Migration d'Oracle vers BigQuery
Ce document fournit des conseils généraux sur la migration d'Oracle vers BigQuery. Il décrit les principales différences d'architecture et suggère des solutions pour migrer des entrepôts de données et des magasins de données exécutés sur un SGBDR Oracle (y compris Exadata) vers BigQuery. Ce document fournit des détails qui peuvent s'appliquer à Exadata, ExaCC et Oracle Autonomous Data Warehouse, car ils utilisent des logiciels Oracle compatibles.
Ce document est destiné aux architectes d'entreprise, aux administrateurs de bases de données, aux développeurs d'applications et aux professionnels de la sécurité informatique qui souhaitent migrer d'Oracle vers BigQuery et résoudre les problèmes techniques liés au processus de migration.
Vous pouvez également utiliser la traduction SQL par lot pour migrer vos scripts SQL de façon groupée, ou la traduction SQL interactive pour traduire des requêtes ad hoc. Oracle SQL, PL/SQL et Exadata sont compatibles avec les deux outils en version preview.
Pré-migration
Pour garantir la réussite de la migration de l'entrepôt de données, commencez par planifier votre stratégie de migration dès le début de votre projet. Pour en savoir plus sur la planification systématique de votre travail de migration, consultez la section Que faut-il migrer et comment procéder : le cadre de migration.
Planification de la capacité BigQuery
Le débit des analyses dans BigQuery est mesuré en emplacements. Un emplacement BigQuery est l'unité propriétaire de Google de la capacité de calcul nécessaire à l'exécution de requêtes SQL.
BigQuery calcule en continu le nombre d'emplacements requis par les requêtes au fur et à mesure de leur exécution, mais il alloue ces emplacements à des requêtes en fonction d'un programmeur équitable.
Vous pouvez choisir entre les modèles tarifaires suivants lorsque vous planifiez la capacité des emplacements BigQuery :
Tarifs à la demande : avec la tarification à la demande, BigQuery facture le nombre d'octets traités (taille des données). Vous ne payez donc que pour les requêtes que vous exécutez. Pour plus d'informations sur la manière dont BigQuery détermine la taille des données, consultez la page Calcul de la taille des données. Étant donné que les emplacements déterminent la capacité de calcul sous-jacente, vous pouvez payer l'utilisation de BigQuery en fonction du nombre d'emplacements dont vous avez besoin (au lieu du nombre d'octets traités). Par défaut, les projets Google Cloud sont limités à un maximum de 2 000 emplacements.
Tarifs basés sur la capacité Avec la tarification basée sur la capacité, vous achetez des réservations d'emplacements BigQuery (au moins 100) au lieu de payer le nombre d'octets traités par les requêtes que vous exécutez. Nous recommandons les tarifs basés sur la capacité pour les charges de travail des entrepôts de données d'entreprise, qui présentent généralement de nombreuses requêtes simultanées de création de rapports et d'extraction, de chargement et de transformation (ELT, Extract-Load-Transform), dont la consommation est prévisible.
Pour vous aider à estimer les emplacements, nous vous recommandons de configurer la surveillance BigQuery à l'aide de Cloud Monitoring et d'analyser vos journaux d'audit à l'aide de BigQuery. De nombreux clients utilisentLooker Studio (par exemple, vous pouvez consulter un exemple Open Source de tableau de bord Looker Studio), Looker ou Tableau en tant qu'interfaces pour visualiser les données des journaux d'audit BigQuery, en particulier pour l'utilisation des emplacements sur l'ensemble des requêtes et des projets. Vous pouvez également exploiter les données des tables système de BigQuery pour surveiller l'utilisation des emplacements entre les jobs et les réservations. Pour obtenir un exemple, consultez un exemple Open Source de tableau de bord Looker Studio.
Surveiller et analyser régulièrement l'utilisation des emplacements vous aide à estimer le nombre total d'emplacements dont votre organisation a besoin à mesure que vous développez sur Google Cloud.
Par exemple, supposons que vous réservez initialement 4 000 emplacements BigQuery pour exécuter simultanément 100 requêtes de complexité moyenne. Si vous remarquez des temps d'attente élevés dans les plans d'exécution de vos requêtes et que vos tableaux de bord indiquent une utilisation des emplacements élevée, cela peut indiquer que vous avez besoin d'emplacements BigQuery supplémentaires pour prendre en charge vos charges de travail. Si vous souhaitez acheter des emplacements vous-même via des engagements annuels ou sur trois ans, vous pouvez commencer à utiliser les réservations BigQuery à l'aide de la console Google Cloud ou de l'outil de ligne de commande bq.
Pour toute question concernant votre forfait actuel et les options précédentes, contactez votre conseiller commercial.
Security in Google Cloud
Les sections suivantes décrivent les contrôles de sécurité courants d'Oracle et expliquent comment vous assurer que votre entrepôt de données reste protégé dans un environnement Google Cloud.
Identity and Access Management (IAM)
Oracle fournit des utilisateurs, droits, rôles et profils pour gérer l'accès aux ressources.
BigQuery utilise IAM pour gérer l'accès aux ressources et permet une gestion centralisée des accès aux ressources et aux actions. Les types de ressources disponibles dans BigQuery incluent les organisations, les projets, les ensembles de données, les tables les vues. Dans la hiérarchie des stratégies IAM, les ensembles de données sont des ressources enfants des projets. Une table hérite des autorisations de l'ensemble de données qui la contient.
Pour accorder l'accès à une ressource, attribuez un ou plusieurs rôles à un utilisateur, un groupe ou un compte de service. Les rôles associés aux organisations et aux projets déterminent la capacité à exécuter des jobs ou à gérer les ressources d'un projet, tandis que les rôles associés aux ensembles de données ont un impact sur l'accès ou la modification des données dans l'ensemble de données en question.
IAM fournit les types de rôles suivants :
- Les rôles prédéfinis sont conçus pour des cas d'utilisation courants et des modèles de contrôle des accès. Ils fournissent un accès précis à un service spécifique et sont gérés par Google Cloud.
Les rôles de base incluent les rôles "Propriétaire", "Éditeur" et "Lecteur".
Les rôles personnalisés fournissent un accès précis en fonction d'une liste d'autorisations spécifiée par l'utilisateur.
Lorsque vous attribuez des rôles prédéfinis et des rôles de base à un utilisateur, les autorisations accordées correspondent à une combinaison des autorisations de chaque rôle individuel.
Sécurité au niveau des lignes
Oracle Label Security (OLS) permet de restreindre l'accès aux données ligne par ligne. Un cas d'utilisation classique de la sécurité au niveau des lignes consiste à limiter l'accès d'un commercial aux comptes qu'il gère. En mettant en œuvre la sécurité au niveau des lignes, vous bénéficiez d'un contrôle d'accès précis.
Pour établir une sécurité au niveau des lignes dans BigQuery, vous pouvez utiliser les vues autorisées et des règles d'accès au niveau des lignes. Pour en savoir plus sur la conception et la mise en œuvre de ces stratégies, consultez la page Présentation de la sécurité au niveau des lignes de BigQuery.
Chiffrement complet de disque
Oracle propose le chiffrement transparent des données (TDE, Transparent Data Encryption) et le chiffrement de réseau pour le chiffrement des données au repos et en transit. Le chiffrement TDE nécessite l'option de sécurité avancée, qui fait l'objet d'une licence séparée.
Par défaut, BigQuery chiffre toutes les données au repos et en transit, indépendamment de la source ou de toute autre condition, et ce chiffrement ne peut pas être désactivé. BigQuery accepte également les clés de chiffrement gérées par le client (CMEK, Customer-Managed Encryption Key) pour les utilisateurs souhaitant contrôler et gérer les clés de chiffrement de clé dans Cloud Key Management Service. Pour en savoir plus sur le chiffrement pratiqué chez Google Cloud, consultez les pages Chiffrement au repos par défaut et Chiffrement en transit.
Masquage et anonymisation des données
Oracle utilise le masquage des données dans la solution Real Application Testing et l'anonymisation des données, qui vous permet de masquer (anonymiser) les données renvoyées par les requêtes émises par les applications.
BigQuery est compatible avec le masquage dynamique des données au niveau des colonnes. Vous pouvez utiliser le masquage de données pour masquer de manière sélective les données de colonne de groupes d'utilisateurs, tout en autorisant l'accès à la colonne.
Vous pouvez utiliser la protection des données sensibles pour identifier et masquer les informations personnelles sensibles sur BigQuery.
Comparaison entre BigQuery et Oracle
Cette section décrit les principales différences entre BigQuery et Oracle. Cette synthèse vous aide à identifier les obstacles à la migration et à planifier les modifications nécessaires.
Architecture du système
L'une des principales différences entre Oracle et BigQuery est le fait que BigQuery est un entrepôt de données d'entreprise cloud sans serveur avec des couches de stockage et de calcul distinctes pouvant évoluer en fonction des besoins de la requête. Compte tenu de la nature de l'offre sans serveur BigQuery, vous n'êtes pas limité par des décisions concernant le matériel. À la place, vous pouvez demander des ressources supplémentaires pour vos requêtes et vos utilisateurs via des réservations. De plus, BigQuery ne nécessite pas de configuration du logiciel et de l'infrastructure sous-jacents comme le système d'exploitation (OS), les systèmes réseau et les systèmes de stockage, y compris pour le scaling et la haute disponibilité. BigQuery se charge des opérations d'évolutivité, de gestion et d'administration. Le schéma suivant illustre la hiérarchie de stockage BigQuery.
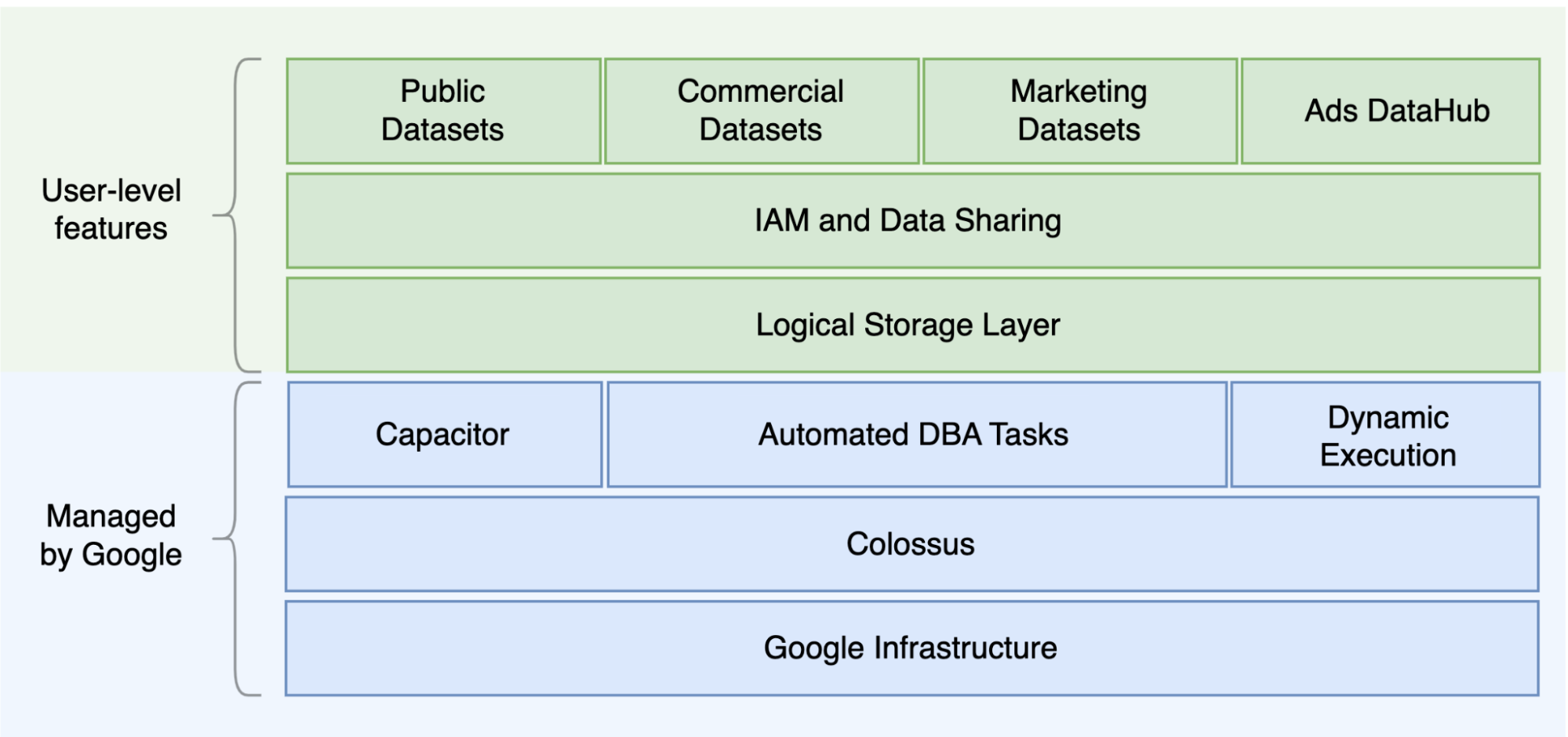
Il peut être utile de connaître l'architecture sous-jacente de stockage et de traitement des requêtes. Par exemple, connaître la séparation entre le stockage (Colossus) et l'exécution de requêtes (Dremel), ainsi que la manière dont Google Cloud alloue des ressources (Borg) peut être utile pour comprendre les différences de comportement et optimiser les performances et la rentabilité des requêtes. Pour en savoir plus, consultez les architectures système de référence pour BigQuery, Oracle et Exadata.
Architecture des données et du stockage
La structure des données et du stockage est un élément important de tout système d'analyse de données, car elle affecte les performances, le coût, l'évolutivité et l'efficacité des requêtes.
BigQuery dissocie le stockage des données et le calcul. Les données sont stockées dans Colossus, où elles sont compressées et stockées dans un format en colonnes appelé Capacitor.
BigQuery agit directement sur les données compressées sans décompression en exploitant Capacitor. BigQuery fournit les ensembles de données comme abstraction de plus haut niveau pour organiser l'accès aux tables comme illustré dans le schéma précédent. Les schémas et les étiquettes peuvent être utilisés pour organiser davantage les tables. BigQuery propose le partitionnement pour améliorer les performances et le coût des requêtes, et pour gérer le cycle de vie des informations. Les ressources de stockage sont allouées au fur et à mesure que vous les consommez et libérées lorsque vous supprimez des données ou des tables.
Oracle stocke les données au format de ligne à l'aide du format de bloc Oracle organisé en segments. Les schémas (appartenant aux utilisateurs) permettent d'organiser les tables et d'autres objets de base de données. Depuis Oracle 12c, l'option multitenant est utilisée pour créer des bases de données connectables au sein d'une instance de base de données pour davantage d'isolation. Le partitionnement peut être utilisé pour améliorer les performances des requêtes et les opérations du cycle de vie des informations. Oracle propose plusieurs options de stockage pour les bases de données autonomes et Real Application Clusters (RAC) telles que ASM, un système de fichiers du système d'exploitation et un système de fichiers du cluster.
Exadata fournit une infrastructure de stockage optimisée dans les serveurs de cellules de stockage et permet aux serveurs Oracle d'accéder à ces données de manière transparente en utilisant ASM. Exadata propose des options de compression en colonnes hybrides (HCC) permettant aux utilisateurs de compresser des tables et des partitions.
Oracle nécessite une capacité de stockage préprovisionnée, un dimensionnement minutieux et des configurations d'incrémentation automatique sur les segments, les fichiers de données et les espaces de table.
Exécution et performances des requêtes
BigQuery gère les performances et effectue le scaling au niveau des requêtes afin de maximiser les performances par rapport au coût. BigQuery utilise de nombreuses optimisations, par exemple :
- Exécution de requêtes en mémoire
- Architecture d'arborescence à plusieurs niveaux basée sur le moteur d'exécution Dremel
- Optimisation automatique de l'espace de stockage dans Capacitor
- Un pétabit par seconde de bande passante bissectionnelle avec Jupiter
- Gestion des ressources avec autoscaling pour fournir des requêtes rapides à l'échelle du pétaoctet
BigQuery rassemble les statistiques de colonne lors du chargement des données et inclut des informations de diagnostic sur les plan de requête et le chronométrage. Les ressources de requête sont allouées en fonction du type de requête et de la complexité. Chaque requête utilise un certain nombre d'emplacements, qui sont des unités de calcul comprenant une certaine quantité de processeurs et de mémoire RAM.
Oracle fournit des jobs de collecte des statistiques de données. L'optimiseur de base de données utilise des statistiques pour fournir des plans d'exécution optimaux. Des index peuvent être nécessaires pour accélérer les recherches de lignes et les opérations de jointure. Oracle propose également un magasin de colonnes en mémoire pour les analyses en mémoire. Exadata offre plusieurs améliorations en termes de performances, telles que l'analyse intelligente des cellules, les index de stockage, le cache flash et les connexions InfiniBand entre les serveurs de stockage et les serveurs de base de données. Real Application Clusters (RAC) peut être utilisé pour obtenir une haute disponibilité des serveurs et assurer le scaling des applications nécessitant une utilisation intensive des processeurs de la base de données en utilisant le même espace de stockage sous-jacent.
L'optimisation des performances des requêtes avec Oracle nécessite une réflexion approfondie sur ces options et les paramètres de base de données. Oracle fournit plusieurs outils tels que l'historique des sessions actives (Active Session History, ASH), la surveillance automatique de diagnostic de base de données (Automatic Database Diagnostic Monitor, ADDM), les dépôts automatiques de charge de travail (Automatic Workload Repository, AWR), un outil de conseils de surveillance et de réglage de SQL, et des outils de conseils d'annulation et de réglage de la mémoire pour le réglage des performances.
Analyses agiles
Dans BigQuery, vous pouvez autoriser différents projets, utilisateurs et groupes à interroger des ensembles de données dans différents projets. La séparation de l'exécution des requêtes permet à des équipes autonomes de travailler au sein de leurs projets sans affecter les autres utilisateurs et projets, en séparant les quotas d'emplacements et en interrogeant la facturation des autres projets et des projets qui hébergent les ensembles de données.
Haute disponibilité, sauvegardes et reprise après sinistre
Oracle fournit Data Guard comme solution de reprise après sinistre et de réplication de base de données. Real Application Clusters (RAC) peut être configuré pour la disponibilité du serveur. Les sauvegardes Recovery Manager (RMAN) peuvent être configurées pour les sauvegardes de bases de données et de journaux d'archive, et peuvent également être utilisées pour les opérations de restauration et de récupération. La fonctionnalité Base de données Flashback peut être utilisée pour obtenir des états antérieurs (flashbacks) de base de données afin de revenir en arrière à un moment spécifique. L"espace de table d'annulation contient des instantanés de table. Il est possible d'interroger d'anciens instantanés à l'aide de la requête Flashback et de clauses de requête "as of" en fonction des opérations LMD/LDD effectuées précédemment et des paramètres de conservation des annulations. Dans Oracle, l'intégrité complète de la base de données doit être gérée dans les espaces de table qui dépendent des métadonnées système, de l'annulation et des espaces de table correspondants, car une cohérence forte est importante pour la sauvegarde Oracle, et les procédures de récupération doivent inclure des données primaires complètes. Vous pouvez planifier des exportations au niveau du schéma de table si la récupération à un moment précis n'est pas nécessaire dans Oracle.
BigQuery est entièrement géré et diffère des systèmes de base de données traditionnels au niveau de ses fonctionnalités de sauvegarde complètes. Vous n'avez pas besoin de prendre en compte les défaillances du serveur, du stockage, les bugs système et les corruptions de données physiques. BigQuery réplique les données sur différents centres de données en fonction de l'emplacement des ensembles de données afin de maximiser la fiabilité et la disponibilité. La fonctionnalité multirégionale de BigQuery réplique les données dans différentes régions et protège contre l'indisponibilité d'une seule zone de la région. La fonctionnalité de région unique de BigQuery réplique les données sur différentes zones de la même région.
BigQuery vous permet d'interroger les instantanés historiques des tables jusqu'à sept jours et de restaurer les tables supprimées dans un délai de deux jours à l'aide de la fonctionnalité temporelle.
Vous pouvez copier une table supprimée (afin de la restaurer) à l'aide de la syntaxe des instantanés (dataset.table@timestamp).
Vous pouvez exporter les données de tables BigQuery pour des besoins de sauvegarde supplémentaires tels que la récupération après des opérations utilisateur accidentelles. Les stratégies et planifications de sauvegarde éprouvées utilisées pour les systèmes d'entrepôt de données existants peuvent être utilisées pour les sauvegardes.
Les opérations par lot et la technique de création d'instantanés permettent différentes stratégies de sauvegarde pour BigQuery. Vous n'avez donc pas besoin d'exporter fréquemment des tables et des partitions inchangées. Une sauvegarde d'exportation de la partition ou de la table est suffisante une fois l'opération de chargement ou d'ETL terminée. Pour réduire les coûts de sauvegarde, vous pouvez stocker les fichiers d'exportation dans Cloud Storage en stockage Nearline ou Coldline et définir une stratégie de cycle de vie pour supprimer les fichiers au bout d'un certain temps, en fonction des exigences de conservation des données.
Mise en cache
BigQuery propose un cache par utilisateur. Si les données ne changent pas, les résultats des requêtes sont mis en cache pendant environ 24 heures. Si les résultats sont récupérés à partir du cache, la requête ne coûte rien.
Oracle propose plusieurs caches pour les données et les résultats de requête, tels que le cache de tampon, le cache de résultats, le cache Flash d'Exadata et magasin de colonnes en mémoire.
Connexions
BigQuery assure la gestion des connexions et ne nécessite de votre part aucune configuration côté serveur. BigQuery fournit des pilotes JDBC et ODBC. Vous pouvez utiliser la console Google Cloud ou bq command-line tool pour les requêtes interactives. Vous pouvez utiliser les API REST et les bibliothèques clientes pour interagir avec BigQuery de manière automatisée. Vous pouvez connecter Google Sheets directement à BigQuery, et il existe également un connecteur BigQuery pour Excel.
Si vous recherchez un client de bureau, il existe des outils libres tels que DBeaver.
Oracle propose des écouteurs, des services, des gestionnaires de services, plusieurs paramètres de configuration et de réglage, ainsi que des serveurs partagés et dédiés pour gérer les connexions à la base de données. Oracle fournit des pilotes JDBC, JDBC Thin, ODBC, et des connexions par le client Oracle et TNS. Des écouteurs, adresses IP et un nom d'analyse sont nécessaires pour les configurations RAC.
Tarifs et licences
Oracle nécessite des licences et des frais d'assistance basés sur le nombre de cœurs pour les éditions de base de données et pour les options de base de données telles que RAC, multitenant, Active Data Guard, le partitionnement en mémoire, Real Application Testing, GoldenGate, et Spatial and Graph.
BigQuery propose des options de tarification flexibles en fonction de l'utilisation du stockage, des requêtes et des insertions en flux continu. BigQuery propose des tarifs basés sur la capacité pour les clients qui ont besoin de coûts et de capacités d'emplacements prévisibles dans des régions spécifiques. Les emplacements utilisés pour les insertions et les chargements en flux continu ne sont pas comptabilisés dans la capacité d'emplacements du projet. Pour déterminer le nombre d'emplacements que vous souhaitez acheter pour votre entrepôt de données, consultez la page Planification de la capacité BigQuery.
De plus, BigQuery réduit automatiquement les coûts de stockage de moitié pour les données non modifiées stockées pendant plus de 90 jours.
Étiquetage
Les ensembles de données, tables et vues BigQuery peuvent être étiquetés avec des paires clé/valeur. Les étiquettes peuvent servir à différencier les coûts de stockage et les rejets de débit internes.
Surveillance et journaux d'audit
Oracle propose différents niveaux et types d'options pour l'audit de base de données, ainsi que des fonctionnalités d'audit vault et de pare-feu de base de données, qui font l'objet d'une licence séparée. Oracle fournit Enterprise Manager pour la surveillance des bases de données.
Pour BigQuery, Cloud Audit Logs est utilisé pour les journaux d'accès aux données et les journaux d'audit, qui sont activés par défaut. Les journaux d'accès aux données sont disponibles pendant 30 jours, tandis que les autres journaux des événements système et des activités d'administration sont disponibles pendant 400 jours. Si vous avez besoin de les conserver plus longtemps, vous pouvez les exporter vers BigQuery, Cloud Storage ou Pub/Sub, comme décrit dans la section Analyse des journaux de sécurité dans Google Cloud. Si une intégration avec un outil de surveillance des incidents existant est nécessaire, Pub/Sub peut être utilisé pour les exportations et un développement personnalisé doit être réalisé sur l'outil existant pour lire les journaux à partir de Pub/Sub.
Les journaux d'audit incluent tous les appels d'API, les instructions de requête et les états des jobs. Vous pouvez utiliser Cloud Monitoring pour surveiller l'allocation des emplacements, les octets analysés dans les requêtes et stockés, ainsi que d'autres métriques BigQuery. Le plan et la chronologie des requêtes BigQuery permettent d'analyser les étapes et les performances des requêtes.
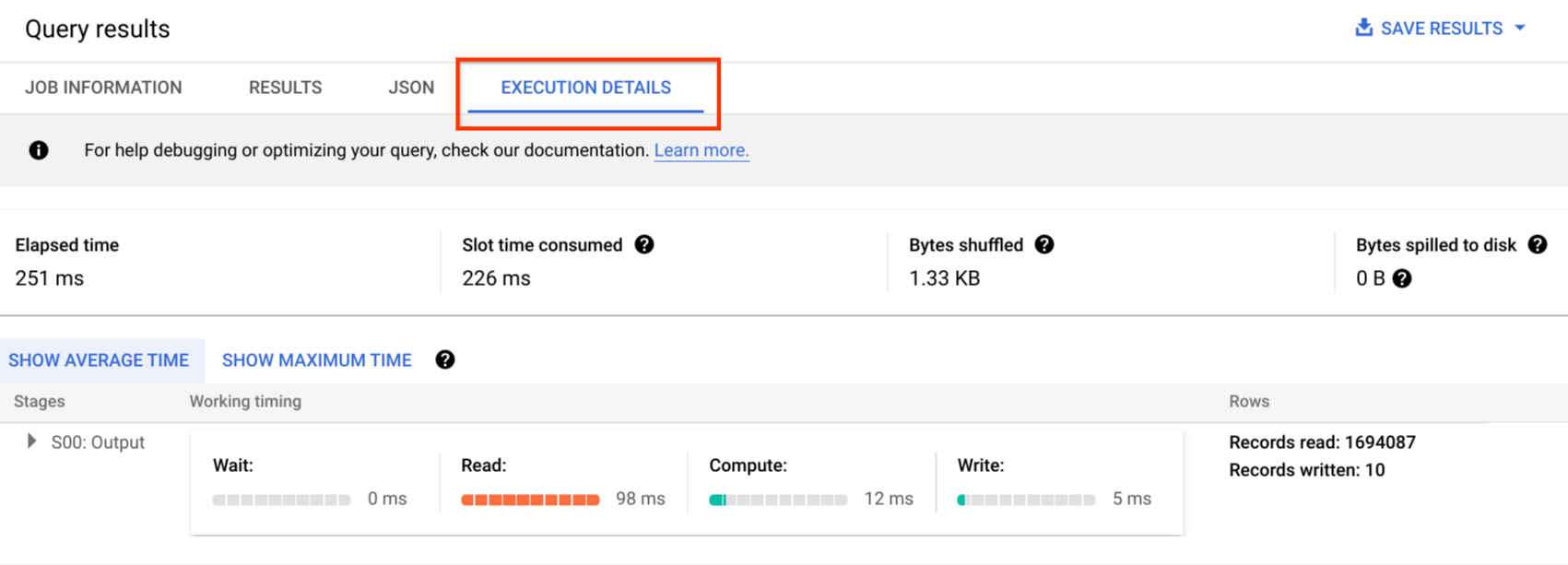
Vous pouvez utiliser la table des messages d'erreur pour résoudre les erreurs de job de requête et d'API. Pour distinguer les allocations d'emplacements par requête ou par job, vous pouvez utiliser cet utilitaire, qui est intéressant pour les clients utilisant des tarifs basés sur la capacité et ayant de nombreux projets répartis sur plusieurs équipes.
Maintenance, mises à niveau et versions
BigQuery est un service entièrement géré, qui ne nécessite de votre part aucune maintenance ni mise à niveau. BigQuery ne propose pas différentes versions. Les mises à niveau sont continues, elles n'occasionnent pas de temps d'arrêt et ne nuisent pas aux performances du système. Pour en savoir plus, consultez les Notes de version.
Oracle et Exadata nécessitent que vous assuriez l'application des correctifs et des mises à niveau, ainsi que la maintenance au niveau de la base de données et de l'infrastructure sous-jacente. Il existe de nombreuses versions d'Oracle, et la sortie d'une nouvelle version majeure est prévue chaque année. Bien que les nouvelles versions soient rétrocompatibles, les performances des requêtes, le contexte et les fonctionnalités peuvent changer.
Certaines applications nécessitent des versions spécifiques telles que 10g, 11g ou 12c. Une planification et des tests minutieux sont nécessaires pour les mises à niveau majeures d'une base de données. La migration à partir de différentes versions peut inclure des besoins de conversion technique différents sur les clauses de requête et les objets de base de données.
Workloads
Oracle Exadata est compatible avec les charges de travail mixtes, y compris les charges de travail OLTP. BigQuery est conçu pour les analyses et non pour gérer les charges de travail OLTP. Les charges de travail OLTP qui utilisent le même Oracle doivent être migrées vers Cloud SQL, Spanner ou Firestore dans Google Cloud. Oracle propose des options supplémentaires telles que Advanced Analytics, et Spatial and Graph. Il peut être nécessaire de réécrire ces charges de travail pour les migrer vers BigQuery. Pour en savoir plus, consultez la section Migrer les options Oracle.
Paramètres et réglages
Oracle propose et nécessite de nombreux paramètres à configurer et régler au niveau dusystème d'exploitation, de la base de données, des options RAC et ASM et des écouteurs pour différentes charges de travail et applications. BigQuery est un service entièrement géré, qui ne nécessite de votre part aucune configuration de paramètres d'initialisation.
Limites et quotas
Oracle applique des limites strictes et souples en fonction de l'infrastructure, de la capacité du matériel, des paramètres, des versions logicielles et des licences. BigQuery applique des quotas et limites sur des actions et des objets spécifiques.
Provisionnement de BigQuery
BigQuery est une plate-forme PaaS (Platform as a Service) et un entrepôt de données cloud de traitement massivement parallèle. Sa capacité évolue à la hausse ou à la baisse sans aucune intervention de l'utilisateur, du fait que Google gère le backend. Par conséquent, contrairement à de nombreux systèmes de SGBDR, BigQuery n'a pas besoin que vous provisionniez les ressources avant utilisation. BigQuery alloue des ressources de stockage et de requête de manière dynamique en fonction de vos habitudes d'utilisation. Les ressources de stockage sont allouées au fur et à mesure que vous les consommez et libérées lorsque vous supprimez des données ou des tables. Les ressources de requête sont allouées en fonction du type de requête et de la complexité. Chaque requête utilise des emplacements. Un programmeur avec équité à terme est utilisé. Il peut donc y avoir de courtes périodes durant lesquelles certaines requêtes reçoivent une part d'emplacements plus élevée, mais le programmeur finit par corriger cette inégalité.
En termes de VM classiques, BigQuery vous offre l'équivalent des deux éléments suivants :
- Facturation à la seconde
- Scaling à la seconde
Pour y parvenir, BigQuery assure les tâches suivantes :
- Il conserve des ressources volumineuses déployées pour éviter d'avoir à évoluer rapidement.
- Il utilise des ressources mutualisées pour allouer instantanément de grands fragments pendant quelques secondes à la fois.
- Il alloue efficace les ressources pour l'ensemble des utilisateurs avec des économies d'échelle.
- Vous n'êtes facturé que pour les jobs que vous exécutez, et non pour les ressources déployées. Vous payez donc les ressources que vous utilisez.
Pour en savoir plus sur la tarification, consultez la section Comprendre la capacité de scaling rapide et la tarification simple de BigQuery.
Migration du schéma
Pour migrer des données d'Oracle vers BigQuery, vous devez connaître les types de données Oracle et les mappages BigQuery.
Types de données Oracle et mappages BigQuery
Les types de données Oracle diffèrent des types de données BigQuery. Pour plus d'informations sur les types de données BigQuery, consultez la documentation officielle.
Pour obtenir une comparaison détaillée des types de données respectifs d'Oracle et BigQuery, consultez le Guide de traduction du langage SQL d'Oracle.
Index
Dans de nombreuses charges de travail analytiques, des tables en colonnes sont utilisées à la place du stockage en lignes. Cela augmente considérablement les opérations basées sur les colonnes et élimine l'utilisation des index pour les analyses par lot. BigQuery stocke également les données sous forme de colonnes. Les index ne sont donc pas nécessaires dans BigQuery. Si la charge de travail d'analyse nécessite un seul petit ensemble d'accès basés sur les lignes, Bigtable peut être une meilleure alternative. Si une charge de travail nécessite un traitement des transactions avec une forte cohérence relationnelle, Spanner ou Cloud SQL peuvent être de meilleures alternatives.
En résumé, aucun index n'est nécessaire et proposé dans BigQuery pour les analyses par lot. Le partitionnement ou le clustering peuvent être utilisés. Pour savoir comment ajuster et améliorer les performances des requêtes dans BigQuery, consultez la page Présentation de l'optimisation des performances des requêtes.
Vues
Comme Oracle, BigQuery permet de créer des vues personnalisées. Cependant, les vues dans BigQuery ne sont pas compatibles avec les instructions LMD.
Vues matérialisées
Les vues matérialisées sont couramment utilisées pour améliorer le temps de rendu des rapports dans les types de rapports et de charges de travail "Write Once Read Many".
Les vues matérialisées sont proposées dans Oracle pour améliorer les performances des vues en créant et en maintenant simplement une table pour y stocker l'ensemble de données des résultats de la requête. Il existe deux façons d'actualiser les vues matérialisées dans Oracle : au commit et à la demande.
La fonctionnalité de vue matérialisée est également disponible dans BigQuery. BigQuery exploite les résultats précalculés des vues matérialisées et, dans la mesure du possible, ne lit que les modifications delta de la table de base pour calculer les résultats à jour.
Les fonctionnalités de mise en cache dans Looker Studio ou d'autres outils d'informatique décisionnelle modernes peuvent également améliorer les performances et vous éviter d'avoir à réexécuter la même requête, ce qui réduit les coûts.
Partitionnement de table
Le partitionnement des tables est largement utilisé dans les entrepôts de données Oracle. Contrairement à Oracle, BigQuery n'est pas compatible avec le partitionnement hiérarchique.
BigQuery met en œuvre trois types de partitionnements de table permettant aux requêtes de spécifier des filtres de prédicat basés sur la colonne de partitionnement afin de réduire la quantité de données analysées.
- Tables partitionnées par temps d'ingestion : les tables sont partitionnées en fonction du temps d'ingestion des données.
- Tables partitionnées par colonne : les tables sont partitionnées en fonction d'une colonne
TIMESTAMPouDATE. - Tables partitionnées par plage d'entiers : les tables sont partitionnées en fonction d'une colonne de nombres entiers.
Pour plus d'informations sur les limites et les quotas appliqués aux tables partitionnées dans BigQuery, consultez la section Présentation des tables partitionnées.
Si les restrictions BigQuery affectent les fonctionnalités de la base de données migrée, envisagez d'utiliser la segmentation au lieu du partitionnement.
De plus, BigQuery n'accepte pas EXCHANGE PARTITION, SPLIT PARTITION ni la conversion d'une table non partitionnée en table partitionnée.
Clustering
Le clustering permet d'organiser et de récupérer efficacement les données stockées dans plusieurs colonnes, qui sont souvent consultées ensemble. Toutefois, les circonstances dans lesquelles le clustering fonctionne mieux sont différentes pour Oracle et BigQuery. Dans BigQuery, si une table est généralement filtrée et agrégée suivant des colonnes spécifiques, utilisez le clustering. Le clustering peut être envisagé pour migrer des tables partitionnées par liste ou classées par index depuis Oracle.
Tables temporaires
Les tables temporaires sont souvent utilisées dans les pipelines ETL Oracle. Une table temporaire contient des données durant une session utilisateur. Ces données sont automatiquement supprimées à la fin de la session.
BigQuery utilise des tables temporaires pour mettre en cache les résultats des requêtes qui ne sont pas écrits dans une table permanente. Une fois la requête terminée, les tables temporaires peuvent exister jusqu'à 24 heures. Les tables sont créées dans un ensemble de données spécial et nommées de manière aléatoire. Vous pouvez également créer des tables temporaires pour votre utilisation. Pour en savoir plus, consultez la section Tables temporaires.
Tables externes
Comme Oracle, BigQuery vous permet d'interroger des sources de données externes. BigQuery permet d'interroger des données directement à partir de sources de données externes, y compris les suivantes :
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
Modélisation des données
Les modèles de données en étoile ou en flocon peuvent être efficaces pour le stockage de données d'analyse et sont couramment utilisés pour les entrepôts de données sur Oracle Exadata.
Les tables dénormalisées éliminent les opérations de jointure coûteuses et, dans la plupart des cas, offrent de meilleures performances pour les analyses dans BigQuery. Les modèles de données en étoile et en flocon sont également pris en charge par BigQuery. Pour en savoir plus sur la conception d'entrepôts de données sur BigQuery, consultez la section Concevoir un schéma.
Différences entre le format de ligne et le format de colonne, et les limites des systèmes sur serveur et sans serveur
Oracle utilise un format de ligne dans lequel la ligne de table est stockée dans des blocs de données. Par conséquent, les colonnes inutiles sont extraites du bloc pour les requêtes d'analyse, en fonction du filtrage et de l'agrégation de colonnes spécifiques.
Oracle utilise une architecture où tout est partagé, avec des dépendances de ressources matérielles fixes, telles que la mémoire et l'espace de stockage, attribuées au serveur. Ce sont les deux principales forces sous-jacentes à de nombreuses techniques de modélisation des données qui ont évolué pour améliorer l'efficacité du stockage et les performances des requêtes d'analyse. C'est le cas des schémas en étoile et en flocon de neige, ainsi que de la modélisation Data Vault.
BigQuery utilise un format en colonnes pour stocker les données et n'a pas de limites fixes sur le stockage et la mémoire. Cette architecture vous permet de dénormaliser davantage et de concevoir des schémas en fonction des lectures et des besoins de votre entreprise et de vos lectures, permettant ainsi de réduire la complexité et d'améliorer la flexibilité, l'évolutivité et les performances.
Dénormalisation
L'un des principaux objectifs de la normalisation des bases de données relationnelles est de réduire la redondance des données. Bien que ce modèle soit particulièrement adapté à une base de données relationnelle utilisant un format de ligne, la dénormalisation des données est préférable pour les bases de données en colonnes. Pour en savoir plus sur les avantages de la dénormalisation des données et d'autres stratégies d'optimisation des requêtes dans BigQuery, consultez la section Dénormalisation.
Techniques pour aplatir votre schéma existant
La technologie BigQuery exploite une combinaison d'accès et de traitement des données en colonnes, d'espace de stockage en mémoire et de traitement distribué pour fournir de bonnes performances de requête.
Lors de la conception d'un schéma d'entrepôt de données BigQuery, la création d'une table de faits dans une structure de table plate (qui consolide toutes les tables de dimensions en un seul enregistrement dans la table de faits) est plus optimale pour l'utilisation du stockage que l'utilisation de plusieurs tables de dimensions d'entrepôt de données. En plus de réduire l'utilisation du stockage, le fait d'avoir une table plate dans BigQuery entraîne une réduction de l'utilisation de JOIN. Le diagramme suivant illustre un exemple d'aplatissement de votre schéma.
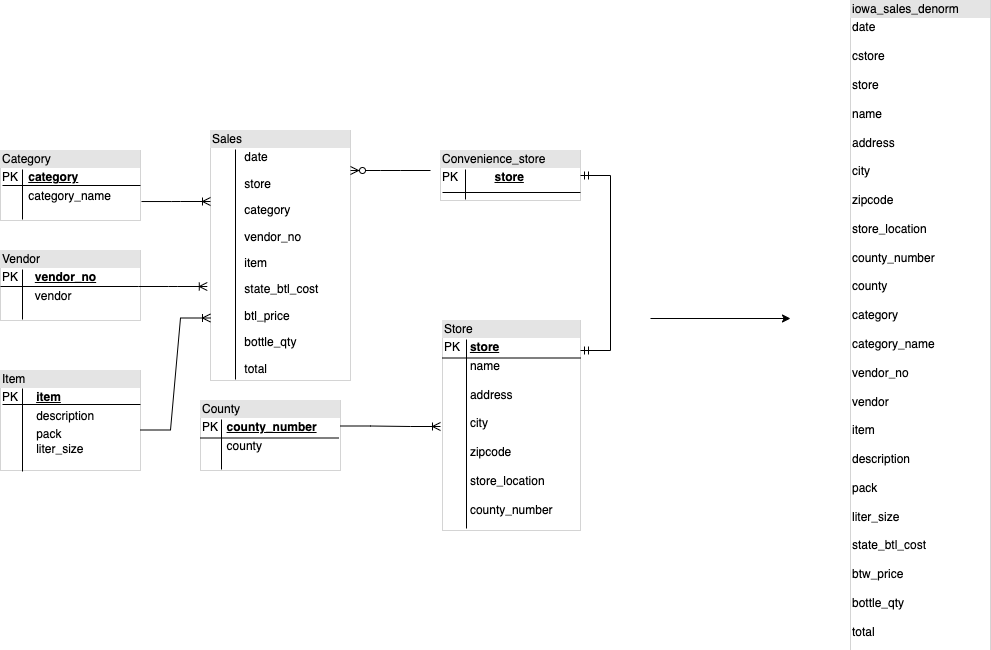
Exemple d'aplatissement d'un schéma en étoile
La Figure 1 illustre une base de données fictive de gestion des ventes comprenant quatre tables :
- Table des commandes/ventes (table de faits)
- Table des employés
- Table des emplacements
- Table des clients
La clé primaire de la table des ventes est OrderNum, qui contient également des clés étrangères pour les trois autres tables.
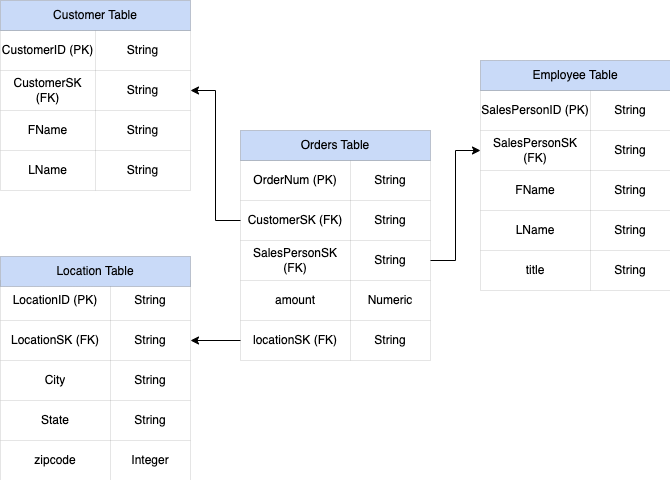
Figure 1 : Exemples de données de ventes dans un schéma en étoile
Exemples de données
Contenu de la table de commandes/faits
| OrderNum | CustomerID | SalesPersonID | amount | Location |
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
Contenu de la table des employés
| SalesPersonID | FName | LName | title |
| 1 | Alex | Smith | Commercial |
| 4 | Lisa | Dupont | Commercial |
| 12 | John | Dupont | Commercial |
Contenu de la table des clients
| CustomerID | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Contenu de la table des emplacements
| Location | city | city | city |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
Requête permettant d'aplatir les données à l'aide de l'instruction LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
Sortie des données aplaties
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | amount | Location | city | state | zipcode |
| O-1 | 1234 | Amanda | Lee | 12 | John | Dupont | 234.22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | John | Dupont | 14.66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Dupont | 182.00 | 26 | Montagne
View |
CA | 90210 |
Champs imbriqués et répétés
Pour concevoir et créer un schéma d'entrepôt de données à partir d'un schéma relationnel (par exemple, schémas en étoile et en flocon contenant des tables de dimensions et de faits), BigQuery présente les fonctionnalités de champs imbriqués et répétés. Par conséquent, les relations peuvent être conservées de la même manière qu'un schéma d'entrepôt de données relationnel normalisé (ou partiellement normalisé) sans affecter les performances. Pour plus d'informations, consultez les bonnes pratiques en matière de performances.
Pour mieux comprendre la mise en œuvre des champs imbriqués et répétés, examinez un schéma relationnel simple d'une table CUSTOMERS et d'une table ORDER/SALES. Il s'agit de deux tables différentes, une pour chaque entité, et les relations sont définies à l'aide d'une clé telle qu'une clé primaire et une clé étrangère servant de lien entre les tables lors de l'interrogation à l'aide de jointures JOIN. Les champs imbriqués et répétés de BigQuery vous permettent de conserver la même relation entre les entités dans une même table. Cela peut être implémenté en rassemblant toutes les données concernant les clients, tandis que les données des commandes sont imbriquées pour chacun des clients. Pour en savoir plus, consultez la section Spécifier des colonnes imbriquées et répétées.
Pour convertir la structure plate en schéma imbriqué ou répété, imbriquez les champs comme suit :
CustomerID,FName,LNameimbriqués dans un nouveau champ appeléCustomer.SalesPersonID,FName,LNameimbriqués dans un nouveau champ appeléSalesperson.LocationID,city,state,zip codeimbriqués dans un nouveau champ appeléLocation.
Les champs OrderNum et amount ne sont pas imbriqués, car ils représentent des éléments uniques.
Il est souhaitable de rendre votre schéma suffisamment flexible pour permettre à chaque commande d'avoir plusieurs clients : un principal et un secondaire. Le champ client est marqué comme répété. Le schéma obtenu est illustré à la Figure 2, qui illustre les champs imbriqués et répétés.
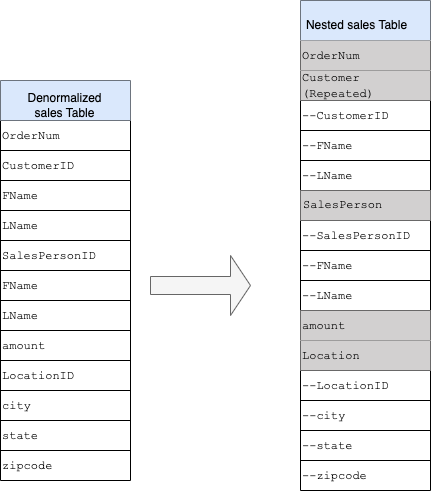
Figure 2 : Représentation logique d'une structure imbriquée
Dans certains cas, la dénormalisation à l'aide de champs imbriqués et répétés n'entraîne pas d'amélioration des performances. Pour plus d'informations sur les limites et les restrictions des champs imbriqués et répétés, consultez la section Charger des données dénormalisées, imbriquées et répétées.
Clés de substitution
Il est courant d'identifier les lignes dans les tables à l'aide de clés uniques. Chez Oracle, les séquences sont couramment utilisées pour créer ces clés. Dans BigQuery, vous pouvez créer des clés de substitution à l'aide des fonctions row_number et partition by. Pour en savoir plus, consultez la section BigQuery et clés de substitution : une approche pratique.
Suivre les modifications et l'historique
Lorsque vous planifiez une migration d'entrepôt de données BigQuery, tenez compte du concept de dimensions à évolution lente (slowly changing dimensions ou SCD). En général, le terme SCD décrit le processus consistant à apporter des modifications (opérations LMD) dans les tables de dimensions.
Pour diverses raisons, les entrepôts de données traditionnels utilisent des types différents pour gérer les modifications de données et conserver les données historiques dans des dimensions à évolution lente. Ces utilisations de types sont nécessaires compte tenu des limites matérielles et des exigences d'efficacité décrites précédemment. Comme le stockage est beaucoup moins cher que le calcul et extrêmement évolutif, la redondance et la duplication des données sont encouragées si elles aboutissent à des requêtes plus rapides dans BigQuery. Vous pouvez utiliser des techniques de création d'instantanés de données, qui permettent de charger l'intégralité des données dans de nouvelles partitions quotidiennes.
Vues spécifiques aux rôles et aux utilisateurs
Utilisez des vues spécifiques aux rôles et aux utilisateurs lorsque les utilisateurs appartiennent à différentes équipes et ne doivent voir que les enregistrements et les résultats dont ils ont besoin.
BigQuery est compatible avec la sécurité au niveau des colonnes et au niveau des lignes. La sécurité au niveau des colonnes fournit un accès précis aux colonnes sensibles à l'aide de tags avec stratégie, autrement dit une classification des données basée sur le type. La sécurité au niveau des lignes vous permet de filtrer les données et d'accéder à des lignes spécifiques d'une table, en fonction des conditions d'éligibilité de l'utilisateur.
Migration de données
Cette section fournit des informations sur la migration de données depuis Oracle vers BigQuery, y compris le chargement initial, la capture de données modifiées (CDC), ainsi que les outils et approches ETL/ELT.
Activités de migration
Il est recommandé d'effectuer la migration en plusieurs phases, en identifiant les cas d'utilisation appropriés. Plusieurs outils et services sont disponibles pour migrer des données d'Oracle vers Google Cloud. Bien que cette liste ne soit pas exhaustive, elle donne une idée de la taille et de l'ampleur de l'effort de migration.
Exporter des données en dehors d'Oracle : pour en savoir plus, consultez les sections Chargement initial et CDC et ingestion en flux continu depuis Oracle vers BigQuery. Les outils ETL peuvent être utilisés pour le chargement initial.
Préproduction des données (dans Cloud Storage) : Cloud Storage est l'emplacement de destination recommandé (zone de préproduction) pour les données exportées depuis Oracle. Cloud Storage est conçu pour une ingestion rapide et flexible de données structurées ou non structurées.
Processus ETL : pour plus d'informations, consultez la section Migration ETL/ELT.
Charger les données directement dans BigQuery : vous pouvez charger les données dans BigQuery directement depuis Cloud Storage, via Dataflow ou via un flux en temps réel. Utilisez Dataflow lorsqu'une transformation des données est requise.
Chargement initial
La migration des données initiales à partir de l'entrepôt de données Oracle existant vers BigQuery peut être différente des pipelines ETL/ELT incrémentiels suivant la taille des données et la bande passante réseau. Vous pouvez utiliser les mêmes pipelines ETL/ELT si la taille des données est de quelques téraoctets.
Si les données atteignent quelques téraoctets, le vidage des données et l'utilisation de gsutil pour le transfert peuvent s'avérer bien plus efficaces que l'utilisation de la méthodologie d'extraction de base de données par programmation de type JdbcIO, car les approches automatisées peuvent nécessiter un réglage beaucoup plus fin des performances. Si la taille des données dépasse les quelques téraoctets et qu'elles sont hébergées dans un stockage en ligne ou dans le cloud (tel qu'Amazon Simple Storage Service, Amazon S3), envisagez d'utiliser le service de transfert de données BigQuery. Transfer Appliance est une option utile pour les transferts à grande échelle (en particulier les transferts avec une bande passante réseau limitée)
Contraintes liées au chargement initial
Lorsque vous planifiez une migration de données, tenez compte des points suivants :
- Taille des données de l'entrepôt Oracle : la taille source de votre schéma a une incidence significative sur la méthode de transfert de données choisie, en particulier lorsque le volume de données est important (téraoctets ou plus). Lorsque la taille des données est relativement faible, le processus de transfert de données peut être réalisé en moins d'étapes. Le traitement de volumes de données à grande échelle rend le processus global plus complexe.
Temps d'arrêt : il est important de déterminer si un temps d'arrêt est une option pour votre migration vers BigQuery. Pour réduire les temps d'arrêt, vous pouvez charger les données historiques stables de manière groupée, et disposer d'une solution CDC pour rattraper les modifications ayant eu lieu pendant le processus de transfert.
Tarification : dans certains scénarios, vous aurez peut-être besoin d'outils d'intégration tiers (par exemple, des outils ETL ou de réplication) nécessitant des licences supplémentaires.
Transfert de données initial (par lot)
Le transfert de données à l'aide d'une méthode par lot indique que les données seront exportées de manière cohérente lors d'un processus unique (par exemple, l'exportation des données de schéma d'entrepôt de données Oracle vers des fichiers CSV, Avro ou Parquet ou l'importation vers Cloud Storage afin de créer des ensembles de données dans BigQuery). Tous les outils et concepts ETL expliqués dans la section Migration ETL/ELT peuvent être utilisés pour le chargement initial.
Si vous ne souhaitez pas utiliser un outil ETL/ELT pour le chargement initial, vous pouvez écrire des scripts personnalisés pour exporter des données vers des fichiers (CSV, Avro ou Parquet) et les importer dans Cloud Storage à l'aide de gsutil, le service de transfert de données BigQuery ou Transfer Appliance. Pour plus d'informations sur l'ajustement des performances des transferts de données volumineux et les options de transfert, consultez la page Transférer vos ensembles de données volumineux. Chargez ensuite des données depuis Cloud Storage vers BigQuery.
Cloud Storage est idéal pour gérer l'arrivée initiale des données. Cloud Storage est un service de stockage d'objets à disponibilité élevée et durable. Le nombre de fichiers n'est pas limité, et vous ne payez que pour l'espace de stockage utilisé. Ce service est optimisé pour fonctionner avec d'autres services Google Cloud tels que BigQuery et Dataflow.
CDC et ingestion en flux continu depuis Oracle vers BigQuery
Il existe plusieurs façons de capturer les données modifiées à partir d'Oracle. Chaque option présente des compromis, principalement en termes d'impact sur les performances du système source, sur les exigences de développement et de configuration, ainsi que sur la tarification et les licences.
CDC basée sur les journaux
Oracle GoldenGate est l'outil d'Oracle recommandé pour l'extraction des journaux de rétablissement. Vous pouvez utiliser GoldenGate for Big Data pour la diffusion des journaux dans BigQuery. GoldenGate nécessite des licences par processeur. Pour en savoir plus sur les tarifs, consultez la page Liste des tarifs mondiaux des technologies Oracle. Si Oracle GoldenGate for Big Data est disponible (si des licences ont déjà été acquises), l'utilisation de GoldenGate peut être un bon choix pour créer des pipelines de données afin de transférer des données (chargement initial), puis de synchroniser toutes les modifications de données.
Oracle XStream
Oracle stocke chaque commit dans des fichiers journaux de rétablissement, qui peuvent être utilisés pour la CDC. Oracle XStream Out est basé sur LogMiner et fourni par des outils tiers tels que Debezium (à partir de la version 0.8) ou commercialement à travers des outils tels que Alooma ou Striim. L'utilisation des API XStream nécessite l'achat d'une licence Oracle GoldenGate, même si GoldenGate n'est pas installé et utilisé. XStream vous permet de propager efficacement les messages Streams entre Oracle et d'autres logiciels.
Oracle LogMiner
Aucune licence spéciale n'est requise pour LogMiner. Vous pouvez utiliser l'option LogMiner dans le connecteur de communauté Debezium. Il est également disponible sur le marché à travers des outils tels que Attunity, Striim ou StreamSets. LogMiner peut avoir un impact sur les performances d'une base de données source très active et doit être utilisé avec prudence lorsque le volume de modifications (la taille du rétablissement) est supérieur à 10 Go par heure en fonction des capacités et de l'utilisation du serveur au niveau du processeur, de la mémoire et des E/S.
CDC basée sur SQL
Il s'agit de l'approche ETL incrémentielle dans laquelle les requêtes SQL interrogent en permanence les tables sources pour vérifier si des modifications ont été apportées en fonction d'une clé qui augmente de façon monotone et d'une colonne de code temporel contenant la dernière date de modification ou d'insertion. S'il n'y a aucune clé augmentant de façon monotone, l'utilisation de la colonne de code temporel (date modifiée) avec une faible précision (secondes) peut entraîner des enregistrements en double ou des données manquées en fonction du volume et de l'opérateur de comparaison, tel que > ou >=.
Pour résoudre ces problèmes, vous pouvez utiliser une précision plus élevée dans les colonnes de code temporel, du type six chiffres après la virgule (correspondant à la microseconde, soit la précision maximale acceptée dans BigQuery) ou ajouter des tâches de déduplication dans votre pipeline ETL/ELT, en fonction des clés métier et des caractéristiques des données.
Il doit y avoir un index sur la colonne de clé ou de code temporel pour améliorer les performances d'extraction et réduire l'impact sur la base de données source. Les opérations de suppression constituent un défi pour cette méthodologie, car elles doivent être gérées dans l'application source de manière réversible, par exemple en ajoutant un drapeau de suppression et en mettant à jour last_modified_date. Une autre solution consiste à consigner ces opérations dans une autre table à l'aide d'un déclencheur.
Déclencheurs
Les déclencheurs de base de données peuvent être créés sur des tables sources pour enregistrer les modifications dans des tables de journalisation fantômes. Les tables de journalisation peuvent contenir des lignes entières pour effectuer le suivi de chaque modification de colonne, ou ne conserver que la clé primaire avec le type d'opération (insertion, mise à jour ou suppression). Vous pouvez ensuite capturer les données modifiées avec une approche basée sur SQL décrite dans la section CDC basée sur SQL. L'utilisation de déclencheurs peut affecter les performances des transactions et doubler la latence des opérations LMD sur une seule ligne en cas de stockage d'une ligne complète. Le stockage de la clé primaire seule peut réduire cette surcharge, mais dans ce cas, une opération JOIN avec la table d'origine est nécessaire pour l'extraction basée sur SQL, ce qui ignore la modification intermédiaire.
Migration ETL/ELT
Il existe de nombreuses possibilités pour gérer les pipelines ETL/ELT sur Google Cloud. Les conseils techniques pour la conversion de charges de travail ETL spécifiques n'entrent pas dans le cadre de ce document. Vous pouvez envisager une approche Lift and Shift ou redéfinir l'architecture de votre plate-forme d'intégration de données en fonction de contraintes telles que les coûts et le temps. Pour en savoir plus sur la migration de vos pipelines de données vers Google Cloud et découvrir de nombreux autres concepts de migration, consultez la page Migrer les pipelines de données.
Approche Lift and Shift
Si votre plate-forme existante est compatible avec BigQuery et que vous souhaitez continuer à utiliser votre outil d'intégration de données existant :
- Vous pouvez conserver la plate-forme ETL/ELT telle quelle et modifier les étapes de stockage nécessaires avec BigQuery dans vos jobs ETL/ELT.
- Si vous souhaitez également migrer la plate-forme ETL/ELT vers Google Cloud, vous pouvez demander à votre fournisseur si la licence de son outil est disponible sur Google Cloud. Le cas échéant, vous pouvez l'installer sur Compute Engine ou vérifier sa disponibilité dans Google Cloud Marketplace
Pour en savoir plus sur les fournisseurs de solutions d'intégration de données, consultez la page Partenaires BigQuery.
Redéfinir l'architecture d'une plate-forme ETL/ELT
Si vous souhaitez redéfinir l'architecture de vos pipelines de données, nous vous recommandons vivement d'utiliser les services Google Cloud.
Cloud Data Fusion
Cloud Data Fusion est une solution CDAP gérée sur Google Cloud qui offre une interface visuelle avec de nombreux plug-ins pour des tâches telles que le glisser-déposer et le développement de pipelines. Cloud Data Fusion peut être utilisé pour capturer des données à partir de nombreux types de systèmes sources, et offre des fonctionnalités de réplication par lots et par flux. Les plug-ins Cloud Data Fusion ou Oracle vous permettent de capturer des données à partir d'Oracle. Un plug-in BigQuery permet de charger les données dans BigQuery et de gérer les mises à jour de schéma.
Aucun schéma de sortie n'est défini à la fois pour les plug-ins sources et récepteurs, et select * from est aussi utilisé dans le plug-in source pour répliquer de nouvelles colonnes.
Vous pouvez utiliser la fonctionnalité Wrangle de Cloud Data Fusion pour le nettoyage et la préparation des données.
Dataflow
Dataflow est une plate-forme de traitement de données sans serveur qui peut effectuer un scaling automatique et traiter des données par lots ou par flux. Dataflow peut être un bon choix pour les développeurs Python et Java qui souhaitent coder leurs pipelines de données et utiliser le même code pour les charges de travail par flux et par lot. Utilisez le modèle JDBC vers BigQuery pour extraire des données de votre base de données Oracle ou d'autres bases de données relationnelles et les charger dans BigQuery. Pour obtenir un exemple de chargement de données à partir d'une base de données relationnelle vers un ensemble de données BigQuery, consultez la page Exécuter des opérations ETL à partir d'une base de données relationnelle dans BigQuery à l'aide de Dataflow.
Cloud Composer
Cloud Composer est un service d'orchestration de workflow entièrement géré de Google Cloud basé sur Apache Airflow. Il vous permet de créer, planifier et surveiller vos pipelines dans plusieurs environnements cloud et centres de données sur site. Cloud Composer fournit des opérateurs et des contributions pouvant exécuter des technologies multicloud pour des cas d'utilisation incluant l'extraction et le chargement, les transformations d'ELT et les appels d'API REST.
Cloud Composer utilise des graphes orientés acycliques (DAG) pour planifier et orchestrer les workflows. Pour comprendre les concepts généraux d'Airflow, consultez la section Concepts d'Apache Airflow. Pour en savoir plus sur les DAG, consultez la page Écrire des DAG (workflows). Pour obtenir des exemples de bonnes pratiques ETL avec Apache Airflow, consultez le site de documentation des bonnes pratiques ETL Airflow. Vous pouvez remplacer l'opérateur Hive de cet exemple par l'opérateur BigQuery, et les mêmes concepts s'appliquent.
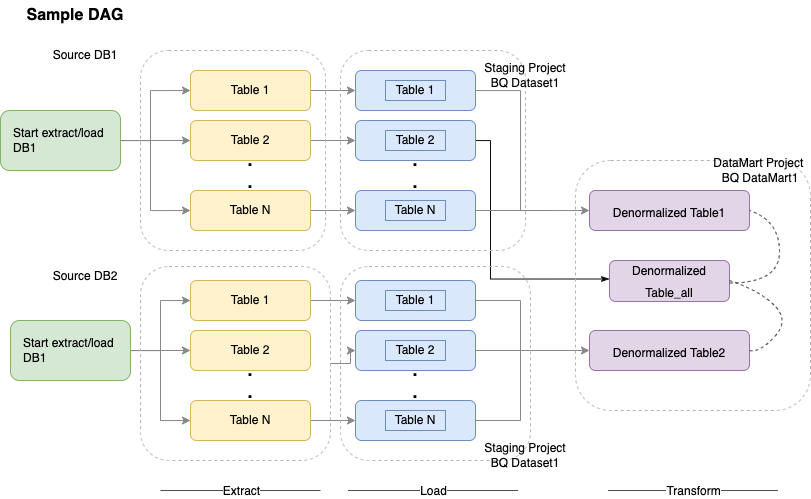
L'exemple de code suivant est un élément de haut niveau d'un exemple de DAG pour le schéma précédent :
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
Le code précédent est fourni à des fins de démonstration et ne peut pas être utilisé tel quel.
Dataprep by Trifacta
Dataprep est un service qui permet d'explorer, de nettoyer et de préparer visuellement des données structurées et non structurées à des fins d'analyse, de création de rapports et de machine learning. Vous pouvez exporter les données sources dans des fichiers JSON ou CSV, les transformer à l'aide de Dataprep, puis les charger à l'aide de Dataflow. Pour obtenir un exemple, consultez la section Tansférer des données Oracle (ETL) vers BigQuery à l'aide de Dataflow et de Dataprep.
Dataproc
Dataproc est un service Hadoop géré par Google. Vous pouvez utiliser Sqoop pour exporter des données en provenance d'Oracle et de nombreuses bases de données relationnelles vers Cloud Storage sous forme de fichiers Avro, puis charger les fichiers Avro dans BigQuery à l'aide de bq tool. Il est très courant d'installer des outils ETL tels que CDAP sur Hadoop, qui utilisent JDBC pour extraire les données, et Apache Spark ou MapReduce pour les transformations des données.
Outils partenaires pour la migration de données
L'espace d'extraction, de transformation et de chargement (ETL) comporte plusieurs fournisseurs. Les leaders du marché ETL tels qu'Informatica, Talend, Matillion, Alooma, Infoworks, Stitch, Fivetran et Striim sont étroitement intégrés à BigQuery et à Oracle. Ils peuvent vous aider à extraire, transformer et charger des données, et gérer des workflows de traitement.
Les outils ETL existent depuis de nombreuses années. Certaines entreprises peuvent trouver plus facile d'exploiter un investissement existant constitué de scripts ETL de confiance. Certaines de nos solutions partenaires clés sont incluses sur le site Web des partenaires BigQuery. Le choix entre des outils partenaires et les utilitaires intégrés à Google Cloud dépend de votre infrastructure actuelle et de l'expertise de votre équipe informatique en matière de développement de pipelines de données en code Java ou Python.
Migration des outils d'informatique décisionnelle
BigQuery offre une suite flexible de solutions d'informatique décisionnelle dont vous pouvez tirer parti pour la génération de rapports et l'analyse. Pour en savoir plus sur la migration et l'intégration à BigQuery des outils d'informatique décisionnelle, consultez la page Présentation des analyses BigQuery.
Traduction de requête (SQL)
Le langage GoogleSQL de BigQuery est conforme à la norme SQL 2011 et inclut des extensions permettant d'interroger des données imbriquées et répétées. Toutes les fonctions et tous les opérateurs SQL compatibles avec ANSI peuvent être utilisés avec des modifications minimales. Pour obtenir une comparaison détaillée de la syntaxe et des fonctions SQL entre Oracle et BigQuery, consultez la documentation de référence sur la traduction du langage SQL d'Oracle vers BigQuery.
Utilisez la traduction SQL par lot pour migrer votre code SQL de façon groupée, ou la traduction SQL interactive pour traduire des requêtes ad hoc.
Migrer les options Oracle
Cette section présente des recommandations et des documentations de référence concernant l'architecture pour convertir les applications qui utilisent les fonctionnalités des options Oracle Data Mining, R et Spatial and Graph.
Option Oracle Advanced Analytics
Oracle propose des options d'analyse avancées pour l'exploration de données, les algorithmes fondamentaux de machine learning (ML) et l'utilisation de R. L'option Advanced Analytics nécessite des licences. Vous pouvez choisir parmi une liste complète de produits d'IA/de ML Google en fonction de vos besoins, du développement à la production à grande échelle.
Oracle R Enterprise
Oracle R Enterprise (ORE), un composant de l'option Oracle Advanced Analytics, intègre à Oracle le langage de programmation statistique Open Source R. Dans les déploiements ORE standards, R est installé sur un serveur Oracle.
Pour les très grandes échelles de données ou les approches d'entreposage, l'intégration de R à BigQuery constitue un choix idéal. Vous pouvez utiliser la bibliothèque R Open Source bigrquery pour intégrer R à BigQuery.
Google s'est associé à RStudio pour mettre les outils de pointe du domaine à la disposition des utilisateurs. RStudio peut être utilisé pour accéder à plusieurs téraoctets de données dans BigQuery, ajuster des modèles dans TensorFlow, et exécuter des modèles de machine learning à grande échelle avec AI Platform. Dans Google Cloud, R peut être installé sur Compute Engine à grande échelle.
Oracle Data Mining
Oracle Data Mining (ODM), un composant de l'option Oracle Advanced Analytics, permet aux développeurs de créer des modèles de machine learning à l'aide d'Oracle PL/SQL Developer sur Oracle.
BigQuery ML permet aux développeurs d'exécuter de nombreux types de modèles, tels que des modèles de régression linéaire, de régression logistique binaire, de régression logistique multiclasses, de clustering en k-moyennes, ainsi que des importations de modèles TensorFlow. Pour en savoir plus, consultez la section Présentation de BigQuery ML.
La conversion de jobs ODM peut nécessiter la réécriture du code. Vous avez le choix entre des solutions de produits d'IA Google complètes telles que BigQuery ML, les API d'IA (notamment Speech-to-Text, Text-to-Speech, Dialogflow, Cloud Translation, l'API Cloud Natural Language, Cloud Vision, l'API Timeseries Insights), ou Vertex AI.
Vertex AI Workbench peut être utilisé comme environnement de développement pour les data scientists, et Vertex AI Training peut être utilisé pour exécuter l'entraînement et l'évaluation des charges de travail à grande échelle.
Option Spatial and Graph
Oracle propose l'option Spatial and Graph pour l'interrogation de données de géométrie et de graphiques. Cette option requiert une licence. Vous pouvez utiliser les fonctions de géométrie dans BigQuery sans frais ni licences supplémentaires, et utiliser d'autres bases de données de graphes dans Google Cloud.
Spatial
BigQuery propose des fonctions et des types de données pour l'analyse géospatiale. Pour en savoir plus, consultez la section Utiliser des données issues des analyses géospatiales. Les types de données et les fonctions spatiales d'Oracle peuvent être convertis en fonctions de géographie en SQL standard BigQuery. Les fonctions de géographie n'entraînent pas de coûts supplémentaires par-dessus les tarifs standards de BigQuery.
Graph
JanusGraph est une solution de base de données de graphes Open Source permettant d'utiliser Bigtable en tant que backend de stockage. Pour en savoir plus, consultez la section Exécuter JanusGraph sur GKE avec Bigtable.
Neo4j est une autre solution de base de données de graphes fournie en tant que service Google Cloud qui s'exécute sur Google Kubernetes Engine (GKE).
Oracle Application Express
Les applications Oracle Application Express (APEX) sont spécifiques à Oracle et doivent être réécrites. Les fonctionnalités de création de rapports et de visualisation des données peuvent être développées à l'aide de Looker Studio ou de BI Engine, tandis que les fonctionnalités au niveau de l'application, telles que la création et la modification de lignes, peuvent être développées sans codage sur AppSheet à l'aide de Cloud SQL.
Étapes suivantes
- Découvrez comment optimiser les charges de travail afin d'optimiser les performances globales et de réduire les coûts.
- Découvrez comment optimiser le stockage dans BigQuery.
- Pour connaître les mises à jour de BigQuery, consultez les notes de version.
- Consultez le Guide de traduction du langage SQL d'Oracle.