Dernière mise à jour : septembre 2020
Notes de version
Ce document fait partie d'une série traitant de la migration de schéma et de données de Teradata vers BigQuery sur Google Cloud. Cette partie est un guide de démarrage rapide (un tutoriel de démonstration de faisabilité) qui vous accompagne tout au long du processus de conversion de différentes instructions SQL Teradata non standards en instructions SQL standards pouvant être utilisées dans BigQuery.
La série consacrée aux spécificités de la transition depuis Teradata comprend les articles suivants :
- Guide de démarrage rapide pour le transfert de schéma et de données
- Présentation de la traduction de requête
- Guide de démarrage rapide de la traduction de requête (ce document)
- Documentation de référence sur la traduction du langage SQL
Pour une présentation de la transition d'un entrepôt de données sur site vers BigQuery sur Google Cloud, consultez la série commençant par l'article Migrer des entrepôts de données vers BigQuery : Introduction et présentation.
Objectifs
- Traduire des requêtes d'un langage SQL Teradata en SQL standard.
- Commencer par une approche manuelle pour les cas simples et passer à une approche automatisée à l'aide de modèles.
- Découvrir des traductions plus complexes dans lesquelles le refactoring de requête est nécessaire.
Coûts
Ce guide de démarrage rapide utilise les composants facturables suivants de Google Cloud :
- BigQuery : ce tutoriel stocke près de 1 Go de données dans BigQuery et en traite moins de 2 Go pour une seule exécution de requêtes. Dans le cadre de la version gratuite de Google Cloud, vous bénéficiez d'un quota de ressources gratuites avec BigQuery dans la limite des conditions fixées. Ce quota est disponible pendant et après l'essai gratuit. Si vous dépassez les limites d'utilisation et que l'essai gratuit est terminé, le service vous sera facturé selon la grille tarifaire figurant sur la page Tarifs de BigQuery.
Vous pouvez utiliser le Simulateur de coût pour générer une estimation du coût en fonction de votre utilisation prévue.
Avant de commencer
- Suivez le guide de démarrage rapide sur le transfert de schéma et de données pour créer le schéma et les données nécessaires dans votre base de données Teradata et dans BigQuery pour suivre ce guide. Vous utilisez le même projet dans ces deux guides de démarrage rapide.
- Assurez-vous que vous disposez de Teradata BTEQ sur votre ordinateur et que vous pouvez vous connecter à une base de données Teradata. Si vous devez installer l'outil BTEQ, vous pouvez le télécharger depuis le site Web de Teradata.
Demandez à votre administrateur système de vous fournir les informations d'installation, de configuration et d'exécution de BTEQ. En remplacement ou en plus de BTEQ, vous pouvez également effectuer les actions suivantes :
- Installer un outil avec une interface graphique telle que DBeaver.
- Installer le module Python fourni par Teradata pour les interactions de scripts avec la base de données Teradata
- Installez Jinja2 sur votre ordinateur s'il ne l'est pas déjà dans votre environnement Python. Jinja2 est un moteur de création de modèles pour Python. Nous vous recommandons d'isoler les environnements Python à l'aide d'un gestionnaire d'environnement, tel que virtualenvwrapper.
- Assurez-vous d'avoir accès à la console BigQuery.
Présentation
Ce guide de démarrage rapide vous accompagne tout au long du processus de traduction de quelques exemples de requêtes du langage SQL Teradata en SQL standard pouvant être utilisés dans BigQuery. Cela commence par une simple méthode de recherche et de remplacement. Il présente ensuite la restructuration automatisée à l'aide de scripts. Enfin, il aborde des traductions plus complexes dans lesquelles des experts en la matière doivent être impliqués pour s'assurer que la requête traduite conserve la sémantique de l'original.
Ce guide de démarrage rapide est destiné aux administrateurs d'entrepôts de données, aux développeurs et aux utilisateurs de données qui souhaitent acquérir une expérience pratique en matière de traduction de requêtes du langage SQL Teradata en SQL ISO:2011 standard.
Remplacer les opérateurs et les fonctions
Comme le langage SQL Teradata est conforme à la norme SQL ANSI/ISO, vous pouvez migrer facilement de nombreuses requêtes sans modifications majeures. Cependant, Teradata accepte également les extensions SQL non standards. Dans les cas simples où vous utilisez des opérateurs et des fonctions non standards dans Teradata, vous pouvez souvent avoir recours au processus de recherche et de remplacement pour traduire des requêtes.
Par exemple, commencez par exécuter une requête dans Teradata pour rechercher le nombre de clients ayant effectué des achats supérieurs à 10 000 $ en 1994.
Sur l'ordinateur sur lequel vous avez installé BTEQ, ouvrez le client Teradata BTEQ :
bteqConnectez-vous à Teradata. Remplacez teradata-ip et teradata-user par les valeurs correspondantes pour votre environnement.
.LOGON teradata-ip/teradata-user
Lorsque vous y êtes invité par BTEQ, exécutez la requête SQL Teradata qui suit :
SELECT COUNT(DISTINCT(O_CUSTKEY)) AS num_customers FROM tpch.orders WHERE O_TOTALPRICE GT 10000 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994;Le résultat doit ressembler à ce qui suit :
num_customers ------------- 86101
Exécutez maintenant la même requête dans BigQuery :
Accédez à la console BigQuery :
Copiez la requête dans l'éditeur de requête.
L'opérateur
GT(supérieur à) n'est pas en SQL standard. L'éditeur de requête affiche donc un message d'erreur concernant la syntaxe :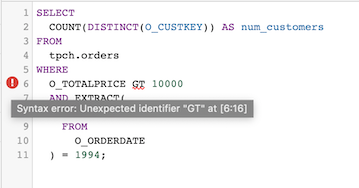
Remplacez
GTpar l'opérateur>.Cliquez sur Exécuter.
Le résultat numérique est identique à celui de Teradata.
Rechercher et remplacer des éléments SQL à l'aide d'un script
La modification que vous venez d'apporter est triviale, mais elle est simple à effectuer à la main. Néanmoins, le processus manuel de recherche et de remplacement devient fastidieux et sujet à erreurs lorsque vous devez traiter des scripts SQL volumineux ou en traiter un grand nombre. Par conséquent, il est préférable d'automatiser cette tâche, comme décrit dans cette section.
Dans la console, accédez à Cloud Shell :
Utilisez un éditeur de texte pour créer un fichier nommé
num-customers.sql. Par exemple, exécutez la commande "vi" pour créer le fichier :vi num-customers.sqlCopiez le script SQL de la section précédente dans le fichier.
Enregistrez et fermez le fichier.
Remplacez
GTpar l'opérateur>:sed -i 's/GT/>/' num-customers.sqlVérifiez que
GTa bien été remplacé par>dans le fichier :cat num-customers.sql
Vous pouvez appliquer le script sed que vous venez d'utiliser pour un ensemble de fichiers groupé. Il permet également de gérer plusieurs remplacements dans chaque fichier.
Dans Cloud Shell, utilisez un éditeur de texte pour ouvrir le fichier nommé
num-customers.sql:vi num-customers.sqlRemplacez le contenu du fichier par le script suivant :
SELECT COUNT(DISTINCT(O_CUSTKEY)) AS num_customers FROM tpch.orders WHERE O_TOTALPRICE GT 10000 AND O_ORDERPRIORITY EQ '1-URGENT' AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994;Le script est presque identique au précédent, mais il dispose d'une ligne supplémentaire réservée à l'ajout des commandes urgentes. Le script SQL dispose désormais de deux opérateurs SQL non standards :
GTetEQ.Enregistrez et fermez le fichier.
Créez 99 copies du fichier :
for i in {1..99}; do cp num-customers.sql "num-customers$i.sql"; doneÀ la fin de la commande, vous disposez de 100 versions du fichier de script.
Remplacez
GTpar>dans tous les fichiers en une seule opération :sed -i 's/GT/>/g;s/EQ/=/g' *.sqlIl est beaucoup plus efficace de modifier les 100 fichiers à l'aide d'un script que de les modifier un par un manuellement.
Répertoriez les fichiers qui incluent l'opérateur
GT:grep GT *.sqlLa commande ne renvoie aucun résultat, car toutes les occurrences de l'opérateur
GTont été remplacées par l'opérateur>.Choisissez l'un des fichiers et vérifiez que les opérateurs ont bien été remplacés par leurs équivalents standards :
cat num-customers33.sql
Voici quelques cas adaptés à cette approche de recherche et de remplacement :
- Des fonctions de date, en remplaçant par exemple :
DATE + kparDATE_ADDTD_DAY_OF_MONTHparEXTRACTMONTHS_BETWEENparDATE_DIFF
- Des fonctions de chaîne, en remplaçant par exemple :
CHARACTER_LENGTHparCHAR_LENGTHINDEXparSTRPOSLEFTparSUBSTR
- Des fonctions mathématiques, en remplaçant par exemple :
NULLIFZEROparNULLIFRANDOMparRANDZEROIFNULLparIFNULL
- Des abréviations, en remplaçant par exemple
SELparSELECT.
Pour obtenir une liste plus exhaustive des traductions courantes, consultez la documentation de référence sur la traduction du langage SQL de Teradata vers BigQuery.
Restructurer des instructions et des scripts SQL à l'aide d'un script
Jusqu'à présent, vous n'avez automatisé que le remplacement d'opérateurs et de fonctions SQL Teradata disposant d'un équivalent exact dans le langage SQL standard. Cependant, la traduction des éléments SQL des fonctions non standards est beaucoup plus complexe. Le script de traduction doit non seulement remplacer les mots clés, mais également ajouter ou déplacer d'autres éléments tels que des arguments, des parenthèses ou d'autres appels de fonction.
Dans cette section, vous recherchez les commandes les plus élevées d'un groupe de clients à la fin de chaque mois à l'aide d'une requête dans Teradata.
Sur l'ordinateur sur lequel vous avez installé BTEQ, ouvrez l'invite de commande BTEQ. Si vous avez fermé BTEQ, exécutez la commande suivante :
bteqLorsque vous y êtes invité par BTEQ, exécutez la requête SQL Teradata qui suit :
SELECT O_CUSTKEY, SUM(O_TOTALPRICE) as total, TD_MONTH_END(O_ORDERDATE) as month_end FROM tpch.orders WHERE O_CUSTKEY < 5 GROUP BY O_CUSTKEY, month_end ORDER BY total DESC;La requête se sert de la fonction Teradata non standard
TD_MONTH_ENDpour obtenir la première date de fin de mois suivant la date de la commande. Par exemple, si la commande a été passée le 16/05/1996,TD_MONTH_ENDrenvoie 31/05/1996. Il suffit d'un argument de date, à savoir la date de la commande. Les résultats sont regroupés par date de fin de mois et par clé client pour obtenir la valeur totale pour un mois et un client donnés.Le résultat doit ressembler à ce qui suit.
O_CUSTKEY total month_end ----------- ----------------- --------- 4 379593.37 96/06/30 4 323004.15 96/08/31 2 312692.22 97/02/28 4 311722.87 92/04/30
Pour exécuter une requête qui renvoie les mêmes résultats dans BigQuery, vous devez remplacer la fonction non standard TD_MONTH_END par son équivalent en langage SQL standard. Cependant, il n'existe pas d'équivalent exact pour cette fonction. Par conséquent, vous créez une fonction qui utilise un modèle Jinja2 pour effectuer cette tâche.
Dans Cloud Shell, créez un fichier nommé
month-end.jinja2:vi month-end.jinja2Copiez l'extrait SQL suivant dans le fichier :
DATE_SUB( DATE_TRUNC( DATE_ADD( {{ date }}, INTERVAL 1 MONTH ), MONTH ), INTERVAL 1 DAY )Ce fichier est un modèle Jinja2. Il s'agit de l'équivalent de la fonction
TD_MONTH_ENDen langage SQL standard. Il possède un espace réservé appelé{{ date }}qui sera remplacé par l'argument de date, dans ce casO_ORDERDATE.Enregistrez et fermez le fichier.
Créez un fichier nommé
translate-query.py:translate-query.pyCopiez le script Python suivant dans le fichier :
"""Translates a sample using a template.""" import re from jinja2 import Environment from jinja2 import PackageLoader env = Environment(loader=PackageLoader('translate-query', '.')) regex = re.compile(r'(.*)TD_MONTH_END\(([A-Z_]+)\)(.*)') with open('month-end.td.sql', 'r') as td_sql: with open('month-end.sql', 'w') as std_sql: for line in td_sql: match = regex.search(line) if match: argument = match.group(2) template = env.get_template('month-end.jinja2') std_sql.write(match.group(1) + template.render(date=argument) \ + match.group(3) + '\n') else: std_sql.write(line)Ce script Python ouvre le fichier que vous avez créé précédemment (
month-end.td.sql), lit les données SQL Teradata en entrée et écrit une traduction du script en langage SQL standard dans le fichiermonth-end.sql.Tenez compte des remarques suivantes :
- Le script recherche une correspondance avec l'expression régulière
(.*)TD_MONTH_END\(([A-Z_]+)\)(.*)sur chaque ligne lue dans le fichier d'entrée. L'expression rechercheTD_MONTH_ENDet capture trois groupes :- Tous les caractères
(.*)avant la fonction dans le groupegroup(1) - L'argument
([A-Z_]+)envoyé à la fonctionTD_MONTH_ENDdans le groupegroup(2) - Tous les caractères
(.*)après la fonction dans le groupegroup(3)
- Tous les caractères
- En cas de correspondance, le script récupère le modèle Jinja2
month-end.jinja2que vous avez créé précédemment. Il écrit ensuite les éléments ci-après dans le fichier de sortie dans l'ordre suivant :- Les caractères représentés par le groupe
group(1). - Le modèle, dans lequel l'espace réservé
datea été remplacé par l'argument d'origine de la fonction SQL Teradata, à savoirO_ORDERDATE. - Les caractères représentés par le groupe
group(3).
- Les caractères représentés par le groupe
- Le script recherche une correspondance avec l'expression régulière
Enregistrez et fermez le fichier.
Exécutez le script Python :
python translate-query.pyUn fichier nommé
month-end.sqlest créé.Affichez le contenu de ce nouveau fichier :
cat month-end.sqlCette commande affiche la requête traduite en langage SQL standard par le script :
SELECT O_CUSTKEY, SUM(O_TOTALPRICE) as total, DATE_SUB( DATE_TRUNC( DATE_ADD( O_ORDERDATE, INTERVAL 1 MONTH ), MONTH ), INTERVAL 1 DAY ) as month_end FROM tpch.orders WHERE O_CUSTKEY < 5 GROUP BY O_CUSTKEY, month_end ORDER BY total DESC;La fonction
TD_MONTH_ENDne s'affiche plus. Elle a été remplacée par le modèle et l'argument de dateO_ORDERDATEdans l'ordre approprié dans le modèle.
Le script Python utilise déjà le modèle d'un fichier Jinja2 externe. La même approche peut être appliquée à l'expression régulière. En d'autres termes, l'expression peut être chargée à partir d'un fichier ou d'un magasin de paires valeur/clé. De cette façon, le script peut être généralisé pour gérer une expression arbitraire et son modèle de traduction correspondant.
Enfin, exécutez le script généré dans BigQuery pour vérifier que les résultats correspondent à ceux obtenus dans Teradata :
Accédez à la console BigQuery :
Copiez la requête que vous avez exécutée précédemment dans l'éditeur de requête.
Cliquez sur Exécuter.
Le résultat est identique à celui de Teradata.
Déployer plus d'efforts dans la traduction des requêtes
Lorsque vous migrez des données, vous devez être entouré de personnes qualifiées pour appliquer un ensemble de traductions à l'aide d'outils, tels que les exemples de scripts vus précédemment. Ces scripts évoluent au fil des efforts de migration. Par conséquent, nous vous conseillons vivement de les mettre dans un dépôt source. Vous devez tester les résultats de l'exécution de ces scripts de manière méticuleuse.
Nous vous conseillons de contacter notre équipe commerciale, qui peut vous mettre en contact avec l'équipe Professional Services Organization et nos partenaires pour vous aider lors de la migration.
Refactoriser des requêtes
Dans la section précédente, vous avez utilisé des scripts pour rechercher les opérateurs en SQL Teradata et les remplacer par leurs équivalents en SQL standard. Vous avez également procédé à une restructuration automatisée limitée de vos requêtes à l'aide de modèles.
Pour traduire certaines fonctionnalités rédigées en langage SQL Teradata, vous devez refactoriser les requêtes SQL de manière plus approfondie. Cette section présente deux exemples : la traduction de la clause QUALIFY et la traduction des références entre colonnes.
Les exemples de cette section sont refactorisés manuellement. En pratique, certains cas de refactorisation plus complexes pourraient être automatisés. En revanche, leur automatisation pourrait générer des retours décroissants en raison de la complexité de l'analyse de chaque cas. De plus, il est possible qu'un script automatisé manque de solutions plus optimales pour préserver la sémantique de la requête.
La clause QUALIFY
La clause QUALIFY de Teradata est une clause conditionnelle utilisée dans une instruction SELECT pour filtrer les résultats d'une fonction analytique triée précédemment calculée.
Les fonctions analytiques triées s'appliquent à une plage de lignes et génèrent un résultat pour chacune d'elles. Les clients de Teradata utilisent généralement cette fonction pour simplifier le classement et l'envoi des résultats, sans avoir recours à une autre sous-requête.
Pour illustrer cela, vous pouvez sélectionner les commandes les plus élevées de chaque client en 1994 à l'aide de la clause QUALIFY.
Sur l'ordinateur sur lequel vous avez installé BTEQ, ouvrez l'invite de commande BTEQ. Si vous avez fermé BTEQ, exécutez la commande suivante :
bteqCopiez la requête SQL Teradata suivante dans l'invite BTEQ :
SELECT O_CUSTKEY, O_TOTALPRICE FROM tpch.orders QUALIFY ROW_NUMBER() OVER ( PARTITION BY O_CUSTKEY ORDER BY O_TOTALPRICE DESC ) = 1 WHERE EXTRACT(YEAR FROM O_ORDERDATE) = 1994 AND (O_CUSTKEY MOD 10000) = 0;Tenez compte des remarques suivantes pour cette requête :
- La requête divise les lignes en partitions. Chaque partition correspond à une clé client (
PARTITION BY O_CUSTKEY). - La clause
QUALIFYne filtre que la première ligne (ROW_NUMBER()=1) de chaque partition. - Étant donné que les lignes de chaque partition sont classées par ordre décroissant de prix total de commande (
ORDER BY O_TOTALPRICE DESC), la première ligne correspond à la commande la plus élevée. - L'instruction
SELECTextrait la clé client et le prix total de la commande (O_CUSTKEY,O_TOTALPRICE), puis filtre les résultats jusqu'en 1994 à l'aide d'une clauseWHERE. - L'opérateur modulo (
MOD) ne récupère qu'un sous-ensemble de lignes à des fins d'affichage. Privilégiez cette méthode d'échantillonnage à la clauseSAMPLE, carSAMPLEeffectue une randomisation : vous ne pouvez donc pas comparer les résultats avec BigQuery.
- La requête divise les lignes en partitions. Chaque partition correspond à une clé client (
Exécutez la requête.
Le résultat doit ressembler à ce qui suit :
O_CUSTKEY O_TOTALPRICE ----------- ----------------- 10000 182742.02 20000 56470.00 40000 211502.51 50000 81584.54 70000 53131.09 80000 15902.64 100000 306639.29 130000 183113.29 140000 250958.13La deuxième colonne indique la valeur totale des commandes la plus élevée en 1994 pour les clés client échantillonnées dans la première colonne.
Pour exécuter la même requête dans BigQuery, vous devez transformer le script SQL pour le rendre conforme à la norme SQL ANSI/ISO.
Accédez à la console BigQuery :
Copiez la requête traduite suivante dans l'éditeur de requête :
SELECT O_CUSTKEY, O_TOTALPRICE FROM ( SELECT O_CUSTKEY, O_TOTALPRICE, ROW_NUMBER() OVER ( PARTITION BY O_CUSTKEY ORDER BY O_TOTALPRICE DESC ) as row_num FROM tpch.orders WHERE EXTRACT(YEAR FROM O_ORDERDATE) = 1994 AND MOD(O_CUSTKEY, 10000) = 0 ) WHERE row_num = 1Cette nouvelle requête présente quelques modifications, dont aucune ne peut être effectuée par simple recherche et remplacement. Veuillez noter les points suivants :
- La clause
QUALIFYest supprimée, et la fonction analytiqueROW_NUMBER()est déplacée sous forme de colonne dans l'instructionSELECT. Un alias lui est attribué (as row_num). - Une requête englobante est créée si elle n'existe pas, en lui ajoutant une condition
WHEREavec le filtre de valeur d'analyse (row_num = 1). - L'opérateur Teradata
MODn'étant pas standard, il est modifié par la fonctionMOD().
- La clause
Cliquez sur Exécuter.
Le résultat en colonnes est identique à celui de Teradata.
Références croisées entre colonnes
Teradata accepte les références croisées entre les colonnes définies au sein d'une même requête. Dans cette section, vous exécutez une requête qui attribue un alias à une instruction SELECT imbriquée et qui fait ensuite référence à cet alias dans une expression CASE.
Pour illustrer cela, vous pouvez exécuter une requête qui détermine si un client était actif au cours d'une année donnée. Un client est considéré comme actif s'il a passé au moins une commande au cours de l'année.
Sur l'ordinateur sur lequel vous avez installé BTEQ, ouvrez l'invite de commande BTEQ. Si vous avez fermé BTEQ, exécutez la commande suivante :
bteqCopiez la requête SQL Teradata suivante dans l'invite BTEQ :
SELECT ( SELECT COUNT(O_CUSTKEY) FROM tpch.orders WHERE O_CUSTKEY = 2 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994 ) AS num_orders, CASE WHEN num_orders = 0 THEN 'INACTIVE' ELSE 'ACTIVE' END AS status;Tenez compte des remarques suivantes pour cette requête :
- Une requête imbriquée permet de compter le nombre d'occurrences de la clé client
2en 1994. Le résultat de cette requête est renvoyé dans la première colonne et reçoit l'aliasnum_orders. - Dans la deuxième colonne, l'expression
CASEgénère le résultatACTIVEsi le nombre de commandes est différent de zéro. Sinon, le résultat estINACTIVE. L'expressionCASEutilise l'alias de la première colonne de la même requête (num_orders) en interne.
- Une requête imbriquée permet de compter le nombre d'occurrences de la clé client
Exécutez la requête.
Le résultat doit ressembler à ce qui suit :
num_orders status ----------- -------- 3 ACTIVE
Pour exécuter la même requête dans BigQuery, vous devez supprimer les références entre les colonnes d'une même requête.
Accédez à la console BigQuery :
Copiez la requête traduite suivante dans l'éditeur de requête :
SELECT customer.num_orders, CASE WHEN customer.num_orders = 0 THEN 'INACTIVE' ELSE 'ACTIVE' END AS status FROM ( SELECT COUNT(O_CUSTKEY) AS num_orders FROM tpch.orders WHERE O_CUSTKEY = 2 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994 ) customer;Notez les modifications apportées à la requête d'origine :
- La requête imbriquée est déplacée dans la clause
FROMd'une requête englobante. Elle reçoit l'aliascustomer. Celui-ci ne définit pas de colonne de sortie, car il se trouve dans une clauseFROMet non dans une clauseSELECT. - La clause
SELECTcontient deux colonnes :- La première colonne génère le nombre de commandes (
num_orders) défini dans la requête imbriquée (customer). - La deuxième colonne contient l'instruction
CASEqui référence le nombre de commandes défini dans la requête imbriquée.
- La première colonne génère le nombre de commandes (
- La requête imbriquée est déplacée dans la clause
Cliquez sur Exécuter.
Le résultat en colonnes est identique à celui de Teradata.
Nettoyer
Pour éviter que les ressources utilisées dans ce tutoriel soient facturées sur votre compte Google Cloud, supprimez-les.
Supprimer le projet
Le moyen le plus simple d'arrêter les frais de facturation consiste à supprimer le projet que vous avez créé dans le cadre de ce tutoriel.
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Étape suivante
- Consultez la documentation de référence sur la traduction du langage SQL de Teradata vers BigQuery pour en savoir plus sur les différences et les mappages entre le langage SQL Teradata et le langage SQL standard utilisé dans BigQuery.
- Passez à la partie suivante de cette série : Gouvernance des données
- Découvrez les offres de l'équipe Professional Services Organization de Google et de notre vaste réseau de partenaires composé d'entreprises pouvant vous aider tout au long du processus de migration.
- Explorez des architectures de référence, des schémas, des tutoriels et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.