This document describes how to set up a continuous integration/continuous deployment (CI/CD) pipeline for processing data by implementing CI/CD methods with managed products on Google Cloud. Data scientists and analysts can adapt the methodologies from CI/CD practices to help to ensure high quality, maintainability, and adaptability of the data processes and workflows. The methods that you can apply are as follows:
- Version control of source code.
- Automatic building, testing, and deployment of apps.
- Environment isolation and separation from production.
- Replicable procedures for environment setup.
This document is intended for data scientists and analysts who build recurrent running data-processing jobs to help structure their research and development (R&D) to systematically and automatically maintain data-processing workloads.
Architecture
The following diagram shows a detailed view of the CI/CD pipeline steps.

The deployments to the test and production environments are separated into two different Cloud Build pipelines–a test and a production pipeline.
In the preceding diagram, the test pipeline consists of the following steps:
- A developer commits code changes to the Cloud Source Repositories.
- Code changes trigger a test build in Cloud Build.
- Cloud Build builds the self-executing JAR file and deploys it to the test JAR bucket on Cloud Storage.
- Cloud Build deploys the test files to the test-file buckets on Cloud Storage.
- Cloud Build sets the variable in Cloud Composer to reference the newly deployed JAR file.
- Cloud Build tests the data-processing workflow Directed Acyclic Graph (DAG) and deploys it to the Cloud Composer bucket on Cloud Storage.
- The workflow DAG file is deployed to Cloud Composer.
- Cloud Build triggers the newly deployed data-processing workflow to run.
- When the data-processing workflow integration test has passed, a message is published to Pub/Sub which contains a reference to the latest self-executing JAR (obtained from the Airflow variables) in the message’s data field.
In the preceding diagram, the production pipeline consists of the following steps:
- The production deployment pipeline is triggered when a message is published to a Pub/Sub topic.
- A developer manually approves the production deployment pipeline and the build is run.
- Cloud Build copies the latest self-executing JAR file from the test JAR bucket to the production JAR bucket on Cloud Storage.
- Cloud Build tests the production data-processing workflow DAG and deploys it to the Cloud Composer bucket on Cloud Storage.
- The production workflow DAG file is deployed to Cloud Composer.
In this reference architecture document, the production data-processing workflow is deployed to the same Cloud Composer environment as the test workflow, to give a consolidated view of all data-processing workflows. For the purposes of this reference architecture, the environments are separated by using different Cloud Storage buckets to hold the input and output data.
To completely separate the environments, you need multiple Cloud Composer environments created in different projects, which are by default separated from each other. This separation helps to secure your production environment. This approach is outside the scope of this tutorial. For more information about how to access resources across multiple Google Cloud projects, see Setting service account permissions.
The data-processing workflow
The instructions for how Cloud Composer runs the data-processing workflow are defined in a Directed Acyclic Graph (DAG) written in Python. In the DAG, all the steps of the data-processing workflow are defined together with the dependencies between them.
The CI/CD pipeline automatically deploys the DAG definition from Cloud Source Repositories to Cloud Composer in each build. This process ensures that Cloud Composer is always up to date with the latest workflow definition without needing any human intervention.
In the DAG definition for the test environment, an end-to-end test step is defined in addition to the data-processing workflow. The test step helps make sure that the data-processing workflow runs correctly.
The data-processing workflow is illustrated in the following diagram.
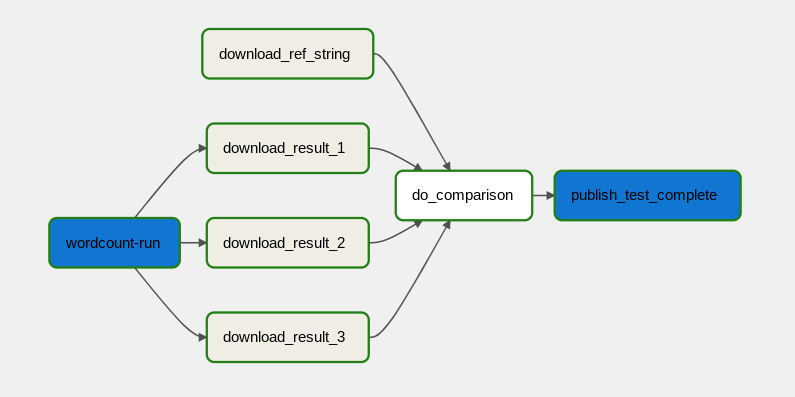
The data-processing workflow consists of the following steps:
- Run the WordCount data process in Dataflow.
Download the output files from the WordCount process. The WordCount process outputs three files:
download_result_1download_result_2download_result_3
Download the reference file, called
download_ref_string.Verify the result against the reference file. This integration test aggregates all three results and compares the aggregated results with the reference file.
Publish a message to Pub/Sub after the integration test has passed.
Using a task-orchestration framework such as Cloud Composer to manage the data-processing workflow helps alleviate the code complexity of the workflow.
Cost optimization
In this document, you use the following billable components of Google Cloud:
Deployment
To deploy this architecture, see Deploy a CI/CD pipeline for data-processing workflows.
What's next
- Learn more about GitOps-style continuous delivery with Cloud Build.
- Learn more about Common Dataflow use-case patterns.
- Learn more about Release Engineering.
- For more reference architectures, diagrams, and best practices, explore the Cloud Architecture Center.