Ce document présente les concepts, les principes, la terminologie et l'architecture de la migration de bases de données avec un temps d'arrêt quasiment nul pour les architectes cloud qui migrent des bases de données vers Google Cloud depuis des environnements sur site ou d'autres environnements cloud.
Il s'agit de la première partie d'une série comprenant deux volets. La partie 2 traite de la configuration et de l'exécution du processus de migration, y compris des scénarios d'échec.
La migration de base de données consiste à migrer des données d'une ou plusieurs bases de données sources vers une ou plusieurs bases de données cibles à l'aide d'un service de migration de base de données. Une fois la migration terminée, l'ensemble de données dans les bases de données sources réside entièrement, mais éventuellement restructuré, dans les bases de données cibles. Les clients ayant accédé aux bases de données sources sont ensuite basculés vers les bases de données cibles, et les bases de données sources sont désactivées.
Le schéma suivant illustre ce processus de migration de base de données.
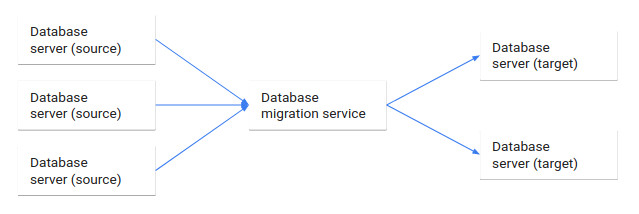
Ce document décrit la migration de base de données du point de vue de l'architecture :
- Services et technologies associés à la migration de base de données
- Différences entre la migration de base de données homogène et hétérogène
- Compromis et sélection d'une tolérance au temps d'arrêt de la migration
- Architecture de configuration compatible avec une solution de remplacement si des erreurs imprévues se produisent lors d'une migration
Ce document ne décrit pas comment configurer une technologie de migration de base de données particulière. Il présente plutôt la migration de base de données en termes fondamentaux, conceptuels et de principe.
Architecture
Le schéma suivant illustre une architecture de migration de base de données générique.
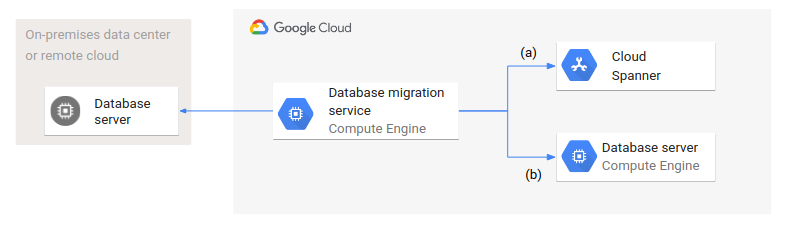
Un service de migration de base de données s'exécute dans Google Cloud et accède aux bases de données source et cible. Deux variantes sont représentées : (a) illustre la migration d'une base de données source depuis un centre de données sur site ou un cloud distant vers une base de données gérée comme Spanner ; (b) illustre une migration vers une base de données sur Compute Engine.
Même si le type (gérée ou non gérée) et la configuration des bases de données cibles sont différents, l'architecture et la configuration de la migration de base de données sont identiques dans les deux cas.
Terminologie
Les termes de migration de données les plus importants pour ces documents sont définis comme suit :
base de données source : base de données contenant des données à migrer vers une ou plusieurs bases de données cibles.
base de données cible : base de données qui reçoit les données migrées depuis une ou plusieurs bases de données sources.
migration de base de données : migration des données de bases de données sources vers des bases de données cibles dans le but de désactiver les systèmes de base de données sources une fois la migration terminée. L'ensemble de données complet, ou un sous-ensemble, est migré.
migration homogène : migration de bases de données sources vers des bases de données cibles dans laquelle les bases de données source et cible appartiennent au même système de gestion de bases de données du même fournisseur.
migration hétérogène : migration de bases de données sources vers les bases de données cibles dans laquelle les bases de données source et cible proviennent de différents systèmes de gestion de bases de données de plusieurs fournisseurs.
système de migration de bases de données : système ou service logiciel qui se connecte aux bases de données source et cible, puis effectue des migrations de données des bases de données sources vers les bases de données cibles.
processus de migration de données : processus configuré ou mis en œuvre, exécuté par le système de migration de données afin de transférer des données des bases de données sources vers des bases de données cibles, en transformant éventuellement les données pendant le transfert.
réplication de base de données : transfert continu des données des bases de données sources vers les bases de données cibles, sans avoir pour objectif de désactiver les bases de données source. La réplication de base de données (parfois appelée streaming de base de données) est un processus continu.
Classification des migrations de base de données
Il existe différents types de migrations de bases de données appartenant à différentes classes. Cette section décrit les critères qui définissent ces classes.
Réplication et migration
Dans une migration de base de données, vous déplacez des données de bases de données sources vers des bases de données cibles. Une fois les données migrées, vous supprimez les bases de données sources et redirigez l'accès du client aux bases de données cibles. Parfois, vous conservez les bases de données sources comme solution de repli si vous rencontrez des problèmes imprévus avec les bases de données cibles. Cependant, une fois que les bases de données cibles fonctionnent de manière fiable, vous finissez par supprimer les bases de données sources.
En revanche, avec la réplication de bases de données, vous transférez continuellement des données des bases de données sources vers les bases de données cibles sans les supprimer. Parfois, la réplication de base de données est appelée "streaming de base de données". Bien qu'il existe une heure de début définie, il n'y a généralement pas d'heure de fin définie. La réplication peut être arrêtée ou devenir une migration.
Ce document traite uniquement de la migration de bases de données.
Migration partielle et migration complète
La migration de base de données est considérée comme un transfert de données complet et cohérent. Vous définissez l'ensemble de données initial à transférer en tant que base de données complète ou partielle (sous-ensemble de données dans une base de données), plus chaque modification validée sur le système de base de données source par la suite.
Migration hétérogène et migration homogène
Une migration de base de données homogène est une migration entre les bases de données source et cible de la même technologie de base de données, par exemple, migrer d'une base de données MySQL vers une base de données MySQL ou d'une base de données Oracle® vers une base de données Oracle. Les migrations homogènes incluent également les migrations entre un système de base de données autohébergé, tel que PostgreSQL, vers une version gérée de celui-ci, telle que Cloud SQL pour PostgreSQL ou AlloyDB pour PostgreSQL.
Dans une migration de base de données homogène, les schémas des bases de données source et cible sont probablement identiques. Si les schémas sont différents, les données des bases de données sources doivent être transformées lors de la migration.
La migration de base de données hétérogène est une migration entre des bases de données source et cible de différentes technologies de base de données, par exemple d'une base de données Oracle vers Spanner. La migration de base de données hétérogène peut être effectuée entre les mêmes modèles de données (par exemple, de relationnel à relationnel) ou entre différents modèles de données (par exemple, de relationnel à clé-valeur).
La migration entre différentes technologies de base de données n'implique pas nécessairement différents modèles de données. Par exemple, Oracle, MySQL, PostgreSQL et Spanner sont tous compatibles avec le modèle de données relationnel. Cependant, les bases de données multi-modèles telles que Oracle, MySQL ou PostgreSQL sont compatibles avec différents modèles de données. Les données stockées sous forme de documents JSON dans une base de données multi-modèles peuvent être migrées vers MongoDB avec peu ou pas de transformation, car le modèle de données est identique dans la base de données source et cible.
Bien que la distinction entre migration homogène et migration hétérogène soit basée sur les technologies de base de données, une autre classification est basée sur les modèles de base de données concernés. Par exemple, une migration d'une base de données Oracle vers Spanner est homogène lorsque les deux utilisent le modèle de données relationnel. Une migration est hétérogène si, par exemple, les données stockées en tant qu'objets JSON dans Oracle sont transférées vers un modèle relationnel dans Spanner.
La catégorisation des migrations par modèle de données permet d'exprimer plus précisément la complexité et les efforts requis pour migrer les données que de baser la catégorisation sur le système de base de données concerné. Cependant, comme la catégorisation couramment utilisée dans le secteur est basée sur les systèmes de base de données concernés, les autres sections reposent sur cette distinction.
Temps d'arrêt de la migration : zéro, minimal et important
Une fois que vous avez migré un ensemble de données de la base de données source vers la base de données cible, vous basculez l'accès du client vers la base de données cible et supprimez la base de données source.
Basculer les clients des bases de données sources aux bases de données cibles implique plusieurs processus :
- Pour poursuivre le traitement, les clients doivent fermer les connexions existantes aux bases de données sources et créer de nouvelles connexions aux bases de données cibles. Dans l'idéal, la fermeture des connexions s'effectue normalement, ce qui signifie que vous n'annulez pas inutilement les transactions en cours.
- Après avoir fermé les connexions aux bases de données sources, vous devez migrer les modifications restantes des bases de données sources vers les bases de données cibles (procédure appelée drainage) pour vous assurer que toutes les modifications sont enregistrées.
- Vous devrez peut-être tester les bases de données cibles pour vous assurer qu'elles fonctionnent et que les clients sont opérationnels et respectent les objectifs de niveau de service (SLO) définis.
Dans une migration, il est impossible d'atteindre un temps d'arrêt réellement nul pour les clients, car il arrive que les clients ne puissent pas traiter les requêtes. Cependant, vous pouvez réduire la durée pendant laquelle les clients ne peuvent pas traiter les requêtes de plusieurs manières (temps d'arrêt quasiment nul) :
- Vous pouvez démarrer vos clients de test en mode lecture seule sur les bases de données cibles bien avant de basculer les clients. Avec cette approche, les tests sont simultanés à la migration.
- Vous pouvez configurer la quantité de données transférées (c'est-à-dire en cours de transfert entre les bases de données source et cible) afin d'être la plus petite possible à l'approche de la période de basculement. Cette étape réduit le temps de drainage, car il existe moins de différences entre les bases de données source et cible.
- Si les nouveaux clients opérant sur les bases de données cibles peuvent être démarrés simultanément avec les clients existants opérant sur les bases de données sources, vous pouvez raccourcir le basculement, car les nouveaux clients sont prêts à s'exécuter dès que toutes les données sont épuisées.
Bien qu'il soit irréaliste d'atteindre un temps d'arrêt nul lors d'un basculement, vous pouvez minimiser le temps d'arrêt en démarrant les activités en même temps que la migration de données en cours, si possible.
Dans certains scénarios de migration de base de données, un temps d'arrêt important est acceptable. En règle générale, cette tolérance est le résultat d'exigences commerciales. Dans ce cas, vous pouvez simplifier votre approche. Par exemple, avec une migration de base de données homogène, vous n'aurez peut-être pas besoin de modifier les données, ce qui fait des exportations et importations ou des sauvegardes et restaurations des approches parfaites. Avec les migrations hétérogènes, le système de migration de base de données n'a pas à gérer les mises à jour des systèmes de base de données sources pendant la migration.
Cependant, vous devez vérifier que le temps d'arrêt acceptable est suffisant pour que la migration de la base de données et les tests de suivi se produisent. Si ce temps d'arrêt ne peut pas être clairement établi ou est trop long, vous devez planifier une migration qui implique un temps d'arrêt minimal.
Cardinalité de la migration de base de données
Dans de nombreuses situations, la migration de base de données s'effectue entre une seule base de données source et une seule base de données cible. Dans ce cas, la cardinalité est de 1:1 (mappage direct). Autrement dit, une base de données source est migrée sans modification vers une base de données cible.
Cependant, un mappage direct n'est pas la seule possibilité. Les autres cardinalités sont les suivantes :
- Regroupement (n:1). Dans un regroupement, vous migrez des données de plusieurs bases de données sources vers un plus petit nombre de bases de données cibles (voire même vers une seule cible). Vous pouvez utiliser cette approche pour simplifier la gestion des bases de données ou pour utiliser une base de données cible pouvant évoluer.
- Distribution (1:n). Dans une distribution, vous migrez des données d'une base de données source vers plusieurs bases de données cibles. Par exemple, vous pouvez utiliser cette approche lorsque vous devez migrer une grande base de données centralisée contenant des données régionales vers plusieurs bases de données cibles régionales.
- Redistribution (n:m). Dans une redistribution, vous migrez des données de plusieurs bases de données sources vers plusieurs bases de données cibles. Vous pouvez utiliser cette approche lorsque vous avez des bases de données sources partitionnées avec des partitions de tailles très différentes. La redistribution répartit équitablement les données partitionnées sur plusieurs bases de données cibles qui représentent les partitions.
La migration de base de données permet de repenser et de mettre en œuvre l'architecture de votre base de données en plus de la simple migration de données.
Cohérence de la migration
On s'attend à ce qu'une migration de base de données soit cohérente. Dans le contexte de la migration, cohérent signifie ce qui suit :
- Terminé. Toutes les données spécifiées pour la migration sont réellement migrées. Les données spécifiées peuvent être toutes les données d'une base de données source ou d'un sous-ensemble de données.
- Sans doublons. Chaque élément de données n'est migré qu'une seule fois. Aucun doublon de données n'est introduit dans la base de données cible.
- Ordonné. Les modifications de données de la base de données source sont appliquées à la base de données cible dans le même ordre que les modifications apportées à la base de données source. Cet aspect est essentiel pour garantir la cohérence des données.
Une autre façon de décrire la cohérence de la migration est qu'une fois la migration terminée, l'état des données entre les bases de données source et cible est équivalent. Par exemple, dans une migration homogène impliquant le mappage direct d'une base de données relationnelle, les mêmes tables et lignes doivent exister dans les bases de données source et cible.
Cette autre méthode de description de la cohérence de la migration est importante, car toutes les migrations de données ne sont pas basées sur l'application séquentielle des transactions de la base de données source à la base de données cible. Par exemple, vous pouvez sauvegarder la base de données source et utiliser la sauvegarde pour restaurer le contenu de la base de données source dans la base de données cible (lorsque des temps d'arrêt importants sont possibles).
Migration active-passive et migration active-active
Il est important de savoir si les bases de données source et cible sont toutes deux ouvertes à la modification du traitement des requêtes. Dans une migration de base de données active-passive, les bases de données sources peuvent être modifiées pendant la migration, tandis que les bases de données cibles n'autorisent qu'un accès en lecture seule.
Une migration active-active permet aux clients d'écrire dans les bases de données source et cible pendant la migration. Dans ce type de migration, des conflits peuvent se produire. Par exemple, en cas de conflit découlant d'une modification sémantique d'un même élément de données, dans la base de données source et dans la base de données cible, vous devrez peut-être exécuter des règles de résolution des conflits pour y remédier.
Dans une migration active-active, vous devez être en mesure de résoudre tous les conflits de données à l'aide de règles de résolution des conflits. Dans le cas contraire, vous risquez de rencontrer des incohérences au niveau des données.
Architecture de migration de base de données
Une architecture de migration de base de données décrit les différents composants nécessaires à l'exécution d'une migration de base de données. Cette section présente une architecture de déploiement générique et traite le système de migration de base de données comme un composant distinct. Elle aborde également les fonctionnalités d'un système de gestion de base de données qui prennent en charge la migration des données, ainsi que les propriétés non fonctionnelles importantes pour de nombreux cas d'utilisation.
Architecture de déploiement
Une migration de base de données peut avoir lieu entre les bases de données source et cible situées dans n'importe quel environnement, comme par exemple sur site ou dans différents clouds. Chaque base de données source et cible peut se trouver dans un environnement différent. Il n'est pas nécessaire que les bases de données soient toutes regroupées dans le même environnement.
Le schéma suivant montre un exemple d'architecture de déploiement impliquant plusieurs environnements.
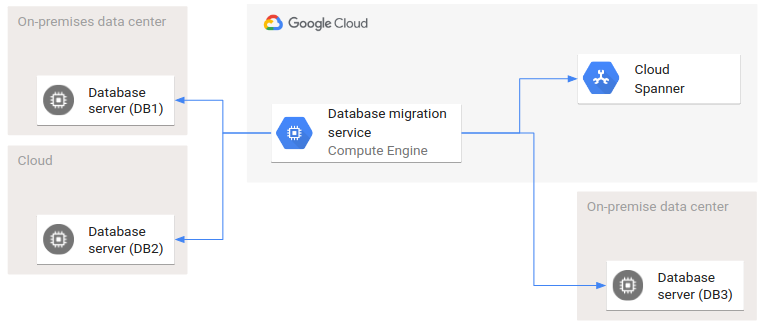
DB1 et DB2 sont deux bases de données sources, et DB3 et Spanner sont les bases de données cibles. Deux clouds et deux centres de données sur site sont impliqués dans cette migration de base de données. Les flèches représentent les relations d'appel : le service de migration de base de données appelle les interfaces de toutes les bases de données source et cible.
Un cas particulier non abordé ici est la migration de données d'une base de données vers la même base de données. Ce cas particulier utilise le système de migration de base de données pour la transformation de données uniquement, et non pour la migration de données entre différents systèmes dans différents environnements.
Il existe trois approches à la migration de base de données, qui sont abordées dans cette section :
- Utiliser un système de migration de base de données
- Utiliser la fonctionnalité de réplication du système de gestion de base de données
- Utiliser la fonctionnalité de migration de base de données personnalisée
Système de migration de base de données
Le système de migration de base de données est au cœur de la migration de base de données. Le système exécute l'extraction des données à partir des bases de données sources, les transporte vers les bases de données cibles et, éventuellement, les modifie pendant le transit. Cette section traite des fonctionnalités de base des systèmes de migration de base de données en général. Database Migration Service, Striim, Debezium, tcVision et Cloud Data Fusion constituent des exemples de systèmes de migration de base de données.
Processus de migration des données
Le principal élément technique d'un système de migration de base de données est le processus de migration de données. Le processus de migration des données est spécifié par un développeur et définit les bases de données sources à partir desquelles les données sont extraites, les bases de données cibles dans lesquelles les données sont transférées et toute logique de modification des données appliquée lors de la migration.
Vous pouvez spécifier un ou plusieurs processus de migration de données et les exécuter de manière séquentielle ou simultanée en fonction des besoins de la migration. Par exemple, si vous migrez des bases de données indépendantes, les processus de migration de données correspondants peuvent s'exécuter en parallèle.
Extraction et insertion de données
Vous pouvez détecter les modifications (insertions, mises à jour, suppressions) dans un système de base de données de deux manières : grâce à la collecte de données modifiées (CDC) compatible avec la base de données sur la base d'un journal des transactions ou grâce à la requête différentielle des données à l'aide de l'interface de requête d'un système de gestion de base de données.
CDC basée sur un journal des transactions
La CDC compatible avec la base de données est basée sur des fonctionnalités de gestion de base de données distinctes de l'interface de requête. Une approche spécifique est basée sur les journaux de transaction (par exemple, le journal binaire dans MySQL). Un journal des transactions contient les modifications apportées aux données dans le bon ordre. Le journal des transactions est lu en continu, ce qui permet d'observer chaque modification. Pour la migration de base de données, cette journalisation est extrêmement utile car la CDC garantit que chaque modification est visible avant d'être migrée vers la base de données cible sans perte et dans le bon ordre.
La CDC est l'approche privilégiée pour la capture des modifications dans un système de gestion de base de données. La CDC est intégrée à la base de données et a le moins d'impact sur la charge du système.
Requête différentielle
Si aucune fonctionnalité de système de gestion de base de données ne permet d'observer toutes les modifications dans le bon ordre, vous pouvez utiliser la requête différentielle. Dans cette approche, chaque élément de données d'une base de données reçoit un attribut supplémentaire contenant un horodatage ou un numéro de séquence. Chaque fois que l'élément de données est modifié, l'horodatage de modification est ajouté ou le numéro de séquence est augmenté. Un algorithme de sondage lit tous les éléments de données depuis sa dernière exécution ou depuis le dernier numéro de séquence utilisé. Une fois que l'algorithme de sondage a déterminé les modifications, il enregistre l'heure actuelle ou le numéro de séquence dans son état interne, puis les transmet à la base de données cible.
Bien que cette approche fonctionne sans problème pour les insertions et les mises à jour, vous devez concevoir soigneusement les suppressions, car elles suppriment un élément de données de la base de données. Une fois les données supprimées, le système d'interrogation ne peut pas détecter la suppression. Vous mettez en œuvre une suppression en utilisant un champ d'état supplémentaire (une option de suppression logique) qui indique que les données sont supprimées. Les éléments de données supprimés peuvent également être collectés dans une ou plusieurs tables, et le système d'interrogation y accède pour déterminer si la suppression a eu lieu.
Pour connaître les variantes des requêtes différentielles, consultez la section Capture de données modifiées.
La requête différentielle est l'approche la moins recommandée, car elle implique des modifications de schéma et de fonctionnalité. L'interrogation de la base de données ajoute également une charge de requête qui n'est pas liée à l'exécution de la logique client.
Adaptateur et agent
Le système de migration de base de données nécessite un accès à la source et aux systèmes de base de données. Les adaptateurs sont l'abstraction qui encapsule la fonctionnalité d'accès. Dans sa forme la plus simple, un adaptateur peut être un pilote JDBC destiné à insérer des données dans une base de données cible compatible avec JDBC. Dans un cas plus complexe, un adaptateur s'exécute dans l'environnement de la cible (parfois appelé agent) et accède à une interface de base de données intégrée telle que des fichiers journaux. Dans un cas encore plus complexe, un adaptateur ou un agent s'interface avec un autre système logiciel qui, à son tour, accède à la base de données. Par exemple, un agent accède à Oracle GoldenGate, qui à son tour accède à une base de données Oracle.
En fonction de la conception du système de base de données, l'adaptateur ou l'agent qui accède à une base de données source met en œuvre l'interface CDC ou l'interface de requête différentielle. Dans les deux cas, l'adaptateur ou l'agent fournit des modifications au système de migration de base de données, et le système de migration de base de données ne sait pas si les modifications ont été capturées par CDC ou par des requêtes différentielles.
Modification des données
Dans certains cas d'utilisation, les données sont migrées des bases de données sources vers des bases de données cibles non modifiées. Ces migrations directes sont généralement homogènes.
Cependant, de nombreux cas d'utilisation nécessitent la modification des données au cours du processus de migration. En règle générale, une modification est nécessaire en cas de différences de schéma, de valeurs de données ou d'opportunités de nettoyage les données pendant la transition.
Les sections suivantes décrivent plusieurs types de modifications pouvant être nécessaires dans une migration de données : transformation de données, enrichissement ou corrélation de données, et réduction ou filtrage de données.
Transformation des données
La transformation de données transforme tout ou partie des valeurs de données de la base de données source. Voici quelques exemples :
- Transformation du type de données. Parfois, les types de données entre les bases de données source et cible ne sont pas équivalents. Dans ce cas, la transformation de type de données caste la valeur source en valeur cible en fonction des règles de transformation de type. Par exemple, un type d'horodatage provenant de la source peut être transformé en chaîne dans la cible.
- Transformation de la structure des données. La transformation de la structure des données modifie la structure dans un même modèle de base de données ou entre différents modèles de base de données. Par exemple, dans un système relationnel, une table source peut être divisée en deux tables cibles ou plusieurs tables sources peuvent être dénormalisées en une table cible à l'aide d'une jointure. Une relation 1:n dans la base de données source peut être transformée en relation parent/enfant dans Spanner. Les documents d'un système de base de données de documents source peuvent être décomposés en un ensemble de lignes relationnelles dans un système cible.
- Transformation de la valeur des données. La transformation de la valeur des données est distincte de la transformation du type de données. La transformation de la valeur des données modifie la valeur sans modifier le type de données. Par exemple, un fuseau horaire local est converti en temps universel coordonné (UTC). Ou un code postal court (cinq chiffres) représenté par une chaîne est converti en code postal long (cinq chiffres suivis d'un tiret suivi de 4 chiffres, également appelé ZIP + 4).
Enrichissement et corrélation des données
La transformation des données est appliquée aux données existantes sans référence à d'autres données de référence associées. Avec l'enrichissement des données, des données supplémentaires sont interrogées pour enrichir les données sources avant qu'elles ne soient stockées dans la base de données cible.
- Corrélation des données. Il est possible de mettre en corrélation les données sources. Par exemple, vous pouvez combiner les données de deux tables issues de deux bases de données sources. Dans une base de données cible, vous pouvez par exemple associer un client à toutes les commandes ouvertes, traitées et annulées, les données du client et les données de commande provenant de deux bases de données sources différentes.
- Enrichissement des données. L'enrichissement des données ajoute des données de référence. Par exemple, vous pouvez enrichir les enregistrements qui ne contiennent qu'un code postal en ajoutant le nom de la ville correspondant au code postal. Une table de référence contenant des codes postaux et des noms de villes correspondants est un ensemble de données statique accessible pour ce cas d'utilisation. Les données de référence peuvent également être dynamiques. Par exemple, vous pouvez utiliser une liste de tous les clients connus comme données de référence.
Réduction et filtrage des données
Un autre type de transformation de données consiste à réduire ou à filtrer les données sources avant de les migrer vers une base de données cible.
- Réduction des données. La réduction des données supprime les attributs d'un élément de données. Par exemple, si un code postal est présent dans un élément de données, le nom de la ville correspondante peut ne pas être obligatoire et être supprimé, car il peut être recalculé ou parce qu'il n'est plus nécessaire. Parfois, ces informations sont conservées pour des raisons historiques afin d'enregistrer le nom de la ville tel que saisi par l'utilisateur, même si le nom de la ville change dans le temps.
- Filtrage des données. Le filtrage des données supprime complètement un élément de données. Par exemple, toutes les commandes annulées peuvent être supprimées et ne pas être transférées vers la base de données cible.
Combinaison et recombinaison de données
Si les données sont migrées depuis différentes bases de données sources vers différentes bases de données cibles, il peut être nécessaire de combiner les données différemment entre les bases de données source et cible.
Supposons que les clients et les commandes soient stockés dans deux bases de données sources différentes. Une base de données source contient toutes les commandes et une deuxième base de données contient tous les clients. Après la migration, les clients et leurs commandes sont stockés dans une relation 1:n au sein d'un schéma de base de données cible unique, mais dans de multiples bases de données cible plutôt qu'une seule, chacune de ces bases de données contenant une partition des données. Chaque base de données cible représente une région et contient tous les clients ainsi que leurs commandes situés dans cette région.
Adressage de la base de données cible
Sauf s'il existe une seule base de données cible, chaque élément de données migré doit être envoyé à la base de données cible appropriée. Voici quelques méthodes pour adresser la base de données cible :
- Adressage basé sur un schéma. L'adressage basé sur un schéma détermine la base de données cible en fonction du schéma. Par exemple, tous les éléments de données d'une collection de clients ou toutes les lignes d'une table client sont transférés vers la même base de données cible stockant les informations client, même si ces informations ont été distribuées dans plusieurs bases de données sources.
- Routage basé sur le contenu. Le routage basé sur le contenu (à l'aide d'un routeur basé sur le contenu, par exemple) détermine la base de données cible en fonction des valeurs des données. Par exemple, tous les clients situés en Amérique latine sont transférés vers une base de données cible spécifique qui représente cette région.
Vous pouvez utiliser les deux types d'adressage simultanément dans une migration de base de données. Quel que soit le type d'adressage utilisé, la base de données cible doit disposer du schéma approprié pour que les éléments de données soient stockés.
Persistance des données en transit
Les systèmes de migration de base de données ou les environnements sur lesquels ils s'exécutent peuvent subir un dysfonctionnement pendant une migration, et les données en transit peuvent être perdues. En cas de dysfonctionnement, vous devez redémarrer le système de migration de base de données et vous assurer que les données stockées dans la base de données source sont migrées de manière cohérente et complète vers les bases de données cibles.
Dans le cadre de la récupération, le système de migration de base de données doit identifier le dernier élément de données migré pour déterminer par où commencer l'extraction à partir des bases de données sources. Pour pouvoir reprendre au moment du dysfonctionnement, le système doit conserver un état interne de progression de la migration.
Vous pouvez conserver l'état de plusieurs manières :
- Vous pouvez stocker tous les éléments de données extraits dans le système de migration de base de données avant toute modification de base de données, puis supprimer l'élément de données une fois sa version modifiée stockée dans la base de données cible. Cette approche garantit que le système de migration de base de données peut déterminer exactement ce qui est extrait et stocké.
- Vous pouvez gérer une liste de références aux éléments de données en transit. Une possibilité consiste à stocker les clés primaires ou d'autres identifiants uniques de chaque élément de données avec un attribut d'état. Après un dysfonctionnement, cet état est la base de la récupération cohérente du système.
- Vous pouvez interroger les bases de données source et cible après un dysfonctionnement pour déterminer la différence entre les systèmes de base de données source et cible. L'élément de données suivant à extraire est déterminé en fonction de la différence.
D'autres approches de maintenance de l'état peuvent dépendre des bases de données sources spécifiques. Par exemple, un système de migration de base de données peut suivre les entrées du journal des transactions extraites de la base de données source et celles qui sont insérées dans la base de données cible. En cas de dysfonctionnement, la migration peut être relancée à partir de la dernière entrée réussie.
La persistance des données en transit est également importante pour d'autres raisons que les erreurs ou les échecs. Par exemple, il peut s'avérer impossible d'interroger les données de la base de données source pour déterminer leur état. Si, par exemple, la base de données source contenait une file d'attente, les messages de cette file d'attente auraient pu être supprimés à un moment donné.
Encore un autre cas d'utilisation de la persistance des données en transit est le traitement à large fenêtre des données. Lors de la modification des données, les éléments de données peuvent être transformés indépendamment les uns des autres. Cependant, la modification des données dépend parfois de plusieurs éléments de données (par exemple, numérotation des éléments de données traités par jour, à partir de zéro chaque jour).
Un dernier cas d'utilisation de la persistance des données en transit consiste à assurer la reproductibilité des données lors de la modification des données lorsque le système de base de données ne peut plus accéder aux bases de données sources. Par exemple, vous devrez peut-être réexécuter les modifications de données avec des règles de modification différentes, puis vérifier et comparer les résultats avec les modifications de données initiales. Cette approche peut être nécessaire si vous devez suivre les incohérences dans la base de données cible en raison d'une modification incorrecte des données.
Vérification de l'exhaustivité et de la cohérence
Vous devez vérifier que la migration de votre base de données est terminée et cohérente. Cette vérification garantit que chaque élément de données n'est migré qu'une seule fois, que les ensembles de données des bases de données source et cible sont identiques et que la migration est terminée.
Selon les règles de modification des données, il est possible qu'un élément de données soit extrait, mais pas inséré dans une base de données cible. Pour cette raison, la comparaison directe des bases de données source et cible n'est pas une méthode fiable pour vérifier l'exhaustivité et la cohérence. Toutefois, si le système de migration de base de données effectue le suivi des éléments filtrés, vous pouvez comparer les bases de données source et cible avec les éléments filtrés.
Fonctionnalité de réplication du système de gestion de bases de données
Dans une migration homogène, la base de données cible est une copie de la base de données source. Plus précisément, les schémas des bases de données source et cible sont identiques, les valeurs des données sont identiques et chaque base de données source bénéficie d'un mappage direct (1:1) avec une base de données cible.
Dans ce cas, vous pouvez utiliser la fonctionnalité de réplication intégrée, fournie avec la plupart des systèmes de gestion de bases de données, pour répliquer une base de données vers une autre.
Il existe deux types de réplication de données : la réplication logique et la réplication physique.
Réplication logique : dans le cas de la réplication logique, les modifications apportées aux objets de base de données sont transférées en fonction de leurs identifiants de réplication (généralement des clés primaires). La réplication logique présente plusieurs avantages : elle est flexible, précise et vous pouvez la personnaliser. Dans certains cas, la réplication logique vous permet de répliquer les modifications entre différentes versions de moteur de base de données. De nombreux moteurs de base de données sont compatibles avec les filtres de réplication logique, qui vous permettent de définir l'ensemble de données à répliquer. Les principaux inconvénients sont que la réplication logique peut avoir un impact sur les performances, et que la latence associée à cette méthode de réplication est généralement supérieure à celle de la réplication physique.
Réplication physique : à l'inverse, la réplication physique opère au niveau des blocs de disque, et offre de meilleures performances avec une latence de réplication plus faible. La réplication physique peut se révéler plus simple et plus efficace avec de grands ensembles de données, en particulier dans le cas de structures de données non relationnelles. Toutefois, elle n'est pas personnalisable et dépend fortement de la version du moteur de base de données.
Exemples : réplication MySQL, réplication PostgreSQL (voir aussi pdlogical) ou réplication Microsoft SQL Server.
Cependant, si une modification des données est requise ou si vous avez une cardinalité autre qu'un mappage direct, les fonctionnalités d'un système de migration de base de données sont nécessaires pour traiter pareil cas d'utilisation.
Fonctionnalité de migration de base de données personnalisée
Voici quelques-unes des raisons justifiant la création d'une fonctionnalité de migration de base de données, plutôt que d'utiliser un système de migration de base de données ou un système de gestion de bases de données :
- Vous avez besoin d'un contrôle total sur chaque détail.
- Vous souhaitez réutiliser les fonctionnalités de migration de bases de données.
- Vous souhaitez réduire vos coûts ou simplifier votre empreinte technologique.
Les composants fondamentaux de la fonctionnalité de migration sont les suivants :
- Exportation et importation : si le temps d'arrêt n'est pas pris en compte, vous pouvez utiliser l'exportation et l'importation de bases de données pour migrer des données via des migrations de base de données homogènes. L'exportation et l'importation nécessitent toutefois de suspendre la base de données source pour empêcher les mises à jour avant d'exporter les données. Sinon, les modifications risquent de ne pas être capturées lors de l'exportation et la base de données cible ne sera pas une copie exacte de la base de données source.
- Sauvegarde et restauration : comme pour l'exportation et l'importation, la sauvegarde et la restauration entraînent des temps d'arrêt, car vous devez suspendre la base de données source afin que la sauvegarde contienne toutes les données et les dernières modifications. Le temps d'arrêt se poursuit jusqu'à la fin de la restauration sur la base de données cible.
- Requête différentielle : en cas de modification potentielle du schéma de base de données, vous pouvez étendre le schéma afin que les modifications de base de données puissent être interrogées dans l'interface de requête. Un attribut d'horodatage supplémentaire est ajouté, indiquant l'heure de la dernière modification. Une option de suppression supplémentaire peut être ajoutée, indiquant si l'élément de données est supprimé ou non (suppression logique). Avec ces deux modifications, un service d'interrogation exécutant un intervalle régulier peut interroger toutes les modifications depuis sa dernière exécution. Les modifications sont appliquées à la base de données cible. D'autres approches sont décrites dans la section Capture de données modifiées.
Voici quelques-unes des options possibles pour créer une migration de base de données personnalisée. Bien qu'une solution personnalisée offre le plus de flexibilité et de contrôle sur la mise en œuvre, elle nécessite une maintenance constante pour résoudre les bugs, les limites d'évolutivité et d'autres problèmes pouvant survenir lors d'une migration de base de données.
Informations complémentaires relatives à la migration de base de données
Les sections suivantes traitent brièvement des aspects non fonctionnels importants dans le contexte de la migration de bases de données. Ces aspects incluent la gestion des erreurs, l'évolutivité, la haute disponibilité et la reprise après sinistre.
Traiter les erreurs
Les échecs pendant la migration de bases de données ne doivent pas entraîner de perte de données ou le traitement des modifications de bases de données dans un ordre inexact. L'intégrité des données doit être préservée quelle que soit la cause de l'échec (un bug dans le système, une interruption du réseau, un plantage de VM ou une défaillance de zone).
Une perte de données se produit lorsqu'un système de migration récupère les données des bases de données sources et ne les stocke pas dans les bases de données cibles à cause d'une erreur. Lorsque des données sont perdues, les bases de données cibles ne correspondent pas aux bases de données sources et sont donc incohérentes et incomplètes. La fonctionnalité de vérification de l'exhaustivité et de la cohérence signale cet état (Vérification de l'exhaustivité et de la cohérence).
Évolutivité
Dans une migration de base de données, le délai de migration est une métrique importante. Dans une migration sans temps d'arrêt (au sens de temps d'arrêt minimal), la migration des données se produit pendant que les bases de données sources continuent de changer. Pour migrer dans un délai raisonnable, le taux de transfert de données doit être beaucoup plus rapide que celui des mises à jour des systèmes de base de données source, en particulier lorsque le système de base de données source est volumineux. Plus le taux de transfert est élevé, plus la migration de la base de données est rapide.
Lorsque les systèmes de base de données source sont suspendus et ne sont pas modifiés, la migration peut être plus rapide, car il n'y a aucune modification à intégrer. Dans une base de données homogène, le délai de migration peut être relativement réduit car vous pouvez utiliser les fonctionnalités de sauvegarde et restauration ou d'exportation et importation, et car le transfert des fichiers évolue.
Haute disponibilité et reprise après sinistre
En général, les bases de données source et cible sont configurées pour une haute disponibilité. Une base de données principale possède une instance dupliquée avec accès en lecture qui est promue en tant que base de données principale en cas d'échec.
Lorsqu'une zone échoue, les bases de données source ou cible basculent vers une zone différente pour être disponibles en continu. Si une défaillance de zone se produit lors d'une migration de base de données, le système de migration lui-même est affecté, car plusieurs des bases de données source ou cible auxquelles il accède deviennent inaccessibles. Le système de migration doit se reconnecter aux bases de données principales nouvellement promues en cours d'exécution après un échec. Une fois le système de migration de base de données reconnecté, il doit récupérer la migration elle-même pour garantir l'exhaustivité et la cohérence des données dans les bases de données cibles. Le système de migration doit déterminer le dernier transfert cohérent pour déterminer où reprendre.
Si le système de migration de base de données subit un dysfonctionnement (par exemple, la zone dans laquelle il s'exécute devient inaccessible), il doit être récupéré. Le redémarrage à froid est une des approches de récupération. Dans cette approche, le système de migration de base de données est installé dans une zone opérationnelle et redémarré. Le plus gros problème à résoudre est que le système de migration doit pouvoir déterminer le dernier transfert de données cohérent avant l'échec et continuer à partir de ce point pour garantir l'exhaustivité et la cohérence des données dans les bases de données cibles.
Si le système de migration de base de données est activé pour la haute disponibilité, il peut basculer et poursuivre le traitement. Si un temps d'arrêt limité du système de migration de base de données est important, vous devez sélectionner une base de données et mettre en œuvre la haute disponibilité.
En termes de récupération de la migration de base de données, la reprise après sinistre est très semblable à la haute disponibilité. Au lieu de se reconnecter aux bases de données principales nouvellement promues dans une zone différente, le système de migration doit se reconnecter aux bases de données d'une autre région (région de basculement). Il en va de même pour le système de migration de base de données lui-même. Si la région dans laquelle le système de migration de base de données s'exécute devient inaccessible, le système de migration de base de données doit basculer vers une autre région et reprendre à partir du dernier transfert de données cohérent.
Pièges
Plusieurs pièges peuvent entraîner des incohérences de données dans les bases de données cibles. Voici quelques exemples courants à éviter :
- Non-respect de l'ordre. Si l'évolutivité du système de migration est obtenue par scaling horizontal, plusieurs processus de transfert de données s'exécutent simultanément (en parallèle). Les modifications apportées à un système de base de données source sont classées en fonction des transactions validées. Si les modifications sont extraites du journal des transactions, l'ordre doit être conservé tout au long de la migration. Le transfert de données en parallèle peut modifier l'ordre à cause de la vitesse variable entre les processus sous-jacents. Il est nécessaire de s'assurer que les données sont insérées dans les bases de données cibles dans le même ordre que celui reçu des bases de données sources.
- Non-respect des règles de cohérence. Avec les requêtes différentielles, les bases de données sources possèdent des attributs de données supplémentaires contenant, par exemple, des horodatages de commit. Les bases de données cibles n'auront pas d'horodatage de commit, car ceux-ci ne sont mis en place que pour permettre la gestion des modifications dans les bases de données sources. Il est important de s'assurer que les insertions dans les bases de données cibles doivent être cohérentes avec l'horodatage, ce qui signifie que toutes les modifications ayant le même horodatage doivent se trouver dans la même transaction d'insertion, de mise à jour ou de conversion supérieure. Sinon, la base de données cible peut présenter un état incohérent (temporairement) si certaines modifications sont insérées et que d'autres avec le même horodatage ne le sont pas. Cet état incohérent temporaire n'a pas d'importance si les bases de données cibles ne sont pas accessibles pour traitement. Toutefois, si elles sont utilisées à des fins de test, la cohérence est primordiale. Un autre aspect à considérer est la création des valeurs d'horodatage dans la base de données source, ainsi que leur lien avec le délai de commit de la transaction dans laquelle elles sont définies. En raison de dépendances de commit de transaction, une transaction dotée d'un horodatage antérieur peut devenir visible après une transaction avec un horodatage ultérieur. Si la requête différentielle est exécutée entre les deux transactions, elle ne verra pas la transaction avec l'horodatage antérieur, ce qui entraînera une incohérence dans la base de données.
- Données manquantes ou en double. Lorsqu'un basculement se produit, une récupération prudente est requise si certaines données ne sont pas répliquées entre l'instance dupliquée principale et celle de basculement. Par exemple, une base de données source bascule et toutes les données ne sont pas répliquées sur l'instance dupliquée de basculement. Dans le même temps, les données sont déjà transférées vers la base de données cible avant l'échec. Après le basculement, la base de données principale nouvellement promue est en retard en termes de modification des données de la base de données cible (on parle dans cette situation de flashback). Un système de migration doit reconnaître cette situation et la récupérer de telle sorte que la base de données cible et la base de données source reviennent à un état cohérent.
- Transactions locales. Pour que les bases de données source et cible reçoivent les mêmes modifications, une approche courante consiste à laisser les clients écrire dans les bases de données source et cible au lieu d'utiliser un système de migration de données. Cette approche présente plusieurs pièges. Le premier problème est que deux écritures de base de données sont deux transactions distinctes. Vous risquez de rencontrer une erreur après la première et avant la deuxième. Ce scénario entraîne des données incohérentes que vous devez récupérer. En outre, il existe en général plusieurs clients qui ne sont pas coordonnés. Les clients ne connaissent pas l'ordre de commit des transactions de la base de données source et ne peuvent donc pas écrire dans les bases de données cibles mettant en œuvre cet ordre de transaction. Les clients peuvent modifier l'ordre, ce qui peut entraîner une incohérence dans les données. À moins que tous les accès ne passent par des clients coordonnés et que tous les clients garantissent l'ordre de transaction cible, cette approche peut entraîner un état incohérent avec la base de données cible.
En général, il existe d'autres pièges à surveiller. Le meilleur moyen de détecter les problèmes susceptibles d'entraîner des incohérences dans les données consiste à effectuer une analyse complète des dysfonctionnements en évaluant tous les scénarios possibles. Si la simultanéité est mise en œuvre dans le système de migration de base de données, tous les ordres d'exécution de processus de migration de données doivent être examinés pour garantir la cohérence des données. Si la haute disponibilité ou la reprise après sinistre (ou les deux) sont mises en œuvre, toutes les combinaisons de dysfonctionnement possibles doivent être examinées.
Étape suivante
- Consultez la section Migrations de bases de données : concepts et principes (partie 2).
- Pour en savoir plus sur la migration de base de données, consultez les documents suivants :
- Consultez la page Migration de bases de données pour obtenir d'autres guides sur la migration de bases de données.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.