Questo tutorial mostra come iniziare a utilizzare la data science su larga scala con R su Google Cloud. È progettato per coloro che hanno una certa esperienza con R e con i blocchi note Jupyter e sono esperti di SQL.
Questo tutorial è incentrato sull'esecuzione di analisi dei dati esplorative utilizzando blocchi note gestiti dall'utente e BigQuery di Vertex AI Workbench. Puoi trovare il codice per questo tutorial in un blocco note Jupyter su GitHub.
Panoramica
R è uno dei linguaggi di programmazione più comunemente utilizzati per la modellazione statistica. Dispone di una vasta community attiva di data scientist e professionisti del machine learning (ML). Con oltre 15.000 pacchetti nel repository open source della Rete R Archive completa (CRAN), R dispone di strumenti per tutte le applicazioni di analisi dei dati, ML e visualizzazione. R ha registrato una crescita costante negli ultimi vent'anni a causa della sua espressività nella sintassi e della completezza dei dati e delle librerie ML.
In qualità di data scientist, potresti voler sapere come usare le tue competenze utilizzando R e come sfruttare anche i vantaggi dei servizi cloud scalabili e completamente gestiti per il ML.
In questo tutorial utilizzerai i blocchi note gestiti dall'utente come ambiente di data science per eseguire l'analisi dei dati esplorativi (EDA). Utilizzi R sui dati estratti nell'ambito di questo tutorial da BigQuery, il data warehouse su cloud serverless, a scalabilità elevata ed economico di Google. Dopo aver analizzato ed elaborato i dati, i dati trasformati vengono archiviati in Cloud Storage per ulteriori attività di ML. Questo flusso è illustrato nel seguente diagramma:
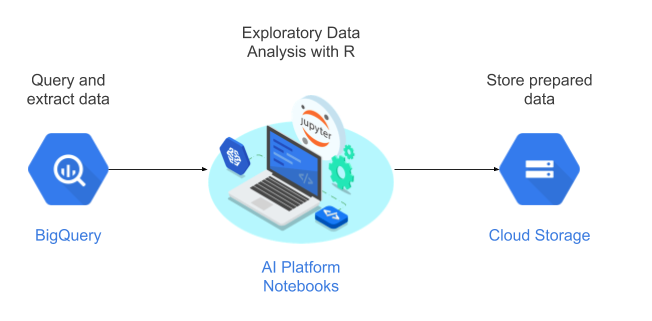
Dati del tutorial
Il set di dati utilizzato in questo tutorial è il set di dati sulla Natività di BigQuery. Questo set di dati pubblico include informazioni su oltre 137 milioni di nascite registrate negli Stati Uniti dal 1969 al 2008.
Questo tutorial è incentrato su EDA e sulla visualizzazione utilizzando R e BigQuery. Il tutorial ti consente di raggiungere un obiettivo di machine learning di prevedere il peso di un bambino in base a una serie di fattori sulla gravidanza e sulla madre del bambino, anche se questo compito non è trattato in questo tutorial.
Blocchi note gestiti dall'utente
I blocchi note gestiti dall'utente di Vertex AI Workbench sono un servizio che offre un ambiente JupyterLab integrato, con le seguenti funzionalità:
- Implementazione con un solo clic. Puoi utilizzare un solo clic per avviare un'istanza JupyterLab preconfigurata con i più recenti framework di machine learning e data science.
- Scalabilità on demand. Puoi iniziare con una configurazione della macchina di piccole dimensioni (ad esempio, 4 vCPU e 15 GB di RAM, come in questo tutorial), e quando i tuoi dati diventano troppo grandi per una macchina, puoi fare lo scale up aggiungendo CPU, RAM e GPU.
- Integrazione con Google Cloud. Le istanze di blocco note gestite dall'utente di Vertex AI Workbench sono integrate con i servizi Google Cloud come BigQuery. Questa integrazione semplifica il passaggio dall'importazione dati alla pre-elaborazione e all'esplorazione.
- Prezzi a consumo. Non sono previsti costi minimi o impegni iniziali. Consulta i prezzi dei blocchi note gestiti dall'utente di Vertex AI Workbench. Paghi anche per le risorse Google Cloud che utilizzi con l'istanza di blocchi note gestiti dall'utente.
I blocchi note gestiti dall'utente vengono eseguiti sulle immagini di deep learning. Queste immagini sono ottimizzate per supportare framework ML come PyTorch e TensorFlow. Questo tutorial supporta la creazione di un'istanza di blocchi note gestiti dall'utente con R 3.6.
Utilizzo di BigQuery con R
BigQuery non richiede la gestione dell'infrastruttura, quindi puoi concentrarti sulla scoperta di insight significativi. BigQuery ti consente di utilizzare un ambiente SQL familiare per lavorare con i tuoi dati, senza bisogno di un amministratore di database. Puoi utilizzare BigQuery per analizzare grandi quantità di dati su larga scala e per preparare i set di dati per il machine learning utilizzando le avanzate funzionalità analitiche SQL di BigQuery.
Per eseguire query sui dati BigQuery utilizzando R, puoi utilizzare bigrquery, una libreria R open source. Il pacchetto BigQuery offre i seguenti livelli di astrazione in aggiunta a BigQuery:
L'API di basso livello fornisce wrapper sottili sull'API REST BigQuery sottostante.
L'interfaccia DBI esegue il wrapping dell'API di basso livello e rende l'utilizzo di BigQuery simile all'utilizzo di qualsiasi altro sistema di database. Questo è il livello più pratico se vuoi eseguire query SQL in BigQuery o caricare meno di 100 MB.
L'interfaccia dbplyr consente di trattare le tabelle BigQuery come frame di dati in memoria. Questo è il livello più pratico se non vuoi scrivere SQL, ma vuoi invece dbplyr scriverlo per te.
Questo tutorial utilizza l'API di basso livello di bigrquery, senza richiedere DBI o dbplyr.
Obiettivi
- Crea un'istanza di blocchi note gestiti dall'utente con supporto R.
- Esegui query e analizza i dati da BigQuery utilizzando la libreria bigrquery R.
- Prepara e archivia i dati per il machine learning in Cloud Storage.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
- BigQuery
- I blocchi note gestiti dall'utente di Vertex AI Workbench. Ti vengono inoltre addebitati costi per le risorse utilizzate all'interno dei blocchi note, tra cui risorse di calcolo, BigQuery e richieste API.
- Cloud Storage
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il Calcolatore prezzi.
Prima di iniziare
- Accedi al tuo account Google Cloud. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Attiva l'API Compute Engine.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Attiva l'API Compute Engine.
Creazione di un'istanza di blocchi note gestiti dall'utente con R
Il primo passaggio consiste nel creare un'istanza di blocchi note gestiti dall'utente che puoi utilizzare per questo tutorial.
Nella console Google Cloud, vai alla pagina Blocchi note.
Nella scheda Blocchi note gestiti dall'utente, fai clic su Nuovo blocco note.
Seleziona R 3.6.
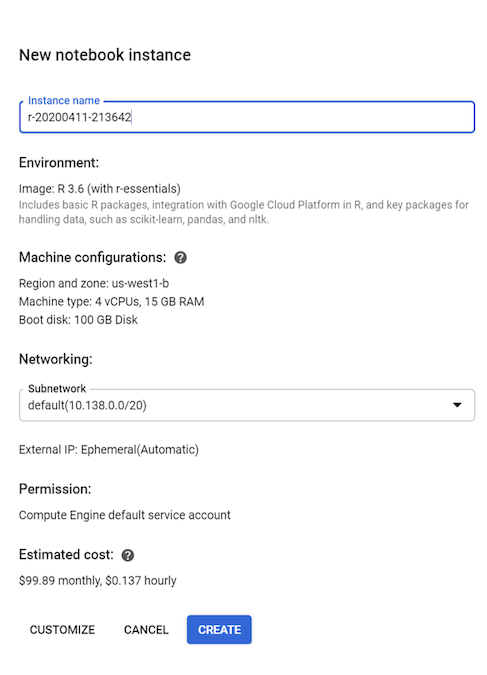
Per questo tutorial, lascia tutti i valori predefiniti e fai clic su Crea:
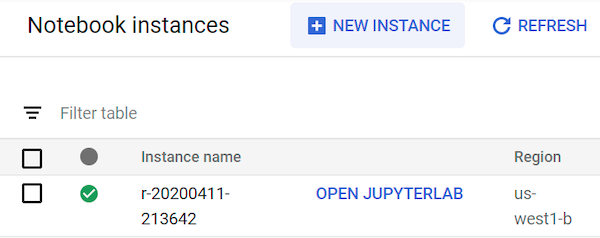
L'avvio dell'istanza di blocchi note gestiti dall'utente può richiedere fino a 90 secondi. Quando è pronto, lo vedi elencato nel riquadro Istanze blocco note con un link Apri JupyterLab accanto al nome dell'istanza:
Apertura di JupyterLab in corso...
Per seguire il tutorial nel blocco note, devi aprire l'ambiente JupyterLab, clonare il repository GitHub ml-on-gcp e quindi aprire il blocco note.
Nell'elenco delle istanze, fai clic su Apri Jupyterlab. In questo modo viene aperto l'ambiente JupyterLab nel browser.
Per avviare una scheda terminale, fai clic su Terminale in Avvio app.
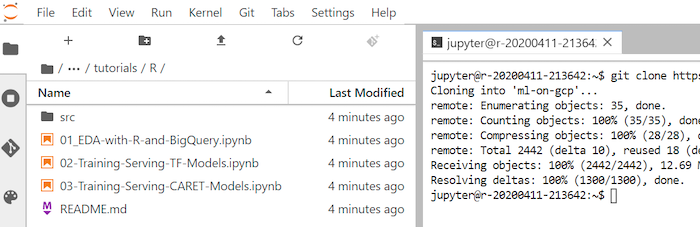
Nel clonazione, clona il repository GitHub
ml-on-gcp:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.gitAl termine del comando, viene visualizzata la cartella
ml-on-gcpnel browser del file.Nel browser di file, apri
ml-on-gcp, poitutorialse infineR.Il risultato della clonazione ha il seguente aspetto:
Apertura del blocco note e configurazione di R
Le librerie R necessarie per questo tutorial, incluso BigrQuery, sono installate nei blocchi note R per impostazione predefinita. Nell'ambito di questa procedura, li importi per renderli disponibili al blocco note.
Nel browser dei file, apri il blocco note
01-EDA-with-R-and-BigQuery.ipynb.Questo blocco note illustra il tutorial di analisi dei dati esplorativa con R e BigQuery. Da questo punto del tutorial, lavori nel blocco note ed esegui il codice che vedi nel blocco note Jupyter.
Importa le librerie R necessarie per questo tutorial:
library(bigrquery) # used for querying BigQuery library(ggplot2) # used for visualization library(dplyr) # used for data wranglingAutentica
bigrqueryutilizzando l'autenticazione out-of-band:bq_auth(use_oob = True)Imposta una variabile sul nome del progetto che utilizzi per questo tutorial:
# Set the project ID PROJECT_ID <- "gcp-data-science-demo"Imposta una variabile sul nome del bucket Cloud Storage:
BUCKET_NAME <- "bucket-name"
Sostituisci bucket-name con un nome univoco a livello globale.
Potrai utilizzare il bucket in un secondo momento per archiviare i dati di output.
Esecuzione di query sui dati da BigQuery
In questa sezione del tutorial, leggi i risultati dell'esecuzione di un'istruzione SQL BigQuery in R e dai un'occhiata preliminare ai dati.
Crea un'istruzione SQL BigQuery che estragga alcuni possibili predittori e la variabile di previsione target per un campione di nascite dal 2000:
sql_query <- " SELECT ROUND(weight_pounds, 2) AS weight_pounds, is_male, mother_age, plurality, gestation_weeks, cigarette_use, alcohol_use, CAST(ABS(FARM_FINGERPRINT(CONCAT( CAST(YEAR AS STRING), CAST(month AS STRING), CAST(weight_pounds AS STRING))) ) AS STRING) AS key FROM publicdata.samples.natality WHERE year > 2000 AND weight_pounds > 0 AND mother_age > 0 AND plurality > 0 AND gestation_weeks > 0 AND month > 0 LIMIT %s "La colonna
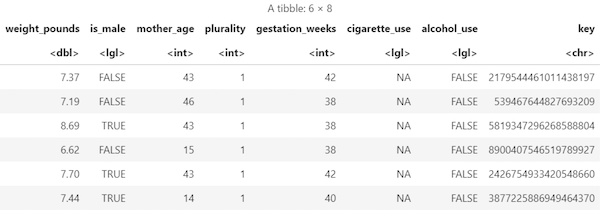
keyè un identificatore di riga generato in base ai valori concatenati delle colonneyear,montheweight_pounds.Esegui la query e recupera i dati come oggetto
data framein memoria:sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) natality_data <- bq_table_download( bq_project_query( PROJECT_ID, query=sql_query ) )Visualizza i risultati recuperati:
head(natality_data)L'output è simile al seguente:
Visualizza il numero di righe e tipi di dati di ogni colonna:
str(natality_data)L'output è simile al seguente:
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 10000 obs. of 8 variables: $ weight_pounds : num 7.75 7.4 6.88 9.38 6.98 7.87 6.69 8.05 5.69 9.22 ... $ is_male : logi FALSE TRUE TRUE TRUE FALSE TRUE ... $ mother_age : int 47 44 42 43 42 43 42 43 45 44 ... $ plurality : int 1 1 1 1 1 1 1 1 1 1 ... $ gestation_weeks: int 41 39 38 39 38 40 35 40 38 39 ... $ cigarette_use : logi NA NA NA NA NA NA ... $ alcohol_use : logi FALSE FALSE FALSE FALSE FALSE FALSE ... $ key : chr "3579741977144949713" "8004866792019451772" "7407363968024554640" "3354974946785669169" ...
Visualizza un riepilogo dei dati recuperati:
summary(natality_data)L'output è simile al seguente:
weight_pounds is_male mother_age plurality Min. : 0.620 Mode :logical Min. :13.0 Min. :1.000 1st Qu.: 6.620 FALSE:4825 1st Qu.:22.0 1st Qu.:1.000 Median : 7.370 TRUE :5175 Median :27.0 Median :1.000 Mean : 7.274 Mean :27.3 Mean :1.038 3rd Qu.: 8.110 3rd Qu.:32.0 3rd Qu.:1.000 Max. :11.440 Max. :51.0 Max. :4.000 gestation_weeks cigarette_use alcohol_use key Min. :18.00 Mode :logical Mode :logical Length:10000 1st Qu.:38.00 FALSE:580 FALSE:8284 Class :character Median :39.00 TRUE :83 TRUE :144 Mode :character Mean :38.68 NA's :9337 NA's :1572 3rd Qu.:40.00 Max. :47.00
Visualizzazione dei dati tramite ggplot2
In questa sezione userai la libreria ggplot2 in R per studiare alcune delle variabili del set di dati relativi alla natalità.
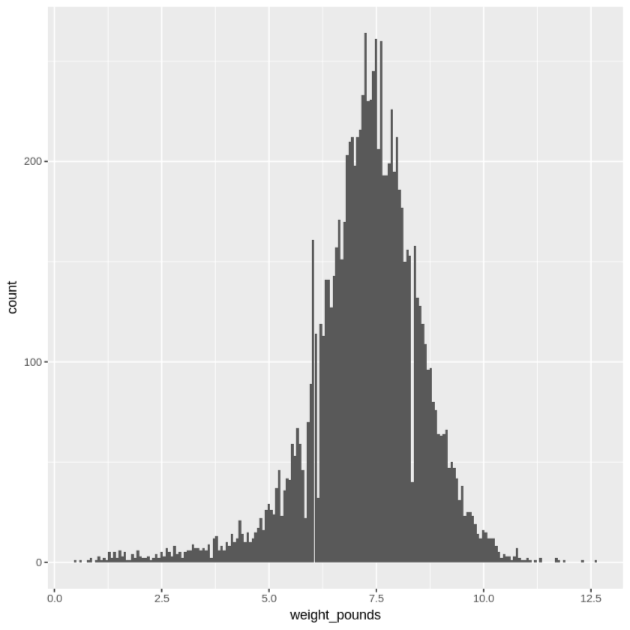
Visualizza la distribuzione dei valori
weight_poundsutilizzando un istogramma:ggplot( data = natality_data, aes(x = weight_pounds) ) + geom_histogram(bins = 200)Il grafico risultante è simile al seguente:
Visualizza la relazione tra
gestation_weekseweight_poundsutilizzando un grafico a dispersione:ggplot( data = natality_data, aes(x = gestation_weeks, y = weight_pounds) ) + geom_point() + geom_smooth(method = "lm")Il grafico risultante è simile al seguente:
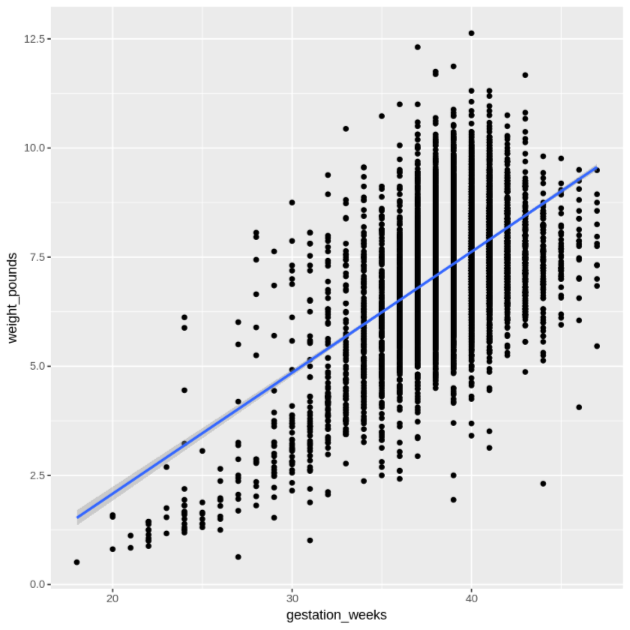
Elaborazione dei dati in BigQuery da R
Quando lavori con set di dati di grandi dimensioni, ti consigliamo di eseguire il maggior numero di analisi possibile (aggregazione, filtraggio, unione, calcolo di colonne e così via) in BigQuery e poi di recuperare i risultati. Eseguire queste attività in R è meno efficiente. L'utilizzo di BigQuery per l'analisi sfrutta la scalabilità e le prestazioni di BigQuery e garantisce che i risultati restituiti possano essere memorizzati nella memoria di R.
Crea una funzione che trovi il numero di record e la ponderazione media di ogni valore della colonna scelta:
get_distinct_values <- function(column_name) { query <- paste0( 'SELECT ', column_name, ', COUNT(1) AS num_babies, AVG(weight_pounds) AS avg_wt FROM publicdata.samples.natality WHERE year > 2000 GROUP BY ', column_name) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Richiama questa funzione utilizzando la colonna
mother_age, quindi controlla il numero di bambini e il peso medio per età della madre:df <- get_distinct_values('mother_age') ggplot(data = df, aes(x = mother_age, y = num_babies)) + geom_line() ggplot(data = df, aes(x = mother_age, y = avg_wt)) + geom_line()L'output del primo comando
ggplotè il seguente, che mostra il numero di bambini nati dall'età della madre.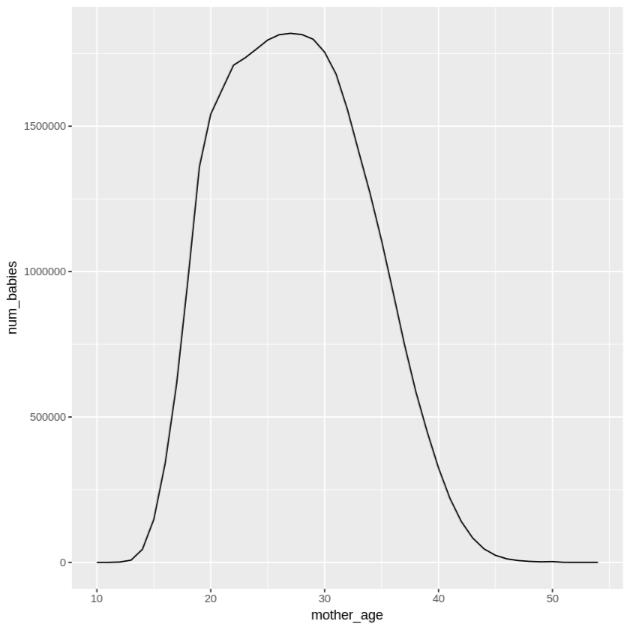
L'output del secondo comando
ggplotè il seguente, che mostra il peso medio dei bambini in base all'età della madre.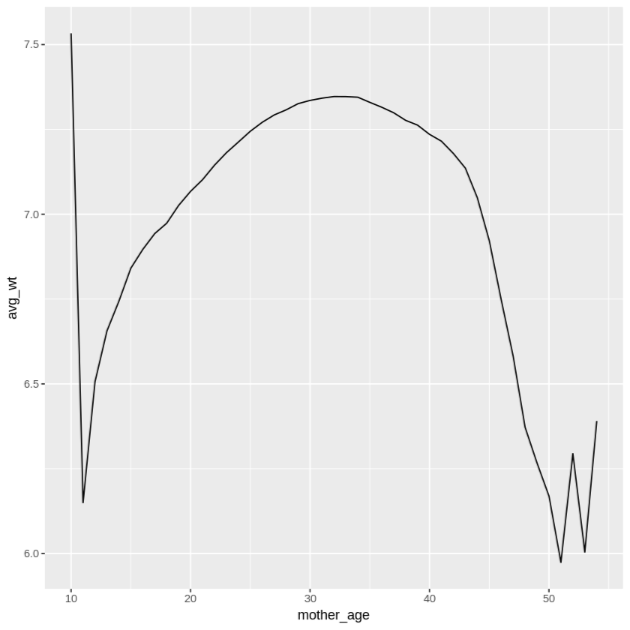
Per vedere altri esempi di visualizzazione, fai riferimento al blocco note.
Salvataggio dei dati come file CSV
L'attività successiva consiste nel salvare i dati estratti da BigQuery come file CSV in Cloud Storage, in modo da poterli utilizzare per altre attività di ML.
Carica i dati di addestramento e valutazione da BigQuery in R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query, sample_size) train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Scrivi i dati in un file CSV locale:
# Write data frames to local CSV files, without headers or row names dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = FALSE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = FALSE, sep = ",")Carica i file CSV in Cloud Storage eseguendo il wrapping dei comandi
gsutiltrasmessi al sistema:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Un'altra opzione per questo passaggio è utilizzare la libreria googleCloudStorageR per eseguire questa operazione utilizzando l'API JSON Cloud Storage.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, devi rimuoverle.
Elimina il progetto
Il modo più semplice per eliminare la fatturazione è eliminare il progetto che hai creato per il tutorial.
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Passaggi successivi
- Scopri di più su come utilizzare i dati BigQuery nei blocchi note R nella documentazione relativa a BigQuery.
- Scopri le best practice per l'ingegneria ML in Regole di ML.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Dai un'occhiata al nostro Centro di architettura cloud.