Dataproc dan Google Cloud berisi beberapa fitur yang dapat membantu mengamankan data Anda. Panduan ini menjelaskan cara kerja keamanan Hadoop dan bagaimana hal itu diterjemahkan ke Google Cloud, yang memberikan panduan tentang cara merancang keamanan saat melakukan deployment di Google Cloud.
Ringkasan
Model dan mekanisme keamanan umum untuk deployment Hadoop lokal berbeda dengan model dan mekanisme keamanan yang disediakan oleh cloud. Memahami keamanan di Hadoop dapat membantu Anda merancang keamanan dengan lebih baik saat melakukan deployment di Google Cloud.
Anda dapat men-deploy Hadoop di Google Cloud dengan dua cara: sebagai cluster yang dikelola Google (Dataproc), atau sebagai cluster yang dikelola pengguna (Hadoop di Compute Engine). Sebagian besar konten dan panduan teknis dalam panduan ini berlaku untuk kedua bentuk deployment. Panduan ini menggunakan istilah Dataproc/Hadoop jika mengacu pada konsep atau prosedur yang berlaku untuk salah satu jenis deployment. Panduan ini menunjukkan beberapa kasus terjadinya deployment ke Dataproc yang berbeda dengan deployment ke Hadoop di Compute Engine.
Keamanan Hadoop lokal yang umum
Diagram berikut menunjukkan infrastruktur Hadoop lokal yang umum dan cara pengamanannya. Perhatikan bagaimana komponen Hadoop dasar berinteraksi satu sama lain dan dengan sistem pengelolaan pengguna.
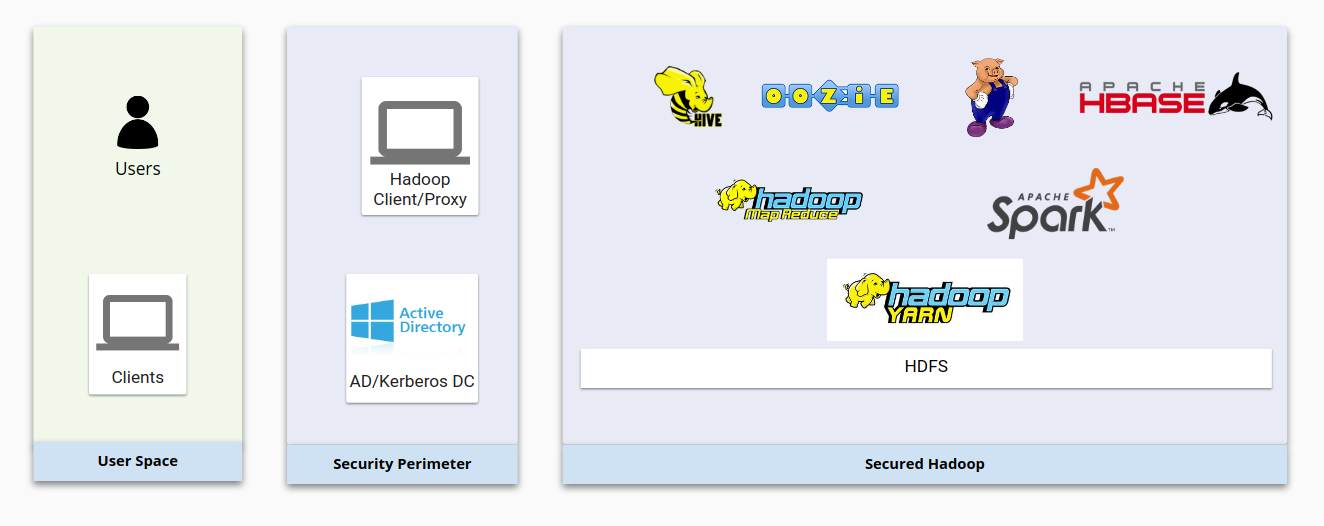
Secara keseluruhan, keamanan Hadoop didasarkan pada empat pilar berikut:
- Autentikasi disediakan melalui Kerberos yang terintegrasi dengan LDAP atau Active Directory
- Otorisasi disediakan melalui HDFS dan produk keamanan seperti Apache Sentry atau Apache Ranger, yang memastikan bahwa pengguna memiliki akses yang tepat ke resource Hadoop.
- Enkripsi disediakan melalui enkripsi jaringan dan enkripsi HDFS, yang bersama-sama mengamankan data saat dalam pengiriman dan dalam penyimpanan.
- Audit disediakan oleh produk yang disediakan vendor seperti Cloudera Navigator.
Dari perspektif akun pengguna, Hadoop memiliki struktur pengguna dan grupnya sendiri untuk mengelola identitas dan menjalankan daemon. Misalnya, daemon Hadoop HDFS dan YARN, dijalankan sebagai pengguna Unix hdfs dan yarn, seperti yang dijelaskan dalam Hadoop dalam Mode Aman.
Pengguna Hadoop biasanya dipetakan dari pengguna sistem Linux atau pengguna Active Directory/LDAP. Pengguna dan grup Active Directory disinkronkan oleh alat seperti Centrify atau RedHat SSSD.
Autentikasi lokal Hadoop
Sistem yang aman mengharuskan pengguna dan layanan untuk membuktikan dirinya ke sistem. Mode aman Hadoop menggunakan Kerberos untuk autentikasi. Sebagian besar komponen Hadoop dirancang menggunakan Kerberos sebagai autentikasi. Kerberos biasanya diimplementasikan dalam sistem autentikasi perusahaan seperti Active Directory atau sistem yang sesuai dengan LDAP.
Prinsip utama Kerberos
Pengguna di Kerberos disebut akun utama. Dalam penerapan Hadoop, ada akun utama pengguna dan akun utama layanan. Akun utama pengguna biasanya disinkronkan dari Active Directory atau sistem pengelolaan pengguna lainnya ke pusat distribusi kunci (KDC). Satu akun utama pengguna mewakili satu pengguna manusia. Akun utama layanan bersifat unik untuk layanan per server, sehingga setiap layanan di setiap server memiliki satu akun utama yang unik untuk mewakilinya.
File keytab
File keytab berisi akun utama Kerberos dan kuncinya. Pengguna dan layanan dapat menggunakan keytab untuk melakukan autentikasi pada layanan Hadoop tanpa menggunakan alat interaktif dan memasukkan sandi. Hadoop membuat akun utama layanan untuk setiap layanan pada setiap node Akun utama ini disimpan dalam file keytab di node Hadoop.
SPNEGO
Jika Anda mengakses cluster Kerberos menggunakan browser web, browser harus mengetahui cara meneruskan kunci Kerberos. Di sinilah Mekanisme Negosiasi GSS-API yang Sederhana dan Terlindungi (SPNEGO) hadir, yang menyediakan cara untuk menggunakan Kerberos dalam aplikasi web.
Integrasi
Hadoop terintegrasi dengan Kerberos tidak hanya untuk autentikasi pengguna, tetapi juga untuk autentikasi layanan. Setiap layanan Hadoop pada setiap node akan memiliki akun utama Kerberos sendiri, yang digunakannya untuk melakukan autentikasi. Layanan biasanya memiliki file keytab yang disimpan di server yang berisi sandi acak.
Untuk dapat berinteraksi dengan layanan, pengguna manusia biasanya perlu mendapatkan
tiket Kerberos melalui perintah kinit atau Centrify atau SSSD.
Otorisasi lokal Hadoop
Setelah identitas divalidasi, sistem otorisasi akan memeriksa jenis akses yang dimiliki pengguna atau layanan. Pada Hadoop, beberapa project open source seperti Apache Sentry dan Apache Ranger digunakan untuk memberikan otorisasi.
Apache Sentry dan Apache Ranger
Apache Sentry dan Apache Ranger adalah mekanisme otorisasi umum yang digunakan di cluster Haadoop. Komponen di Hadoop mengimplementasikan pluginnya sendiri ke Sentry atau Ranger untuk menentukan cara berperilaku saat Sentry atau Ranger mengonfirmasi atau menolak akses ke identitas. Sentry dan Ranger mengandalkan sistem autentikasi seperti Kerberos, LDAP, atau AD. Mekanisme pemetaan grup di Hadoop memastikan bahwa Sentry atau Ranger melihat pemetaan grup yang sama dengan yang dilihat oleh komponen ekosistem Hadoop lainnya.
Izin HDFS dan ACL
HDFS menggunakan sistem izin mirip POSIX dengan daftar kontrol akses (ACL) untuk menentukan apakah pengguna memiliki akses ke file atau tidak. Setiap file dan direktori terkait dengan pemilik dan grup. Struktur ini memiliki folder root yang dimiliki oleh superuser. Level struktur yang berbeda dapat memiliki enkripsi yang berbeda, dan kepemilikan, izin, serta ACL yang diperluas (facl) yang berbeda.
Seperti yang ditunjukkan pada diagram berikut, izin biasanya diberikan di level direktori kepada grup tertentu berdasarkan kebutuhan akses mereka. Pola akses diidentifikasi sebagai peran yang berbeda dan dipetakan ke grup Active Directory. Objek yang termasuk dalam satu set data umumnya berada di lapisan yang memiliki izin untuk grup tertentu, dengan direktori yang berbeda untuk kategori data yang berbeda.
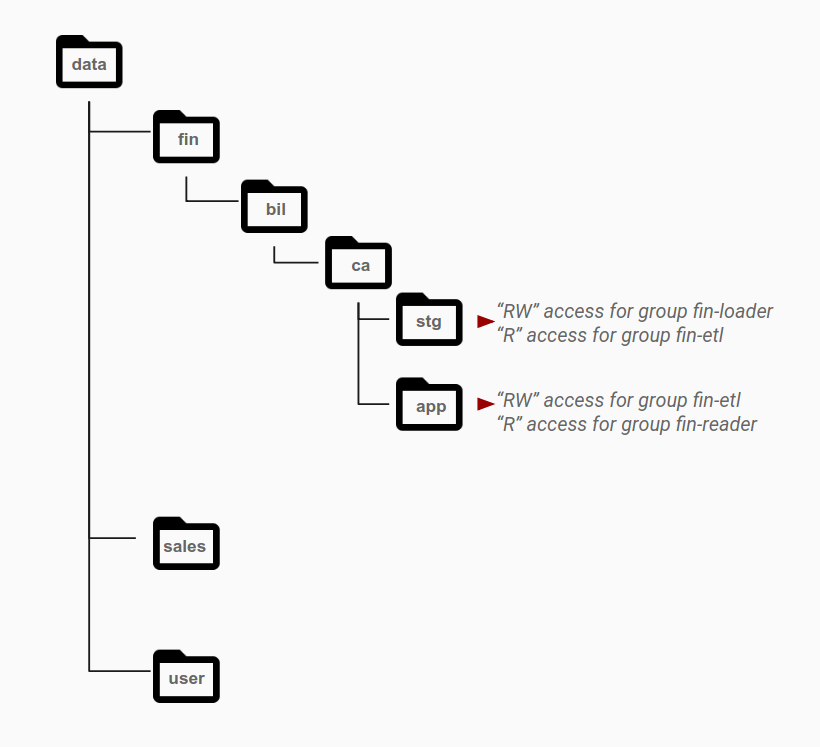
Misalnya, direktori stg adalah area staging untuk data keuangan. Folder
stg memiliki izin baca dan tulis untuk grup fin-loader. Dari
area staging ini, grup akun aplikasi lain, fin-etl, yang
mewakili pipeline ETL, memiliki akses hanya baca ke direktori ini. Pipeline ETL
memproses data dan menyimpannya ke dalam direktori app untuk ditayangkan. Untuk mengaktifkan
pola akses ini, direktori app memiliki akses baca/tulis untuk grup fin-etl
, yang merupakan identitas yang digunakan untuk menulis data ETL, dan akses hanya
baca untuk grup fin-reader yang memakai data yang dihasilkan.
Enkripsi lokal Hadoop
Hadoop menyediakan cara untuk mengenkripsi data dalam penyimpanan dan data dalam pengiriman. Untuk mengenkripsi data dalam penyimpanan, Anda dapat mengenkripsi HDFS dengan menggunakan enkripsi kunci berbasis Java atau solusi enkripsi yang disediakan vendor. HDFS mendukung zona enkripsi untuk memungkinkan mengenkripsi file yang berbeda menggunakan kunci yang berbeda. Setiap zona enkripsi dikaitkan dengan satu kunci zona enkripsi yang ditentukan saat zona dibuat.
Setiap file dalam zona enkripsi memiliki kunci enkripsi data (DEK) yang unik. DEK tidak pernah ditangani secara langsung oleh HDFS. Sebaliknya, HDFS hanya akan menangani kunci enkripsi data (EDEK) terenkripsi. Klien mendekripsi EDEK, lalu menggunakan DEK berikutnya untuk membaca dan menulis data. Node data HDFS hanya melihat aliran byte yang dienkripsi.
Transit data antara node Hadoop dapat dienkripsi menggunakan Transport Layer Security (TLS). TLS menyediakan enkripsi dan autentikasi dalam komunikasi antara dua komponen dari Hadoop. Biasanya Hadoop akan menggunakan sertifikat internal yang ditandatangani CA untuk TLS antarkomponen.
Audit lokal Hadoop
Bagian penting dari keamanan adalah audit. Audit membantu Anda menemukan aktivitas yang mencurigakan dan memberikan catatan tentang siapa yang memiliki akses ke resource. Cloudera Navigator dan alat pihak ketiga lainnya biasanya digunakan untuk tujuan pengelolaan data, seperti pelacakan audit di Hadoop. Alat ini memberikan visibilitas dan kontrol atas data di datastore Hadoop serta komputasi yang dilakukan pada data tersebut. Audit data dapat mencatat catatan lengkap dan tidak dapat diubah semua aktivitas dalam suatu sistem.
Hadoop di Google Cloud
Dalam lingkungan Hadoop lokal tradisional, empat pilar keamanan Hadoop (autentikasi, otorisasi, enkripsi, dan audit) terintegrasi dan ditangani oleh berbagai komponen. Di Google Cloud, layanan tersebut ditangani oleh berbagai komponen Google Cloud secara eksternal ke Dataproc dan Hadoop di Compute Engine.
Anda dapat mengelola resource Google Cloud menggunakan konsol Google Cloud, yang merupakan antarmuka berbasis web. Anda juga dapat menggunakan Google Cloud CLI, yang bisa lebih cepat dan nyaman jika Anda terbiasa bekerja di command line. Anda dapat menjalankan perintah gcloud dengan menginstal gcloud CLI di komputer lokal, atau dengan menggunakan instance Cloud Shell.
Autentikasi Google Cloud Hadoop
Ada dua jenis identitas Google dalam Google Cloud: akun layanan dan akun pengguna. Sebagian besar Google API memerlukan autentikasi dengan identitas Google. Sejumlah Google Cloud API akan berfungsi tanpa autentikasi (menggunakan kunci API), tetapi sebaiknya gunakan semua API dengan autentikasi akun layanan.
Akun layanan menggunakan kunci pribadi untuk membuat identitas. Akun pengguna menggunakan protokol OAUTH 2.0 untuk mengautentikasi pengguna akhir. Untuk mengetahui informasi selengkapnya, lihat Ringkasan Autentikasi.
Otorisasi Google Cloud Hadoop
Google Cloud menyediakan beberapa cara untuk menentukan izin yang dimiliki identitas terautentikasi untuk satu set resource.
IAM
Google Cloud menawarkan Identity and Access Management (IAM), yang memungkinkan Anda mengelola kontrol akses dengan menentukan pengguna (akun utama) yang memiliki akses (peran) untuk resource tertentu.
Dengan IAM, Anda dapat memberikan akses ke resource Google Cloud dan mencegah akses yang tidak diinginkan ke resource lainnya. IAM memungkinkan Anda menerapkan prinsip keamanan dengan hak istimewa terendah, jadi Anda hanya memberikan akses minimum yang diperlukan ke resource Anda.
Akun layanan
Akun layanan adalah jenis Akun Google khusus milik aplikasi Anda atau virtual machine (VM), bukan milik pengguna akhir perorangan. Aplikasi dapat menggunakan kredensial akun layanan untuk mengautentikasi dirinya dengan Cloud API lainnya. Selain itu, Anda dapat membuat aturan firewall yang mengizinkan atau menolak traffic ke dan dari instance berdasarkan akun layanan yang ditetapkan untuk setiap instance.
Cluster Dataproc dibangun di atas VM Compute Engine. Jika akun layanan kustom ditetapkan saat membuat cluster Dataproc, akun layanan tersebut akan ditetapkan ke semua VM di cluster Anda. Langkah ini akan memberi cluster Anda akses dan kontrol terperinci atas resource Google Cloud. Jika Anda tidak menentukan akun layanan, VM Dataproc akan menggunakan akun layanan Compute Engine default yang dikelola Google. Akun ini secara default memiliki peran editor project yang luas, sehingga memberinya berbagai izin. Sebaiknya jangan gunakan akun layanan default untuk membuat cluster Dataproc di lingkungan produksi.
Izin akun layanan
Saat Anda menetapkan akun layanan kustom ke cluster Dataproc/Hadoop, tingkat akses akun layanan tersebut ditentukan oleh kombinasi cakupan akses yang diberikan ke instance VM cluster dan peran IAM yang diberikan ke akun layanan Anda. Untuk menyiapkan instance menggunakan akun layanan kustom, Anda perlu mengonfigurasi cakupan akses dan peran IAM. Pada dasarnya, mekanisme ini berinteraksi dengan cara berikut:
- Cakupan akses mengizinkan akses yang dimiliki instance.
- IAM membatasi akses tersebut ke peran yang diberikan ke akun layanan yang digunakan instance.
- Izin di persimpangan cakupan akses dan peran IAM adalah izin akhir yang dimiliki instance.
Saat membuat cluster Dataproc atau instance Compute Engine di konsol Google Cloud, pilih cakupan akses instance:
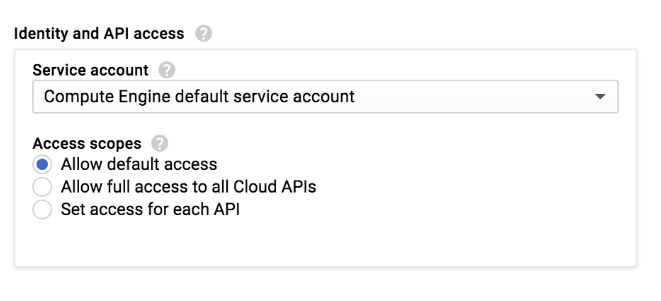
Cluster Dataproc atau instance Compute Engine memiliki sekumpulan cakupan akses yang ditentukan untuk digunakan dengan setelan Izinkan akses default:
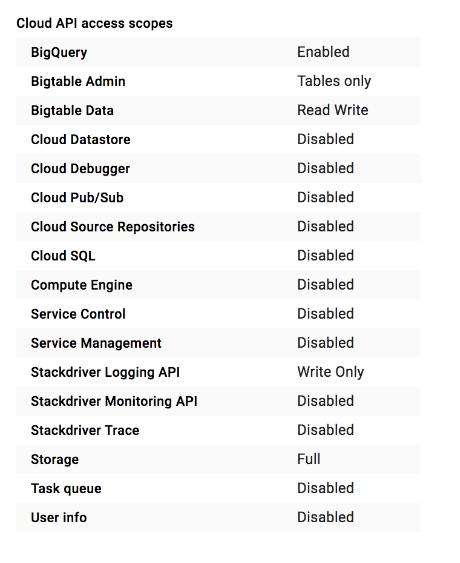
Ada
banyak cakupan akses
yang dapat Anda pilih. Sebaiknya saat Anda membuat instance VM atau
cluster baru, tetapkan Izinkan akses penuh ke semua Cloud API (di konsol) atau
cakupan akses https://www.googleapis.com/auth/cloud-platform (jika Anda menggunakan
Google Cloud CLI). Cakupan ini mengizinkan akses ke semua
layanan Google Cloud. Setelah Anda menetapkan cakupan, sebaiknya
batasi akses tersebut dengan menetapkan peran IAM ke akun
layanan cluster.
Akun tersebut tidak dapat melakukan tindakan apa pun di luar peran ini, meskipun ada cakupan akses Google Cloud. Untuk mengetahui detail selengkapnya, lihat dokumentasi izin akun layanan.
Membandingkan IAM dengan Apache Sentry dan Apache Ranger
IAM memiliki peran yang mirip dengan Apache Sentry dan Apache Ranger. IAM menentukan akses melalui peran. Akses ke komponen Google Cloud lainnya ditentukan dalam peran-peran tersebut dan dikaitkan dengan akun layanan. Ini berarti semua instance yang menggunakan akun layanan yang sama memiliki akses yang sama ke resource Google Cloud lainnya. Siapa pun yang memiliki akses ke instance ini juga memiliki akses yang sama ke resource Google Cloud ini seperti yang dimiliki akun layanan.
Cluster Dataproc dan instance Compute Engine tidak memiliki mekanisme untuk memetakan pengguna dan grup Google ke pengguna dan grup Linux. Tapi, Anda dapat membuat pengguna dan grup Linux. Di dalam cluster Dataproc atau di dalam VM Compute Engine, izin HDFS serta pemetaan pengguna dan grup Hadoop masih berfungsi. Pemetaan ini dapat digunakan untuk membatasi akses ke HDFS atau menerapkan alokasi resource menggunakan antrean YARN.
Ketika aplikasi di cluster Dataproc atau VM Compute Engine perlu mengakses resource di luar seperti Cloud Storage atau BigQuery, aplikasi tersebut akan diautentikasi sebagai identitas akun layanan yang Anda tetapkan ke VM di cluster. Kemudian, gunakan IAM untuk memberi akun layanan khusus cluster Anda level akses minimum yang diperlukan oleh aplikasi Anda.
Izin Cloud Storage
Dataproc menggunakan Cloud Storage sebagai sistem penyimpanannya. Dataproc juga menyediakan sistem HDFS lokal, tetapi HDFS tidak akan tersedia jika cluster Dataproc dihapus. Jika aplikasi tidak terlalu bergantung pada HDFS, sebaiknya gunakan Cloud Storage untuk memanfaatkan Google Cloud sepenuhnya.
Cloud Storage tidak memiliki hierarki penyimpanan. Struktur direktori menyimulasikan struktur sistem file. API ini juga tidak memiliki izin seperti POSIX. Kontrol akses oleh akun pengguna IAM dan akun layanan dapat ditetapkan di level bucket. Tidak menerapkan izin akses berdasarkan pengguna Linux.
Enkripsi Google Cloud Hadoop
Dengan beberapa pengecualian kecil, layanan Google Cloud mengenkripsi konten pelanggan dalam penyimpanan dan dalam pengiriman menggunakan berbagai metode enkripsi. Enkripsi bersifat otomatis, dan tidak memerlukan tindakan dari pelanggan.
Misalnya, semua data baru yang disimpan di persistent disk dienkripsi menggunakan Advanced Encryption Standard (AES-256) 256 bit, dan setiap kunci enkripsi itu sendiri dienkripsi dengan serangkaian kunci root (master) yang dirotasi secara berkala. Google Cloud menggunakan kebijakan pengelolaan kunci dan enkripsi, library kriptografis, dan root of trust yang sama dengan yang digunakan untuk banyak layanan produksi Google, termasuk Gmail dan data perusahaan Google.
Enkripsi adalah fitur default Google Cloud (tidak seperti kebanyakan implementasi Hadoop lokal), Anda tidak perlu khawatir untuk menerapkan enkripsi kecuali jika Anda ingin menggunakan kunci enkripsi Anda sendiri. Google Cloud juga menyediakan solusi kunci enkripsi yang dikelola pelanggan dan solusi kunci enkripsi yang disediakan pelanggan. Jika perlu mengelola kunci enkripsi sendiri atau menyimpan kunci enkripsi secara lokal, Anda bisa melakukannya.
Untuk mengetahui detail selengkapnya, lihat enkripsi dalam penyimpanan dan enkripsi saat pengiriman.
Audit Google Cloud Hadoop
Cloud Audit Logs dapat menyimpan beberapa jenis log untuk setiap project dan organisasi. Layanan Google Cloud menulis entri log audit ke log ini untuk membantu Anda menjawab pertanyaan "siapa yang melakukan apa, di mana, dan kapan?" dalam project Google Cloud Anda.
Untuk mengetahui informasi lebih lanjut tentang layanan dan log audit yang menulis log audit, lihat dokumentasi Cloud Audit Logs.
Proses migrasi
Untuk membantu menjalankan operasi Hadoop yang aman dan efisien di Google Cloud, ikuti proses yang diuraikan di bagian ini.
Di bagian ini, kami berasumsi bahwa Anda telah menyiapkan lingkungan Google Cloud. Ini termasuk membuat pengguna dan grup di Google Workspace. Pengguna dan grup ini dikelola secara manual atau disinkronkan dengan Active Directory, dan Anda telah mengonfigurasi semuanya sehingga Google Cloud berfungsi sepenuhnya dalam hal autentikasi pengguna.
Menentukan siapa yang akan mengelola identitas
Sebagian besar pelanggan Google menggunakan Cloud Identity untuk mengelola identitas. Namun, ada beberapa perusahaan yang mengelola identitas perusahaan mereka secara terpisah dari identitas Google Cloud. Dalam hal ini, izin POSIX dan SSH mereka menentukan akses pengguna akhir ke resource cloud.
Jika memiliki sistem identitas independen, Anda dapat memulai dengan membuat kunci akun layanan Google Cloud dan mendownloadnya. Kemudian, Anda dapat menghubungkan model keamanan POSIX dan SSH lokal dengan model Google Cloud dengan memberikan izin akses bergaya POSIX yang sesuai ke file kunci akun layanan yang didownload. Izinkan atau tolak akses identitas lokal Anda ke keyfile ini.
Jika Anda mengikuti cara ini, kemampuan untuk dapat diaudit akan dilakukan oleh sistem pengelolaan identitas Anda sendiri. Untuk menyediakan jejak audit, Anda dapat menggunakan log SSH (yang menyimpan keyfile akun layanan) login pengguna pada node edge, atau Anda dapat memilih mekanisme keystore yang lebih berat dan eksplisit untuk mengambil layanan-kredensial akun dari pengguna. Dalam hal ini, "peniruan akun layanan" dicatat di audit pada lapisan keystore.
Menentukan apakah akan menggunakan satu project data atau beberapa project data
Jika organisasi Anda memiliki banyak data, artinya membagi data ke bucket Cloud Storage yang berbeda. Anda juga perlu memikirkan cara mendistribusikan bucket data ini di antara proyek-proyek Anda. Anda mungkin tergoda untuk memindahkan data dalam jumlah kecil saat mulai menggunakan Google Cloud, dan memindahkan lebih banyak data seiring waktu sejalan dengan perkembangan workload dan aplikasi.
Menempatkan semua bucket data dalam satu project tampak praktis, namun sering kali bukanlah merupakan pendekatan yang baik. Untuk mengelola akses ke data, gunakan struktur direktori yang diratakan dengan peran IAM untuk bucket. Pengelolaan bucket bisa jadi sulit ketika jumlah bucket bertambah.
Alternatifnya adalah menyimpan data dalam beberapa project yang masing-masing dikhususkan untuk organisasi yang berbeda, yaitu project untuk departemen keuangan, project untuk grup hukum, dan seterusnya. Dalam hal ini, setiap grup mengelola izinnya sendiri secara independen.
Selama pemrosesan data, Anda mungkin perlu mengakses atau membuat bucket ad hoc. Pemrosesan dapat dibagi melintasi batas kepercayaan, seperti ilmuwan data yang mengakses data yang dihasilkan oleh proses yang bukan milik mereka.
Diagram berikut menunjukkan organisasi data standar di Cloud Storage dalam satu project data dan dalam beberapa project data.
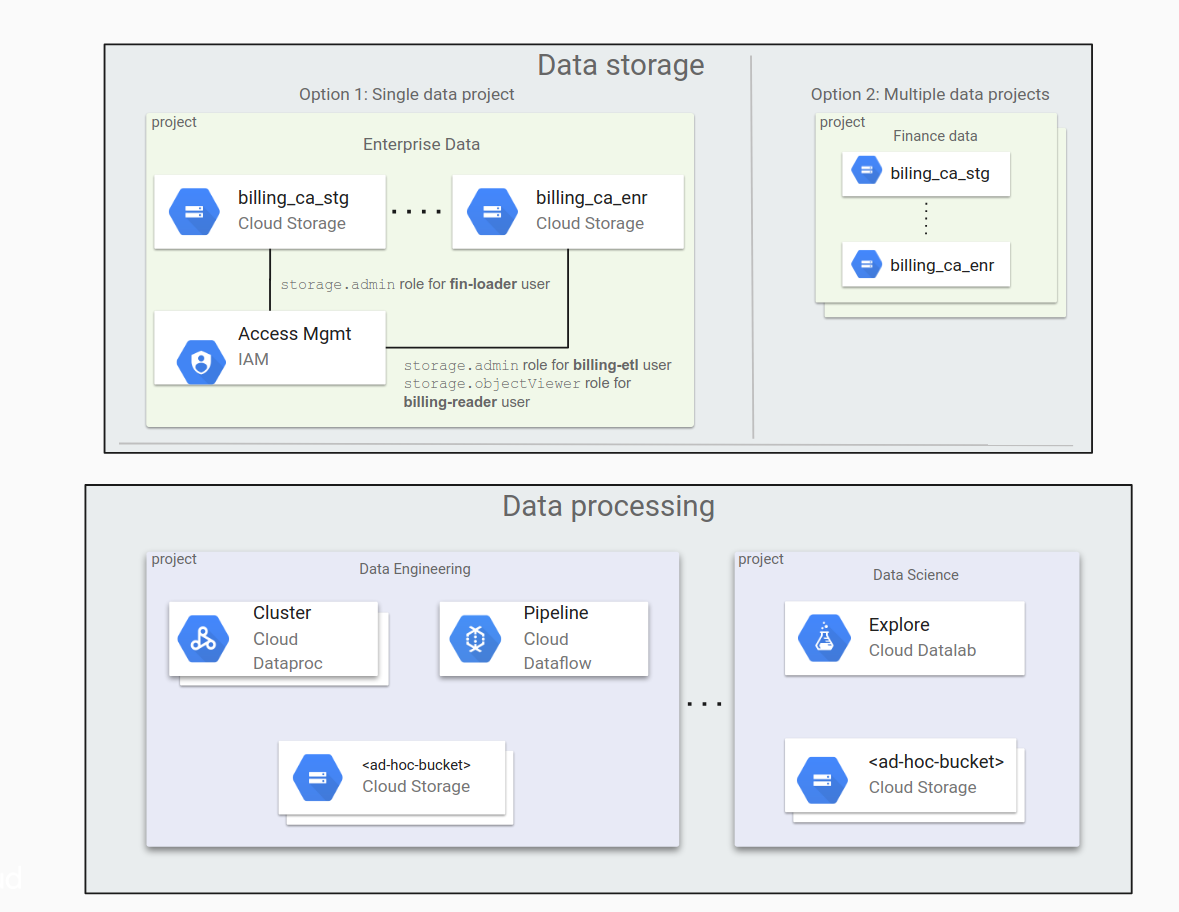
Berikut adalah poin-poin utama yang perlu dipertimbangkan saat menentukan pendekatan yang terbaik untuk organisasi Anda.
Dengan satu project data:
- Mengelola semua bucket menjadi mudah, asalkan jumlah bucket kecil.
- Pemberian izin sebagian besar dilakukan oleh anggota grup admin.
Dengan beberapa project data:
- Akan lebih mudah untuk mendelegasikan tanggung jawab manajemen kepada pemilik proyek.
- Pendekatan ini berguna bagi organisasi yang memiliki proses pemberian izin berbeda. Misalnya, proses pemberian izin untuk project departemen pemasaran mungkin berbeda dengan untuk project departemen hukum.
Mengidentifikasi aplikasi dan membuat akun layanan
Saat cluster Dataproc/Hadoop berinteraksi dengan
resource Google Cloud lainnya seperti dengan Cloud Storage, Anda harus
mengidentifikasi semua aplikasi yang akan berjalan di Dataproc/Hadoop dan
akses yang diperlukan. Misalnya, ada tugas ETL yang
mengisi data keuangan di California ke bucket financial-ca. Tugas ETL ini
akan memerlukan akses baca dan tulis ke bucket. Setelah mengidentifikasi
aplikasi yang akan menggunakan Hadoop, Anda dapat membuat akun layanan untuk setiap
aplikasi tersebut.
Perlu diingat bahwa akses ini tidak memengaruhi pengguna Linux di dalam cluster Dataproc atau di Hadoop pada Compute Engine.
Untuk informasi selengkapnya tentang Akun Layanan, lihat Membuat dan Mengelola Akun Layanan.
Memberikan izin ke akun layanan
Setelah mengetahui akses yang harus dimiliki setiap aplikasi ke bucket Cloud Storage yang berbeda, Anda dapat menetapkan izin tersebut pada akun layanan aplikasi yang relevan. Jika aplikasi Anda juga perlu mengakses komponen Google Cloud lainnya, seperti BigQuery atau Bigtable, Anda juga dapat memberikan izin ke komponen tersebut menggunakan akun layanan.
Misalnya, Anda dapat menetapkan operation-ca-etl sebagai aplikasi ETL untuk
menghasilkan laporan operasi dengan mengumpulkan data pemasaran dan penjualan dari
California, sehingga memberikan izin untuk menulis laporan ke bucket data
departemen keuangan. Kemudian, Anda dapat menetapkan aplikasi marketing-report-ca dan sales-report-ca
agar masing-masing memiliki akses baca dan tulis ke departemennya sendiri. Diagram
berikut mengilustrasikan penyiapan ini.
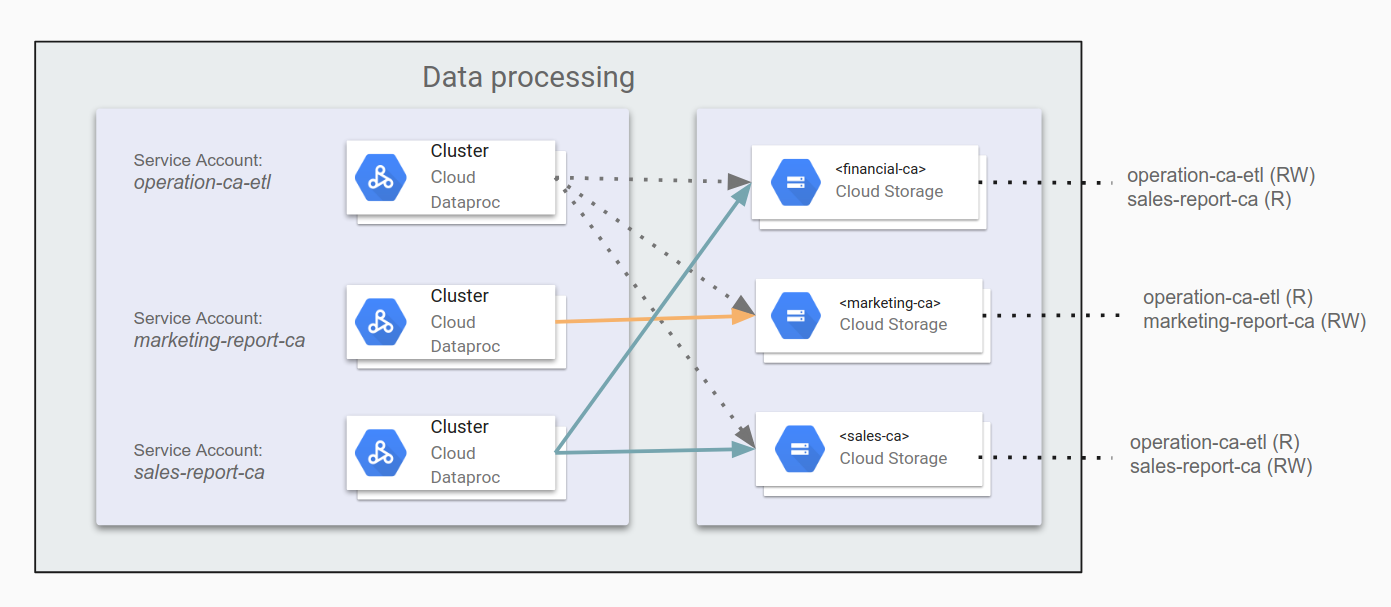
Anda harus mengikuti prinsip hak istimewa terendah. Prinsip ini menetapkan bahwa Anda hanya memberikan izin minimum yang diperlukan untuk setiap pengguna atau akun layanan untuk melakukan satu tugas atau banyak tugasnya. Izin default di Google Cloud dioptimalkan untuk memberikan kemudahan penggunaan dan mengurangi waktu penyiapan. Untuk mem-build infrastruktur Hadoop yang kemungkinan lulus peninjauan keamanan dan kepatuhan, Anda harus mendesain izin yang lebih ketat. Melakukan investasi upaya sejak awal, dan mendokumentasikan strategi tersebut, tidak hanya membantu menyediakan pipeline yang aman dan mematuhi kebijakan, tetapi juga membantu jika sudah saatnya meninjau arsitektur dengan tim keamanan dan kepatuhan.
Membuat cluster
Setelah merencanakan dan mengonfigurasi akses, Anda dapat membuat cluster Dataproc atau Hadoop di Compute Engine dengan akun layanan yang telah dibuat. Setiap cluster akan memiliki akses ke komponen Google Cloud lainnya berdasarkan izin yang telah Anda berikan ke akun layanan tersebut. Pastikan Anda memberikan cakupan atau cakupan akses yang benar untuk akses ke Google Cloud, lalu sesuaikan dengan akses akun layanan. Jika muncul masalah akses, terutama untuk Hadoop di Compute Engine, pastikan untuk memeriksa izin ini.
Untuk membuat cluster Dataproc dengan akun layanan tertentu, gunakan
perintah gcloud ini:
gcloud dataproc clusters create [CLUSTER_NAME] \
--service-account=[SERVICE_ACCOUNT_NAME]@[PROJECT+_ID].iam.gserviceaccount.comn \
--scopes=scope[, ...]
Alasan berikut menyebabkan Anda untuk sebaiknya menghindari penggunaan akun layanan Compute Engine default:
- Jika beberapa cluster dan VM Compute Engine menggunakan akun layanan Compute Engine default, proses audit akan menjadi sulit.
- Setelan project untuk akun layanan Compute Engine default dapat bervariasi, yang berarti project tersebut mungkin memiliki lebih banyak hak istimewa daripada kebutuhan cluster Anda.
- Perubahan pada akun layanan Compute Engine default mungkin memengaruhi atau bahkan merusak cluster Anda dan aplikasi yang berjalan di dalamnya secara tidak sengaja.
Pertimbangkan untuk menetapkan izin IAM untuk setiap cluster
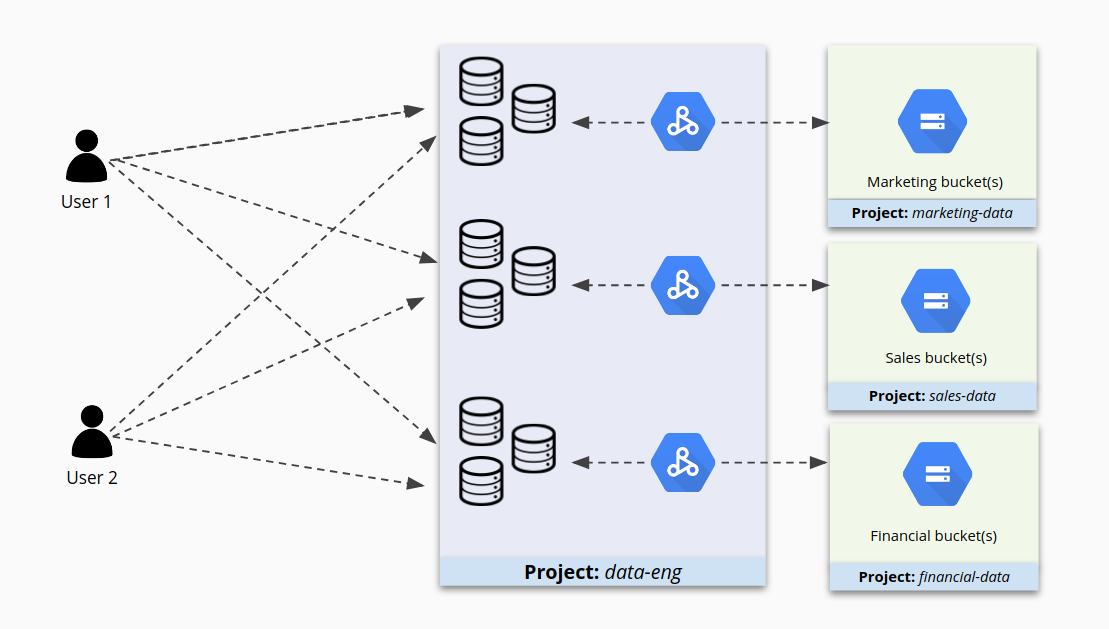
Menempatkan banyak cluster dalam satu project dapat memudahkan pengelolaan cluster tersebut, tetapi mungkin bukan cara terbaik untuk mengamankan akses ke cluster tersebut. Misalnya, dengan adanya cluster 1 dan 2 di project A, beberapa pengguna mungkin memiliki hak istimewa yang tepat untuk menangani cluster 1, tetapi mungkin juga memiliki terlalu banyak izin untuk cluster 2. Atau lebih buruk lagi, mereka mungkin memiliki akses ke cluster 2 hanya karena berada dalam project tersebut ketika mereka seharusnya tidak memiliki akses.
Jika project berisi banyak cluster, akses ke cluster tersebut dapat merepotkan, seperti yang ditunjukkan pada gambar berikut.
Jika Anda mengelompokkan beberapa cluster bersama ke dalam project yang lebih kecil, lalu mengonfigurasi IAM secara terpisah untuk setiap cluster, Anda akan memiliki tingkat kontrol yang lebih baik atas akses. Sekarang pengguna memiliki akses ke cluster yang ditujukan untuk mereka dan dibatasi sehingga tidak dapat mengakses pengguna lain.
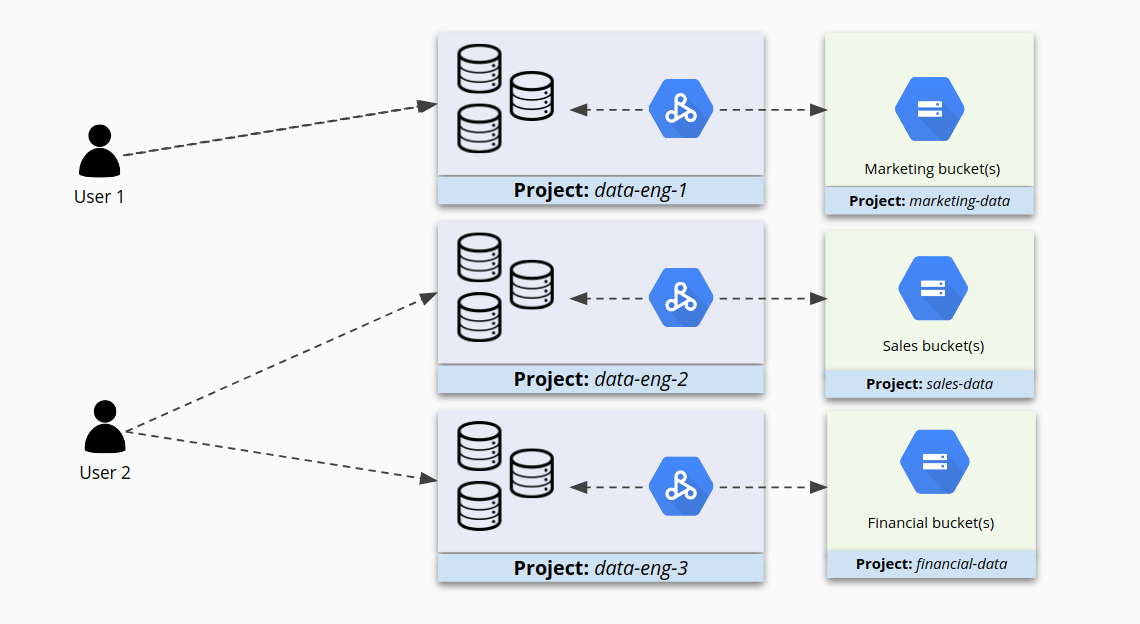
Membatasi akses ke cluster
Menetapkan akses menggunakan akun layanan akan mengamankan interaksi antara Dataproc/Hadoop dan komponen Google Cloud lainnya. Namun, hal ini tidak sepenuhnya mengontrol siapa yang dapat mengakses Dataproc/Hadoop. Misalnya, pengguna dalam cluster yang memiliki alamat IP node cluster Dataproc/Hadoop masih dapat menggunakan SSH untuk terhubung (dalam beberapa kasus) atau mengirimkan tugas ke cluster tersebut. Di lingkungan lokal, administrator sistem biasanya memiliki subnet, aturan firewall, autentikasi Linux, dan strategi lainnya untuk membatasi akses ke cluster Hadoop.
Ada banyak cara untuk membatasi akses di level autentikasi Google Workspace atau Google Cloud saat Anda menjalankan Dataproc/Hadoop di Compute Engine. Namun, panduan ini berfokus pada akses di level komponen Google Cloud.
Membatasi login SSH menggunakan login OS
Di lingkungan lokal, untuk membatasi pengguna agar tidak terhubung ke node Hadoop, Anda perlu menyiapkan kontrol akses perimeter, akses SSH level Linux, dan file sudoer.
Di Google Cloud, Anda dapat mengonfigurasi pembatasan SSH level pengguna untuk terhubung ke instance Compute Engine menggunakan proses berikut:
- Aktifkan fitur Login OS pada project Anda atau pada instance individual.
- Berikan peran IAM yang diperlukan kepada Anda sendiri dan akun utama lainnya.
- Jika ingin, tambahkan kunci SSH kustom ke akun pengguna untuk Anda sendiri dan akun utama lainnya. Atau, Compute Engine dapat otomatis membuat kunci ini saat Anda terhubung ke instance.
Setelah Anda mengaktifkan Login OS pada satu atau beberapa instance dalam project, instance tersebut hanya menerima koneksi dari akun pengguna yang memiliki peran IAM yang diperlukan dalam project atau organisasi Anda.
Contohnya, Anda dapat memberikan akses instance kepada pengguna dengan proses berikut:
Berikan peran akses instance yang diperlukan kepada pengguna. Pengguna harus memiliki peran berikut:
- Peran
iam.serviceAccountUser Salah satu peran login berikut:
- Peran
compute.osLogin, yang tidak memberikan izin administrator - Peran
compute.osAdminLogin, yang memberikan izin administrator
- Peran
- Peran
Jika Anda adalah administrator organisasi yang ingin mengizinkan identitas Google dari luar organisasi untuk mengakses instance Anda, berikan peran
compute.osLoginExternalUserkepada orang di luar organisasi Anda di tingkat organisasi. Kemudian, Anda juga harus memberikan perancompute.osLoginataucompute.osAdminLoginkepada identitas luar tersebut di level project atau organisasi.
Setelah Anda mengonfigurasi peran yang diperlukan, hubungkan ke instance menggunakan alat Compute Engine. Compute Engine secara otomatis membuat kunci SSH dan mengaitkannya dengan akun pengguna Anda.
Untuk mengetahui informasi selengkapnya tentang fitur Login OS, lihat Mengelola Akses Instance Menggunakan Login OS.
Membatasi akses jaringan menggunakan aturan firewall
Di Google Cloud, Anda juga dapat membuat aturan firewall yang menggunakan akun layanan untuk memfilter traffic masuk atau keluar. Pendekatan ini dapat berfungsi sangat baik dalam situasi berikut:
- Anda memiliki berbagai pengguna atau aplikasi yang memerlukan akses ke Haadoop, yang berarti membuat aturan berdasarkan IP bukanlah hal yang mudah.
- Anda menjalankan cluster Hadoop atau VM klien sementara, sehingga alamat IP sering berubah.
Dengan menggunakan aturan firewall yang dikombinasikan dengan akun layanan, Anda dapat menyetel akses ke cluster Dataproc/Hadoop tertentu agar hanya mengizinkan akun layanan tertentu. Dengan begitu, hanya VM yang berjalan sebagai akun layanan tersebut yang akan memiliki akses pada tingkat cluster yang telah ditentukan.
Diagram berikut menggambarkan proses penggunaan akun layanan untuk membatasi
akses. dataproc-app-1, dataproc-1, dataproc-2, dan
app-1-client adalah akun layanan. Aturan firewall mengizinkan dataproc-app-1 untuk mengakses dataproc-1 dan dataproc-2, serta mengizinkan klien yang menggunakan app-1-client untuk mengakses dataproc-1. Di sisi penyimpanan, akses dan izin Cloud Storage dibatasi oleh izin Cloud Storage untuk akun
layanan, bukan aturan firewall.
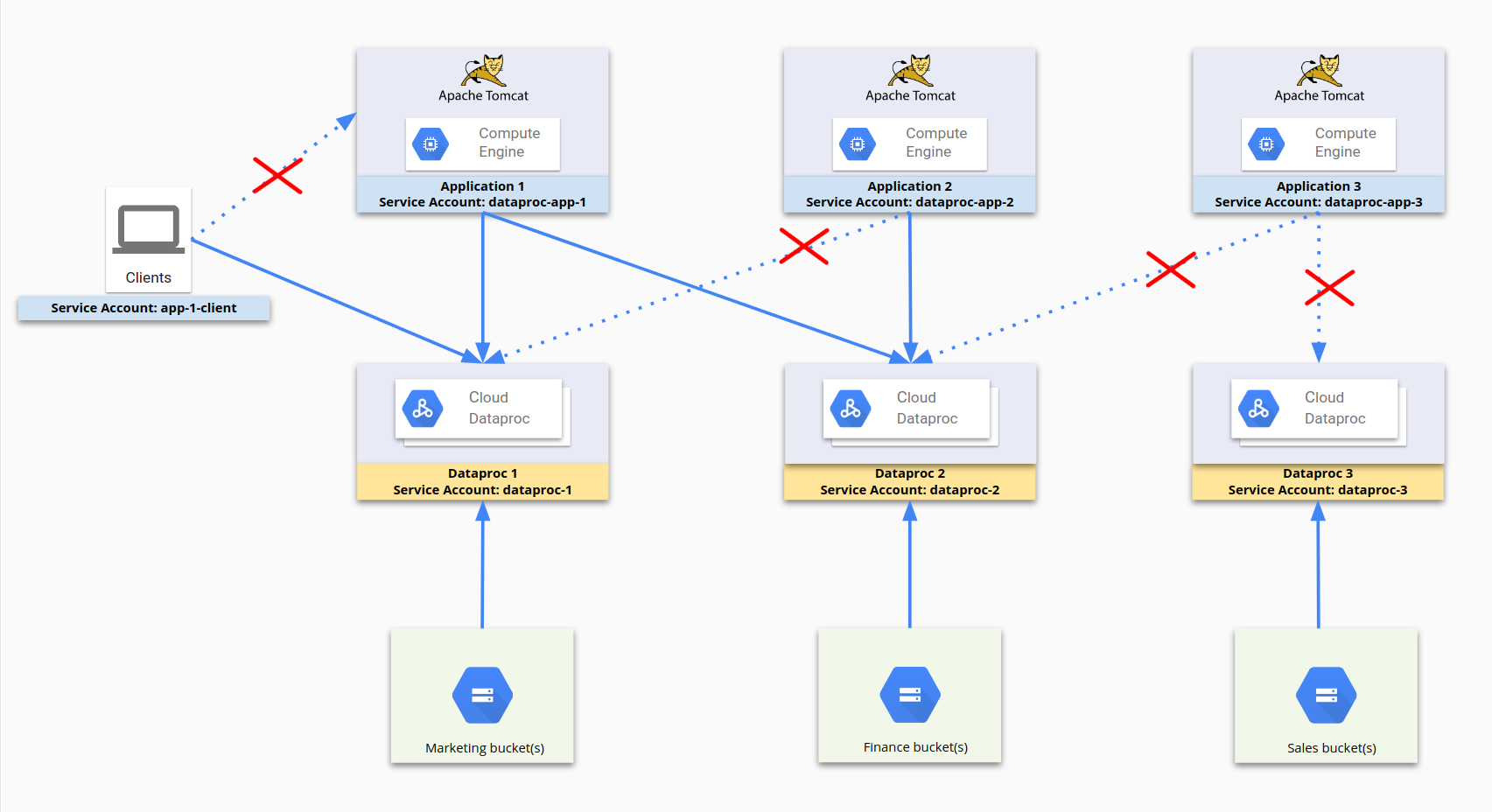
Untuk konfigurasi ini, aturan firewall berikut telah ditetapkan:
| Nama aturan | Setelan |
|---|---|
dp1 |
Target: dataproc-1Sumber: [Rentang IP] Sumber SA: dataproc-app-1Izinkan [port] |
dp2 |
Target: dataproc-2Sumber: [Rentang IP] Sumber SA: dataproc-app-2Izinkan [port] |
dp2-2 |
Target: dataproc-2Sumber: [Rentang IP] Sumber SA: dataproc-app-1Izinkan [port] |
app-1-client |
Target: dataproc-1Sumber: [Rentang IP] Sumber SA: app-1-clientIzinkan [port] |
Untuk mengetahui informasi selengkapnya tentang penggunaan aturan firewall dengan akun layanan, baca Pemfilteran sumber dan target berdasarkan akun layanan.
Memeriksa port firewall yang terbuka secara tidak sengaja
Memiliki aturan firewall yang sesuai juga penting untuk mengekspos antarmuka pengguna berbasis Web yang berjalan di cluster. Pastikan port firewall Anda tidak terbuka dari Internet yang terhubung ke antarmuka tersebut. Port yang terbuka dan aturan firewall yang tidak dikonfigurasi dengan benar dapat memungkinkan pengguna yang tidak sah untuk mengeksekusi kode arbitrer.
Misalnya, Apache Hadoop YARN menyediakan REST API yang memiliki port yang sama dengan antarmuka web YARN. Secara default, pengguna yang dapat mengakses antarmuka web YARN dapat membuat aplikasi, mengirim tugas, dan mungkin dapat melakukan operasi Cloud Storage.
Tinjau Konfigurasi jaringan Dataproc dan Buat tunnel SSH untuk membuat koneksi yang aman ke pengontrol cluster Anda. Untuk mengetahui informasi selengkapnya tentang penggunaan aturan firewall dengan akun layanan, lihat Pemfilteran sumber dan target berdasarkan akun layanan.
Bagaimana dengan cluster multi-tenant?
Secara umum, praktik terbaiknya adalah menjalankan cluster Dataproc/Hadoop terpisah untuk berbagai aplikasi. Namun, jika harus menggunakan cluster multi-tenant dan tidak ingin melanggar persyaratan keamanan, Anda dapat membuat pengguna dan grup Linux di dalam cluster Dataproc/Hadoop untuk memberikan otorisasi dan alokasi resource melalui Antrean YARN. Autentikasi harus diterapkan oleh Anda karena tidak ada pemetaan langsung antara pengguna Google dan pengguna Linux. Mengaktifkan Kerberos pada cluster dapat memperkuat level autentikasi dalam cakupan cluster.
Terkadang, pengguna manusia seperti sekelompok data scientist menggunakan cluster Hadoop untuk menemukan data dan mem-build model. Dalam situasi seperti ini, mengelompokkan pengguna yang memiliki akses yang sama ke data dan membuat satu cluster Dataproc/Hadoop khusus adalah pilihan yang bagus. Dengan cara ini, Anda dapat menambahkan pengguna ke grup yang memiliki izin untuk mengakses data. Resource cluster juga dapat dialokasikan berdasarkan pengguna Linux mereka.