本教程旨在向数据分析师介绍 BigQuery ML 中的矩阵分解模型。通过 BigQuery ML,用户可以利用 SQL 查询在 BigQuery 中创建和执行机器学习模型。其目标是让 SQL 专业人员能够利用现有的工具构建模型,并通过消除数据移动需求来提高开发速度,从而实现机器学习的普及。
在本教程中,您将学习如何使用 GA360_test.ga_sessions_sample 示例表基于隐式反馈创建一个根据给定访问者 ID 和内容 ID 提供推荐内容的矩阵分解模型。
ga_sessions_sample 表包含由 Google Analytics 360 收集并发送到 BigQuery 的会话数据切片的相关信息。
目标
在本教程中,您将使用以下内容:
- BigQuery ML:使用
CREATE MODEL语句创建隐式推荐模型。 ML.EVALUATE函数:用于评估机器学习模型。ML.WEIGHTS函数:用于检查训练过程中生成的潜在因子权重。ML.RECOMMEND函数:用于为用户生成推荐内容。
费用
本教程使用 Google Cloud 的如下计费组件:
- BigQuery
- BigQuery ML
如需详细了解 BigQuery 费用,请参阅 BigQuery 价格页面。
如需详细了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 新项目会自动启用 BigQuery。如需在现有项目中激活 BigQuery,请转到
启用 BigQuery API。
第一步:创建数据集
创建 BigQuery 数据集以存储您的机器学习模型:
在 Google Cloud 控制台中,转到 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。

在创建数据集页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 US (multiple regions in United States)(美国[美国的多个区域])。
公共数据集存储在
US多区域中。为简单起见,请将数据集存储在同一位置。保持其余默认设置不变,然后点击创建数据集。

第二步:将 Analytics 360 数据加载到 BigQuery 中
大多数情况下,数据中的评分不会反映用户明确设置的值。在这些情况下,我们可以为这些值设计一个代理作为隐式评分,并使用另一种算法来计算推荐内容。在此示例中,我们将使用示例 Analytics 360 数据集。此示例采用以下文章中的数据。
以下是要运行的查询,用于根据 cloud-training-demos.GA360_test.ga_sessions_sample 中访问者在页面上的会话时长来创建具有隐式评分的数据集。此查询的目标是创建一个包含三列的数据集,我们可以将其映射到用户列、内容项列和评分列。
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL CREATE OR REPLACE TABLE bqml_tutorial.analytics_session_data AS WITH visitor_page_content AS ( SELECT fullVisitorID, ( SELECT MAX( IF (index=10, value, NULL)) FROM UNNEST(hits.customDimensions)) AS latestContentId, (LEAD(hits.time, 1) OVER (PARTITION BY fullVisitorId ORDER BY hits.time ASC) - hits.time) AS session_duration FROM `cloud-training-demos.GA360_test.ga_sessions_sample`, UNNEST(hits) AS hits WHERE # only include hits on pages hits.type = "PAGE" GROUP BY fullVisitorId, latestContentId, hits.time ) # aggregate web stats SELECT fullVisitorID AS visitorId, latestContentId AS contentId, SUM(session_duration) AS session_duration FROM visitor_page_content WHERE latestContentId IS NOT NULL GROUP BY fullVisitorID, latestContentId HAVING session_duration > 0 ORDER BY latestContentId(可选)如需设置处理位置,请依次点击更多 > 查询设置。在处理位置部分中,选择
US。此步骤是可选的,因为系统将根据数据集的位置自动检测处理位置。
点击运行。
查询运行完毕后,(
bqml_tutorial.analytics_session_data) 将显示在导航面板中。由于查询使用CREATE TABLE语句来创建表,因此您看不到查询结果。如果您查看生成的表,其应如下所示:
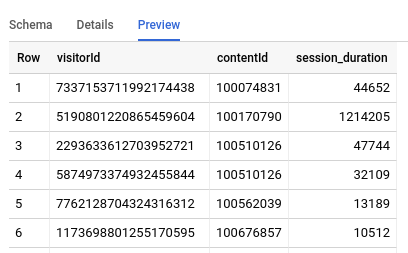
请注意,此结果会因数据导出到 BigQuery 的方式而异。用于提取您自己数据的查询可能会有所不同。
第三步:创建隐式推荐模型
接下来,您将使用上一步中加载的 Google Analytics(分析)表格创建隐式推荐模型。以下 GoogleSQL 查询用于创建将用来预测每个 visitorId contentId 对的置信度评分的模型。系统创建评分的方法是,按会话时长中位数确定中心值并进行扩缩,然后将会话时长超过中位数 3.33 倍的记录过滤为离群值。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_implicit_mf_model` OPTIONS (model_type='matrix_factorization', feedback_type='implicit', user_col='visitorId', item_col='contentId', rating_col='rating', l2_reg=30, num_factors=15) AS SELECT visitorId, contentId, 0.3 * (1 + (session_duration - 57937) / 57937) AS rating FROM `bqml_tutorial.analytics_session_data` WHERE 0.3 * (1 + (session_duration - 57937) / 57937) < 1
查询详情
CREATE MODEL 子句用于创建和训练名为 bqml_tutorial.my_implicit_mf_model 的模型。
OPTIONS(model_type='matrix_factorization', feedback_type='IMPLICIT',
user_col='visitorId', ...) 子句表示您正在创建矩阵分解模型。由于指定了 feedback_type='IMPLICIT',因此系统将训练隐式矩阵分解模型。
如需查看如何创建显式矩阵分解模型的示例,请参阅创建显式矩阵分解模型。
此查询的 SELECT 语句使用以下列生成推荐内容。
visitorId- 访问者 ID (INT64)。contentId- 内容 ID (INT64)。rating- 为visitorId及其各自居中和缩放的contentId计算的隐式评分(从 0 到 1,FLOAT64)。
FROM 子句 - bqml_tutorial.analytics_session_data - 表示您正在查询 bqml_tutorial 数据集中的 analytics_session_data 表。
如果按照第二步和第八步中的说明操作,则此数据集位于您的 BigQuery 项目中。
运行 CREATE MODEL 查询
要运行 CREATE MODEL 查询来创建和训练模型,请执行以下操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_implicit_mf_model` OPTIONS (model_type='matrix_factorization', feedback_type='implicit', user_col='visitorId', item_col='contentId', rating_col='rating', l2_reg=30, num_factors=15) AS SELECT visitorId, contentId, 0.3 * (1 + (session_duration - 57937) / 57937) AS rating FROM `bqml_tutorial.analytics_session_data`
点击运行。
查询大约需要 12 分钟才能完成,之后您的模型 (
my_implicit_mf_model) 会显示在导航面板中。由于查询使用CREATE MODEL语句来创建模型,因此您看不到查询结果。
第四步(可选):获取训练统计信息
如需查看模型训练的结果,您可以使用 ML.TRAINING_INFO 函数,也可以在 Google Cloud 控制台中查看统计信息。在本教程中,您将使用 Google Cloud 控制台。
机器学习算法通过检查众多示例并尝试找到实现损失最小化的模型来构建模型。该过程称为经验风险最小化。
要查看运行 CREATE MODEL 查询时生成的模型训练统计信息,请执行以下操作:
在 Google Cloud 控制台导航面板的资源部分中,展开 [PROJECT_ID] > bqml_tutorial,然后点击 my_implicit_mf_model。
点击训练标签页,然后点击表。结果应如下所示:
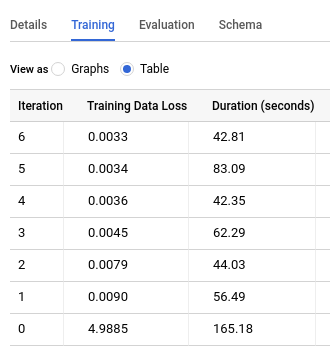
训练数据丢失列表示在训练数据集上训练模型后计算得出的损失指标。由于您执行了矩阵分解,因此该列为均方误差。默认情况下,矩阵分解模型不会拆分数据,因此除非指定保留数据集,否则评估数据损失列不会显示,因为拆分数据可能会丢失用户或推荐项的所有评分。因此,该模型不会显示有关丢失用户或推荐项的潜在因子信息。
如需详细了解
ML.TRAINING_INFO函数,请参阅 BigQuery ML 语法参考。
第五步:评估模型
创建模型后,您可以使用 ML.EVALUATE 函数评估推荐模型的性能。ML.EVALUATE 函数根据实际评分来评估预测评分。
用于评估模型的查询如下所示:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_implicit_mf_model`)
查询详情
最顶层的 SELECT 语句从模型中检索列。
FROM 子句使用 ML.EVALUATE 函数评估模型 bqml_tutorial.my_implicit_mf_model。
运行 ML.EVALUATE 查询
要运行 ML.EVALUATE 查询以评估模型,请执行以下操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_implicit_mf_model`)
(可选)如需设置处理位置,请依次点击更多 > 查询设置。在处理位置部分中,选择
US。此步骤是可选的,因为系统将根据数据集的位置自动检测处理位置。 点击运行。
查询完成后,点击查询文本区域下方的结果标签页。结果应如下所示:

由于您执行了隐式矩阵分解,因此结果包含以下列:
mean_average_precisionmean_squared_errornormalized_discounted_cumulative_gainaverage_rank
mean_average_precision、normalized_discounted_cumulative_gain和average_rank是排名指标,详情请参阅隐式矩阵分解指标。
第六步:预测评分并作出推荐
使用模型预测评分并作出推荐
查找一组 visitorIds 的所有 contentId 评分置信度
ML.RECOMMEND 不需要接受除模型之外的任何其他参数,但可以接受可选表。如果输入表中只有一列与输入 user 或输入 item 列的名称匹配,则将输出每个 user 的所有预测推荐项评分,反之亦然。请注意,如果输入表中包含所有 users 或所有 items,则 ML.RECOMMEND 的输出结果与不传递可选参数时相同。
以下示例演示了查询如何提取 5 个访问者的所有预测评分置信度。
#standardSQL
SELECT
*
FROM
ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`,
(
SELECT
visitorId
FROM
`bqml_tutorial.analytics_session_data`
LIMIT 5))
查询详情
最顶层的 SELECT 语句检索 visitorId、contentId 和 predicted_rating_confidence 列。最后一列由 ML.RECOMMEND 函数生成。当您使用 ML.RECOMMEND 函数时,隐式矩阵分解模型的输出列名称为 predicted_rating-column-name_confidence。对于隐式矩阵分解模型来说,predicted_rating_confidence 是 user/item 对的估计置信度。此置信度值大致介于 0 到 1 之间,user 偏爱置信度值高的 item,而非置信度值较低的 item。
ML.RECOMMEND 函数用于通过模型 bqml_tutorial.my_implicit_mf_model 预测评分。
此查询的嵌套 SELECT 语句仅从用于训练的原始表中选择 visitorId 列。
LIMIT 子句 - LIMIT 5 - 将随机过滤出 5 个 visitorId 以发送到 ML.RECOMMEND。
查找所有“visitorId-contentId”对的评分
您现已对模型进行了评估,下一步是使用该模型获得评分置信度。您可以使用模型在以下查询中预测每个“用户-推荐项”组合的置信度:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`)
查询详情
最顶层的 SELECT 语句检索 visitorId、contentId 和 predicted_rating_confidence 列。最后一列由 ML.RECOMMEND 函数生成。当您使用 ML.RECOMMEND 函数时,隐式矩阵分解模型的输出列名称为 predicted_rating-column-name_confidence。对于隐式矩阵分解模型来说,predicted_rating_confidence 是 user/item 对的估计置信度。此置信度值大致介于 0 到 1 之间,user 偏爱置信度值高的 item,而非置信度值较低的 item。
ML.RECOMMEND 函数用于通过模型 bqml_tutorial.my_implicit_mf_model 预测评分。
将结果保存到表的一种方法如下:
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_content` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`)
如果 ML.RECOMMEND 发生 Query Exceeded Resource Limits 错误,请使用较高的结算层级重试。在 BigQuery 命令行工具中,可以使用 --maximum_billing_tier 标志设置结算层级。
生成推荐内容
以下查询使用 ML.RECOMMEND 为每个 visitorId 输出推荐的前 5 个 contentId。
#standardSQL
SELECT
visitorId,
ARRAY_AGG(STRUCT(contentId, predicted_rating_confidence)
ORDER BY predicted_rating_confidence DESC LIMIT 5) AS rec
FROM
`bqml_tutorial.recommend_content`
GROUP BY
visitorId
查询详情
SELECT 语句使用 GROUP BY visitorId 聚合 ML.RECOMMEND 查询的结果,以按降序聚合 contentId 和 predicted_rating_confidence,结果仅保留前 5 个内容 ID。
使用之前的推荐查询,我们可以按预测评分排序,并为每个用户输出预测最准的推荐项。以下查询将 item_ids 和之前上传的 movielens.movie_titles 表中的 movie_ids 联接起来,为每位用户输出推荐的前 5 部电影。
运行 ML.RECOMMEND 查询
如需运行 ML.RECOMMEND 查询为每个访问者 ID 输出推荐的前 5 个内容 ID,请执行以下操作:
在 Google Cloud 控制台中,点击编写新查询按钮。
在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_content` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_implicit_mf_model`)
点击运行。
查询运行完毕后,(
bqml_tutorial.recommend_content) 会显示在 Google Cloud 控制台的导航面板中。由于查询使用CREATE TABLE语句来创建表,因此您看不到查询结果。编写新查询。在上一个查询运行完毕后,在查询编辑器文本区域中输入以下 GoogleSQL 查询。
#standardSQL SELECT visitorId, ARRAY_AGG(STRUCT(contentId, predicted_rating_confidence) ORDER BY predicted_rating_confidence DESC LIMIT 5) AS rec FROM `bqml_tutorial.recommend_content` GROUP BY visitorId
(可选)如需设置处理位置,请依次点击更多 > 查询设置。在处理位置部分中,选择
US。此步骤是可选的,因为系统将根据数据集的位置自动检测处理位置。 点击运行。
查询完成后,点击查询文本区域下方的结果标签页。结果应如下所示:
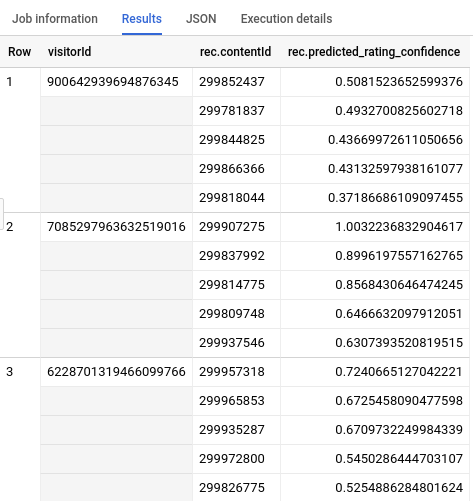
清除数据
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- 删除您在教程中创建的项目。
- 或者,保留项目但删除数据集。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在 Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击窗口右侧的删除数据集。此操作会删除相关数据集、表和所有数据。
在删除数据集对话框中,输入您的数据集的名称 (
bqml_tutorial),然后点击删除以确认删除命令。
删除项目
要删除项目,请执行以下操作:
- 在 Google Cloud 控制台中,进入管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
后续步骤
- 要详细了解机器学习,请参阅机器学习速成课程。
- 如需大致了解 BigQuery ML,请参阅 BigQuery ML 简介。
- 如需详细了解 Google Cloud 控制台,请参阅使用 Google Cloud 控制台。