Ce tutoriel décrit comment déployer et gérer un système de base de données Microsoft SQL Server dans deux régions Google Cloud en tant que solution de reprise après sinistre. Il explique également comment basculer d'une instance de base de données défaillante à une instance opérationnelle. Dans ce document, un sinistre est un événement qui entraîne l'échec ou l'indisponibilité d'une base de données principale.
Une base de données principale peut échouer lorsque la région dans laquelle elle se trouve devient défaillante ou inaccessible. Même si une région est disponible et fonctionne normalement, une base de données principale peut échouer en raison d'une erreur système. Dans ce cas, la reprise après sinistre consiste à mettre une base de données secondaire à la disposition des clients, afin qu'ils puissent poursuivre leur traitement.
Ce tutoriel est destiné aux architectes, aux administrateurs et aux ingénieurs de bases de données.
Objectifs
- Déployer un environnement multirégional de reprise après sinistre sur Google Cloud à l'aide de groupes de disponibilité AlwaysOn Microsoft SQL Server
- Simuler un sinistre et exécuter un processus complet de reprise après sinistre pour valider la configuration de reprise après sinistre
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
Pour ce tutoriel, vous avez besoin d'un projet Google Cloud. Vous pouvez en créer un ou sélectionner un projet existant :
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Dans la console Google Cloud, activez Cloud Shell.
Comprendre la reprise après sinistre
Dans Google Cloud, la reprise après sinistre consiste à assurer la continuité du traitement, en particulier en cas de défaillance ou d'indisponibilité d'une région. Pour les systèmes tels que les systèmes de gestion de base de données, vous devez mettre en œuvre la reprise après sinistre en déployant le système dans au moins deux régions. Avec cette configuration, le système continue de fonctionner si une région devient indisponible.
Reprise après sinistre du système de base de données
Le processus de mise à disposition d'une base de données secondaire en cas d'échec de l'instance de base de données principale est appelé reprise après sinistre de base de données. Pour en savoir plus sur ce concept, consultez la page Reprise après sinistre pour Microsoft SQL Server. Idéalement, l'état de la base de données secondaire est cohérent avec la base de données principale au moment où elle devient indisponible, ou il ne manque à la base de données secondaire qu'un petit ensemble de transactions récentes de la base de données principale.
Architecture de reprise après sinistre
Pour Microsoft SQL Server, le schéma suivant illustre une architecture minimale permettant la reprise après sinistre de base de données.

Figure 1 : Architecture standard de reprise après sinistre avec Microsoft SQL Server.
Cette architecture fonctionne comme suit :
- Deux instances de Microsoft SQL Server (une instance principale et une instance de secours) se trouvent dans la même région (R1), mais dans des zones différentes (zones A et B). Les deux instances de la région R1 coordonnent leurs états à l'aide du mode de commit synchrone. Le mode synchrone est utilisé, car il offre une haute disponibilité et permet de conserver un état cohérent des données.
- Une instance de Microsoft SQL Server (instance secondaire ou de reprise après sinistre) se situe dans une deuxième région (R2). Pour la reprise après sinistre, l'instance secondaire de la région R2 se synchronise avec l'instance principale de la région R1 à l'aide du mode de commit asynchrone. Le mode asynchrone est utilisé en raison de ses performances (il ne ralentit pas le traitement des commits dans l'instance principale).
Dans le schéma précédent, l'architecture décrit un groupe de disponibilité. S'il est utilisé avec un écouteur, le groupe de disponibilité fournit la même chaîne de connexion aux clients lorsque la diffusion est effectuée par les ressources suivantes :
- L'instance principale
- L'instance de secours (après une défaillance zonale)
- L'instance secondaire (après une défaillance zonale et une fois que l'instance secondaire est devenue la nouvelle instance principale)
Dans une variante de l'architecture ci-dessus, vous déployez les deux instances de la première région (R1) dans la même zone. Cette approche peut améliorer les performances, mais n'offre pas de disponibilité élevée. L'interruption d'une seule zone peut en effet suffire à lancer le processus de reprise après sinistre.
Processus de base de reprise après sinistre
Le processus de reprise après sinistre démarre lorsqu'une région devient indisponible et que la base de données principale est soumise à un basculement, afin que le traitement se poursuive dans une autre région opérationnelle. Ce processus définit les étapes opérationnelles qui doivent être effectuées (manuellement ou automatiquement) pour limiter la défaillance régionale et établir une instance principale en cours d'exécution dans une région disponible.
Un processus de base de reprise après sinistre comprend les étapes suivantes :
- La première région (R1) qui exécute l'instance de base de données principale devient indisponible.
- L'équipe en charge des opérations reconnaît officiellement le sinistre et décide si un basculement est nécessaire.
- Si un basculement est nécessaire, l'instance de base de données secondaire de la deuxième région (R2) devient la nouvelle instance principale.
- Les clients reprennent le traitement sur la nouvelle base de données principale et accèdent à l'instance principale dans la région R2.
Bien que ce processus de base définisse à nouveau une base de données principale opérationnelle, il n'établit pas une architecture complète de reprise après sinistre, dans laquelle la nouvelle instance principale dispose d'une instance de secours et d'une instance secondaire.
Processus complet de reprise après sinistre
Un processus complet de reprise après sinistre étend le processus de base en ajoutant des étapes qui permettent d'établir une architecture complète de reprise après sinistre après un basculement. Le schéma suivant illustre une architecture complète de reprise après sinistre de base de données.
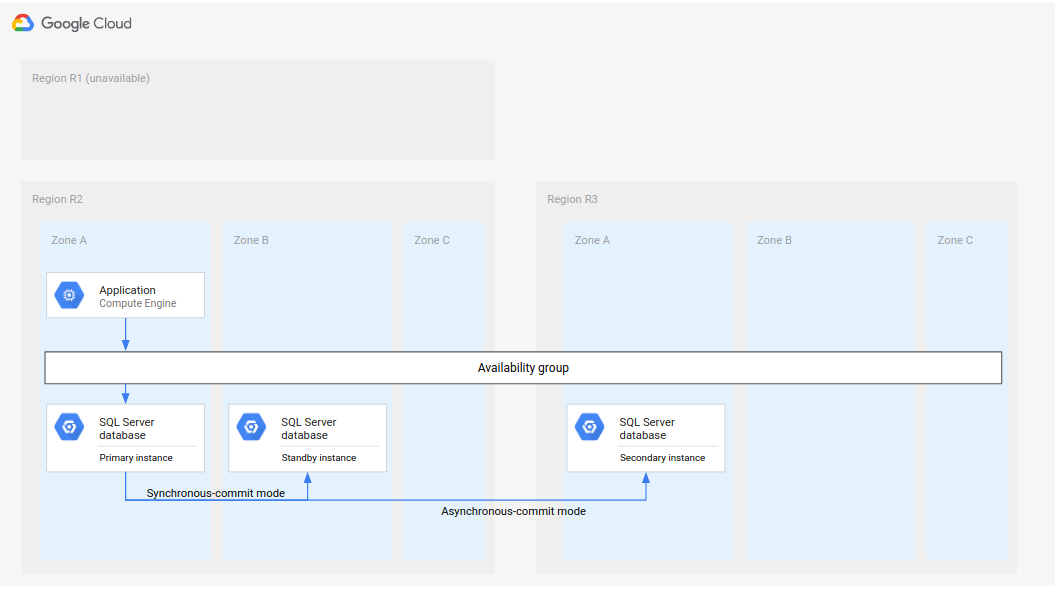
Figure 2. Reprise après sinistre avec une région principale indisponible (R1).
Cette architecture complète de reprise après sinistre de base de données fonctionne comme suit :
- La première région (R1) qui exécute l'instance de base de données principale devient indisponible.
- L'équipe en charge des opérations reconnaît officiellement le sinistre et décide si un basculement est nécessaire.
- Si un basculement est nécessaire, l'instance de base de données secondaire de la deuxième région (R2) devient l'instance principale.
- Une autre instance secondaire, la nouvelle instance de secours, est créée et démarrée dans la région R2, puis ajoutée à l'instance principale. L'instance de secours se trouve dans une zone différente de l'instance principale. La base de données principale comprend désormais deux instances (l'instance principale et l'instance de secours) à disponibilité élevée.
- Dans une troisième région (R3), une autre instance de base de données secondaire (de secours) est créée et démarrée. Cette instance secondaire est associée de manière asynchrone à la nouvelle instance principale dans la région R2. À ce stade, l'architecture de reprise après sinistre d'origine est recréée et opérationnelle.
Revenir à une région récupérée
Une fois la première région (R1) de nouveau en ligne, elle peut héberger la nouvelle base de données secondaire. Si la région R1 redevient rapidement disponible, vous pouvez mettre en œuvre l'étape 5 du processus de reprise complet dans la région R1 plutôt que la région R3. Dans ce cas, il n'est pas nécessaire d'avoir recours à une troisième région.
Le schéma suivant illustre l'architecture si la région R1 redevient disponible à temps.

Figure 3. Reprise après sinistre lorsque la région R1 défaillante redevient disponible.
Dans cette architecture, les étapes de récupération sont les mêmes que celles décrites précédemment dans la section Processus complet de reprise après sinistre, à ceci près que la région R1 devient l'emplacement des instances secondaires au lieu de la région R3.
Choisir une édition de SQL Server
Ce tutoriel s'applique aux versions suivantes de Microsoft SQL Server :
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
Le tutoriel utilise la fonctionnalité des groupes de disponibilité AlwaysOn SQL Server.
Si vous n'avez pas besoin d'une base de données principale Microsoft SQL Server à disponibilité élevée et qu'une seule instance de base de données vous suffit en tant qu'instance principale, vous pouvez utiliser les versions suivantes de SQL Server :
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
Avec les versions 2016, 2017 et 2019 de SQL Server, Microsoft SQL Server Management Studio est déjà installé dans l'image. Vous n'avez pas besoin de l'installer séparément. Dans un environnement de production, nous vous recommandons toutefois d'installer une instance de Microsoft SQL Server Management Studio sur une VM distincte dans chaque région. Si vous configurez un environnement à haute disponibilité, vous devez effectuer une installation de Microsoft SQL Server Management Studio dans chaque zone afin de garantir que le service reste disponible si une autre zone devient indisponible.
Configurer Microsoft SQL Server pour la reprise après sinistre multirégionale
Cette section utilise l'image sql-ent-2016-win-2016 pour Microsoft SQL Server 2016 Enterprise Edition. Si vous installez Microsoft SQL Server 2017 Enterprise Edition, utilisez l'image sql-ent-2017-win-2016. Pour Microsoft SQL Server 2019 Enterprise Edition, utilisez sql-ent-2019-win-2019. Pour obtenir la liste complète des images, consultez la page Images.
Configurer un cluster à haute disponibilité comprenant deux instances
Pour configurer une architecture multirégionale de reprise après sinistre de base de données pour SQL Server, vous devez d'abord créer un cluster à haute disponibilité à deux instances dans une région. Une instance sert d'instance principale, tandis que l'autre sert d'instance secondaire. Pour effectuer cette étape, suivez les instructions de la page Configurer des groupes de disponibilité AlwaysOn SQL Server.
Ce tutoriel utilise us-central1 comme région principale (appelée R1).
Avant de commencer, prenez connaissance des points suivants.
Tout d'abord, si vous suivez les étapes de la page Configurer des groupes de disponibilité AlwaysOn SQL Server, vous allez créer deux instances SQL Server dans la même zone (us-central1-f). Cette configuration ne vous protège pas en cas de défaillance de us-central1-f. Par conséquent, pour obtenir une haute disponibilité, vous allez déployer une instance SQL Server (cluster-sql1) dans us-central1-c et une deuxième instance (cluster-sql2) dans us-central1-f. Les étapes de la section suivante (sur l'ajout d'une instance secondaire pour la reprise après sinistre) supposent que vous disposez de cette configuration de déploiement.
Deuxièmement, les étapes de la page Configurer des groupes de disponibilité AlwaysOn SQL Server incluent l'exécution de l'instruction suivante :
BACKUP DATABASE TestDB to disk = '\\cluster-sql2\SQLBackup\TestDB.bak' WITH INIT
Cette instruction entraîne l'échec de l'instance de secours. Exécutez plutôt la commande suivante (le nom du fichier de sauvegarde est différent) :
BACKUP DATABASE TestDB to disk = '\\cluster-sql2\SQLBackup\TestDB-backup.bak' WITH INIT
Troisièmement, les étapes de la page Configurer des groupes de disponibilité AlwaysOn SQL Server entraînent la création de répertoires de sauvegarde. Vous n'utiliserez ces sauvegardes que lors de la synchronisation initiale de l'instance principale et de l'instance de secours. Elles ne vous serviront plus par la suite. Une autre approche pour créer des répertoires de sauvegarde consiste à choisir l'option Automatic seeding (Amorçage automatique) dans ces étapes. Cette approche simplifie le processus de configuration.
Quatrièmement, si les bases de données ne se synchronisent pas, exécutez la commande suivante dans cluster-sql2 :
ALTER DATABASE [TestDB] SET HADR AVAILABILITY GROUP = [cluster-ag]
Enfin, dans ce tutoriel, vous allez créer un contrôleur de domaine dans us-central1-f, comme le montre le schéma suivant.

Figure 4. Architecture standard de reprise après sinistre mise en œuvre dans ce tutoriel.
Bien que vous mettiez en œuvre l'architecture précédente pour ce tutoriel, il est recommandé de configurer un contrôleur de domaine dans plusieurs zones. Cette approche vous permet d'établir une architecture de base de données à haute disponibilité et compatible avec la reprise après sinistre. Par exemple, si une interruption se produit dans une zone, cette zone ne devient pas un point de défaillance unique pour votre architecture déployée.
Ajouter une instance secondaire pour la reprise après sinistre
Vous allez ensuite configurer une troisième instance SQL Server (une instance secondaire nommée cluster-sql3), ainsi que sa mise en réseau :
Dans Cloud Shell, sous le cloud privé virtuel (VPC) que vous avez utilisé pour la région principale, créez un sous-réseau dans la région secondaire (
us-east1) :gcloud compute networks subnets create wsfcsubnet4 --network wsfcnet \ --region us-east1 --range 10.3.0.0/24Modifiez la règle de pare-feu appelée
allow-internal-portspour autoriser le nouveau sous-réseau à recevoir du trafic :gcloud compute firewall-rules update allow-internal-ports \ --source-ranges 10.0.0.0/24,10.1.0.0/24,10.2.0.0/24,10.3.0.0/24La règle
allow-internal-portsest incluse dans les étapes des instructions que vous avez suivies précédemment.Créez une instance SQL Server :
gcloud compute instances create cluster-sql3 --machine-type n1-highmem-4 \ --boot-disk-type pd-ssd --boot-disk-size 200GB \ --image-project windows-sql-cloud --image-family sql-ent-2016-win-2016 \ --zone us-east1-b \ --network-interface "subnet=wsfcsubnet4,private-network-ip=10.3.0.4,aliases=10.3.0.5;10.3.0.6" \ --can-ip-forward --metadata sysprep-specialize-script-ps1="Install-WindowsFeature Failover-Clustering -IncludeManagementTools;"Définissez un mot de passe Windows pour la nouvelle instance SQL Server :
Dans la console Google Cloud, accédez à la page "Compute Engine".
Dans la colonne Connecter du cluster Compute Engine
cluster-sql3, sélectionnez la liste déroulante Définir un mot de passe Windows.Définissez le nom d'utilisateur et le mot de passe. Notez-les en vue d'une utilisation ultérieure.
Cliquez sur RDP pour vous connecter à l'instance
cluster-sql3.Saisissez le nom d'utilisateur et le mot de passe définis à l'étape 4, puis cliquez sur OK.
Ouvrez une fenêtre Windows PowerShell en tant qu'administrateur, puis configurez le DNS et les ports ouverts :
netsh interface ip set dns Ethernet static 10.2.0.100 netsh advfirewall firewall add rule name="Open Port 5022 for Availability Groups" dir=in action=allow protocol=TCP localport=5022 netsh advfirewall firewall add rule name="Open Port 1433 for SQL Server" dir=in action=allow protocol=TCP localport=1433Ajoutez l'instance au domaine Windows :
Add-Computer -DomainName "dbeng.com" -Credential "dbeng.com\Administrator" -Restart -ForceCette commande interrompt votre connexion RDP.
Ajouter l'instance secondaire au cluster de basculement
Vous allez maintenant ajouter l'instance secondaire (cluster-sql3) au cluster de basculement Windows :
Connectez-vous aux instances
cluster-sql1oucluster-sql2à l'aide de RDP, puis connectez-vous en tant qu'administrateur.Ouvrez une fenêtre PowerShell en tant qu'administrateur et définissez des variables pour l'environnement de cluster de ce tutoriel :
$node3 = "cluster-sql3" $nameWSFC = "cluster-dbclus" # Name of clusterAjoutez l'instance secondaire au cluster :
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3L'exécution de cette commande peut prendre un certain temps. Comme le processus peut cesser de répondre et ne pas reprendre automatiquement, appuyez occasionnellement sur
Enter.Dans le nœud, activez la fonctionnalité de haute disponibilité AlwaysOn :
Enable-SqlAlwaysOn -ServerInstance $node3 -ForceCréez deux dossiers aux chemins
C:\SQLDataetC:\SQLLogpour stocker les données de la base de données et les fichiers journaux :New-item -ItemType Directory "C:\SQLData" New-item -ItemType Directory "C:\SQLLog"
Le nœud est maintenant associé au cluster de basculement.
Ajouter l'instance secondaire au groupe de disponibilité existant
Vous allez ensuite ajouter l'instance SQL Server (l'instance secondaire) et la base de données au groupe de disponibilité :
Dans l'un des trois nœuds d'instance (
cluster-sql1,cluster-sql2oucluster-sql3), ouvrez Microsoft SQL Server Management Studio et connectez-vous à l'instance principale (cluster-sql1) :- Accédez à l'explorateur d'objets.
- Sélectionnez la liste déroulante Connect (Se connecter).
- Sélectionnez Moteur de base de données.
- Dans la liste déroulante Nom du serveur, sélectionnez
cluster-sql1. Si le cluster n'est pas répertorié, saisissez-le dans le champ.
Cliquez sur Nouvelle requête.
Collez la commande suivante pour ajouter une adresse IP à l'écouteur utilisé pour le nœud, puis cliquez sur Exécuter :
ALTER AVAILABILITY GROUP [cluster-ag] MODIFY LISTENER 'cluster-listene' (ADD IP ('10.3.0.6', '255.255.255.0'))Dans l'explorateur d'objets, développez le nœud AlwaysOn High Availability (Haute disponibilité AlwaysOn), puis le nœud Availability Groups (Groupes de disponibilité).
Effectuez un clic droit sur le groupe de disponibilité nommé
cluster-ag, puis sélectionnez Ajouter un réplica.Sur la page Introduction, cliquez sur le nœud AlwaysOn High Availability (Haute disponibilité AlwaysOn), puis sur le nœud Availability Groups (Groupes de disponibilité).
Sur la page Connect to Replicas (Se connecter à des réplicas), cliquez sur Connect (Se connecter) pour vous connecter à l'instance dupliquée secondaire
cluster-sql2.Sur la page Specify Replicas (Spécifier les réplicas), cliquez sur Ajouter un réplica, puis ajoutez le nœud
cluster-sql3. Ne sélectionnez pas l'option Basculement automatique, car cela entraîne un commit synchrone. Cette configuration dépasse les limites régionales, ce qui n'est pas recommandé.Sur la page Select Data Synchronization (Sélectionner la synchronisation des données), choisissez Automatic seeding (Amorçage automatique).
Comme il n'y a aucun écouteur, la page Validation génère un avertissement, que vous pouvez ignorer.
Suivez les instructions de l'assistant.
Le mode de basculement pour cluster-sql1 et cluster-sql2 est automatique, tandis qu'il est manuel pour cluster-sql3. Cette différence est l'une des manières de distinguer la haute disponibilité de la reprise après sinistre.
Le groupe de disponibilité est maintenant prêt. Vous avez configuré deux nœuds pour la haute disponibilité et un troisième pour la reprise après sinistre.
Simuler une reprise après sinistre
Dans cette section, vous allez tester l'architecture de reprise après sinistre de ce tutoriel et songer à des mises en œuvre facultatives de reprise après sinistre.
Simuler une interruption et exécuter un basculement de reprise après sinistre
Simulez une défaillance (interruption) dans la région principale :
Dans Microsoft SQL Server Management Studio sur
cluster-sql1, connectez-vous àcluster-sql1.Créez une table. Une fois que vous aurez ajouté des instances dupliquées lors de prochaines étapes, vous vous assurerez du fonctionnement de l'instance dupliquée en vérifiant que cette table est présente.
USE TestDB GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GODans Cloud Shell, arrêtez les deux serveurs de la région principale (
us-central1) :gcloud compute instances stop cluster-sql2 --zone us-central1-f --quiet gcloud compute instances stop cluster-sql1 --zone us-central1-c --quiet
Dans Microsoft SQL Server Management Studio sur
cluster-sql3, connectez-vous àcluster-sql3.Exécutez un basculement et définissez le mode de disponibilité sur le commit synchrone. Il est nécessaire de forcer un basculement, car le nœud est en mode de commit asynchrone.
ALTER AVAILABILITY GROUP [cluster-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOVous pouvez reprendre le traitement.
cluster-sql3est désormais l'instance principale.(Facultatif) Créez une table dans
cluster-sql3. Après avoir synchronisé les instances dupliquées avec la nouvelle instance principale, vous devez vérifier si cette table est répliquée dans les instances dupliquées.USE TestDB GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
Bien que cluster-sql3 soit l'instance principale à ce stade, vous souhaiterez peut-être revenir à la région d'origine, ou configurer une nouvelle instance secondaire et une nouvelle instance de secours pour recréer une architecture complète de reprise après sinistre. La section suivante aborde ces options.
(Facultatif) Recréer une architecture de reprise après sinistre qui réplique entièrement les transactions
Ce cas d'utilisation corrige une défaillance en répliquant toutes les transactions depuis la base de données principale vers la base de données secondaire, avant l'échec de la base de données principale. Dans ce scénario idéal, aucune donnée n'est perdue. L'état de la base de données secondaire est cohérent avec la base de données principale au point de défaillance.
Dans ce scénario, vous pouvez recréer une architecture complète de reprise après sinistre de deux manières :
- En revenant à l'instance principale et à l'instance de secours d'origine (si elles sont disponibles).
- En créant une instance de secours et une instance secondaire pour
cluster-sql3au cas où les instances principale et de secours d'origine ne seraient pas disponibles.
Méthode 1 : revenir à l'instance principale et à l'instance de secours d'origine
Dans Cloud Shell, démarrez l'instance principale et l'instance de secours d'origine (les anciennes instances) :
gcloud compute instances start cluster-sql1 --zone us-central1-c --quiet gcloud compute instances start cluster-sql2 --zone us-central1-f --quietDans Microsoft SQL Server Management Studio, ajoutez à nouveau
cluster-sql1etcluster-sql2en tant qu'instances dupliquées secondaires :Sur
cluster-sql3, ajoutez les deux serveurs en mode de commit asynchrone :USE [master] GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOSur
cluster-sql1, relancez la synchronisation des bases de données :USE [master] GO ALTER DATABASE [TestDB] SET HADR RESUME; GOSur
cluster-sql2, relancez la synchronisation des bases de données :USE [master] GO ALTER DATABASE [TestDB] SET HADR RESUME; GO
Définissez à nouveau
cluster-sql1en tant qu'instance principale :Sur
cluster-sql3, définissez le mode de disponibilité decluster-sql1sur le commit synchrone. L'instancecluster-sql1redevient l'instance principale.USE [master] GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOSur
cluster-sql1, définissezcluster-sql1en tant qu'instance principale et les deux autres nœuds en tant qu'instances secondaires :USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [cluster-ag] FAILOVER; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON 'CLUSTER-SQL3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
Une fois toutes les commandes exécutées, cluster-sql1 est l'instance principale et les autres nœuds sont des instances secondaires, comme le montre le schéma ci-dessous.

Méthode 2 : configurer une nouvelle instance principale et une nouvelle instance de secours
Il est possible que vous ne puissiez pas récupérer les instances principale et de secours d'origine à la suite de la défaillance, que leur récupération prenne trop de temps ou que la région soit inaccessible. Une approche consiste à conserver cluster-sql3 en tant qu'instance principale, puis à créer une instance de secours et une instance secondaire, comme le montre le schéma suivant.

Figure 5. Reprise après sinistre avec la région principale d'origine R1 indisponible.
Cette mise en œuvre nécessite que vous effectuiez les opérations suivantes :
Conservez
cluster-sql3en tant qu'instance principale dansus-east1.Ajoutez une instance de secours (
cluster-sql4) dans une zone différente deus-east1. Cette étape permet de rendre le nouveau déploiement hautement disponible.Créez une instance secondaire (
cluster-sql5) dans une région distincte, par exempleus-west2. Cette étape configure le nouveau déploiement pour la reprise après sinistre. Le déploiement général est maintenant terminé. L'architecture de base de données est entièrement compatible avec la haute disponibilité et la reprise après sinistre.
(Facultatif) Effectuer un repli lorsqu'il manque des transactions
Une défaillance va s'avérer particulièrement problématique lorsqu'une ou plusieurs transactions validées sur l'instance principale ne sont pas répliquées sur l'instance secondaire au point de défaillance (on parle alors de défaillance permanente). Lors d'un basculement, toutes les transactions validées qui ne sont pas répliquées sont perdues.
Pour tester les étapes de basculement pour ce scénario, vous devez générer une défaillance permanente. Voici la meilleure approche à suivre pour générer une défaillance permanente :
- Modifiez le réseau afin qu'il n'y ait aucune connectivité entre l'instance principale et l'instance secondaire.
- Apportez une modification à l'instance principale (par exemple, ajoutez une table ou insérez des données).
- Suivez le processus de basculement comme décrit précédemment pour que l'instance secondaire devienne la nouvelle instance principale.
Ici, les étapes du processus de basculement sont identiques à celles du scénario idéal, sauf que la table ajoutée à l'instance principale après l'interruption de la connectivité réseau n'est pas visible dans l'instance secondaire.
La seule option pour résoudre une défaillance permanente consiste à supprimer les instances dupliquées (cluster-sql1 et cluster-sql2) du groupe de disponibilité et à les resynchroniser. La synchronisation modifie leur état pour qu'elles correspondent à l'instance secondaire. Toute transaction n'ayant pas été répliquée avant la défaillance est perdue.
Pour ajouter cluster-sql1 en tant qu'instance secondaire, vous pouvez suivre les étapes qui vous ont précédemment permis d'ajouter cluster-sql3 (voir Ajouter l'instance secondaire au cluster de basculement), avec la différence suivante : cluster-sql3 est désormais l'instance principale, et non cluster-sql1. Vous devez remplacer toute occurrence de cluster-sql3 par le nom du serveur que vous ajoutez au groupe de disponibilité. Si vous réutilisez la même VM (cluster-sql1 et cluster-sql2), vous n'avez pas besoin d'ajouter le serveur au cluster de basculement Windows Server. Rajoutez simplement l'instance SQL Server au groupe de disponibilité.
À ce stade, cluster-sql3 est l'instance principale, et cluster-sql1 et cluster-sql2 sont des instances secondaires. Vous pouvez maintenant revenir à l'instance cluster-sql1, définir cluster-sql2 en tant qu'instance de secours et définir cluster-sql3 en tant qu'instance secondaire. Le système possède désormais le même état qu'avant avant la défaillance.
Basculement automatique
Le basculement automatique vers une instance secondaire en tant qu'instance principale peut créer des problèmes. Lorsque l'instance principale d'origine redevient disponible, une situation de split-brain peut se produire si certains clients accèdent à l'instance secondaire pendant que d'autres écrivent sur l'instance principale restaurée. Dans ce cas, l'instance principale et l'instance secondaire peuvent être mises à jour en parallèle, et leurs états divergent. Pour éviter cette situation, ce tutoriel fournit des instructions permettant de mettre en œuvre un basculement manuel, où vous décidez si (et quand) vous souhaitez effectuer un basculement.
Si vous mettez en œuvre un basculement automatique, vous devez vous assurer que seule l'une des instances configurées est l'instance principale et qu'elle peut être modifiée. Les instances de secours ou secondaires ne doivent pas fournir un accès en écriture aux clients (sauf l'instance principale pour la réplication de l'état). En outre, vous devez éviter les basculements rapides en chaîne sur une courte durée. Par exemple, un basculement toutes les cinq minutes ne permet pas d'obtenir une stratégie de reprise après sinistre fiable. Dans le cas des processus de basculement automatisés, vous pouvez développer des protections contre ce genre de scénarios problématiques, et même demander à un administrateur de base de données de prendre des décisions complexes, si nécessaire.
Architecture de déploiement alternative
Dans ce tutoriel, vous configurez une architecture de reprise après sinistre dans laquelle une instance secondaire devient l'instance principale lors d'un basculement, comme le montre le schéma suivant.

Figure 6. Architecture standard de reprise après sinistre avec Microsoft SQL Server.
Cela signifie qu'en cas de basculement, le déploiement obtenu ne dispose que d'une instance jusqu'à ce qu'un repli soit possible, ou jusqu'à ce que vous configuriez une instance de secours (pour la haute disponibilité) et une instance secondaire (pour la reprise après sinistre).
Une autre architecture de déploiement consiste à configurer deux instances secondaires, qui sont des instances dupliquées de l'instance principale. Si un basculement se produit, vous pouvez reconfigurer l'une des instances secondaires en tant qu'instance de secours. Les schémas suivants illustrent l'architecture de déploiement avant et après un basculement.

Figure 7. Architecture standard de reprise après sinistre avec deux instances secondaires.

Figure 8. Architecture standard de reprise après sinistre avec deux instances secondaires après le basculement.
Bien que vous deviez tout de même définir l'une des deux instances secondaires en tant qu'instance de secours (Figure 8), ce processus est beaucoup plus rapide que si vous deviez créer et configurer une instance de secours à partir de zéro.
Vous pouvez également aborder la reprise après sinistre avec une configuration semblable à cette architecture exploitant deux instances secondaires. En plus d'utiliser deux instances secondaires dans une deuxième région (Figure 7), vous pouvez déployer deux autres instances secondaires dans une troisième région. Cette configuration vous permet de créer efficacement une architecture de déploiement à haute disponibilité et compatible avec la reprise après sinistre après une défaillance de la région principale.
Nettoyer
Pour éviter que les ressources utilisées dans ce tutoriel soient facturées sur votre compte Google Cloud, procédez comme suit :
Supprimer le projet
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Étapes suivantes
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.