Ce document explique comment configurer un pipeline d'intégration continue/de déploiement continu (CI/CD) pour le traitement des données en appliquant des méthodes CI/CD à l'aide de produits gérés sur Google Cloud. Les data scientists et les analystes peuvent adapter les méthodologies mises en œuvre dans les pratiques CI/CD pour garantir la haute qualité, la facilité de gestion et l'adaptabilité des processus de données et des workflows. Vous pouvez appliquer les méthodes suivantes :
- Contrôle des versions du code source
- Création, test et déploiement automatiques d'applications
- Isolation et séparation des environnements de développement et de test de l'environnement de production
- Procédures reproductibles pour la configuration des environnements
Ce document est destiné aux data scientists et aux analystes qui créent et exécutent des tâches récurrentes de traitement des données afin de structurer leurs activités de recherche et développement (R&D), et de gérer de manière systématique et automatique les charges de travail de traitement des données.
Architecture
Le schéma suivant présente une vue détaillée des étapes du pipeline CI/CD.

Les déploiements dans les environnements de test et de production sont séparés en deux pipelines Cloud Build différents : un pipeline de test et un pipeline de production.
Dans le schéma précédent, le pipeline de test comprend les étapes suivantes :
- Un développeur valide les modifications de code dans Cloud Source Repositories.
- Les modifications de code déclenchent une compilation test dans Cloud Build.
- Cloud Build crée le fichier JAR auto-exécutable et le déploie dans le bucket JAR de test sur Cloud Storage.
- Cloud Build déploie les fichiers de test dans les buckets de fichiers de test sur Cloud Storage.
- Cloud Build définit dans Cloud Composer la variable utilisée pour référencer le fichier JAR qui vient d'être déployé.
- Cloud Build teste le graphe orienté acyclique (DAG, Directed Acyclic Graph) du workflow de traitement des données et le déploie dans le bucket Cloud Composer sur Cloud Storage.
- Le fichier DAG du workflow est déployé dans Cloud Composer.
- Cloud Build déclenche l'exécution du workflow de traitement des données qui vient d'être déployé.
- Une fois le test d'intégration du workflow de traitement des données passé, un message est publié dans Pub/Sub contenant une référence au dernier fichier JAR auto-exécutable (obtenu à partir des variables Airflow) dans les données du message.
Dans le schéma précédent, le pipeline de production comprend les étapes suivantes :
- Le pipeline de déploiement en production est déclenché lorsqu'un message est publié dans un sujet Pub/Sub.
- Un développeur approuve manuellement le pipeline de déploiement en production et la compilation est exécutée.
- Cloud Build copie le dernier fichier JAR auto-exécutable à partir du bucket JAR de test vers le bucket JAR de production sur Cloud Storage.
- Cloud Build teste le DAG du workflow de production de traitement des données et le déploie dans le bucket Cloud Composer sur Cloud Storage.
- Le fichier DAG du workflow de production est déployé dans Cloud Composer.
Dans ce document d'architecture de référence, le workflow de production est déployé dans le même environnement Cloud Composer que le workflow de test afin de fournir une vue consolidée de tous les workflows. Pour les besoins de cette architecture de référence, les environnements sont séparés par l'utilisation de différents buckets Cloud Storage pour stocker les données d'entrée et de sortie.
Pour séparer complètement les deux environnements, vous devez créer plusieurs environnements Cloud Composer dans différents projets, séparés par défaut les uns des autres. Cette séparation permet de sécuriser votre environnement de production. Cette approche n'entre pas dans le cadre de ce tutoriel. Pour en savoir plus sur l'accès aux ressources de plusieurs projets Google Cloud, consultez la page Définir des autorisations de compte de service.
Le workflow de traitement des données
Les instructions relatives à l'exécution du workflow de traitement des données par Cloud Composer sont définies dans un graphe orienté acyclique (DAG) écrit en Python. Le DAG définit toutes les étapes du workflow de traitement des données, ainsi que les dépendances entre elles.
Le pipeline CI/CD déploie automatiquement la définition du DAG à partir de Cloud Source Repositories dans Cloud Composer, dans chaque compilation. Ce processus garantit que Cloud Composer est toujours à jour avec la dernière définition du workflow sans qu'aucune intervention humaine ne soit requise.
En plus du workflow de traitement des données, la définition du DAG pour l'environnement de test comprend une étape de test de bout en bout. Cette étape de test permet de vérifier que le workflow de traitement des données s'exécute correctement.
Le workflow de traitement des données est illustré dans le schéma suivant.
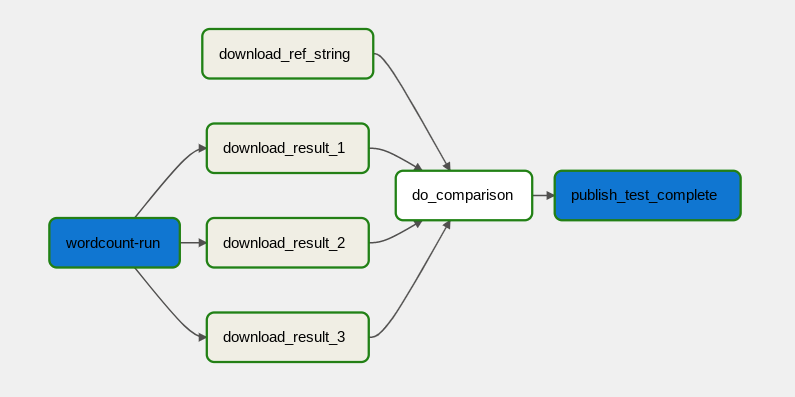
Le workflow de traitement des données comprend les étapes suivantes :
- Exécution du processus de données WordCount dans Dataflow.
Téléchargement des trois fichiers de sortie générés par le processus WordCount :
download_result_1download_result_2download_result_3
Téléchargement du fichier de référence appelé
download_ref_string.Vérification des résultats par rapport au fichier de référence. Ce test d'intégration agrège les trois résultats et compare les résultats agrégés au fichier de référence.
Publication d'un message sur Pub/Sub une fois que le test d'intégration a réussi.
L'utilisation d'un framework d'orchestration de tâches, tel que Cloud Composer, pour gérer le workflow de traitement des données permet de réduire la complexité du code du workflow.
Optimisation des coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Déploiement
Pour déployer cette architecture, consultez la page Déployer un pipeline CI/CD pour les workflows de traitement des données.
Étapes suivantes
- Découvrez la livraison continue de type GitOps avec Cloud Build.
- Apprenez-en plus sur les modèles courants de cas d'utilisation de Cloud Dataflow.
- Découvrez l'ingénierie des versions.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.