK und verwenden den ausgelesenen DEK zum Lesen und Schreiben von Daten. Für die HDFS-Datenknoten ist nur ein Stream verschlüsselter Byte sichtbar.
Datenübertragungen zwischen Hadoop-Knoten können mit Transport Layer Security (TLS) verschlüsselt werden. TLS bietet Verschlüsselung und Authentifizierung für die Kommunikation zwischen zwei beliebigen Komponenten in Hadoop. Normalerweise würde Hadoop interne, CA-signierte Zertifikate für TLS zwischen Komponenten nutzen.
Auditing bei lokalen Hadoop-Bereitstellungen
Auditing ist ein wichtiger Sicherheitsfaktor. Über das Auditing können Sie verdächtige Aktivitäten aufspüren und erhalten Aufzeichnungen darüber, wer Zugriff auf Ressourcen hatte. Für die Datenverwaltung, z. B. für das Audit-Tracing in Hadoop, werden oft Cloudera Navigator oder andere Tools von Drittanbietern verwendet. Mit diesen Tools kann man die Daten in Hadoop-Datenspeichern und die Berechnungen mit diesen Daten sehen und kontrollieren. Mit dem Daten-Auditing lassen sich alle Aktivitäten innerhalb eines Systems vollständig und in unveränderlicher Form erfassen.
Hadoop in Google Cloud
In einer traditionellen lokalen Hadoop-Umgebung werden die vier hauptsächlichen Sicherheitsfunktionen (Authentifizierung, Autorisierung, Verschlüsselung und Audit) durch verschiedene Komponenten integriert und umgesetzt. In Google Cloud werden sie von verschiedenen Google Cloud-Komponenten verarbeitet, die sich außerhalb von Dataproc und Hadoop in Compute Engine befinden.
Sie können Google Cloud-Ressourcen mithilfe der Google Cloud Console verwalten, einer webbasierten Benutzeroberfläche. Alternativ können Sie die Google Cloud CLI verwenden, die schneller und komfortabler ist, wenn Sie mit der Befehlszeile vertraut sind. Wenn Sie Befehle in gcloud ausführen möchten, müssen Sie entweder die gcloud CLI auf Ihrem lokalen Computer installieren oder eine Instanz von Cloud Shell einsetzen.
Hadoop-Authentifizierung von Google Cloud
In Google Cloud gibt es zwei Arten von Google-Identitäten: Dienstkonten und Nutzerkonten. Die meisten Google APIs erfordern eine Authentifizierung mit einer Google-Identität. Einige wenige Google Cloud APIs funktionieren ohne Authentifizierung, da sie API-Schlüssel verwenden. Wir empfehlen jedoch, alle APIs mit einer Dienstkontoauthentifizierung zu verwenden.
Bei Dienstkonten werden private Schlüssel zur Feststellung der Identität eingesetzt. Bei Nutzerkonten wird der Endnutzer mit dem Protokoll OAUTH 2.0 authentifiziert. Weitere Informationen dazu finden Sie in der Authentifizierungsübersicht.
Hadoop-Autorisierung in Google Cloud
Google Cloud bietet mehrere Methoden, um anzugeben, welche Berechtigungen eine authentifizierte Identität für eine Reihe von Ressourcen hat.
IAM
Google Cloud bietet die Identitäts- und Zugriffsverwaltung (IAM). Mit diesem Produkt können Sie den Zugriff steuern und festlegen, welche Nutzer (Hauptkonten) welchen Zugriff (welche Rolle) auf welche Ressourcen haben.
Mit IAM können Sie den Zugriff auf Google Cloud-Ressourcen gewähren und unerwünschten Zugriff auf andere Ressourcen verhindern. Sie haben die Möglichkeit, das Sicherheitsprinzip der geringsten Berechtigung zu implementieren und so nur den unbedingt notwendigen Zugriff auf Ressourcen zu gewähren.
Dienstkonten
Ein Dienstkonto ist eine spezielle Art von Google-Konto, das zu einer Anwendung oder einer virtuellen Maschine (VM) und nicht zu einem bestimmten Endnutzer gehört. Anwendungen können sich mit den Anmeldedaten des Dienstkontos bei anderen Cloud APIs authentifizieren. Außerdem können Sie Firewallregeln erstellen, mit denen Traffic von und zu Instanzen anhand des Dienstkontos, das der jeweiligen Instanz zugewiesen ist, zugelassen oder verweigert wird.
Dataproc-Cluster werden zusätzlich zu Compute Engine-VMs erstellt. Durch Zuweisen eines benutzerdefinierten Dienstkontos beim Erstellen eines Dataproc-Clusters wird dieses Dienstkonto allen VMs in diesem Cluster zugewiesen. Dadurch erhält der Cluster differenzierte Zugriffsrechte auf Google Cloud-Ressourcen. Wenn Sie kein Dienstkonto angeben, verwenden Dataproc-VMs das standardmäßige von Google verwaltete Compute Engine-Dienstkonto. Dieses Konto hat standardmäßig die Rolle "Projektbearbeiter" und damit eine große Bandbreite an Berechtigungen. Wir empfehlen, Dataproc-Cluster in einer Produktionsumgebung nicht mit dem Standarddienstkonto zu erstellen.
Dienstkontoberechtigungen
Wenn Sie einem Dataproc/Hadoop-Cluster ein benutzerdefiniertes Dienstkonto zuweisen, entspricht die Zugriffsebene dieses Dienstkontos der Kombination der Zugriffsbereiche, die den VM-Instanzen des Clusters gewährt werden, und der IAM-Rollen, die dem Dienstkonto zugewiesen werden. Wenn Sie mit Ihrem benutzerdefinierten Dienstkonto eine Instanz einrichten möchten, müssen Sie sowohl Zugriffsbereiche als auch IAM-Rollen konfigurieren. Diese Mechanismen interagieren im Wesentlichen so:
- Mit Zugriffsbereichen wird der Zugriff einer Instanz autorisiert.
- Durch IAM wird dieser Zugriff auf die Rollen eingeschränkt, die dem von der Instanz verwendeten Dienstkonto zugewiesen wurden.
- Die endgültigen Berechtigungen der Instanz ergeben sich aus der Schnittmenge der Zugriffsbereiche und der IAM-Rollen.
Wenn Sie einen Dataproc-Cluster oder eine Compute Engine-Instanz in der Google Cloud Console erstellen, wählen Sie den Zugriffsbereich der Instanz aus:
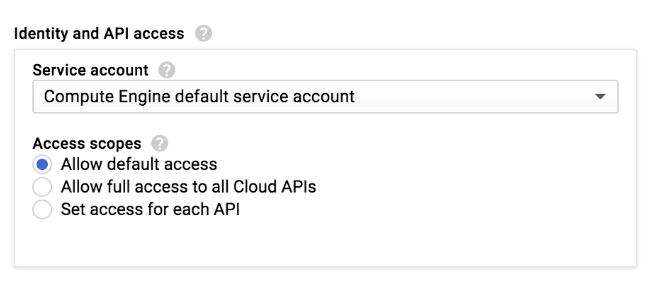
Für einen Dataproc-Cluster oder eine Compute Engine-Instanz ist eine Reihe von Zugriffsbereichen zur Verwendung mit der Einstellung Standardzugriff zulassen definiert:
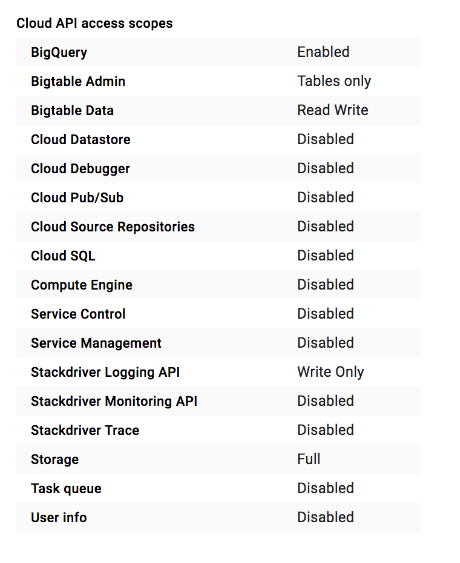
Es gibt viele Zugriffsbereiche zur Auswahl. Wir empfehlen, beim Erstellen einer neuen VM-Instanz oder eines neuen Clusters in der Console die Einstellung Uneingeschränkten Zugriff auf alle Cloud APIs zulassen auszuwählen. Wenn Sie mit dem Google Cloud CLI arbeiten, empfehlen wir dementsprechend den Zugriffsbereich https://www.googleapis.com/auth/cloud-platform. Diese Bereiche autorisieren den Zugriff auf alle Google Cloud-Dienste. Nachdem Sie den Bereich festgelegt haben, sollten Sie den Zugriff darauf beschränken. Weisen Sie dem Cluster-Dienstkonto zu diesem Zweck IAM-Rollen zu.
Das Konto kann trotz des Google Cloud-Zugriffsbereichs keine Aktionen außerhalb dieser Rollen ausführen. Weitere Informationen finden Sie in der Dokumentation zu den Dienstkontoberechtigungen.
IAM im Vergleich zu Apache Sentry und Apache Ranger
IAM spielt eine ähnliche Rolle wie Apache Sentry und Apache Ranger. Bei IAM wird der Zugriff über Rollen definiert. In diesen Rollen wird der Zugriff auf andere Google Cloud-Komponenten definiert und mit Dienstkonten verknüpft. Das bedeutet, dass alle Instanzen, die dasselbe Dienstkonto verwenden, denselben Zugriff auf andere Google Cloud-Ressourcen haben. Jedes Konto mit Zugriff auf diese Instanzen hat auch den gleichen Zugriff auf diese Google Cloud-Ressourcen wie das Dienstkonto.
Bei Dataproc-Clustern und Compute Engine-Instanzen gibt es keinen Mechanismus, durch den Google-Nutzer und -Gruppen Linux-Nutzern und -Gruppen zugeordnet werden. Sie können aber Linux-Nutzer und -Gruppen erstellen. Innerhalb des Dataproc-Clusters oder in Compute Engine-VMs funktionieren HDFS-Berechtigungen und Hadoop-Nutzer- und -Gruppenzuordnungen weiterhin. Über diese Zuordnung kann der Zugriff auf HDFS beschränkt oder die Ressourcenzuweisung mithilfe einer YARN-Warteschlange erzwungen werden.
Wenn Anwendungen in einem Dataproc-Cluster oder einer Compute Engine-VM auf externe Ressourcen wie Cloud Storage oder BigQuery zugreifen müssen, werden diese Anwendungen mit der Identität des Dienstkontos authentifiziert, das Sie den VMs im Cluster zugewiesen haben. Mit IAM gewähren Sie dem benutzerdefinierten Dienstkonto des Clusters anschließend die für Ihre Anwendung erforderliche Mindestzugriffsebene.
Cloud Storage-Berechtigungen
Dataproc verwendet Cloud Storage als Speichersystem. Dataproc bietet auch ein lokales HDFS-System, aber wenn der Dataproc-Cluster gelöscht wird, ist HDFS nicht mehr verfügbar. Wenn die Anwendung nicht zwingend auf HDFS angewiesen ist, nutzen Sie Cloud Storage und somit alle Vorteile von Google Cloud.
Cloud Storage hat keine Speicherhierarchien. In der Verzeichnisstruktur wird die Struktur eines Dateisystems simuliert. Es gibt auch keine POSIX-ähnlichen Berechtigungen. Der Zugriff durch IAM-Nutzerkonten und -Dienstkonten kann auf Bucket-Ebene geregelt werden. Linux-Nutzerberechtigungen werden nicht angewendet.
Hadoop-Verschlüsselung in Google Cloud
Von wenigen Ausnahmen abgesehen, verschlüsseln Google Cloud-Dienste inaktive und übertragene Kundeninhalte und setzen dabei verschiedene Verschlüsselungsmethoden ein. Die Verschlüsselung erfolgt automatisch und erfordert keinen Eingriff durch den Kunden.
Beispielsweise werden alle neu auf nichtflüchtigem Speicher gespeicherten Daten gemäß dem Standard AES-256 verschlüsselt, wobei jeder Verschlüsselungsschlüssel wiederum mit einem Satz von regelmäßig rotierenden Stammschlüsseln (Masterschlüsseln) verschlüsselt wird. Google Cloud nutzt dieselben Verschlüsselungs- und Schlüsselverwaltungsrichtlinien, Kryptografiebibliotheken und Roots of Trust, die auch von zahlreichen Google-Produktionsdiensten wie Gmail und für die eigenen Unternehmensdaten von Google verwendet werden.
Da im Gegensatz zu den meisten lokalen Hadoop-Implementierungen die Verschlüsselung in Google Cloud eine Standardfunktion ist, müssen Sie sich keine Gedanken über die Implementierung der Verschlüsselung machen, solange Sie keine eigenen Verschlüsselungsschlüssel verwenden möchten. Google Cloud bietet außerdem eine Lösung für vom Kunden verwaltete Verschlüsselungsschlüssel und eine Lösung für vom Kunden bereitgestellte Verschlüsselungsschlüssel. Sie können bei Bedarf also die Verschlüsselungsschlüssel selbst verwalten oder lokal speichern.
Weitere Informationen dazu finden Sie unter Verschlüsselung inaktiver Daten und Verschlüsselung bei der Übertragung.
Hadoop-Auditing auf Google Cloud
Mit Cloud-Audit-Logs können einige Logtypen für jedes Projekt und jede Organisation verwaltet werden. Google Cloud-Dienste schreiben Audit-Logs, damit Sie für Ihre Google Cloud-Projekte herausfinden können, wer was wo und wann getan hat.
Weitere Informationen zu Audit-Logs und Diensten, die Audit-Logs schreiben, finden Sie in der Dokumentation zu Cloud-Audit-Logs.
Migrationsprozess
Führen Sie den in diesem Abschnitt beschriebenen Prozess aus, um für einen sicheren und effizienten Betrieb von Hadoop in Google Cloud zu sorgen.
In diesem Abschnitt gehen wir davon aus, dass Sie Ihre Google Cloud-Umgebung eingerichtet haben. Dazu gehört auch das Erstellen von Nutzern und Gruppen in Google Arbeitsbereich. Diese Nutzer und Gruppen werden entweder manuell verwaltet oder mit Active Directory synchronisiert. Außerdem sollten Sie alle notwendigen Konfigurationseinstellungen vorgenommen haben, damit die Authentifizierung von Nutzern in Google Cloud rundum einsatzbereit ist.
Entscheiden, wer Identitäten verwaltet
Die meisten Google-Kunden verwenden Cloud Identity zum Verwalten von Identitäten. Einige Kunden verwalten ihre Unternehmensidentitäten jedoch unabhängig von Google Cloud-Identitäten. In diesem Fall steuern die POSIX- und SSH-Berechtigungen den Endnutzerzugriff auf Cloudressourcen.
Wenn Sie ein unabhängiges Identitätssystem haben, erstellen Sie zuerst Google Cloud-Dienstkontoschlüssel und laden diese herunter. Sie können Ihr lokales POSIX- und SSH-Sicherheitsmodell dann im Google Cloud-Modell übernehmen. Dazu erteilen Sie entsprechende POSIX-ähnliche Zugriffsberechtigungen für die heruntergeladenen Dienstkonto-Schlüsseldateien. Mit anderen Worten, Sie erlauben oder verweigern Ihren lokalen Identitäten den Zugriff auf diese Schlüsseldateien.
Bei dieser Methode sind Ihre eigenen Identitätsmanagementsysteme für das Auditing zuständig. Für einen Audit-Trail können Sie die SSH-Logs (mit den Dienstkonto-Schlüsseldateien) von Nutzeranmeldungen auf Edge-Knoten verwenden oder die Dienstkonto-Anmeldedaten von Nutzern über einen komplexeren und expliziten Schlüsselspeichermechanismus abrufen. In letzterem Fall erfolgt das Audit-Logging eines "Identitätswechsels beim Dienstkonto" auf Schlüsselspeicherebene.
Entscheiden, ob ein oder mehrere Datenprojekte verwendet werden sollen
Wenn es in Ihrer Organisation viele Daten gibt, müssen die Daten auf verschiedene Cloud Storage-Buckets aufgeteilt werden. Sie sollten sich Gedanken darüber machen, wie Sie diese Daten-Buckets unter Ihren Projekten aufteilen. Möglicherweise erscheint es Ihnen praktisch, bei der Verwendung von Google Cloud zuerst eine kleine Menge von Daten zu verschieben und im Laufe der Zeit mit weiteren Arbeitslasten und Anwendungen auch immer mehr Daten zu verschieben.
Alle Daten-Buckets unter einem Projekt zu belassen, ist vielleicht bequem, aber oft nicht sinnvoll. Sie arbeiten dann bei der Zugriffssteuerung mit einer flachen Verzeichnisstruktur und IAM-Rollen für Buckets. Wenn die Zahl der Buckets zunimmt, kann dies immer schwerfälliger werden.
Eine Alternative besteht darin, Daten in mehreren Projekten zu speichern, die jeweils verschiedenen Organisationen zugeordnet sind: ein Projekt für die Finanzabteilung, eines für die Rechtsabteilung und so weiter. In diesem Fall verwaltet jede Gruppe ihre eigenen Berechtigungen selbst.
Während der Datenverarbeitung kann es notwendig sein, ad hoc auf Buckets zuzugreifen oder neue zu erstellen. Vielleicht muss die Verarbeitung über Zertifizierungsgrenzen hinweg aufgeteilt werden. Zum Beispiel benötigen Data Scientists manchmal Zugriff auf Daten, die von einem Prozess erzeugt werden, der ihnen nicht gehört.
Im folgenden Diagramm wird gezeigt, wie eine typische Datenorganisation in Cloud Storage bei einem einzelnen Datenprojekt und bei mehreren Datenprojekten aussehen kann.
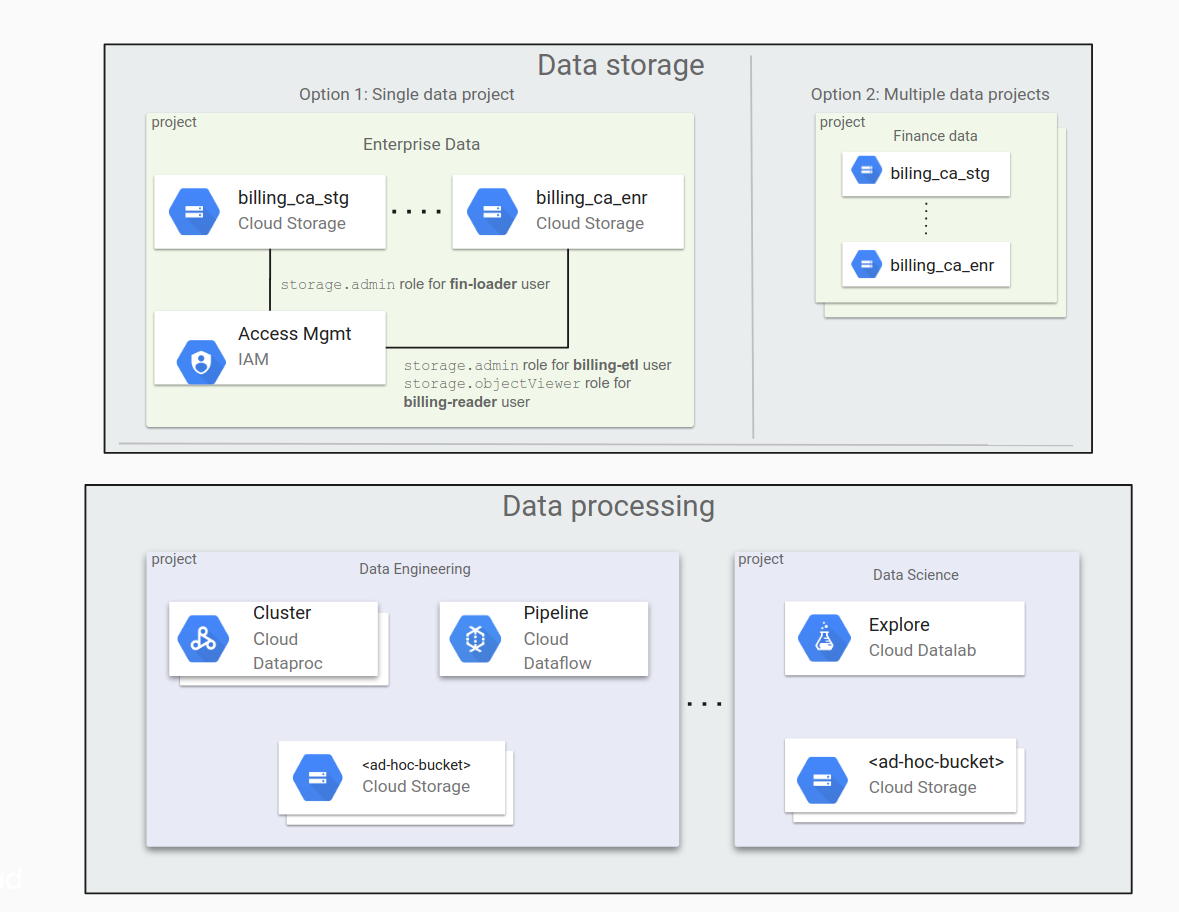
Hier die wichtigsten Punkte, die man berücksichtigen muss, wenn es darum geht, welche Vorgehensweise für Ihre Organisation am besten ist.
Wenn man mit nur einem Datenprojekt arbeitet:
- Es ist einfach, alle Buckets zu verwalten, solange die Anzahl der Buckets überschaubar ist.
- Die Berechtigungen werden hauptsächlich durch Mitglieder der Administratorengruppe erteilt.
Wenn man mit mehreren Datenprojekten arbeitet:
- Es ist einfacher, Verwaltungsaufgaben an Projektinhaber zu delegieren.
- Diese Vorgehensweise eignet sich für Organisationen, bei denen es unterschiedliche Verfahren gibt, Berechtigungen zu erteilen. Beispielsweise wenn die Berechtigungen für Projekte in der Marketingabteilung auf andere Weise erteilt werden als für Projekte in der Rechtsabteilung.
Anwendungen identifizieren und Dienstkonten erstellen
Wenn Dataproc/Hadoop-Cluster mit anderen Google Cloud-Ressourcen interagieren, z. B. mit Cloud Storage, identifizieren Sie alle Anwendungen, die auf Dataproc/Hadoop ausgeführt werden, und ihren erforderlichen Zugriff. Nehmen wir zum Beispiel an, es gibt einen ETL-Job, der Finanzdaten aus Kalifornien in den Bucket financial-ca schreibt. Dieser ETL-Job benötigt Lese- und Schreibzugriff auf den Bucket. Nachdem Sie die Anwendungen, die Hadoop verwenden, identifiziert haben, können Sie für jede dieser Anwendungen ein Dienstkonto erstellen.
Beachten Sie, dass dieser Zugriff keine Auswirkungen auf Linux-Nutzer innerhalb des Dataproc-Clusters oder in Hadoop in Compute Engine hat.
Weitere Informationen zu Dienstkonten finden Sie unter Dienstkonten erstellen und verwalten.
Berechtigungen für Dienstkonten erteilen
Wenn Sie wissen, welche Zugriffsberechtigungen jede Anwendung auf verschiedene Cloud Storage-Buckets benötigt, können Sie den entsprechenden Anwendungsdienstkonten diese Berechtigungen erteilen. Wenn Ihre Anwendungen auch Zugriff auf andere Google Cloud-Komponenten wie BigQuery oder Bigtable benötigen, können Sie mithilfe von Dienstkonten auch Zugriff auf diese Komponenten gewähren.
Beispielsweise könnten Sie operation-ca-etl als ETL-Anwendung angeben, die operative Berichte erzeugen und dazu Marketing- und Vertriebsdaten aus Kalifornien zusammenstellen soll. Dieser Anwendung erteilen Sie dann die Berechtigung, Berichte in den Daten-Bucket der Finanzabteilung zu schreiben. Anschließend gewähren Sie den Anwendungen marketing-report-ca und sales-report-ca jeweils Lese- und Schreibzugriff auf ihre eigenen Abteilungen. Im folgenden Diagramm wird diese Konfiguration veranschaulicht.
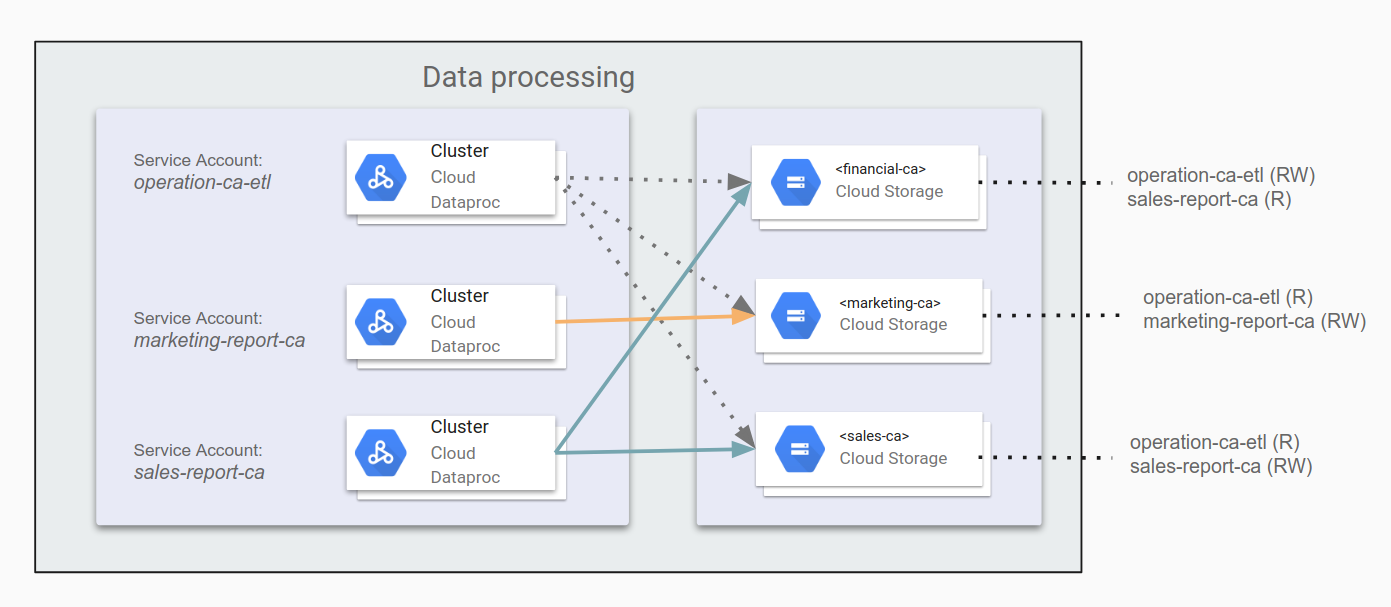
Sie sollten sich an den Grundsatz der geringsten Berechtigung halten. Dieser Grundsatz besagt, dass Sie jedem Nutzer- oder Dienstkonto nur die Berechtigungen erteilen, die es mindestens benötigt, um seine Aufgaben zu erfüllen. Die Standardberechtigungen sind in Google Cloud auf Nutzerfreundlichkeit und schnelle Einrichtung ausgelegt. Für Hadoop-Infrastrukturen, die Sicherheits- und Compliance-Prüfungen standhalten müssen, sollten Sie die Berechtigungen restriktiver gestalten. Wenn Sie frühzeitig Arbeit in diese Strategien investieren und sie dokumentieren, tragen Sie damit nicht nur zu einer sicheren und konformen Pipeline bei. Es hilft auch Sicherheits- und Complianceteams sehr, die Architektur zu überprüfen.
Cluster erstellen
Nachdem Sie den Zugriff geplant und konfiguriert haben, können Sie Dataproc-Cluster oder Hadoop in Compute Engine mit den von Ihnen erstellten Dienstkonten einrichten. Jeder Cluster kann im Rahmen der Berechtigungen, die Sie seinem Dienstkonto erteilt haben, auf andere Google Cloud-Komponenten zugreifen. Achten Sie darauf, die richtigen Zugriffsbereiche für den Google Cloud-Zugriff anzugeben, und stimmen Sie dies dann mit den Dienstkonto-Zugriffsberechtigungen ab. Wenn ein Zugriffsproblem auftritt, insbesondere bei Hadoop in Compute Engine, müssen Sie diese Berechtigungen überprüfen.
Verwenden Sie diesen gcloud-Befehl, um einen Dataproc-Cluster mit einem bestimmten Dienstkonto zu erstellen:
gcloud dataproc clusters create [CLUSTER_NAME] \
--service-account=[SERVICE_ACCOUNT_NAME]@[PROJECT+_ID].iam.gserviceaccount.comn \
--scopes=scope[, ...]
Folgende Gründe sprechen dagegen, das Compute Engine-Standarddienstkonto zu verwenden:
- Wenn mehrere Cluster und Compute Engine-VMs das Compute Engine-Standarddienstkonto verwenden, wird das Auditing erschwert.
- Die Projekteinstellungen für das Compute Engine-Standarddienstkonto können unterschiedlich sein, sodass es möglicherweise mehr Berechtigungen hat, als der Cluster benötigt.
- Änderungen am Compute Engine-Standarddienstkonto können Ihre Cluster und die darin ausgeführten Anwendungen unbeabsichtigt beeinträchtigen oder sogar zu Abbrüchen führen.
Getrennte IAM-Berechtigungen für jeden Cluster in Betracht ziehen
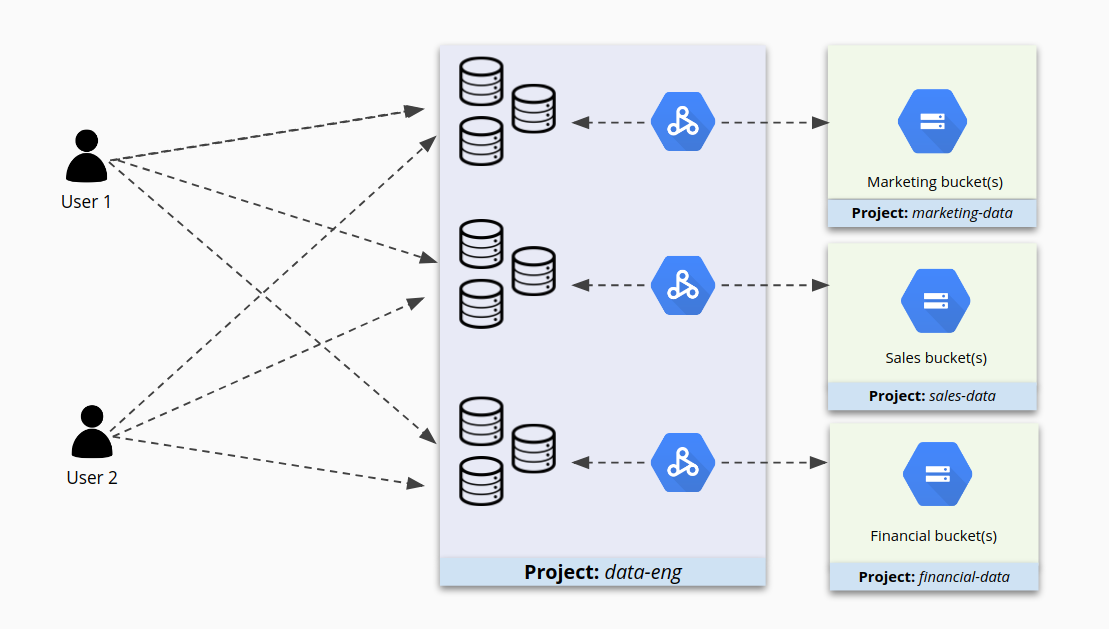
Wenn Sie viele Cluster unter einem Projekt platzieren, ist das vielleicht bequem zu verwalten, aber möglicherweise nicht die beste Art, den Zugriff darauf zu sichern. Nehmen wir an, in Projekt A gibt es die Cluster 1 und 2. Dann können Nutzer, die die Berechtigungen zur Arbeit mit Cluster 1 haben, gleichzeitig auch zu viele Berechtigungen für Cluster 2 haben. Oder schlimmer noch, sie haben möglicherweise nur deshalb Zugriff auf Cluster 2, weil er sich in diesem Projekt befindet, obwohl sie gar keinen Zugriff haben sollten.
Wenn Projekte viele Cluster enthalten, kann der Zugriff auf diese Cluster zu einem Verwirrspiel werden, wie in der folgenden Abbildung dargestellt.
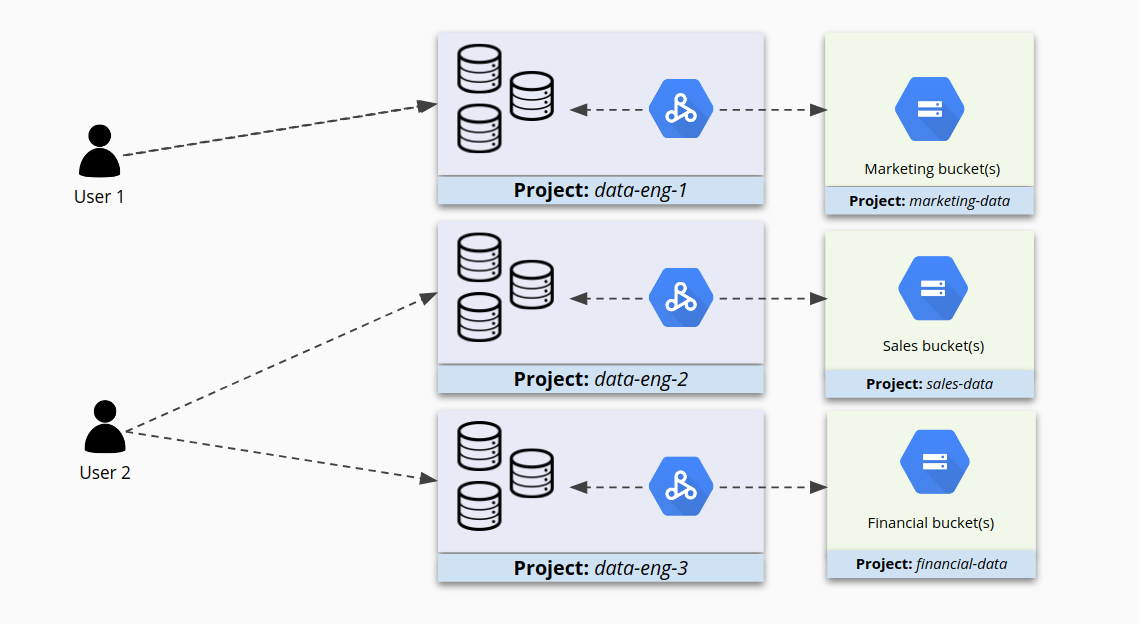
Wenn Sie stattdessen ähnliche Cluster zu kleineren Projekten zusammenfassen und dann IAM für jeden Cluster separat konfigurieren, können Sie den Zugriff genauer steuern. Die Nutzer können jetzt auf die für sie bestimmten Cluster zugreifen, aber nicht auf andere.
Zugriff auf Cluster einschränken
Wenn der Zugriff mithilfe von Dienstkonten gesteuert wird, sind die Interaktionen zwischen Dataproc/Hadoop und anderen Google Cloud-Komponenten abgesichert. Auf diese Weise wird jedoch nicht vollständig kontrolliert, wer auf Dataproc/Hadoop zugreifen kann. Beispielsweise kann ein Nutzer im Cluster in einigen Fällen immer noch eine SSH-Verbindung zum Cluster herstellen oder Aufträge an ihn senden, wenn er die IP-Adresse der Dataproc/Hadoop-Clusterknoten kennt. In der lokalen Umgebung kann der Systemadministrator den Zugriff auf Hadoop-Cluster normalerweise über Subnetze, Firewallregeln, Linux-Authentifizierung und andere Strategien einschränken.
Es gibt viele Möglichkeiten, den Zugriff auf der Ebene der Google Workspace oder Google Cloud-Authentifizierung zu beschränken, wenn Sie Dataproc/Hadoop in Compute Engine ausführen. In diesem Leitfaden geht es jedoch um den Zugriff auf der Ebene der Google Cloud-Komponenten.
SSH-Anmeldung mit OS Login beschränken
Wenn Sie die Nutzer in der lokalen Umgebung am Aufbau einer Verbindung mit einem Hadoop-Knoten hindern möchten, müssen Sie dazu eine Perimeter-Zugriffskontrolle, SSH-Zugriff auf Linux-Ebene und sudoer-Dateien einrichten.
In Google Cloud können Sie auf Nutzerebene SSH-Einschränkungen für die Verbindung mit Compute Engine-Instanzen konfigurieren. Gehen Sie dazu so vor:
- Aktivieren Sie OS Login für Ihr Projekt oder für einzelne Instanzen.
- Weisen Sie sich selbst und anderen Hauptkonten die erforderlichen IAM-Rollen zu.
- Fügen Sie optional benutzerdefinierte SSH-Schlüssel zu den Nutzerkonten für sich selbst und andere Hauptkonten hinzu. Alternativ kann Compute Engine die Schlüssel automatisch generieren, wenn Sie eine Verbindung zu Instanzen herstellen.
Sobald OS Login auf einer oder mehreren Instanzen in Ihrem Projekt aktiviert ist, akzeptieren diese Instanzen nur Verbindungen von Nutzerkonten, die die für Ihr Projekt oder Ihre Organisation erforderlichen IAM-Rollen haben.
Beispielsweise können Sie Nutzern auf folgende Weise Instanzzugriff gewähren:
Weisen Sie den Nutzern die erforderlichen Rollen für den Instanzzugriff zu. Die Nutzer brauchen folgende Rollen:
- Die Rolle
iam.serviceAccountUser Eine der folgenden Log-in-Rollen:
- Die Rolle
compute.osLoginohne Administratorberechtigungen - Die Rolle
compute.osAdminLoginmit Administratorberechtigungen
- Die Rolle
- Die Rolle
Wenn Sie Administrator der Organisation sind und Google-Identitäten von außerhalb Ihrer Organisation Zugriff auf Ihre Instanzen gewähren möchten, weisen Sie diesen externen Identitäten auf Organisationsebene die Rolle
compute.osLoginExternalUserzu. Anschließend müssen Sie den externen Identitäten entweder die Rollecompute.osLoginodercompute.osAdminLoginauf Projekt- oder Organisationsebene zuweisen.
Nach der Konfiguration der erforderlichen Rollen können Sie mit den Compute Engine-Tools Verbindungen zu einer Instanz herstellen. Compute Engine generiert automatisch SSH-Schlüssel und ordnet sie Ihrem Nutzerkonto zu.
Weitere Informationen zu OS Login finden Sie unter Zugriff auf Instanzen mit OS Login verwalten.
Netzwerkzugriff durch Firewallregeln einschränken
In Google Cloud können Sie auch Firewallregeln erstellen, die Dienstkonten verwenden, um eingehenden oder ausgehenden Traffic zu filtern. Diese Vorgehensweise kann in folgenden Fällen besonders gut funktionieren:
- Sie haben eine große Bandbreite an Nutzern oder Anwendungen, die Zugriff auf Hadoop benötigen, sodass es besonders umständlich ist, IP-basierte Regeln aufzustellen.
- Hadoop-Cluster oder Client-VMs werden nur vorübergehend ausgeführt, sodass sich die IP-Adressen häufig ändern.
Durch die Kombination aus Firewallregeln und Dienstkonten können Sie den Zugriff auf einen bestimmten Dataproc/Hadoop-Cluster so steuern, dass nur ein bestimmtes Dienstkonto zugelassen wird. Auf diese Weise können nur VMs, die als dieses Dienstkonto ausgeführt werden, auf der angegebenen Ebene auf den Cluster zugreifen.
Das folgende Diagramm veranschaulicht, wie der Zugriff mithilfe von Dienstkonten eingeschränkt werden kann. dataproc-app-1, dataproc-1, dataproc-2 und app-1-client sind Dienstkonten. Die Firewallregeln lassen zu, dass dataproc-app-1 auf dataproc-1 und dataproc-2 zugreift und dass Clients mithilfe von app-1-client auf dataproc-1 zugreifen. Auf Seite des Speichers sind der Zugriff auf und die Berechtigungen für Cloud Storage durch Cloud Storage-Berechtigungen für Dienstkonten beschränkt. Hier werden keine Firewallregeln verwendet.
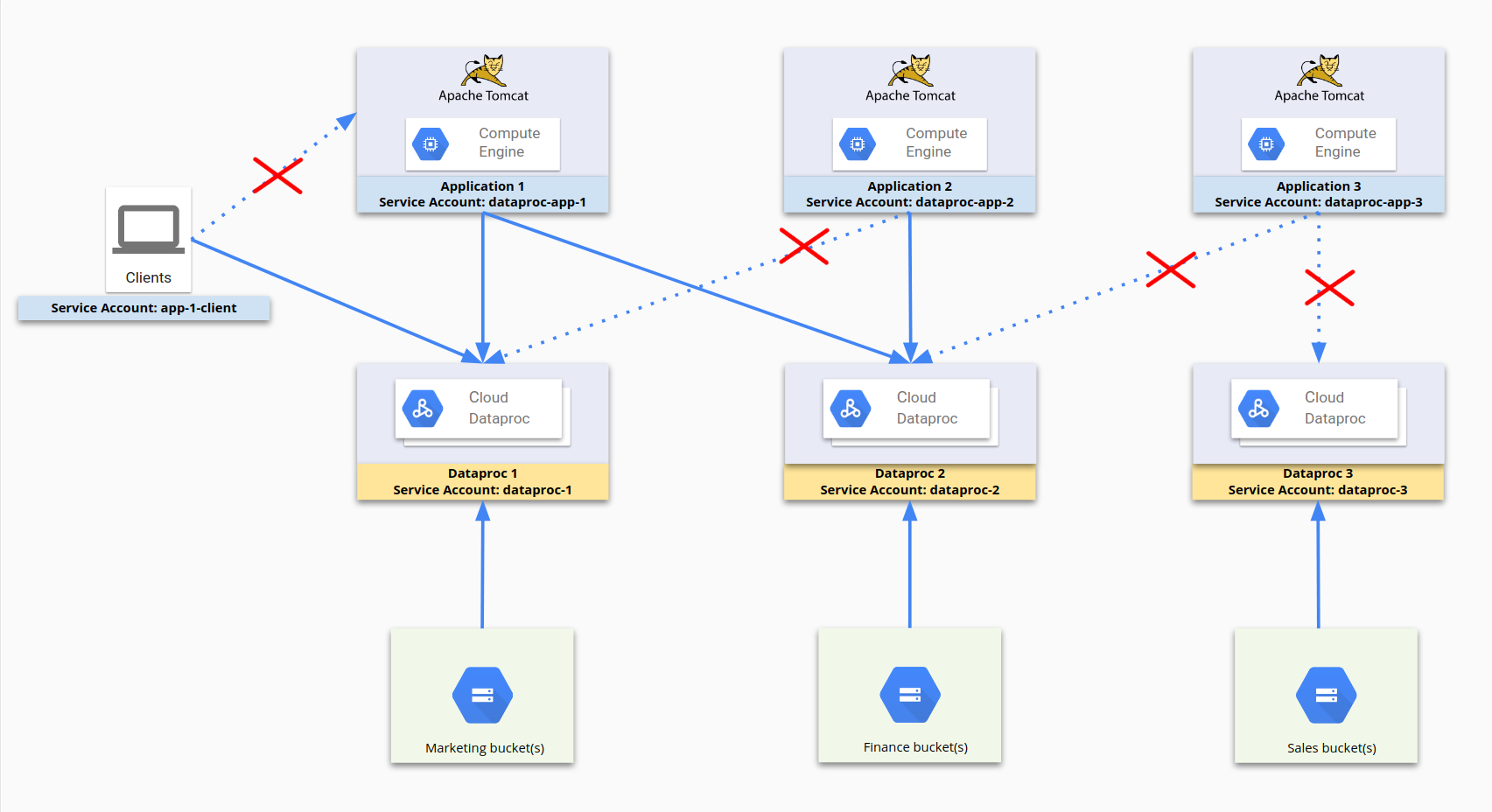
Für diese Konfiguration wurden die folgenden Firewallregeln festgelegt:
| Regelname | Einstellungen |
|---|---|
dp1 |
Ziel: dataproc-1Quelle: [IP-Bereich] Quell-Dienstkonto: dataproc-app-1[Ports] zulassen |
dp2 |
Ziel: dataproc-2Quelle: [IP-Bereich] Quell-Dienstkonto: dataproc-app-2[Ports] zulassen |
dp2-2 |
Ziel: dataproc-2Quelle: [IP-Bereich] Quell-Dienstkonto: dataproc-app-1[Ports] zulassen |
app-1-client |
Ziel: dataproc-1Quelle: [IP-Bereich] Quell-Dienstkonto: app-1-client[Ports] zulassen |
Weitere Informationen zum Einsatz von Firewallregeln mit Dienstkonten finden Sie unter Quell- und Zielfilterung nach Dienstkonto.
Auf unabsichtlich geöffnete Firewallports prüfen
Die richtigen Firewallregeln sind auch dann wichtig, wenn man webbasierte Benutzeroberflächen verfügbar machen möchte, die auf dem Cluster ausgeführt werden. Achten Sie darauf, dass keine Firewallports zum Internet offen sind, die eine Verbindung zu diesen Oberflächen haben. Offene Ports und falsch konfigurierte Firewallregeln können dazu führen, dass unbefugte Nutzer beliebigen Code ausführen können.
Apache Hadoop YARN beispielsweise bietet REST APIs, die dieselben Ports wie die YARN-Weboberflächen nutzen. Nutzer, die auf die YARN-Weboberfläche zugreifen können, können standardmäßig auch Anwendungen erstellen, Jobs senden und möglicherweise sogar Cloud Storage-Vorgänge ausführen.
Prüfen Sie die Dataproc-Netzwerkkonfigurationen und erstellen Sie einen SSH-Tunnel, um eine sichere Verbindung zum Controller Ihres Clusters herzustellen. Weitere Informationen zum Einsatz von Firewallregeln mit Dienstkonten finden Sie unter Quell- und Zielfilterung nach Dienstkonto.
Vorgehensweise bei Clustern mit mehreren Mandanten
Im Allgemeinen empfiehlt es sich, für unterschiedliche Anwendungen separate Dataproc/Hadoop-Cluster auszuführen. Wenn Sie jedoch einen Cluster mit mehreren Mandanten verwenden müssen und nicht gegen Sicherheitsanforderungen verstoßen möchten, können Sie in den Dataproc/Hadoop-Clustern Linux-Nutzer und -Gruppen erstellen und Autorisierung und Ressourcenzuweisung über eine YARN-Warteschlange regeln. Sie müssen die Authentifizierung dann selbst implementieren, denn es gibt keine direkte Zuordnung zwischen Google-Nutzern und Linux-Nutzern. Durch Aktivieren von Kerberos im Cluster kann das Authentifizierungsniveau innerhalb des Clusters gesteigert werden.
Manchmal verwenden menschliche Nutzer, etwa eine Gruppe von Data Scientists, einen Hadoop-Cluster zur Datenermittlung oder zur Modellerstellung. In dieser Situation wäre es sinnvoll, Nutzer mit demselben Datenzugriff in Gruppen zusammenzufassen und einen dedizierten Dataproc/Hadoop-Cluster zu erstellen. Dadurch können später weitere Nutzer in die Gruppe aufgenommen werden, deren Mitglieder auf die Daten zugreifen dürfen. Clusterressourcen können auch anhand ihrer Linux-Nutzer zugewiesen werden.