En esta explicación, se muestra cómo procesar de manera previa un modelo de aprendizaje automático, entrenarlo y hacer predicciones con él mediante Apache Beam, Google Dataflow y TensorFlow.
Para demostrar estos conceptos, esta guía usa el ejemplo de código de Moléculas. Dados los datos moleculares como entrada, el ejemplo de código de Moléculas crea y entrena un modelo de aprendizaje automático para predecir la energía molecular.
Costos
En esta explicación, es posible que se usen componentes facturables de Google Cloud, incluidos uno o más de los siguientes elementos:
- Dataflow
- Cloud Storage
- AI Platform
Usa la calculadora de precios para generar una estimación de los costos según el uso previsto.
Descripción general
El ejemplo de código de Moléculas extrae archivos que contienen datos moleculares y cuenta el número de átomos de carbono, hidrógeno, oxígeno y nitrógeno que hay en cada molécula. Luego, el código normaliza los conteos a valores entre 0 y 1, y los envía a un estimador de red neuronal profunda de TensorFlow. El estimador de red neuronal entrena un modelo de aprendizaje automático para predecir la energía molecular.
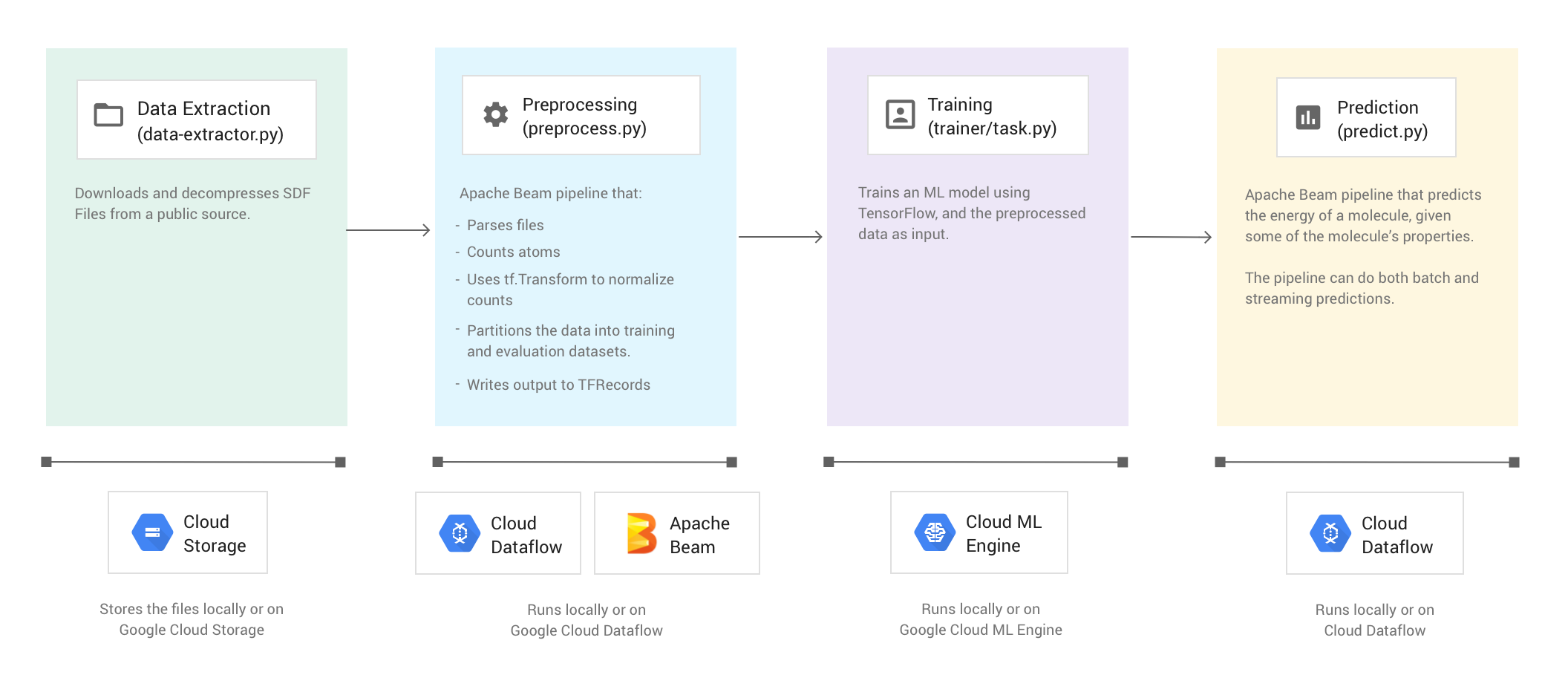
La muestra de código consta de cuatro fases:
- Extracción de datos (
data-extractor.py) - Procesamiento previo (
preprocess.py) - Entrenamiento (
trainer/task.py) - Predicción (
predict.py)
En las siguientes secciones, se explican las cuatro fases, pero esta explicación se enfoca más en las fases que usan Apache Beam y Dataflow: la de procesamiento previo y la de predicción. La fase de procesamiento previo también usa la biblioteca de Transformaciones de TensorFlow (comúnmente conocida como tf.Transform).
En la siguiente imagen, se muestra el flujo de trabajo del ejemplo de código de Moléculas.
Ejecuta la muestra de código
Para configurar tu entorno, sigue las instrucciones en README del repositorio de Moléculas en GitHub. A continuación, ejecuta el ejemplo de código de Moléculas con una de las la secuencias de comandos wrapper proporcionadas, run-local o run-cloud. Estas secuencias de comandos ejecutan de forma automática las cuatro fases del ejemplo de código (extracción, procesamiento previo, entrenamiento y predicción).
Como alternativa, puedes ejecutar cada fase de forma manual con los comandos provistos en las secciones de este documento.
Ejecuta de forma local
Para ejecutar el ejemplo de código de Moléculas localmente, ejecuta la secuencia de comandos wrapper run-local :
./run-local
Los registros de resultados te muestran cuándo la secuencia de comandos ejecuta cada una de las cuatro fases (extracción de datos, procesamiento previo, entrenamiento y predicción).
La secuencia de comandos data-extractor.py tiene un argumento obligatorio para el número de archivos.
Para facilitar su uso, la secuencia de comandos run-local y las secuencias de comando run-cloud tienen un valor predeterminado de 5 archivos para este argumento. Cada archivo contiene 25,000 moléculas. La ejecución del ejemplo de código toma alrededor de 3 a 7 minutos de principio a fin. La duración de la ejecución varía según la CPU de tu computadora.
Ejecuta en Google Cloud
Para ejecutar la muestra de código de moléculas en Google Cloud, ejecuta la secuencia de comandos del wrapper run-cloud. Todos los archivos de entrada deben estar en Cloud Storage.
Configura el parámetro --work-dir en el depósito de Cloud Storage:
./run-cloud --work-dir gs://<your-bucket-name>/cloudml-samples/molecules
Fase 1: extracción de datos
Código fuente: data-extractor.py
El primer paso es extraer los datos de entrada. El archivo data-extractor.py extrae y descomprime los archivos SDF especificados. En pasos posteriores, el ejemplo procesa de forma previa estos archivos y usa los datos para entrenar y evaluar el modelo de aprendizaje automático. El archivo extrae los archivos SDF de la fuente pública y los almacena en un subdirectorio dentro del directorio de trabajo especificado. El directorio de trabajo predeterminado (--work-dir) es /tmp/cloudml-samples/molecules.
Almacena los archivos extraídos
Almacena los archivos de datos extraídos de forma local:
python data-extractor.py --max-data-files 5
O bien, almacénalos en una ubicación de Cloud Storage:
WORK_DIR=gs://<your bucket name>/cloudml-samples/molecules
python data-extractor.py --work-dir $WORK_DIR --max-data-files 5
Fase 2: procesamiento previo
Código fuente: preprocess.py
El ejemplo de código de Moléculas usa una canalización de Apache Beam para procesar de forma previa los datos. La canalización realiza las siguientes acciones de procesamiento previo:
- Lee y analiza los archivos SDF extraídos.
- Cuenta el número de átomos diferentes en cada una de las moléculas en los archivos.
- Normaliza los conteos a valores entre 0 y 1 mediante
tf.Transform. - Divide al conjunto de datos en uno de entrenamiento y uno de evaluación.
- Escribe los dos conjuntos de datos como objetos
TFRecord.
Las transformaciones de Apache Beam pueden manipular de manera eficiente elementos individuales a la vez, pero las transformaciones que requieren un pase completo del conjunto de datos no se pueden realizar con facilidad solo mediante Apache Beam, por lo que es mejor usar tf.Transform. Debido a esto, el código usa las transformaciones de Apache Beam a fin de leer las moléculas, darles formato y contar los átomos en cada una. Luego, el código usa tf.Transform a fin de encontrar los conteos globales mínimos y máximos para normalizar los datos.
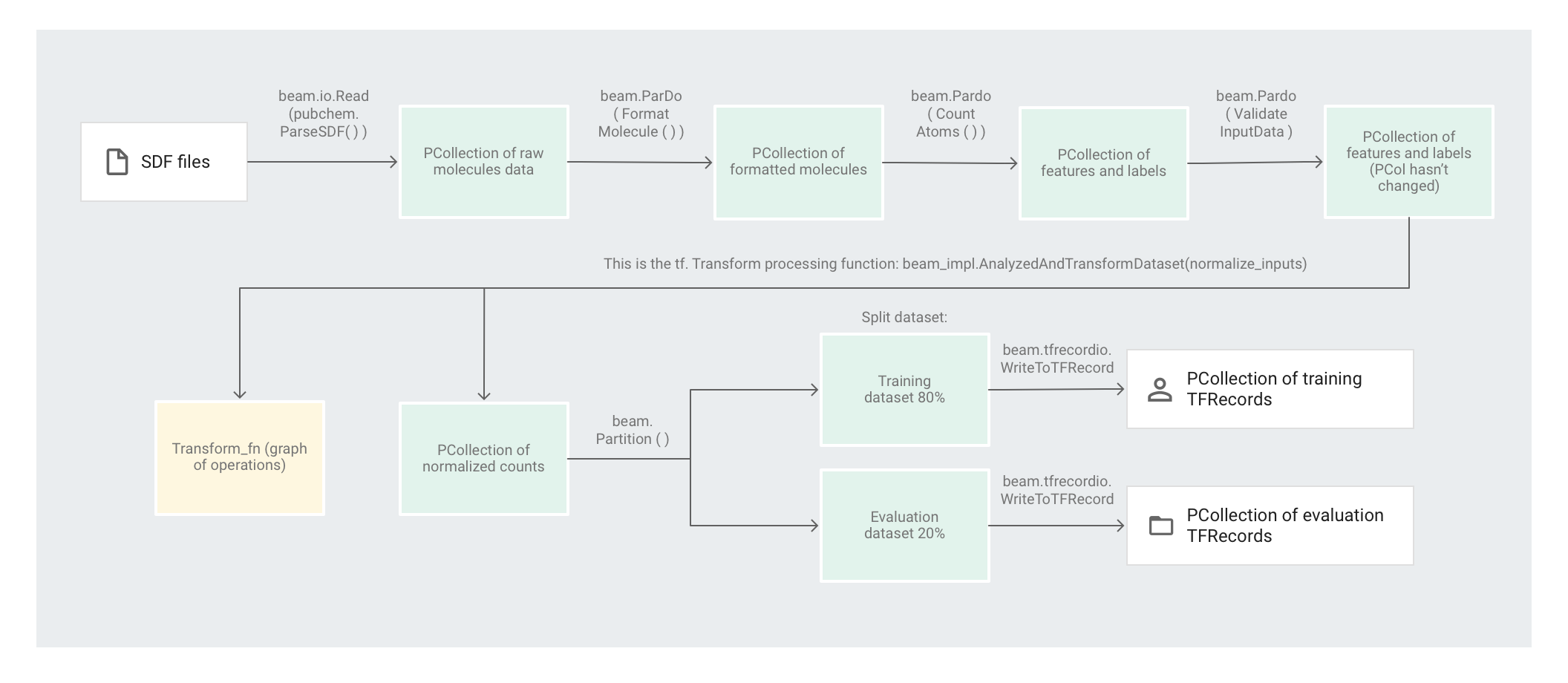
En la siguiente imagen, se muestran los pasos en la canalización.
Aplica transformaciones basadas en elementos
El código preprocess.py crea una canalización de Apache Beam.
A continuación, el código aplica una transformación feature_extraction a la canalización.
La canalización utiliza SimpleFeatureExtraction como su transformación feature_extraction.
La transformación SimpleFeatureExtraction, definida en pubchem/pipeline.py, contiene una serie de transformaciones que manipulan todos los elementos de forma independiente.
Primero, el código analiza las moléculas del archivo fuente, luego les da formato en un diccionario de propiedades moleculares y, por último, cuenta los átomos en la molécula. Estos conteos son las características (entradas) para el modelo de aprendizaje automático.
La transformación de lectura beam.io.Read(pubchem.ParseSDF(data_files_pattern)) lee archivos SDF de una fuente personalizada.
La fuente personalizada, llamada ParseSDF, se define en pubchem/pipeline.py.
ParseSDF extiende FileBasedSource y, luego, implementa la función read_records que abre los archivos SDF extraídos.
Cuando ejecutas la muestra de código de moléculas en Google Cloud, múltiples trabajadores (VM) pueden leer los archivos a la vez. Para garantizar que no haya dos trabajadores que lean el mismo contenido en los archivos, cada archivo usa un range_tracker.
La canalización agrupa los datos sin procesar en secciones de información relevante necesaria para los siguientes pasos. Cada sección en el archivo SDF analizado se almacena en un diccionario (consulta pipeline/sdf.py), en el que las claves son los nombres de las secciones y los valores son el contenido de línea sin procesar de la sección correspondiente.
El código aplica beam.ParDo(FormatMolecule()) a la canalización. El ParDo aplica el DoFn llamado FormatMolecule a cada molécula. FormatMolecule produce un diccionario de moléculas con formato. El siguiente fragmento es un ejemplo de un elemento en la PCollection de salida:
{
'atoms': [
{
'atom_atom_mapping_number': 0,
'atom_stereo_parity': 0,
'atom_symbol': u'O',
'charge': 0,
'exact_change_flag': 0,
'h0_designator': 0,
'hydrogen_count': 0,
'inversion_retention': 0,
'mass_difference': 0,
'stereo_care_box': 0,
'valence': 0,
'x': -0.0782,
'y': -1.5651,
'z': 1.3894,
},
...
],
'bonds': [
{
'bond_stereo': 0,
'bond_topology': 0,
'bond_type': 1,
'first_atom_number': 1,
'reacting_center_status': 0,
'second_atom_number': 5,
},
...
],
'<PUBCHEM_COMPOUND_CID>': ['3\n'],
...
'<PUBCHEM_MMFF94_ENERGY>': ['19.4085\n'],
...
}
A continuación, el código aplica beam.ParDo(CountAtoms()) a la canalización. El DoFn CountAtoms suma la cantidad de átomos de carbono, hidrógeno, nitrógeno y oxígeno que tiene cada molécula. CountAtoms da como resultado una PCollection de características y etiquetas.
Aquí hay un ejemplo de un elemento en la PCollection de salida:
{
'ID': 3,
'TotalC': 7,
'TotalH': 8,
'TotalO': 4,
'TotalN': 0,
'Energy': 19.4085,
}
Luego, la canalización valida las entradas. ValidateInputData DoFn valida que cada elemento coincida con los metadatos que se indican en input_schema. Esta validación garantiza el cumplimiento de los datos en el formato correcto cuando se incorporan a TensorFlow.
Aplica transformaciones de pase completo
El ejemplo de código de Moléculas usa un Regresor de red neuronal profunda para hacer predicciones. La recomendación general es normalizar las entradas antes de incorporarlas al modelo de AA. La canalización usa tf.Transform para normalizar los conteos de cada átomo a valores entre 0 y 1. Para leer más sobre la normalización de entradas, consulta escalamiento de características.
Normalizar los valores requiere un pase completo a través del conjunto de datos que registre los valores mínimos y máximos. El código usa tf.Transform para recorrer todo el conjunto de datos y aplicar transformaciones de pase completo.
Para usar tf.Transform, el código debe proporcionar una función que contenga la lógica de la transformación que se realizará en el conjunto de datos. En preprocess.py, el código usa la transformación AnalyzeAndTransformDataset proporcionada por tf.Transform. Obtén más información sobre cómo usar tf.Transform.
En preprocess.py, la función feature_scaling utilizada es normalize_inputs, que se define en pubchem/pipeline.py. La función utiliza la tf.Transform scale_to_0_1 para normalizar los conteos a valores entre 0 y 1.
Es posible normalizar los datos de forma manual, pero, si el conjunto de datos es grande, es más rápido usar Dataflow. Usar Dataflow permite que la canalización se ejecute en múltiples trabajadores (VM) según sea necesario.
Particiona el conjunto de datos
A continuación, la canalización preprocess.py divide el conjunto de datos único en dos. Asigna alrededor del 80% de los datos como datos de entrenamiento y alrededor del 20% como datos de evaluación.
Escribe el resultado
Finalmente, la canalización preprocess.py escribe los dos conjuntos de datos (entrenamiento y evaluación) con la transformación WriteToTFRecord.
Ejecuta la canalización de procesamiento previo
Ejecuta la canalización de procesamiento previo de forma local:
python preprocess.py
O bien, ejecútala en Dataflow:
PROJECT=$(gcloud config get-value project)
WORK_DIR=gs://<your bucket name>/cloudml-samples/molecules
python preprocess.py \
--project $PROJECT \
--runner DataflowRunner \
--temp_location $WORK_DIR/beam-temp \
--setup_file ./setup.py \
--work-dir $WORK_DIR
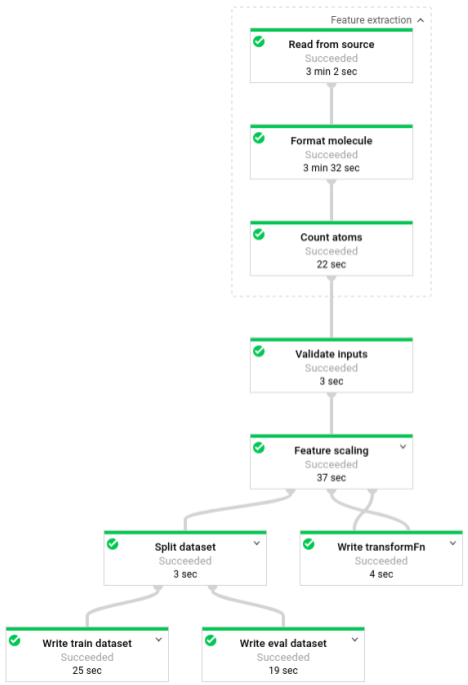
Una vez que se ejecuta la canalización, puedes ver su progreso en la interfaz de supervisión de Dataflow:
Fase 3: Entrenamiento
Código fuente: trainer/task.py
Recuerda que, al final de la fase de procesamiento previo, el código divide los datos en dos conjuntos de datos (entrenamiento y evaluación).
El ejemplo usa TensorFlow para entrenar el modelo de aprendizaje automático. El archivo trainer/task.py en el ejemplo de código de Moléculas contiene el código para entrenar el modelo. La función principal de trainer/task.py carga los datos que se procesaron en la fase de procesamiento previo.
El estimador usa el conjunto de datos de entrenamiento para entrenar el modelo y, luego, usa el conjunto de datos de evaluación a fin de verificar que el modelo predice con precisión la energía molecular dadas algunas de las propiedades de la molécula.
Obtén más información sobre el entrenamiento de un modelo de AA.
Entrena el modelo
Entrena el modelo de forma local:
python trainer/task.py
# To get the path of the trained model
EXPORT_DIR=/tmp/cloudml-samples/molecules/model/export/final
MODEL_DIR=$(ls -d -1 $EXPORT_DIR/* | sort -r | head -n 1)
O bien, entrena el modelo en AI Platform:
- Primero, selecciona una región compatible para ejecutar el trabajo de entrenamiento.
gcloud config set compute/region $REGION
- Inicia el trabajo de entrenamiento
JOB="cloudml_samples_molecules_$(date +%Y%m%d_%H%M%S)"
BUCKET=gs://<your bucket name>
WORK_DIR=$BUCKET/cloudml-samples/molecules
gcloud ai-platform jobs submit training $JOB \
--module-name trainer.task \
--package-path trainer \
--staging-bucket $BUCKET \
--runtime-version 1.13 \
--stream-logs \
-- \
--work-dir $WORK_DIR
# To get the path of the trained model:
EXPORT_DIR=$WORK_DIR/model/export
MODEL_DIR=$(gsutil ls -d $EXPORT_DIR/* | sort -r | head -n 1)
Fase 4: predicción
Código fuente: predict.py
Después de que el estimador entrena el modelo, puedes proporcionarle entradas para que haga predicciones. En el ejemplo de código de Moléculas, la canalización en predict.py es responsable de hacer predicciones. La canalización puede actuar como una canalización por lotes o una de transmisión.
El código de la canalización es el mismo en ambos casos, a excepción de las interacciones de fuente y receptor. Si la canalización se ejecuta en modo por lotes, lee los archivos de entrada de la fuente personalizada y escribe las predicciones de salida como archivos de texto en el directorio de trabajo especificado. Si la canalización se ejecuta en modo de transmisión, lee las moléculas de entrada a medida que llegan desde un tema de Pub/Sub. La canalización escribe las predicciones resultantes cuando están listas en un tema de Pub/Sub diferente.
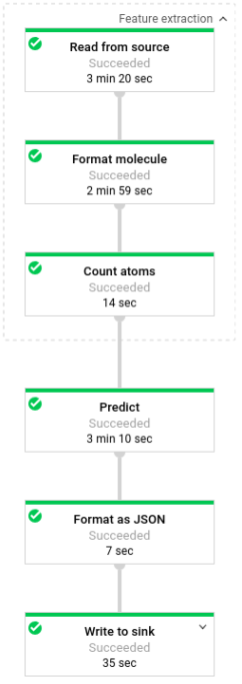
En la siguiente imagen, se muestran los pasos en las canalizaciones de predicción (por lotes y de transmisión).
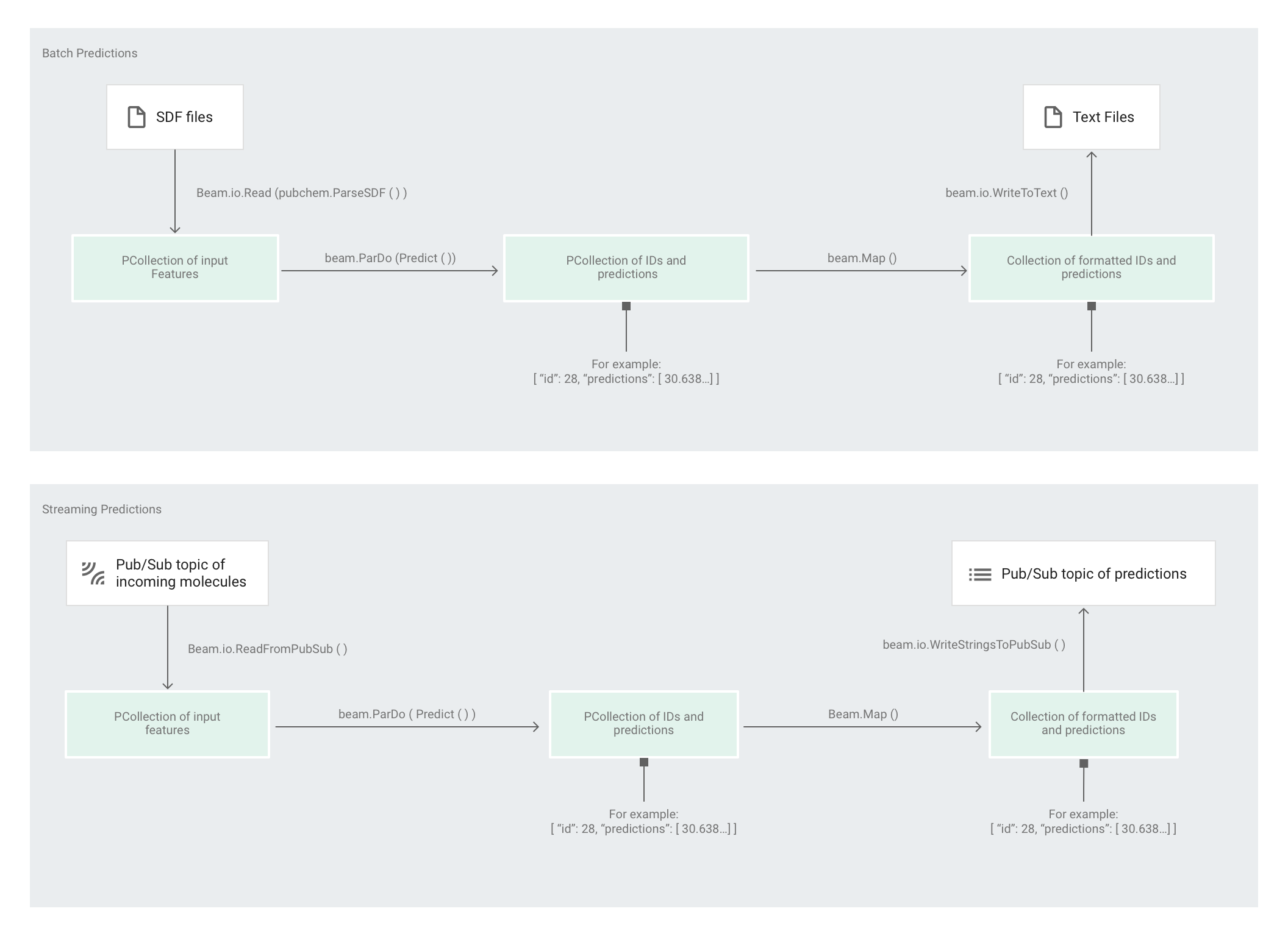
En predict.py, el código define la canalización en la función run:
El código llama a la función run con los siguientes parámetros:
Primero, el código pasa la transformación pubchem.SimpleFeatureExtraction(source) como la transformación feature_extraction. Esta transformación, que también se usó en la fase de procesamiento previo, se aplica a la canalización:
La transformación lee desde la fuente apropiada en función del modo de ejecución de la canalización (por lotes o de transmisión), da formato a las moléculas y cuenta los diferentes átomos en cada una.
A continuación, se aplica beam.ParDo(Predict(…)) a la canalización que realiza la predicción de la energía molecular.
Predict, el DoFn que se pasa, usa el diccionario dado de atributos de entrada (conteos de átomos) para predecir la energía molecular.
La siguiente transformación que se aplica a la canalización es beam.Map(lambda result: json.dumps(result)), que toma el diccionario de resultados de predicción y lo serializa en una string JSON.
Por último, el resultado se escribe en el receptor (ya sea como archivos de texto en el directorio de trabajo en el modo por lotes o como mensajes publicados en un tema de Pub/Sub en el modo de transmisión).
Predicciones por lotes
Las predicciones por lotes están optimizadas para la capacidad de procesamiento en lugar de la latencia. Las predicciones por lotes funcionan mejor si realizas muchas predicciones y puedes esperar a que todas terminen para obtener los resultados.
Ejecuta la canalización de predicción en modo por lotes
Ejecuta la canalización de predicción por lotes de forma local:
# For simplicity, we'll use the same files we used for training
python predict.py \
--model-dir $MODEL_DIR \
batch \
--inputs-dir /tmp/cloudml-samples/molecules/data \
--outputs-dir /tmp/cloudml-samples/molecules/predictions
O bien, ejecútala en Dataflow:
# For simplicity, we'll use the same files we used for training
PROJECT=$(gcloud config get-value project)
WORK_DIR=gs://<your bucket name>/cloudml-samples/molecules
python predict.py \
--work-dir $WORK_DIR \
--model-dir $MODEL_DIR \
batch \
--project $PROJECT \
--runner DataflowRunner \
--temp_location $WORK_DIR/beam-temp \
--setup_file ./setup.py \
--inputs-dir $WORK_DIR/data \
--outputs-dir $WORK_DIR/predictions
Una vez que se ejecuta la canalización, puedes ver su progreso en la interfaz de supervisión de Dataflow:
Predicciones de transmisión
Las predicciones de transmisión están optimizadas para la latencia en lugar de la capacidad de procesamiento. Las predicciones de transmisión funcionan mejor si realizas predicciones esporádicas, pero deseas obtener los resultados lo antes posible.
El servicio de predicción (la canalización de predicción de transmisión) recibe las moléculas de entrada desde un tema de Pub/Sub y publica el resultado (las predicciones) en otro tema de Pub/Sub.
Crea el tema de Pub/Sub de entradas:
gcloud pubsub topics create molecules-inputs
Crea el tema de Pub/Sub de salidas:
gcloud pubsub topics create molecules-predictions
Ejecuta la canalización de predicción de transmisión de forma local:
# Run on terminal 1
PROJECT=$(gcloud config get-value project)
python predict.py \
--model-dir $MODEL_DIR \
stream \
--project $PROJECT
--inputs-topic molecules-inputs \
--outputs-topic molecules-predictions
O bien, ejecútala en Dataflow:
# Run on terminal 1
PROJECT=$(gcloud config get-value project)
WORK_DIR=gs://<your bucket name>/cloudml-samples/molecules
python predict.py \
--work-dir $WORK_DIR \
--model-dir $MODEL_DIR \
stream \
--project $PROJECT
--runner DataflowRunner \
--temp_location $WORK_DIR/beam-temp \
--setup_file ./setup.py \
--inputs-topic molecules-inputs \
--outputs-topic molecules-predictions
Después de ejecutar el servicio de predicción (la canalización de predicción de transmisión), debes ejecutar un publicador para enviar las moléculas al servicio de predicción y un suscriptor a fin de estar a la escucha de los resultados de las predicciones. El ejemplo de código de Moléculas proporciona servicios de publicador (publisher.py) y suscriptor (subscriber.py).
El publicador analiza los archivos SDF de un directorio y los publica en el tema de entradas. El suscriptor está a la escucha de los resultados de predicción y los registra. Para simplificar, en este ejemplo se usan los mismos archivos SDF de la fase de entrenamiento.
Ejecuta el suscriptor:
# Run on terminal 2
python subscriber.py \
--project $PROJECT \
--topic molecules-predictions
Ejecuta el publicador:
# Run on terminal 3
python publisher.py \
--project $PROJECT \
--topic molecules-inputs \
--inputs-dir $WORK_DIR/data
Una vez que el publicador comience a analizar y publicar las moléculas, comenzarás a ver las predicciones del suscriptor.
Limpieza
Una vez que termines de ejecutar la canalización de predicciones de transmisión, detenla para evitar incurrir en cargos.
Pasos siguientes
- Consulta la documentación de Apache Beam
- Lee la documentación de TensorFlow:
- Prueba otra muestra de código que use Apache Beam y
tf.Transform. - Entrena un modelo de AA para clasificar series temporales con el ejemplo de Global Fishing Watch.