この記事は、Google Cloud で AI Platform を使用して、顧客のライフタイム バリュー(CLV)を予測する方法を説明する 4 パート構成のシリーズのパート 3 です。
このシリーズの記事は次のとおりです。
- パート 1: はじめに。CLV の概要と、CLV 予測の 2 つのモデリング手法について説明します。
- パート 2: モデルのトレーニング。データを準備し、モデルをトレーニングする方法について説明します。
- パート 3: 本番環境へのデプロイ(この記事)パート 2 で説明したモデルを本番環境システムにデプロイする方法について説明します。
- パート 4: AutoML Tables の使用。AutoML Tables を使用してモデルをビルドおよびデプロイする方法を説明します。
コードのインストール
この記事で説明するプロセスに従う場合は、GitHub のサンプルコードをインストールする必要があります。
gcloud CLI をインストール済みの場合は、パソコンのターミナル ウィンドウを開き、コマンドを実行します。gcloud CLI がインストールされていない場合は、Cloud Shell のインスタンスを開きます。
サンプルコード リポジトリのクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
README ファイルのインストール セクションと自動化セクションにあるインストール手順に沿って環境を設定し、ソリューション コンポーネントをデプロイします。これには、サンプル データセットと Cloud Composer 環境が含まれます。
以下のセクションのコマンド例では、これらの手順の両方を完了していることを前提としています。
インストール手順の一部として、README ファイルの設定セクションの説明に従って、環境に合わせて変数を設定します。
地理的に最も近い Google Cloud リージョンに対応するように REGION 変数を変更します。リージョンのリストについては、リージョンとゾーンをご覧ください。
アーキテクチャと実装
次の図は、この説明で使用されるアーキテクチャを示しています。

アーキテクチャは次の機能に分割されます。
- データの取り込み: データが BigQuery にインポートされます。
- データの準備: 元データが、モデルで使用できるように変換されます。
- モデルのトレーニング: 予測に使用できるように、モデルの構築、トレーニング、調整が行われます。
- 予測の提供: オフライン予測が保存され、低レイテンシで利用できるようになります。
- 自動化: これらのタスクはすべて Cloud Composer によって実行され、管理されます。
データの取り込み
この記事では、データの取り込みを行うための具体的な方法については説明しません。BigQuery でデータを取り込む方法はさまざまあり、Pub/Sub、Cloud Storage、BigQuery Data Transfer Service などから取り込めます。詳細については、データ ウェアハウス使用者のための BigQuery をご覧ください。このシリーズで説明するアプローチでは、一般公開データセットを使用します。README ファイルのサンプルコードのように、このデータセットを BigQuery にインポートします。
データの準備
データを準備するには、このシリーズのパート 2 で示しているように、BigQuery でクエリを実行します。本番環境のアーキテクチャでは、Apache Airflow の有向非巡回グラフ(DAG)の一部としてクエリを実行します。このドキュメントの後半の自動化に関するセクションでは、データの準備のためにクエリを実行する方法について詳しく説明しています。
AI Platform でモデルをトレーニングする
このセクションでは、アーキテクチャのトレーニング部分の概要について説明します。
選択したモデルのタイプに関係なく、このソリューションに示されているコードは、トレーニングと予測の両方の目的で、AI Platform 上で動作するようにパッケージ化されています。AI Platform には以下の利点があります。
- 分散環境でローカルに、またはクラウドで実行できます。
- Cloud Storage などの Google の他のプロダクトへの組み込み接続を提供します。
- いくつかのコマンドを使用するだけで実行できます。
- ハイパーパラメータの調整が容易になります。
- インフラストラクチャの変更を最小限に抑えてスケーリングします(必要な場合)。
AI Platform でモデルのトレーニングと評価を行うには、トレーニング、評価、テストのデータセットを用意する必要があります。このシリーズのパート 2 に示すような SQL クエリを実行してデータセットを作成します。こうしたデータセットを BigQuery テーブルから Cloud Storage にエクスポートします。この記事で説明している本番環境のアーキテクチャでは、クエリが Airflow DAG によって実行されます。これについては、後述の「自動化」セクションで詳しく説明しています。README ファイルの DAG の実行の説明に従って DAG を手動で実行できます。
予測の提供
予測はオンラインまたはオフラインで作成できます。ただし、予測を作成することと、予測を提供することは異なります。この CLV のコンテキストでは、顧客がウェブサイトにログインしたり、小売店を訪れたりするといったイベントが、その顧客の生涯価値に大きく影響することはありません。したがって、結果をリアルタイムで提示する必要がある場合でも、オフラインで予測を行えます。オフライン予測では、次の操作機能を利用できます。
- トレーニングと予測の両方に対して同じ前処理ステップを実行できます。トレーニングと予測が別々に前処理されている場合、予測の精度が低くなる可能性があります。この現象をトレーニング サービング スキューといいます。
- トレーニングと予測のデータを準備するために、同じツールを使用できます。このシリーズで取り上げたアプローチでは、主に BigQuery を使用してデータを準備しています。
AI Platform を使用してモデルをデプロイし、バッチジョブを使用してオフラインで予測を行うことができます。AI Platform の予測では、次のタスクの実行が容易になります。
- バージョンの管理
- インフラストラクチャの変更を最小限に抑えたスケーリング
- 大規模なデプロイ
- 他の Google Cloud プロダクトとの連携
- SLA の提供
バッチ予測タスクでは、入力と出力の両方に Cloud Storage に保存されているファイルを使用します。DNN モデルの場合、task.py で定義されている次のサービス関数で入力の形式を定義します。
予測の出力形式は、model.py のコードの Estimator モデル関数によって返される EstimatorSpec で定義されます。
予測の使用
モデルの作成とデプロイが完了したら、モデルを使用して CLV 予測を実行できます。一般的な CLV の使用例は次のとおりです。
- データ スペシャリストは、ユーザー セグメントを構築するときにオフライン予測を利用できます。
- 顧客がオンラインまたは店内でブランドと関わるとき、組織はリアルタイムで特定のオファーを行えます。
BigQuery を使用した分析
CLV を理解することは、ブランド アクティベーションの成功には不可欠です。この記事では、以前の売上に基づいて生涯価値を計算することに焦点を当てています。売上データは通常、顧客管理(CRM)ツールから得られますが、ユーザーの行動に関する情報は、Google アナリティクス 360 などの他のソースに含まれている可能性があります。
次のいずれかのタスクを実行する場合は、BigQuery を使用する必要があります。
- あらゆるソースからの構造化データを保存する。
- Google アナリティクス 360、YouTube、AdWords などの一般的な SaaS ツールからデータを自動的に転送する。
- テラバイト単位の顧客データの結合などのアドホック クエリを実行する。
- 主要なビジネス インテリジェンス ツールを使用してデータを可視化する。
BigQuery は、マネージド ストレージとクエリエンジンとしての機能に加え、機械学習アルゴリズムを直接実行できる BigQuery ML 機能を備えています。BigQuery に各顧客の CLV 値を読み込むことで、データ アナリスト、科学者、エンジニアは所定のタスクで追加の指標を利用できるようになります。次のセクションで説明する Airflow DAG には、CLV 予測を BigQuery に読み込むタスクが含まれています。
Datastore を使用した低レイテンシ サービスの提供
オフラインで行われた予測は、リアルタイムで予測を提供するために再利用できることがあります。このシナリオでは、予測の鮮度は重要ではありませんが、妥当なタイミングで適切にデータにアクセスすることは重要です。
リアルタイムでの提供のためにオフライン予測を保存すると、顧客が行った操作によって CLV が直ちに変更されることはありません。ただし、CLV に迅速にアクセスすることが重要です。たとえば、顧客がウェブサイトを使用したり、ヘルプデスクに質問したり、POS を通じてチェックアウトしたりする際に、必要な対応を迅速に行うことにより、顧客関係を向上させることができます。したがって、予測結果を高速データベースに格納し、フロントエンドで安全なクエリを利用できるようにすることが成功の鍵となります。
たとえば、数十万もの顧客がいる場合は、次の理由から Datastore が適しています。
- NoSQL ドキュメント データベースがサポートされる。
- キー(顧客 ID)を使用してデータにすばやくアクセスできるだけでなく、SQL クエリも有効。
- REST API を介してアクセスできる。
- すぐに使用できる。つまり、設定のオーバーヘッドがない。
- 自動スケーリングに対応している。
このソリューションでは、CSV データセットを Datastore に直接読み込む方法がないため、JavaScript テンプレートとともに Dialogflow の Apache Beam を使用して、CLV 予測を Datastore に読み込みます。JavaScript テンプレートの次のコード スニペットは、その方法を示しています。
データが Datastore にある場合は、以下のような操作を選択できます。
- アプリから Datastore クライアント ライブラリを使用する。
- Cloud Endpoints または Apigee API Platform を使用して API エンドポイントを構築する。
- サーバーレス タスクに Cloud Functions を使用する。
ソリューションの自動化
最初の前処理、トレーニング、予測のステップを実行する際には、これまでに説明した方法でデータの使用を開始します。ただし、自動化と障害管理が必要であるため、プラットフォームではまだ本番環境の準備ができていません。
これらのステップは、いくつかのスクリプトにまとめて実行できますが、ワークフロー管理ツールを使用してステップを自動化することをおすすめします。Apache Airflow は一般的なワークフロー管理ツールで、Cloud Composer を使用して Google Cloud 上でマネージド Airflow パイプラインを実行できます。
Airflow は、各タスクの指定や、他のタスクとの関連の指定が可能な有向非巡回グラフ(DAG)で動作します。このシリーズで説明しているアプローチでは、次の操作を行います。
- BigQuery データセットを作成します。
- 一般公開データセットを Cloud Storage から BigQuery に読み込みます。
- BigQuery テーブルからデータをクリーニングし、新しい BigQuery テーブルに書き込みます。
- 1 つの BigQuery テーブル内のデータに基づいて機能を作成し、別の BigQuery テーブルに書き込みます。
- モデルがディープ ニューラル ネットワーク(DNN)の場合、データを BigQuery 内のトレーニング セットと評価セットに分割します。
- データセットを Cloud Storage にエクスポートし、AI Platform で使用できるようにします。
- AI Platform で定期的にモデルをトレーニングします。
- 更新されたモデルを AI Platform にデプロイします。
- 定期的に新しいデータのバッチ予測を行います。
- Cloud Storage にすでに保存されている予測を Datastore と BigQuery に保存します。
Cloud Composer の設定
Cloud Composer の設定方法については、GitHub リポジトリの README ファイルの手順をご覧ください。
このソリューションの有向非巡回グラフ
このソリューションでは、2 つの DAG を使用します。最初の DAG では、前述のシーケンスのステップ 1~8 を行います。
次の図は、Cloud Composer / Airflow の UI を示し、Airflow DAG のステップ 1~8 をまとめています。
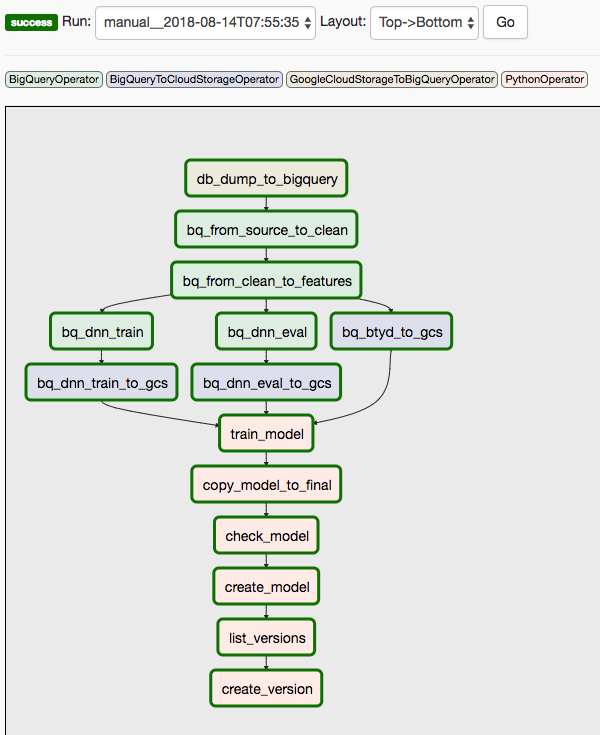
2 番目の DAG では、ステップ 9 と 10 を行います。
次の図は、Airflow DAG プロセスのステップ 9 と 10 をまとめたものです。
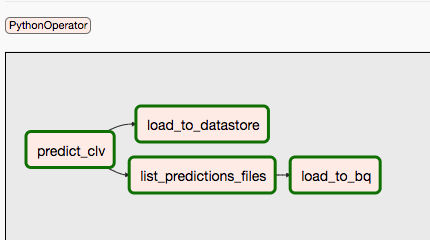
予測とトレーニングが別々に異なるスケジュールで行われる可能性があるため、DAG は分離されています。たとえば、次のことを行います。
- 新規顧客または既存顧客のデータを毎日予測する。
- 新しいデータを組み込むために週に 1 回モデルを再トレーニングするか、特定の数の新しいトランザクションを受け取った後に DAG をトリガーする。
最初の DAG を手動でトリガーするには、Cloud Shell の README ファイルの DAG の実行セクションに記載されているコマンドを実行するか、gcloud CLI を使用します。
conf パラメータは、自動化のさまざまな部分に変数を渡します。たとえば、クリーンアップしたデータから機能を抽出するために使用される次の SQL クエリでは、変数を使用して FROM 句をパラメータ化します。
同様のコマンドを使用して、2 番目の DAG をトリガーできます。詳細については、GitHub リポジトリの README ファイルをご覧ください。
次のステップ
- GitHub リポジトリで完全な例を実行する。
- 次のいずれかを使用して、CLV モデルに新しい機能を組み込む。
- クリックストリーム データ。これは履歴データがない顧客の CLV を予測するのに役立ちます。
- 製品の部門とカテゴリ。コンテキストを追加でき、ニューラル ネットワークに役立つことがあります。
- このソリューションで使用しているのと同じ入力で作成する新機能。たとえば、しきい値の日付より前の最後の数週間または数か月の売上の傾向。
- パート 4: モデルに対する AutoML Tables を使用するを読む。
- 他の予測ソリューションについて学習する。
- Google Cloud に関するリファレンス アーキテクチャ、図、チュートリアル、ベスト プラクティスを確認する。Cloud Architecture Center を確認します。