Artikel ini adalah bagian keempat dari rangkaian empat bagian yang membahas cara memprediksi nilai umur pelanggan (CLV) menggunakan AI Platform (AI Platform) di Google Cloud. Artikel ini menunjukkan cara menggunakan Tabel AutoML untuk melakukan prediksi.
Artikel dalam rangkaian ini meliputi:
- Bagian 1: Pengantar. Memperkenalkan CLV dan dua teknik pemodelan untuk memprediksi CLV.
- Bagian 2: Melatih model Membahas cara menyiapkan data dan melatih model.
- Bagian 3: Men-deploy ke produksi. Menjelaskan cara men-deploy model yang dibahas di Bagian 2 ke sistem produksi.
- Bagian 4: Menggunakan AutoML Tables (artikel ini). Menunjukkan cara menggunakan AutoML Tables untuk membangun dan men-deploy model.
Proses yang dijelaskan dalam artikel ini bergantung pada langkah pemrosesan data yang sama di BigQuery seperti yang dijelaskan di Bagian 2 dari seri ini. Artikel ini menunjukkan cara mengupload set data BigQuery tersebut ke AutoML Tables dan membuat model. Artikel ini juga menunjukkan cara mengintegrasikan model AutoML ke dalam sistem produksi yang dijelaskan di Bagian 3.
Kode untuk menerapkan sistem ini berada dalam repositori GitHub yang sama dengan seri aslinya. Artikel ini membahas cara menggunakan kode untuk Tabel AutoML di repositori tersebut.
Keunggulan Tabel AutoML
Di bagian awal seri ini, Anda telah mempelajari cara memprediksi CLV menggunakan model statistik dan model DNN yang diimplementasikan di TensorFlow. AutoML Tables memiliki beberapa keunggulan dibandingkan dua metode lainnya:
- Coding tidak diperlukan untuk membuat model. Ada UI konsol yang memungkinkan Anda membuat, melatih, mengelola, dan men-deploy set data dan model.
- Menambahkan atau mengubah fitur itu mudah, dan dapat dilakukan langsung di antarmuka konsol.
- Proses pelatihan dilakukan secara otomatis, termasuk penyesuaian hyperparameter.
- AutoML Tables mencari arsitektur terbaik untuk set data Anda, sehingga Anda tidak perlu memilih dari banyak opsi yang tersedia.
- AutoML Tables memberikan analisis mendetail tentang performa model terlatih, termasuk tingkat kepentingan fitur.
Hasilnya, diperlukan waktu dan biaya yang lebih sedikit untuk mengembangkan serta melatih model yang sepenuhnya dioptimalkan menggunakan AutoML Tables.
Deployment produksi solusi AutoML Tables mengharuskan Anda menggunakan API klien Python untuk membuat dan men-deploy model serta menjalankan prediksi. Artikel ini menunjukkan cara membuat dan melatih model AutoML Tables menggunakan API klien. Untuk mendapatkan panduan cara melakukan langkah-langkah ini menggunakan konsol AutoML Tables, lihat dokumentasi AutoML Tables.
Menginstal kode
Jika Anda belum menginstal kode untuk seri aslinya, ikuti langkah-langkah yang sama seperti yang dijelaskan di Bagian 2 dari seri asli untuk menginstal kode. File README di repositori GitHub menjelaskan semua langkah yang diperlukan untuk menyiapkan lingkungan Anda, menginstal kode, dan menyiapkan AutoML Tables di project Anda.
Jika sebelumnya kode telah diinstal, Anda harus melakukan langkah-langkah tambahan berikut untuk menyelesaikan penginstalan artikel ini:
- Aktifkan AutoML Tables API di project Anda.
- Aktifkan lingkungan miniconda yang sebelumnya Anda instal.
- Instal library klien Python seperti yang dijelaskan dalam dokumentasi AutoML Tables.
- Buat dan download file kunci API, lalu simpan di lokasi yang diketahui untuk digunakan nanti dengan library klien.
Menjalankan kode
Untuk sebagian besar langkah dalam artikel ini, Anda menjalankan perintah Python. Setelah menyiapkan lingkungan dan menginstal kode, Anda memiliki opsi berikut untuk menjalankan kode:
Jalankan kode di notebook Jupyter. Dari jendela terminal di lingkungan miniconda yang diaktifkan, jalankan perintah berikut:
$ (clv) jupyter notebookKode untuk setiap langkah dalam artikel ini ada di notebook dalam repositori kode bernama
notebooks/clv_automl.ipynb. Buka notebook ini di antarmuka Jupyter. Kemudian, Anda dapat menjalankan setiap langkah seperti yang Anda ikuti dalam tutorial.Jalankan kode sebagai skrip Python. Langkah-langkah kode untuk tutorial ini ada dalam repositori kode dalam file
clv_automl/clv_automl.py. Skrip ini mengambil argumen di command line untuk parameter yang dapat dikonfigurasi seperti project ID, lokasi file kunci API, region Google Cloud, dan nama set data BigQuery. Jalankan skrip dari jendela terminal di lingkungan miniconda yang telah aktif, dengan mengganti nama project Google Cloud Anda dengan[YOUR_PROJECT]:$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
Untuk mengetahui daftar lengkap parameter dan nilai default, lihat metode
create_parserdalam skrip, atau jalankan skrip tanpa argumen untuk melihat dokumentasi penggunaan.Setelah Anda menginstal lingkungan Cloud Composer seperti yang dijelaskan di README, jalankan kode dengan menjalankan DAG, seperti yang akan dijelaskan nanti di bagian Menjalankan DAG.
Menyiapkan data
Artikel ini menggunakan set data dan langkah persiapan data yang sama di BigQuery, yang dijelaskan di Bagian 2 dari seri asli. Setelah selesai menggabungkan data seperti yang dijelaskan dalam artikel tersebut, Anda siap membuat set data untuk digunakan dengan Tabel AutoML.
Membuat set data AutoML Tables
Untuk memulai, upload data yang telah Anda siapkan di BigQuery ke dalam Tabel AutoML.
Untuk menginisialisasi klien, tetapkan nama file kunci ke nama file yang Anda download pada langkah penginstalan:
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)Buat set data:
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
Mengimpor data dari BigQuery
Setelah membuat set data, Anda dapat mengimpor data dari BigQuery.
Impor data dari BigQuery ke set data AutoML Tables:
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
Melatih model
Setelah membuat set data AutoML untuk data CLV, Anda dapat membuat model AutoML Tables.
Dapatkan spesifikasi kolom AutoML Tables untuk setiap kolom dalam set data:
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}Spesifikasi kolom diperlukan pada langkah-langkah berikutnya.
Tetapkan salah satu kolom sebagai label untuk model AutoML Tables:
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)Kode ini menggunakan kolom label yang sama (
target_monetary) dengan model DNN TensorFlow di Bagian 2.Tentukan fitur untuk melatih model:
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')Fitur yang digunakan untuk melatih model AutoML Tables adalah fitur yang sama dengan yang digunakan untuk melatih model DNN TensorFlow di Bagian 2 dari seri aslinya. Namun, penambahan atau pengurangan fitur dari model akan jauh lebih mudah dengan AutoML Tables. Setelah dibuat di BigQuery, fitur tersebut otomatis disertakan dalam model, kecuali jika Anda menghapusnya secara eksplisit seperti yang ditunjukkan dalam cuplikan kode sebelumnya.
Tentukan opsi untuk membuat model. Tujuan pengoptimalan meminimalkan rata-rata error absolut, yang diwakili oleh parameter
MINIMIZE_MAE, direkomendasikan untuk set data ini.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }Untuk mengetahui informasi lebih lanjut, lihat dokumentasi AutoML Tables tentang tujuan pengoptimalan.
Buat model dan mulai pelatihan:
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.nameNilai yang ditampilkan dari panggilan klien (
create_model_response) segera ditampilkan. Nilaicreate_model_response.result()adalah promise, yang melakukan pemblokiran hingga pelatihan selesai. Nilaimodel_nameadalah jalur resource yang diperlukan untuk panggilan klien lebih lanjut yang beroperasi pada model.
Mengevaluasi model
Setelah pelatihan model selesai, Anda dapat mengambil statistik evaluasi model. Anda dapat menggunakan konsol Google Cloud atau API klien.
Untuk menggunakan konsol, di konsol AutoML Tables, buka tab Evaluate:

Untuk menggunakan API klien, ambil statistik evaluasi model:
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]Anda akan melihat output yang mirip dengan ini:
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
Root mean kuadrat error 853.481 lebih baik dibandingkan model probabilistik dan TensorFlow yang digunakan dalam seri aslinya. Namun, seperti yang dibahas di Bagian 2, sebaiknya coba setiap teknik yang disediakan dengan data Anda untuk melihat teknik mana yang memiliki performa terbaik.
Men-deploy model AutoML
DAG Cloud Composer dari seri aslinya telah diperbarui guna menyertakan model AutoML Tables untuk pelatihan dan prediksi. Untuk mengetahui informasi umum tentang fungsi DAG Cloud Composer, lihat bagian Mengotomatiskan Solusi di Bagian 3 dalam artikel asli.
Anda dapat menginstal sistem orkestrasi Cloud Composer untuk solusi ini dengan mengikuti petunjuk di README.
Metode panggilan DAG yang diupdate dalam skrip clv_automl/clv_automl.py yang
mereplikasi panggilan kode klien yang ditampilkan sebelumnya untuk membuat model dan
menjalankan prediksi.
DAG pelatihan
DAG yang diperbarui untuk pelatihan mencakup tugas untuk membuat model Tabel AutoML. Diagram berikut menunjukkan DAG baru untuk pelatihan.

DAG prediksi
DAG yang diupdate untuk prediksi mencakup tugas untuk menjalankan prediksi batch dengan model AutoML Tables. Diagram berikut menunjukkan DAG baru untuk prediksi.
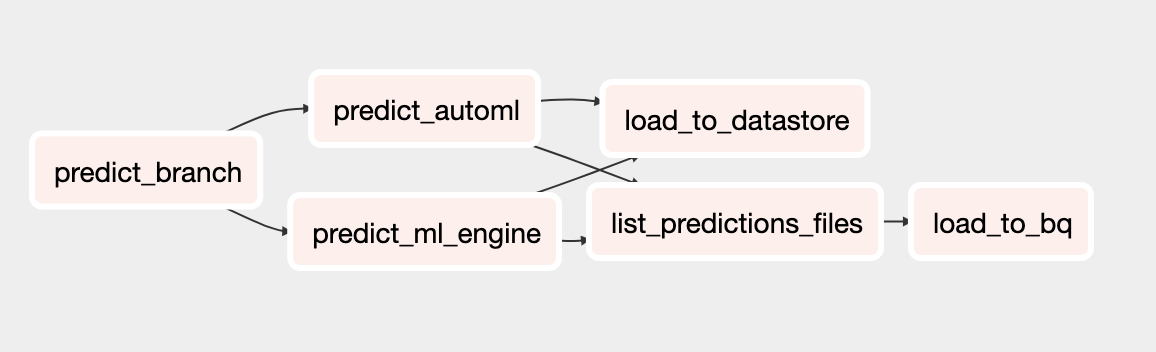
Menjalankan DAG
Untuk memicu DAG secara manual, Anda dapat menjalankan perintah dari bagian Jalankan Dags pada file README di Cloud Shell atau dengan menggunakan Google Cloud CLI.
Untuk menjalankan DAG
build_train_deploy:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'Jalankan DAG
predict_serve:gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
Langkah selanjutnya
- Tinjau kumpulan tutorial CLV lengkap.
- Jalankan contoh lengkap di repositori GitHub.
- Pelajari solusi perkiraan prediktif lainnya.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.