本教程介绍如何从 Amazon DynamoDB 迁移到 Spanner。主要受众是想要从 NoSQL 系统迁移到 Spanner 的应用所有者。Spanner 是一个支持事务的完全关系型 SQL 数据库系统,能够容错且具备很高的扩缩能力。如果您对 Amazon DynamoDB 表的用法统一(就类型和布局而言),则映射到 Spanner 非常简单。如果 Amazon DynamoDB 表包含任意数据类型和值,则转移到其他 NoSQL 服务(例如 Datastore 或 Firestore)可能更简单。
本教程假定您熟悉数据库架构、数据类型、NoSQL 的基础知识以及关系型数据库系统。本教程依赖于运行预定义任务来执行示例迁移。完成本教程之后,您可以修改提供的代码和步骤以便匹配您的环境。
以下架构图概括了本教程中用于迁移数据的组件:

目标
- 将数据从 Amazon DynamoDB 迁移到 Spanner。
- 创建 Spanner 数据库和迁移表。
- 将 NoSQL 架构映射到关系型架构。
- 创建和导出使用 Amazon DynamoDB 的数据集示例。
- 在 Amazon S3 和 Cloud Storage 之间转移数据。
- 使用 Dataflow 将数据加载到 Spanner 中。
费用
本教程使用 Google Cloud 的以下收费组件:
Spanner 费用基于实例中的计算容量以及每月结算周期内存储的数据量。在学习本教程期间,您将使用这些资源的最低配置,并在结束时清理。对于实际场景,请估算您的吞吐量和存储要求,然后使用 Spanner 实例文档确定所需的计算容量。
除了 Google Cloud 资源之外,本教程还使用以下 Amazon Web Services (AWS) 资源:
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
只有在迁移过程中才需要这些服务。在本教程结束时,请按照说明清理所有资源以防止产生不必要的费用。您可以使用 AWS 价格计算器估算这些费用。
如需根据您的预计使用情况来估算费用,请使用价格计算器。
准备工作
- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Spanner, Pub/Sub, Compute Engine, and Dataflow API。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Spanner, Pub/Sub, Compute Engine, and Dataflow API。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备环境
在本教程中,您将在 Cloud Shell 中运行命令。Cloud Shell 让您能够访问 Google Cloud 中的命令行,并且包含进行 Google Cloud 开发所需的 Google Cloud CLI 及其他工具。初始化 Cloud Shell 可能需要几分钟。
-
在 Google Cloud 控制台中,激活 Cloud Shell。
Cloud Shell 会话随即会在 Google Cloud 控制台的底部启动,并显示命令行提示符。Cloud Shell 是一个已安装 Google Cloud CLI 且已为当前项目设置值的 Shell 环境。该会话可能需要几秒钟时间来完成初始化。
- 设置默认的 Compute Engine 地区,例如
us-central1-b。<pre class="devsite-click-to-copy"> gcloud config set compute/zone us-central1-b </pre></li> - 克隆包含示例代码的 GitHub 代码库。
<pre class="devsite-click-to-copy"> git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git </pre></li> - 转到克隆的目录。
<pre class="devsite-click-to-copy"> cd dynamodb-spanner-migration </pre></li> - 创建 Python 虚拟环境。
<pre class="devsite-click-to-copy"> pip3 install virtualenv virtualenv env </pre></li> - 激活虚拟环境。
<pre class="devsite-click-to-copy"> source env/bin/activate </pre></li> - 安装必需的 Python 模块。
<pre class="devsite-click-to-copy"> pip3 install -r requirements.txt </pre></li>
配置 AWS 访问权限
在本教程中,您将创建和删除 Amazon DynamoDB 表、Amazon S3 存储桶和其他资源。要访问这些资源,首先需要创建所需的 AWS Identity and Access Management (IAM) 权限。您可以使用测试或沙箱 AWS 账号来避免影响同一账号中的生产资源。
为 AWS Lambda 创建 AWS IAM 角色
在本部分中,您将创建 AWS IAM 角色,AWS Lambda 将在本教程的后续步骤中使用该角色。
- 在 AWS 控制台中,转到 IAM 部分,点击 Roles,然后选择 Create role。
- 在 Trusted entity type 下,确保已选择 AWS service。
- 在 Use case 下,选择 Lambda,然后点击 Next。
- 在 Permission policies 过滤条件框中,输入
AWSLambdaDynamoDBExecutionRole,然后按Return进行搜索。 - 选中 AWSLambdaDynamoDBExecutionRole 复选框,然后点击 Next。
- 在 Role name 框中,输入
dynamodb-spanner-lambda-role,然后点击 Create role。
创建 AWS IAM 用户
按照以下步骤创建 AWS IAM 用户,该用户能够以编程方式访问在整个教程中所使用的 AWS 资源。
- 如果您仍在 AWS 控制台的 IAM 部分,请点击 Users,然后选择 Add User。
- 在 User name 框中,输入
dynamodb-spanner-migration。 在 Access type 下,选中 Access key - Programmatic access 左侧的复选框。
点击 Next: Permissions。
点击 Attach existing policies directly,然后使用 Search 框进行过滤,选中以下三个政策旁边的复选框:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
点击 Next: Tags 和 Next: Review,然后点击 Create user。
点击 Show 以查看凭据。屏幕上将显示新创建的用户的访问密钥 ID 和秘密访问密钥。请先不要关闭此窗口,下一部分中会用到这些凭据。请妥善地保存这些凭据,因为可以使用这些凭据来更改您的账号并影响您的环境。在本教程结束时,您可以删除 IAM 用户。
配置 AWS 命令行界面
在 Cloud Shell 中,配置 AWS 命令行界面 (CLI)。
aws configure
此时会显示以下输出:
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- 输入您创建的 AWS IAM 账号的
ACCESS KEY ID和SECRET ACCESS KEY。 - 在 Default region name 字段中,输入
us-west-2。将其他字段保留为默认值。
- 输入您创建的 AWS IAM 账号的
关闭 AWS IAM 控制台窗口。
了解数据模型
下一部分概述了 Amazon DynamoDB 和 Spanner 的数据类型、键和索引之间的异同。
数据类型
Spanner 使用 GoogleSQL 数据类型。下表描述了 Amazon DynamoDB 数据类型与 Spanner 数据类型之间的对应关系。
| Amazon DynamoDB | Spanner |
|---|---|
| 数字 | 根据精度或预期用途,可能会映射为 INT64、FLOAT64、TIMESTAMP 或 DATE。 |
| 字符串 | 字符串 |
| 布尔值 | BOOL |
| 空值 | 没有明确的类型。列可以包含空值。 |
| 二进制 | 字节 |
| 集合 | 数组 |
| 映射和清单 | 如果结构一致并且可以使用表 DDL 语法来描述,则为结构体类型。 |
主键
Amazon DynamoDB 主键可实现唯一性,它可以是哈希键,也可以组合使用哈希键加范围键。本教程首先展示主键为哈希键的 Amazon DynamoDB 表的迁移。此哈希键会成为 Spanner 表的主键。然后,关于交错表的部分中对 Amazon DynamoDB 表组合使用哈希键和范围键作为主键的这种情况进行了建模。
二级索引
Amazon DynamoDB 和 Spanner 都支持在非主键特性上创建索引。请记下 Amazon DynamoDB 表中的任何二级索引,以便在 Spanner 表上创建它们,本教程的后续部分介绍了这部分内容。
示例表
为了便于学习本教程,您将以下示例表从 Amazon DynamoDB 迁移到 Spanner:
| Amazon DynamoDB | Spanner | |
|---|---|---|
| 表名称 |
Migration
|
Migration
|
| 主键 |
"Username" : String
|
"Username" : STRING(1024)
|
| 键类型 | 哈希 | 不适用 |
| 其他字段 |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
准备 Amazon DynamoDB 表
在下面的部分中,您将创建 Amazon DynamoDB 源表并为其填充数据。
在 Cloud Shell 中,创建一个使用示例表特性的 Amazon DynamoDB 表。
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75验证该表的状态是否为
ACTIVE。aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'使用示例数据填充该表。
python3 make-fake-data.py --table Migration --items 25000
创建 Spanner 数据库
您将创建一个可能具有最小计算容量(100 个处理单元)的 Spanner 实例。此计算容量足以满足本教程的范围。对于生产部署,请参阅 Spanner 实例的文档以确定适当的计算容量来满足数据库性能要求。
在此示例中,您将在创建数据库的同时创建表架构。您也可以在创建数据库之后执行架构更新,这是一种常见的做法。
在设置默认 Compute Engine 地区的区域中创建一个 Spanner 实例,例如
us-central1。gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"在 Spanner 实例中创建数据库以及示例表。
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"
准备迁移
后续部分将向您介绍如何导出 Amazon DynamoDB 源表,以及设置 Pub/Sub 复制功能来捕获导出时对数据库所做的任何更改。
将更改流式传输到 Pub/Sub
请使用 AWS Lambda 函数将数据库更改流式传输到 Pub/Sub。
在 Cloud Shell 中,在源表上启用 Amazon DynamoDB 流。
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES设置一个 Pub/Sub 主题以接收更改。
gcloud pubsub topics create spanner-migration
将出现以下输出:
Created topic [projects/your-project/topics/spanner-migration].
创建 IAM 服务账号以将表更新推送到 Pub/Sub 主题。
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"将出现以下输出:
Created service account [spanner-migration].
创建 IAM 政策绑定,以便服务账号有权发布到 Pub/Sub。将
GOOGLE_CLOUD_PROJECT替换为您的 Google Cloud 项目的名称。gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com此时会显示以下输出:
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
为服务账号创建凭据。
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com此时会显示以下输出:
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
准备并打包 AWS Lambda 函数以将 Amazon DynamoDB 表的更改推送到 Pub/Sub 主题。
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub
cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd -
zip -g pubsub-lambda.zip ddbpubsub.py创建一个变量以捕获您之前创建的 Lambda 执行角色的 Amazon 资源名称 (ARN)。
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)使用
pubsub-lambda.zip包创建 AWS Lambda 函数。aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"此时会显示以下输出:
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128,
... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }创建变量以捕获表的 Amazon DynamoDB 流的 ARN。
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)将 Lambda 函数附加到 Amazon DynamoDB 表。
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZON如需在测试期间优化响应性能,请将
--batch-size 1添加到上一个命令的最后,这样,每当创建、更新或删除条目时,都会触发该函数。您将会看到类似于以下内容的输出:
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...
将 Amazon DynamoDB 表导出到 Amazon S3
在 Cloud Shell 中,为您在后续部分中使用的存储桶名称创建变量。
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-export创建 Amazon S3 存储桶以接收 DynamoDB 导出。
aws s3 mb s3://${BUCKET}在 AWS Management Console 中,前往 DynamoDB,然后点击 Tables。
点击
Migration表。在 Exports and stream 标签页下,点击 Export to S3。
如果出现提示,请启用
point-in-time-recovery(PITR)。点击 Browse S3,选择您之前创建的 S3 存储桶。
点击导出。
点击刷新图标以更新导出作业的状态。作业需要几分钟才能完成导出。
该过程完成后,请查看输出存储桶。
aws s3 ls --recursive s3://${BUCKET}此步骤大约需要 5 分钟。完成后,您将看到如下所示的输出:
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
执行迁移
由于已采用 Pub/Sub 传送,您可以推送在导出之后进行的任何表更改。
将导出的表复制到 Cloud Storage
在 Cloud Shell 中,创建一个 Cloud Storage 存储桶,以接收从 Amazon S3 导出的文件。
gsutil mb gs://${BUCKET}将 Amazon S3 中的文件同步到 Cloud Storage 中。对于大多数复制操作,
rsync命令有效。如果导出的文件很大(数 GB 或更大),请使用 Cloud Storage Transfer Service 以在后台管理传输。gsutil rsync -d -r s3://${BUCKET} gs://${BUCKET}
批量导入数据
如需将导出文件中的数据写入 Spanner 表,请以示例 Apache Beam 代码运行一个 Dataflow 作业。
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"如需查看导入作业的进度,请在 Google Cloud 控制台中前往 Dataflow。
当作业正在运行时,您可以查看执行图以检查日志。点击状态显示为正在运行的作业。
点击每个阶段以查看已处理的元素数量。当所有阶段都显示成功时,表示导入完成。在 Amazon DynamoDB 表中创建的相同数量的元素在每个阶段都显示为已处理。
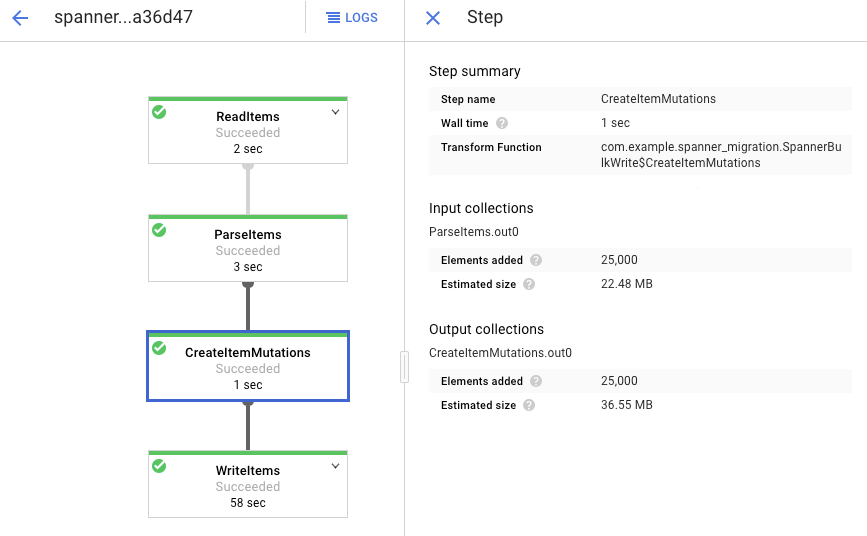
验证目标 Spanner 表中的记录数与 Amazon DynamoDB 表中的条目数是否匹配。
aws dynamodb describe-table --table-name Migration --query Table.ItemCount
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"将出现以下输出:
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
对每个表中的随机条目进行采样以确保数据一致。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"此时会显示以下输出:
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
使用上一步中从 Spanner 查询返回的同一
Username来查询 Amazon DynamoDB 表,例如aallen2538。该值特定于数据库中的示例数据。aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'其他字段的值应与 Spanner 输出中的值匹配。此时会显示以下输出:
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }
复制新更改
批量导入作业完成后,您可以设置流式作业以将源表中的现行更新写入 Spanner。您可以订阅 Pub/Sub 中的事件并将其写入 Spanner
您创建的 Lambda 函数配置为捕获对源 Amazon DynamoDB 表进行的更改并将这些更改发布到 Pub/Sub。
订阅 AWS Lambda 将向其发送事件的 Pub/Sub 主题。
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migration此时会显示以下输出:
Created subscription [projects/your-project/subscriptions/spanner-migration].
如需以流式方式将传送到 Pub/Sub 的更改写入 Spanner 表,请在 Cloud Shell 中运行 Dataflow 作业。
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"与批量加载步骤类似,如需查看作业进度,请在 Google Cloud 控制台中前往 Dataflow。
点击状态为正在运行的作业。
处理图显示与之前类似的输出,但每个已处理的条目都会在状态窗口中计数。系统延迟时间是一个粗略估计值,大致说明更改体现在 Spanner 表中之前预计会延迟多长时间。
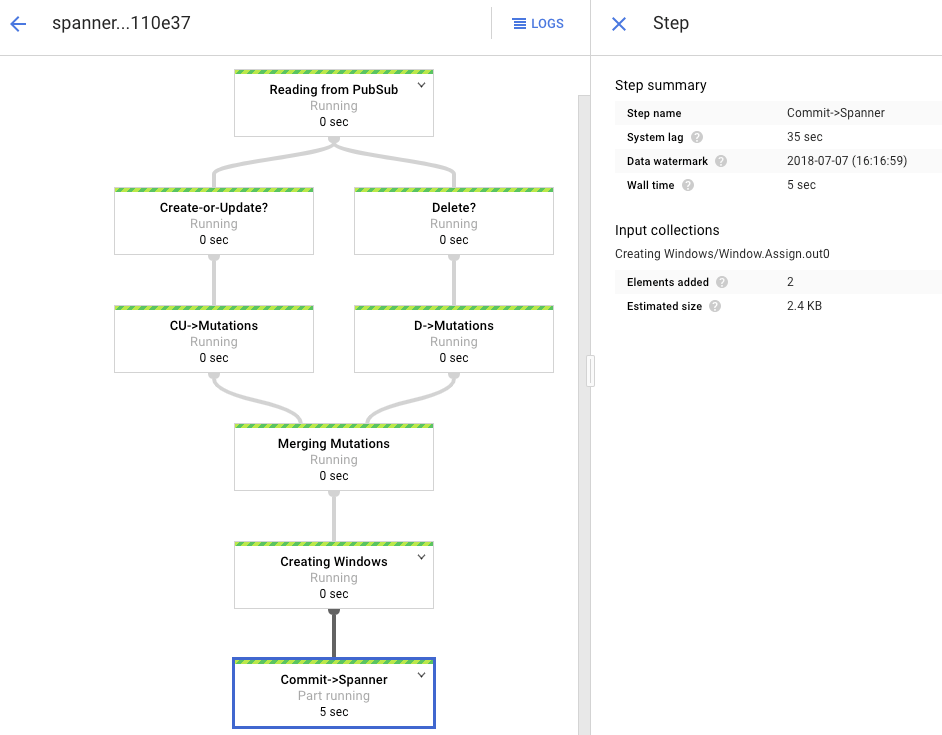
您在批量加载阶段运行的 Dataflow 作业是一组有限的输入,也称为“有界”数据集。此 Dataflow 作业使用 Pub/Sub 作为流式源,并且被视为“无界”。如需详细了解这两种类型的源,请查看 Apache Beam 编程指南中关于 PCollections 的部分。此步骤中的 Dataflow 作业应保持活跃状态,因此在完成时不会终止。流式 Dataflow 作业仍处于正在运行状态,而不是成功状态。
验证复制
请对源表进行一些更改,以验证更改是否会复制到 Spanner 表。
在 Spanner 中查询一个不存在的行。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"该操作不会返回任何结果。
使用您在 Spanner 查询中所使用的键在 Amazon DynamoDB 中创建一条记录。如果命令成功运行,则不会有输出。
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'再次运行同一查询以验证该行现在出现在 Spanner 中。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"输出会显示插入的行:
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
更改原始条目中的某些属性并更新 Amazon DynamoDB 表。
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEW您将会看到类似于以下内容的输出:
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }验证更改已传播到 Spanner 表。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"输出如下所示:
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
从 Amazon DynamoDB 源表中删除测试条目。
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'验证对应的行已从 Spanner 表中删除。此更改传播后,以下命令将返回零行:
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"
使用交错表
Spanner 支持交错表的概念。这是一种设计模型,其中顶级条目有多个与它相关的嵌套条目,例如客户及其订单,或玩家及其游戏得分。如果您的 Amazon DynamoDB 源表使用的主键是由哈希键和范围键组成,则可以建模一个交错表架构,如下图所示。利用此结构,您在联接父表中的字段时能够高效地查询交错表。

应用二级索引
最佳做法是在加载数据之后再对 Spanner 表应用二级索引。由于复制操作正在进行,您可以设置二级索引来加快查询速度。与 Spanner 表一样,Spanner 的二级索引也完全一致。它们并不具备最终一致性,这在许多 NoSQL 数据库中很常见。此功能有助于简化您的应用设计。
运行不使用任何索引的查询。在给定的列值的情况下,查找的是前 N 个出现的条目。这是 Amazon DynamoDB 中用于提高数据库效率的常用查询。
转到 Spanner。
点击 Spanner Studio。
在查询字段中,输入以下查询,然后点击运行查询。
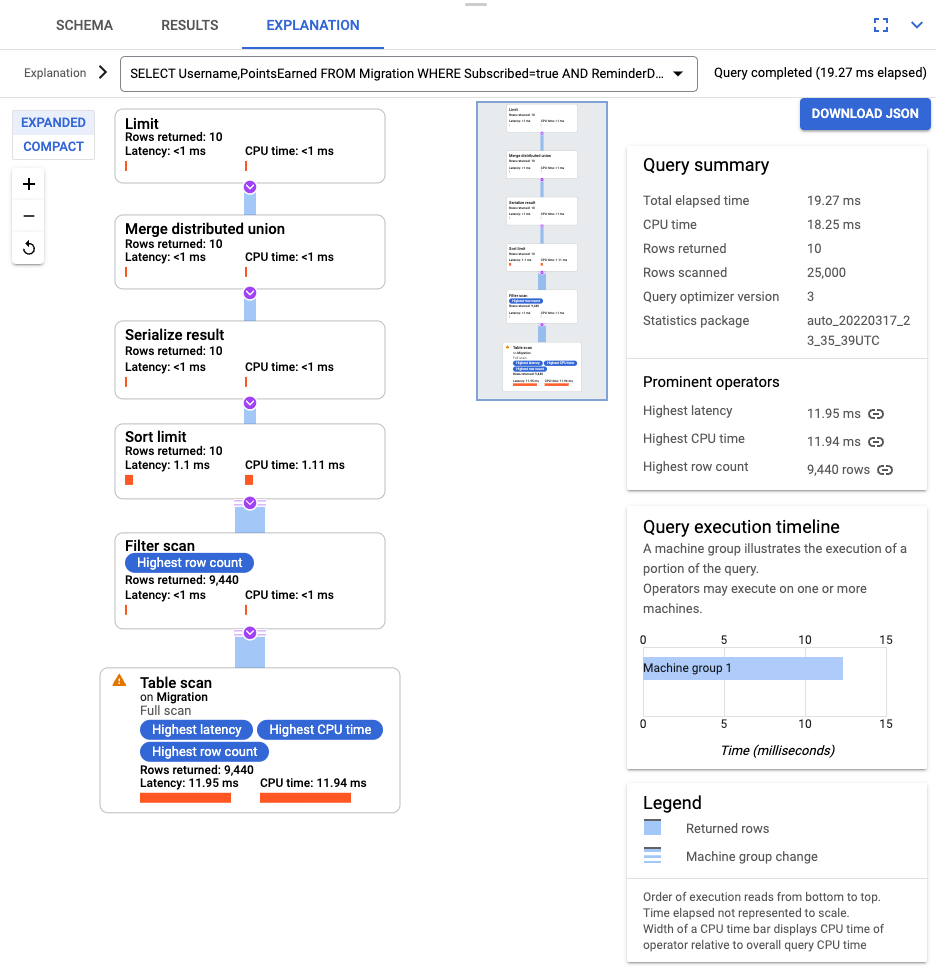
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
查询运行后,点击说明并记下扫描的行数与返回的行数。如果没有索引,Spanner 将为了返回一小部分与查询匹配的数据而扫描整个表。
如果这代表常见查询,请在 Subscribed 和 ReminderDate 列上创建复合索引。在 Spanner 控制台上,在左侧导航窗格中选择索引,然后点击创建索引。
在文本框中,输入索引定义。
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
要在后台开始构建数据库,请点击创建。
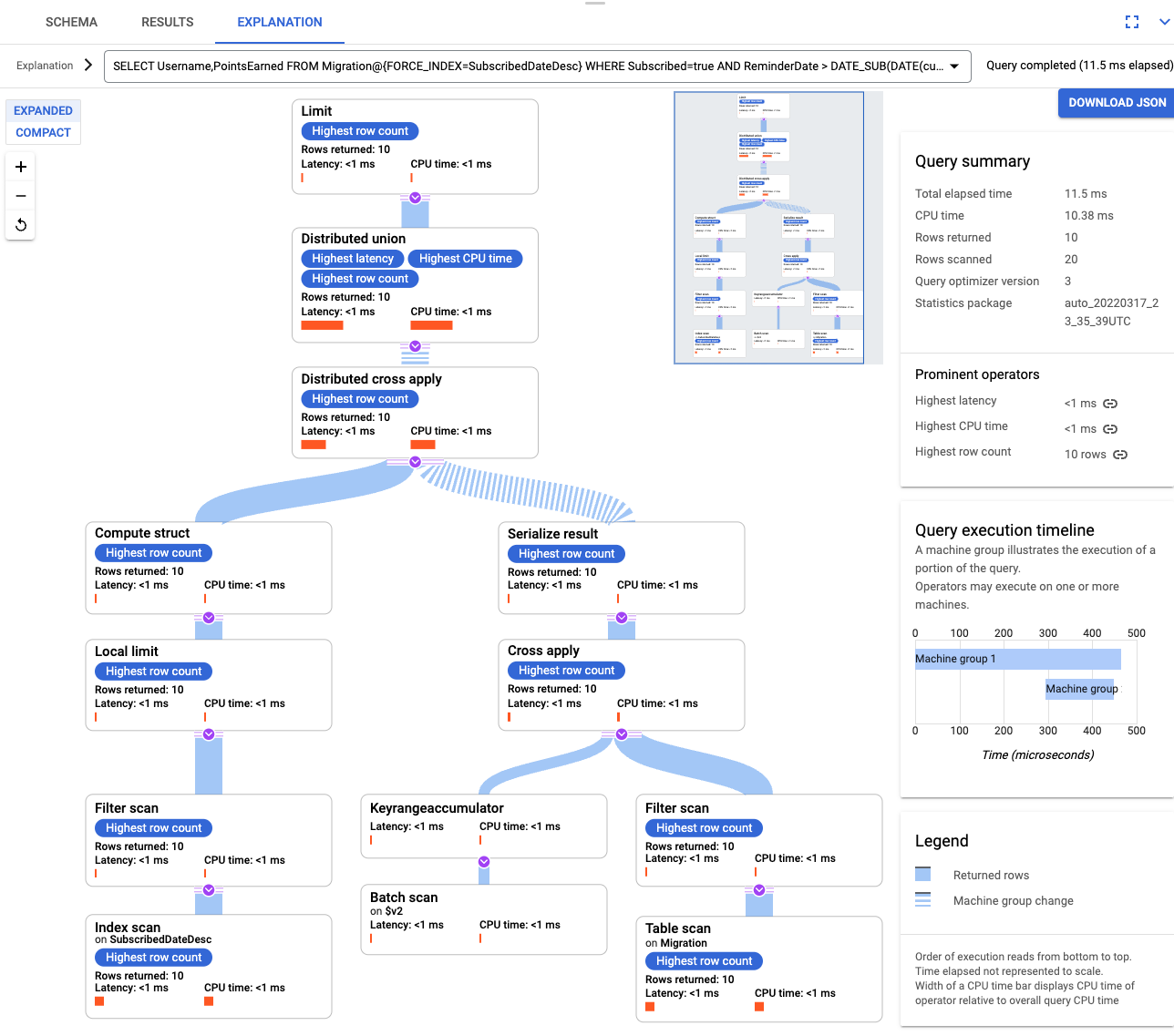
创建索引后,再次运行查询并添加索引。
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10再次检查查询说明。请注意,扫描的行数已减少。每一步返回的行数都与查询返回的数量匹配。
交错索引
您可以在 Spanner 中设置交错索引。上一部分所述的二级索引位于数据库层次结构的根部,它们使用索引的方式与传统数据库相同。交错索引位于其交错行的上下文内。如需详细了解在何处应用交错索引,请参阅索引选项。
针对您的数据模型进行调整
为了使本教程的迁移部分适应您自己的情况,请修改 Apache Beam 源文件。进行实际迁移期间切勿更改源架构,否则可能会丢失数据。
如需解析传入的 JSON 并构建变更,请使用 GSON。调整 JSON 定义以匹配您的数据。
调整对应的 JSON 映射。
在前面的步骤中,您修改了 Apache Beam 源代码以进行批量导入。请以类似的方式修改流水线流式传输部分的源代码。最后,调整 Spanner 目标数据库的表创建脚本、架构和索引。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除项目
- 在 Google Cloud 控制台中,进入管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
删除 AWS 资源
如果您的 AWS 账号不仅仅用于本教程,那么在删除以下资源时,请务必谨慎:
- 名为 Migration 的 DynamoDB 表。
- 在迁移步骤中创建的 Amazon S3 存储桶和 Lambda 函数。
- 最后是您在学习本教程的过程中创建的 AWS IAM 用户。
后续步骤
- 了解如何优化 Spanner 架构。
- 了解如何在更复杂的情况下使用 Dataflow。