Neste documento, descrevemos como configurar um pipeline de integração/implantação contínuas (CI/CD) para processar dados implementando métodos de CI/CD com produtos gerenciados no Google Cloud. Os cientistas e analistas de dados podem adaptar as metodologias das práticas de CI/CD para garantir alta qualidade, facilidade de manutenção e de adaptação dos processos de dados e fluxos de trabalho. É possível aplicar os seguintes métodos:
- Controle de versão do código-fonte
- Desenvolvimento, teste e implantação automáticos de apps
- Isolamento de ambiente e separação da produção
- Replicação de procedimentos para configuração de ambiente
Este documento visa ajudar os cientistas e analistas de dados que criam jobs recorrentes de processamento de dados a estruturar o processo de pesquisa e desenvolvimento (P&D) para sistematizar e automatizar as cargas de trabalho.
Arquitetura
Veja no diagrama a seguir uma visualização detalhada das etapas do pipeline de CI/CD.

As implantações nos ambientes de teste e produção são separadas em dois pipelines diferentes do Cloud Build: um de teste e outro de produção.
No diagrama anterior, o pipeline de teste consiste nas seguintes etapas:
- Um desenvolvedor confirma as alterações de código no Cloud Source Repositories.
- As alterações acionam uma compilação de teste no Cloud Build.
- O Cloud Build cria o arquivo JAR autoexecutável e o implanta no bucket do JAR de teste no Cloud Storage.
- O Cloud Build implanta os arquivos de teste nos buckets do arquivo de teste no Cloud Storage.
- O Cloud Build define a variável no Cloud Composer para chamar o arquivo JAR recém-implantado.
- O Cloud Build testa o fluxo de trabalho Directed Acyclic Graph (DAG) (em inglês) do processamento de dados e o implanta no bucket do Cloud Composer no Cloud Storage.
- O arquivo DAG do fluxo de trabalho é implantado no Cloud Composer.
- O Cloud Build aciona a execução do fluxo de trabalho de processamento de dados recém-implantado.
- Quando o teste de integração do fluxo de trabalho de processamento de dados é aprovado, uma mensagem é publicada no Pub/Sub que contém uma referência ao JAR de execução automática mais recente (recebido das variáveis do Airflow) no campo de dados da mensagem.
No diagrama anterior, o pipeline de produção consiste nas seguintes etapas:
- O pipeline de implantação de produção é acionado quando uma mensagem é publicada em um tópico do Pub/Sub.
- Um desenvolvedor aprova manualmente o pipeline de implantação da produção e o build é executado.
- O Cloud Build copia o arquivo JAR autoexecutável mais recente do bucket do JAR de teste para o bucket do JAR de produção no Cloud Storage.
- O Cloud Build testa o DAG do fluxo de trabalho de processamento de dados de produção e o implanta no bucket do Cloud Composer no Cloud Storage.
- O arquivo DAG do fluxo de trabalho de produção é implantado no Cloud Composer.
Neste documento de arquitetura de referência, o fluxo de trabalho de processamento de dados de produção é implantado no mesmo ambiente do Cloud Composer que o fluxo de teste para fornecer uma visão consolidada de todas as tarefas de processamento de dados. Para os fins dessa arquitetura de referência, os ambientes são separados usando diferentes buckets do Cloud Storage para armazenar os dados de entrada e saída.
Se você quiser separar completamente os ambientes, precisará criar vários ambientes do Cloud Composer em diferentes projetos, que são separados um do outro por padrão. Essa separação ajuda a proteger seu ambiente de produção. No entanto, esse procedimento não faz parte do escopo deste tutorial. Para mais informações de como acessar recursos em vários projetos do Google Cloud, consulte Como definir permissões de conta de serviço.
Fluxo de trabalho de processamento de dados
As instruções sobre como o Cloud Composer executa o fluxo de trabalho de processamento de dados são definidas em um Directed Acyclic Graph (DAG) (em inglês) escrito em Python. No DAG, todas as etapas do fluxo são indicadas juntamente com as dependências entre elas.
O pipeline de CI/CD implanta automaticamente a definição do DAG do Cloud Source Repositories para o Cloud Composer em cada compilação. Esse processo garante que o Cloud Composer esteja sempre atualizado com as instruções mais recentes de fluxo de trabalho, sem precisar de intervenção humana.
Além do fluxo de trabalho de processamento de dados, a definição do DAG para o ambiente de teste também contém instruções da etapa completa de teste, que ajuda a garantir a execução correta do processamento de dados.
O fluxo de trabalho de processamento de dados está ilustrado no diagrama a seguir.
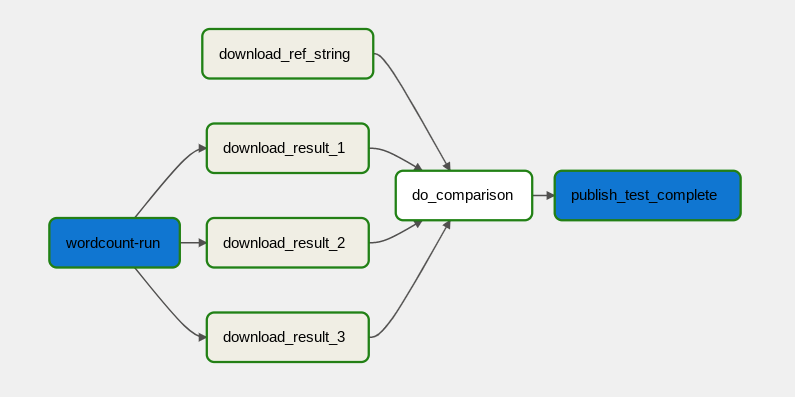
O fluxo de trabalho de processamento de dados consiste nas seguintes etapas:
- Executar o processo de dados WordCount no Dataflow.
Fazer o download dos arquivos de saída do processo WordCount, que gera três arquivos:
download_result_1download_result_2download_result_3
Fazer o download do arquivo de referência chamado
download_ref_string.Comparar o resultado com o arquivo de referência. Esse teste de integração agrega as três saídas e compara os resultados com o arquivo de referência.
Publique uma mensagem no Pub/Sub depois que o teste de integração for aprovado.
Usar uma estrutura de orquestração de tarefas, como o Cloud Composer, para gerenciar o fluxo de trabalho de processamento de dados ajuda a reduzir a complexidade do código do fluxo.
Otimização de custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Implantação
Para implantar essa arquitetura, consulte Implantar um pipeline de CI/CD para fluxos de trabalho de processamento de dados.
A seguir
- Saiba mais sobre Entrega contínua no estilo GitOps com o Cloud Build.
- Saiba mais sobre os padrões comuns de casos de uso do Dataflow (em inglês).
- Saiba mais sobre engenharia de lançamento.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.