Ce document décrit plusieurs méthodes permettant d'utiliser la capture de données modifiées (CDC, Change Data Capture) pour intégrer diverses sources de données à BigQuery. Ce document fournit une analyse des compromis entre cohérence des données, facilité d'utilisation et coûts de chacune des approches. Il vous aidera à comprendre les solutions existantes, à découvrir différentes approches permettant d'utiliser les données répliquées par la CDC, et à créer une analyse de coûts des approches.
Ce document a pour objectif d'aider les architectes de données, les ingénieurs de données et les analystes commerciaux à développer une approche optimale pour accéder aux données répliquées dans BigQuery. Il suppose que vous maîtrisez BigQuery, SQL et les outils de ligne de commande.
Présentation de la réplication de données à l'aide de la CDC
Les bases de données, telles que MySQL, Oracle et SAP, sont les sources de données CDC les plus courantes. Cependant, n'importe quel système peut être considéré comme une source de données s'il enregistre et apporte des modifications aux éléments de données identifiés par des clés primaires. Si un système ne fournit pas de processus CDC intégré, tel qu'un journal des transactions, vous pouvez déployer un lecteur par lots incrémentiel afin d'obtenir les modifications.
Ce document traite des processus de CDC qui répondent aux critères suivants :
- La réplication de données capture séparément les modifications pour chaque table.
- Chaque table possède une clé primaire ou une clé primaire composite.
- Chaque événement CDC émis se voit attribuer un ID de modification qui augmente de façon linéaire, généralement une valeur numérique telle qu'un ID de transaction ou un horodatage.
- Chaque événement CDC contient l'état complet de la ligne qui a été modifiée.
Le schéma suivant illustre une architecture générique utilisant la CDC pour répliquer des sources de données vers BigQuery :
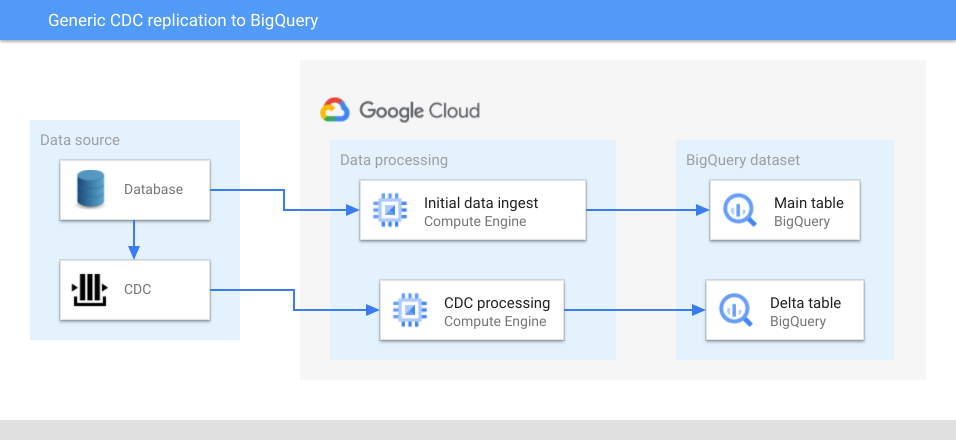
Dans le schéma ci-dessus, une table principale et une table delta sont créées dans BigQuery pour chaque table de données source. La table principale contient toutes les colonnes de la table source, ainsi qu'une colonne correspondant à la dernière valeur de l'ID de modification. Vous pouvez considérer le dernier ID de modification comme l'ID de version de l'entité identifiée par la clé primaire de l'enregistrement et l'utiliser pour rechercher la dernière version.
La table delta contient toutes les colonnes de la table source, ainsi qu'une colonne de type d'opération (mise à jour, insertion ou suppression) et la valeur de l'ID de modification.
Voici le processus global permettant de répliquer des données dans BigQuery à l'aide de la CDC :
- Un vidage des données initiales d'une table source est extrait.
- Les données extraites sont éventuellement transformées, puis chargées dans la table principale correspondante. Si la table ne comporte pas de colonne pouvant être utilisée comme ID de modification, telle qu'un horodatage mis à jour, l'ID de modification est défini sur la valeur la plus faible possible pour le type de données de cette colonne. Cela permet au traitement suivant d'identifier les enregistrements de table principaux mis à jour après le vidage initial des données.
- Les lignes qui changent après le vidage des données initiales sont capturées par le processus de capture CDC.
- Si nécessaire, la transformation de données supplémentaire est effectuée par la couche de traitement CDC. Par exemple, la couche de traitement CDC peut reformater l'horodatage à utiliser par BigQuery, scinder des colonnes verticalement ou supprimer des colonnes.
- Les données sont insérées dans la table delta correspondante dans BigQuery à l'aide de chargements de micro-lots ou d'insertions en flux continu.
Si des transformations supplémentaires sont effectuées avant que les données ne soient insérées dans BigQuery, le nombre et le type de colonnes peuvent différer de la table source. Cependant, le même ensemble de colonnes existe dans les tables principale et delta.
Les tables delta contiennent tous les événements de modification correspondant à une table particulière depuis le chargement initial. La disponibilité de tous les événements de modification peut s'avérer utile pour identifier des tendances, l'état des entités représentées par une table à un moment spécifique ou la fréquence de modification.
Pour obtenir l'état actuel d'une entité représentée par une clé primaire particulière, vous pouvez interroger la table principale et la table delta pour rechercher l'enregistrement comportant l'ID de modification le plus récent. Cette requête peut s'avérer coûteuse, car vous devrez peut-être effectuer une jointure entre la table principale et la table delta, puis effectuer une analyse complète de l'une des tables ou des deux pour trouver l'entrée la plus récente pour une clé primaire particulière. Vous pouvez éviter d'effectuer une analyse complète de la table en mettant en cluster ou en partitionnant les tables en fonction de la clé primaire, mais ce n'est pas toujours possible.
Ce document compare les approches génériques suivantes qui peuvent vous aider à obtenir l'état actuel d'une entité lorsque vous ne pouvez pas partitionner ou mettre en cluster les tables :
- Approche de cohérence immédiate : les requêtes reflètent l'état actuel des données répliquées. La cohérence immédiate nécessite une requête qui regroupe la table principale et la table delta, et sélectionne la ligne la plus récente pour chaque clé primaire.
- Approche économique : les requêtes plus rapides et moins coûteuses sont exécutées au détriment d'un délai de disponibilité des données. Vous pouvez fusionner périodiquement les données dans la table principale.
- Approche hybride : vous utilisez l'approche de cohérence immédiate ou l'approche économique, en fonction de vos exigences et de votre budget.
Ce document décrit d'autres façons d'améliorer les performances en plus de ces approches.
Avant de commencer
Ce document explique comment utiliser l'outil de ligne de commande bq et les instructions SQL pour afficher et interroger des données BigQuery. Des exemples de mise en page et de requêtes de table sont présentés plus loin dans ce document. Si vous souhaitez tester des exemples de données, procédez comme suit :
- Sélectionnez un projet, ou créez un projet et activez la facturation pour le projet.
- Si vous créez un projet, BigQuery est automatiquement activé.
- Si vous sélectionnez un projet existant, activez l'API BigQuery.
- Dans Google Cloud Console, ouvrez Cloud Shell.
Pour mettre à jour votre fichier de configuration BigQuery, ouvrez le fichier
~/.bigqueryrcdans un éditeur de texte, puis ajoutez ou mettez à jour les lignes suivantes n'importe où dans le fichier :[query] --use_legacy_sql=false [mk] --use_legacy_sql=falseClonez le dépôt GitHub contenant les scripts permettant de configurer l'environnement BigQuery :
git clone https://github.com/GoogleCloudPlatform/bq-mirroring-cdc.gitCréez l'ensemble de données, ainsi que les tables principales et delta :
cd bq-mirroring-cdc/tutorial chmod +x *.sh ./create-tables.sh
Pour éviter des frais potentiels lorsque vous avez terminé vos tests, arrêtez le projet ou supprimez l'ensemble de données.
Configurer des données BigQuery
Pour illustrer différentes solutions pour la réplication de données à l'aide de la CDC vers BigQuery, vous utilisez une paire de tables principale et delta remplies avec des exemples de données tels que les exemples de tables simples suivants.
Pour mettre en œuvre une configuration plus sophistiquée que celle décrite dans ce document, vous pouvez utiliser la démonstration de l'intégration BigQuery pour CDC. La démonstration automatise le processus de remplissage des tables et inclut des scripts permettant de surveiller le processus de réplication. Si vous souhaitez exécuter la démonstration, suivez les instructions du fichier README situé à la racine du dépôt GitHub que vous avez cloné dans la section Avant de commencer de ce document.
L'exemple de données utilise un modèle de données simple : une session Web contenant un ID de session généré par le système requis et un nom d'utilisateur facultatif. Lorsque la session démarre, le nom d'utilisateur est nul. Une fois l'utilisateur connecté, le nom d'utilisateur est renseigné.
Pour charger des données dans la table principale à partir des scripts d'environnement BigQuery, vous pouvez exécuter une commande semblable à celle-ci :
bq load cdc_tutorial.session_main init.csv
Pour obtenir le contenu principal de la table, vous pouvez exécuter une requête de ce type :
bq query "select * from cdc_tutorial.session_main limit 1000"
La sortie ressemble à ceci :
+-----+----------+-----------+ | id | username | change_id | +-----+----------+-----------+ | 100 | NULL | 1 | | 101 | Sam | 2 | | 102 | Jamie | 3 | +-----+----------+-----------+
Vous allez ensuite charger le premier lot de modifications CDC dans la table delta. Pour charger le premier lot de modifications CDC dans la table delta à partir des scripts d'environnement BigQuery, vous pouvez exécuter une commande semblable à celle-ci :
bq load cdc_tutorial.session_delta first-batch.csv
Pour obtenir le contenu d'une table delta, vous pouvez exécuter une requête de ce type :
bq query "select * from cdc_tutorial.session_delta limit 1000"
La sortie ressemble à ceci :
+-----+----------+-----------+-------------+ | id | username | change_id | change_type | +-----+----------+-----------+-------------+ | 100 | Cory | 4 | U | | 101 | Sam | 5 | D | | 103 | NULL | 6 | I | | 104 | Jamie | 7 | I | +-----+----------+-----------+-------------+
Dans le résultat précédent, la valeur change_id correspond à l'ID unique d'une modification de ligne de table. Les valeurs de la colonne change_type sont les suivantes :
U: opérations de mise à jourD: opérations de suppressionI: opérations d'insertion
La table principale contient des informations sur les sessions 100, 101 et 102. La table delta contient les modifications suivantes :
- La session 100 est mise à jour avec le nom d'utilisateur "Cory".
- La session 101 est supprimée.
- Les nouvelles sessions 103 et 104 sont créées.
L'état actuel des sessions dans le système source est le suivant :
+-----+----------+ | id | username | +-----+----------+ | 100 | Cory | | 102 | Jamie | | 103 | NULL | | 104 | Jamie | +-----+----------+
Bien que l'état actuel soit affiché sous forme de table, cette table n'existe pas sous forme matérialisée. Cette table est la combinaison de la table principale et de la table delta.
Interroger les données
Plusieurs méthodes permettent de déterminer l'état général des sessions. Les avantages et les inconvénients de chaque approche sont décrits dans les sections suivantes.
Approche de la cohérence immédiate
Si la cohérence immédiate des données est votre objectif principal et que les données sources changent fréquemment, vous pouvez utiliser une seule requête qui regroupe les tables principale et delta et sélectionne la ligne la plus récente (la ligne avec l'horodatage le plus récent ou la valeur la plus élevée).
Pour créer une vue BigQuery qui regroupe les tables principale et delta et identifie la ligne la plus récente, vous pouvez exécuter une commande d'outil bq de ce type :
bq mk --view \
"SELECT * EXCEPT(change_type, row_num)
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY id ORDER BY change_id DESC) AS row_num
FROM (
SELECT * EXCEPT(change_type), change_type
FROM \`$(gcloud config get-value project).cdc_tutorial.session_delta\` UNION ALL
SELECT *, 'I'
FROM \`$(gcloud config get-value project).cdc_tutorial.session_main\`))
WHERE
row_num = 1
AND change_type <> 'D'" \
cdc_tutorial.session_latest_v
L'instruction SQL de la vue BigQuery précédente effectue les opérations suivantes :
- La partie
UNION ALLla plus profonde produit les lignes des tables principale et delta :SELECT * EXCEPT(change_type), change_type FROM session_deltaforce la colonnechange_typeà être la dernière colonne de la liste.SELECT *, 'I' FROM session_mainsélectionne la ligne dans la table principale comme s'il s'agissait d'une ligne d'insertion.- L'utilisation de l'opérateur
*permet de simplifier l'exemple. S'il existe des colonnes supplémentaires ou un ordre de colonne différent, remplacez le raccourci par des listes de colonnes explicites.
SELECT *, ROW_NUMBER() OVER (PARTITION BY id ORDER BY change_id DESC) AS row_numutilise une fonction de fenêtrage dans BigQuery pour attribuer des numéros de ligne séquentiels commençant par 1 à chacun des groupes de ligne qui comportent la même valeurid, définie parPARTITION BY. Les lignes sont ordonnées parchange_iddans l'ordre décroissant dans ce groupe. Parce qu'il est certain quechange_idva augmenter, la dernière modification comporte une colonnerow_numayant la valeur 1.WHERE row_num = 1 AND change_type <> 'D'ne sélectionne que la dernière ligne de chaque groupe. Il s'agit d'une technique de déduplication courante dans BigQuery. Cette clause supprime également la ligne du résultat si son type de modification est supprimé.- La valeur en tête de liste
SELECT * EXCEPT(change_type, row_num)supprime les colonnes supplémentaires ajoutées pour le traitement et qui ne sont pas pertinentes.
L'exemple précédent n'utilise pas les types de modification d'insertion et de mise à jour dans la vue, car le fait de référencer la valeur change_id la plus élevée sélectionne l'insertion d'origine ou la dernière mise à jour. Dans ce cas, chaque ligne contient l'intégralité des données pour toutes les colonnes.
Une fois la vue créée, vous pouvez exécuter des requêtes sur celle-ci. Pour obtenir les modifications les plus récentes, vous pouvez exécuter une requête semblable à la suivante :
bq query 'select * from cdc_tutorial.session_latest_v order by id limit 10'
La sortie ressemble à ceci :
+-----+----------+-----------+ | id | username | change_id | +-----+----------+-----------+ | 100 | Cory | 4 | | 102 | Jamie | 3 | | 103 | NULL | 6 | | 104 | Jamie | 7 | +-----+----------+-----------+
Lorsque vous interrogez la vue, les données de la table delta sont immédiatement visibles si vous avez mis à jour les données dans la table delta à l'aide d'une instruction LMD (langage de manipulation de données), ou presque immédiatement si vous avez diffusé des données.
Approche d'optimisation des coûts
L'approche de cohérence immédiate est simple, mais elle peut s'avérer inefficace, car elle nécessite que BigQuery lise tous les enregistrements historiques, les trie par clé primaire et traite les autres opérations de la requête pour mettre en œuvre la vue. Si vous interrogez fréquemment l'état de la session, l'approche de cohérence immédiate peut réduire les performances et augmenter les coûts de stockage et de traitement des données dans BigQuery.
Pour réduire les coûts, vous pouvez fusionner les modifications de la table delta dans la table principale et supprimer définitivement les lignes fusionnées de la table delta à certaines périodes. La fusion et la suppression définitive entraînent des coûts supplémentaires. Cependant, si vous interrogez fréquemment la table principale, les coûts sont négligeables par rapport au coût de la recherche en continu du dernier enregistrement d'une clé dans la table delta.
Pour fusionner les données de la table delta vers la table principale, vous pouvez exécuter une instruction MERGE semblable à celle-ci :
bq query \
'MERGE `cdc_tutorial.session_main` m
USING
(
SELECT * EXCEPT(row_num)
FROM (
SELECT *, ROW_NUMBER() OVER(PARTITION BY delta.id ORDER BY delta.change_id DESC) AS row_num
FROM `cdc_tutorial.session_delta` delta )
WHERE row_num = 1) d
ON m.id = d.id
WHEN NOT MATCHED
AND change_type IN ("I", "U") THEN
INSERT (id, username, change_id)
VALUES (d.id, d.username, d.change_id)
WHEN MATCHED
AND d.change_type = "D" THEN
DELETE
WHEN MATCHED
AND d.change_type = "U"
AND (m.change_id < d.change_id) THEN
UPDATE
SET username = d.username, change_id = d.change_id'
L'instruction MERGE précédente a affecté quatre lignes, et la table principale indique l'état actuel des sessions. Pour interroger la table principale dans cette vue, vous pouvez exécuter une requête de ce type :
bq query 'select * from cdc_tutorial.session_main order by id limit 10'
Le résultat se présente comme suit :
+-----+----------+-----------+ | id | username | change_id | +-----+----------+-----------+ | 100 | Cory | 4 | | 102 | Jamie | 3 | | 103 | NULL | 6 | | 104 | Jamie | 7 | +-----+----------+-----------+
Les données de la table principale reflètent les états des dernières sessions.
La meilleure façon de fusionner des données fréquemment et de manière cohérente est d'utiliser une instruction MERGE, qui vous permet de combiner plusieurs instructions INSERT, UPDATE et DELETE en une seule opération atomique. Voici certaines de nuances de l'instruction MERGE précédente :
- La table
session_mainest fusionnée avec la source de données spécifiée dans la clauseUSING, qui est dans le cas présent une sous-requête. - La sous-requête utilise la même technique que celle de la vue dans l'approche de cohérence immédiate : elle sélectionne la dernière ligne du groupe d'enregistrements possédant la même valeur
id; une combinaison deROW_NUMBER() OVER(PARTITION BY id ORDER BY change_id DESC) row_numetWHERE row_num = 1. - La fusion est effectuée sur les colonnes
iddes deux tables, qui est la clé primaire. - La clause
WHEN NOT MATCHEDrecherche une correspondance. En l'absence de correspondance, la requête vérifie que le dernier enregistrement est inséré ou mis à jour, puis insère l'enregistrement.- Lorsque l'enregistrement est mis en correspondance et que le type de modification est la suppression, l'enregistrement est supprimé dans la table principale.
- Lorsque l'enregistrement est mis en correspondance, que le type de modification est la mise à jour et que la valeur
change_idde la table delta est supérieure à la valeurchange_idde l'enregistrement principal, les données sont mises à jour, y compris la valeurchange_idla plus récente.
L'instruction MERGE précédente fonctionne correctement pour toutes les combinaisons des modifications suivantes :
- Plusieurs lignes de mise à jour pour la même clé primaire : seule la dernière mise à jour s'applique.
Mises à jour sans correspondance dans la table principale : si la table principale ne comporte pas l'enregistrement sous la clé primaire, un nouvel enregistrement est inséré.
Cette approche ignore l'extraction de la table principale et commence avec la table delta. La table principale est automatiquement renseignée.
Insérez et mettez à jour des lignes dans le lot delta non traité. La ligne de mise à jour la plus récente est utilisée et un nouvel enregistrement est inséré dans la table principale.
Insérez et supprimez des lignes dans le lot non traité. L'enregistrement n'est pas inséré.
L'instruction MERGE précédente est idempotente : l'exécuter plusieurs fois génère le même état de la table principale et n'entraîne aucun effet secondaire.
Si vous exécutez à nouveau l'instruction MERGE sans ajouter de lignes à la table delta, le résultat ressemble à ceci :
Number of affected rows: 0
Vous pouvez exécuter l'instruction MERGE sur un intervalle régulier pour actualiser la table principale après chaque fusion. L'actualisation des données dans la table principale dépend de la fréquence des fusions. Pour en savoir plus sur l'exécution automatique de l'instruction MERGE, consultez la section "Planifier des fusions" du fichier de démonstration README que vous avez téléchargé précédemment.
Approche hybride
L'approche de cohérence immédiate et l'approche économique ne sont pas forcément exclusives. Si vous exécutez des requêtes sur la vue session_latest_v et sur la table session_main, elles renvoient les mêmes résultats. Vous pouvez choisir l'approche à utiliser en fonction de vos besoins et de votre budget : coûts plus élevés et cohérence immédiate ou coût moindre, mais données potentiellement non actualisées. Les sections suivantes expliquent comment comparer des approches et des alternatives potentielles.
Comparer les approches
Cette section explique comment comparer les approches en prenant en compte le coût et les performances de chaque solution, et l'équilibre entre latence des données acceptable et coût d'exécution des fusions.
Coût des requêtes
Pour évaluer le coût et les performances de chaque solution, l'exemple suivant fournit une analyse d'environ 500 000 sessions générées par la démonstration de l'intégration CDC pour BigQuery. Le modèle de session dans la démonstration est un peu plus complexe que celui qui a été introduit plus tôt dans ce document. De plus, il est déployé dans un ensemble de données différent, mais les concepts sont identiques.
Vous pouvez comparer le coût des requêtes en utilisant une simple requête d'agrégation. L'exemple de requête suivant teste l'approche de cohérence immédiate sur la vue qui combine les données delta avec la table principale :
SELECT status, count(*) FROM `cdc_demo.session_latest_v`
GROUP BY status ORDER BY status
La requête génère le coût suivant :
Slot time consumed: 15.115 sec, Bytes shuffled 80.66 MB
L'exemple de requête suivant teste l'approche économique sur la table principale :
SELECT status, count(*) FROM `cdc_demo.session_main`
GROUP BY status ORDER BY status
La requête génère le coût réduit suivant :
Slot time consumed: 1.118 sec, Bytes shuffled 609 B
L'utilisation des emplacements peut varier lorsque vous exécutez les mêmes requêtes plusieurs fois, mais les moyennes sont assez cohérentes. La valeur Bytes shuffled est cohérente entre les différentes exécutions.
Les résultats des tests de performances varient en fonction des types de requêtes et de la structure de la table. La démonstration précédente n'utilise ni la mise en cluster ni le partition des données.
Latence des données
Lorsque vous utilisez l'approche économique, la latence des données est la somme des éléments suivants :
- Le délai de déclenchement de la réplication des données. Il s'agit de la durée s'écoulant entre le moment où les données sont conservées lors de l'événement source et celui où le système de réplication déclenche le processus de réplication.
- Le temps d'insertion des données dans BigQuery (varie selon la solution de réplication).
- Le délai d'affichage des données de la mémoire tampon du streaming BigQuery dans la table delta. Si vous utilisez des insertions en flux continu, cette opération dure généralement quelques secondes.
- Le délai entre les exécutions de fusion.
- Le temps d'exécution de la fusion.
Lorsque vous utilisez l'approche de cohérence immédiate, la latence des données correspond à la somme des éléments suivants :
- Le délai de déclenchement de la réplication des données.
- Le temps d'insertion des données dans BigQuery.
- Le délai d'affichage des données de la mémoire tampon du streaming BigQuery dans la table delta.
Vous pouvez configurer le délai entre les exécutions de fusion en fonction du compromis entre les coûts d'exécution des fusions et la nécessité de rendre les données plus cohérentes. Si nécessaire, vous pouvez utiliser un schéma plus complexe, tel que des fusions fréquentes effectuées pendant les heures d'ouverture et des fusions horaires pendant les heures creuses.
Alternatives à prendre en compte
L'approche de cohérence immédiate et l'approche économique sont les options de CDC les plus génériques pour intégrer diverses sources de données à BigQuery. Cette section décrit des options d'intégration de données plus simples et moins coûteuses.
Tableau delta en tant que source unique de vérité
Si la table delta contient l'historique complet des modifications, vous pouvez créer une vue avec cette table, sans utiliser la table principale. L'utilisation d'une table delta comme source unique de vérité est un exemple de base de données d'événements. Cette approche permet une cohérence immédiate à faible coût avec une faible perte de performances. Adoptez cette approche si vous disposez d'une table de dimension en évolution très lente comportant un nombre réduit d'enregistrements.
Vidage complet des données sans la CDC
Si vous disposez de tables de taille raisonnable (par exemple, de moins de 1 Go), il peut s'avérer plus simple d'effectuer un vidage complet des données dans la séquence suivante :
- Importez le vidage des données initiales dans une table portant un nom unique.
- Créez une vue qui ne fait référence qu'à la nouvelle table.
- Exécutez des requêtes sur la vue, et non sur la table sous-jacente.
- Importez le prochain vidage de données dans une autre table.
- Recréez la vue pour qu'elle pointe vers les données récemment importées.
- Vous pouvez également supprimer la table d'origine.
- Répétez les étapes précédentes pour effectuer régulièrement l'importation, la recréation et la suppression.
Conserver l'historique des modifications dans la table principale
Dans l'approche économique, l'historique des modifications n'est pas conservé et la dernière modification écrase les données précédentes. Si vous devez conserver un historique, vous pouvez le stocker à l'aide d'un tableau de modifications, en veillant à ne pas dépasser la limite de taille de ligne maximale. Lorsque vous conservez l'historique des modifications dans la table principale, le LMD est plus complexe, car une seule opération MERGE peut fusionner plusieurs lignes de la table delta en une seule ligne de la table principale.
Utiliser des sources de données fédérées
Dans certains cas, vous pouvez répliquer une source de données autre que BigQuery, puis exposer cette source de données à l'aide d'une requête fédérée. BigQuery accepte un certain nombre de sources de données externes. Par exemple, si vous répliquez un schéma de type "étoile" à partir d'une base de données MySQL, vous pouvez répliquer les dimensions à évolution lente dans une version MySQL en lecture seule à l'aide de la réplication MySQL native. Lorsque vous utilisez cette méthode, vous ne répliquez que la table des données fréquemment modifiées dans BigQuery. Si vous souhaitez utiliser des sources de données fédérées, sachez qu'il existe plusieurs limites pour les interroger.
Améliorer davantage les performances
Cette section explique comment améliorer davantage les performances en mettant en cluster et en partitionnant vos tables, puis en supprimant définitivement les données fusionnées.
Mettre en cluster et partitionner des tables BigQuery
Si vous disposez d'un ensemble de données fréquemment interrogé, analysez l'utilisation de chaque table et ajustez la conception de la table à l'aide de la mise en cluster et du partitionnement. La mise en cluster de la table principale ou delta, ou des deux tables par clé primaire peut offrir de meilleures performances par rapport aux autres approches. Pour vérifier les performances, testez les requêtes sur un ensemble de données d'au moins 10 Go.
Supprimer définitivement les données fusionnées
La table delta s'agrandit au fil du temps et chaque requête de fusion perd des ressources en lisant un certain nombre de lignes dont vous n'avez pas besoin dans le résultat final. Si vous n'utilisez que les données de la table delta pour calculer le dernier état, la suppression des enregistrements fusionnés peut réduire le coût de la fusion et réduire votre coût global en réduisant la quantité de données stockées dans BigQuery.
Vous pouvez supprimer définitivement les données fusionnées avec l'une des méthodes suivantes :
- Interrogez régulièrement la table principale pour obtenir la valeur
change_idmaximale et supprimez tous les enregistrements delta dont la valeurchange_idest inférieure à cette valeur maximale. Si vous gérez des insertions en flux continu dans la table delta, celles-ci peuvent ne pas être supprimées pendant un certain temps. - Utilisez le partitionnement basé sur l'ingestion des tables delta et exécutez un script quotidien pour supprimer les partitions déjà traitées. Lorsque le partitionnement BigQuery plus précis devient disponible, vous pouvez augmenter la fréquence de suppression définitive. Pour en savoir plus sur la mise en œuvre, consultez la section "Purger les données traitées" du fichier de démonstration
READMEque vous avez téléchargé précédemment.
Conclusions
Pour choisir la bonne approche (ou plusieurs approches), tenez compte des cas d'utilisation que vous tentez de résoudre. Vous pourrez peut-être résoudre vos besoins de réplication des données à l'aide des technologies de migration de bases de données existantes. Si vous avez des besoins complexes (par exemple, si vous devez résoudre un cas d'utilisation de données en temps quasi réel et optimiser le coût du reste du modèle d'accès aux données), vous devrez peut-être configurer une fréquence de migration de la base de données personnalisée basée sur d'autres produits ou solutions Open Source. Les approches et les techniques décrites dans ce document peuvent vous aider à mettre en œuvre une telle solution.
Étapes suivantes
- Consultez la page Migrer des pipelines de données.
- Découvrez comment concevoir une architecture ETL pour un entrepôt de données cloud natif sur Google Cloud et effectuer des opérations ETL à partir d'une base de données relationnelle dans BigQuery à l'aide de Dataflow.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.