이 가이드에서는 두 Google Cloud 리전 간에 재해 복구(DR) 솔루션으로 Microsoft SQL Server 데이터베이스 시스템을 배포 및 관리하고 장애가 발생한 데이터베이스 인스턴스에서 정상적으로 작동하는 인스턴스로 장애 조치하는 방법을 설명합니다. 이 문서에서 재해는 기본 데이터베이스에 장애가 발생하거나 사용할 수 없는 상태를 의미합니다.
기본 데이터베이스는 데이터베이스가 위치한 리전에 장애가 발생하거나 액세스할 수 없는 상태가 되었을 때 장애가 발생할 수 있습니다. 리전을 사용할 수 있고 정상적으로 작동하더라도 시스템 오류로 인해 기본 데이터베이스에 장애가 발생할 수 있습니다. 이럴 때 재해 복구는 처리를 계속하기 위해 보조 데이터베이스를 클라이언트에 제공하는 과정을 의미합니다.
이 가이드는 데이터베이스 설계자, 관리자, 엔지니어를 대상으로 합니다.
목표
- Microsoft SQL Server의 AlwaysOn 가용성 그룹을 사용하여 Google Cloud에 멀티 리전 재해 복구 환경을 배포합니다.
- 재해 이벤트를 시뮬레이션하고 전체 재해 복구 프로세스를 수행하여 재해 복구 구성을 검사합니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
이 가이드에는 Google Cloud 프로젝트가 필요합니다. 새 프로젝트를 만들거나 기존에 만든 프로젝트를 선택할 수 있습니다.
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
Google Cloud 콘솔에서 Cloud Shell을 활성화합니다.
재해 복구 이해
Google Cloud에서 재해 복구(DR)는 특히 리전에 장애가 발생하거나 액세스할 수 없을 때 연속적인 처리 기능을 제공하는 것입니다. 데이터베이스 관리 시스템과 같은 시스템에 대해 최소 2개 이상의 리전에 시스템을 배포하여 DR을 구현합니다. 이렇게 설정하면 한 리전을 사용할 수 없게 되어도 시스템이 계속 작동합니다.
데이터베이스 시스템 재해 복구
기본 데이터베이스 인스턴스에 장애가 발생할 때 보조 데이터베이스를 사용할 수 있게 만드는 프로세스를 데이터베이스 재해 복구(또는 데이터베이스 DR)라고 합니다. 이 개념에 대한 자세한 내용은 Microsoft SQL Server 재해 복구를 참조하세요. 이상적으로 보조 데이터베이스 상태는 기본 데이터베이스가 사용할 수 없게 된 시점에 기본 데이터베이스와 일치합니다. 또는 보조 데이터베이스에 기본 데이터베이스의 최근 트랜잭션 일부만 누락됩니다.
재해 복구 아키텍처
Microsoft SQL Server에서 다음 다이어그램은 데이터베이스 DR을 지원하는 최소한의 아키텍처를 보여줍니다.
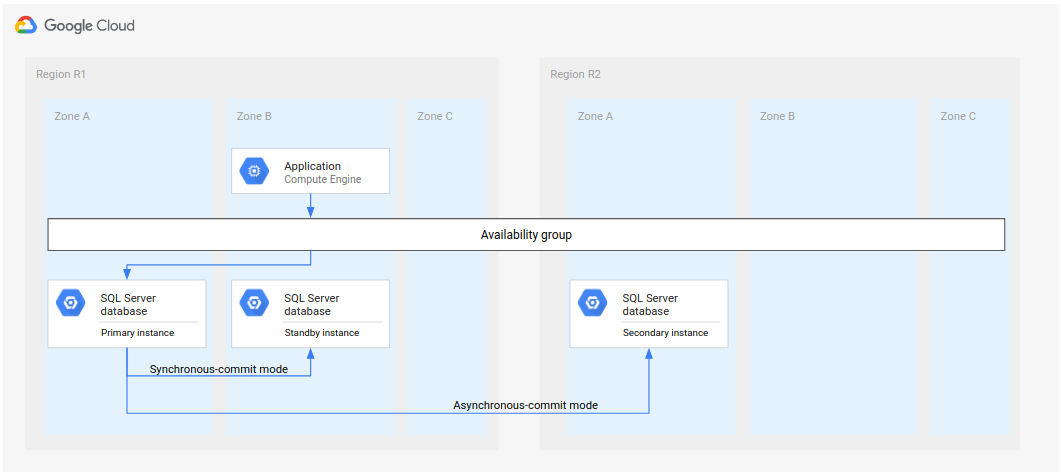
그림 1. Microsoft SQL Server의 표준 재해 복구 이키텍처.
이 아키텍처의 동작은 다음과 같습니다.
- Microsoft SQL Server의 두 인스턴스(기본 인스턴스와 보조 인스턴스)가 동일한 리전(R1)에 배치되지만 영역은 서로 다릅니다(A 및 B 영역). R1에 있는 두 인스턴스는 동기 커밋 모드를 사용하여 해당 상태를 조정합니다. 동기 모드가 사용되는 이유는 고가용성을 지원하고 데이터를 일관적인 상태로 유지하기 때문입니다.
- Microsoft SQL Server의 한 인스턴스(보조 또는 재해 복구 인스턴스)가 두 번째 리전(R2)에 배치됩니다. DR을 위해 R2의 보조 인스턴스는 비동기 커밋 모드를 사용하여 R1의 기본 인스턴스와 동기화됩니다. 비동기 모드는 성능상의 이유로 사용됩니다(기본 인스턴스의 커밋 처리 속도에 영향을 주지 않음).
앞의 다이어그램에서 아키텍처는 가용성 그룹을 보여줍니다. 가용성 그룹은 리스너와 함께 사용될 경우 클라이언트가 다음 인스턴스로 경우 클라이언트에 동일한 연결 문자열을 제공합니다.
- 기본 인스턴스
- 대기 인스턴스(영역 장애 발생 후)
- 보조 인스턴스(리전 장애 발생 후 및 보조 인스턴스가 새로운 기본 인스턴스로 전환된 후)
위 아키텍처의 한 가지 변형에서는 첫 번째 리전(R1)에 있는 두 인스턴스를 동일한 영역에 배포합니다. 이 방식은 성능이 향상될 수 있지만 가용성이 높지 않습니다. 단일 영역 중단 시 DR 프로세스를 시작해야 할 수 있습니다.
기본 재해 복구 프로세스
리전을 사용할 수 없으면 DR 프로세스가 시작되고 다른 작동 리전에서 처리가 계속되도록 기본 데이터베이스가 장애 조치됩니다. DR 프로세스에는 리전 장애를 완화하고 사용 가능한 리전에서 실행되는 기본 인스턴스를 설정하기 위해 수동 또는 자동으로 수행해야 하는 작업 단계가 기술됩니다.
기본 데이터베이스 DR 프로세스는 다음 단계들로 구성됩니다.
- 기본 데이터베이스 인스턴스를 실행하는 첫 번째 리전(R1)이 사용할 수 없는 상태가 됩니다.
- 운영팀이 재해 상태를 인식하고, 공식적으로 재해를 인정하고, 장애 조치가 필요한지 여부를 결정합니다.
- 장애 조치가 필요하면 두 번째 리전(R2)에 있는 보조 데이터베이스 인스턴스가 새로운 기본 인스턴스로 설정됩니다.
- 클라이언트가 새로운 기본 데이터베이스에서 처리를 재개하고 R2의 기본 인스턴스에 액세스합니다.
이러한 기본 프로세스는 작동하는 기본 데이터베이스를 다시 설정하지만, 새 기본 인스턴스에 대기 및 보조 데이터베이스 인스턴스가 포함된 전체 DR 아키텍처를 설정하지 않습니다.e.
재해 복구 프로세스 완료
전체 DR 프로세스는 장애 조치 후 전체 DR 아키텍처를 설정하기 위한 단계를 추가하여 기본 DR 프로세스를 확장합니다. 다음 다이어그램은 전체 데이터베이스 DR 아키텍처를 보여줍니다.

그림 2. 사용할 수 없는 기본 리전(R1)에서 재해 복구.
이 전체 데이터베이스 DR 아키텍처는 다음과 같이 작동합니다.
- 기본 데이터베이스 인스턴스를 실행하는 첫 번째 리전(R1)이 사용할 수 없는 상태가 됩니다.
- 운영팀이 재해 상태를 인식하고, 공식적으로 재해를 인정하고, 장애 조치가 필요한지 여부를 결정합니다.
- 장애 조치가 필요하면 두 번째 리전(R2)에 있는 보조 데이터베이스 인스턴스가 기본 인스턴스로 설정됩니다.
- 새로운 대기 인스턴스인 또 다른 보조 인스턴스가 생성되고 R2에서 시작되고 기본 인스턴스에 추가됩니다. 대기 인스턴스는 기본 인스턴스와 다른 영역에 배치됩니다. 기본 데이터베이스는 이제 가용성이 높은 2개의 인스턴스(기본 및 대기)로 구성됩니다.
- 세 번째 리전(R3)에서는 새로운 보조(대기) 데이터베이스 인스턴스가 생성되고 시작됩니다. 이 보조 인스턴스는 R2의 새 기본 인스턴스에 비동기적으로 연결됩니다. 이 시점에서 원래 재해 복구 아키텍처가 다시 생성되고 작동됩니다.
복구된 리전으로 대체
첫 번째 리전(R1)이 온라인으로 전환된 후 새 보조 데이터베이스를 호스팅할 수 있습니다. R1이 곧 사용 가능한 상태가 되면 R3(세 번째 리전) 대신 R1에서 전체 복구 프로세스의 5단계를 구현할 수 있습니다. 이 경우에는 세 번째 리전이 필요하지 않습니다.
다음 다이어그램은 R1이 시간 내에 사용 가능하게 되었을 때의 아키텍처를 보여줍니다.

그림 3. 장애가 발생한 R1 리전이 다시 사용 가능하게 된 후의 재해 복구.
이 아키텍처에서 복구 단계는 앞의 전체 재해 복구 프로세스에서 설명한 것과 동일하며, R1이 R3 대신 보조 인스턴스의 위치로 사용되는 것만 다릅니다.
SQL Server 버전 선택
이 가이드에서 지원되는 Microsoft SQL Server 버전은 다음과 같습니다.
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
이 가이드에서는 SQL Server의 AlwaysOn 가용성 그룹 기능이 사용됩니다.
고가용성(HA) Microsoft SQL Server 기본 데이터베이스가 필요하지 않고, 단일 데이터베이스 인스턴스만 기본 인스턴스로 사용해도 충분한 경우에는 다음 SQL Server를 사용할 수 있습니다.
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
SQL Server의 2016, 2017, 2019 버전에서는 Microsoft SQL Server Management Studio가 이미지에 설치되어 있습니다. 따라서 이를 별도로 설치할 필요가 없습니다. 하지만 프로덕션 환경에서는 Microsoft SQL Server Management Studio의 한 인스턴스를 각 리전의 개별 VM에 설치하는 것이 좋습니다. HA 환경을 설정할 때는 한 영역을 사용할 수 없을 때 다른 영역을 사용할 수 있도록 각 영역에 대해 한 번씩 Microsoft SQL Server Management Studio를 설치해야 합니다.
멀티 리전 DR을 위한 Microsoft SQL Server 설정
이 섹션에서는 Microsoft SQL Server
2016 Enterprise Edition의 sql-ent-2016-win-2016 이미지가 사용됩니다. Microsoft SQL Server 2017 Enterprise Edition을 설치할 때는 sql-ent-2017-win-2016을 사용합니다. Microsoft SQL Server 2019 Enterprise Edition의 경우에는 sql-ent-2019-win-2019를 사용합니다. 전체 이미지 목록은 이미지를 참조하세요.
2인스턴스 고가용성 클러스터 설정
SQL Server에 대해 멀티 리전 데이터베이스 DR 아키텍처를 설정하려면 먼저 한 리전에 2인스턴스 고가용성(HA) 클러스터를 만듭니다. 한 인스턴스는 기본 인스턴스로, 다른 인스턴스는 보조 인스턴스로 사용됩니다. 이 단계를 수행하려면 SQL Server AlwaysOn 가용성 그룹 구성의 안내를 따릅니다.
이 가이드에서는 기본 리전(R1으로 표시)에 us-central1이 사용됩니다.
시작하기 전에 다음 고려사항을 검토하세요.
먼저 SQL Server AlwaysOn 가용성 그룹의 단계를 따를 경우 동일 영역(us-central1-f)에 2개의 SQL Server 인스턴스를 만듭니다. 이 설정은 us-central1-f 장애에 대한 보호 기능을 제공하지 않습니다. 따라서 HA 지원을 제공하기 위해 us-central1-c에 SQL Server 인스턴스(cluster-sql1) 하나와 us-central1-f에 보조 인스턴스(cluster-sql2) 하나를 배포합니다. 다음 섹션의 단계(재해 복구를 위한 보조 인스턴스 추가)에서는 이 배포 설정을 사용한다고 가정합니다.
둘째, SQL Server AlwaysOn 가용성 그룹 구성의 단계에는 다음 명령문 실행이 포함됩니다.
BACKUP DATABASE TestDB to disk = '\\cluster-sql2\SQLBackup\TestDB.bak' WITH INIT
이 명령문은 보조 인스턴스에 장애를 일으킵니다. 대신 다음 명령어(백업 파일 이름은 다름)를 실행합니다.
BACKUP DATABASE TestDB to disk = '\\cluster-sql2\SQLBackup\TestDB-backup.bak' WITH INIT
셋째, SQL Server AlwaysOn 가용성 그룹 구성의 단계는 백업 디렉터리를 만듭니다. 이러한 백업은 기본 인스턴스 및 대기 인스턴스를 처음에 동기화할 때만 사용되며, 이후에는 사용되지 않습니다. 백업 디렉터리 만들기에 대한 다른 대안은 이러한 단계에서 자동 시드를 선택하는 것입니다. 이 방법을 사용하면 설정 프로세스가 간소화됩니다.
넷째, 데이터베이스가 동기화되지 않으면 cluster-sql2에서 다음 명령어를 실행합니다.
ALTER DATABASE [TestDB] SET HADR AVAILABILITY GROUP = [cluster-ag]
다섯째, 이 가이드에서는 다음 다이어그램에 표시된 것처럼 us-central1-f에서 하나의 도메인 컨트롤러를 만듭니다.

그림 4. 이 가이드에서 구현된 표준 재해 복구 아키텍처.
이 가이드에서 앞의 아키텍처를 구현했더라도 두 개 이상의 영역에 도메인 컨트롤러를 설정하는 것이 가장 좋습니다. 이렇게 하면 HA 및 DR이 지원되는 데이터베이스 아키텍처를 설정할 수 있습니다. 예를 들어 한 영역에서 중단이 발생해도, 이 영역이 배포된 아키텍처의 단일 장애점이 되지 않습니다.
재해 복구를 위한 보조 인스턴스 추가
그런 후 네트워킹과 함께 세 번째 SQL Server 인스턴스(이름이 cluster-sql3인 보조 인스턴스)를 설정합니다.
Cloud Shell에서 기본 리전에 사용한 것과 동일한 Virtual Private Cloud(VPC)에서 두 번째 리전(
us-east1)에 서브넷을 만듭니다.gcloud compute networks subnets create wsfcsubnet4 --network wsfcnet \ --region us-east1 --range 10.3.0.0/24새로운 서브넷의 트래픽 수신을 허용하도록
allow-internal-ports라는 방화벽 규칙을 수정합니다.gcloud compute firewall-rules update allow-internal-ports \ --source-ranges 10.0.0.0/24,10.1.0.0/24,10.2.0.0/24,10.3.0.0/24allow-internal-ports규칙은 앞에서 수행한 지침의 단계에 포함되어 있습니다.SQL Server 인스턴스를 만듭니다.
gcloud compute instances create cluster-sql3 --machine-type n1-highmem-4 \ --boot-disk-type pd-ssd --boot-disk-size 200GB \ --image-project windows-sql-cloud --image-family sql-ent-2016-win-2016 \ --zone us-east1-b \ --network-interface "subnet=wsfcsubnet4,private-network-ip=10.3.0.4,aliases=10.3.0.5;10.3.0.6" \ --can-ip-forward --metadata sysprep-specialize-script-ps1="Install-WindowsFeature Failover-Clustering -IncludeManagementTools;"새 SQL Server 인스턴스에 대해 Windows 비밀번호를 설정합니다.
Google Cloud 콘솔에서 Compute Engine 인스턴스 페이지로 이동합니다.
Compute Engine 클러스터
cluster-sql3의 연결 열에서 Windows 비밀번호 설정 드롭다운 목록을 선택합니다.사용자 이름과 비밀번호를 설정합니다. 나중에 사용할 수 있도록 기록해 둡니다.
RDP를 클릭하여
cluster-sql3인스턴스에 연결합니다.4단계에서 설정한 사용자 이름과 비밀번호를 입력한 후 확인을 클릭합니다.
관리자 권한으로 Windows PowerShell 창을 열고 DNS를 구성하고 포트를 엽니다.
netsh interface ip set dns Ethernet static 10.2.0.100 netsh advfirewall firewall add rule name="Open Port 5022 for Availability Groups" dir=in action=allow protocol=TCP localport=5022 netsh advfirewall firewall add rule name="Open Port 1433 for SQL Server" dir=in action=allow protocol=TCP localport=1433인스턴스를 Windows 도메인에 추가합니다.
Add-Computer -DomainName "dbeng.com" -Credential "dbeng.com\Administrator" -Restart -Force이 명령어는 RDP 연결을 종료합니다.
장애 조치 클러스터에 보조 인스턴스 추가
그런 후 Windows 장애 조치 클러스터에 보조 인스턴스(cluster-sql3)를 추가합니다.
RDP를 사용하여
cluster-sql1또는cluster-sql2인스턴스에 연결하고 관리자로 로그인합니다.관리자 권한으로 PowerShell 창을 열고 이 가이드의 클러스터 환경에 대해 변수를 설정합니다.
$node3 = "cluster-sql3" $nameWSFC = "cluster-dbclus" # Name of cluster클러스터에 보조 인스턴스를 추가합니다.
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3이 명령어를 실행하는 데 시간이 걸릴 수 있습니다. 프로세스가 응답하지 않고 자동으로 반환되지 않을 수 있으므로 이따금
Enter를 누르세요.노드에서 AlwaysOn 고가용성 기능을 사용 설정합니다.
Enable-SqlAlwaysOn -ServerInstance $node3 -ForceC:\SQLData및C:\SQLLog에 데이터베이스 데이터와 로그 파일을 저장하기 위한 두 폴더를 만듭니다.New-item -ItemType Directory "C:\SQLData" New-item -ItemType Directory "C:\SQLLog"
노드가 이제 장애 조치 클러스터에 조인됩니다.
보조 인스턴스를 기존 가용성 그룹에 추가합니다.
그런 후 SQL Server 인스턴스(보조 인스턴스) 및 데이터베이스를 가용성 그룹에 추가합니다.
3개 인스턴스 노드(
cluster-sql1,cluster-sql2,cluster-sql3)에서 Microsoft SQL Server Management Studio를 열고 기본 인스턴스(cluster-sql1)에 연결합니다.- 객체 탐색기로 이동합니다.
- 연결 드롭다운 목록을 선택합니다.
- Database Engine을 선택합니다.
- 서버 이름 드롭다운 목록에서
cluster-sql1을 선택합니다. 클러스터가 나열되지 않으면 필드에 입력합니다.
새 쿼리를 클릭합니다.
다음 명령어를 붙여 넣어서 노드에 사용되는 리스너에 IP 주소를 추가한 후 실행을 클릭합니다.
ALTER AVAILABILITY GROUP [cluster-ag] MODIFY LISTENER 'cluster-listene' (ADD IP ('10.3.0.6', '255.255.255.0'))객체 탐색기에서 AlwaysOn 고가용성 노드를 확장한 후 가용성 그룹 노드를 확장합니다.
이름이
cluster-ag인 가용성 그룹을 마우스 오른쪽 버튼으로 클릭한 후 복제본 추가를 선택합니다.소개 페이지에서 AlwaysOn 고가용성 노드를 클릭한 후 가용성 그룹 노드를 클릭합니다.
복제본에 연결 페이지에서 연결을 클릭하여 기존 보조 복제본
cluster-sql2에 연결합니다.복제본 지정 페이지에서 복제본 추가를 클릭한 후 새 노드
cluster-sql3을 추가합니다. 자동 장애 조치는 동기 커밋을 일으키므로 자동 장애 조치를 선택하지 마세요. 이러한 설정은 리전 경계를 넘어서며, 이는 권장되지 않는 방식입니다.데이터 동기화 선택 페이지에서 자동 시드를 선택합니다.
리스너가 없기 때문에 검사 페이지에 경고가 생성되지만, 이는 무시해도 됩니다.
마법사 단계를 완료합니다.
cluster-sql1 및 cluster-sql2의 장애 조치 모드는 자동이고 cluster-sql3의 경우에는 수동입니다. 이러한 차이는 재해 복구와 고가용성을 구별하기 위한 한 가지 방법입니다.
가용성 그룹이 이제 준비되었습니다. 고가용성을 위한 2개 노드와 재해 복구를 위한 세 번째 노드가 구성되었습니다.
재해 복구 시뮬레이션
이 섹션에서는 이 가이드의 재해 복구 아키텍처를 테스트하고 선택사항인 DR 구현을 고려합니다.
장애 시뮬레이션 및 DR 장애 조치 수행
기본 리전의 오류(장애)를 시뮬레이션합니다.
cluster-sql1의 Microsoft SQL Server Management Studio에서cluster-sql1에 연결합니다.테이블을 만듭니다. 이후 단계에 복제본을 추가한 후 이 테이블이 있는지 여부를 확인하여 복제본이 작동하는지 확인합니다.
USE TestDB GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GOCloud Shell의 기본 리전(
us-central1)에서 두 서버를 종료합니다.gcloud compute instances stop cluster-sql2 --zone us-central1-f --quiet gcloud compute instances stop cluster-sql1 --zone us-central1-c --quiet
cluster-sql3의 Microsoft SQL Server Management Studio에서cluster-sql3에 연결합니다.장애 조치를 실행하고 가용성 모드를 동기 커밋으로 설정합니다. 노드가 비동기 커밋 모드이므로 장애 조치를 강제 적용해야 합니다.
ALTER AVAILABILITY GROUP [cluster-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO처리를 재개할 수 있습니다.
cluster-sql3가 이제 기본 인스턴스입니다.(선택사항)
cluster-sql3에서 새 테이블을 만듭니다. 복제본을 새 기본 인스턴스와 동기화한 후 이 테이블이 복제본에 복제되었는지 확인합니다.USE TestDB GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
이 시점에서는 cluster-sql3이 기본이지만 원래 리전으로 돌아가거나 완전한 DR 아키텍처를 다시 만들기 위해 새로운 보조 인스턴스 및 대기 인스턴스를 설정해야 할 수도 있습니다. 다음 섹션에서는 이러한 옵션들에 대해 설명합니다.
(선택사항) 트랜잭션을 완전히 복제하는 DR 아키텍처 다시 만들기
이 사용 사례에서는 기본 데이터베이스에 장애가 발생하기 전 기본 데이터베이스에서 보조 데이터베이스로 모든 트랜잭션이 복제되는 장애 상황을 다룹니다. 이 이상적인 시나리오에서는 데이터가 전혀 손실되지 않습니다. 보조 데이터베이스의 상태는 장애 시점에 기본 데이터베이스와 일치합니다.
이 시나리오에서는 두 가지 방법으로 완전한 DR 아키텍처를 다시 만들 수 있습니다.
- 원래 기본 및 원래 대기(사용 가능한 경우)로 돌아갑니다.
- 원래 기본 및 대기를 사용할 수 없는 경우를 대비하여
cluster-sql3에 대해 새로운 대기 및 보조를 만듭니다.
방법 1: 원래 기본 및 대기로 돌아가기
Cloud Shell에서 원래(이전) 기본 및 대기를 시작합니다.
gcloud compute instances start cluster-sql1 --zone us-central1-c --quiet gcloud compute instances start cluster-sql2 --zone us-central1-f --quietMicrosoft SQL Server Management Studio에서
cluster-sql1및cluster-sql2를 보조 복제본으로 추가합니다.cluster-sql3에서 비동기 커밋 모드로 2개 서버를 추가합니다.USE [master] GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOcluster-sql1에서 데이터베이스 동기화를 다시 시작합니다.USE [master] GO ALTER DATABASE [TestDB] SET HADR RESUME; GOcluster-sql2에서 데이터베이스 동기화를 다시 시작합니다.USE [master] GO ALTER DATABASE [TestDB] SET HADR RESUME; GO
cluster-sql1을 다시 기본으로 만듭니다.cluster-sql3에서cluster-sql1의 가용성 모드를 동기 커밋으로 변경합니다.cluster-sql1인스턴스가 다시 기본이 됩니다.USE [master] GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOcluster-sql1에서cluster-sql1을 기본으로 변경하고 다른 2개 노드를 보조로 변경합니다.USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [cluster-ag] FAILOVER; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
모든 명령어가 성공한 후 다음 다이어그램에 표시된 것처럼 cluster-sql1이 기본이 되고 다른 노드는 보조가 됩니다.

방법 2: 새로운 기본 및 대기 설정
장애로부터 원래 기본 및 대기 인스턴스를 복구하지 못하거나 복구하는 데 시간이 너무 오래 걸리거나 해당 리전에 액세스하지 못하게 될 경우도 있습니다. 한 가지 방법은 cluster-sql3을 기본으로 유지하고 다음 다이어그램에 표시된 것처럼 새로운 대기 및 새로운 보조 인스턴스를 만드는 것입니다.

그림 5. 원래 기본 리전 R1을 사용할 수 없는 경우의 재해 복구.
이 구현을 위해서는 다음을 수행해야 합니다.
us-east1에서cluster-sql3을 기본으로 유지합니다.us-east1의 다른 영역에 새로운 대기 인스턴스(cluster-sql4)를 추가합니다. 이 단계에서는 새로운 배포를 고가용성으로 설정합니다.개별 리전(예:
us-west2)에 새로운 보조 인스턴스(cluster-sql5)를 만듭니다. 이 단계에서는 재해 복구를 위해 새로운 배포를 설정합니다. 전체 배포가 이제 완료되었습니다. 데이터베이스 아키텍처가 HA 및 DR을 완전히 지원합니다.
(선택사항) 트랜잭션이 누락된 경우 대체 실행
기본에서 커밋된 하나 이상의 트랜잭션이 장애 시점(하드 오류라고도 부름)에 보조로 복제되지 않는 경우는 덜 이상적인 장애 상태입니다. 장애 조치 단계에서 복제되지 않은 모든 커밋된 트랜잭션이 손실됩니다.
이 시나리오의 장애 조치 단계를 테스트하기 위해서는 하드 오류를 일으켜야 합니다. 하드 오류를 일으키는 가장 좋은 방법은 다음과 같습니다.
- 기본 및 보조 인스턴스가 연결되지 않도록 네트워크를 변경합니다.
- 테이블 추가 또는 일부 데이터 삽입 등의 방법으로 기본을 변경합니다.
- 보조가 새로운 기본이 되도록 앞에서 설명한 대로 장애 조치 프로세스를 진행합니다.
장애 조치 프로세스 단계가 이상적인 시나리오의 단계와 동일하지만 네트워크 연결이 중단된 후 기본에 추가된 테이블이 보조에 표시되지 않는다는 것만 다릅니다.
하드 오류를 해결하기 위한 유일한 옵션은 가용성 그룹에서 복제본(cluster-sql1 및 cluster-sql2)을 삭제하고 복제본을 다시 동기화하는 것입니다. 동기화하면 보조와 일치하도록 상태가 변경됩니다. 오류 이전에 복제되지 않은 트랜잭션은 모두 손실됩니다.
cluster-sql1을 보조 인스턴스로 추가하기 위해서는 이전에 cluster-sql3을 추가할 때와 동일한 단계(장애 조치 클러스터에 보조 인스턴스 추가 참조)를 따르면 되지만, 한 가지 차이가 있습니다. 지금은 cluster-sql1이 아닌 cluster-sql3이 기본입니다. cluster-sql3의 인스턴스를 가용성 그룹에 추가하는 서버 이름으로 바꿔야 합니다. 동일한 VM(cluster-sql1 및 cluster-sql2)을 사용할 경우에는 서버를 Windows Server 장애 조치 클러스터에 추가할 필요가 없습니다. SQL Server 인스턴스만 다시 가용성 그룹에 추가합니다.
이 시점에서는 cluster-sql3이 기본이고 cluster-sql1 및 cluster-sql2는 보조입니다. 이제 cluster-sql1로 돌아가서 cluster-sql2를 대기로, cluster-sql3을 보조로 만들 수 있습니다. 시스템 상태는 이제 오류 이전과 동일합니다.
자동 장애 조치
보조 인스턴스를 기본으로 설정하여 자동으로 장애 조치하면 문제가 발생할 수 있습니다. 원래 기본이 다시 사용 가능하게 된 후 일부 클라이언트가 보조에 액세스하고 다른 클라이언트는 복원된 기본에 쓰기를 수행하는 분할 브레인 상황이 발생할 수 있습니다. 이 경우 기본 및 보조가 병렬로 업데이트되고 상태가 달라집니다. 이 상황을 방지하기 위해, 이 가이드에서는 사용자가 장애 조치 여부(또는 시점)를 결정하는 수동 장애 조치 지침을 제공합니다.
자동 장애 조치를 구현할 경우에는 구성된 인스턴스 중 하나만 기본이 되고 수정될 수 있도록 해야 합니다. 모든 대기 또는 보조 인스턴스는 상태 복제를 위한 기본을 제외하고 모든 클라이언트에 쓰기 액세스를 제공하지 않아야 합니다. 또한 후속 장애 조치가 단시간 내에 연속적으로 급하게 수행되지 않도록 해야 합니다. 예를 들어 5분 간격으로 장애 조치를 수행하는 것은 믿을 만한 재해 복구 전략이 되지 않습니다. 자동 장애 조치 프로세스를 위해서는 이와 같이 문제가 될 만한 시나리오의 대비책을 마련하고, 경우에 따라 복잡한 의사결정이 필요하면 데이터베이스 관리자의 도움도 요청해야 합니다.
대체 배포 아키텍처
이 가이드에서는 다음 다이어그램에 표시된 것처럼 장애 조치 시 기본 인스턴스가 되는 보조 인스턴스가 포함된 재해 복구 아키텍처를 설정합니다.

그림 6. Microsoft SQL Server를 사용하는 표준 재해 복구 이키텍처.
즉, 장애 조치 시 결과 배포에는 대체가 가능할 때까지 또는 대기(HA용) 및 보조(DR용)를 구성할 때까지 단일 인스턴스가 포함됩니다.
대체 배포 아키텍처는 2개의 보조 인스턴스를 구성하는 것입니다. 두 인스턴스 모두 기본의 복제본입니다. 장애 조치가 수행될 때 보조 중 하나를 대기로 다시 구성할 수 있습니다. 다음 다이어그램은 장애 조치 이전 및 이후의 배포 아키텍처를 보여줍니다.
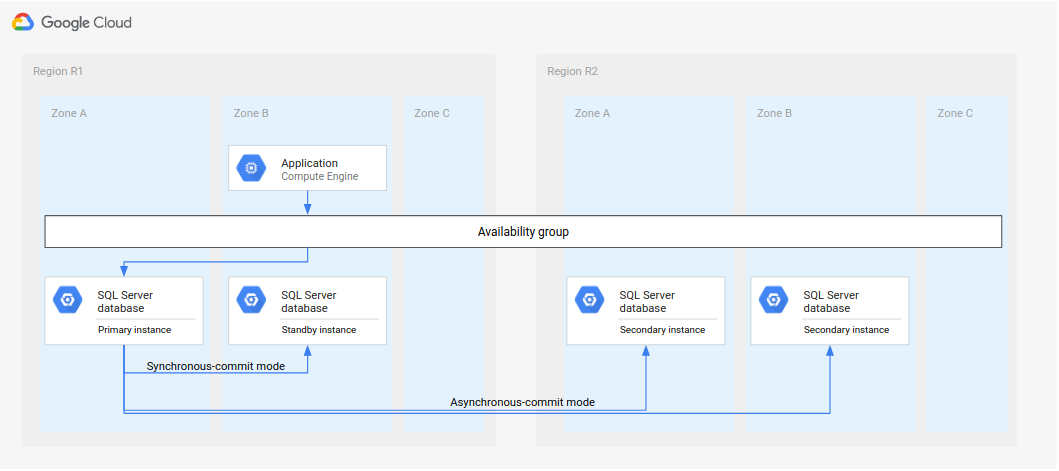
그림 7. 2개의 보조 인스턴스가 포함된 표준 재해 복구 아키텍처.

그림 8. 장애 조치 후 2개의 보조 인스턴스가 포함된 표준 재해 복구 아키텍처.
여전히 2개의 보조 중 하나를 대기로 만들어야 하지만(그림 8), 이 프로세스는 처음부터 새 대기를 만들고 구성하는 것보다 훨씬 빠릅니다.
또한 2개의 보조 인스턴스를 사용하는 이 아키텍처와 동일한 설정으로 DR을 해결할 수도 있습니다. 두 번째 리전에 2개의 보조를 배포하는 것 외에도(그림 7) 세 번째 리전에 또 다른 2개의 보조를 배포할 수 있습니다. 이 설정을 사용하면 기본 리전에 오류가 발생한 후 HA 및 DR 지원 배포 아키텍처를 효율적으로 만들 수 있습니다.
정리
이 가이드에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 안내를 따르세요.
프로젝트 삭제
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
다음 단계
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기